|
|
|
| Text-to-image generation algorithm based on generative adversarial network and coordinate attention mechanism |
Yunhong LI( ),Qiqi ZHANG,Jinni CHEN,Weichong CHEN,Xueping SU,Chengming LIANG ),Qiqi ZHANG,Jinni CHEN,Weichong CHEN,Xueping SU,Chengming LIANG |
| School of Electronics and Information, Xi’an Polytechnic University, Xi’an 710048, China |
|
|
|
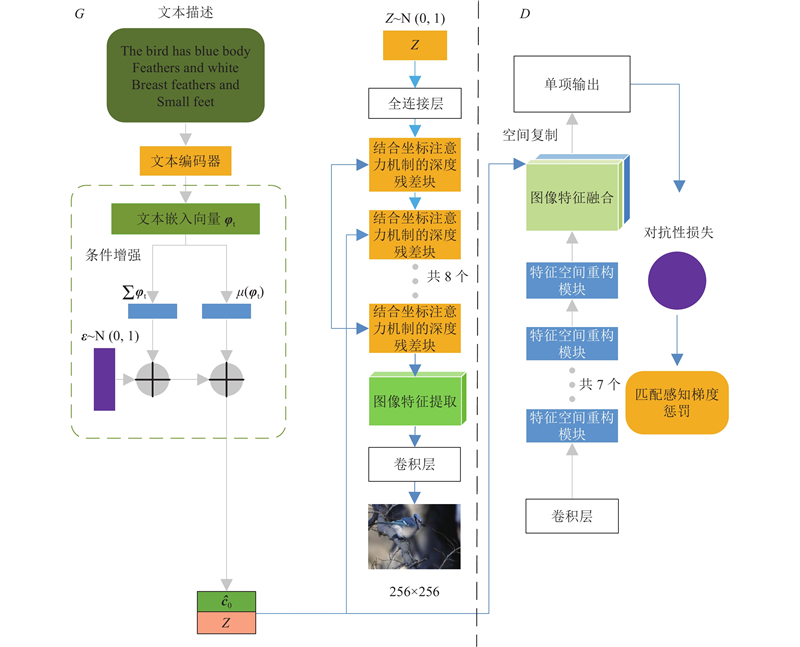
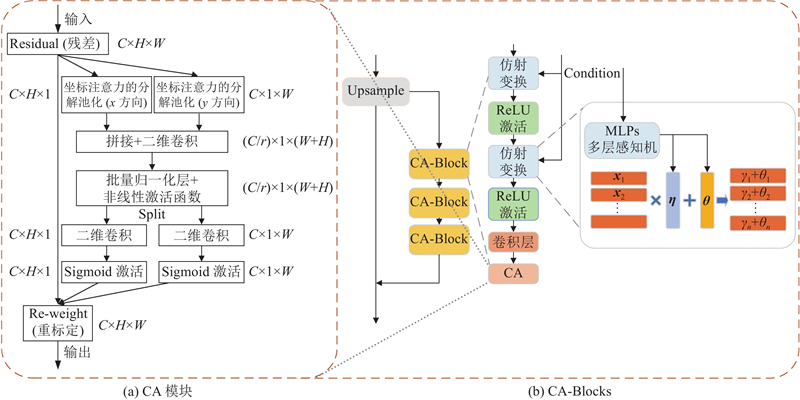
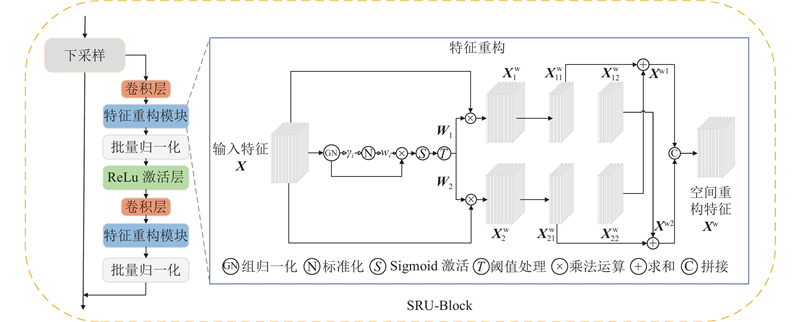
Abstract A text-to-image generation algorithm based on coordinate attention mechanism and generative adversarial network (CAT-GAN) was proposed in order to address the issue of poor diversity and low overall quality in the image generated by adversarial network. The conditional enhancement was used to calculate the mean and covariance matrix of the text feature vector, generating conditional variable to replace the original high-dimensional text feature and solve the sparsity problem. The coordinate attention mechanism was introduced into the residual block of the generator network to form a deep fusion module combined with the coordinate attention mechanism (CA-Block). The long-term dependency relationship of feature between channels can be captured while retaining the precise position of feature and enhancing the representation of the target object. The spatial reconstruction unit was introduced into the discriminator network to form a feature space reconstruction module (SRU-Block). Redundant feature was separated via weight assignment and reconstruction, enhancing the discriminator’s ability to represent feature. The model was tested and verified using the CUB-200, Oxford-102 Flowers and COCO dataset. The experimental results showed that the IS and FID index value of the proposed model (CAT-GAN) were the best compared with models such as StackGAN++, AttnGAN, DAE-GAN, DM-GAN, DT-GAN and DF-GAN. The IS index value reached 5.13, 4.10 and 31.81, and the FID index value reached 14.34, 16.76 and 26.36. The proposed model has better visualization effect, proving the effectiveness of the proposed method.
|
|
Received: 15 July 2025
Published: 06 May 2026
|
|
|
| Fund: 国家自然科学基金青年基金资助项目(62403368);陕西省自然科学基础研究重点资助项目(2022JZ-35);陕西省自然科学基础研究资助项目(2024JCYBMS-455);陕西高校青年创新团队资助项目;西安市“科学家+工程师”团队项目(25KGYB00029). |
基于生成对抗网络和坐标注意力机制的文本生成图像算法
针对对抗网络生成的图像存在多样性差、总体质量不高的问题,提出基于坐标注意力机制和生成对抗网络的文本生成图像算法(CAT-GAN). 采用条件增强计算文本特征向量的均值和协方差矩阵,生成条件变量代替原高维文本特征,解决稀疏性问题. 将坐标注意力机制引入生成器网络的残差块中,构成结合坐标注意力机制的深度融合模块(CA-Block),在捕捉通道间特征长期依赖关系的同时,保留特征的精确位置,增强感兴趣对象的表示. 在鉴别器网络中引入空间重构单元,构成特征空间重构模块(SRU-Block). 通过权重分离冗余特征并重构,增强鉴别器对特征的表征能力. 通过CUB-200、Oxford-102 Flowers及COCO数据集,测试并验证模型. 实验结果表明,与StackGAN++、AttnGAN、DAE-GAN、DM-GAN、DT-GAN及DF-GAN等模型相比,所提模型(CAT-GAN)的IS和FID指标值均为最优,IS指标值分别达到5.13、4.10、31.81,FID指标值分别达到14.34、16.76、26.36. 所提模型具有更好的可视化效果,证明了所提方法的有效性.
关键词:
文本生成图像,
生成对抗网络(GAN),
条件增强,
坐标注意力机制,
仿射变换
|
|
| [1] |
曹寅, 秦俊平, 马千里, 等 文本生成图像研究综述[J]. 浙江大学学报: 工学版, 2024, 58 (2): 219- 238
CAO Yin, QIN Junping, MA Qianli, et al Survey of text-to-image synthesis[J]. Journal of Zhejiang University: Engineering Science, 2024, 58 (2): 219- 238
|
|
|
| [2] |
李云红, 朱绵云, 任劼, 等 改进深度卷积生成式对抗网络的文本生成图像[J]. 北京航空航天大学学报, 2023, 49 (8): 1875- 1883
LI Yunhong, ZHU Mianyun, REN Jie, et al Text-to-image synthesis based on modified deep convolutional generative adversarial network[J]. Journal of Beijing University of Aeronautics and Astronautics, 2023, 49 (8): 1875- 1883
doi: 10.13700/j.bh.1001-5965.2021.0588
|
|
|
| [3] |
梁成名, 李云红, 李丽敏, 等 结合语义分割图的注意力机制文本生成图像[J]. 空军工程大学学报, 2024, 25 (4): 118- 127
LIANG Chengming, LI Yunhong, LI Limin, et al A semantic segmentation graph in combination with attention mechanism text generation images[J]. Journal of Air Force Engineering University, 2024, 25 (4): 118- 127
doi: 10.3969/j.issn.2097-1915.2024.04.016
|
|
|
| [4] |
李丰, 文益民 融合多尺度视觉和文本语义特征的图像描述生成算法[J]. 山东大学学报: 工学版, 2025, 55 (3): 80- 87
LI Feng, WEN Yimin Multi-scale visual and textual semantic feature fusion for image captioning[J]. Journal of Shandong University: Engineering Science, 2025, 55 (3): 80- 87
doi: 10.6040/j.issn.1672-3961.0.2024.018
|
|
|
| [5] |
周刚, 李捍东, 陈烨烨 基于对比学习的文本生成图像[J]. 软件工程, 2025, 28 (2): 37- 41
ZHOU Gang, LI Handong, CHEN Yeye Text-to-image generation based on contrastive learning[J]. Software Engineering, 2025, 28 (2): 37- 41
|
|
|
| [6] |
ZHANG H, XU T, LI H, et al. StackGAN: text to photo-realistic image synthesis with stacked generative adversarial networks [C]//Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 5908–5916.
|
|
|
| [7] |
XU T, ZHANG P, HUANG Q, et al. AttnGAN: fine-grained text to image generation with attentional generative adversarial networks [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 1316–1324.
|
|
|
| [8] |
TAO M, TANG H, WU F, et al. DF-GAN: a simple and effective baseline for text-to-image synthesis [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 16494–16504.
|
|
|
| [9] |
YE S, WANG H, TAN M, et al Recurrent affine transformation for text-to-image synthesis[J]. IEEE Transactions on Multimedia, 2024, 26: 462- 473
doi: 10.1109/TMM.2023.3266607
|
|
|
| [10] |
HÖLLEIN L, BOŽIČ A, MÜLLER N, et al. ViewDiff: 3D-consistent image generation with text-to-image models [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 5043–5052.
|
|
|
| [11] |
SHIRAKAWA T, UCHIDA S. NoiseCollage: a layout-aware text-to-image diffusion model based on noise cropping and merging [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 8921-8930.
|
|
|
| [12] |
GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of Wasserstein GANs [C]//Advances in Neural Information Processing Systems. Long Beach: Curran Associates, Inc., 2017.
|
|
|
| [13] |
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]//Advances in Neural Information Processing Systems. Cambridge: MIT Press, 2014: 2672-2680.
|
|
|
| [14] |
WAH C, BRANSON S, WELINDER P, et al. The caltech-UCSD birds-200-2011 dataset [R]. Pasadena: California Institute of Technology, 2011.
|
|
|
| [15] |
NILSBACK M E, ZISSERMAN A. Automated flower classification over a large number of classes [C]//Proceedings of the 6th Indian Conference on Computer Vision, Graphics and Image Processing. Bhubaneswar: IEEE, 2009: 722–729.
|
|
|
| [16] |
SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs [C]// Proceedings of Advances in Neural Information Processing Systems. Barcelona: Curran Associates, Inc., 2016: 2234–2242.
|
|
|
| [17] |
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium [C]//Proceedings of the Neural Information Processing Systems. Long Beach: Curran Associates, Inc., 2017.
|
|
|
| [18] |
ZHU M, PAN P, CHEN W, et al. DM-GAN: dynamic memory generative adversarial networks for text-to-image synthesis [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2020: 5795–5803.
|
|
|
| [19] |
ZHANG H, XU T, LI H, et al StackGAN: realistic image synthesis with stacked generative adversarial networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41 (8): 1947- 1962
doi: 10.1109/TPAMI.2018.2856256
|
|
|
| [20] |
RUAN S, ZHANG Y, ZHANG K, et al. DAE-GAN: dynamic aspect-aware GAN for text-to-image synthesis [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2022: 13940–13949.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|