

计算机视觉技术通过卷积神经网络、语义分割算法能够快速提取图像特征,实现裂缝的精准定位与分类[5]. 在完全黑暗环境中,相机无法捕捉有效图像信息,基于图像的语义分割算法(如DeepLabV3+[6]、U-Net[7]、TransUNET[8]、Segformer[9]等)均依赖于图像的颜色、纹理、边缘等视觉特征进行特征提取. 黑暗环境导致图像的颜色信息消失,细节特征(如纹理、边缘)变得模糊不清甚至不可见,算法由此失去赖以分析的基础数据[10]. 以U-Net为例,该网络结构基于编码器-解码器架构,编码器对输入图像进行特征提取,若输入的是黑暗环境下无有效信息的“黑屏”图像,编码器无法提取有价值的图像特征,后续的特征融合与分割预测也就无从谈起[11]. 为了突破这一困境,研究人员尝试改进算法,采用主动光源技术(如红外成像[12-13]、激光雷达[14])获取图像;结合低照度图像增强算法优化视觉数据,或采用基于物理模型的方法模拟裂缝特征;通过迁移学习[15]、对抗生成网络[16]技术增强算法在低质量图像下的鲁棒性. 但这些方法仍存在局限性:主动光源易受环境干扰,在潮湿、粉尘环境中成像模糊[17];基于算法优化的解决方案虽能提升一定性能,但面对极端黑暗场景,检测准确率与稳定性仍难以满足工程需求[18].
鉴于传统视觉方法的瓶颈,本研究提出基于触觉仿生技术的全新解决途径. 与现有依赖视觉图像的裂缝检测技术不同,触觉仿生识别能够突破黑暗环境下传统检测手段对光照的依赖,通过模拟人类皮肤接触—形变—感知的闭环机制[19],从根本上解决极端黑暗环境下视觉信息缺失的痛点. 与如红外成像、激光雷达的主动光源技术相比,触觉仿生识别更能适应如潮湿、粉尘的复杂工程场景干扰.
1. 触觉仿生传感系统设计
1.1. 触觉仿生技术识别混凝土裂缝原理
图 1
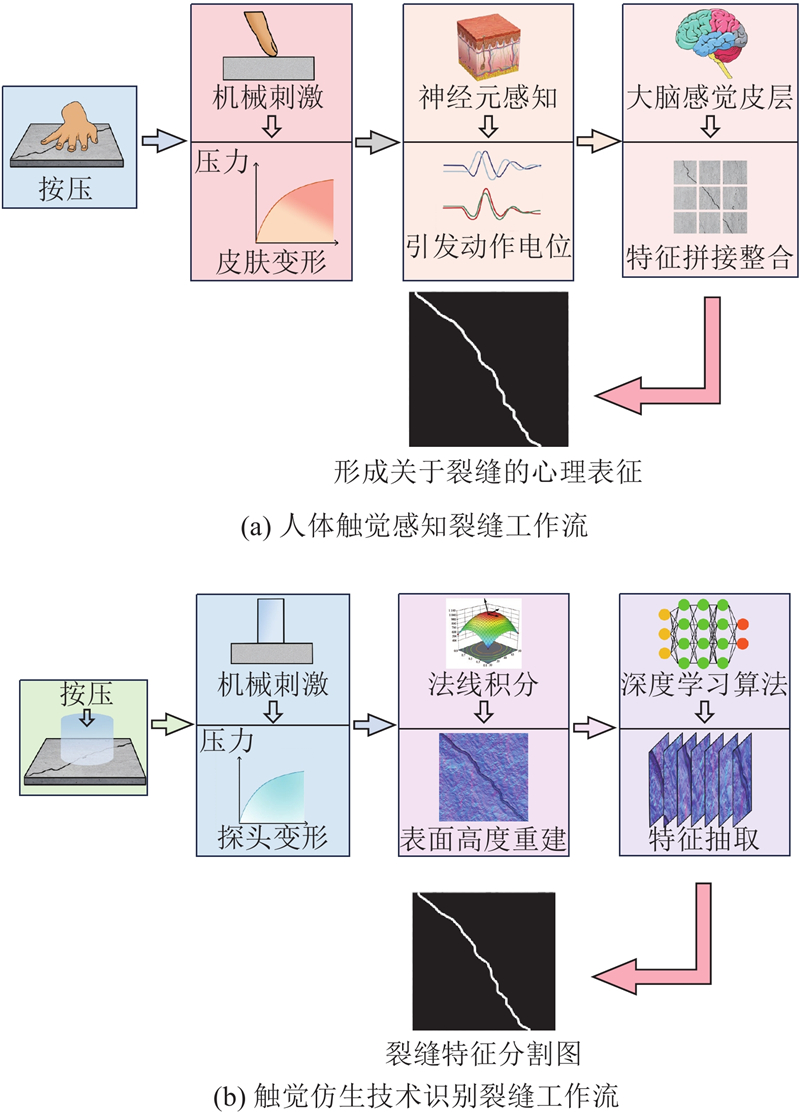
图 1 人体触觉感知和触觉仿生技术识别混凝土裂缝原理对比
Fig.1 Comparative analysis of human tactile perception and biomimetic tactile technology for concrete crack detection
1.2. 触觉探头制作
硅胶的弹性与柔韧性良好[21],因此选用易于模具加工成型的双组分加成性硅胶作为制作传感器探头的材料. 将调配好的硅胶倒入模具中,待硅胶固化后,在探头表面喷涂铝粉,使其均匀覆盖在触觉探头的硅胶表面,形成均匀反射面,减少反射不均带来的图像误差,降低外部环境光线干扰,便于摄像头清晰捕捉反射光变化. 触觉仿生探头的制作过程如图2所示.依据单轴拉伸试验测得触觉仿生探头在哑铃形态下的弹性模量为0.6 MPa,表面硬度通过邵氏硬度计测量为 Shore A 37. 将硅胶样本制备成薄片,放入分光光度计中测试,其平均透光率为 88.3%. 将探头安装于按压机构,在5 N加载力下模拟实际检测中反复按压与摩擦(探头前进位移速度为 10 mm/s)的工况,连续循环 1 000 次后,未发现明显脱落或划痕,证明铝粉涂层的均匀性与完整性可满足长期检测需求. 触觉仿生探头循环按压摩擦测试前后的表面形貌如图3所示.
图 2

图 3

图 3 触觉探头循环按压摩擦前后的表面形貌图
Fig.3 Surface topography of tactile probe before and after cyclic pressing and friction
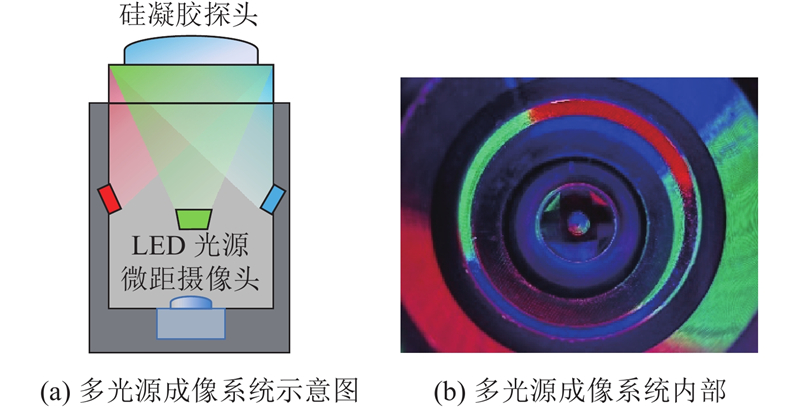
1.3. 探头表面多光源成像系统
当光线以反射或透射的形式投射至硅凝胶探头表面时,外部物体与探头的接触会引发弹性形变. 捕捉探头的弹性形变须利用光源照射产生的明暗梯度变化. 考虑到单一光源可能由于阴影、反射不均匀导致部分变形信息无法准确获取的情况,光源系统的设计参考Gelsight 技术中弹性体平台结合多光源照明实现高分辨率几何感知的核心思路[22]. Gelsight侧重机器手抓取力感知场景[23],模块化组件(如 LED 环、电极阵列)导致单传感器成本较高,且部分型号(如 GelBelt)在高速运动(>1 m/s)时易出现信号延迟. 为了更好满足未来结合移动平台实现大面积自动化检测的需求,考虑到移动平台(如爬壁机器人、小型无人机)的续航与空间限制,光源选用微型贴片式高亮度 LED,分别为红光(R)、绿光(G)、蓝光(B),波长分别为
图 4
1.4. 探头按压机构与移动搭载平台
以路面混凝土裂缝的探测应用为例,设计能够搭载触觉探头的探头按压机构与移动搭载平台,实现对混凝土裂缝的采集. 按压机构由机械臂、步进电机和齿轮组构成,步进电机通过齿轮旋转转换为机械臂向下的直线运动,实现触觉探头对路面的垂直按压动作. 移动平台采用麦克纳姆轮,可实现平台的全方位移动. 探头按压机构与移动搭载平台如图5所示.
图 5

2. 基于多光源的物体纹理重建
触觉仿生技术的核心工作原理可概括为3个部分:1)机械接触触发形变,硅胶探头与混凝土表面接触后,裂缝的凹凸结构使弹性体产生物理形变;2)通过多光源捕捉光影变化,由三色 LED 灯从不同角度照射形变表面,形成与裂缝纹理匹配的明暗梯度;3)基于朗伯反射模型,将光影强度信号转化为表面法向量信息,通过泊松方程与快速傅里叶变换(fast Fourier transform, FFT)运算,从法向量场反推裂缝的几何信息,最终生成可用于分割的触觉图像. 成像过程用反射模型描述为
式中:
式中:
式中:
式中:
为了验证触觉探头对不同尺度裂缝的检测精度,设计针对性实验:采用光敏树脂 3D 打印(试件打印尺寸精度为±0.02 mm)制作 4 个尺寸为 80 mm×80 mm×10 mm 的试件,每个试件表面刻有长80 mm、深2 mm的直角沟槽(模拟裂缝),沟槽宽度分别为 2、4、6、8 mm,如图6所示.
图 6

实验通过触觉探头采集各试件的触觉图像,利用朗伯反射模型与泊松方程重建裂缝三维形态,重建后的图像如图7所示. 图中,
图 7
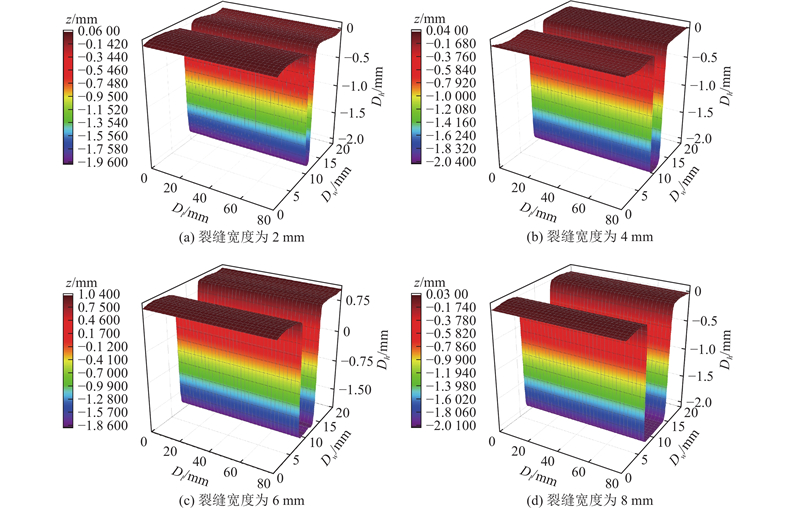
图 7 不同宽度裂缝的形貌重建效果
Fig.7 Reconstruction effect of crack morphology with different widths
3. 基于触觉图像的混凝土裂缝特征提取网络
3.1. 网络整体架构
基于语义分割算法的基本原理,构建基于触觉纹理图像的混凝土裂缝特征提取网络,命名为触觉混凝土裂缝分割网络(tactile segmentation network for concrete cracks, TSCC-Net). 该主要由4个部分组成,包括特征金字塔、语义感知提取器、互融合模块及分割头. 网络整体架构如图8所示. TSCC-Net为触觉图像专属的轻量化分割方案,相比传统视觉分割网络(如 U-Net、TransUNet)的优势如下:1)针对混凝土触觉图像纹理粗糙的特性,设计语义感知提取器强化全局语义与局部细节的关联;2)通过互融合模块解决触觉图像中高层语义与低层纹理的耦合难题;3)采用轻量化架构,满足移动检测设备的实时性需求,兼顾精度与效率.
图 8
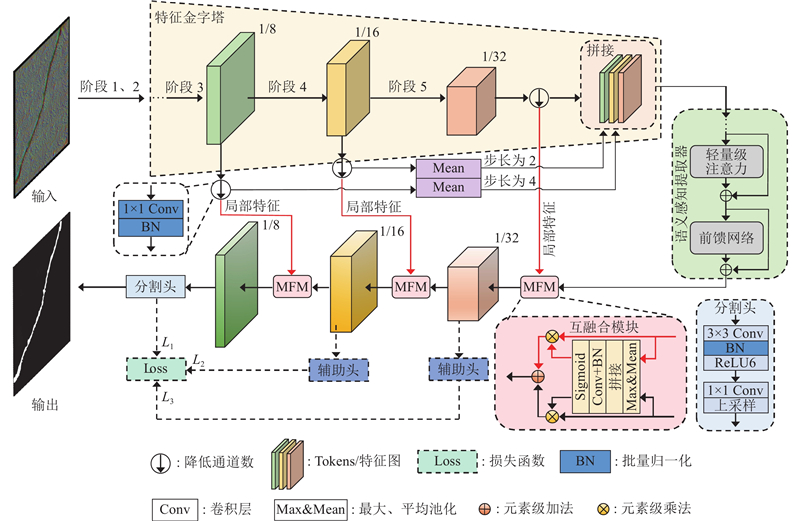
图 8 触觉混凝土裂缝分割网络的整体架构
Fig.8 Overall architecture of tactile segmentation network for concrete cracks
3.2. 语义感知提取器
语义感知提取器的作用是提取、理解和利用高层语义信息,具体构成如下.
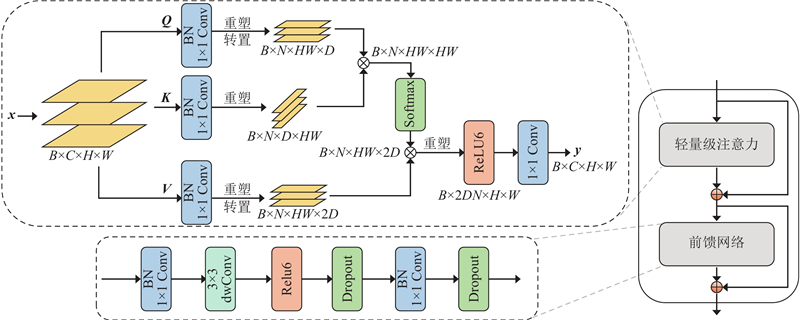
3.2.1. 轻量级注意力
对于注意力机制,为了更符合图像处理的需求,以三维张量的格式生成键值对,张量大小为
式中:
3.2.2. 前馈网络
常规的前馈网络(feed-forward network,FFN)由2个多层感知机(multilayer perceptron, MLP)层和1个3×3深度卷积(dwConv)层组成,其中深度卷积用于补充位置编码并增强定位能力. MLP(全连接层)会将输入维度扩大 2~4 倍,对移动检测所需的低延迟场景效率偏低. 为了提升效率,采用1×1卷积替换全连接层,并将FFN的扩展因子设置为2,以保持计算模式不变. 深度卷积层保留局部连接性,使重复堆叠块在保留ViT架构的同时高效运行. 语义感知提取器的示意图如图9所示.
图 9
3.3. 互融合模块
互融合模块可以增强触觉图像处理中不同区域特征之间的交互,以更好地恢复目标细节并形成更完整的特征表示. 如图10所示,前端为预处理部分,能够调整2类不同特征图的尺寸和通道数,对于来自高层的语义特征
图 10
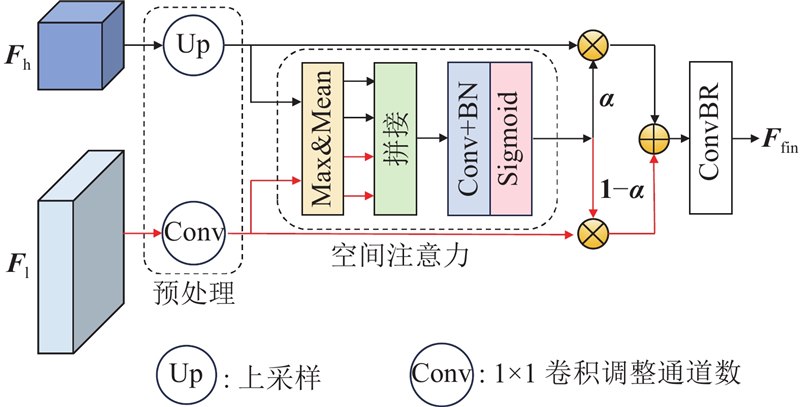
式中:
式中:
使用1×1卷积,对拼接后特征图
式中:
式中:
式中:
3.4. 辅助监督模块
为了减少触觉图像中表面纹理变化对训练的影响,在TSCC-Net中增加辅助监督模块. 除了网络解码阶段的输出结果外,对2种不同尺度的特征实施辅助监督. 通过采用在线难样本挖掘(online hard example mining, OHEM)[27]的交叉熵损失对模型CEL进行优化,最终损失为各阶段损失的加权和. 因此,TSCC-Net的最终损失表达式为
式中:
4. 实验数据集制作
4.1. 实验数据采集
基于移动搭载平台,在夜晚光照严重不足的环境中进行混凝土裂缝图像采集工作,获得对应的触觉图像. 使用LableMe软件对原始图像的裂缝进行标记和分类,构建符合模型训练需求标注数据集. 现场采集的典型裂缝图像和触觉图像标签如图11所示. 所有数据和真值按照7∶2∶1划分为训练集、测试集和验证集.
图 11

4.2. 数据增强方案
为了提升模型的泛化能力与鲁棒性,对原始数据集进行数据增强. 对原始触觉图像进行随机旋转、水平/垂直翻转、随机缩放等操作,模拟检测过程中探头不同的接触角度与距离变化. 通过改变图像对比度,模拟实际检测中探头各个方向光照变化的情况. 通过随机添加高斯噪声,提高模型面对不同粗糙混凝土表面的鲁棒性. 数据增强后的典型图像如图12所示.
图 12

5. 实验及结果分析
5.1. 实验环境及训练设置
实验使用的处理器为12th Gen Intel® CoreTM i9-12900 KF,频率3.20 GHz,核心数为16,显卡为NVIDIA RTX 4070 Ti,显存为16 GB,配置CUDNN 8.6和CUDA 11.6加速训练过程. 优化器选择随机梯度下降(stochastic gradient descent, SGD),批量大小设置为16,迭代800个轮次,SGD优化器的动量设置为0.9,权重衰减设置为5.0×10−4,初始学习率设置为0.005,采用多项式衰减,逐步减少学习率.
5.2. 模型评价指标
采用准确率ACC、阳性预测值PPV、真阴性率TNR、真阳性率TPR、F1 分数以及交并比IOU作为精度指标,计算式分别为
选用参数总量NP和每秒能够处理的图像帧数RF量化模型的推理效率,展示模型在实际移动场景中的实时性表现.
5.3. 消融实验
为了验证TSCC-Net中各模块的有效性,设计消融实验,对网络中的语义感知提取器、互融合模块及辅助监督模块的性能进行独立验证,同时对比不同模块组合下的模型性能差异.
5.3.1. 语义感知提取器消融实验
在前馈网络部分,为了提升效率,采用1×1卷积替换全连接层,将前馈网络的扩展因子设置为2. 共设置4组实验,通过控制单一变量,对比采用 MLP 和1×1 卷积在扩展因子分别为 2和4 下对模型性能的影响,结果如表1所示. 可以看出,4组实验的 IOU 均维持在 85.9%~86.4%,精度水平接近,说明无论采用 MLP 还是 1×1 卷积,或是调整扩展因子为 2 或 4,均未对模型的基础分割能力产生显著负面影响,验证了2种结构在特征转换功能上的等效性. 综合来看,采用 1×1 卷积替换 MLP,并将扩展因子设置为 2 的设计,是兼顾分割精度、模型轻量化与实时性的最优选择.
表 1 前馈网络结构与扩展因子消融实验结果
Tab.1
| 模型配置 | IOU/% | NP/MB |
| 1×1Conv+dwConv扩展因子为4 | 86.4 | 15.92 |
| 1×1Conv+dwConv扩展因子为2 | 86.3 | 12.86 |
| MLP+ dwConv扩展因子为2 | 85.9 | 17.24 |
| MLP+ dwConv扩展因子为4 | 86.0 | 23.68 |
5.3.2. 辅助监督模块消融实验
为了验证损失权重组合的最优性,进行4组不同权重组合的消融实验,结果如表2所示.可以看出,若
表 2 辅助监督模块权重组合消融实验结果
Tab.2
| IOU | F1 | |
| 1.0/0.3/0.3 | 84.7 | 86.8 |
| 1.0/0.4/0.4 | 86.3 | 88.5 |
| 1.0/0.5/0.5 | 85.1 | 87.3 |
| 1.0/0.6/0.6 | 85.5 | 87.8 |
5.3.3. 整体模型模块消融实验
为了验证 TSCC-Net 中各模块的有效性及模块间的协同效应,以 IOU、F1 分数作为主要评价指标进行消融实验,结果如表3所示. 可以看出,在基线模型基础上,添加语义感知提取器贡献最显著(IOU提升了2.9个百分点,F1 分数提升了3.3个百分点),互融合模块与辅助监督模块均有小幅提升. 双模块组合性能均优于单一模块叠加,语义感知提取器与互融合模块组合后 IOU 达到85.6%,体现了语义引导与特征互补的协同增益,全模块组合的 TSCC-Net 性能最优(IOU=86.3%、F1=88.5%),证明 TSCC-Net 架构设计适合触觉图像裂缝分割需求.
表 3 触觉混凝土裂缝分割网络的模块消融实验结果
Tab.3
| 模型配置 | IOU | F1 |
| 基线模型(仅特征金字塔+分割头) | 80.9 | 83.1 |
| 基线模型+语义感知提取器 | 83.8 | 86.4 |
| 基线模型+互融合模块 | 81.7 | 83.9 |
| 基线模型+辅助监督模块 | 81.3 | 83.5 |
| 基线模型+语义感知提取器+互融合模块 | 85.6 | 87.7 |
| 基线模型+语义感知提取器+辅助监督模块 | 85.4 | 87.3 |
| 基线模型+互融合模块+辅助监督模块 | 85.0 | 86.9 |
| TSCC-Net | 86.3 | 88.5 |
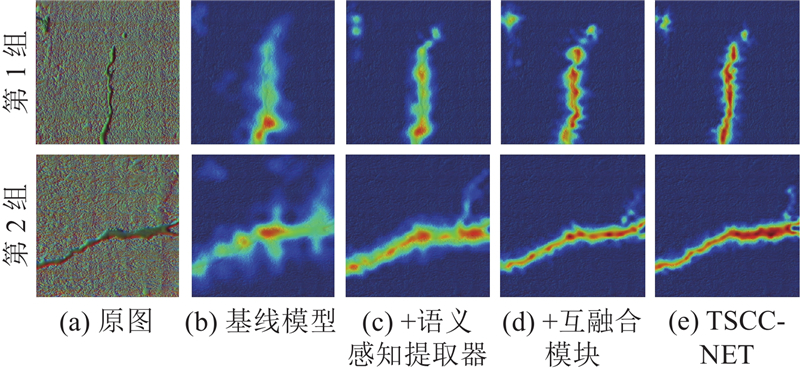
进一步呈现语义感知提取器、互融合模块和辅助监督模块对网络整体决策的影响,使用Score-cam热力图对TSCC-Net进行可视化分析,结果如图13所示. 在第1组图像中,相对于基线模型的热力图,在添加语义感知提取器后,热力图对裂缝的聚焦度有明显提升,关注区域逐渐向裂缝上收缩;加入互融合模块后,对窄缝区域的热力强度明显增强,背景噪声干扰也明显降低;完整模型的热力图几乎精准覆盖裂缝全区域,避免了因混凝土表面纹理变化导致的误判. 第2组裂缝图像的热力图呈现出类似的规律. 综合来看,3组模块的协同作用使TSCC-Net在裂缝定位精度、细节恢复能力和抗干扰性上得到全面提升,验证了图像分割网络架构设计的合理性.
图 13
5.4. 不同模型对比实验
为了验证TSCC-Net在黑暗环境下的混凝土裂缝识别性能,将其与主流的语义分割模型(HRNet、U-Net、Segformer、PSPNet和DeepLabV3+)进行对比实验. 所有模型均基于相同数据集、训练配置及评价指标开展测试,从检测精度与推理效率2个方面进行对比分析,结果如表4所示. 在检测精度方面,TSCC-Net的IOU=86.3%,F1=88.5%,均显著高于其他对比模型. 在IOU指标上,较第二名DeepLabV3+的84.9%提升了1.4 个百分点,TSCC-Net的 ACC、PPV、TNR分别为92.4%、87.2%、90.6%,说明TSCC-Net的互融合模块利用空间注意力机制强化特征互补,辅助监督模块优化中间层特征训练,三者协同提升了裂缝定位精度与细节恢复能力,使TSCC-Net在区分裂缝与混凝土表面纹理特征上比其他模型的鲁棒性强. 在推理效率层面,TSCC-Net总参数量为12.86 MB,显著低于DeepLabV3+(52.39 MB)和PSPNet(46.71 MB). 通过轻量化设计,TSCC-Net的推理速度达到114.5帧/s,仅略低于Segformer的117.6 帧/s,远高于U-Net的34.9 帧/s,证明该模型在保持高精度的同时,可以满足移动设备实时检测需求. 以当前实验阶段采用的60 帧/s摄像头采集速率,算法存在44.5 帧/s的处理冗余,保证不会因算法处理速度不够导致采集图片积压. 目前使用的移动搭载平台为初步试制,仅用于可行性研究,后续工程化落地时,选用 120 帧/s及以上的工业级微距相机,可匹配算法的高速推理能力.
表 4 不同语义分割模型的性能对比
Tab.4
| 模型 | IOU/% | F1/% | ACC/% | PPV/% | TPR/% | TNR/% | NP/MB | RF/(帧·s−1) |
| U-Net | 81.2 | 83.4 | 87.6 | 83.1 | 84.5 | 85.7 | 24.89 | 34.9 |
| Segformer | 80.8 | 81.3 | 84.1 | 82.5 | 83.2 | 83.8 | 3.71 | 117.6 |
| PSPNet | 83.5 | 86.3 | 88.6 | 84.9 | 86.3 | 87.9 | 46.71 | 83.8 |
| HRNet | 84.3 | 87.1 | 89.7 | 85.5 | 87.4 | 88.4 | 9.63 | 48.2 |
| DeepLabV3+ | 84.9 | 87.7 | 90.7 | 86.3 | 88.2 | 89.7 | 52.39 | 52.6 |
| TSCC-Net | 86.3 | 88.5 | 92.4 | 87.2 | 89.8 | 90.6 | 12.86 | 114.5 |
如图14所示为原始黑暗环境下各模型对混凝土裂缝的分割效果. 由图可见,触觉图像能够在黑暗环境下清晰呈现裂缝的物理轮廓,且每种模型都能进行较准确的裂缝分割. 传统视觉模型对长裂缝上较窄的过渡段存在对连续性识别不好的问题,容易出现局部漏检,如在第4组图像中,Segformer的裂缝尾部识别出现接连欠分割现象;HRNet对表面纹理干扰较敏感,在第2组中,它将背景误判为了裂缝). 在TSCC-Net 的分割结果中,裂缝的形状基本得到完整保留,尤其是在混凝土表面粗糙纹理干扰下,仍能精准区分裂缝与背景.
图 14

图 14 不同模型的混凝土裂缝分割效果对比
Fig.14 Comparison of different models for concrete crack segmentation
为了进一步证明触觉仿生技术的优势,使用红外成像仪采集夜间的路面裂缝,并使用相同的模型进行测试,分割效果如图15所示. 由图可见,相较于原始照片,路面裂缝的分割效果虽有一定提升,但受路面温度分布不均的影响,在裂缝收窄区域及图像边缘部分,裂缝边缘成像模糊不清,导致分割效果仍欠佳. 这一对比结果表明,在黑暗环境下,触觉传感技术对路面裂缝分割效果的提升更为显著.
图 15

图 15 不同模型针对红外图像的路面裂缝分割效果对比
Fig.15 Comparison of different models for infrared pavement crack segmentation
6. 结 语
本研究针对极端黑暗环境下混凝土裂缝识别难题,提出基于触觉仿生技术的解决方案,通过设计触觉传感系统与轻量化的深度学习网络,实现黑暗场景下裂缝的精准检测. 1) 设计的硅胶触觉探头结合多光源成像系统,能够直接接触混凝土表面获取包含裂缝深度、宽度的物理信息的触觉图像. 该技术不依赖视觉光源,通过重建算法清晰还原混凝土的表面裂缝等细节. 2) TSCC-Net 通过语义感知提取器、互融合模块与辅助监督模块的协同作用,在触觉图像裂缝识别中交并比达到86.3%,F1 分数为 88.5%,模型参数量为12.86 MB,推理速度达到114.5 帧/s,兼顾了检测精度与实时性,证明了其在触觉图像识别场景中应用的优越性. 3) 当前实验中采用的探头尺寸与按压频率局限于实验室场景,未来计划针对如桥梁、公路的大型结构的检测需求,设计模块化大尺寸触觉探头,通过阵列式传感器布局覆盖更大检测面积,解决当前小探头在大面积检测中效率不足的问题,推动触觉仿生技术在实际工程中的规模化应用.
参考文献
混凝土铺装层开裂对正交异性钢桥面疲劳性能劣化作用研究
[J].
Effect of concrete overlay cracking on fatigue deterioration of orthotropic steel bridge deck
[J].
基于SLGM和T-LSIS的大跨混凝土箱梁桥裂缝统一识别与开裂机理研究
[J].
Unified identification and cracking mechanism research of cracks in long-span concrete box girder bridges using SLGM and T-LSIS
[J].
隧道群明暗转换对暗反应时间的影响
[J].
Influence of tunnel group light-dark conversion on dark reaction time
[J].
基于结构和纹理感知的井下低光照自监督图像增强方法
[J].DOI:10.13225/j.cnki.jccs.2024.0234 [本文引用: 1]
Underground low-light self-supervised image enhancement method based on structure and texture perception
[J].DOI:10.13225/j.cnki.jccs.2024.0234 [本文引用: 1]
基于阵列超声和特征融合神经网络的钢筋混凝土结构内部裂缝检测
[J].DOI:10.14006/j.jzjgxb.2023.0729 [本文引用: 1]
Internal crack recognition of reinforce concrete structure based on array ultrasound and feature fusion neural network
[J].DOI:10.14006/j.jzjgxb.2023.0729 [本文引用: 1]
基于改进DeepLabv3+模型的桥梁裂缝图像分割方法
[J].DOI:10.13229/j.cnki.jdxbgxb.20220205 [本文引用: 1]
Bridge crack image segmentation method based on improved DeepLabv3+ model
[J].DOI:10.13229/j.cnki.jdxbgxb.20220205 [本文引用: 1]
Comparative study on concrete crack detection of tunnel based on different deep learning algorithms
[J].DOI:10.3389/feart.2021.817785 [本文引用: 1]
External attention based TransUNet and label expansion strategy for crack detection
[J].DOI:10.1109/TITS.2022.3154407 [本文引用: 1]
Automatic crack detection on concrete and asphalt surfaces using semantic segmentation network with hierarchical Transformer
[J].DOI:10.1016/j.engstruct.2024.117903 [本文引用: 1]
Research on crack disease identification based on visible spectrum in harsh tunnel environment
[J].DOI:10.1109/ACCESS.2023.3329991 [本文引用: 1]
UNet-based model for crack detection integrating visual explanations
[J].DOI:10.1016/j.conbuildmat.2021.126265 [本文引用: 1]
RTFormerF10: 基于RTFormer-slim模型融合红外与可见光图像的裂缝分割研究
[J].DOI:10.19721/j.cnki.1001-7372.2025.04.006 [本文引用: 1]
RTFormerF10: research on crack segmentation based on RTFormer-slim model fusion of infrared and visible light images
[J].DOI:10.19721/j.cnki.1001-7372.2025.04.006 [本文引用: 1]
Efficient crack detection method for tunnel lining surface cracks based on infrared images
[J].DOI:10.1061/(ASCE)CP.1943-5487.0000645 [本文引用: 1]
Towards automated detection and quantification of concrete cracks using integrated images and lidar data from unmanned aerial vehicles
[J].DOI:10.1002/stc.2757 [本文引用: 1]
Integrated transfer learning method for image recognition based on neural network
[J].DOI:10.1080/03772063.2021.1978877 [本文引用: 1]
Multi-stage generative adversarial networks for generating pavement crack images
[J].DOI:10.1016/j.engappai.2023.107767 [本文引用: 1]
Intelligent recognition of tunnel lining defects based on deep learning: methods, challenges and prospects
[J].DOI:10.1016/j.engfailanal.2025.109332 [本文引用: 1]
基于深度学习的土木基础设施裂缝检测综述
[J].
Review of deep learning-based crack detection for civil infrastructures
[J].
压力/弯曲双模态柔性触觉传感器用于手部动作识别
[J].DOI:10.13873/J.1000-9787(2025)05-0044-04 [本文引用: 1]
Pressure/bending bimodal flexible tactile sensor for hand motion recognition
[J].DOI:10.13873/J.1000-9787(2025)05-0044-04 [本文引用: 1]
用于生物组织弹性模量检测的压电触觉传感器
[J].DOI:10.19650/j.cnki.cjsi.J2413534 [本文引用: 1]
Design of piezoelectric tactile sensors for elastic modulus detection of biological tissues
[J].DOI:10.19650/j.cnki.cjsi.J2413534 [本文引用: 1]
Silicones for maxillofacial prostheses and their modifications in service
[J].DOI:10.3390/ma17133297 [本文引用: 1]
3D force identification and prediction using deep learning based on a Gelsight-structured sensor
[J].DOI:10.1016/j.sna.2024.115036 [本文引用: 1]
Bidirectional Sim-to-Real transfer for GelSight tactile sensors with CycleGAN
[J].DOI:10.1109/LRA.2022.3167064 [本文引用: 1]
三分量双色反射模型驱动的透明PET瓶图像高光去除方法研究
[J].DOI:10.13382/j.jemi.B2407784 [本文引用: 1]
Research on highlight removal method driven by three component dichromatic reflection model for transparent PET bottle images
[J].DOI:10.13382/j.jemi.B2407784 [本文引用: 1]
Federated LeViT-ResUNet for scalable and privacy-preserving agricultural monitoring using drone and Internet of Things data
[J].DOI:10.3390/agronomy15040928 [本文引用: 1]
Detecting CVT measurement errors using a voltage online monitoring system and maximum approximate coefficient growth rate
[J].DOI:10.1109/JSEN.2024.3459054 [本文引用: 1]
Deep blind image quality assessment powered by online hard example mining
[J].DOI:10.1109/TMM.2023.3257564 [本文引用: 1]
DDR-Unet: a high-accuracy and efficient ore image segmentation method
[J].DOI:10.1109/tim.2023.3317480 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}