

在公共安全方面,车底隐藏的危险物具有隐蔽性强、破坏力大、探测难度高等问题. 在我国行政机构、民航机场、海港等公共场所,一些不法分子利用机动车辆,将危险物品藏匿在车底,从而躲避执法人员的检查,这些危险物品给人民群众的生命财产安全带来巨大影响. 因此,如何对车底进行高效且全面的安全检查成为当务之急.
针对车底危险物检测这一现实问题,国内学者做过一系列研究. 张辉等[1]设计了车底扫描探测系统,该检测系统用线阵电荷耦合器件(charge-coupled device,CCD)摄像机对车底快速扫描、成像,然后采用图像处理方法进行分类,从而检测是否有危险物. 徐常星等[2]提出一种基于机器学习的智能车底安检平台,其在检测车底危险物时采用图像对比算法,利用放射矩阵计算图像相似度,从而检测出危险物目标,但由于车底危险物目标相对整幅车底图像较小,其传统的图像匹配方法无法满足检测的准确性与实时性. 许金金等[3]设计了基于红外图像的车底藏人系统,主要通过定位目标区域和提取目标感兴趣区域来检测出可疑目标,但该系统采用传统的边缘检测算子,检测出的人体图像不明显且误检率较高.
针对上述研究存在的问题,本研究提出一种SG-YOLOv5s车底危险物检测网络模型,并在自建的车底危险物数据集上进行验证. 首先,针对车底危险物图像不足的现状以及车底图像难以获取的问题,利用智能小车拍摄大量车底碎片化图像,采用AutoStitch[7] (automatic panoramic image stitching using invariant features)算法对碎片化图像进行拼接,最终得到完整的车底图像. 其次,模型以YOLOv5s网络为基础,引入ShuffleNet v2和Ghost卷积模块来改进骨干和颈部,大大减少了网络的参数量,提高了检测精确性,并且在训练阶段采用Mixup[8]数据增强,能够较好地提升网络的泛化能力. 最后,将定位损失函数CIoU[9]替换成SIoU[10],使目标框回归变得更加稳定,能提升模型预测准确度.
1. YOLOv5s算法
图 1
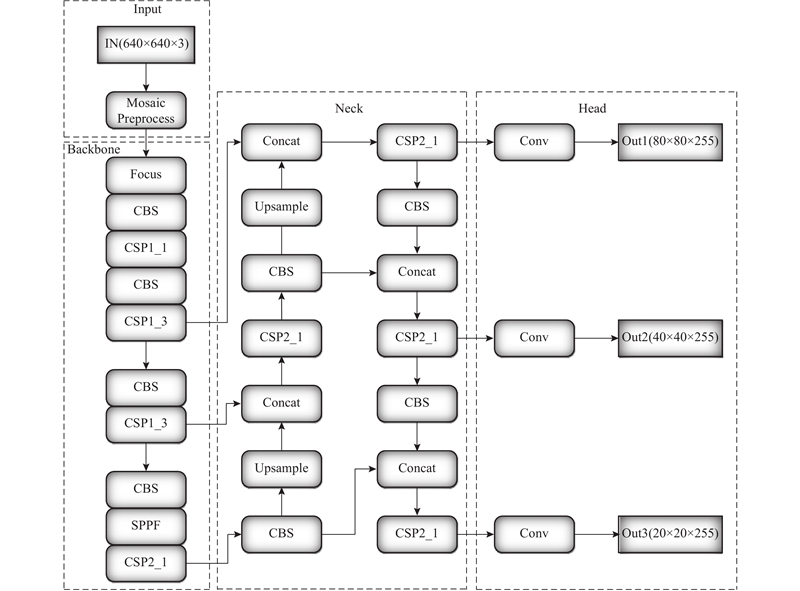
输入端主要包括马赛克(Mosaic)数据增强、自适应锚框计算和自适应图片缩放. Mosaic数据增强方法采用了4张图片,并且按照随机缩放、随机裁剪和随机排布的方式进行拼接,具体的效果如图2所示. 这种增强方法可以将几张图片组合成一张,不但可以丰富数据集,而且能极大地提升网络的训练速度,降低模型的内存需求.
图 2

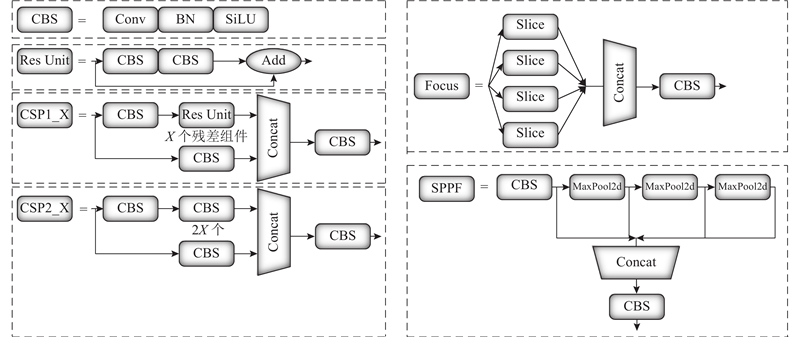
Backbone网络主要由Focus、CBS、CSP、SPPF(spatial pyramid pooling fast)组成,如图3所示. Focus结构的主要思想是通过Slice操作对输入图像进行裁剪. CBS模块是YOLOv5s的一个基本卷积模块,对输入图像进行卷积、规范化操作和线性激活操作. YOLOv5s中设计了2种CSP结构,CSP1_X结构主要应用于基准网络中,另一种CSP2_X结构则主要应用于Neck网络中. 采用CSP模块是先将基础层的特征映射划分为2部分,然后通过跨阶段分层进行合并,减少了计算量且保证了精度. SPPF模块,又称快速-空间金字塔池化,是将输入以串行的方式依次通过3个大小为5×5的最大池化,再将特征图进行Concat操作,加快了提取重要特征的速度.
图 3
2. SG-YOLOv5s网络
为了实现精确且高效的车底危险物目标检测,方便后续的边缘端侧部署,本研究提出一种轻量化SG-YOLOv5s网络,如图4所示. 依据ShuffleNet v2论文[17]中提到的避免网络的碎片化,减少网络分支带来的冗余计算,摒弃原YOLOv5s中基准网络的CBS模块和CSP1_X模块,采用图5中ShuffleNet v2基本单元中的S-(1)模块代替CBS模块,用S-(2)模块代替CSP1_X模块,从而重新构建基准网络. S-(1)模块提取输入特征图的特征,并且保持特征图大小不变. S-(2)是下采样模块,使特征图空间大小减半,通道数翻倍. 在Neck网络中仍然是采用FPN和PAN结构,但用Ghost Module和自主设计的GhostBottleneck替换原有Neck网络中的CBS模块,并采用S-(1)替换CSP2_X模块. 用轻量化模块替换原有网络中的模块,可以减少许多冗余分支,大量降低网络的参数量和计算量.
图 4
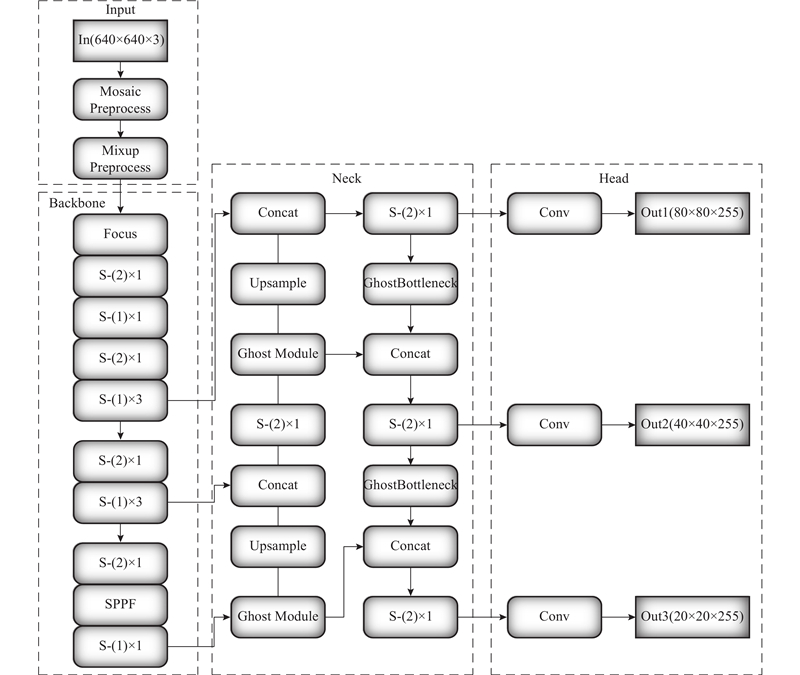
图 5
改进主干网络结构如表1所示,其序号从小到大依次堆叠起来,中层次特征兼容性更好. 为了加强对中间层的特征提取,在设计Backbone网络时,在序号4和6的模块处,将S-(1)模块的重复次数设置为3,这样设计既能有效保证网络的深度,又能较好地降低网络的参数量,提高网络训练速度. 参数配置中第1个参数表示输入的通道数,第2个参数表示输出的通道数,第3个参数表示卷积核步长. SPPF模块的参数配置稍有不同,第1个参数和第2个参数依旧是表示输入的通道数和输出的通道数,但第3个参数表示池化核的大小均为5×5. 与SPP模块不同,SPPF模块使用大小为5×5的池化核,依次对输入以串行的方式进行最大池化,然后再将输入和依次进行最大池化后的输出进行拼接,从而提高运行效率,降低计算量. 假设输入尺寸 640×640×3,从表中的输出特征图中可以看出,经过这一系列步骤,特征图的长宽尺度逐渐缩小,通道数量逐渐扩张,特征将由浅入深地一步一步被表达.
表 1 Backbone网络结构参数
Tab.1
| 序号 | 模块重复次数 | 模块名 | 参数配置 | 输出大小 |
| 0 | 1 | Focus | [3, 32, 3] | 32×320×320 |
| 1 | 1 | S-(2) | [32, 64, 2] | 64×160×160 |
| 2 | 1 | S-(1) | [64, 64, 1] | 64×160×160 |
| 3 | 1 | S-(2) | [64, 128, 2] | 128×80×80 |
| 4 | 3 | S-(1) | [128, 128, 1] | 128×80×80 |
| 5 | 1 | S-(2) | [128, 256, 2] | 256×40×40 |
| 6 | 3 | S-(1) | [256, 256, 1] | 256×40×40 |
| 7 | 1 | S-(2) | [256, 512, 2] | 512×20×20 |
| 8 | 1 | SPPF | [512, 512, [5, 5, 5]] | 512×20×20 |
| 9 | 1 | S-(1) | [512, 512, 1] | 512×20×20 |
2.1. ShuffleNet v2网络引入
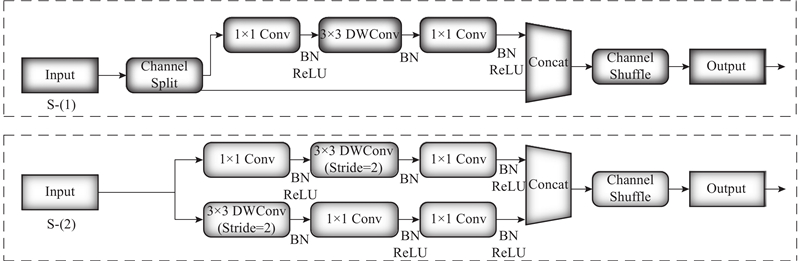
在分析ShuffleNet v1[18]设计不足的基础上,根据4条准则改进得到ShuffleNet v2,如图5所示. 图中展示了ShuffleNet v2的2个基本单元,主要包括通道分割(Channel Split)、逐通道卷积(Depthwise Convolution,DWConv)和通道混洗(Channel Shuffle). 4条准则如下:1)1×1卷积平衡输入和输出的通道大小;2)谨慎使用分组卷积;3)避免网络的碎片化;4)减少元素级运算. 为了改善v1的缺陷,在v2中引入了通道分割这一新的运算方法. Channel Split在开始时是将输入特征图在通道维度分成2个分支:c1和c2,在实际实现时c1=c2. 左边分支做同等映射,右边的分支包含连续3个卷积,并且输入和输出通道相同,这满足第1条原则,而且2个1×1卷积不再是组卷积,这满足第2条原则. 2个分支的输出不再是Add元素相加,而是Concat在一起,紧接着是对2个分支Concat结果进行通道混洗,以保证2个分支的信息交流. Concat和Channel Shuffle可以和下一个模块单元的Channel Split合成一个元素级运算,这满足第4条原则.
2.2. Ghost卷积模块引入
图 6
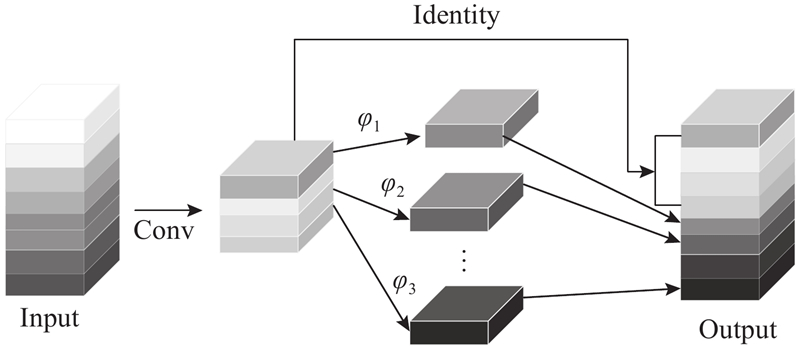
Ghost卷积与传统卷积的不同之处在于,它分为2个步骤执行. 第1步是用少量1×1的普通卷积生成
两者计算量之比如下:
由式(3)可以看出,与普通卷积相比,在不更改输出特征图大小的情况下,Ghost模块中所需的计算量均已降低,约为传统卷积的
依据轻量化的Ghost卷积模块,本研究自主设计出GhostBottleneck结构,如图7所示. 与原GhostBottleneck不同的是,本研究设计出的 GhostBottleneck结构在2条分支上均包含Ghost Module和步长为2的逐通道卷积,这样设计不但能满足Neck网络中特征图空间减半的需求,而且能大大减少普通卷积过程中的运算量和模型参数数量.
图 7

2.3. Mixup数据增强
Mixup是一种简单且有效的数据增强方法,在目标检测领域得到广泛应用. Mixup是一种用于增强图像混合的计算机视觉算法,它可以混合不同类的图像来扩展训练数据集. 为了提高网络对遮挡和重叠目标的识别能力,在Mosaic增强方法的基础上,采用Mixup数据增强,将4张图像拼接成一张图像,送给网络进行训练,能够有效提高网络检测精度,如图8所示. 在训练中设置前70%的epoch使用Mosaic数据增强,且每个epoch使用Mosaic数据增强的概率为50%,仅在开启Mosaic数据增强时才开启Mixup数据增强,每个epoch使用Mixup数据增强的概率为25%.
图 8

2.4. 损失函数改进
虽然CIoU解决了GIoU[20]训练中发散的问题,但纵横比描述的是相对值,存在一定的模糊,没有考虑难易样本的平衡. 针对上述CIoU所存在的问题且鉴于车底危险物识别时,预测框可能在训练过程中无法正确匹配真实框,本研究引用了一种新的边界框回归损失函数SIoU_Loss,其在损失函数的代价中引入方向性,与CIoU损失相比,具有更好的推理性能. SIoU损失函数由4个成本函数组成:角度成本(angle cost)、距离成本(distance cost)、形状成本(shape cost)、IoU成本(IoU cost).
1)角度成本. 角度成本示意图如图9所示.
图 9
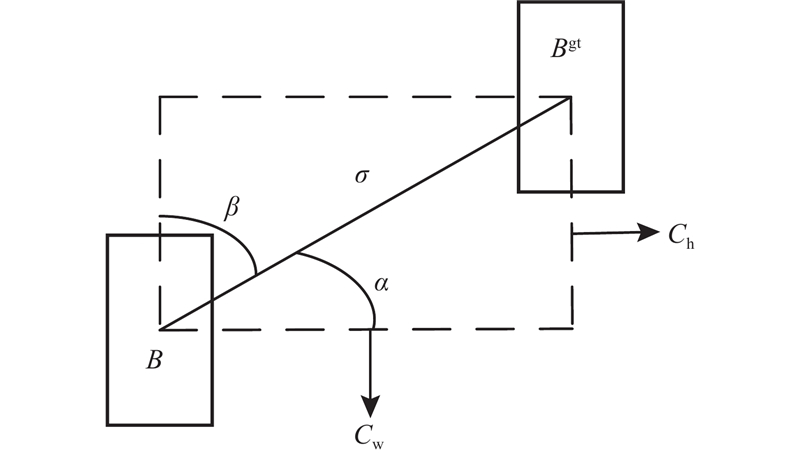
原始角度成本表达式如下:
其中,
式中:
最终角度成本表达式如下:
引入角度成本的目的是最大限度地减少与距离相关的变量数量.
2)距离成本. 考虑到上面的角度成本,重新定义距离成本:
其中,
式中:Cw为2个框的质心横坐标之差.
由式(6)~(8)可以看出,
3)形状成本. 表达式如下:
其中,
式中:w、h为预测框的宽和高,wgt、hgt为真实框的宽和高.
形状成本即从长宽来看,真实框的形状与预测框是否相似,
4)IoU成本. 表达式如下:
式中:B表示预测框,Bgt表示真实框.
SIoU_Loss表达式为
3. 实验结果与分析
3.1. 数据集的建立
鉴于车底危险物的图像较少且目前没有公开的相关数据集,本研究使用自建的车底危险物数据集. 针对车底空间狭小且不易拍摄到完整车底图像的问题,首先,将汽车停在起降台上,使其升高一小段距离,再在车底放入不同的模拟危险物;其次,使用智能机器人小车搭载1080P超清摄像头进入车底拍摄;最后,采用AutoStitch图像拼接算法将机器人小车拍摄的碎片化图像拼接成一张完整的车底图像. AutoStitch图像拼接算法是目前广泛使用的拼接算法,该算法在原始图像拼接素材上,需要多幅图像之间有较大的重合区域. 机器人小车上装有Wi-Fi模块,能与手机上的App进行交互,在小车进入车底前,调整摄像头水平向上,小车每向前一次,通过手机上的App能看到车底的情况,这时按下拍摄按键,就能成功拍摄一张车底的碎片化图像. 由于须操控机器人小车进行拍摄,在拍摄过程中摄像头角度略有变化,这样会略微导致拼接出的图像产生边缘畸变[21],但边缘畸变的图像数量不多且模拟危险物的清晰度不受影响. 根据车长的不同,每辆汽车一般需要拍摄10~14张车底的碎片化图像. 由于是白天进行拍摄,阳光照射的强度会影响拍摄碎片化图像的亮暗,如图10所示,但拼接出的完整车底图像中的模拟危险物依旧清晰可见,如图11所示.
图 10

图 11

制作数据集期间共拍摄30000多张碎片化车底图像,拼接出2716张完整的车底图像,来自10辆不同车型的车底,有9类模拟危险物,分别为手套(glove)、剪刀(scissors)、老虎钳(pliers)、塑料瓶(plastic bottles)、刀(knife)、袋子(bag)、棍子(stick)、滚筒(drum)、螺丝刀(screwdriver),其中剪刀、刀、螺丝刀用于模拟管制刀具危险物,塑料瓶、袋子用于模拟瓶中或袋中有不明物体危险物. 使用LabelImg标注软件对完整车底图像进行标注. 在实验前,随机划分训练集、验证集和测试集,分别包含2199、245和272张图像.
3.2. 评价指标
使用的评价指标[22]有准确率(precision,P)、召回率(recall,R)、平均精度(average precision,AP)、平均精度均值(mean average precision,mAP)、参数量(parameter,Par)、权重大小(memory,Me)、每秒传输帧数(frames per second,FPS). 准确率和召回率. 表达式如下:
式中:
3.3. 实验环境配置
实验环境如下:操作系统Windows11;CPU AMD Ryzen 7 5800H with Radeon Graphics 3.20 GHz;内存大小16 GB;GPU Nvidia GeForce RTX 3070Ti;深度学习框架Pytorch 1.11.0;CUDA版本为11.5;本研究在设定图像预处理时采用Mosaic数据增强和Mixup数据增强;模型输入的尺寸为640×640×3;优化器采用Adam;batch_size为8;初始学习率设置为0.001;动量(momentum)等于0.937;总训练轮数为400轮.
3.4. 车底危险物识别
表 2 每类危险物的平均精度
Tab.2
| 类别 | AP/% | 类别 | AP/% | |
| 手套 | 99.76 | 袋子 | 99.33 | |
| 剪刀 | 94.69 | 棍子 | 98.16 | |
| 老虎钳 | 100.00 | 滚筒 | 97.05 | |
| 塑料瓶 | 98.28 | 螺丝刀 | 99.19 | |
| 刀 | 92.18 | — | — |
图 12

图 12 不同类型车底的不同种类危险物检测
Fig.12 Detection of different types of hazardous objects under different types of vehicles
3.5. 消融实验
消融实验简单来说就是控制变量法,在目标检测中采用消融实验是为了验证改进思路的有效性和起作用方式. 如表3所示为SG-YOLOv5s网络模型消融实验结果分析,分为是否采用Mixup数据增强,是否采用Backbone网络改进,是否采用Neck网络改进,是否采用SIoU损失函数这4个部分. 表中,①是原有YOLOv5s模型,②是增加了Mixup数据增强,③是采用改进的Backbone网络加Mixup数据增强,④是采用改进的Neck网络加Mixup数据增强,⑤是采用改进的Backbone网络和Neck网络加上Mixup数据增强,⑥是SG-YOLOv5s网络模型,在⑤的基础上,将CIou换成SIoU. 表中,mAP_0.5表示IoU取值为0.5时计算出模型的mAP数值.
表 3 SG-YOLOv5s网络模型消融实验结果分析
Tab.3
| 模型 | P/% | R/% | Par/MB | Me/MB | FPS | mAP_0.5/% |
| ①YOLOv5s | 96.59 | 94.08 | 7.03 | 26.81 | 50.39 | 96.37 |
| ②YOLOV5s+Mixup | 97.60 | 94.31 | 7.03 | 26.81 | 49.22 | 96.49 |
| ③YOLOv5s+Backbone+Mixup | 96.17 | 94.50 | 4.15 | 15.83 | 46.37 | 96.49 |
| ④YOLOv5s+Neck+Mixup | 96.99 | 96.96 | 4.90 | 18.68 | 45.33 | 97.00 |
| ⑤Backbone+Neck+Mixup+CIoU | 96.92 | 97.02 | 2.02 | 7.70 | 47.04 | 97.19 |
| ⑥Backbone+Neck+Mixup+SIoU | 96.80 | 97.96 | 2.02 | 7.70 | 47.39 | 97.63 |
如表3所示,在自建数据集上,消融实验②与①的对比表明Mixup数据增强对于实验精度有略微的提升,提高了0.12%;消融实验③、④与②的对比,表明改进后的Backbone网络在精度上与原模型相当,而改进后的Neck网络相对原模型精度有所提高;消融实验⑤与②进行比较,准确率略有下降,召回率明显提升,改进的Backbone网络和Neck网络相结合,精度提高0.7%. 消融实验⑥与⑤相比,平均精度提高0.44%,表明SIoU损失函数比CIoU效果更好. 本研究提出的SG-YOLOv5s模型的参数量和权重体积与原模型相比均大大减少,在P、R、mAP_0.5上,SG-YOLOv5s模型分别提高了0.21%、3.88%、1.26%,均优于原始模型.
3.6. SG-YOLOv5s网络模型在不同图像尺寸下的性能对比
为了在SG-YOLOv5s网络模型检测精度和实时性方面做出尽可能的平衡,本研究在其他输入参数条件保持一致的情况下,对模型传入数据的尺寸进行改变,以便得出最优的传入图像数据规格,如表4所示. 可以看出,较小的输入图像尺寸会严重降低检测精度,并且导致模型的运算效率明显变缓. 因此选用640×640像素的图像作为输入尺寸较合理.
表 4 SG-YOLOv5s网络模型在不同图像尺寸下的性能对比
Tab.4
| 尺寸/像素 | mAP_0.5/% | FPS |
| 320×320 | 79.95 | 35.53 |
| 416×416 | 87.58 | 38.99 |
| 512×512 | 92.99 | 42.62 |
| 640×640 | 97.63 | 47.39 |
3.7. 常见目标检测模型的性能对比
为了比较SG-YOLOv5s网络模型的检测效果,选择了一些常见的目标检测网络模型进行对比:Faster R-CNN[23]、YOLOv3、YOLOv4[24]、YOLOv5s、YOLOX[25]、YOLOv7[26]. 如表5所示为常见目标检测模型的性能对比. 可以看出, YOLOv5s、YOLOX-s和YOLOv7模型比Faster R-CNN、YOLOv3、YOLOv4的模型参数量都要小且精度更高,但其模型参数量和权重体积仍然过大,不适宜部署在边缘端侧. 本研究提出的SG-YOLOv5s模型,相较于其他主流模型,在参数量和权重大小上优势明显,虽然其识别速度略低于YOLOv5s的,但检测精度优势较大,比YOLOv5s模型的高1.26%,比YOLOX-s模型的高0.48%,更适合部署在边缘终端中使用.
表 5 常见目标检测模型的性能对比
Tab.5
| 模型 | P/% | R/% | Par/MB | Me/MB | FPS | mAP_0.5/% |
| Faster R-CNN | 71.51 | 85.61 | 137.10 | 522.99 | 13.18 | 87.88 |
| YOLOv3 | 93.63 | 87.39 | 61.53 | 234.74 | 39.63 | 92.11 |
| YOLOv4 | 93.82 | 91.22 | 63.95 | 243.94 | 30.97 | 93.97 |
| YOLOX-s | 97.74 | 97.21 | 8.94 | 34.10 | 42.89 | 97.15 |
| YOLOv7 | 96.75 | 94.97 | 37.21 | 141.93 | 33.14 | 97.03 |
| YOLOv5s | 96.59 | 94.08 | 7.03 | 26.81 | 50.39 | 96.37 |
| SG-YOLOv5s | 96.80 | 97.96 | 2.02 | 7.70 | 47.39 | 97.63 |
为了更加直观地进行评价,将SG-YOLOv5s模型与原YOLOv5s模型对车底危险物的检测效果进行对比,如图13所示. 图中,左边为YOLOv5s的检测效果,右边为SG-YOLOv5s模型的检测效果. 第1排的对比图表明,SG-YOLOv5s模型对于车底危险物的检测精度更高;第2、3排的对比图表明,YOLOv5s的检测存在漏检的问题,而SG-YOLOv5s模型均检测出藏匿在车底的危险物;第4排的对比图表明,YOLOv5s模型存在检测目标的预测框定位不精准的问题,而SG-YOLOv5s模型则将2个危险物精确框出. 综上,SG-YOLOv5s模型在车底危险物检测中效果更好.
图 13

图 13 SG-YOLOv5s模型与原YOLOv5s模型的检测效果对比
Fig.13 Comparison of detection effects between SG-YOLOv5s model and original YOLOv5s model
4. 结 语
鉴于车底危险物检测模型精度低、参数多、权重体积大、难以在端侧部署的问题,提出SG-YOLOv5s网络模型,模型以YOLOv5s网络为基础,引入ShuffleNet v2和Ghost卷积模块来改进骨干和颈部,大大减少了网络的参数量,提高了检测精确性;在训练阶段采用Mixup数据增强,能够较好地提升网络的泛化能力;将定位损失函数CIoU替换成SIoU,使目标框回归变得更加稳定,提升模型预测准确度. 在自建车底模拟危险物数据集上进行训练和验证,结果表明,模型在检测精度提升1.26%的基础上,参数量减少了71.27%,模型大小仅为7.70 MB.
虽然模型的参数量已满足嵌入式系统上的部署要求,但模型的检测速度仍有较大的上升空间,后续也须在保证精度的同时加快模型检测速度,从而使模型更好地适应车底危险物现场检测需求,为边防检查、军事管理区、监狱、大型活动等提供安全且智能化的检测识别工具.
参考文献
视频车底安检系统的开发
[J].DOI:10.3969/j.issn.1000-0682.2010.02.007 [本文引用: 1]
Development of under vehicle surveillance system
[J].DOI:10.3969/j.issn.1000-0682.2010.02.007 [本文引用: 1]
智能视觉车底安检便携移动平台
[J].
Intelligent vision under car security portable mobile platform
[J].
基于红外图像的车底藏人检测系统设计
[J].DOI:10.3778/j.issn.1002-8331.1206-0027 [本文引用: 1]
Infrared image-based system for detecting hiding personnel under vehicle
[J].DOI:10.3778/j.issn.1002-8331.1206-0027 [本文引用: 1]
基于改进YoloX-s的密贴检查器故障检测方法
[J].
A fault detection method of closure detectors based on the improved YoloX-s
[J].
一种基于YOLOv3的汽车底部危险目标检测算法
[J].
A vehicle bottom dangerous object detection algorithm based on YOLOv3
[J].
基于改进YOLOv5的金属工件表面缺陷检测
[J].
Surface defect detection of metal workpiece based on improved YOLOv5
[J].
融合注意力机制的 YOLOv5 口罩检测算法
[J].
Mask detection algorithm based on YOLOv5 integrating attention mechanism
[J].
基于模型压缩的ED-YOLO电力巡检无人机避障目标检测算法
[J].
ED-YOLO power inspection UAV obstacle avoidance target detection algorithm based on model compression
[J].
改进YOLOv5的建筑物破损检测算法研究
[J].
Research on improved YOLO v5 building damage detection algorithm
[J].
基于Opencv图像处理的无人机影像拼接技术研究
[J].
Research on UAV image Mosaic technology based on Opencv image processing
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}