| 计算机技术 |
|

|
|
|
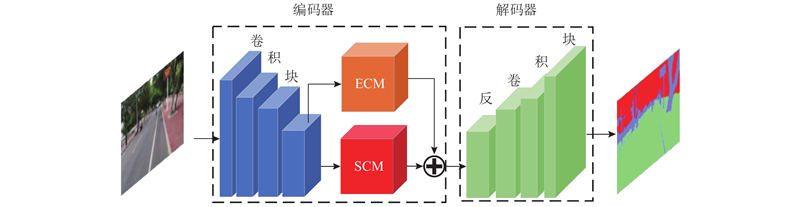
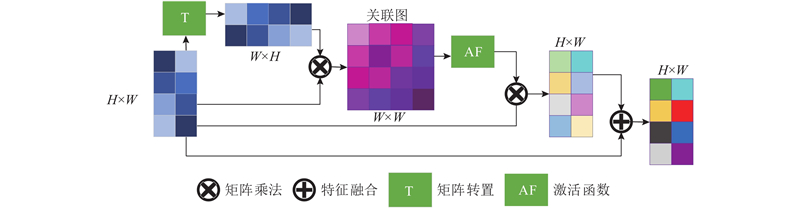
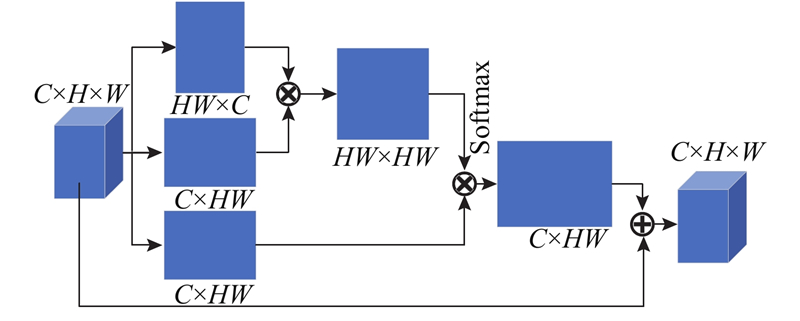
| 结合空间上下文算法的道路场景法线区域分割 |
陈雪云( ),姚渠*(),丁启辰,贝学宇,黄小巧,金鑫 ),姚渠*(),丁启辰,贝学宇,黄小巧,金鑫 |
| 广西大学 电气工程学院, 广西 南宁 530000 |
|
| Normal region segmentation of road scene based on spatial context algorithm |
| Xue-yun CHEN(),Qu YAO*(),Qi-chen DING,Xue-yu BEI,Xiao-qiao HUANG,Xin JIN |
| School of Electrical Engineering, Guangxi University, Nanning 530000, China |
引用本文:
陈雪云,姚渠,丁启辰,贝学宇,黄小巧,金鑫. 结合空间上下文算法的道路场景法线区域分割[J]. 浙江大学学报(工学版), 2021, 55(11): 2013-2021.
Xue-yun CHEN,Qu YAO,Qi-chen DING,Xue-yu BEI,Xiao-qiao HUANG,Xin JIN. Normal region segmentation of road scene based on spatial context algorithm. Journal of ZheJiang University (Engineering Science), 2021, 55(11): 2013-2021.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2021.11.001
或
https://www.zjujournals.com/eng/CN/Y2021/V55/I11/2013
|
| 1 |
HOIEM D, EFROS A, HEBERT M Recovering surface layout from an image[J]. International Journal of Computer Vision, 2007, 75 (1): 151- 172
doi: 10.1007/s11263-006-0031-y
|
| 2 |
FOUHEY D, GUPTA A, HEBERT M. Data-driven 3D primitives for single image understanding[C]// International Conference on Computer Vision. Sydney: IEEE, 2013: 3392-3399.
|
| 3 |
LADICK L, ZEISL B, POLLEFEYS M. Discriminatively trained dense surface normal estimation[C]// European Conference on Computer Vision. Cham: Springer, 2014: 468-484.
|
| 4 |
KUSUPAT U, CHENG S, CHEN R, et al. Normal assisted stereo depth estimation[C]// Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 2189-2199.
|
| 5 |
ZHANG S, XIE W, ZHANG G, et al. Robust stereo matching with surface normal prediction[C]// International Conference on Robotics and Automation. Singapore: IEEE, 2017: 2540-2547.
|
| 6 |
EIGEN D, FERGUS R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture[C]// International Conference on Computer Vision. Santiago: IEEE, 2015: 2650-2658.
|
| 7 |
KRIZHEVSKY A , SUTSKEVER I , HINTON G . Classification with deep convolutional neural networks[J]. Communications of the ACM. 2017, 60(6): 84-90.
|
| 8 |
BANSAL A, RUSSELL B, GUPTA A. Marr revisited: 2D-3D alignment via surface normal prediction[C]// Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 5965-5974.
|
| 9 |
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [C]// International Conference on Learning Representations. San Diego: ICRL, 2014.
|
| 10 |
冼楚华, 刘欣, 李桂清, 等 基于多尺度卷积网络的单幅图像的点法向估计[J]. 华南理工大学学报:自然科学版, 2018, 46 (12): 7- 15
XIAN Chu-hua, LIU Xin, LI Gui-qing, et al Normal estimation from single monocular images based on multi-scale convolution network[J]. Journal of South China University of Technology: Natural Science Edition, 2018, 46 (12): 7- 15
|
| 11 |
HAN Y, ZHANG S, ZHANG Y, et al Monocular depth estimation with guidance of surface normal map[J]. Neurocomputing, 2018, 280: 86- 100
doi: 10.1016/j.neucom.2017.08.074
|
| 12 |
SHEIHAMER E, LONG J, DARRELL T Fully convolutional networks for semantic segmentation[J]. Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (4): 640- 651
doi: 10.1109/TPAMI.2016.2572683
|
| 13 |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
| 14 |
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]// International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich: Springer, 2015: 234-241.
|
| 15 |
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network[C]// Conference on Computer Vision And Pattern Recognition. Honolulu: IEEE, 2017: 6230-6239.
|
| 16 |
CHEN L, PAPANDREOU G, KOKKINOS I, et al DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. Transactions on Pattern Analysis and Machine Intelligence, 2018, 40 (4): 834- 848
doi: 10.1109/TPAMI.2017.2699184
|
| 17 |
WANG X, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]// Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7794-7803.
|
| 18 |
FU J , LIU J , TIAN H , et al. Dual attention network for scene segmentation[C]// Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 3141-3149.
|
| 19 |
CAO Y, XU J , LIN S, et al. GCNet: non-local networks meet squeeze-excitation networks and beyond[C]// International Conference on Computer Vision Workshops. Seoul: IEEE, 2019: 1971-1980.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|