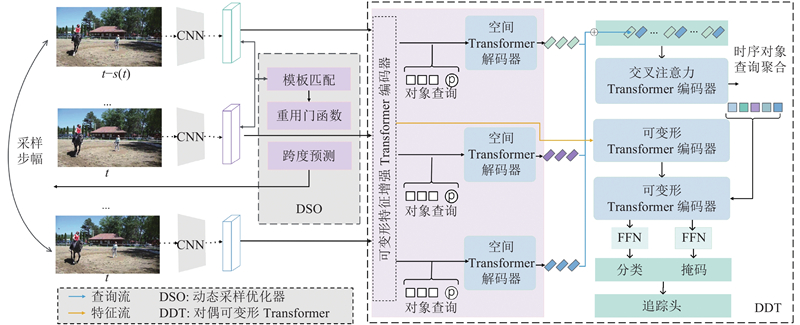
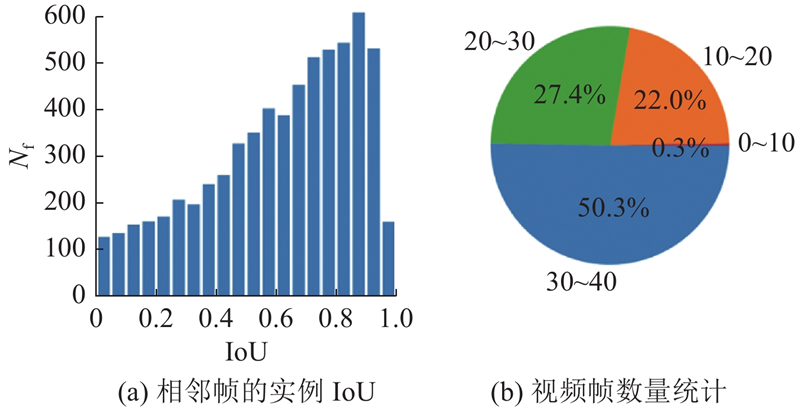
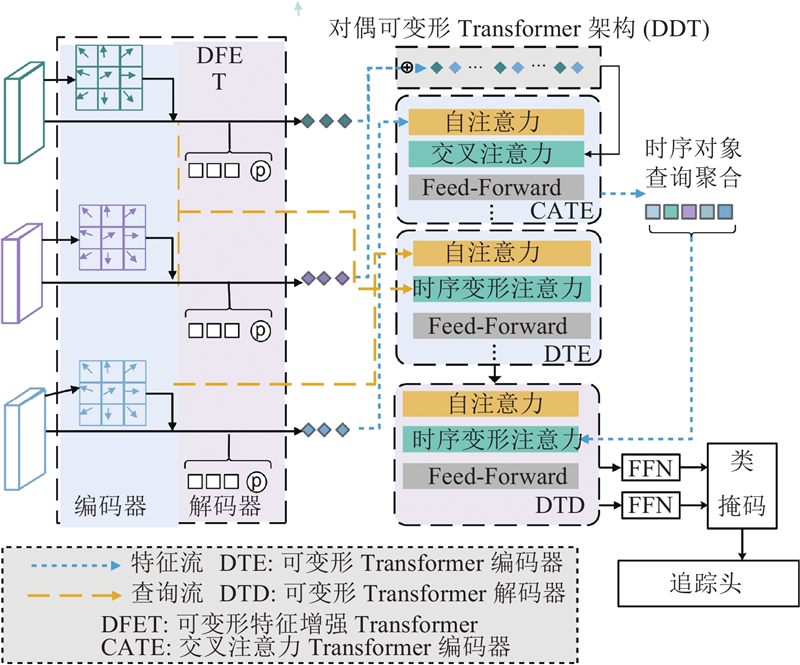
| 计算机技术、通信技术 |
|

|
|
|
| 基于动态采样对偶可变形网络的实时视频实例分割 |
宋一然1( ),周千寓1,邵志文1,2,易冉1,马利庄1,*() ),周千寓1,邵志文1,2,易冉1,马利庄1,*() |
1. 上海交通大学 计算机科学与工程系,上海 200240
2. 中国矿业大学 计算机科学与技术学院,江苏 徐州 221116 |
|
| Dynamic sampling dual deformable network for online video instance segmentation |
| Yiran SONG1(),Qianyu ZHOU1,Zhiwen SHAO1,2,Ran YI1,Lizhuang MA1,*() |
1. Department of Computer Science and Engineering, Shanghai Jiao Tong University, Shanghai 200240, China
2. College of Computer Science and Technology, China University of Mining and Technology, Xuzhou 221116, China |
引用本文:
宋一然,周千寓,邵志文,易冉,马利庄. 基于动态采样对偶可变形网络的实时视频实例分割[J]. 浙江大学学报(工学版), 2024, 58(2): 247-256.
Yiran SONG,Qianyu ZHOU,Zhiwen SHAO,Ran YI,Lizhuang MA. Dynamic sampling dual deformable network for online video instance segmentation. Journal of ZheJiang University (Engineering Science), 2024, 58(2): 247-256.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2024.02.003
或
https://www.zjujournals.com/eng/CN/Y2024/V58/I2/247
|
| 1 |
YANG L, FAN Y, XU N. Video instance segmentation [C] // Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 5188-5197.
|
| 2 |
CAO J, WU X, SHEN C. Sipmask: spatial information preservation for fast image and video instance segmentation [C] // European Conference on Computer Vision. Glasgow: Springer, 2020.
|
| 3 |
YANG S, ZHOU L, HUANG Q. Crossover learning for fast online video instance segmentation [C] // Proceedings of the IEEE/CVF International Conference on Computer Vision. [S. l.]: IEEE, 2021: 8043-8052.
|
| 4 |
LIU D, HUANG Y, YU J. SG-Net: spatial granularity network for one-stage video instance segmentation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2021: 9816-9825.
|
| 5 |
HE K, GAURAV G, ROSS G. Mask R-CNN [C]//Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2961-2969.
|
| 6 |
BOLYA D, WANG C, JIA Y. Yolact: real-time instance segmentation [C] // Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 9157-9166.
|
| 7 |
TIAN Z, SHEN C, CHEN H. Conditional convolutions for instance segmentation [C]// European Conference on Computer Vision. Glasgow: Springer, 2020: 282–298.
|
| 8 |
CHEN H, ZHANG X, YUAN L. BlendMask: top-down meets bottom-up for instance segmentation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2020: 8573-8581.
|
| 9 |
BERTASIUS G, TORRESANI L. Classifying, segmenting, and tracking object instances in video with mask propagation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2020: 9739-9748.
|
| 10 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C] // Advances in Neural Information Processing Systems. Los Angeles: Curran Associates, 2017: 5998-6008.
|
| 11 |
WANG Y, FAN Y, XU N. End-to-end video instance segmentation with transformers [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2021: 8741-8750.
|
| 12 |
CARION N, TOUVRON H, VEDALDI A. End-to-end object detection with transformers [C] // European Conference on Computer Vision. Cham: Springer, 2020: 213-229.
|
| 13 |
ZHU X, ZHOU D, YANG D, et al. Deformable DETR: deformable Transformers for end-to-end object detection [C] // International Conference on Learning Representations. Addis Ababa: PMLR, 2020
|
| 14 |
PARK H, KIM S, LEE J. Learning dynamic network using a reuse gate function in semi-supervised video object segmentation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2021: 8405-8414.
|
| 15 |
HE L, XIE W, YANG W. End-to-end video object detection with spatial-temporal Transformers [C] // Proceedings of the 29th ACM International Conference on Multimedia. Chengdu: ACM, 2021: 1507-1516.
|
| 16 |
HAN Y, LIU Z, YANG M Dynamic neural networks: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 44 (11): 7436- 7456
|
| 17 |
GLOROT X, BENGIO Y. Understanding the difficulty of training deep feedforward neural networks [C] // Proceedings of the 13th International Conference on Artificial Intelligence and Statistics. Belgirate: Springer, 2010: 249-256.
|
| 18 |
LI X, ZHANG Y, CHEN W Improving video instance segmentation via temporal pyramid routing[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45 (5): 6594- 6601
|
| 19 |
LI Y, LIU J, XU M. Learning dynamic routing for semantic segmentation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2020: 8553-8562.
|
| 20 |
SUN P, KUNDU J, YUAN Y. Transtrack: multiple-object tracking with Transformer [EB/OL]//[2023-06-01]. https://doi.org/10.48550/arXiv.2012.15460.
|
| 21 |
MEINHARDT T, TEICHMANN M, CIPOLLA R. Trackformer: multi-object tracking with transformers [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 8844-8854.
|
| 22 |
HWANG S, LIM S, YOON S Video instance segmentation using inter-frame communication Transformers[J]. Advances in Neural Information Processing Systems, 2021, 34: 13352- 13363
|
| 23 |
DAI J, HE K, SUN J. Deformable convolutional networks [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii: IEEE, 2017: 764-773.
|
| 24 |
MILLETARI F, NAVAB N, AHMADI S. V-Net: fully convolutional neural networks for volumetric medical image segmentation [C] // 4th International Conference on 3D Vision. Stanford University: IEEE, 2016: 565-571.
|
| 25 |
STEWART R, ANDRILOUKA M, NG A. Y. End-to-end people detection in crowded scenes [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2325-2333.
|
| 26 |
LIN T, GOYAL P, GIRSHICK R, et al. focal loss for dense object detection [C] // Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2980-2988.
|
| 27 |
WANG H, CHEN K, WANG K. Max-DeepLab: end-to-end panoptic segmentation with mask transformers [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2021: 5463-5474.
|
| 28 |
IOFFE S. SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C] // International Conference on Machine Learning. Lille: Springer, 2015: 448-456.
|
| 29 |
LIN T, MAIRE M, BELONGIE S, et al. Microsoft coco: common objects in context [C] // European conference on Computer Vision. Stockholm: Springer, 2014: 740-755.
|
| 30 |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
| 31 |
FU Y, ZHANG Y, XU Y. Compfeat: comprehensive feature aggregation for video instance segmentation [C] // Proceedings of the AAAI Conference on Artificial Intelligence. [S. l.]: AAAI, 2021, 35(2): 1361-1369.
|
| 32 |
JIANG Z, GU Z, PENG J, et al. STC: spatio-temporal contrastive learning for video instance segmentation [C] // European Conference on Computer Vision. Cham: Springer, 2022: 539-556.
|
| 33 |
FUJITAKE M, SUGIMOTO A Video sparse Transformer with attention-guided memory for video object detection[J]. IEEE Access, 2022, 10: 65886- 65900
doi: 10.1109/ACCESS.2022.3184031
|
| 34 |
WU Y, BUAA K, SUN C. Detectron2 [EB/OL]. [2023-06-01]. https://github.com/facebookresearch/detectron2.2019.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|