|
|
|
| Text-to-image generation method based on multimodal semantic information |
Bing YANG1,2( ),Jiahui ZHOU1,2,Jinliang YAO1,2,Xueqin XIANG3 ),Jiahui ZHOU1,2,Jinliang YAO1,2,Xueqin XIANG3 |
1. School of Computer Science and Technology, Hangzhou Dianzi University, Hangzhou 310018, China
2. Key Laboratory of Brain Machine Collaborative Intelligence of Zhejiang Province, Hangzhou Dianzi University, Hangzhou 310018, China
3. Hangzhou Lingban Technology Limited Company, Hangzhou 311121, China |
|
|
|
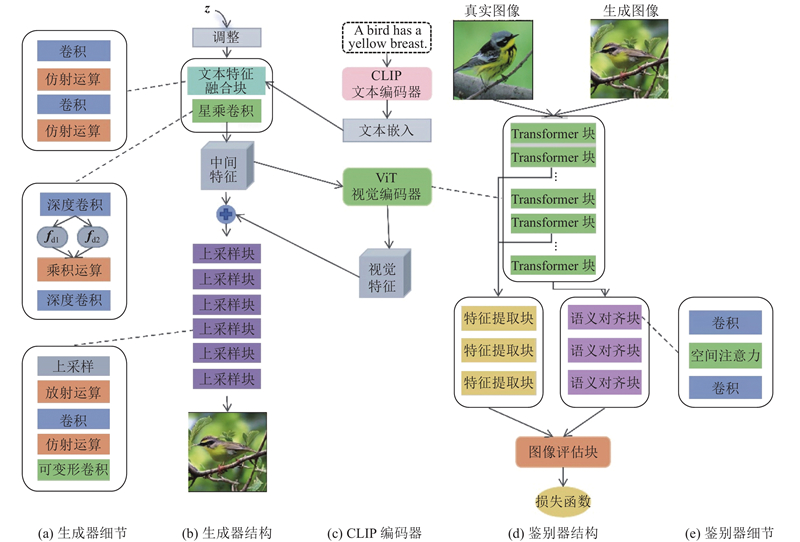
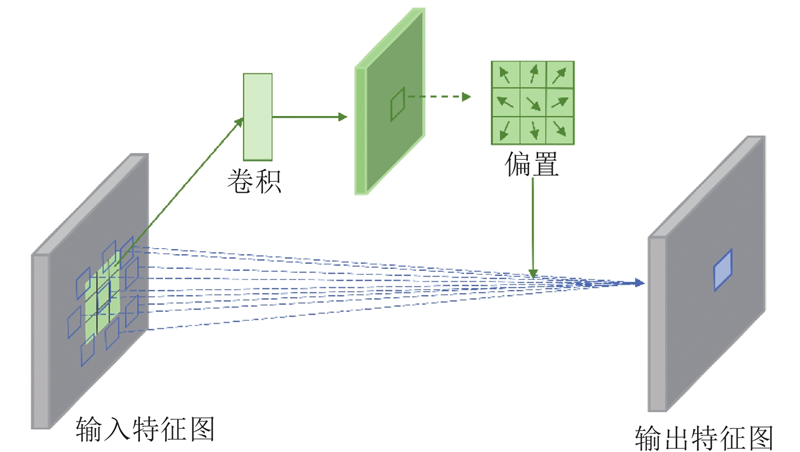
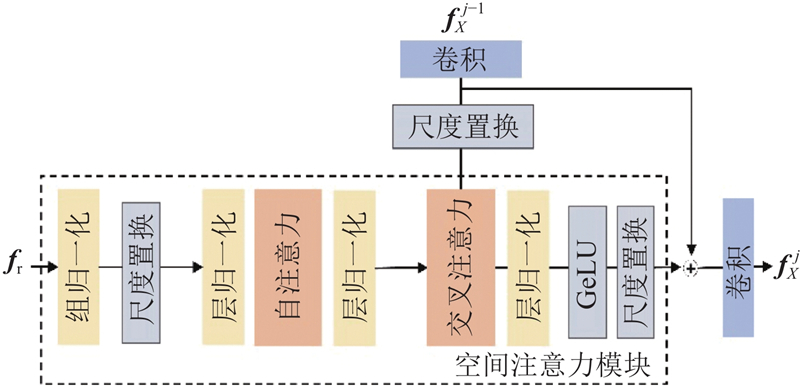
Abstract A new method was proposed to address text-image semantic inconsistencies and detail deficiencies in text-to-image generation. A discrimination mechanism was established that integrates real-image semantics with textual descriptions, mitigating text’s inherent information sparsity to alleviate detail omission or distortion in synthesized images. Deformable and star product convolutions were incorporated into a generator, enhancing the structural adaptability of the generator to improve fine-grained rendering and overall fidelity. To validate the effectiveness of the proposed method, model training and evaluation were conducted on the CUB and COCO datasets. Compared to generative adversarial networks trained with contrastive language-image pretraining (GALIP), the proposed method offers significant advantages in detail representation, semantic consistency, and overall image quality, while achieving efficient generation.
|
|
Received: 23 January 2025
Published: 03 February 2026
|
|
|
| Fund: 浙江省基础公益研究计划(LGG22F020027). |
基于多模态语义信息的文本生成图像方法
针对文本语义与图像语义不一致以及图像细节表现不足的问题,提出新的文本生成图像方法. 基于多模态语义信息建立鉴别依据,在文本语义基础上引入真实图像语义,以解决文本描述信息密度低的问题,有效缓解生成图像细节缺失或失真的现象. 在生成器中集成可变形卷积和星模块卷积,增强生成器表达能力,提高生成图像的细节表现和整体质量. 为了验证所提方法的有效性,在CUB数据集和COCO数据集上进行模型训练及评估. 与生成式对抗对比语言?图像预训练模型(GALIP)相比,所提方法在保证高效生成的同时,在细节表现、语义一致性及整体质量上具有显著优势.
关键词:
文本生成图像,
多模态语义,
可变形卷积,
星模块卷积,
语义对齐鉴别器
|
|
| [1] |
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. [S.1.]: MIT Press, 2014: 2672–2680.
|
|
|
| [2] |
HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models [EB/OL]. (2020−12−16)[2024−12−23]. https://arxiv.org/pdf/2006.11239.
|
|
|
| [3] |
QIAO T, ZHANG J, XU D, et al. MirrorGAN: learning text-to-image generation by redescription [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2020: 1505–1514.
|
|
|
| [4] |
TAO M, TANG H, WU F, et al. DF-GAN: a simple and effective baseline for text-to-image synthesis [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 16494–16504.
|
|
|
| [5] |
TAO M, BAO B K, TANG H, et al. GALIP: generative adversarial CLIPs for text-to-image synthesis [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 14214–14223.
|
|
|
| [6] |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the International Conference on Machine Learning. [S.l.]: ICLR, 2021: 748−763.
|
|
|
| [7] |
MA X, DAI X, BAI Y, et al. Rewrite the stars [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 5694–5703.
|
|
|
| [8] |
XIONG Y, LI Z, CHEN Y, et al. Efficient deformable ConvNets : rethinking dynamic and sparse operator for vision applications [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 5652−5661.
|
|
|
| [9] |
REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis [C]// Proceedings of the 33rd International Conference on International Conference on Machine Learning. [S.l.]: ACM, 2016: 1060–1069.
|
|
|
| [10] |
ZHANG H, XU T, LI H, et al. StackGAN: text to photo-realistic image synthesis with stacked generative adversarial networks [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 5908–5916.
|
|
|
| [11] |
TAN H, LIU X, YIN B, et al DR-GAN: distribution regularization for text-to-image generation[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34 (12): 10309- 10323
doi: 10.1109/TNNLS.2022.3165573
|
|
|
| [12] |
YE S, WANG H, TAN M, et al Recurrent affine transformation for text-to-image synthesis[J]. IEEE Transactions on Multimedia, 2024, 26: 462- 473
doi: 10.1109/TMM.2023.3266607
|
|
|
| [13] |
ZHOU Y, ZHANG R, CHEN C, et al. Towards language-free training for text-to-image generation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 17886–17896.
|
|
|
| [14] |
RAMESH A, DHARIWAL P, NICHOL A, et al. Hierarchical text-conditional image generation with CLIP latents [EB/OL]. (2022−04−13)[2024−12−23]. https://arxiv.org/pdf/2204.06125.
|
|
|
| [15] |
VASWAMI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. [S.l.]: Curran Associates Inc. , 2017: 6000–6010.
|
|
|
| [16] |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale [EB/OL]. (2021−06−03)[2024−12−23]. https://arxiv.org/pdf/2010.11929.
|
|
|
| [17] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770–778.
|
|
|
| [18] |
WAH C, BRANSON S, WELINDER P, et al. The Caltech-UCSD birds-200-2011 dataset [DB/OL]. (2022−08−12)[2024−06−23]. https://authors.library.caltech.edu/27452/1/CUB_200_2011.pdf.
|
|
|
| [19] |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// Computer Vision – ECCV 2014. [S.l.]: Springer, 2014: 740–755.
|
|
|
| [20] |
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. [S.l.]: ACM, 2017: 6629–6640.
|
|
|
| [21] |
WU C, LIANG J, JI L, et al. NÜWA: visual synthesis pre-training for neural visual world creation [C]// Computer Vision – ECCV 2022. [S.l.]: Springer, 2022: 720–736.
|
|
|
| [22] |
SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. [S.l.]: ACM, 2016: 2234–2242.
|
|
|
| [23] |
GU S, CHEN D, BAO J, et al. Vector quantized diffusion model for text-to-image synthesis [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 10686–10696.
|
|
|
| [24] |
YANG B, XIANG X, KONG W, et al DMF-GAN: deep multimodal fusion generative adversarial networks for text-to-image synthesis[J]. IEEE Transactions on Multimedia, 2024, 26: 6956- 6967
doi: 10.1109/TMM.2024.3358086
|
|
|
| [25] |
JIN D, YU Q, YU L, et al SAW-GAN: multi-granularity text fusion generative adversarial networks for text-to-image generation[J]. Knowledge-Based Systems, 2024, 294: 111795
doi: 10.1016/j.knosys.2024.111795
|
|
|
| [26] |
GAFNI O, POLYAK A, ASHUAL O, et al. Make-a-scene: scene-based text-to-image generation with human priors [C]// Computer Vision – ECCV 2022. [S.l.]: Springer, 2022: 89–106.
|
|
|
| [27] |
ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 10674–10685.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|