|
|
|
| Lightweight micro-expression recognition based on optical flow and convolutional vision Transformer |
Kaiwei XU1,2( ),Hafiz KHIZER BIN TALIB1,2,Yanlong CAO1,2,*(),Yuanping XU3,Zhijie XU4,Jingchun SONG5 ),Hafiz KHIZER BIN TALIB1,2,Yanlong CAO1,2,*(),Yuanping XU3,Zhijie XU4,Jingchun SONG5 |
1. School of Mechanical Engineering, Zhejiang University, Hangzhou 310058, China
2. State Key Laboratory of Fluid Power and Mechatronic Systems, Zhejiang University, Hangzhou 310058, China
3. School of Software Engineering, Chengdu University of Information Technology, Chengdu 610225, China
4. School of Advanced Technology, Xi’an Jiaotong-Liverpool University, Suzhou 215123, China
5. Department of Critical Care Medicine, 908th Hospital of Joint Logistic Support Force of Chinese PLA, Nanchang 330002, China |
|
|
|
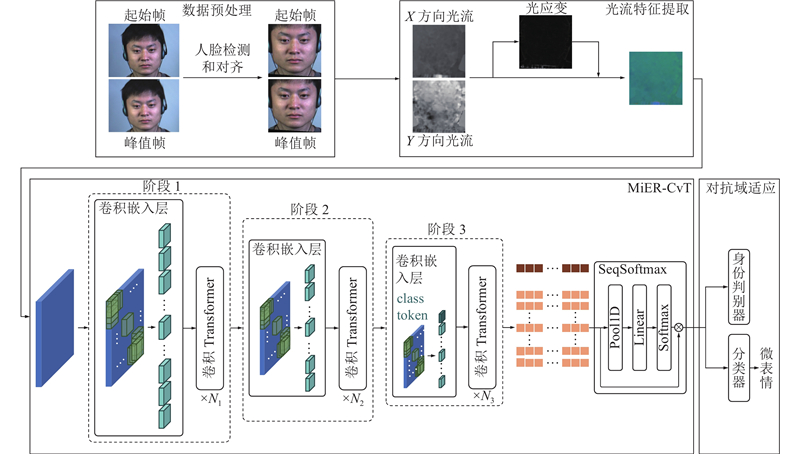
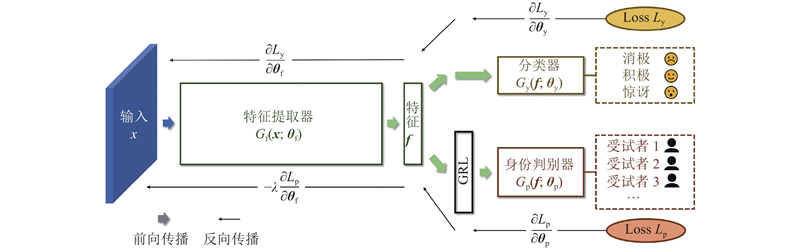
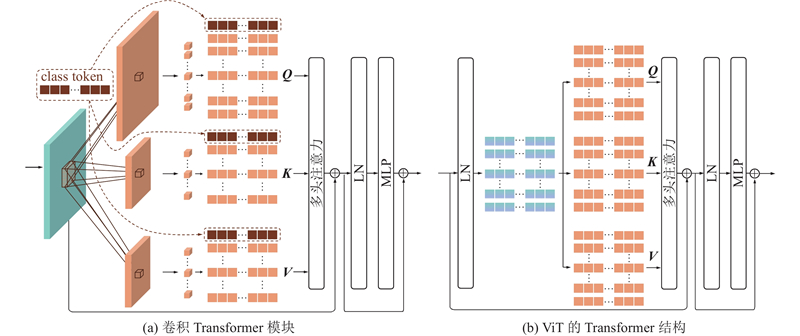
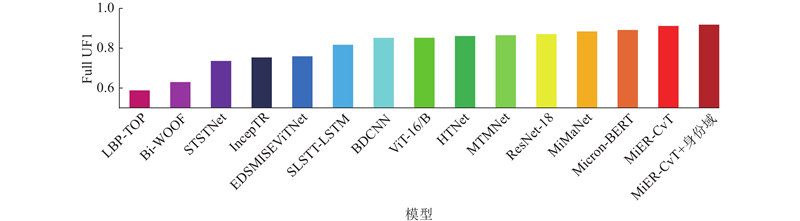
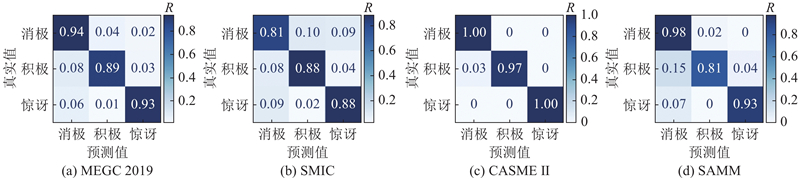
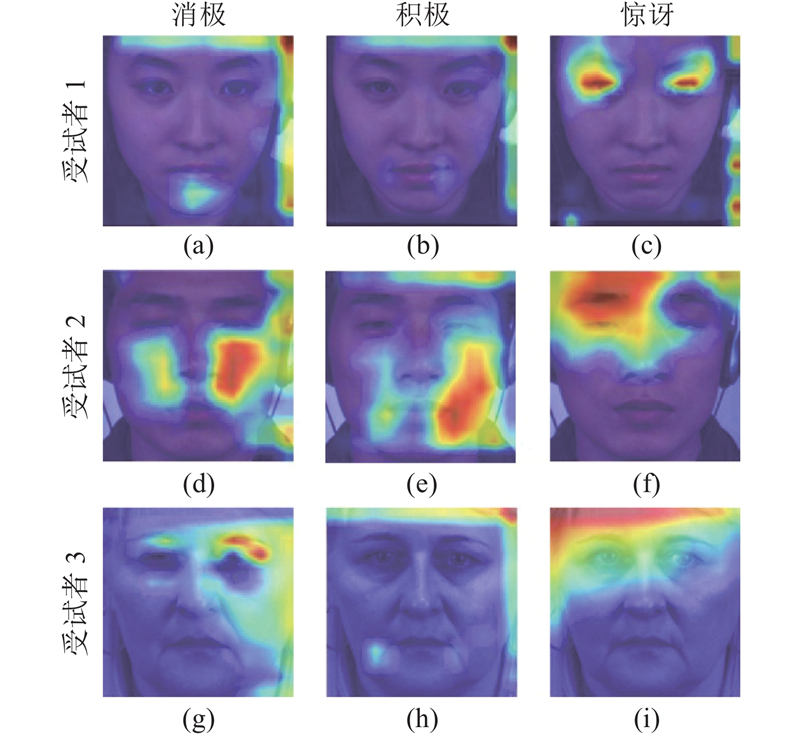
Abstract A lightweight micro-expression recognition method based on optical flow and convolutional vision Transformer was proposed to solve the problems of short duration, low motion intensity and insufficient sample size of micro-expressions. The optical flow and optical strain of human faces between the onset frame and the apex frame were extracted to highlight the movement of facial muscles, thereby effectively reducing the texture interference and lowering the feature dimension. The adversarial domain adaptation method based on identity domain was adopted to further remove the irrelevant components in the micro-expression features by making full use of the subjects’ labels. A lightweight multi-stage CNN-Transformer hybrid model named MiER-CvT, including the convolutional embedding layer, the convolutional Transformer block and the SeqSoftmax layer, was constructed to enhance the model’s capabilities of local representation and information integration for micro-expressions. The experimental results showed that the proposed method achieved a UF1 score of 0.9171 and a UAR score of 0.9192 on the MEGC 2019 dataset, and the parameter number and computational complexity of MiER-CvT were 7.5 M and 0.1 G, respectively. Compared with the existing methods, such as MiMaNet, the proposed method has the advantages of high precision and light weight.
|
|
Received: 30 March 2025
Published: 23 May 2026
|
|
|
| Fund: 青岛市关键技术攻关及产业化示范类资助项目(23-7-2-qljh-2-gx);苏州市工业园区科教领军人才资助项目(KJL2024104). |
|
Corresponding Authors:
Yanlong CAO
E-mail: kaiweixu@zju.edu.cn;sdcaoyl@zju.edu.cn
|
基于光流和卷积视觉Transformer的轻量级微表情识别
针对微表情持续时间短、动作强度低和样本量不足的问题,提出基于光流和卷积视觉Transformer的轻量级微表情识别方法. 通过提取起始帧与峰值帧之间人脸的光流和光应变,突出面部肌肉的运动,有效减少纹理干扰并降低特征维度;引入基于身份域的对抗域适应方法,充分利用受试者标签,去除微表情特征中的无关成分;构建轻型的多阶段CNN-Transformer混合模型MiER-CvT,包括卷积嵌入层、卷积Transformer模块和SeqSoftmax层,以增强模型对微表情的局部表征能力和信息整合能力. 实验结果表明,所提方法在MEGC 2019数据集上取得了0.9171的UF1值和0.9192的UAR值,且MiER-CvT的参数量和计算量分别为7.5 M和0.1 G. 相比于MiMaNet等方法,所提方法兼具高精度和轻量化的优势.
关键词:
微表情识别,
光流估计,
卷积视觉Transformer,
注意力机制,
域适应
|
|
| [1] |
LIONG S T, GAN Y, SEE J, et al. Shallow triple stream three-dimensional CNN (STSTNet) for micro-expression recognition [C]// Proceedings of the 14th IEEE International Conference on Automatic Face & Gesture Recognition. Lille: IEEE, 2019: 1–5.
|
|
|
| [2] |
PORTER S, TEN BRINKE L Reading between the lies: identifying concealed and falsified emotions in universal facial expressions[J]. Psychological Science, 2008, 19 (5): 508- 514
doi: 10.1111/j.1467-9280.2008.02116.x
|
|
|
| [3] |
ZHAO G, PIETIKAINEN M Dynamic texture recognition using local binary patterns with an application to facial expressions[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29 (6): 915- 928
doi: 10.1109/TPAMI.2007.1110
|
|
|
| [4] |
OJALA T, PIETIKAINEN M, MAENPAA T Multiresolution gray-scale and rotation invariant texture classification with local binary patterns[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24 (7): 971- 987
doi: 10.1109/TPAMI.2002.1017623
|
|
|
| [5] |
CHAUDHRY R, RAVICHANDRAN A, HAGER G, et al. Histograms of oriented optical flow and Binet-Cauchy kernels on nonlinear dynamical systems for the recognition of human actions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami: IEEE, 2009: 1932–1939.
|
|
|
| [6] |
LIU Y, ZHANG J, YAN W, et al A main directional mean optical flow feature for spontaneous micro-expression recognition[J]. IEEE Transactions on Affective Computing, 2016, 7 (4): 299- 310
doi: 10.1109/TAFFC.2015.2485205
|
|
|
| [7] |
LIONG S T, SEE J, WONG K, et al Less is more: micro-expression recognition from video using apex frame[J]. Signal Processing: Image Communication, 2018, 62: 82- 92
doi: 10.1016/j.image.2017.11.006
|
|
|
| [8] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach: Curran Associates Inc, 2017: 6000–6010.
|
|
|
| [9] |
WANG C, PENG M, BI T, et al Micro-attention for micro-expression recognition[J]. Neurocomputing, 2020, 410: 354- 362
doi: 10.1016/j.neucom.2020.06.005
|
|
|
| [10] |
XIA B, WANG W, WANG S, et al. Learning from macro-expression: a micro-expression recognition framework [C]// Proceedings of the 28th ACM International Conference on Multimedia. Seattle: ACM, 2020: 2936–2944.
|
|
|
| [11] |
XIA B, WANG S. Micro-expression recognition enhanced by macro-expression from spatial-temporal domain [C]// Proceedings of the 30th International Joint Conference on Artificial Intelligence. Montreal: IJCAI, 2021: 1186–1193.
|
|
|
| [12] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770–778.
|
|
|
| [13] |
GAN Y S, LIONG S T, YAU W, et al OFF-ApexNet on micro-expression recognition system[J]. Signal Processing: Image Communication, 2019, 74: 129- 139
doi: 10.1016/j.image.2019.02.005
|
|
|
| [14] |
KHOR H Q, SEE J, LIONG S T, et al. Dual-stream shallow networks for facial micro-expression recognition [C]// Proceedings of the IEEE International Conference on Image Processing. Taipei: IEEE, 2019: 36–40.
|
|
|
| [15] |
CHEN B, LIU K, XU Y, et al Block division convolutional network with implicit deep features augmentation for micro-expression recognition[J]. IEEE Transactions on Multimedia, 2023, 25: 1345- 1358
doi: 10.1109/TMM.2022.3141616
|
|
|
| [16] |
DOSOVITSKIY A, FISCHER P, ILG E, et al. FlowNet: learning optical flow with convolutional networks [C]// Proceedings of the IEEE International Conference on Computer Vision. Santiago: IEEE, 2016: 2758–2766.
|
|
|
| [17] |
梁岩, 黄润才, 卢士铖 基于改进3D ResNet18的多模态微表情识别[J]. 计算机应用研究, 2025, 42 (3): 903- 910
LIANG Yan, HUANG Runcai, LU Shicheng Multimodal micro-expression recognition based on improved 3D ResNet18[J]. Application Research of Computers, 2025, 42 (3): 903- 910
doi: 10.19734/j.issn.1001-3695.2024.04.0216
|
|
|
| [18] |
ZHANG L, HONG X, ARANDJELOVIĆ O, et al Short and long range relation based spatio-temporal Transformer for micro-expression recognition[J]. IEEE Transactions on Affective Computing, 2022, 13 (4): 1973- 1985
doi: 10.1109/TAFFC.2022.3213509
|
|
|
| [19] |
HOCHREITER S, SCHMIDHUBER J Long short-term memory[J]. Neural Computation, 1997, 9 (8): 1735- 1780
doi: 10.1162/neco.1997.9.8.1735
|
|
|
| [20] |
FAN Y, JIA M, ZHANG Y, et al. Micro-expression recognition using pre-trained model and Transformer [C]// Proceedings of the IEEE 4th International Conference on Civil Aviation Safety and Information Technology. Dali: IEEE, 2022: 1404–1408.
|
|
|
| [21] |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale [EB/OL]. (2021-06-03) [2025-08-05]. https://arxiv.org/abs/2010.11929.
|
|
|
| [22] |
WANG Z, ZHANG K, LUO W, et al HTNet for micro-expression recognition[J]. Neurocomputing, 2024, 602: 128196
doi: 10.1016/j.neucom.2024.128196
|
|
|
| [23] |
ZHOU H, HUANG S, XU Y IncepTR: micro-expression recognition integrating inception-CBAM and vision Transformer[J]. Multimedia Systems, 2023, 29 (6): 3863- 3876
doi: 10.1007/s00530-023-01164-0
|
|
|
| [24] |
WOO S, PARK J, LEE J Y, et al: CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision. Munich: Springer, 2018: 3–19.
|
|
|
| [25] |
SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 1–9.
|
|
|
| [26] |
XUE F, WANG Q, GUO G. TransFER: learning relation-aware facial expression representations with Transformers [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 3581–3590.
|
|
|
| [27] |
张波, 武瑀繁 基于双分支轻量化网络的微表情识别算法[J]. 激光与光电子学进展, 2024, 61 (14): 1437001
ZHANG Bo, WU Yufan Microexpression recognition algorithm based on a two-branch lightweight network[J]. Laser & Optoelectronics Progress, 2024, 61 (14): 1437001
|
|
|
| [28] |
SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: inverted residuals and linear bottlenecks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 4510–4520.
|
|
|
| [29] |
NGUYEN X, DUONG C, LI X, et al. Micron-BERT: BERT-based facial micro-expression recognition [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 1482–1492.
|
|
|
| [30] |
BAO H, DONG L, PIAO S, et al. BEiT: BERT pre-training of image Transformers [EB/OL]. (2022-09-03) [2025-08-05]. https://arxiv.org/abs/2106.08254.
|
|
|
| [31] |
MITCHELL T M. The need for biases in learning generalizations [R]. New Jersey: Rutgers University, 1980.
|
|
|
| [32] |
WU H, XIAO B, CODELLA N, et al. CvT: introducing convolutions to vision Transformers [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 22–31.
|
|
|
| [33] |
SHREVE M, GODAVARTHY S, GOLDGOF D, et al. Macro- and micro-expression spotting in long videos using spatio-temporal strain [C]// Proceedings of the IEEE International Conference on Automatic Face & Gesture Recognition. Santa Barbara: IEEE, 2011: 51–56.
|
|
|
| [34] |
安晶晶, 刘高平, 朱佳宁 Farneback光流法在短临预报中的应用[J]. 软件, 2018, 39 (10): 18- 25
AN Jingjing, LIU Gaoping, ZHU Jianing Application of farneback optical flow method in nowcasting[J]. Computer Engineering & Software, 2018, 39 (10): 18- 25
doi: 10.3969/j.issn.1003-6970.2018.10.005
|
|
|
| [35] |
GANIN Y, LEMPITSKY V. Unsupervised domain adaptation by backpropagation [C]// Proceedings of the International Conference on Machine Learning. Lille: JMLR, 2015: 1180–1189.
|
|
|
| [36] |
IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// Proceedings of the International Conference on Machine Learning. Lille: JMLR, 2015: 448–456.
|
|
|
| [37] |
SIFRE L, MALLAT S. Rigid-motion scattering for texture classification [EB/OL]. (2014-03-07) [2025-08-05]. https://arxiv.org/abs/1403.1687.
|
|
|
| [38] |
LI X, PFISTER T, HUANG X, et al. A spontaneous micro-expression database: inducement, collection and baseline [C]// Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition. Shanghai: IEEE, 2013: 1–6.
|
|
|
| [39] |
YAN W, LI X, WANG S, et al CASME II: an improved spontaneous micro-expression database and the baseline evaluation[J]. PLoS One, 2014, 9 (1): e86041
doi: 10.1371/journal.pone.0086041
|
|
|
| [40] |
DAVISON A K, LANSLEY C, COSTEN N, et al SAMM: a spontaneous micro-facial movement dataset[J]. IEEE Transactions on Affective Computing, 2018, 9 (1): 116- 129
doi: 10.1109/TAFFC.2016.2573832
|
|
|
| [41] |
FU R, HU Q, DONG X, et al. Axiom-based Grad-CAM: towards accurate visualization and explanation of CNNs [C]// Proceedings of the British Machine Vision Conference. [S.l.]: BMVA, 2020: 146.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|