|
|
|
| Dynamic sampling dual deformable network for online video instance segmentation |
Yiran SONG1( ),Qianyu ZHOU1,Zhiwen SHAO1,2,Ran YI1,Lizhuang MA1,*() ),Qianyu ZHOU1,Zhiwen SHAO1,2,Ran YI1,Lizhuang MA1,*() |
1. Department of Computer Science and Engineering, Shanghai Jiao Tong University, Shanghai 200240, China
2. College of Computer Science and Technology, China University of Mining and Technology, Xuzhou 221116, China |
|
|
|
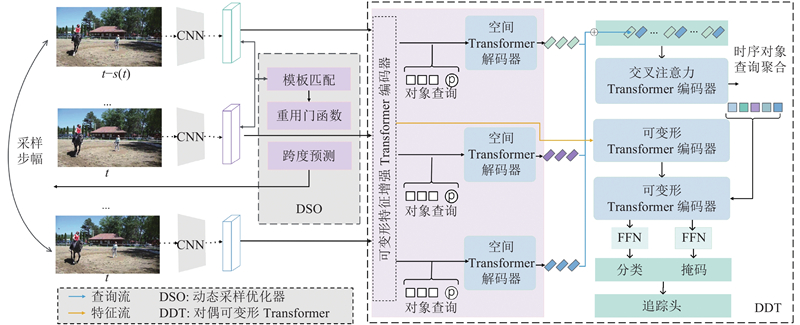
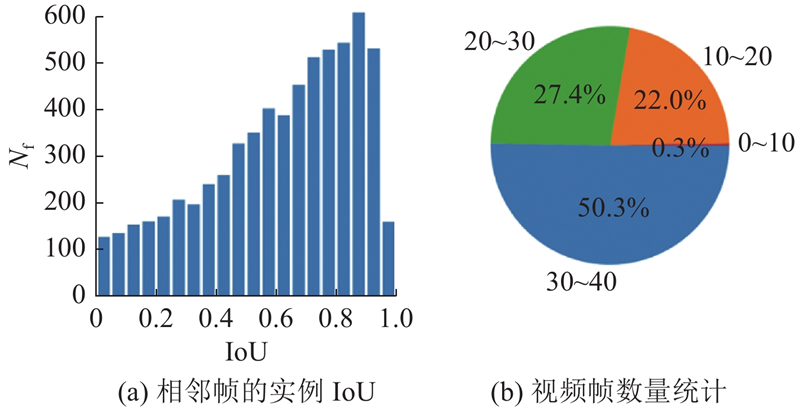
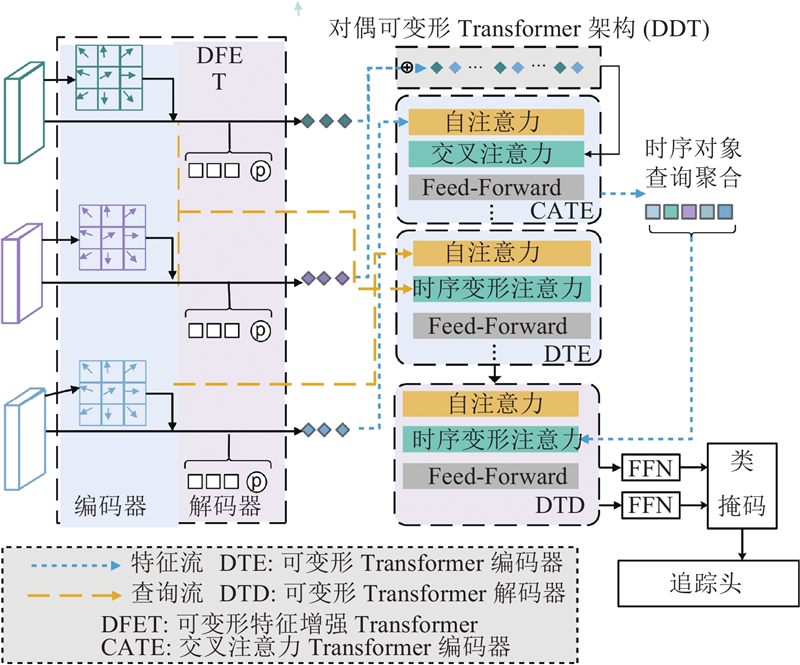
Abstract The dynamic sampling dual deformable network (DSDDN) was proposed in order to enhance the inference speed of video instance segmentation by better using temporal information within video frames. A dynamic sampling strategy was employed, which adjusted the sampling policy based on the similarity between consecutive frames. The inference process for the current frame was skipped for frames with high similarity by utilizing only segmentation results from the preceding frame for straightforward transfer computation. Frames with a larger temporal span were dynamically aggregated for frames with low similarity in order to enhance information for the current frame. Two deformable operations were additionally incorporated within the Transformer structure to circumvent the exponential computational cost associated with attention-based methods. The complex network was optimized through carefully designed tracking heads and loss functions. The proposed method achieves an inference accuracy of 39.1% mAP and an inference speed of 40.2 frames per second on the YouTube-VIS dataset, validating the effectiveness of the approach in achieving a favorable balance between accuracy and speed in real-time video segmentation tasks.
|
|
Received: 27 June 2023
Published: 23 January 2024
|
|
|
| Fund: Shanghai Science and Technology Commission (21511101200); National Natural Science Foundation of China (72192821); Shanghai Sailing Program (22YF1420300); CCF-Tencent Open Research Fund (RAGR20220121); Young Elite Scientists Sponsorship Program by CAST (2022QNRC001); National Natural Science Foundation of China (62302297) |
|
Corresponding Authors:
Lizhuang MA
E-mail: songyiran@sjtu.edu.cn;lzma@sjtu.edu.cn
|
基于动态采样对偶可变形网络的实时视频实例分割
为了更好地利用视频帧中蕴含的时间信息,提升视频实例分割的推理速度,提出动态采样对偶可变形网络 (DSDDN). DSDDN使用动态采样策略, 根据前、后帧的相似性调整采样策略. 对于相似性高的帧, 该方法跳过当前帧的推理过程,仅使用前帧分割进行简单迁移计算. 对于相似性低的帧, 该方法动态聚合时间跨度更大的视频帧作为输入,对当前帧进行信息增强. 在Transformer结构里,该方法额外使用2个可变形操作, 避免基于注意力的方法中的指数级计算量. 提供精心设计的追踪头和损失函数,优化复杂的网络. 在YouTube-VIS数据集上获得了39.1%的平均推理精度与40.2 帧/s的推理速度,验证了提出的方法能够在实时视频分割任务上取得精度与推理速度的良好平衡.
关键词:
视频,
实时推理,
实例分割,
动态网络,
对偶可变形网络
|
|
| [1] |
YANG L, FAN Y, XU N. Video instance segmentation [C] // Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 5188-5197.
|
|
|
| [2] |
CAO J, WU X, SHEN C. Sipmask: spatial information preservation for fast image and video instance segmentation [C] // European Conference on Computer Vision. Glasgow: Springer, 2020.
|
|
|
| [3] |
YANG S, ZHOU L, HUANG Q. Crossover learning for fast online video instance segmentation [C] // Proceedings of the IEEE/CVF International Conference on Computer Vision. [S. l.]: IEEE, 2021: 8043-8052.
|
|
|
| [4] |
LIU D, HUANG Y, YU J. SG-Net: spatial granularity network for one-stage video instance segmentation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2021: 9816-9825.
|
|
|
| [5] |
HE K, GAURAV G, ROSS G. Mask R-CNN [C]//Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2961-2969.
|
|
|
| [6] |
BOLYA D, WANG C, JIA Y. Yolact: real-time instance segmentation [C] // Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 9157-9166.
|
|
|
| [7] |
TIAN Z, SHEN C, CHEN H. Conditional convolutions for instance segmentation [C]// European Conference on Computer Vision. Glasgow: Springer, 2020: 282–298.
|
|
|
| [8] |
CHEN H, ZHANG X, YUAN L. BlendMask: top-down meets bottom-up for instance segmentation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2020: 8573-8581.
|
|
|
| [9] |
BERTASIUS G, TORRESANI L. Classifying, segmenting, and tracking object instances in video with mask propagation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2020: 9739-9748.
|
|
|
| [10] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C] // Advances in Neural Information Processing Systems. Los Angeles: Curran Associates, 2017: 5998-6008.
|
|
|
| [11] |
WANG Y, FAN Y, XU N. End-to-end video instance segmentation with transformers [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2021: 8741-8750.
|
|
|
| [12] |
CARION N, TOUVRON H, VEDALDI A. End-to-end object detection with transformers [C] // European Conference on Computer Vision. Cham: Springer, 2020: 213-229.
|
|
|
| [13] |
ZHU X, ZHOU D, YANG D, et al. Deformable DETR: deformable Transformers for end-to-end object detection [C] // International Conference on Learning Representations. Addis Ababa: PMLR, 2020
|
|
|
| [14] |
PARK H, KIM S, LEE J. Learning dynamic network using a reuse gate function in semi-supervised video object segmentation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2021: 8405-8414.
|
|
|
| [15] |
HE L, XIE W, YANG W. End-to-end video object detection with spatial-temporal Transformers [C] // Proceedings of the 29th ACM International Conference on Multimedia. Chengdu: ACM, 2021: 1507-1516.
|
|
|
| [16] |
HAN Y, LIU Z, YANG M Dynamic neural networks: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 44 (11): 7436- 7456
|
|
|
| [17] |
GLOROT X, BENGIO Y. Understanding the difficulty of training deep feedforward neural networks [C] // Proceedings of the 13th International Conference on Artificial Intelligence and Statistics. Belgirate: Springer, 2010: 249-256.
|
|
|
| [18] |
LI X, ZHANG Y, CHEN W Improving video instance segmentation via temporal pyramid routing[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45 (5): 6594- 6601
|
|
|
| [19] |
LI Y, LIU J, XU M. Learning dynamic routing for semantic segmentation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2020: 8553-8562.
|
|
|
| [20] |
SUN P, KUNDU J, YUAN Y. Transtrack: multiple-object tracking with Transformer [EB/OL]//[2023-06-01]. https://doi.org/10.48550/arXiv.2012.15460.
|
|
|
| [21] |
MEINHARDT T, TEICHMANN M, CIPOLLA R. Trackformer: multi-object tracking with transformers [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 8844-8854.
|
|
|
| [22] |
HWANG S, LIM S, YOON S Video instance segmentation using inter-frame communication Transformers[J]. Advances in Neural Information Processing Systems, 2021, 34: 13352- 13363
|
|
|
| [23] |
DAI J, HE K, SUN J. Deformable convolutional networks [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii: IEEE, 2017: 764-773.
|
|
|
| [24] |
MILLETARI F, NAVAB N, AHMADI S. V-Net: fully convolutional neural networks for volumetric medical image segmentation [C] // 4th International Conference on 3D Vision. Stanford University: IEEE, 2016: 565-571.
|
|
|
| [25] |
STEWART R, ANDRILOUKA M, NG A. Y. End-to-end people detection in crowded scenes [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2325-2333.
|
|
|
| [26] |
LIN T, GOYAL P, GIRSHICK R, et al. focal loss for dense object detection [C] // Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2980-2988.
|
|
|
| [27] |
WANG H, CHEN K, WANG K. Max-DeepLab: end-to-end panoptic segmentation with mask transformers [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2021: 5463-5474.
|
|
|
| [28] |
IOFFE S. SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C] // International Conference on Machine Learning. Lille: Springer, 2015: 448-456.
|
|
|
| [29] |
LIN T, MAIRE M, BELONGIE S, et al. Microsoft coco: common objects in context [C] // European conference on Computer Vision. Stockholm: Springer, 2014: 740-755.
|
|
|
| [30] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
|
|
| [31] |
FU Y, ZHANG Y, XU Y. Compfeat: comprehensive feature aggregation for video instance segmentation [C] // Proceedings of the AAAI Conference on Artificial Intelligence. [S. l.]: AAAI, 2021, 35(2): 1361-1369.
|
|
|
| [32] |
JIANG Z, GU Z, PENG J, et al. STC: spatio-temporal contrastive learning for video instance segmentation [C] // European Conference on Computer Vision. Cham: Springer, 2022: 539-556.
|
|
|
| [33] |
FUJITAKE M, SUGIMOTO A Video sparse Transformer with attention-guided memory for video object detection[J]. IEEE Access, 2022, 10: 65886- 65900
doi: 10.1109/ACCESS.2022.3184031
|
|
|
| [34] |
WU Y, BUAA K, SUN C. Detectron2 [EB/OL]. [2023-06-01]. https://github.com/facebookresearch/detectron2.2019.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|