(6) $\left. \begin{array}{l} L = \displaystyle\sum\limits_{t = 1}^T {{\alpha _t}(L_{{\text{bbox}}}^t + L_{{\text{mask}}}^t)}, \hfill \\ L_{{\text{bbox}}}^t({{\boldsymbol{c}}_t},{{\boldsymbol{r}}_t},{{\hat {\boldsymbol{c}}}_t},{{\hat {\boldsymbol{r}}}_t}) = {L_{{\text{cls}}}}({{\boldsymbol{c}}_t},{{\hat {\boldsymbol{c}}}_t}) + {L_{{\text{reg}}}}({{\boldsymbol{r}}_t},{{\hat {\boldsymbol{r}}}_t}), \hfill \\ L_{{\text{mask}}}^t({{\boldsymbol{m}}_t},{{\hat {\boldsymbol{m}}}_t}) = {\text{BCE(}}{{\boldsymbol{m}}_t},{{\hat {\boldsymbol{m}}}_t}) . \end{array}\right\} $
[1]
罗杨. 复杂环境下的车道线检测 [D]. 成都: 电子科技大学, 2020.
[本文引用: 1]
LUO Yang. Lane detection under complicated environment [D]. Chengdu: University of Electronic Science and Technology of China, 2020.
[本文引用: 1]
[2]
NGUYEN T N A, PHUNG S L, BOUZERDOUM A Hybrid deep learning-gaussian process network for pedestrian lane detection in unstructured scenes
[J]. IEEE Transactions on Neural Networks and Learning Systems , 2020 , 31 (12 ): 5324 - 5338
DOI:10.1109/TNNLS.2020.2966246
[本文引用: 1]
[3]
吴一全, 刘莉 基于视觉的车道线检测方法研究进展
[J]. 仪器仪表学报 , 2019 , 40 (12 ): 92 - 109
[本文引用: 1]
WU Yi-quan, LIU Li Research and development of the vision-based lane detection methods
[J]. Chinese Journal of Scientific Instrument , 2019 , 40 (12 ): 92 - 109
[本文引用: 1]
[4]
胡忠闯. 基于深度学习的车道线检测算法研究 [D]. 杭州: 浙江大学, 2018.
[本文引用: 1]
HU Zhong-chuang. Deep learning based lane markings detection algorithm [D]. Hangzhou: Zhejiang University, 2018.
[本文引用: 1]
[5]
YOO H, YANG U, SOHN K Gradient-enhancing conversion for illumination-robust lane detection
[J]. IEEE Transactions on Intelligent Transportation Systems , 2013 , 14 (3 ): 1083 - 1094
DOI:10.1109/TITS.2013.2252427
[本文引用: 1]
[7]
SHEN Y H, BI Y R, YANG Z, et al Lane line detection and recognition based on dynamic ROI and modified firefly algorithm
[J]. International Journal of Intelligent Robotics and Applications , 2021 , 5 (2 ): 143 - 155
DOI:10.1007/s41315-021-00175-2
[本文引用: 1]
[8]
庞彦伟, 修宇璇 基于边缘特征融合和跨连接的车道线语义分割神经网络
[J]. 天津大学学报: 自然科学与工程技术版 , 2019 , 52 (8 ): 779 - 787
[本文引用: 1]
PANG Yan-wei, XIU Yu-xuan Lane semantic segmentation neural network based on edge feature merging and skip connections
[J]. Journal of Tianjin University: Science and Technology , 2019 , 52 (8 ): 779 - 787
[本文引用: 1]
[9]
PAN X G, SHI J P, LUO P, et al. Spatial as deep: spatial CNN for traffic scene understanding [C]// 32nd AAAI Conference on Artificial Intelligence . New Orleans: AAAI, 2018: 7276-7283.
[本文引用: 1]
[10]
NEVEN D, BRABANDERE B D, GEORGOULIS S, et al. Towards end-to-end lane detection: an instance segmentation approach [C]// 2018 IEEE Intelligent Vehicles Symposium . Suzhou: IEEE, 2018: 286-291.
[本文引用: 1]
[11]
CAI Z W, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6154-6162.
[本文引用: 1]
[12]
CHEN K, PANG J M, WANG J Q, et al. Hybrid task cascade for instance segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 4969-4978.
[本文引用: 3]
[13]
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 1]
[14]
YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions [C]// International Conference on Learning Representations . San Juan: [s.n.], 2016: 1-13.
[本文引用: 1]
[15]
DAI J F, QI H Z, XIONG Y W, et al. Deformable convolutional networks [C]// IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 764-773.
[本文引用: 1]
[16]
LIU Z W, SHEN C, FAN X, et al Scale-aware limited deformable convolutional neural networks for traffic sign detection and classification
[J]. IET Intelligent Transport Systems , 2020 , 14 (12 ): 1712 - 1722
DOI:10.1049/iet-its.2020.0217
[本文引用: 1]
[17]
CHEN S Y, ZHANG Z X, ZHONG R F, et al A dense feature pyramid network-based deep learning model for road marking instance segmentation using MLS point clouds
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2021 , 59 (1 ): 784 - 800
DOI:10.1109/TGRS.2020.2996617
[本文引用: 1]
[18]
LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8759-8768.
[本文引用: 2]
[19]
周志华. 机器学习[M]. 1版. 北京: 清华大学出版社, 2016: 24-26.
[本文引用: 1]
[20]
HE K M, GEORGIA G, PIOTR D, et al. Mask R-CNN [C]// IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2980-2988.
[本文引用: 2]
1
... 随着人工智能技术以及汽车工业的快速发展,无人驾驶汽车及无人驾驶技术逐渐成为智能交通领域的研究热点. 在无人驾驶汽车道路环境的感知过程中,车道线信息的精确感知是汽车智能行驶的基本要求之一,车道线检测与分类对于规范汽车行驶行为、保障汽车行车安全具有重要意义. 由于真实道路场景的环境复杂多样,光照强度变化、车辆遮挡、车道线磨损等问题给车道线检测与分类研究带来了困难[1 ] ,车道线检测与分类逐渐成为国内外学者和研究机构的研究热点[2 -3 ] . 目前,车道线检测算法主要包括基于传统图像处理的方法及基于深度学习的方法2类[4 ] . ...
1
... 随着人工智能技术以及汽车工业的快速发展,无人驾驶汽车及无人驾驶技术逐渐成为智能交通领域的研究热点. 在无人驾驶汽车道路环境的感知过程中,车道线信息的精确感知是汽车智能行驶的基本要求之一,车道线检测与分类对于规范汽车行驶行为、保障汽车行车安全具有重要意义. 由于真实道路场景的环境复杂多样,光照强度变化、车辆遮挡、车道线磨损等问题给车道线检测与分类研究带来了困难[1 ] ,车道线检测与分类逐渐成为国内外学者和研究机构的研究热点[2 -3 ] . 目前,车道线检测算法主要包括基于传统图像处理的方法及基于深度学习的方法2类[4 ] . ...
Hybrid deep learning-gaussian process network for pedestrian lane detection in unstructured scenes
1
2020
... 随着人工智能技术以及汽车工业的快速发展,无人驾驶汽车及无人驾驶技术逐渐成为智能交通领域的研究热点. 在无人驾驶汽车道路环境的感知过程中,车道线信息的精确感知是汽车智能行驶的基本要求之一,车道线检测与分类对于规范汽车行驶行为、保障汽车行车安全具有重要意义. 由于真实道路场景的环境复杂多样,光照强度变化、车辆遮挡、车道线磨损等问题给车道线检测与分类研究带来了困难[1 ] ,车道线检测与分类逐渐成为国内外学者和研究机构的研究热点[2 -3 ] . 目前,车道线检测算法主要包括基于传统图像处理的方法及基于深度学习的方法2类[4 ] . ...
基于视觉的车道线检测方法研究进展
1
2019
... 随着人工智能技术以及汽车工业的快速发展,无人驾驶汽车及无人驾驶技术逐渐成为智能交通领域的研究热点. 在无人驾驶汽车道路环境的感知过程中,车道线信息的精确感知是汽车智能行驶的基本要求之一,车道线检测与分类对于规范汽车行驶行为、保障汽车行车安全具有重要意义. 由于真实道路场景的环境复杂多样,光照强度变化、车辆遮挡、车道线磨损等问题给车道线检测与分类研究带来了困难[1 ] ,车道线检测与分类逐渐成为国内外学者和研究机构的研究热点[2 -3 ] . 目前,车道线检测算法主要包括基于传统图像处理的方法及基于深度学习的方法2类[4 ] . ...
基于视觉的车道线检测方法研究进展
1
2019
... 随着人工智能技术以及汽车工业的快速发展,无人驾驶汽车及无人驾驶技术逐渐成为智能交通领域的研究热点. 在无人驾驶汽车道路环境的感知过程中,车道线信息的精确感知是汽车智能行驶的基本要求之一,车道线检测与分类对于规范汽车行驶行为、保障汽车行车安全具有重要意义. 由于真实道路场景的环境复杂多样,光照强度变化、车辆遮挡、车道线磨损等问题给车道线检测与分类研究带来了困难[1 ] ,车道线检测与分类逐渐成为国内外学者和研究机构的研究热点[2 -3 ] . 目前,车道线检测算法主要包括基于传统图像处理的方法及基于深度学习的方法2类[4 ] . ...
1
... 随着人工智能技术以及汽车工业的快速发展,无人驾驶汽车及无人驾驶技术逐渐成为智能交通领域的研究热点. 在无人驾驶汽车道路环境的感知过程中,车道线信息的精确感知是汽车智能行驶的基本要求之一,车道线检测与分类对于规范汽车行驶行为、保障汽车行车安全具有重要意义. 由于真实道路场景的环境复杂多样,光照强度变化、车辆遮挡、车道线磨损等问题给车道线检测与分类研究带来了困难[1 ] ,车道线检测与分类逐渐成为国内外学者和研究机构的研究热点[2 -3 ] . 目前,车道线检测算法主要包括基于传统图像处理的方法及基于深度学习的方法2类[4 ] . ...
1
... 随着人工智能技术以及汽车工业的快速发展,无人驾驶汽车及无人驾驶技术逐渐成为智能交通领域的研究热点. 在无人驾驶汽车道路环境的感知过程中,车道线信息的精确感知是汽车智能行驶的基本要求之一,车道线检测与分类对于规范汽车行驶行为、保障汽车行车安全具有重要意义. 由于真实道路场景的环境复杂多样,光照强度变化、车辆遮挡、车道线磨损等问题给车道线检测与分类研究带来了困难[1 ] ,车道线检测与分类逐渐成为国内外学者和研究机构的研究热点[2 -3 ] . 目前,车道线检测算法主要包括基于传统图像处理的方法及基于深度学习的方法2类[4 ] . ...
Gradient-enhancing conversion for illumination-robust lane detection
1
2013
... 基于传统图像处理的车道线检测方法[5 -7 ] 计算量较小,计算效率高,能够在场景简单、车道线标记清晰的道路环境中取得较好的检测性能,但是该方法依赖于人工提取的特征,经验参数的选择对检测效果的影响较大,在复杂场景中检测精度较低、鲁棒性较差,难以满足实际道路场景的应用需求. ...
基于IPM和边缘图像过滤的多干扰车道线检测
0
2020
基于IPM和边缘图像过滤的多干扰车道线检测
0
2020
Lane line detection and recognition based on dynamic ROI and modified firefly algorithm
1
2021
... 基于传统图像处理的车道线检测方法[5 -7 ] 计算量较小,计算效率高,能够在场景简单、车道线标记清晰的道路环境中取得较好的检测性能,但是该方法依赖于人工提取的特征,经验参数的选择对检测效果的影响较大,在复杂场景中检测精度较低、鲁棒性较差,难以满足实际道路场景的应用需求. ...
基于边缘特征融合和跨连接的车道线语义分割神经网络
1
2019
... 近年来,随着深度学习理论的深入研究及计算机硬件性能的不断提高,深度学习在机器视觉和图像处理领域的应用中取得了显著的进展,基于深度学习的车道线检测方法是目前车道线检测领域的研究热点. 庞彦伟等[8 ] 以主流的语义分割网络框架为基础网络,在编码器阶段逐层融合原始特征图和边缘特征提取子网络提取的边缘特征图,建立从编码器到解码器对称位置的跨连接,在解码器逐层上采样的过程中融合编码器对应尺寸的特征图,以增强车道线特征. Pan等[9 ] 提出Spatial CNN(SCNN)网络,在特征图中采用逐片卷积的方式代替传统逐层卷积方式进行计算,使得特征图中像素的行和列之间能够传递信息,提取目标空间关系特征,提高车道线的检测性能. Neven等[10 ] 提出端到端的车道线检测算法,包括LaneNet和 H-Net 2个网络模型. LaneNet网络通过语义分割分支输出车道像素,利用车道嵌入分支将分割的车道像素分离到不同的车道实例中. H-Net网络用于根据道路平面变化估计透视变换矩阵的参数,以适应道路平面变化的情况. 基于深度学习的车道线检测方法与基于传统图像处理的车道线检测方法相比,在检测精度和环境适应能力方面有较大的提升,但是存在车道线特征表述模糊、语义信息利用率较低的问题,有待进一步研究解决. ...
基于边缘特征融合和跨连接的车道线语义分割神经网络
1
2019
... 近年来,随着深度学习理论的深入研究及计算机硬件性能的不断提高,深度学习在机器视觉和图像处理领域的应用中取得了显著的进展,基于深度学习的车道线检测方法是目前车道线检测领域的研究热点. 庞彦伟等[8 ] 以主流的语义分割网络框架为基础网络,在编码器阶段逐层融合原始特征图和边缘特征提取子网络提取的边缘特征图,建立从编码器到解码器对称位置的跨连接,在解码器逐层上采样的过程中融合编码器对应尺寸的特征图,以增强车道线特征. Pan等[9 ] 提出Spatial CNN(SCNN)网络,在特征图中采用逐片卷积的方式代替传统逐层卷积方式进行计算,使得特征图中像素的行和列之间能够传递信息,提取目标空间关系特征,提高车道线的检测性能. Neven等[10 ] 提出端到端的车道线检测算法,包括LaneNet和 H-Net 2个网络模型. LaneNet网络通过语义分割分支输出车道像素,利用车道嵌入分支将分割的车道像素分离到不同的车道实例中. H-Net网络用于根据道路平面变化估计透视变换矩阵的参数,以适应道路平面变化的情况. 基于深度学习的车道线检测方法与基于传统图像处理的车道线检测方法相比,在检测精度和环境适应能力方面有较大的提升,但是存在车道线特征表述模糊、语义信息利用率较低的问题,有待进一步研究解决. ...
1
... 近年来,随着深度学习理论的深入研究及计算机硬件性能的不断提高,深度学习在机器视觉和图像处理领域的应用中取得了显著的进展,基于深度学习的车道线检测方法是目前车道线检测领域的研究热点. 庞彦伟等[8 ] 以主流的语义分割网络框架为基础网络,在编码器阶段逐层融合原始特征图和边缘特征提取子网络提取的边缘特征图,建立从编码器到解码器对称位置的跨连接,在解码器逐层上采样的过程中融合编码器对应尺寸的特征图,以增强车道线特征. Pan等[9 ] 提出Spatial CNN(SCNN)网络,在特征图中采用逐片卷积的方式代替传统逐层卷积方式进行计算,使得特征图中像素的行和列之间能够传递信息,提取目标空间关系特征,提高车道线的检测性能. Neven等[10 ] 提出端到端的车道线检测算法,包括LaneNet和 H-Net 2个网络模型. LaneNet网络通过语义分割分支输出车道像素,利用车道嵌入分支将分割的车道像素分离到不同的车道实例中. H-Net网络用于根据道路平面变化估计透视变换矩阵的参数,以适应道路平面变化的情况. 基于深度学习的车道线检测方法与基于传统图像处理的车道线检测方法相比,在检测精度和环境适应能力方面有较大的提升,但是存在车道线特征表述模糊、语义信息利用率较低的问题,有待进一步研究解决. ...
1
... 近年来,随着深度学习理论的深入研究及计算机硬件性能的不断提高,深度学习在机器视觉和图像处理领域的应用中取得了显著的进展,基于深度学习的车道线检测方法是目前车道线检测领域的研究热点. 庞彦伟等[8 ] 以主流的语义分割网络框架为基础网络,在编码器阶段逐层融合原始特征图和边缘特征提取子网络提取的边缘特征图,建立从编码器到解码器对称位置的跨连接,在解码器逐层上采样的过程中融合编码器对应尺寸的特征图,以增强车道线特征. Pan等[9 ] 提出Spatial CNN(SCNN)网络,在特征图中采用逐片卷积的方式代替传统逐层卷积方式进行计算,使得特征图中像素的行和列之间能够传递信息,提取目标空间关系特征,提高车道线的检测性能. Neven等[10 ] 提出端到端的车道线检测算法,包括LaneNet和 H-Net 2个网络模型. LaneNet网络通过语义分割分支输出车道像素,利用车道嵌入分支将分割的车道像素分离到不同的车道实例中. H-Net网络用于根据道路平面变化估计透视变换矩阵的参数,以适应道路平面变化的情况. 基于深度学习的车道线检测方法与基于传统图像处理的车道线检测方法相比,在检测精度和环境适应能力方面有较大的提升,但是存在车道线特征表述模糊、语义信息利用率较低的问题,有待进一步研究解决. ...
1
... 鉴于Cascade R-CNN[11 ] 网络的多阶段级联结构在目标检测任务中表现出优异的检测性能,Chen等[12 ] 设计多任务多阶段的混合级联结构用于实例分割,提出混合任务级联(hybrid task cascade, HTC)网络. 网络结构图如图1 所示. 该网络在每个阶段交替执行边界框回归和掩码预测,在相邻的掩码分支之间增加连接路径,提供掩码分支之间的信息流,提高实例分割的性能. ...
3
... 鉴于Cascade R-CNN[11 ] 网络的多阶段级联结构在目标检测任务中表现出优异的检测性能,Chen等[12 ] 设计多任务多阶段的混合级联结构用于实例分割,提出混合任务级联(hybrid task cascade, HTC)网络. 网络结构图如图1 所示. 该网络在每个阶段交替执行边界框回归和掩码预测,在相邻的掩码分支之间增加连接路径,提供掩码分支之间的信息流,提高实例分割的性能. ...
... Lane detection results based on different deep learning models
Tab.3 模型 结构 M /106 mAP AP0.5 AP0.75 Mask R-CNN[20 ] 两阶段 62.75 54.6 90.8 58.7 Cascade Mask R-CNN[12 ] 多阶段 95.80 57.7 92.0 62.8 HTC[12 ] 多阶段 95.93 57.8 92.4 62.8 本文方法 多阶段 100.76 58.8 94.5 64.4
如图7 、8 所示为本文方法在测试集中的车道线检测结果. 可知,利用本文方法可以有效地识别车道线的类别,在不同光照条件、不同天气状况、不同道路场景以及车道线磨损、遮挡复杂环境下均具有较好的检测性能. ...
... [
12 ]
多阶段 95.93 57.8 92.4 62.8 本文方法 多阶段 100.76 58.8 94.5 64.4 如图7 、8 所示为本文方法在测试集中的车道线检测结果. 可知,利用本文方法可以有效地识别车道线的类别,在不同光照条件、不同天气状况、不同道路场景以及车道线磨损、遮挡复杂环境下均具有较好的检测性能. ...
1
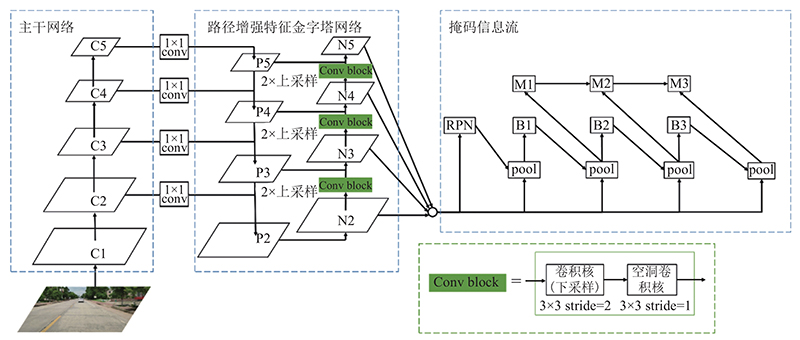
... 用于车道线检测的改进HTC网络结构如图2 所示. 采用残差网络(ResNet)[13 ] 作为主干网络,ResNet包含5个卷积块,分别表示为C1 、C2 、C3 、C4 、C5 . 在卷积块中使用可变形卷积替换常规卷积,提取输出5个不同尺度的车道线特征图,用于构建特征金字塔,输出的车道线特征图如图3 所示. 改进特征金字塔网络结构,在特征金字塔网络的基础上添加自底向上的低层特征传递路径. 该路径包含的网络层数不到10层,缩短了底层与最顶层特征之间的信息传递路径,使得特征金字塔网络输出的特征图包含更多的车道线细节信息,在增强路径中引入空洞卷积[14 ] ,在不损失车道线特征信息的情况下,增大特征图感受野. HTC网络包含4个级联的阶段:第1个为区域候选网络(region proposal network,RPN),在RPN网络中,设定锚框的宽高比分别为0.5、1和2;另外3个阶段为交并比(intersection over union,IOU)阈值逐渐增大的检测模块,阈值分别设置为0.5、0.6和0.7. 不同阶段掩码分支之间存在掩码信息传递路径,这样各阶段的掩码分支既能够得到主干网络提取的特征,也能够得到上一阶段掩码分支输出的特征. HTC网络逐阶段筛选精度更高的目标边界框及目标掩码,减少了复杂背景信息对车道线检测的干扰,提高了车道线的检测精度. ...
1
... 用于车道线检测的改进HTC网络结构如图2 所示. 采用残差网络(ResNet)[13 ] 作为主干网络,ResNet包含5个卷积块,分别表示为C1 、C2 、C3 、C4 、C5 . 在卷积块中使用可变形卷积替换常规卷积,提取输出5个不同尺度的车道线特征图,用于构建特征金字塔,输出的车道线特征图如图3 所示. 改进特征金字塔网络结构,在特征金字塔网络的基础上添加自底向上的低层特征传递路径. 该路径包含的网络层数不到10层,缩短了底层与最顶层特征之间的信息传递路径,使得特征金字塔网络输出的特征图包含更多的车道线细节信息,在增强路径中引入空洞卷积[14 ] ,在不损失车道线特征信息的情况下,增大特征图感受野. HTC网络包含4个级联的阶段:第1个为区域候选网络(region proposal network,RPN),在RPN网络中,设定锚框的宽高比分别为0.5、1和2;另外3个阶段为交并比(intersection over union,IOU)阈值逐渐增大的检测模块,阈值分别设置为0.5、0.6和0.7. 不同阶段掩码分支之间存在掩码信息传递路径,这样各阶段的掩码分支既能够得到主干网络提取的特征,也能够得到上一阶段掩码分支输出的特征. HTC网络逐阶段筛选精度更高的目标边界框及目标掩码,减少了复杂背景信息对车道线检测的干扰,提高了车道线的检测精度. ...
1
... 在常规的卷积神经网络中,由于卷积核的几何结构固定,缺乏对复杂形状目标的自适应几何变换,容易导致目标关键特征信息的丢失. 针对这一问题,Dai等[15 ] 提出可变形卷积(deformable convolution,DCN)概念. 可变形卷积通过在卷积核的每个采样点的位置添加二维偏移向量来捕捉更丰富的特征,通过学习偏移变量实现根据目标几何特征自适应调整采样位置,不局限于常规卷积的规则格点采样. 采样位置更符合目标物体本身的形状和尺寸,有利于目标特征的提取[16 ] . ...
Scale-aware limited deformable convolutional neural networks for traffic sign detection and classification
1
2020
... 在常规的卷积神经网络中,由于卷积核的几何结构固定,缺乏对复杂形状目标的自适应几何变换,容易导致目标关键特征信息的丢失. 针对这一问题,Dai等[15 ] 提出可变形卷积(deformable convolution,DCN)概念. 可变形卷积通过在卷积核的每个采样点的位置添加二维偏移向量来捕捉更丰富的特征,通过学习偏移变量实现根据目标几何特征自适应调整采样位置,不局限于常规卷积的规则格点采样. 采样位置更符合目标物体本身的形状和尺寸,有利于目标特征的提取[16 ] . ...
A dense feature pyramid network-based deep learning model for road marking instance segmentation using MLS point clouds
1
2021
... 特征金字塔网络结构主要包括自下向上的不同维度特征生成、自上向下的特征补充增强、主干网络层提取特征与最终输出的各维度特征之间的关联表达3个基本过程,利用目标不同尺度的特征进行预测输出[17 ] . 在车道线检测图像中,如图3 所示,低层特征主要包括车道线的边缘轮廓和形状细节特征信息,该类信息更有利于车道线精确定位及轮廓范围提取. 高层特征主要包括车道线语义信息,该类信息更有利于车道线分类. 在特征金字塔网络结构中,自下向上的特征生成通路要经过多层的卷积池化操作,较长的特征传递路径容易导致传递过程中低层特征所包含的细节信息的丢失,使得车道线检测定位与轮廓分割精度降低. ...
2
... 为了充分利用特征金字塔低层特征所包含的车道线细节信息,引入路径聚合网络[18 ] (path aggregation network,PANet)中的特征金字塔路径增强策略. 在特征金字塔网络的基础上添加自下向上的低层特征传递路径,该路径包含的网络层数不到10层,能够较好地保留低层特征信息. 通过改进增强路径的特征提取方式,采用空洞卷积,增强整个特征层次结构的定位能力,提高车道线的检测精度,网络结构如图2 所示. ...
... Lane detection results based on different feature extraction methods in augmented path
Tab.2 增强路径特征 M /106 mAP AP0.5 AP0.75 常规卷积[18 ] 100.76 58.6 94.3 63.5 空洞卷积 100.76 58.8 94.5 64.4
基于不同深度学习模型的车道线检测结果对比如表3 所示. 可以看出,Mask R-CNN网络[20 ] 由于单一的IOU阈值检测模型结构,网络模型的参数量最少,但检测精度最低. 本文所研究的改进HTC网络模型的检测精度达到最高,较Mask R-CNN、Cascade Mask R-CNN、HTC网络分别提高了3.7%、2.5% 和 2.1%. 改进HTC网络模型相比于对比方法可以获得更高的准确率和召回率,这得益于改进HTC网络的多阶段级联的网络结构及更强的车道线特征表征能力;相比于Cascade Mask R-CNN和HTC网络,改进HTC网络模型的参数量仅增加了5 MB. 所研究的改进HTC网络可以在较少增加模型参数的基础上,有效提高车道线的检测精度,实现车道线的检测准确性与计算资源消耗的平衡. ...
1
... 在对车道线图像进行预处理的过程中,因检测目标为车道线,图片上半部分均为无效区域,所以裁剪图片上半部分,以减少模型训练与测试的计算量. 通过数据增强的方法扩充数据集,以丰富数据集的场景多样性及光照多样性,提高算法的鲁棒性. 通过图像水平翻转,丰富图像拍摄方向及场景的多样性. 通过亮度调整模拟现实道路场景中光照强度的变化,提高网络模型对光照强度变化环境的适应能力. 通过添加噪声干扰,提高网络模型对包含大量干扰信息的车道线图像的检测能力. 通过数据增强方法,构建车道线数据集共10 000张图片,按照4∶1[19 ] 的比例划分为训练集和测试集,车道线数据集的构建流程如图4 所示. ...
2
... 基于不同深度学习模型的车道线检测结果对比如表3 所示. 可以看出,Mask R-CNN网络[20 ] 由于单一的IOU阈值检测模型结构,网络模型的参数量最少,但检测精度最低. 本文所研究的改进HTC网络模型的检测精度达到最高,较Mask R-CNN、Cascade Mask R-CNN、HTC网络分别提高了3.7%、2.5% 和 2.1%. 改进HTC网络模型相比于对比方法可以获得更高的准确率和召回率,这得益于改进HTC网络的多阶段级联的网络结构及更强的车道线特征表征能力;相比于Cascade Mask R-CNN和HTC网络,改进HTC网络模型的参数量仅增加了5 MB. 所研究的改进HTC网络可以在较少增加模型参数的基础上,有效提高车道线的检测精度,实现车道线的检测准确性与计算资源消耗的平衡. ...
... Lane detection results based on different deep learning models
Tab.3 模型 结构 M /106 mAP AP0.5 AP0.75 Mask R-CNN[20 ] 两阶段 62.75 54.6 90.8 58.7 Cascade Mask R-CNN[12 ] 多阶段 95.80 57.7 92.0 62.8 HTC[12 ] 多阶段 95.93 57.8 92.4 62.8 本文方法 多阶段 100.76 58.8 94.5 64.4
如图7 、8 所示为本文方法在测试集中的车道线检测结果. 可知,利用本文方法可以有效地识别车道线的类别,在不同光照条件、不同天气状况、不同道路场景以及车道线磨损、遮挡复杂环境下均具有较好的检测性能. ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}