|
|
|
| 3D human pose estimation based on multi-scale encoder fusion |
Xiaoan BAO1( ),Enlin CHEN1,Na ZHANG1,Xiaomei TU2,Biao WU3,Qingqi ZHANG4,*() ),Enlin CHEN1,Na ZHANG1,Xiaomei TU2,Biao WU3,Qingqi ZHANG4,*() |
1. School of Computer Science and Technology, Zhejiang Sci-Tech University, Hangzhou 310018, China
2. School of Civil Engineering and Architecture, Zhejiang Guangsha Vocational and Technical University of Construction, Dongyang 322100, China
3. School of Science, Zhejiang Sci-Tech University, Hangzhou 310018, China
4. Graduate School of East Asian Studies, Yamaguchi University, Yamaguchi 753-8514, Japan |
|
|
|
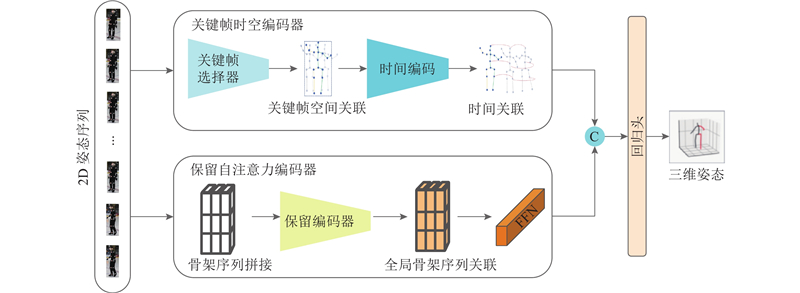
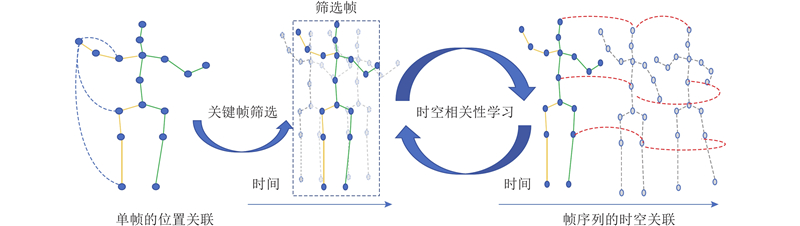
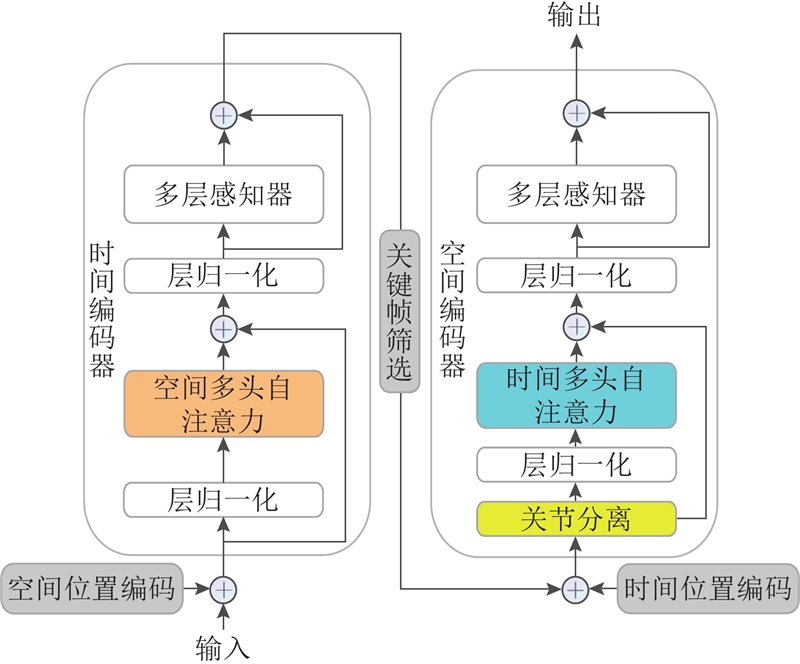
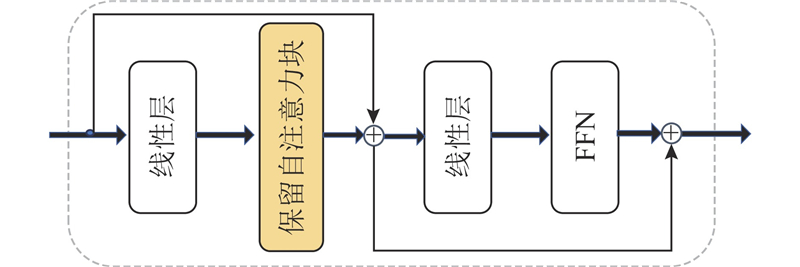
Abstract A 3D human pose estimation method based on multi-scale encoder fusion was proposed in order to address the contradiction between redundant information interference and the need for information completeness. The method consisted of a key-frame spatial-temporal encoder (KFSTE) and a global retention self-attention encoder (GRSAE). The skeletal feature sequence was filtered by using a key-frame selector in KFSTE. Then local spatial-temporal dependencies were modeled through a temporal encoder. Global single-stage encoding was performed via a retention encoder in GRSAE to capture global skeletal sequence feature, thereby avoiding information loss caused by key-frame selection bias. The 3D human pose coordinates were predicted by concatenating the features from the two encoders followed by a regression module. The experimental results on the large-scale Human3.6M dataset demonstrated that the proposed method reduced the mean per-joint position error (MPJPE) by 3% compared with MixSTE and achieved the best performance on 11 actions.
|
|
Received: 13 March 2025
Published: 04 February 2026
|
|
|
| Fund: 国家自然科学基金资助项目 (6207050141);浙江省重点研发计划资助项目(2020C03094);浙江省教育厅一般科研资助项目(Y202147659);浙江省教育厅资助项目(Y202250706,Y202250677);浙江省基础公益研究计划资助项目(QY19E050003). |
|
Corresponding Authors:
Qingqi ZHANG
E-mail: baoxiaoan@zstu.edu.cn;c503snw@yamaguchi-u.ac.jp
|
基于多尺度编码器融合的三维人体姿态估计算法
针对冗余信息干扰与信息完整性需求之间的矛盾,提出基于多尺度编码器融合的三维人体姿态估计方法. 该方法由关键帧时空编码器(KFSTE)和全局保留自注意力编码器(GRSAE)构成. KFSTE通过关键帧选择器对骨架特征序列进行筛选后,由时间编码器获取局部时空建模. GRSAE通过保留编码器进行全局单阶段编码来获取全局骨架序列特征,避免因关键帧筛选偏差导致的信息损失. 通过对双编码器的特征拼接及回归处理,预测得到三维人体姿态坐标. 实验结果表明,在较大规模的Human3.6M数据集上,所提方法的平均关节位置误差(MPJPE)比MixSTE低3%,有11个动作获得最佳.
关键词:
三维人体姿态估计,
时空编码器,
关键帧提取,
保留自注意力编码,
多编码特征融合
|
|
| [1] |
ZHANG C, YANG T, WENG J, et al. Unsupervised pre-training for temporal action localization tasks [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 14011–14021.
|
|
|
| [2] |
CHEN H, HE J Y, XIANG W, et al. Hdformer: high-order directed transformer for 3d human pose estimation [C]//Proceedings of the 32nd International Joint Conference on Artificial Intelligence. Macao: ACM, 2023: 581-589.
|
|
|
| [3] |
LIU M, YUAN J. Recognizing human actions as the evolution of pose estimation maps [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 1159–1168.
|
|
|
| [4] |
ZHANG Q, BAO X, WU R, et al A skeleton temporal fusion graph convolutional network for elderly action recognition[J]. IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences, 2025, 108 (5): 704- 713
|
|
|
| [5] |
MEHTA D, SRIDHAR S, SOTNYCHENKO O, et al VNect: real-time 3D human pose estimation with a single RGB camera[J]. ACM Transactions on Graphics, 2017, 36 (4): 1- 14
|
|
|
| [6] |
MOON G, LEE K M. I2L-MeshNet: image-to-lixel prediction network for accurate 3D human pose and mesh estimation from a single RGB image [C]//Proceedings of the European Conference on Computer Vision. Cham: Springer, 2020: 752–768.
|
|
|
| [7] |
PAVLAKOS G, ZHOU X, DANIILIDIS K. Ordinal depth supervision for 3D human pose estimation [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7307–7316.
|
|
|
| [8] |
CHEN T, FANG C, SHEN X, et al Anatomy-aware 3D human pose estimation with bone-based pose decomposition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32 (1): 198- 209
doi: 10.1109/TCSVT.2021.3057267
|
|
|
| [9] |
LIU R, SHEN J, WANG H, et al. Attention mechanism exploits temporal contexts: real-time 3D human pose reconstruction [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 5063–5072.
|
|
|
| [10] |
WANG J, YAN S, XIONG Y, et al. Motion guided 3D pose estimation from videos [C]// Proceedings of the European Conference on Computer Vision. Cham: Springer, 2020: 764–780.
|
|
|
| [11] |
ZENG A, SUN X, HUANG F, et al. SRNet: improving generalization in 3D human pose estimation with a split-and-recombine approach [C]// Proceedings of the European Conference on Computer Vision. Cham: Springer, 2020: 507–523.
|
|
|
| [12] |
CAO Z, SIMON T, WEI S E, et al. Realtime multi-person 2d pose estimation using part affinity fields [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 7291-7299.
|
|
|
| [13] |
ZHENG C, ZHU S, MENDIETA M, et al. 3D human pose estimation with spatial and temporal transformers [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2022: 11636–11645.
|
|
|
| [14] |
LI W, LIU H, DING R, et al Exploiting temporal contexts with strided transformer for 3D human pose estimation[J]. IEEE Transactions on Multimedia, 2023, 25: 1282- 1293
doi: 10.1109/TMM.2022.3141231
|
|
|
| [15] |
ZHANG J, TU Z, YANG J, et al. MixSTE: seq2seq mixed spatio-temporal encoder for 3D human pose estimation in video [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 13222–13232.
|
|
|
| [16] |
ZHU W, MA X, LIU Z, et al. MotionBERT: a unified perspective on learning human motion representations [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2024: 15039–15053.
|
|
|
| [17] |
TANG Z, QIU Z, HAO Y, et al. 3D human pose estimation with spatio-temporal criss-cross attention [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 4790–4799.
|
|
|
| [18] |
CHEN X, HAN Y, WANG X, et al Action keypoint network for efficient video recognition[J]. IEEE Transactions on Image Processing, 2022, 31: 4980- 4993
doi: 10.1109/TIP.2022.3191461
|
|
|
| [19] |
EINFALT M, LUDWIG K, LIENHART R. Uplift and upsample: efficient 3D human pose estimation with uplifting transformers [C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. Waikoloa: IEEE, 2023: 2902–2912.
|
|
|
| [20] |
FAN Q, HUANG H, CHEN M, et al. Rmt: retentive networks meet vision transformers [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 5641-5651.
|
|
|
| [21] |
LI W, LIU H, TANG H, et al. MHFormer: multi-hypothesis transformer for 3D human pose estimation [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 13137–13146.
|
|
|
| [22] |
SHAN W, LIU Z, ZHANG X, et al. P-STMO: pre-trained spatial temporal many-to-one model for3D human pose estimation [C]//European Conference on Computer Vision. Cham: Springer, 2022: 461–478.
|
|
|
| [23] |
FAN Q, HUANG H, CHEN M, et al. RMT: retentive networks meet vision transformers [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 5641–5651.
|
|
|
| [24] |
IONESCU C, PAPAVA D, OLARU V, et al Human3.6M: large scale datasets and predictive methods for 3D human sensing in natural environments[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36 (7): 1325- 1339
doi: 10.1109/TPAMI.2013.248
|
|
|
| [25] |
MEHTA D, RHODIN H, CASAS D, et al. Monocular 3D human pose estimation in the wild using improved CNN supervision [C]//Proceedings of the International Conference on 3D Vision. Qingdao: IEEE, 2018: 506–516.
|
|
|
| [26] |
ZHENG C, WU W, CHEN C, et al Deep learning-based human pose estimation: a survey[J]. ACM Computing Surveys, 2024, 56 (1): 1- 37
|
|
|
| [27] |
MARGOSSIAN C C A review of automatic differentiation and its efficient implementation[J]. WIREs Data Mining and Knowledge Discovery, 2019, 9 (4): e1305
doi: 10.1002/widm.1305
|
|
|
| [28] |
FINDER S E, AMOYAL R, TREISTER E, et al. Wavelet convolutions for large receptive fields [C]//European Conference on Computer Vision. Cham: Springer, 2024: 363-380.
|
|
|
| [29] |
CHEN Y, WANG Z, PENG Y, et al. Cascaded pyramid network for multi-person pose estimation [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7103–7112.
|
|
|
| [30] |
PENG J, ZHOU Y, MOK P Y. KTPFormer: kinematics and trajectory prior knowledge-enhanced transformer for 3D human pose estimation [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 1123–1132.
|
|
|
| [31] |
LIU J, LIU M, LIU H, et al. Tcpformer: Learning temporal correlation with implicit pose proxy for 3d human pose estimation [C]//Proceedings of the AAAI Conference on Artificial Intelligence. Washington: AAAI, 2025, 39(5): 5478−5486.
|
|
|
| [32] |
PAVLLO D, FEICHTENHOFER C, GRANGIER D, et al. 3D human pose estimation in video with temporal convolutions and semi-supervised training [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2020: 7745–7754.
|
|
|
| [33] |
YEH R, HU Y T, SCHWING A. Chirality nets for human pose regression [J]. Advances in Neural Information Processing Systems, 2019, 32: 8161–8171.
|
|
|
| [34] |
WANG J, YAN S, XIONG Y, et al. Motion guided 3d pose estimation from videos [C]//European Conference on Computer Vision. Cham: Springer, 2020: 764−780.
|
|
|
| [35] |
CAI Y, GE L, LIU J, et al. Exploiting spatial-temporal relationships for 3D pose estimation via graph convolutional networks [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2020: 2272–2281.
|
|
|
| [36] |
LI H, SHI B, DAI W, et al Pose-oriented transformer with uncertainty-guided refinement for 2D-to-3D human pose estimation[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2023, 37 (1): 1296- 1304
doi: 10.1609/aaai.v37i1.25213
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|