|
|
|
| Monocular 3D object detection based on context information enhancement and depth guidance |
Jiayi YU1( ),Qin WU1,2,*() ),Qin WU1,2,*() |
1. School of Artificial Intelligence and Computer Science, Jiangnan University, Wuxi 214122, China
2. Jiangsu Provincial Engineering Laboratory of Pattern Recognition and Computing Intelligence, Jiangnan University, Wuxi 214122, China |
|
|
|
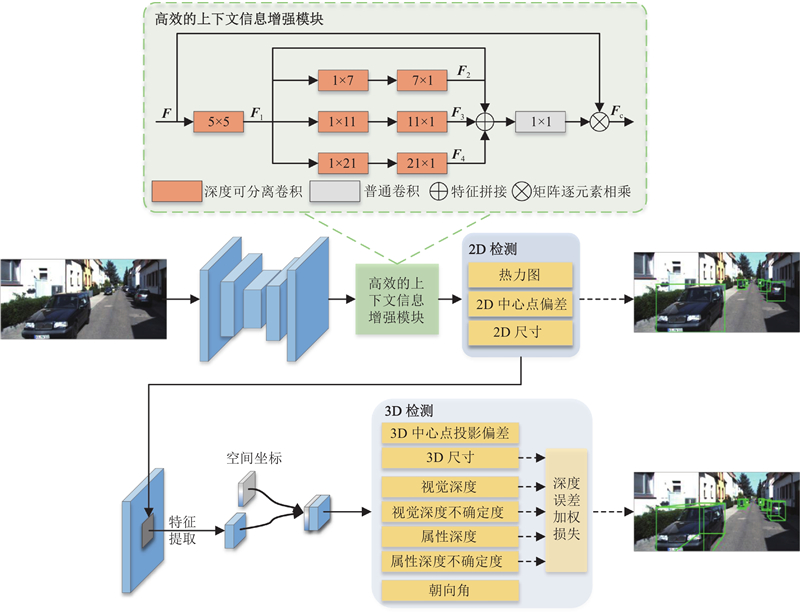
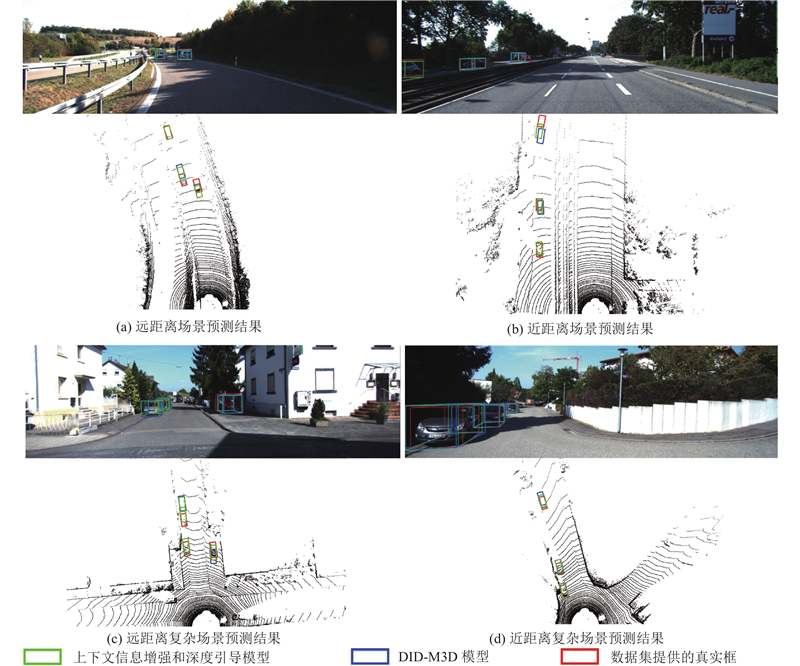
Abstract A method based on context information enhancement and depth guidance was proposed to fully utilize the feature information provided by a monocular image. An efficient context information enhancement module was proposed to adaptively enhance the context information for multi-scale objects by using multiple large kernel convolutions, and the depth-wise separable convolution and strip convolution were adopted to effectively reduce the parameter count and computational complexity associated with large kernel convolutions. The prediction errors of each attribute in the 3D object bounding box were analyzed, and the primary cause of the large deviation in the prediction bounding box is the inaccurate prediction of the length and depth of the 3D object. A depth error weighted loss function was proposed to provide supervision for the predictions of length and depth for the 3D object during the training process. By using the proposed loss function, the prediction accuracy of the length and depth attributes was improved, and the accuracy of the 3D prediction bounding box was enhanced. Experiments were conducted on the KITTI dataset, and the results showed that the proposed method achieved higher accuracy than existing monocular 3D object detection methods at multiple levels of the dataset.
|
|
Received: 29 November 2023
Published: 18 January 2025
|
|
|
| Fund: 国家自然科学基金资助项目(61972180). |
|
Corresponding Authors:
Qin WU
E-mail: 3076710949@qq.com;qinwu@jiangnan.edu.cn
|
基于上下文信息增强和深度引导的单目3D目标检测
为了充分利用单目图像提供的特征信息,提出上下文信息增强和深度引导的单目3D目标检测方法. 设计高效的上下文信息增强模块,使用多个大核卷积自适应地增强多尺度目标的上下文信息,利用深度可分离卷积和条形卷积操作有效减少大核卷积的参数量和计算复杂度. 统计分析3D目标框各个属性的预测误差,发现3D目标框的长度和深度属性预测不准确是导致预测框偏差大的主要原因. 设计深度误差加权损失函数,在训练过程中进行目标的长度和深度预测监督,提高长度和深度属性的预测精度,进而提升3D预测框的准确性. 在KITTI数据集上开展实验,结果表明,所提方法在数据集的多个级别上的平均准确度高于现有的单目3D目标检测方法.
关键词:
单目3D目标检测,
大核卷积,
深度可分离卷积,
条形卷积,
多尺度目标
|
|
| [1] |
LIU Y X, YUAN Y X, LIU M Ground-aware monocular 3D object detection for autonomous driving[J]. IEEE Robotics and Automation Letters, 2021, 6 (2): 919- 926
doi: 10.1109/LRA.2021.3052442
|
|
|
| [2] |
SIMONELLI A, BULÒ S R, PORZI L, et al. Disentangling monocular 3D object detection [C]// IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 1991–1999.
|
|
|
| [3] |
WANG Y, CHAO W L, GARG D, et al. Pseudo-LiDAR from visual depth estimation: bridging the gap in 3D object detection for autonomous driving [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 8445–8453.
|
|
|
| [4] |
MA X Z, LIU S N, XIA Z Y, et al. Rethinking pseudo-LiDAR representation [C]// European Conference on Computer Vision . Glasgow: Springer, 2020: 311–327.
|
|
|
| [5] |
PENG L, LIU F, YU Z X, et al. LiDAR point cloud guided monocular 3D object detection [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 123–139.
|
|
|
| [6] |
HONG Y, DAI H, DING Y. Cross-modality knowledge distillation network for monocular 3D object detection [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 87–104.
|
|
|
| [7] |
LIU Z D, ZHOU D F, LU F X, et al. AutoShape: real-time shape-aware monocular 3D object detection [C]/ / IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 15641–15650.
|
|
|
| [8] |
张峻宁, 苏群星, 刘鹏远, 等 基于空间约束的自适应单目3D物体检测算法[J]. 浙江大学学报: 工学版, 2020, 54 (6): 1138- 1146
ZHANG Junning, SU Qunxing, LIU Pengyuan, et al Adaptive monocular 3D object detection algorithm based on spatial constraint[J]. Journal of Zhejiang University: Engineering Science, 2020, 54 (6): 1138- 1146
|
|
|
| [9] |
LI Y Y, CHEN Y T, HE J W, et al. Densely constrained depth estimator for monocular 3D object detection [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 718–734.
|
|
|
| [10] |
LU Y, MA X Z, YANG L, et al. Geometry uncertainty projection network for monocular 3D object detection [C]// IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 3111–3121.
|
|
|
| [11] |
LIU Z C, WU Z Z, TÓTH R. SMOKE: single-stage monocular 3D object detection via keypoint estimation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops . Seattle: IEEE, 2020: 996–997.
|
|
|
| [12] |
BRAZIL G, LIU X M. M3D-RPN: monocular 3D region proposal network for object detection [C]// IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9287–9296.
|
|
|
| [13] |
ZHANG R R, QIU H, WANG T, et al. MonoDETR: depth-guided transformer for monocular 3D object detection [C]// IEEE/CVF International Conference on Computer Vision . Paris: IEEE, 2023: 9155–9166.
|
|
|
| [14] |
HUANG K C, WU T H, SU H T, et al. MonoDTR: monocular 3D object detection with depth-aware transformer [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 4012–4021.
|
|
|
| [15] |
YU F, WANG D Q, SHELHAMER E, et al. Deep layer aggregation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 2403–2412.
|
|
|
| [16] |
ZHOU X Y, WANG D Q, KRÄHENBÜHL P. Objects as points [EB/OL]. (2019–04–25)[2023–11–29]. https://arxiv.org/pdf/1904.07850.
|
|
|
| [17] |
PENG L, WU X P, YANG Z, et al. DID-M3D: decoupling instance depth for monocular 3D object detection [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 71–88.
|
|
|
| [18] |
GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite [C]// IEEE Conference on Computer Vision and Pattern Recognition . Providence: IEEE, 2012: 3354–3361.
|
|
|
| [19] |
MOUSAVIAN A, ANGUELOV D, FLYNN J, et al. 3D bounding box estimation using deep learning and geometry [C]// IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 7074–7082.
|
|
|
| [20] |
SUN P, KRETZSCHMAR H, DOTIWALLA X, et al. Scalability in perception for autonomous driving: Waymo open dataset [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 2446–2454.
|
|
|
| [21] |
READING C, HARAKEH A, CHAE J, et al. Categorical depth distribution network for monocular 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 8555–8564.
|
|
|
| [22] |
MA X Z, ZHANG Y M, XU D, et al. Delving into localization errors for monocular 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 4721–4730.
|
|
|
| [23] |
KUMAR A, BRAZIL G, LIU X M. GrooMeD-NMS: grouped mathematically differentiable NMS for monocular 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 8973–8983.
|
|
|
| [24] |
ZHOU Y S, HE Y, ZHU H Z, et al. Monocular 3D object detection: an extrinsic parameter free approach [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 7556–7566.
|
|
|
| [25] |
ZHANG Y P, LU J W, ZHOU J. Objects are different: flexible monocular 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 3289–3298.
|
|
|
| [26] |
WANG L, ZHANG L, ZHU Y, et al. Progressive coordinate transforms for monocular 3D object detection [C]// The 35th International Conference on Neural Information Processing Systems . [S. l.]: Curran Associates, 2021: 13364–13377.
|
|
|
| [27] |
QIN Z Q, LI X. MonoGround: detecting monocular 3D objects from the ground [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 3793–3802.
|
|
|
| [28] |
GU J Q, WU B J, FAN L B, et al. Homography loss for monocular 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 1080–1089.
|
|
|
| [29] |
LIAN Q, LI P L, CHEN X Z. MonoJSG: joint semantic and geometric cost volume for monocular 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 1070–1079.
|
|
|
| [30] |
KUMAR A, BRAZIL G, CORONA E, et al. DEVIANT: depth equivariant network for monocular 3D object detection [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 664–683.
|
|
|
| [31] |
ZHOU Z Y, DU L, YE X Q, et al SGM3D: stereo guided monocular 3D object detection[J]. IEEE Robotics and Automation Letters, 2022, 7 (4): 10478- 10485
doi: 10.1109/LRA.2022.3191849
|
|
|
| [32] |
LIU X P, XUE N, WU T F. Learning auxiliary monocular contexts helps monocular 3D object detection [C]// AAAI Conference on Artificial Intelligence . Vancouver: AAAI, 2022: 1810–1818.
|
|
|
| [33] |
SHI X P, CHEN Z X, KIM T K. Multivariate probabilistic monocular 3D object detection [C]// IEEE/CVF Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2023: 4281–4290.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|