[1]
CADENA C, CARLONE L, CARRILLO H, et al Past, present, and future of simultaneous localization and mapping: toward the robust-perception age
[J]. IEEE Transactions on Robotics , 2016 , 32 (6 ): 1309 - 1332
DOI:10.1109/TRO.2016.2624754
[本文引用: 1]
[2]
王朋, 郝伟龙, 倪翠, 等 视觉SLAM方法综述
[J]. 北京航空航天大学学报 , 2024 , 50 (2 ): 359 - 367
DOI:10.13700/j.bh.1001-5965.2022.0376
[本文引用: 1]
WANG Peng, HAO Weilong, NI Cui, et al An overview of visual SLAM methods
[J]. Journal of Beijing University of Aeronautics and Astronautics , 2024 , 50 (2 ): 359 - 367
DOI:10.13700/j.bh.1001-5965.2022.0376
[本文引用: 1]
[3]
QIN T, LI P, SHEN S VINS-mono: a robust and versatile monocular visual-inertial state estimator
[J]. IEEE Transactions on Robotics , 2018 , 34 (4 ): 1004 - 1020
DOI:10.1109/TRO.2018.2853729
[本文引用: 1]
[4]
ENGEL J, KOLTUN V, CREMERS D Direct sparse odometry
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2018 , 40 (3 ): 611 - 625
DOI:10.1109/TPAMI.2017.2658577
[本文引用: 1]
[5]
KLEIN G, MURRAY D. Parallel tracking and mapping for small AR workspaces [C]// Proceedings of the 6th IEEE and ACM International Symposium on Mixed and Augmented Reality . Nara: IEEE, 2008: 225–234.
[本文引用: 1]
[6]
CARUSO D, ENGEL J, CREMERS D. Large-scale direct SLAM for omnidirectional cameras [C]// Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems . Hamburg: IEEE, 2015: 141–148.
[本文引用: 1]
[7]
MUR-ARTAL R, MONTIEL J M M, TARDÓS J D ORB-SLAM: a versatile and accurate monocular SLAM system
[J]. IEEE Transactions on Robotics , 2015 , 31 (5 ): 1147 - 1163
DOI:10.1109/TRO.2015.2463671
[本文引用: 1]
[8]
FORSTER C, PIZZOLI M, SCARAMUZZA D. SVO: fast semi-direct monocular visual odometry [C]// Proceedings of the IEEE International Conference on Robotics and Automation . Hong Kong: IEEE, 2014: 15–22.
[本文引用: 1]
[10]
BESCOS B, FÁCIL J M, CIVERA J, et al DynaSLAM: tracking, mapping, and inpainting in dynamic scenes
[J]. IEEE Robotics and Automation Letters , 2018 , 3 (4 ): 4076 - 4083
DOI:10.1109/LRA.2018.2860039
[本文引用: 1]
[11]
HU X, ZHANG Y, CAO Z, et al. CFP-SLAM: a real-time visual SLAM based on coarse-to-fine probability in dynamic environments [C]// Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems . Kyoto: IEEE, 2022: 4399–4406.
[本文引用: 2]
[12]
CHANG J, DONG N, LI D A real-time dynamic object segmentation framework for SLAM system in dynamic scenes
[J]. IEEE Transactions on Instrumentation and Measurement , 2021 , 70 : 2513709
[本文引用: 1]
[13]
ZHANG J, HENEIN M, MAHONY R, et al. VDO-SLAM: a visual dynamic object-aware SLAM system [EB/OL]. (2021–12–14)[2025–07–03]. https://arxiv.org/pdf/2005.11052.
[本文引用: 1]
[14]
张玮奇, 王嘉, 张琳, 等 SUI-SLAM: 一种面向室内动态环境的融合语义和不确定度的视觉SLAM方法
[J]. 机器人 , 2024 , 46 (6 ): 732 - 742
DOI:10.13973/j.cnki.robot.230195
[本文引用: 1]
ZHANG Weiqi, WANG Jia, ZHANG Lin, et al SUI-SLAM: a semantics and uncertainty incorporated visual SLAM algorithm towards dynamic indoor environments
[J]. Robot , 2024 , 46 (6 ): 732 - 742
DOI:10.13973/j.cnki.robot.230195
[本文引用: 1]
[15]
翟伟光, 王峰, 马星宇, 等 YSG-SLAM: 动态场景下基于YOLACT的实时语义RGB-D SLAM系统
[J]. 兵工学报 , 2025 , 46 (6 ): 167 - 179
DOI:10.12382/bgxb.2024.0443
[本文引用: 1]
ZHAI Weiguang, WANG Feng, MA Xingyu, et al YSG-SLAM: a real-time semantic RGB-D SLAM based on YOLACT in dynamic scene
[J]. Acta Armamentarii , 2025 , 46 (6 ): 167 - 179
DOI:10.12382/bgxb.2024.0443
[本文引用: 1]
[16]
刘钰嵩, 何丽, 袁亮, 等 动态场景下基于光流的语义RGBD-SLAM算法
[J]. 仪器仪表学报 , 2022 , 43 (12 ): 139 - 148
DOI:10.19650/j.cnki.cjsi.J2209856
[本文引用: 1]
LIU Yusong, HE Li, YUAN Liang, et al Semantic RGBD-SLAM in dynamic scene based on optical flow
[J]. Chinese Journal of Scientific Instrument , 2022 , 43 (12 ): 139 - 148
DOI:10.19650/j.cnki.cjsi.J2209856
[本文引用: 1]
[17]
CAMPOS C, ELVIRA R, RODRÍGUEZ J J G, et al ORB-SLAM3: an accurate open-source library for visual, visual–inertial, and multimap SLAM
[J]. IEEE Transactions on Robotics , 2021 , 37 (6 ): 1874 - 1890
DOI:10.1109/TRO.2021.3075644
[本文引用: 1]
[18]
YU C, LIU Z, LIU X J, et al. DS-SLAM: a semantic visual SLAM towards dynamic environments [C]// Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems . Madrid: IEEE, 2019: 1168–1174.
[本文引用: 1]
[19]
CHENG S, SUN C, ZHANG S, et al SG-SLAM: a real-time RGB-D visual SLAM toward dynamic scenes with semantic and geometric information
[J]. IEEE Transactions on Instrumentation and Measurement , 2023 , 72 : 7501012
[本文引用: 1]
[20]
HE J, LI M, WANG Y, et al OVD-SLAM: an online visual SLAM for dynamic environments
[J]. IEEE Sensors Journal , 2023 , 23 (12 ): 13210 - 13219
DOI:10.1109/JSEN.2023.3270534
[本文引用: 1]
Past, present, and future of simultaneous localization and mapping: toward the robust-perception age
1
2016
... 同步定位与建图(simultaneous localization and mapping,SLAM)是搭载各种传感器的移动平台在未知环境下实现自主定位与构建周围环境地图的技术[1 ] . 视觉SLAM借助相机传感器,依靠视觉感知环境,实时进行自身定位与周围环境地图构建,在小场景中的定位误差多为厘米级,优于传统里程计的分米级,是精度高、优势显著的技术[2 ] . 视觉SLAM的前端可分为特征点法[3 ] 和直接法[4 ] . 特征点法依靠特征点的提取与匹配追踪多帧图像间同名特征点的运动轨迹,依据三角测量原理算出特征点的三维空间位置,进而确定相机位姿与地图点位置. 直接法使用图像像素灰度信息,依据光度一致性假设,通过两帧图像之间的像素灰度值构建最小化光度误差求解相机位姿并进行地图构建. ...
视觉SLAM方法综述
1
2024
... 同步定位与建图(simultaneous localization and mapping,SLAM)是搭载各种传感器的移动平台在未知环境下实现自主定位与构建周围环境地图的技术[1 ] . 视觉SLAM借助相机传感器,依靠视觉感知环境,实时进行自身定位与周围环境地图构建,在小场景中的定位误差多为厘米级,优于传统里程计的分米级,是精度高、优势显著的技术[2 ] . 视觉SLAM的前端可分为特征点法[3 ] 和直接法[4 ] . 特征点法依靠特征点的提取与匹配追踪多帧图像间同名特征点的运动轨迹,依据三角测量原理算出特征点的三维空间位置,进而确定相机位姿与地图点位置. 直接法使用图像像素灰度信息,依据光度一致性假设,通过两帧图像之间的像素灰度值构建最小化光度误差求解相机位姿并进行地图构建. ...
视觉SLAM方法综述
1
2024
... 同步定位与建图(simultaneous localization and mapping,SLAM)是搭载各种传感器的移动平台在未知环境下实现自主定位与构建周围环境地图的技术[1 ] . 视觉SLAM借助相机传感器,依靠视觉感知环境,实时进行自身定位与周围环境地图构建,在小场景中的定位误差多为厘米级,优于传统里程计的分米级,是精度高、优势显著的技术[2 ] . 视觉SLAM的前端可分为特征点法[3 ] 和直接法[4 ] . 特征点法依靠特征点的提取与匹配追踪多帧图像间同名特征点的运动轨迹,依据三角测量原理算出特征点的三维空间位置,进而确定相机位姿与地图点位置. 直接法使用图像像素灰度信息,依据光度一致性假设,通过两帧图像之间的像素灰度值构建最小化光度误差求解相机位姿并进行地图构建. ...
VINS-mono: a robust and versatile monocular visual-inertial state estimator
1
2018
... 同步定位与建图(simultaneous localization and mapping,SLAM)是搭载各种传感器的移动平台在未知环境下实现自主定位与构建周围环境地图的技术[1 ] . 视觉SLAM借助相机传感器,依靠视觉感知环境,实时进行自身定位与周围环境地图构建,在小场景中的定位误差多为厘米级,优于传统里程计的分米级,是精度高、优势显著的技术[2 ] . 视觉SLAM的前端可分为特征点法[3 ] 和直接法[4 ] . 特征点法依靠特征点的提取与匹配追踪多帧图像间同名特征点的运动轨迹,依据三角测量原理算出特征点的三维空间位置,进而确定相机位姿与地图点位置. 直接法使用图像像素灰度信息,依据光度一致性假设,通过两帧图像之间的像素灰度值构建最小化光度误差求解相机位姿并进行地图构建. ...
Direct sparse odometry
1
2018
... 同步定位与建图(simultaneous localization and mapping,SLAM)是搭载各种传感器的移动平台在未知环境下实现自主定位与构建周围环境地图的技术[1 ] . 视觉SLAM借助相机传感器,依靠视觉感知环境,实时进行自身定位与周围环境地图构建,在小场景中的定位误差多为厘米级,优于传统里程计的分米级,是精度高、优势显著的技术[2 ] . 视觉SLAM的前端可分为特征点法[3 ] 和直接法[4 ] . 特征点法依靠特征点的提取与匹配追踪多帧图像间同名特征点的运动轨迹,依据三角测量原理算出特征点的三维空间位置,进而确定相机位姿与地图点位置. 直接法使用图像像素灰度信息,依据光度一致性假设,通过两帧图像之间的像素灰度值构建最小化光度误差求解相机位姿并进行地图构建. ...
1
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
1
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
ORB-SLAM: a versatile and accurate monocular SLAM system
1
2015
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
1
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
深度学习下的视觉SLAM综述
1
2023
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
深度学习下的视觉SLAM综述
1
2023
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
DynaSLAM: tracking, mapping, and inpainting in dynamic scenes
1
2018
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
2
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
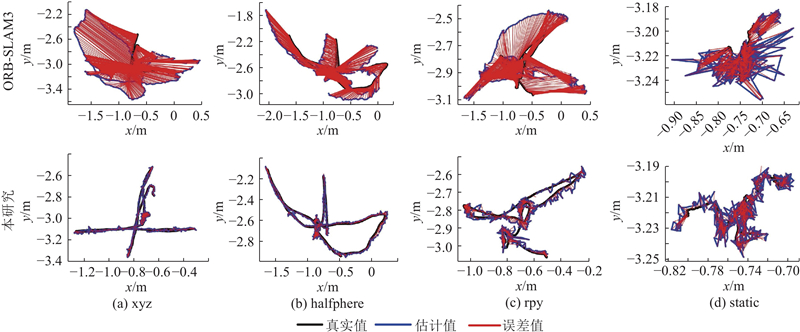
... Absolute trajectory error comparison of different SLAM algorithms on TUM dataset
m Tab.3 算法 RMSEA σ xyz rpy halfphere static xyz rpy halfphere static DS-SLAM[18 ] 0.0247 0.4442 0.0303 0.0081 0.0161 0.2350 0.0159 0.0036 SG-SLAM[19 ] 0.0152 0.0324 0.0268 0.0073 0.0075 0.0187 0.0134 0.0034 OVD-SLAM[20 ] 0.0135 0.0349 0.0229 0.0068 0.0068 0.0211 0.0111 0.0030 CFP-SLAM[11 ] 0.0141 0.0368 0.0237 0.0066 0.0072 0.0230 0.0114 0.0030 本研究 0.0152 0.0294 0.0214 0.0058 0.0070 0.0149 0.0112 0.0027
2.3. 稠密地图重建效果 如图12 所示,为了验证所提稠密地图构建方法的有效性,选取 TUM 动态数据集的 static 序列作为测试数据,对比 ORB-SLAM3 原生方法构建的稀疏地图与所提算法构建的稠密地图的性能差异. ORB-SLAM3 算法仅能构建稀疏地图,该稀疏地图仅包含离散分布的无关联点云,无法完整表征场景结构与物体轮廓. 所提算法采用位姿关联与深度拼接方法构建稠密地图:通过算法估计的精准位姿关联不同帧点云,再结合深度信息完成融合拼接,最终生成稠密地图. 对比ORB-SLAM3 算法生成的稀疏地图可以看出,本研究构建的稠密地图能呈现场景物体形状、空间布局等细节,提升了地图真实感. ...
A real-time dynamic object segmentation framework for SLAM system in dynamic scenes
1
2021
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
1
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
SUI-SLAM: 一种面向室内动态环境的融合语义和不确定度的视觉SLAM方法
1
2024
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
SUI-SLAM: 一种面向室内动态环境的融合语义和不确定度的视觉SLAM方法
1
2024
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
YSG-SLAM: 动态场景下基于YOLACT的实时语义RGB-D SLAM系统
1
2025
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
YSG-SLAM: 动态场景下基于YOLACT的实时语义RGB-D SLAM系统
1
2025
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
动态场景下基于光流的语义RGBD-SLAM算法
1
2022
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
动态场景下基于光流的语义RGBD-SLAM算法
1
2022
... 传统基于特征点法和直接法的视觉SLAM算法均设置于静态场景下,如PTAM[5 ] 、LSD-SLAM[6 ] 、ORB-SLAM[7 ] 、SVO[8 ] . 这些算法在静态或者少量动态场景下的位姿估计与地图构建精度较高,但在动态场景下的实时性、定位精度、检测精度、鲁棒性降低. 基于深度学习和几何的方法[9 ] 能够提高系统在动态场景下的定位精度、检测精度和鲁棒性,减少运动物体对系统的影响以及减小位姿误差. Bescos等[10 ] 使用Mask R-CNN像素级实例分割技术与多视图几何方法剔除动态物体. Hu等[11 ] 提出CFP-SLAM 算法,利用目标检测网络YOLOv5 和几何约束区分高动态物体和低动态物体,并使用关键点由粗到精的两阶段静态概率计算方法提高匹配像素点对在定位时的利用效率. Chang等[12 ] 使用YOLACT(you only look at coefficients)分割动态对象,在去除内部异常值后,引入几何约束来过滤动态点. Zhang等[13 ] 提出 VDO-SLAM算法,通过MaskR-CNN 实例分割以及 PWC-Net 光流网络提取图像中的移动目标,对相机位姿、动态和静态特征点、运动物体的位姿进行联合计算与优化. 张玮奇等[14 ] 提出SUI-SLAM算法,基于Mask R-CNN的语义分割结果获取动态先验信息,并结合深度信息,优化特征点匹配关联与位姿求解精度. 翟伟光等[15 ] 提出YSG-SLAM算法,通过增双并行线程,分别用于语义分割与语义建图,同时引入动态特征剔除、自适应阈值以此来提高定位精度. 刘钰嵩等[16 ] 提出RGBD-SLAM算法,通过透视矫正结合 RAFT-S 与 BiSeNetv2分离动静特征构建静态语义地图. 上述SLAM算法均遵循动态干扰抑制—静态特征保留—位姿与地图协同优化的核心逻辑,存在以下不足: 1)动态区域特征点的过度剔除,导致可用特征点数量不足;2)静态特征保留策略的复杂性问题,在一定程度增加了算法的复杂度;3)稠密地图构建的碎片化问题,无法获取丰富的环境感知与理解. ...
ORB-SLAM3: an accurate open-source library for visual, visual–inertial, and multimap SLAM
1
2021
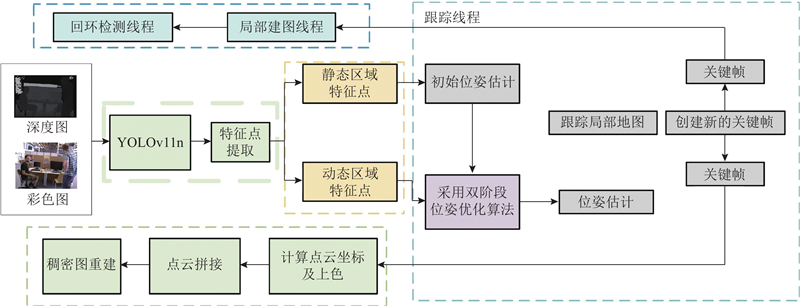
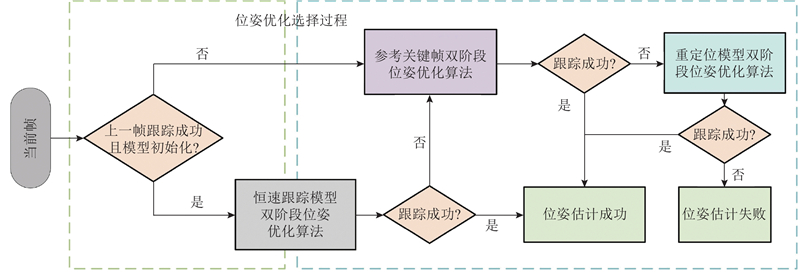
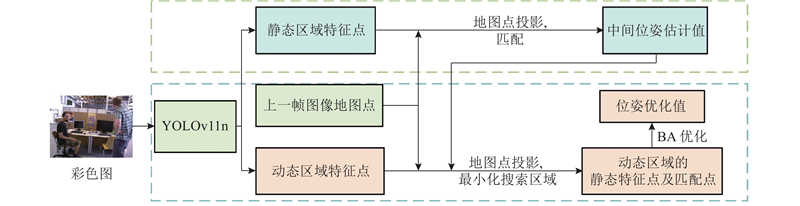
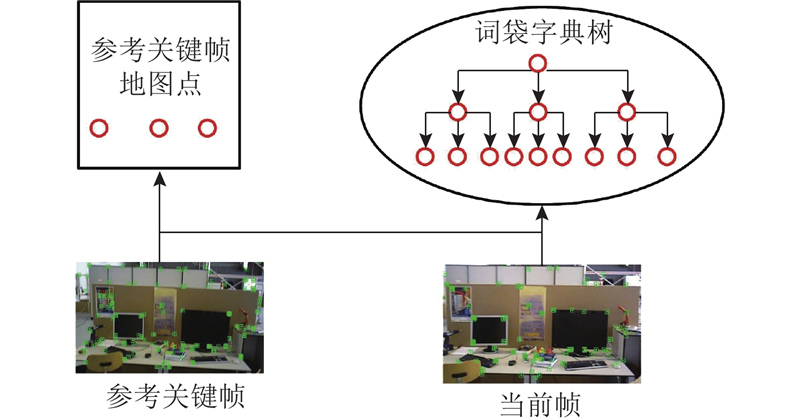
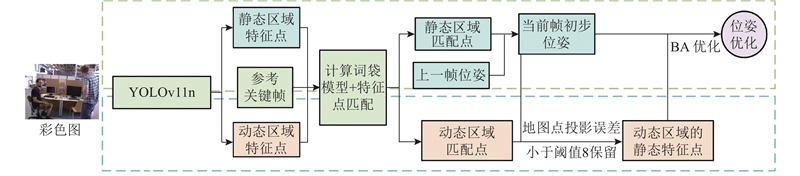
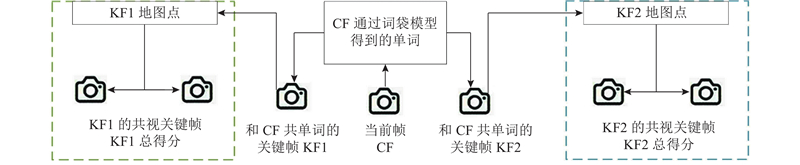
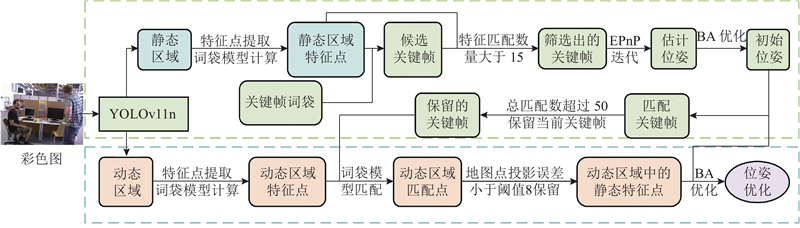
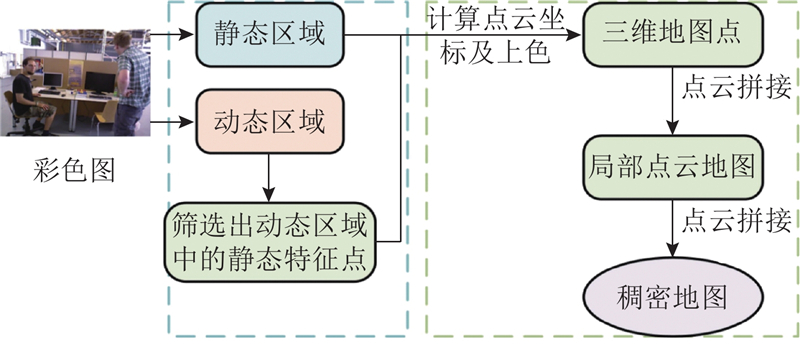
... 本研究提出融合YOLOv11n目标检测的优化ORB-SLAM3[17 ] 算法. 1)采用基于开放神经网络交换格式(open neural network exchange, ONNX)推理的YOLOv11n目标检测算法获取先验动态区域;2)通过双阶段位姿优化方法筛选出动态区域中的静态特征点,精准剔除动态场景下的动态特征点,同时进行位姿优化;3)利用关键帧中所有位于静态区域的像素点及经筛选得到的动态区域静态特征点执行投影操作生成3D点云,通过点云拼接构建稠密地图. ...
1
... Absolute trajectory error comparison of different SLAM algorithms on TUM dataset
m Tab.3 算法 RMSEA σ xyz rpy halfphere static xyz rpy halfphere static DS-SLAM[18 ] 0.0247 0.4442 0.0303 0.0081 0.0161 0.2350 0.0159 0.0036 SG-SLAM[19 ] 0.0152 0.0324 0.0268 0.0073 0.0075 0.0187 0.0134 0.0034 OVD-SLAM[20 ] 0.0135 0.0349 0.0229 0.0068 0.0068 0.0211 0.0111 0.0030 CFP-SLAM[11 ] 0.0141 0.0368 0.0237 0.0066 0.0072 0.0230 0.0114 0.0030 本研究 0.0152 0.0294 0.0214 0.0058 0.0070 0.0149 0.0112 0.0027
2.3. 稠密地图重建效果 如图12 所示,为了验证所提稠密地图构建方法的有效性,选取 TUM 动态数据集的 static 序列作为测试数据,对比 ORB-SLAM3 原生方法构建的稀疏地图与所提算法构建的稠密地图的性能差异. ORB-SLAM3 算法仅能构建稀疏地图,该稀疏地图仅包含离散分布的无关联点云,无法完整表征场景结构与物体轮廓. 所提算法采用位姿关联与深度拼接方法构建稠密地图:通过算法估计的精准位姿关联不同帧点云,再结合深度信息完成融合拼接,最终生成稠密地图. 对比ORB-SLAM3 算法生成的稀疏地图可以看出,本研究构建的稠密地图能呈现场景物体形状、空间布局等细节,提升了地图真实感. ...
SG-SLAM: a real-time RGB-D visual SLAM toward dynamic scenes with semantic and geometric information
1
2023
... Absolute trajectory error comparison of different SLAM algorithms on TUM dataset
m Tab.3 算法 RMSEA σ xyz rpy halfphere static xyz rpy halfphere static DS-SLAM[18 ] 0.0247 0.4442 0.0303 0.0081 0.0161 0.2350 0.0159 0.0036 SG-SLAM[19 ] 0.0152 0.0324 0.0268 0.0073 0.0075 0.0187 0.0134 0.0034 OVD-SLAM[20 ] 0.0135 0.0349 0.0229 0.0068 0.0068 0.0211 0.0111 0.0030 CFP-SLAM[11 ] 0.0141 0.0368 0.0237 0.0066 0.0072 0.0230 0.0114 0.0030 本研究 0.0152 0.0294 0.0214 0.0058 0.0070 0.0149 0.0112 0.0027
2.3. 稠密地图重建效果 如图12 所示,为了验证所提稠密地图构建方法的有效性,选取 TUM 动态数据集的 static 序列作为测试数据,对比 ORB-SLAM3 原生方法构建的稀疏地图与所提算法构建的稠密地图的性能差异. ORB-SLAM3 算法仅能构建稀疏地图,该稀疏地图仅包含离散分布的无关联点云,无法完整表征场景结构与物体轮廓. 所提算法采用位姿关联与深度拼接方法构建稠密地图:通过算法估计的精准位姿关联不同帧点云,再结合深度信息完成融合拼接,最终生成稠密地图. 对比ORB-SLAM3 算法生成的稀疏地图可以看出,本研究构建的稠密地图能呈现场景物体形状、空间布局等细节,提升了地图真实感. ...
OVD-SLAM: an online visual SLAM for dynamic environments
1
2023
... Absolute trajectory error comparison of different SLAM algorithms on TUM dataset
m Tab.3 算法 RMSEA σ xyz rpy halfphere static xyz rpy halfphere static DS-SLAM[18 ] 0.0247 0.4442 0.0303 0.0081 0.0161 0.2350 0.0159 0.0036 SG-SLAM[19 ] 0.0152 0.0324 0.0268 0.0073 0.0075 0.0187 0.0134 0.0034 OVD-SLAM[20 ] 0.0135 0.0349 0.0229 0.0068 0.0068 0.0211 0.0111 0.0030 CFP-SLAM[11 ] 0.0141 0.0368 0.0237 0.0066 0.0072 0.0230 0.0114 0.0030 本研究 0.0152 0.0294 0.0214 0.0058 0.0070 0.0149 0.0112 0.0027
2.3. 稠密地图重建效果 如图12 所示,为了验证所提稠密地图构建方法的有效性,选取 TUM 动态数据集的 static 序列作为测试数据,对比 ORB-SLAM3 原生方法构建的稀疏地图与所提算法构建的稠密地图的性能差异. ORB-SLAM3 算法仅能构建稀疏地图,该稀疏地图仅包含离散分布的无关联点云,无法完整表征场景结构与物体轮廓. 所提算法采用位姿关联与深度拼接方法构建稠密地图:通过算法估计的精准位姿关联不同帧点云,再结合深度信息完成融合拼接,最终生成稠密地图. 对比ORB-SLAM3 算法生成的稀疏地图可以看出,本研究构建的稠密地图能呈现场景物体形状、空间布局等细节,提升了地图真实感. ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}