|
|
|
| Image captioning generation based on multiple-view cross-modal feature fusion |
Naizhou ZHANG1( ),Yunchao ZHAO1,Wei CAO2,Xiaojian ZHANG1 ),Yunchao ZHAO1,Wei CAO2,Xiaojian ZHANG1 |
1. College of Computer and Information Engineering, Henan University of Economics and Law, Zhengzhou 450046, China
2. School of Data Science and E-commerce, Henan University of Economics and Law, Zhengzhou 450046, China |
|
|
|
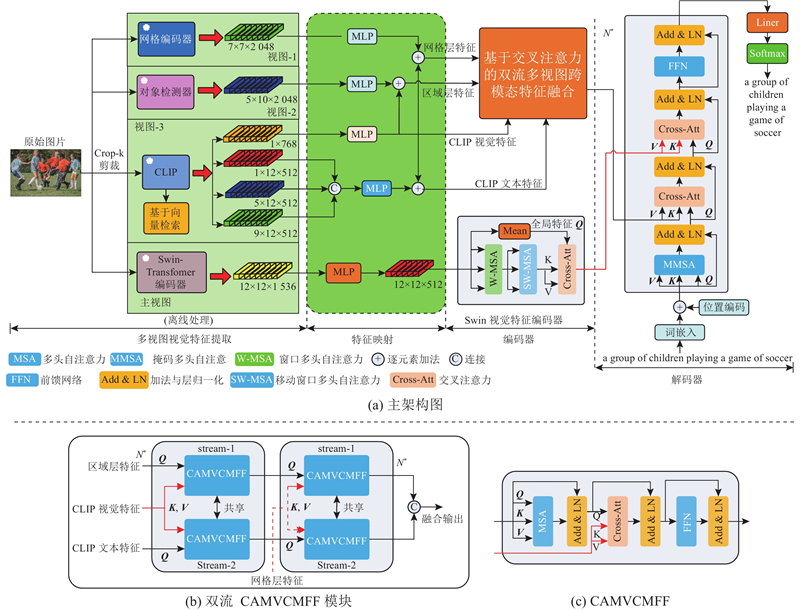
Abstract A new method based on multi-view cross-modal feature augmentation and fusion for image captioning was proposed aiming at the issue of visual information loss in visual feature extraction. Multiple pre-trained visual feature extractor was employed to map image data into different feature space, and a cross-attention dual-stream mechanism was introduced to achieve dynamic enhancement and complementary fusion of multi-view cross-modal feature. Multiple visual feature was effectively coordinated. The complementarity between different visual feature representation was exploited, and visual information loss during feature encoding was mitigated. The quality of image captioning generation was significantly improved by optimizing the encoder-decoder architecture. The experimental results showed that the proposed model significantly outperformed existing state-of-the-art methods across multiple evaluation metrics for image captioning performance, validating the effectiveness of multi-view feature collaboration.
|
|
Received: 20 September 2025
Published: 06 May 2026
|
|
|
| Fund: 国家自然科学基金资助项目(62072156);河南省科技攻关项目(262102210047);河南省高等学校重点科研项目计划基础研究专项资助项目(25ZX012). |
基于多视图跨模态特征融合的图像描述生成
针对视觉特征提取过程中的视觉信息损失问题,提出新的基于多视图跨模态特征增强与融合的图像描述生成方法. 使用多个预训练图像视觉特征提取器将图像数据映射到不同的特征空间中,引入交叉注意力双流机制,实现多视图跨模态特征的动态增强与互补融合. 利用该方法,对多种视觉特征进行有效地协同融合,利用不同视觉特征表示之间的互补性,减少在视觉特征编码过程中的视觉信息损失. 通过优化编码器-解码器架构,显著提升了图像描述生成的质量. 实验结果表明,提出的模型在衡量图像描述生成性能的多个指标上,明显优于现有的主流方法,验证了多视图特征协同的有效性.
关键词:
图像描述,
视觉特征提取,
跨模态特征融合,
注意力机制,
对比语言-图像预训练(CLIP)
|
|
| [1] |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]//Proceedings of the International Conference on Machine Learning. Vienna: PMLR, 2021: 8748–8763.
|
|
|
| [2] |
LI J, LI D, XIONG C, et al. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation [C]//Proceedings of the International Conference on Machine Learning. Baltimore: PMLR, 2022: 12888–12900.
|
|
|
| [3] |
李志欣, 魏海洋, 张灿龙, 等 图像描述生成研究进展[J]. 计算机研究与发展, 2021, 58 (9): 1951- 1974
LI Zhixin, WEI Haiyang, ZHANG Canlong, et al Research progress on image captioning[J]. Journal of Computer Research and Development, 2021, 58 (9): 1951- 1974
doi: 10.7544/issn1000-1239.2021.20200281
|
|
|
| [4] |
XU K, BA J, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention [C]//Proceedings of the International Conference on Machine Learning. Lille: JMLR, 2015: 2048–2057.
|
|
|
| [5] |
LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 3242–3250.
|
|
|
| [6] |
RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1179–1195.
|
|
|
| [7] |
JIANG H, MISRA I, ROHRBACH M, et al. In defense of grid features for visual question answering [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 10264–10273.
|
|
|
| [8] |
WU M, ZHANG X, SUN X, et al. DIFNet: boosting visual information flow for image captioning [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 17999–18008.
|
|
|
| [9] |
HUANG L, WANG W, CHEN J, et al. Attention on attention for image captioning [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 4633–4642.
|
|
|
| [10] |
PAN Y, YAO T, LI Y, et al. X-linear attention networks for image captioning [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 10968–10977.
|
|
|
| [11] |
CORNIA M, STEFANINI M, BARALDI L, et al. Meshed-memory transformer for image captioning [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 10575–10584.
|
|
|
| [12] |
JI J, LUO Y, SUN X, et al Improving image captioning by leveraging intra- and inter-layer global representation in transformer network[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35 (2): 1655- 1663
doi: 10.1609/aaai.v35i2.16258
|
|
|
| [13] |
ZHANG X, SUN X, LUO Y, et al. RSTNet: captioning with adaptive attention on visual and non-visual words [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 15460–15469.
|
|
|
| [14] |
LUO Y, JI J, SUN X, et al Dual-level collaborative transformer for image captioning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35 (3): 2286- 2293
|
|
|
| [15] |
LI X, YIN X, LI C, et al. Oscar: object-semantics aligned pre-training for vision-language tasks [C]//Proceedings of the 16th European Conference on Computer Vision. Cham: Springer, 2020: 121–137.
|
|
|
| [16] |
KUO C W, KIRA Z. Beyond a pre-trained object detector: cross-modal textual and visual context for image captioning [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 17948–17958.
|
|
|
| [17] |
KUO C W, KIRA Z. HAAV: hierarchical aggregation of augmented views for image captioning [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 11039–11049.
|
|
|
| [18] |
LIU Z, LIU J, MA F Improving cross-modal alignment with synthetic pairs for text-only image captioning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2024, 38 (4): 3864- 3872
doi: 10.1609/aaai.v38i4.28178
|
|
|
| [19] |
QIU L, NING S, HE X Mining fine-grained image-text alignment for zero-shot captioning via text-only training[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2024, 38 (5): 4605- 4613
doi: 10.1609/aaai.v38i5.28260
|
|
|
| [20] |
LEE J R, SHIN Y, SON G, et al. Diffusion bridge: leveraging diffusion model to reduce the modality gap between text and vision for zero-shot image captioning [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2025: 4050–4059.
|
|
|
| [21] |
WANG Y, XU J, SUN Y End-to-end transformer based model for image captioning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36 (3): 2585- 2594
doi: 10.1609/aaai.v36i3.20160
|
|
|
| [22] |
ASHISH V, NOAM S, NIKI P, et al. Attention is all you need [C]// Annual Conference on Neural Information Processing Systems. Long Beach: NeurIPS Foundation, 2017: 5998–6008.
|
|
|
| [23] |
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2022: 9992–10002.
|
|
|
| [24] |
XIONG Y, LIAO R, ZHAO H, et al. UPSNet: a unified panoptic segmentation network [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2020: 8810–8818.
|
|
|
| [25] |
KRISHNA R, ZHU Y, GROTH O, et al Visual genome: connecting language and vision using crowdsourced dense image annotations[J]. International Journal of Computer Vision, 2017, 123 (1): 32- 73
doi: 10.1007/s11263-016-0981-7
|
|
|
| [26] |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]//Proceedings of the 13th European Conference on Computer Vision. Cham: Springer, 2014: 740–755.
|
|
|
| [27] |
KARPATHY A, LI F F Deep visual-semantic alignments for generating image descriptions[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (4): 664- 676
doi: 10.1109/TPAMI.2016.2598339
|
|
|
| [28] |
PAPINENI K, ROUKOS S, WARD T, et al. Bleu: a method for automatic evaluation of machine translation [C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Philadelphia: ACL, 2002: 311–318.
|
|
|
| [29] |
LAVIE A, AGARWAL A. Meteor: an automatic metric for MT evaluation with high levels of correlation with human judgments [C]//Proceedings of the 2nd Workshop on Statistical Machine Translation. Prague: ACL, 2007: 228–231.
|
|
|
| [30] |
LIN C Y. ROUGE: a package for automatic evaluation of summaries [C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. Barcelona: ACL, 2004.
|
|
|
| [31] |
VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: consensus-based image description evaluation [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 4566–4575.
|
|
|
| [32] |
ANDERSON P, FERNANDO B, JOHNSON M, et al. SPICE: semantic propositional image caption evaluation [C]//Proceedings of the 14th European Conference on Computer Vision. Cham: Springer, 2016: 382–398.
|
|
|
| [33] |
刘茂福, 施琦, 聂礼强 基于视觉关联与上下文双注意力的图像描述生成方法[J]. 软件学报, 2022, 33 (9): 3210- 3222
LIU Maofu, SHI Qi, NIE Liqiang Image captioning based on visual relevance and context dual attention[J]. Journal of Software, 2022, 33 (9): 3210- 3222
doi: 10.13328/j.cnki.jos.006623
|
|
|
| [34] |
LI J, VO D M, SUGIMOTO A, et al. Evcap: retrieval-augmented image captioning with external visual-name memory for open-world comprehension [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 13733–13742.
|
|
|
| [35] |
WANG J, WANG W, WANG L, et al Learning visual relationship and context-aware attention for image captioning[J]. Pattern Recognition, 2020, 98: 107075
doi: 10.1016/j.patcog.2019.107075
|
|
|
| [36] |
李志欣, 魏海洋, 黄飞成, 等 结合视觉特征和场景语义的图像描述生成[J]. 计算机学报, 2020, 43 (9): 1624- 1640
LI Zhixin, WEI Haiyang, HUANG Feicheng, et al Combine visual features and scene semantics for image captioning[J]. Chinese Journal of Computers, 2020, 43 (9): 1624- 1640
doi: 10.11897/SP.J.1016.2020.01624
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|