

轴孔装配是装配作业中最基本的装配单元,占据装配作业的约40%,并且大口径部件装配在航空航天、武器装备、船舶制造等领域应用广泛[1]. 目前,实现大口径部件的自动化装配仍然是个挑战[2-3]. 一些主动的力控制策略已被应用于实际装配任务,并具有一定的实用性. Zhang等[4]基于简化分析方法,针对轴孔装配任务提出更实用的模糊力控制策略. Pan等[5]建立空间机械臂等效刚度模型,然后沿着装配方向建立柔性指数,提出考虑等效刚度优化的空间机械臂装配任务控制方法,有效减小了接触碰撞扰动的影响. 然而,当上述控制算法应用于复杂接触模型装配场景时,需要大量时间和精力来调整控制器参数以适应新的装配任务. 因此,需要不依赖于物理接触模型分析的高级算法来较好地执行大口径轴孔装配任务.
受人类工人通过学习经验[6]完成轴孔装配任务启发,工业机器人可以通过学习装配技能来完成复杂的轴孔装配. 因此,可以应用标准强化学习(reinforcement learning, RL)使机器人通过试验学习装配技能,而不仅仅是将人类的技能传递给机器人程序[7]. 单纯的RL方法是通过对动作空间进行离散化来输出离散动作, 因此在连续的、高维的[8]机器人控制任务存在较大的局限性. 通过将深度学习引入强化学习中,得到深度强化学习(deep reinforcement learning, DRL)算法[9],该算法利用神经网络的强大知识表征能力,处理大量轴孔接触状态数据[10-11], 在装配动作规划这类典型的序贯决策问题上表现出显著性能. 特别是深度确定性决策梯度(deep deterministic policy gradients, DDPG)算法,在诸多应用场景中都能够稳定有效地完成连续的高维动作控制任务. 另外,为了解决DRL算法经验和样本数据不足、训练代价高[12]、探测动作安全性低[13]等问题,人们选择了与其他控制方法协同的深度强化学习算法.
Kumar等[14]对强化学习控制器进行改进,相较于基于Lyapunov理论的马尔可夫博弈控制器,其所提出的模糊RL控制器具有卓越的跟踪性能和更低的计算复杂性. Zarandi 等[15]提出柔性模糊强化学习算法,该算法用基于模糊规则的系统来逼近值函数. Ren 等[16]将人类成功操纵任务的基本思想,即可变顺应性和学习应用于机器人组装. Xu等[17]采用DDPG算法实现了多轴孔装配任务,采用模糊奖励机制来提高探索效率. Zhang等[18]提出人机协同强化学习算法,以优化装配过程中的任务序列分配方案,实现复杂装配操作的人机协作. Ma等[19]提出示教学习和强化学习相结合的方式,实现了PCB板上排针的插入任务. Hou等[20]提出模糊逻辑驱动的基于可变时间尺度预测的强化学习(fuzzy logic-driven variable time-scale prediction-based reinforcement learning, FLDVTSP-RL)方法,相比传统深度Q网络,可以有效减少装配时间.
上述方法都是应用于小型轴孔装配任务的. 在大口径轴孔装配过程中零件具有较大的惯性,就会有较大的冲击力,可能会导致部件的损伤. 为了解决大口径轴孔装配任务中的上述问题,本研究提出基于模糊动作的深度确定性决策梯度(deep deterministic policy gradients with fuzzy actions, DDPGFA)算法,该算法以DDPG算法为基础,解决大部件轴孔接触状态建模困难问题,能获得较为准确的状态数据. 引入模糊动作策略,加快离线训练速度,得到更加精确和稳定的机器人动作输出. 进行大口径轴孔装配的实验,对比有无模糊策略的强化学习算法控制效果,验证DDPGFA算法的有效性.
1. 大口径轴孔装配任务
在实际装配任务中,由于较难获取精确的接触环境参数,控制策略可能产生较大的接触力误差. 对于装配精度要求较高时的大口径轴孔装配任务,比如如图1所示,零件直径超过200 mm,且装配精度要求为0.05 mm的装配任务,须在装配过程中保持较小的装配力,以及较稳定的装配速度.
图 1

2. 深度强化学习算法与模糊策略
基于强化学习的装配机器人训练过程如图2所示. 图中,
图 2

图 2 基于模糊动作的深度确定性决策梯度算法框架
Fig.2 Algorithm framework of deep deterministic policy gradients with fuzzy actions
2.1. DDPGFA装配算法的元素定义
在建立轴孔柔顺装配策略时,主要目的是在每一个轴孔接触状态下确定机械臂对轴的姿态的调整动作,以确保零部件的完好和顺利装配. 因此对DDPGFA算法应用于轴孔装配做了以下几方面的工作.
1)状态空间
式中:
在实际装配任务中,为了降低接触力模型的复杂度,减少计算量,可以将对算法决策没有影响的
2)输出动作空间
图 3
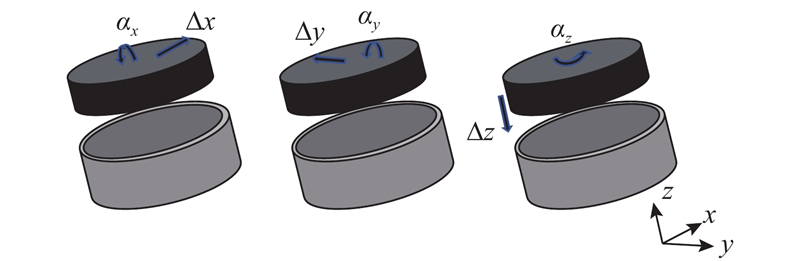
动作空间
式中:
3)奖励函数r的设计. 在大口径部件装入的过程中,要求大口径部件的受力要尽可能保持在一个相对合理的范围内,奖励函数应该引导模型学会根据零件的受力情况来进行插入装配动作的调整. 从对装配过程影响较大的力和位移2个因素来设计奖励函数. 首先,依据在径向力安全阈值范围内的实际装配深度来获得主要奖励;其次,设计2种结束状态,分别为单个径向力或单个径向累积位移超过预定范围时的状态;最后设计装配成功的奖励,即轴向累积位移达到预定值. 模型中的奖励函数设计如下:
式中:
2.2. 模糊控制策略设计
在模糊策略设计中,使用模糊规则来给出X向和Y向的动作调整系数. 大口径部件在装配时会因夹具的刚性不足而产生抖动,因此利用模糊控制对输入精确度要求不高的特点,设计模糊控制规则,以减小抖动误差对装配过程的影响.
模糊策略的设计,首先是模糊控制器的输入和输出. 考虑到强化学习输出有X、Y、Z 3个方向上的动作,其中Z向动作为插入动作,X和Y向为调整动作,因此模糊策略只对X和Y方向进行控制. 由此输入和输出量如图4所示. 图中, HX、HY分别为方向X和Y上的动作调整系数.
图 4

在装配过程中,方向X和Y相对于孔轴心来说具有对称性,因此隶属度函数A(FX)和A(FY)相同,A(HX)和A(HY)相同,隶属度函数示意图如图5所示.
图 5

输入FX和FY被分为3个范围,S、P、L分别表示偏小、合适、偏大,在装配训练中X和Y的径向力阈值为30 N,因此输入隶属度范围为[−30,30]. 输出
为了便于强化学习算法输出力的调节,依据前面建立的隶属度函数和已有的力控经验制定相应的模糊规则,如表1所示.
表 1 一些模糊策略规则
Tab.1
| 规则 | FX | FY | HX | HY |
| 1 | S | S | I | I |
| 2 | P | S | U | I |
| 3 | L | S | I | I |
| 4 | S | P | I | U |
| | | | | |
2.3. 柔顺装配技能学习流程
由确定性策略梯度(deterministic policy gradient, DPG)训练出来的行为评判法是DDPGFA算法的基础[21]. DDPGFA是针对连续行为的策略学习方法,它基于策略-评估网络结构,直接使用动作值函数来学习动作策略. DDPGFA算法包含4个网络,分别为 Actor网络、策略Actor网络、Critic网络和策略Critic网络.
探索策略的目标是防止智能定位于局部最优. 为此,采用贪婪策略来执行探索行为. 在线学习阶段算法的步骤如算法1[12]所示.
算法1. DDPGFA算法
输入阶段:初始化最大实验次数T1 ;每次装配实验最大探索次数T2;网络参数更新频率f ;延迟更新因子
随机初始化Actor网络
初始化目标网络参数
初始化经验回放池
将Actor和Critic的参数赋值给相应目标网络;
For episode =1 to T1 do
初始化动作中的随机噪声
For i=1 to T2 do
根据当前策略和随机噪声采样获得动作:
将
机器人执行动作:
计算奖赏
存储数据对
从
设
计算损失函数:
采用Adam optimizer更新
计算策略网络的更新梯度
更新策略Actor网络和策略Critic网络参数
End for
End for
3. 仿真设计与结果分析
3.1. 仿真设计
建立的虚拟轴孔装配环境与实际装配环境基本相同,模拟大口径部件装配过程的部分环境参数值如表2所示.
表 2 装配环境参数
Tab.2
| 环境参数 | 数值 |
| 动作输出维度 | 6 |
| 状态维度 | 7 |
| 允许最大径向力/ N | 30 |
| 允许最大轴向力/ N | 100 |
| 轴直径/mm | 205.9 |
| 孔直径/mm | 206.0 |
| 插入深度/mm | 4 |
| 弹性系数/(N·m−1) | 200 |
| 动摩擦因子 | 0.25 |
状态设置:为了显示轴入孔阶段的详细过程,设置7个状态量,分别是X、Y、Z轴的力和力矩,还有轴和孔的相对位姿信息,其中Z向转矩
动作设置:动作集使用了较为灵活的6个基本动作,包含了X、Y、Z轴移动和转动.
回报设置:依据轴孔装配中主要参数变化情况,即径向力和径向累积位移来设计回报函数,以引导机器人快速高效地装轴入孔. 为了安全起见,在装配过程中指定了力的阈值并将其纳入奖励函数. 单一的径向力或单一的径向累积位移超过设定的范围是给定的2个结束状态. 奖励函数表示为
式中:Asumx、Asumy分别为X、Y方向累积运动量的阈值,FTX、FTY分别为X、Y方向力的安全阈值. 如果
网络结构设置:单独的DDPG算法和DDPGFA算法的参数如表3所示.
表 3 DDPG算法和DDPGFA算法训练参数
Tab.3
| 参数 | 数值 |
| Actor网络学习率 | 0.001 |
| Critic网络学习率 | 0.01 |
| 折扣因子 | 0.99 |
| 经验池容量 | 10000 |
| 小批量采样数量 | 32 |
| 开始采样时经验池数量 | 1000 |
| 衰减率 | 0.01 |
3.2. 仿真结果分析
在训练过程中,在迭代过程中记录智能体获得的累积奖励,并在相同装配条件下测试DDPG装配策略的训练效果, 如图6所示为2种装配算法训练过程中的总奖励Rew随训练回合T的变化曲线.
图 6

图 6 DDPGFA算法和DDPG算法训练过程奖励曲线
Fig.6 Reward curves of training process of DDPGFA and DDPG algorithms
从2种算法的奖励曲线可以看出,DDPGFA算法在训练快速性方面强于DDPG算法,相比之下,训练成功所用回合数减少了15%.仿真图表明,经过150轮训练,训练过程逐渐稳定下来,在每一次成功的训练过程中都能将各轴上的力维持在预定的阈值内.
4. 装配验证实验
装配任务由KUKA六自由度机器人执行,机器人重复定位精度为 ±50
表 4 装配实验算法与初始轴孔相对位置
Tab.4
| 实验序号 | 算法 | |
| 1 | DDPG | (0.5, 0.5, 0.5) |
| DDPGFA | (0.5, 0.5, 0.5) | |
| 2 | DDPG | (1.0, 1.0, 0.5) |
| DDPGFA | (1.0, 1.0, 0.5) | |
| 3 | DDPG | (2.0, 2.0, 0.5) |
| DDPGFA | (2.0, 2.0, 0.5) | |
| 4 | DDPG | (2.5, 2.5, 0.5) |
| DDPGFA | (2.5, 2.5, 0.5) |
图 7

图 7 实验过程中DDPG与DDPGFA算法受力图
Fig.7 Force diagram of DDPG and DDPGFA algorithms during experimentation
表 5 DDPG与DDPGFA算法在X向和Z向的装配受力
Tab.5
| 实验序号 | 所用算法 | FX/N | FZ/N | |||
| 最大值 | 平均值 | 最大值 | 平均值 | |||
| 1 | DDPG | 3.78 | 1.92 | 3.05 | 1.49 | |
| DDPGFA | 2.45 | 1.36 | 2.25 | 1.26 | ||
| 2 | DDPG | 2.05 | 1.21 | 3.40 | 1.96 | |
| DDPGFA | 1.52 | 0.77 | 2.85 | 1.83 | ||
| 3 | DDPG | 1.40 | 1.20 | 31.05 | 12.05 | |
| DDPGFA | 1.29 | 0.86 | 2.52 | 1.95 | ||
| 4 | DDPG | 2.62 | 1.28 | 8.70 | 2.49 | |
| DDPGFA | 1.78 | 1.13 | 3.85 | 2.26 | ||
此外,在相同的位置误差下,DDPGFA算法的平均装配力明显小于DDPG算法的装配力变化,装配力降低了约30%.在实验3和实验4中,DDPG算法的力的波动较大;在实验4中,DDPG算法装配失败. 虽然有明显的位置偏差,但DDPGFA算法调整得较平稳,装配力也在可接受的范围内.
综上所述,基于DDPGFA算法的装配策略比基于单独的DDPG算法的具有更稳定的训练过程和更强的求解能力,更能够满足大直径轴孔零件的装配任务要求,验证了改进算法的有效性.
5. 结 语
提出用于大口径轴孔装配任务的DDPGFA装配策略,该策略通过将模糊动作与传统的DDPG算法结合,完成轴入孔的装配训练阶段,然后应用于实际的装配过程.
装配训练过程表明,提出的DDPGFA策略可以实现更平滑的收敛状态,并具有更快的收敛速度,在仿真训练上比典型的DDPG算法快15%. 在实际装配过程中,DDPGFA策略在相同的初始位置偏差下有更稳定的装配步骤. 并且在装配过程中,装配接触力减少了约30%,可以更快、更精确地进行机器人装配动作调整. 实验结果证明所提控制策略的可行性和高效性.
在后续研究中,将考虑采用不同尺寸的轴孔来做对比实验,制定更加泛用的控制策略,实现多种轴孔的柔顺装配.
参考文献
工业机器人的研发及应用综述
[J].DOI:10.16183/j.cnki.jsjtu.2016.S.025 [本文引用: 1]
A review of the research and development of industrial robots
[J].DOI:10.16183/j.cnki.jsjtu.2016.S.025 [本文引用: 1]
Peg-on-hole: mathematical investigation of motion of a peg and of forces of its interaction with a vertically fixed hole during their alignment with a three-point contact
[J].
基于力/位混合控制的工业机器人精密轴孔装配
[J].
Industrial robot high precision peg-in-hole assembly based on hybrid force/position control
[J].
Force control for a rigid dual peg-in-hole assembly
[J].DOI:10.1108/AA-09-2016-120 [本文引用: 1]
A control method of space manipulator for peg-in-hole assembly task considering equivalent stiffness optimization
[J].DOI:10.3390/aerospace8100310 [本文引用: 1]
Variable compliance control for robotic peg-in-hole assembly: a deep-reinforcement-learning approach
[J].DOI:10.3390/app10196923 [本文引用: 1]
A learning framework of adaptive manipulative skills from human to robot
[J].
Survey of model-based reinforcement learning: applications on robotics
[J].DOI:10.1007/s10846-017-0468-y [本文引用: 1]
Reinforcement learning in robotics: a survey
[J].DOI:10.1177/0278364913495721 [本文引用: 1]
Artificial intelligence-based optimal grasping control
[J].DOI:10.3390/s20216390 [本文引用: 1]
Continuous control of a polymerization system with deep reinforcement learning
[J].DOI:10.1016/j.jprocont.2018.11.004 [本文引用: 1]
Deep reinforcement learning: a brief survey
[J].DOI:10.1109/MSP.2017.2743240 [本文引用: 2]
A comprehensive survey on safe reinforcement learning
[J].
Linguistic Lyapunov reinforcement learning control for robotic manipulators
[J].DOI:10.1016/j.neucom.2017.06.064 [本文引用: 1]
A fuzzy reinforcement learning algorithm for inventory control in supply chains
[J].
Learning-based variable compliance control for robotic assembly
[J].DOI:10.1115/1.4041331 [本文引用: 1]
Feedback deep deterministic policy gradient with fuzzy reward for robotic multiple peg-in-hole assembly tasks
[J].
A reinforcement learning method for human-robot collaboration in assembly tasks
[J].DOI:10.1016/j.rcim.2021.102227 [本文引用: 1]
Efficient insertion control for precision assembly based on demonstration learning and reinforcement learning
[J].DOI:10.1109/TII.2020.3020065 [本文引用: 1]
Fuzzy logic-driven variable time-scale prediction-based reinforcement learning for robotic multiple peg-in-hole assembly
[J].
A survey of actor-critic reinforcement learning: standard and natural policy gradients
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}