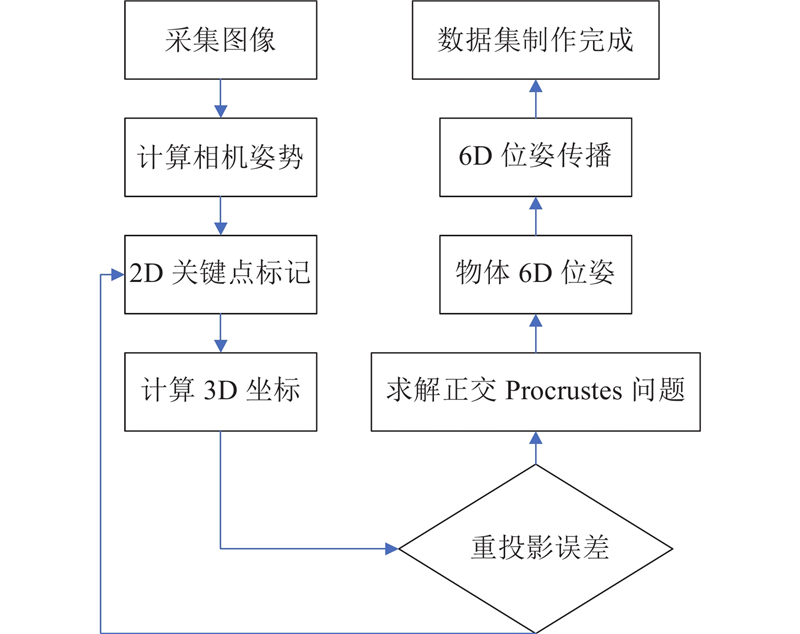
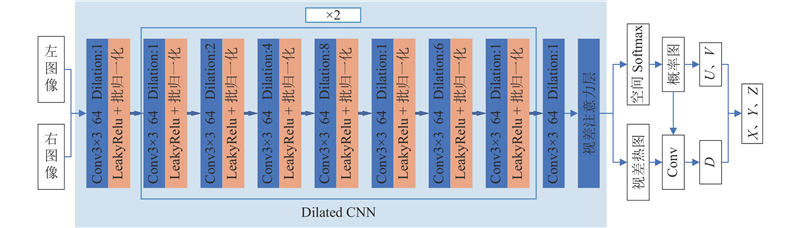
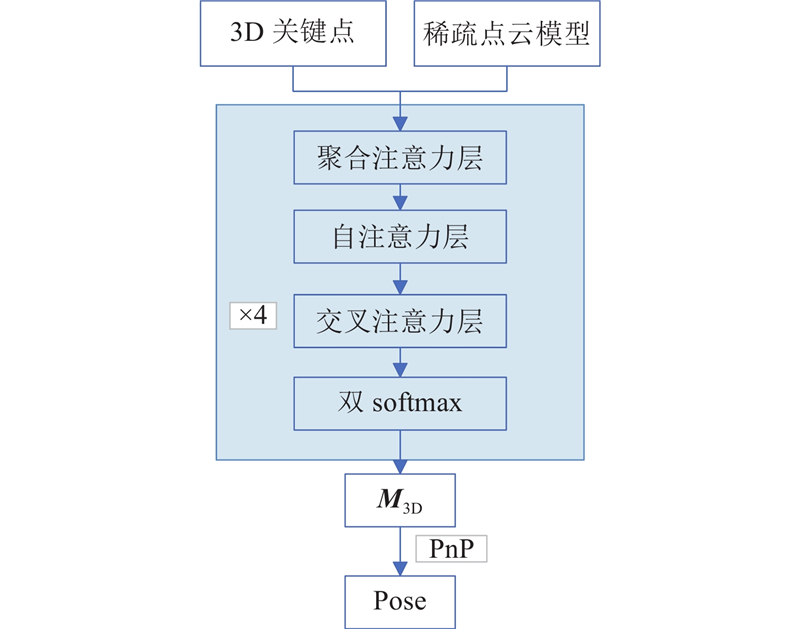
针对传统位姿估计方法中依赖CAD模型的问题,提出基于多视图几何的双目数据集制作方法及基于3D关键点的物体6D位姿估计网络StereoNet. 通过3D关键点估计网络获取物体的3D关键点,在网络中引入视差注意模块,提高关键点预测的精度. 采用运动恢复结构(SfM)方法重建物体的稀疏点云模型,将查询图像的3D点与SfM模型中的3D点输入图注意力网络(GATs)中进行匹配,通过RANSAC和PnP算法计算得到物体的6D位姿. 实验结果表明,当对3D关键点估计时,StereoNet的MAE评价指标较KeypointNet、KeyPose高1.2~1.6倍. 在6D位姿估计方面,StereoNet的5 cm 5°和3 cm 3°评价指标均优于HLoc、OnePose、Gen6D,平均精确度达到82.1%,证明该网络具有良好的泛化性和准确性.
关键词:6D位姿
;
数据集制作
;
双目视觉
;
3D关键点匹配
;
PnP算法
Abstract
A binocular dataset fabrication method based on multi-view geometry and a 3D key point-based object 6D pose estimation network, StereoNet, were proposed to address the reliance on CAD models in traditional pose estimation methods. The 3D key points of the object were obtained through a 3D key point estimation network, and a parallax attention module was introduced into the network to improve the accuracy of key point prediction. The structure-from-motion (SfM) method was employed to reconstruct a sparse point cloud model of the object. The 3D points from the query image and those from the SfM model were fed into a graph attention network (GATs) for matching. The 6D pose of the object was computed by using the RANSAC and PnP algorithms. The experimental results showed that the MAE metric of StereoNet was 1.2–1.6 times higher than that of KeypointNet and KeyPose in 3D key point estimation. StereoNet outperformed HLoc, OnePose, and Gen6D in the 5 cm 5° and 3 cm 3° evaluation metrics in terms of 6D pose estimation, achieving an average accuracy of 82.1%. The network has strong generalization ability and accuracy.
Keywords:6D pose
;
dataset creation
;
binocular vision
;
3D key point matching
;
perspective-n-point (PnP) algorithm
NING Kaixu, LU Qing, YANG Heng, WANG Shaohan. 6D pose estimation of binocular vision object based on 3D key point. Journal of Zhejiang University(Engineering Science)[J], 2025, 59(11): 2277-2284 doi:10.3785/j.issn.1008-973X.2025.11.006
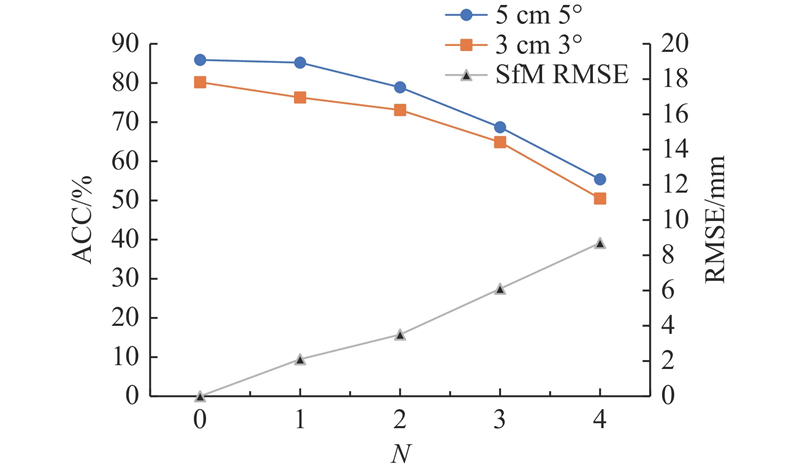
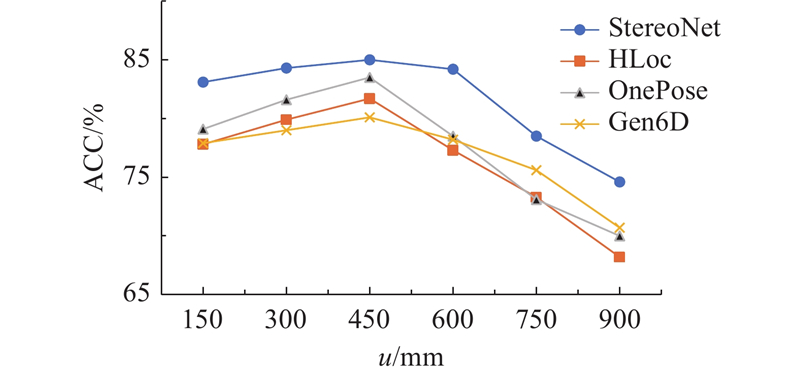
对自制数据集中未见过的物体进行对比试验. 对于3D关键点估计,将平均绝对误差(MAE)作为评估指标. MAE表示预测关键点位置与真实关键点位置之间的平均误差. 对于位姿估计,由于没有CAD模型,不能直接采用常用的ADD指标和2D投影指标. 另一个常用来评估预测物体位姿质量的指标为m cm n°指标,该指标表示当预测出物体的3D旋转误差低于阈值n°,3D平移误差小于m cm时,则认为物体的6D位姿预测准确. 按照该定义,本文选用5 cm 5°和3 cm 3°这2项指标对提出网络进行评估.
PENG S D, LIU Y, HUANG Q X, et al. Pvnet: pixel-wise voting network for 6dof pose estimation [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 4561-4570.
HE Y S, SUN W, HUANG H B, et al. Pvn3d: a deep point-wise 3d keypoints voting network for 6dof pose estimation [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 11632-11641.
HE Y S, HUANG H B, FAN H Q, et al. Ffb6d: a full flow bidirectional fusion network for 6d pose estimation [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 3003-3013.
LI Z G, WANG G, JI X Y. CDPN: coordinates-based disentangled pose network for real time rgb-based 6-DoF object pose estimation [C]// IEEE International Conference on Computer Vision. Seoul: IEEE, 2019: 7678-7687.
TREMBLAY J, TO T, SUNDARALINGAM B, et al. Deep object pose estimation for semantic robotic grasping of household objects [C]//2nd Conference on Robot Learning. Zurich: PMLR, 2018: 306-316.
GAO G, LAURI M, WANG Y L, et al. 6d object pose regression via supervised learning on point clouds [C]//IEEE International Conference on Robotics and Automation. Paris: IEEE, 2020: 3643-3649.
CHEN W, JIA X, CHANG H J, et al. g2l-net: global to local network for real-time 6d pose estimation with embedding vector features [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 4233-4242.
AHMADYAN A, ZHANG L K, ABLAVATSKI A, et al. Objectron: a large scale dataset of object-centric videos in the wild with pose annotations [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 7822-7831.
WANG H, SRIDHAR S, HUANG J W, et al. Normalized object coordinate space for category-level 6d object pose and size estimation [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 2642-2651.
ZHANG R D, DI Y, MANHARDT F, et al. SSP-pose: symmetry-aware shape prior deformation for direct category-level object pose estimation [C]//IEEE/RSJ International Conference on Intelligent Robots and Systems. Kyoto: IEEE, 2022: 7452-7459.
HE Y S, WANG Y, FAN H Q, et al. Fs6d: few-shot 6d pose estimation of novel objects [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 6814-6824.
WU J, WANG Y, XIONG R. Unseen object pose estimation via registration [C]// IEEE International Conference on Real-time Computing and Robotics. Guangzhou: IEEE, 2021: 974-979.
SUN J M, WANG Z H, ZHANG S Y, et al. Onepose: one-shot object pose estimation without cad models [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 6825-6834.
CHEN K, JAMES S, SUI C Y, et al. Stereopose: category-level 6d transparent object pose estimation from stereo images via back-view nocs [C]//IEEE International Conference on Robotics and Automation. London: IEEE, 2023: 2855-2861.
WANG Y Q, YING X Y, WANG L G, et al. Symmetric parallax attention for stereo image super-resolution [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 766-775.
VELIčKOVIć P, CUCURULL G, CASANOVA A, et al. Graph attention networks [C]//Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg: ACL, 2021: 850-862.
SUWAJANAKORN S, SNAVELY N, TOMPSON J J, et al. Discovery of latent 3d keypoints via end-to-end geometric reasoning [C]//Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc, 2018: 2067-2074.
LIU X Y, JONSCHKOWSKI R, ANGELOVA A, et al. Keypose: multi-view 3d labeling and keypoint estimation for transparent objects [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 11602-11610.
SARLIN P E, CADENA C, SIEGWART R, et al. From coarse to fine: robust hierarchical localization at large scale [C] //Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 12716-12725.
LIU Y, WEN Y L, PENG S D, et al. Gen6d: generalizable model-free 6-dof object pose estimation from rgb images [C]//European Conference on Computer Vision. Cham: Springer, 2022: 298-315.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}