[1]
HOIEM D, EFROS A, HEBERT M Recovering surface layout from an image
[J]. International Journal of Computer Vision , 2007 , 75 (1 ): 151 - 172
DOI:10.1007/s11263-006-0031-y
[本文引用: 1]
[2]
FOUHEY D, GUPTA A, HEBERT M. Data-driven 3D primitives for single image understanding[C]// International Conference on Computer Vision . Sydney: IEEE, 2013: 3392-3399.
[本文引用: 2]
[3]
LADICK L, ZEISL B, POLLEFEYS M. Discriminatively trained dense surface normal estimation[C]// European Conference on Computer Vision. Cham: Springer, 2014: 468-484.
[本文引用: 1]
[4]
KUSUPAT U, CHENG S, CHEN R, et al. Normal assisted stereo depth estimation[C]// Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 2189-2199.
[本文引用: 1]
[5]
ZHANG S, XIE W, ZHANG G, et al. Robust stereo matching with surface normal prediction[C]// International Conference on Robotics and Automation . Singapore: IEEE, 2017: 2540-2547.
[本文引用: 1]
[6]
EIGEN D, FERGUS R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture[C]// International Conference on Computer Vision. Santiago: IEEE, 2015: 2650-2658.
[本文引用: 1]
[7]
KRIZHEVSKY A , SUTSKEVER I , HINTON G . Classification with deep convolutional neural networks[J]. Communications of the ACM . 2017, 60(6): 84-90.
[本文引用: 1]
[8]
BANSAL A, RUSSELL B, GUPTA A. Marr revisited: 2D-3D alignment via surface normal prediction[C]// Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 5965-5974.
[本文引用: 2]
[9]
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [C]// International Conference on Learning Representations . San Diego: ICRL, 2014.
[本文引用: 1]
[10]
冼楚华, 刘欣, 李桂清, 等 基于多尺度卷积网络的单幅图像的点法向估计
[J]. 华南理工大学学报:自然科学版 , 2018 , 46 (12 ): 7 - 15
URL
[本文引用: 4]
XIAN Chu-hua, LIU Xin, LI Gui-qing, et al Normal estimation from single monocular images based on multi-scale convolution network
[J]. Journal of South China University of Technology: Natural Science Edition , 2018 , 46 (12 ): 7 - 15
URL
[本文引用: 4]
[12]
SHEIHAMER E, LONG J, DARRELL T Fully convolutional networks for semantic segmentation
[J]. Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (4 ): 640 - 651
DOI:10.1109/TPAMI.2016.2572683
[本文引用: 2]
[13]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
[本文引用: 1]
[14]
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]// International Conference on Medical Image Computing and Computer-Assisted Intervention . Munich: Springer, 2015: 234-241.
[本文引用: 2]
[15]
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network[C]// Conference on Computer Vision And Pattern Recognition . Honolulu: IEEE, 2017: 6230-6239.
[本文引用: 2]
[16]
CHEN L, PAPANDREOU G, KOKKINOS I, et al DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
[J]. Transactions on Pattern Analysis and Machine Intelligence , 2018 , 40 (4 ): 834 - 848
DOI:10.1109/TPAMI.2017.2699184
[本文引用: 1]
[17]
WANG X, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]// Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7794-7803.
[本文引用: 2]
[18]
FU J , LIU J , TIAN H , et al. Dual attention network for scene segmentation[C]// Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 3141-3149.
[本文引用: 1]
[19]
CAO Y, XU J , LIN S, et al. GCNet: non-local networks meet squeeze-excitation networks and beyond[C]// International Conference on Computer Vision Workshops . Seoul: IEEE, 2019: 1971-1980.
[本文引用: 1]
[20]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7132-7141.
[本文引用: 1]
Recovering surface layout from an image
1
2007
... 传统方法根据场景的几何和纹理信息提取法线方向. Hoiem等[1 ] 利用颜色、纹理、透视图等线索,实现左右和上下法线方向的区域分割. Fouhey等[2 ] 从图像中提取矩形平面、消失点和直线等图元信息,通过三维模型得到场景法线. Ladick等[3 ] 利用预设的分割特征线索和超像素几何面,实现法线区域分割. 利用颜色纹理的法线提取方法须对目标物体材质、形状和粗糙度等物理基础信息进行推理,而利用透视图和图元信息的法线提取方式须获取场景的几何先验信息. 综上,传统的法线提取方法依赖场景目标的先验信息,较容易受到干扰,检测精度不高. ...
2
... 传统方法根据场景的几何和纹理信息提取法线方向. Hoiem等[1 ] 利用颜色、纹理、透视图等线索,实现左右和上下法线方向的区域分割. Fouhey等[2 ] 从图像中提取矩形平面、消失点和直线等图元信息,通过三维模型得到场景法线. Ladick等[3 ] 利用预设的分割特征线索和超像素几何面,实现法线区域分割. 利用颜色纹理的法线提取方法须对目标物体材质、形状和粗糙度等物理基础信息进行推理,而利用透视图和图元信息的法线提取方式须获取场景的几何先验信息. 综上,传统的法线提取方法依赖场景目标的先验信息,较容易受到干扰,检测精度不高. ...
... 法线评价标准参考文献[2 ],使用以下几个评价指标进行度量,余弦距离的平均角(mean)、中位角(median)、均方误差(root mean square error, RMSE)和余弦角度阈值误差P 1 、P 2 、P 3 ,其中P 1 、P 2 、P 3 分别为小于阈值11.25°、20.50°、30.00°的余弦角度占全部余弦角度的百分比.这些评价指标是使用余弦距离的角度取值进行评估,得到弧度制余弦值后还须使用反余弦函数得到对应角度. 其中,阈值百分比计算步骤如下:先计算法线检测图与标定图对应各列向量的余弦距离,再将其转化为角度,统计阈值内角度占所有角度取值的百分比. 这些指标中平均角、中位角和均方误差从不同方面表现检测结果与标定这2个分布的差异程度,取值越小表明网络性能越好;余弦角度阈值评估输出结果与标定不同阈值条件下的全图占比情况,取值越大,输出与标定相似程度越高. ...
1
... 传统方法根据场景的几何和纹理信息提取法线方向. Hoiem等[1 ] 利用颜色、纹理、透视图等线索,实现左右和上下法线方向的区域分割. Fouhey等[2 ] 从图像中提取矩形平面、消失点和直线等图元信息,通过三维模型得到场景法线. Ladick等[3 ] 利用预设的分割特征线索和超像素几何面,实现法线区域分割. 利用颜色纹理的法线提取方法须对目标物体材质、形状和粗糙度等物理基础信息进行推理,而利用透视图和图元信息的法线提取方式须获取场景的几何先验信息. 综上,传统的法线提取方法依赖场景目标的先验信息,较容易受到干扰,检测精度不高. ...
1
... 基于深度学习的法线检测方法包括2类. 一类是基于多目图像:Kusupat等[4 ] 使用多视角立体视觉的方式实现了法线检测,通过多幅不同视角的图像计算视差信息获取法线,摆脱了对场景先验知识的依赖. Zhang等[5 ] 通过最小二乘法求解连续视差图,得到曲面的法线信息. 另一类是基于单目图像:Eigen等[6 -7 ] 使用AlexNet模型构造深度神经网络,使用多任务训练方式进行室内场景的法线检测. Bansal等[8 -9 ] 提出的MarrNet使用VGG网络用局部法线信息优化整体法线提取,实现了室内场景的家具法线检测. 冼楚华等[10 ] 搭建DenseNet结合全卷积的网络以单目法线数据集作为参考,实现室内法向量预测. Han等[11 ] 引入基于自动编码器的条件随机场(conditional random fields, CRF)模块从超像素分割得到法线预测. 上述基于多目图像的方法对摄像设备的数目有更高的要求,单目图像的法线检测方法依赖于先验的深度信息,其采用的网络结构也较简单,检测精度还有提升的余地. ...
1
... 基于深度学习的法线检测方法包括2类. 一类是基于多目图像:Kusupat等[4 ] 使用多视角立体视觉的方式实现了法线检测,通过多幅不同视角的图像计算视差信息获取法线,摆脱了对场景先验知识的依赖. Zhang等[5 ] 通过最小二乘法求解连续视差图,得到曲面的法线信息. 另一类是基于单目图像:Eigen等[6 -7 ] 使用AlexNet模型构造深度神经网络,使用多任务训练方式进行室内场景的法线检测. Bansal等[8 -9 ] 提出的MarrNet使用VGG网络用局部法线信息优化整体法线提取,实现了室内场景的家具法线检测. 冼楚华等[10 ] 搭建DenseNet结合全卷积的网络以单目法线数据集作为参考,实现室内法向量预测. Han等[11 ] 引入基于自动编码器的条件随机场(conditional random fields, CRF)模块从超像素分割得到法线预测. 上述基于多目图像的方法对摄像设备的数目有更高的要求,单目图像的法线检测方法依赖于先验的深度信息,其采用的网络结构也较简单,检测精度还有提升的余地. ...
1
... 基于深度学习的法线检测方法包括2类. 一类是基于多目图像:Kusupat等[4 ] 使用多视角立体视觉的方式实现了法线检测,通过多幅不同视角的图像计算视差信息获取法线,摆脱了对场景先验知识的依赖. Zhang等[5 ] 通过最小二乘法求解连续视差图,得到曲面的法线信息. 另一类是基于单目图像:Eigen等[6 -7 ] 使用AlexNet模型构造深度神经网络,使用多任务训练方式进行室内场景的法线检测. Bansal等[8 -9 ] 提出的MarrNet使用VGG网络用局部法线信息优化整体法线提取,实现了室内场景的家具法线检测. 冼楚华等[10 ] 搭建DenseNet结合全卷积的网络以单目法线数据集作为参考,实现室内法向量预测. Han等[11 ] 引入基于自动编码器的条件随机场(conditional random fields, CRF)模块从超像素分割得到法线预测. 上述基于多目图像的方法对摄像设备的数目有更高的要求,单目图像的法线检测方法依赖于先验的深度信息,其采用的网络结构也较简单,检测精度还有提升的余地. ...
1
... 基于深度学习的法线检测方法包括2类. 一类是基于多目图像:Kusupat等[4 ] 使用多视角立体视觉的方式实现了法线检测,通过多幅不同视角的图像计算视差信息获取法线,摆脱了对场景先验知识的依赖. Zhang等[5 ] 通过最小二乘法求解连续视差图,得到曲面的法线信息. 另一类是基于单目图像:Eigen等[6 -7 ] 使用AlexNet模型构造深度神经网络,使用多任务训练方式进行室内场景的法线检测. Bansal等[8 -9 ] 提出的MarrNet使用VGG网络用局部法线信息优化整体法线提取,实现了室内场景的家具法线检测. 冼楚华等[10 ] 搭建DenseNet结合全卷积的网络以单目法线数据集作为参考,实现室内法向量预测. Han等[11 ] 引入基于自动编码器的条件随机场(conditional random fields, CRF)模块从超像素分割得到法线预测. 上述基于多目图像的方法对摄像设备的数目有更高的要求,单目图像的法线检测方法依赖于先验的深度信息,其采用的网络结构也较简单,检测精度还有提升的余地. ...
2
... 基于深度学习的法线检测方法包括2类. 一类是基于多目图像:Kusupat等[4 ] 使用多视角立体视觉的方式实现了法线检测,通过多幅不同视角的图像计算视差信息获取法线,摆脱了对场景先验知识的依赖. Zhang等[5 ] 通过最小二乘法求解连续视差图,得到曲面的法线信息. 另一类是基于单目图像:Eigen等[6 -7 ] 使用AlexNet模型构造深度神经网络,使用多任务训练方式进行室内场景的法线检测. Bansal等[8 -9 ] 提出的MarrNet使用VGG网络用局部法线信息优化整体法线提取,实现了室内场景的家具法线检测. 冼楚华等[10 ] 搭建DenseNet结合全卷积的网络以单目法线数据集作为参考,实现室内法向量预测. Han等[11 ] 引入基于自动编码器的条件随机场(conditional random fields, CRF)模块从超像素分割得到法线预测. 上述基于多目图像的方法对摄像设备的数目有更高的要求,单目图像的法线检测方法依赖于先验的深度信息,其采用的网络结构也较简单,检测精度还有提升的余地. ...
... Test results comparison of different normal detection network
Tab.1 网络 Mean Median RMSE/% P 1 /% P 2 /% P 3 /% MarrNet[8 ] 35.18 32.16 38.64 18.38 42.74 61.51 文献[10 ]方法 28.95 25.43 34.35 35.37 59.26 82.89 本研究算法 25.26 22.57 29.81 41.75 72.68 91.27
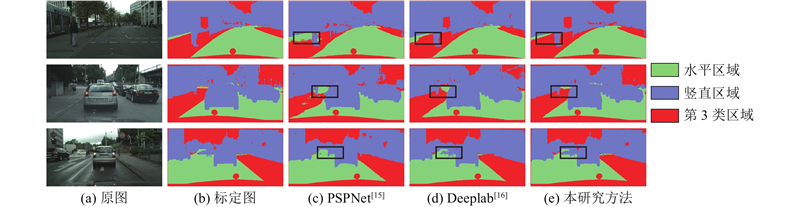
3.2. 分割网络对比实验 分割网络对比实验在Cityscape数据集上进行,将测试集图片输入不同分割网络得到的输出结果进行对比. 着重选取人行道与路面分割错误以及车辆分割错误的例子展示,这些区域的识别错误将带来极大的安全隐患. 不同分割网络部分实验结果对比如图7 所示. 图中,黑框标记分割出现较大差异的区域,(a)列为输入的测试原图像,(b)列为对应的标定图片,(c)~(e)列分别为对应网络的输出结果.由PSPNet输出结果可以看出,多尺度池化导致棋盘效应较严重,部分人行道区域被识别为路面,且远处的车辆没有被正确识别,而是被划分为路面区域. 与PSPNet相比,Deeplab分割结果较好,其采用的空洞卷积避免了池化操作的特征信息丢失,减少了孔洞的产生,可以看到,人行道识别错误区域面积有所减小,远处车辆识别率有所提高. 本研究所提方法加强了上下文信息的提取,减少了纹理信息对分割的干扰,在特征提取过程中引入边缘信息,人行道与路面的分割表现较出色,与标定图片区域基本吻合,且正确将远处车辆识别为障碍物区域,网络在小目标的分割准确度有所提高. ...
1
... 基于深度学习的法线检测方法包括2类. 一类是基于多目图像:Kusupat等[4 ] 使用多视角立体视觉的方式实现了法线检测,通过多幅不同视角的图像计算视差信息获取法线,摆脱了对场景先验知识的依赖. Zhang等[5 ] 通过最小二乘法求解连续视差图,得到曲面的法线信息. 另一类是基于单目图像:Eigen等[6 -7 ] 使用AlexNet模型构造深度神经网络,使用多任务训练方式进行室内场景的法线检测. Bansal等[8 -9 ] 提出的MarrNet使用VGG网络用局部法线信息优化整体法线提取,实现了室内场景的家具法线检测. 冼楚华等[10 ] 搭建DenseNet结合全卷积的网络以单目法线数据集作为参考,实现室内法向量预测. Han等[11 ] 引入基于自动编码器的条件随机场(conditional random fields, CRF)模块从超像素分割得到法线预测. 上述基于多目图像的方法对摄像设备的数目有更高的要求,单目图像的法线检测方法依赖于先验的深度信息,其采用的网络结构也较简单,检测精度还有提升的余地. ...
基于多尺度卷积网络的单幅图像的点法向估计
4
2018
... 基于深度学习的法线检测方法包括2类. 一类是基于多目图像:Kusupat等[4 ] 使用多视角立体视觉的方式实现了法线检测,通过多幅不同视角的图像计算视差信息获取法线,摆脱了对场景先验知识的依赖. Zhang等[5 ] 通过最小二乘法求解连续视差图,得到曲面的法线信息. 另一类是基于单目图像:Eigen等[6 -7 ] 使用AlexNet模型构造深度神经网络,使用多任务训练方式进行室内场景的法线检测. Bansal等[8 -9 ] 提出的MarrNet使用VGG网络用局部法线信息优化整体法线提取,实现了室内场景的家具法线检测. 冼楚华等[10 ] 搭建DenseNet结合全卷积的网络以单目法线数据集作为参考,实现室内法向量预测. Han等[11 ] 引入基于自动编码器的条件随机场(conditional random fields, CRF)模块从超像素分割得到法线预测. 上述基于多目图像的方法对摄像设备的数目有更高的要求,单目图像的法线检测方法依赖于先验的深度信息,其采用的网络结构也较简单,检测精度还有提升的余地. ...
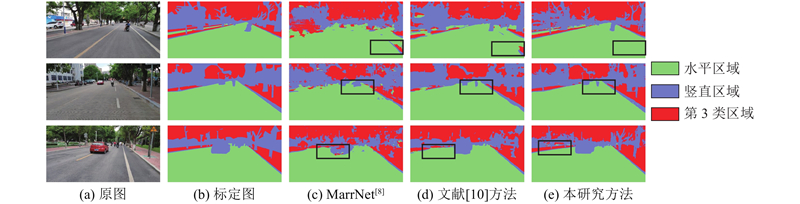
... 法线网络对比实验在自建数据集实现,将247张测试集数据作为测试输入样本,送进不同的法线检测网络对比输出结果. 如图6 (a)、(b)所示分别为道路场景原图和法线区域标定图片,如图6 (c)~(e)所示分别为对应网络区域检测结果. 图中,绿色表示道路的水平区域,紫色表示树干、车辆和建筑等竖直区域,红色表示第3类区域,黑框标记分割出现较大差异的区域. 由于网络层数较浅,MarrNet的法线区域分割相对粗糙,存在将车道线误识别为其他区域、障碍物识别不够准确和交界区域分割较零碎等问题. 文献[10 ]的网络把车辆障碍物的区域分割得较为准确,不过有少量车道线分割错误问题,而且人行道和路缘石区域的分割准确率不高. 本研究方法在特征提取方面进行优化,在人行道和路缘石的分割上的表现较优异,车辆区域分割完整且边缘较光滑,不过对于路旁的竖直区域仍存在部分错误分割. ...
... 如表1 所示,实验数据为输入多张测试集图片分别得到的输出结果的整体平均值.本研究提出的法线区域分割网络与过往图像到法线的端对端网络相比,特征提取能力有所增强,各项指标精度都有所提高,与文献[10 ]提出的网络相比,RMSE提升了4.54%,余弦距离在11.25°、22.50°、30.00°阈值内的百分占比分别提升6.38%、13.42%、8.38%. ...
... Test results comparison of different normal detection network
Tab.1 网络 Mean Median RMSE/% P 1 /% P 2 /% P 3 /% MarrNet[8 ] 35.18 32.16 38.64 18.38 42.74 61.51 文献[10 ]方法 28.95 25.43 34.35 35.37 59.26 82.89 本研究算法 25.26 22.57 29.81 41.75 72.68 91.27
3.2. 分割网络对比实验 分割网络对比实验在Cityscape数据集上进行,将测试集图片输入不同分割网络得到的输出结果进行对比. 着重选取人行道与路面分割错误以及车辆分割错误的例子展示,这些区域的识别错误将带来极大的安全隐患. 不同分割网络部分实验结果对比如图7 所示. 图中,黑框标记分割出现较大差异的区域,(a)列为输入的测试原图像,(b)列为对应的标定图片,(c)~(e)列分别为对应网络的输出结果.由PSPNet输出结果可以看出,多尺度池化导致棋盘效应较严重,部分人行道区域被识别为路面,且远处的车辆没有被正确识别,而是被划分为路面区域. 与PSPNet相比,Deeplab分割结果较好,其采用的空洞卷积避免了池化操作的特征信息丢失,减少了孔洞的产生,可以看到,人行道识别错误区域面积有所减小,远处车辆识别率有所提高. 本研究所提方法加强了上下文信息的提取,减少了纹理信息对分割的干扰,在特征提取过程中引入边缘信息,人行道与路面的分割表现较出色,与标定图片区域基本吻合,且正确将远处车辆识别为障碍物区域,网络在小目标的分割准确度有所提高. ...
基于多尺度卷积网络的单幅图像的点法向估计
4
2018
... 基于深度学习的法线检测方法包括2类. 一类是基于多目图像:Kusupat等[4 ] 使用多视角立体视觉的方式实现了法线检测,通过多幅不同视角的图像计算视差信息获取法线,摆脱了对场景先验知识的依赖. Zhang等[5 ] 通过最小二乘法求解连续视差图,得到曲面的法线信息. 另一类是基于单目图像:Eigen等[6 -7 ] 使用AlexNet模型构造深度神经网络,使用多任务训练方式进行室内场景的法线检测. Bansal等[8 -9 ] 提出的MarrNet使用VGG网络用局部法线信息优化整体法线提取,实现了室内场景的家具法线检测. 冼楚华等[10 ] 搭建DenseNet结合全卷积的网络以单目法线数据集作为参考,实现室内法向量预测. Han等[11 ] 引入基于自动编码器的条件随机场(conditional random fields, CRF)模块从超像素分割得到法线预测. 上述基于多目图像的方法对摄像设备的数目有更高的要求,单目图像的法线检测方法依赖于先验的深度信息,其采用的网络结构也较简单,检测精度还有提升的余地. ...
... 法线网络对比实验在自建数据集实现,将247张测试集数据作为测试输入样本,送进不同的法线检测网络对比输出结果. 如图6 (a)、(b)所示分别为道路场景原图和法线区域标定图片,如图6 (c)~(e)所示分别为对应网络区域检测结果. 图中,绿色表示道路的水平区域,紫色表示树干、车辆和建筑等竖直区域,红色表示第3类区域,黑框标记分割出现较大差异的区域. 由于网络层数较浅,MarrNet的法线区域分割相对粗糙,存在将车道线误识别为其他区域、障碍物识别不够准确和交界区域分割较零碎等问题. 文献[10 ]的网络把车辆障碍物的区域分割得较为准确,不过有少量车道线分割错误问题,而且人行道和路缘石区域的分割准确率不高. 本研究方法在特征提取方面进行优化,在人行道和路缘石的分割上的表现较优异,车辆区域分割完整且边缘较光滑,不过对于路旁的竖直区域仍存在部分错误分割. ...
... 如表1 所示,实验数据为输入多张测试集图片分别得到的输出结果的整体平均值.本研究提出的法线区域分割网络与过往图像到法线的端对端网络相比,特征提取能力有所增强,各项指标精度都有所提高,与文献[10 ]提出的网络相比,RMSE提升了4.54%,余弦距离在11.25°、22.50°、30.00°阈值内的百分占比分别提升6.38%、13.42%、8.38%. ...
... Test results comparison of different normal detection network
Tab.1 网络 Mean Median RMSE/% P 1 /% P 2 /% P 3 /% MarrNet[8 ] 35.18 32.16 38.64 18.38 42.74 61.51 文献[10 ]方法 28.95 25.43 34.35 35.37 59.26 82.89 本研究算法 25.26 22.57 29.81 41.75 72.68 91.27
3.2. 分割网络对比实验 分割网络对比实验在Cityscape数据集上进行,将测试集图片输入不同分割网络得到的输出结果进行对比. 着重选取人行道与路面分割错误以及车辆分割错误的例子展示,这些区域的识别错误将带来极大的安全隐患. 不同分割网络部分实验结果对比如图7 所示. 图中,黑框标记分割出现较大差异的区域,(a)列为输入的测试原图像,(b)列为对应的标定图片,(c)~(e)列分别为对应网络的输出结果.由PSPNet输出结果可以看出,多尺度池化导致棋盘效应较严重,部分人行道区域被识别为路面,且远处的车辆没有被正确识别,而是被划分为路面区域. 与PSPNet相比,Deeplab分割结果较好,其采用的空洞卷积避免了池化操作的特征信息丢失,减少了孔洞的产生,可以看到,人行道识别错误区域面积有所减小,远处车辆识别率有所提高. 本研究所提方法加强了上下文信息的提取,减少了纹理信息对分割的干扰,在特征提取过程中引入边缘信息,人行道与路面的分割表现较出色,与标定图片区域基本吻合,且正确将远处车辆识别为障碍物区域,网络在小目标的分割准确度有所提高. ...
Monocular depth estimation with guidance of surface normal map
1
2018
... 基于深度学习的法线检测方法包括2类. 一类是基于多目图像:Kusupat等[4 ] 使用多视角立体视觉的方式实现了法线检测,通过多幅不同视角的图像计算视差信息获取法线,摆脱了对场景先验知识的依赖. Zhang等[5 ] 通过最小二乘法求解连续视差图,得到曲面的法线信息. 另一类是基于单目图像:Eigen等[6 -7 ] 使用AlexNet模型构造深度神经网络,使用多任务训练方式进行室内场景的法线检测. Bansal等[8 -9 ] 提出的MarrNet使用VGG网络用局部法线信息优化整体法线提取,实现了室内场景的家具法线检测. 冼楚华等[10 ] 搭建DenseNet结合全卷积的网络以单目法线数据集作为参考,实现室内法向量预测. Han等[11 ] 引入基于自动编码器的条件随机场(conditional random fields, CRF)模块从超像素分割得到法线预测. 上述基于多目图像的方法对摄像设备的数目有更高的要求,单目图像的法线检测方法依赖于先验的深度信息,其采用的网络结构也较简单,检测精度还有提升的余地. ...
Fully convolutional networks for semantic segmentation
2
2017
... 主流的语义分割方法包括:全卷积网络(fully convolutional networks, FCN)、UNet和金字塔场景解析网络(pyramid scene parsing network, PSPNet)等. Shelhamer等[12 ] 提出的FCN将全连接层替换为卷积层,改善了只能接受特定大小图像的问题. He等[13 ] 将网络的卷积层修改为残差块,使用跨层连接提高对深层特征的提取,达到了优化梯度传播方式的目标. UNet在FCN网络结构基础上引入跳跃连接,将编码层的低阶特征与解码层融合,对特征融合进行优化[14 ] . Zhao等[15 ] 提出的PSPNet使用不同尺寸的池化层提取特征信息,并将这些特征信息拼接再进行特征提取,增强了局部上下文特征信息的提取. Chen等[16 ] 使用空洞金字塔池化构建Deeplab网络进行空间上下文的特征提取,改善了传统池化带来的信息损失. Wang等[17 ] 首次提出非局部(Non-local)算法,使用矩阵乘法操作建立像素间的映射关系,从全局性联系上下文信息. Fu等[18 ] 在Non-local算法的基础上增加通道注意力机制,使用双路上下文提取模块,在通道与和空间与分别实现全局特征信息的提取,拓展了上下文算法的提取途径. Cao等[19 -20 ] 结合SENet和Non-local算法优化了通道加权方式. ...
... Test results of different segmentation networks
Tab.2 网络 IoU/% MPA/% FCN[12 ] 63.43 75.17 UNet[14 ] 71.25 80.36 PSPnet[15 ] 70.82 80.04 Deeplab[17 ] 71.66 82.59 本研究算法 73.76 85.33
以上实验结果验证了本研究方法的有效性,网络结合上下文和边缘信息进行特征提取增强了网络在位置间关联性的敏感程度,使检测区域边缘更为完整,对纹理相似的区域有更强的分辨能力,提高了分割准确度. ...
1
... 主流的语义分割方法包括:全卷积网络(fully convolutional networks, FCN)、UNet和金字塔场景解析网络(pyramid scene parsing network, PSPNet)等. Shelhamer等[12 ] 提出的FCN将全连接层替换为卷积层,改善了只能接受特定大小图像的问题. He等[13 ] 将网络的卷积层修改为残差块,使用跨层连接提高对深层特征的提取,达到了优化梯度传播方式的目标. UNet在FCN网络结构基础上引入跳跃连接,将编码层的低阶特征与解码层融合,对特征融合进行优化[14 ] . Zhao等[15 ] 提出的PSPNet使用不同尺寸的池化层提取特征信息,并将这些特征信息拼接再进行特征提取,增强了局部上下文特征信息的提取. Chen等[16 ] 使用空洞金字塔池化构建Deeplab网络进行空间上下文的特征提取,改善了传统池化带来的信息损失. Wang等[17 ] 首次提出非局部(Non-local)算法,使用矩阵乘法操作建立像素间的映射关系,从全局性联系上下文信息. Fu等[18 ] 在Non-local算法的基础上增加通道注意力机制,使用双路上下文提取模块,在通道与和空间与分别实现全局特征信息的提取,拓展了上下文算法的提取途径. Cao等[19 -20 ] 结合SENet和Non-local算法优化了通道加权方式. ...
2
... 主流的语义分割方法包括:全卷积网络(fully convolutional networks, FCN)、UNet和金字塔场景解析网络(pyramid scene parsing network, PSPNet)等. Shelhamer等[12 ] 提出的FCN将全连接层替换为卷积层,改善了只能接受特定大小图像的问题. He等[13 ] 将网络的卷积层修改为残差块,使用跨层连接提高对深层特征的提取,达到了优化梯度传播方式的目标. UNet在FCN网络结构基础上引入跳跃连接,将编码层的低阶特征与解码层融合,对特征融合进行优化[14 ] . Zhao等[15 ] 提出的PSPNet使用不同尺寸的池化层提取特征信息,并将这些特征信息拼接再进行特征提取,增强了局部上下文特征信息的提取. Chen等[16 ] 使用空洞金字塔池化构建Deeplab网络进行空间上下文的特征提取,改善了传统池化带来的信息损失. Wang等[17 ] 首次提出非局部(Non-local)算法,使用矩阵乘法操作建立像素间的映射关系,从全局性联系上下文信息. Fu等[18 ] 在Non-local算法的基础上增加通道注意力机制,使用双路上下文提取模块,在通道与和空间与分别实现全局特征信息的提取,拓展了上下文算法的提取途径. Cao等[19 -20 ] 结合SENet和Non-local算法优化了通道加权方式. ...
... Test results of different segmentation networks
Tab.2 网络 IoU/% MPA/% FCN[12 ] 63.43 75.17 UNet[14 ] 71.25 80.36 PSPnet[15 ] 70.82 80.04 Deeplab[17 ] 71.66 82.59 本研究算法 73.76 85.33
以上实验结果验证了本研究方法的有效性,网络结合上下文和边缘信息进行特征提取增强了网络在位置间关联性的敏感程度,使检测区域边缘更为完整,对纹理相似的区域有更强的分辨能力,提高了分割准确度. ...
2
... 主流的语义分割方法包括:全卷积网络(fully convolutional networks, FCN)、UNet和金字塔场景解析网络(pyramid scene parsing network, PSPNet)等. Shelhamer等[12 ] 提出的FCN将全连接层替换为卷积层,改善了只能接受特定大小图像的问题. He等[13 ] 将网络的卷积层修改为残差块,使用跨层连接提高对深层特征的提取,达到了优化梯度传播方式的目标. UNet在FCN网络结构基础上引入跳跃连接,将编码层的低阶特征与解码层融合,对特征融合进行优化[14 ] . Zhao等[15 ] 提出的PSPNet使用不同尺寸的池化层提取特征信息,并将这些特征信息拼接再进行特征提取,增强了局部上下文特征信息的提取. Chen等[16 ] 使用空洞金字塔池化构建Deeplab网络进行空间上下文的特征提取,改善了传统池化带来的信息损失. Wang等[17 ] 首次提出非局部(Non-local)算法,使用矩阵乘法操作建立像素间的映射关系,从全局性联系上下文信息. Fu等[18 ] 在Non-local算法的基础上增加通道注意力机制,使用双路上下文提取模块,在通道与和空间与分别实现全局特征信息的提取,拓展了上下文算法的提取途径. Cao等[19 -20 ] 结合SENet和Non-local算法优化了通道加权方式. ...
... Test results of different segmentation networks
Tab.2 网络 IoU/% MPA/% FCN[12 ] 63.43 75.17 UNet[14 ] 71.25 80.36 PSPnet[15 ] 70.82 80.04 Deeplab[17 ] 71.66 82.59 本研究算法 73.76 85.33
以上实验结果验证了本研究方法的有效性,网络结合上下文和边缘信息进行特征提取增强了网络在位置间关联性的敏感程度,使检测区域边缘更为完整,对纹理相似的区域有更强的分辨能力,提高了分割准确度. ...
DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
1
2018
... 主流的语义分割方法包括:全卷积网络(fully convolutional networks, FCN)、UNet和金字塔场景解析网络(pyramid scene parsing network, PSPNet)等. Shelhamer等[12 ] 提出的FCN将全连接层替换为卷积层,改善了只能接受特定大小图像的问题. He等[13 ] 将网络的卷积层修改为残差块,使用跨层连接提高对深层特征的提取,达到了优化梯度传播方式的目标. UNet在FCN网络结构基础上引入跳跃连接,将编码层的低阶特征与解码层融合,对特征融合进行优化[14 ] . Zhao等[15 ] 提出的PSPNet使用不同尺寸的池化层提取特征信息,并将这些特征信息拼接再进行特征提取,增强了局部上下文特征信息的提取. Chen等[16 ] 使用空洞金字塔池化构建Deeplab网络进行空间上下文的特征提取,改善了传统池化带来的信息损失. Wang等[17 ] 首次提出非局部(Non-local)算法,使用矩阵乘法操作建立像素间的映射关系,从全局性联系上下文信息. Fu等[18 ] 在Non-local算法的基础上增加通道注意力机制,使用双路上下文提取模块,在通道与和空间与分别实现全局特征信息的提取,拓展了上下文算法的提取途径. Cao等[19 -20 ] 结合SENet和Non-local算法优化了通道加权方式. ...
2
... 主流的语义分割方法包括:全卷积网络(fully convolutional networks, FCN)、UNet和金字塔场景解析网络(pyramid scene parsing network, PSPNet)等. Shelhamer等[12 ] 提出的FCN将全连接层替换为卷积层,改善了只能接受特定大小图像的问题. He等[13 ] 将网络的卷积层修改为残差块,使用跨层连接提高对深层特征的提取,达到了优化梯度传播方式的目标. UNet在FCN网络结构基础上引入跳跃连接,将编码层的低阶特征与解码层融合,对特征融合进行优化[14 ] . Zhao等[15 ] 提出的PSPNet使用不同尺寸的池化层提取特征信息,并将这些特征信息拼接再进行特征提取,增强了局部上下文特征信息的提取. Chen等[16 ] 使用空洞金字塔池化构建Deeplab网络进行空间上下文的特征提取,改善了传统池化带来的信息损失. Wang等[17 ] 首次提出非局部(Non-local)算法,使用矩阵乘法操作建立像素间的映射关系,从全局性联系上下文信息. Fu等[18 ] 在Non-local算法的基础上增加通道注意力机制,使用双路上下文提取模块,在通道与和空间与分别实现全局特征信息的提取,拓展了上下文算法的提取途径. Cao等[19 -20 ] 结合SENet和Non-local算法优化了通道加权方式. ...
... Test results of different segmentation networks
Tab.2 网络 IoU/% MPA/% FCN[12 ] 63.43 75.17 UNet[14 ] 71.25 80.36 PSPnet[15 ] 70.82 80.04 Deeplab[17 ] 71.66 82.59 本研究算法 73.76 85.33
以上实验结果验证了本研究方法的有效性,网络结合上下文和边缘信息进行特征提取增强了网络在位置间关联性的敏感程度,使检测区域边缘更为完整,对纹理相似的区域有更强的分辨能力,提高了分割准确度. ...
1
... 主流的语义分割方法包括:全卷积网络(fully convolutional networks, FCN)、UNet和金字塔场景解析网络(pyramid scene parsing network, PSPNet)等. Shelhamer等[12 ] 提出的FCN将全连接层替换为卷积层,改善了只能接受特定大小图像的问题. He等[13 ] 将网络的卷积层修改为残差块,使用跨层连接提高对深层特征的提取,达到了优化梯度传播方式的目标. UNet在FCN网络结构基础上引入跳跃连接,将编码层的低阶特征与解码层融合,对特征融合进行优化[14 ] . Zhao等[15 ] 提出的PSPNet使用不同尺寸的池化层提取特征信息,并将这些特征信息拼接再进行特征提取,增强了局部上下文特征信息的提取. Chen等[16 ] 使用空洞金字塔池化构建Deeplab网络进行空间上下文的特征提取,改善了传统池化带来的信息损失. Wang等[17 ] 首次提出非局部(Non-local)算法,使用矩阵乘法操作建立像素间的映射关系,从全局性联系上下文信息. Fu等[18 ] 在Non-local算法的基础上增加通道注意力机制,使用双路上下文提取模块,在通道与和空间与分别实现全局特征信息的提取,拓展了上下文算法的提取途径. Cao等[19 -20 ] 结合SENet和Non-local算法优化了通道加权方式. ...
1
... 主流的语义分割方法包括:全卷积网络(fully convolutional networks, FCN)、UNet和金字塔场景解析网络(pyramid scene parsing network, PSPNet)等. Shelhamer等[12 ] 提出的FCN将全连接层替换为卷积层,改善了只能接受特定大小图像的问题. He等[13 ] 将网络的卷积层修改为残差块,使用跨层连接提高对深层特征的提取,达到了优化梯度传播方式的目标. UNet在FCN网络结构基础上引入跳跃连接,将编码层的低阶特征与解码层融合,对特征融合进行优化[14 ] . Zhao等[15 ] 提出的PSPNet使用不同尺寸的池化层提取特征信息,并将这些特征信息拼接再进行特征提取,增强了局部上下文特征信息的提取. Chen等[16 ] 使用空洞金字塔池化构建Deeplab网络进行空间上下文的特征提取,改善了传统池化带来的信息损失. Wang等[17 ] 首次提出非局部(Non-local)算法,使用矩阵乘法操作建立像素间的映射关系,从全局性联系上下文信息. Fu等[18 ] 在Non-local算法的基础上增加通道注意力机制,使用双路上下文提取模块,在通道与和空间与分别实现全局特征信息的提取,拓展了上下文算法的提取途径. Cao等[19 -20 ] 结合SENet和Non-local算法优化了通道加权方式. ...
1
... 主流的语义分割方法包括:全卷积网络(fully convolutional networks, FCN)、UNet和金字塔场景解析网络(pyramid scene parsing network, PSPNet)等. Shelhamer等[12 ] 提出的FCN将全连接层替换为卷积层,改善了只能接受特定大小图像的问题. He等[13 ] 将网络的卷积层修改为残差块,使用跨层连接提高对深层特征的提取,达到了优化梯度传播方式的目标. UNet在FCN网络结构基础上引入跳跃连接,将编码层的低阶特征与解码层融合,对特征融合进行优化[14 ] . Zhao等[15 ] 提出的PSPNet使用不同尺寸的池化层提取特征信息,并将这些特征信息拼接再进行特征提取,增强了局部上下文特征信息的提取. Chen等[16 ] 使用空洞金字塔池化构建Deeplab网络进行空间上下文的特征提取,改善了传统池化带来的信息损失. Wang等[17 ] 首次提出非局部(Non-local)算法,使用矩阵乘法操作建立像素间的映射关系,从全局性联系上下文信息. Fu等[18 ] 在Non-local算法的基础上增加通道注意力机制,使用双路上下文提取模块,在通道与和空间与分别实现全局特征信息的提取,拓展了上下文算法的提取途径. Cao等[19 -20 ] 结合SENet和Non-local算法优化了通道加权方式. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}