[1]
YANG L, FAN Y, XU N. Video instance segmentation [C] // Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 5188-5197.
[本文引用: 6]
[2]
CAO J, WU X, SHEN C. Sipmask: spatial information preservation for fast image and video instance segmentation [C] // European Conference on Computer Vision . Glasgow: Springer, 2020.
[本文引用: 5]
[3]
YANG S, ZHOU L, HUANG Q. Crossover learning for fast online video instance segmentation [C] // Proceedings of the IEEE/CVF International Conference on Computer Vision . [S. l.]: IEEE, 2021: 8043-8052.
[本文引用: 5]
[4]
LIU D, HUANG Y, YU J. SG-Net: spatial granularity network for one-stage video instance segmentation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l.]: IEEE, 2021: 9816-9825.
[本文引用: 2]
[5]
HE K, GAURAV G, ROSS G. Mask R-CNN [C]//Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2961-2969.
[本文引用: 1]
[6]
BOLYA D, WANG C, JIA Y. Yolact: real-time instance segmentation [C] // Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9157-9166.
[7]
TIAN Z, SHEN C, CHEN H. Conditional convolutions for instance segmentation [C]// European Conference on Computer Vision . Glasgow: Springer, 2020: 282–298.
[8]
CHEN H, ZHANG X, YUAN L. BlendMask: top-down meets bottom-up for instance segmentation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l.]: IEEE, 2020: 8573-8581.
[本文引用: 5]
[9]
BERTASIUS G, TORRESANI L. Classifying, segmenting, and tracking object instances in video with mask propagation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l.]: IEEE, 2020: 9739-9748.
[本文引用: 2]
[10]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C] // Advances in Neural Information Processing Systems . Los Angeles: Curran Associates, 2017: 5998-6008.
[本文引用: 4]
[11]
WANG Y, FAN Y, XU N. End-to-end video instance segmentation with transformers [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l.]: IEEE, 2021: 8741-8750.
[本文引用: 5]
[12]
CARION N, TOUVRON H, VEDALDI A. End-to-end object detection with transformers [C] // European Conference on Computer Vision . Cham: Springer, 2020: 213-229.
[本文引用: 6]
[13]
ZHU X, ZHOU D, YANG D, et al. Deformable DETR: deformable Transformers for end-to-end object detection [C] // International Conference on Learning Representations . Addis Ababa: PMLR, 2020
[本文引用: 7]
[14]
PARK H, KIM S, LEE J. Learning dynamic network using a reuse gate function in semi-supervised video object segmentation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l.]: IEEE, 2021: 8405-8414.
[本文引用: 3]
[15]
HE L, XIE W, YANG W. End-to-end video object detection with spatial-temporal Transformers [C] // Proceedings of the 29th ACM International Conference on Multimedia . Chengdu: ACM, 2021: 1507-1516.
[本文引用: 3]
[16]
HAN Y, LIU Z, YANG M Dynamic neural networks: a survey
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2021 , 44 (11 ): 7436 - 7456
[17]
GLOROT X, BENGIO Y. Understanding the difficulty of training deep feedforward neural networks [C] // Proceedings of the 13th International Conference on Artificial Intelligence and Statistics. Belgirate: Springer, 2010: 249-256.
[本文引用: 1]
[18]
LI X, ZHANG Y, CHEN W Improving video instance segmentation via temporal pyramid routing
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 45 (5 ): 6594 - 6601
[本文引用: 1]
[19]
LI Y, LIU J, XU M. Learning dynamic routing for semantic segmentation [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l.]: IEEE, 2020: 8553-8562.
[本文引用: 1]
[20]
SUN P, KUNDU J, YUAN Y. Transtrack: multiple-object tracking with Transformer [EB/OL]//[2023-06-01]. https://doi.org/10.48550/arXiv.2012.15460.
[本文引用: 1]
[21]
MEINHARDT T, TEICHMANN M, CIPOLLA R. Trackformer: multi-object tracking with transformers [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 8844-8854.
[22]
HWANG S, LIM S, YOON S Video instance segmentation using inter-frame communication Transformers
[J]. Advances in Neural Information Processing Systems , 2021 , 34 : 13352 - 13363
[本文引用: 8]
[23]
DAI J, HE K, SUN J. Deformable convolutional networks [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Honolulu, Hawaii: IEEE, 2017: 764-773.
[本文引用: 1]
[24]
MILLETARI F, NAVAB N, AHMADI S. V-Net: fully convolutional neural networks for volumetric medical image segmentation [C] // 4th International Conference on 3D Vision . Stanford University: IEEE, 2016: 565-571.
[本文引用: 2]
[25]
STEWART R, ANDRILOUKA M, NG A. Y. End-to-end people detection in crowded scenes [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 2325-2333.
[本文引用: 1]
[26]
LIN T, GOYAL P, GIRSHICK R, et al. focal loss for dense object detection [C] // Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2980-2988.
[本文引用: 2]
[27]
WANG H, CHEN K, WANG K. Max-DeepLab: end-to-end panoptic segmentation with mask transformers [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l.]: IEEE, 2021: 5463-5474.
[本文引用: 1]
[28]
IOFFE S. SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C] // International Conference on Machine Learning . Lille: Springer, 2015: 448-456.
[本文引用: 1]
[29]
LIN T, MAIRE M, BELONGIE S, et al. Microsoft coco: common objects in context [C] // European conference on Computer Vision . Stockholm: Springer, 2014: 740-755.
[本文引用: 1]
[30]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 2]
[31]
FU Y, ZHANG Y, XU Y. Compfeat: comprehensive feature aggregation for video instance segmentation [C] // Proceedings of the AAAI Conference on Artificial Intelligence . [S. l.]: AAAI, 2021, 35(2): 1361-1369.
[本文引用: 2]
[32]
JIANG Z, GU Z, PENG J, et al. STC: spatio-temporal contrastive learning for video instance segmentation [C] // European Conference on Computer Vision . Cham: Springer, 2022: 539-556.
[本文引用: 1]
[33]
FUJITAKE M, SUGIMOTO A Video sparse Transformer with attention-guided memory for video object detection
[J]. IEEE Access , 2022 , 10 : 65886 - 65900
DOI:10.1109/ACCESS.2022.3184031
[本文引用: 1]
[34]
WU Y, BUAA K, SUN C. Detectron2 [EB/OL]. [2023-06-01]. https://github.com/facebookresearch/detectron2.2019.
[本文引用: 1]
[35]
ATHAR A, BAAQUE M. A, KITTANEH S. Stem-seg: spatio-temporal embeddings for instance segmentation in videos [C] // European Conference on Computer Vision . Göttingen: Springer, 2020: 158-177.
[本文引用: 1]
6
... 视频实例分割(video instance segmentation,VIS)是多任务问题,目的是在视频帧中进行物体检测、实例分割和物体跟踪[1 ] . 许多最先进的方法[1 -4 ] 是将图像实例分割模型[5 -8 ] 扩展到视频领域. 这些逐帧处理的方法可以处理一些简单的情况,但不能解决视频中经常出现的部分遮挡和运动模糊问题. 为了解决该问题,许多方法提出特征聚合的思路,以片段方式作为输入来增强时间上的关联性. Mask-Prop[9 ] 提出增加掩码传播分支,将帧级实例对象掩码从每一帧视频传播到视频片段中的所有其他帧. 以前的视频分割方法是通过输入固定长度的clip来进行推理,该方法有利于提升模糊帧的分割精度,但导致静止或缓慢移动的帧产生了大量不必要的计算. ...
... [1 -4 ]是将图像实例分割模型[5 -8 ] 扩展到视频领域. 这些逐帧处理的方法可以处理一些简单的情况,但不能解决视频中经常出现的部分遮挡和运动模糊问题. 为了解决该问题,许多方法提出特征聚合的思路,以片段方式作为输入来增强时间上的关联性. Mask-Prop[9 ] 提出增加掩码传播分支,将帧级实例对象掩码从每一帧视频传播到视频片段中的所有其他帧. 以前的视频分割方法是通过输入固定长度的clip来进行推理,该方法有利于提升模糊帧的分割精度,但导致静止或缓慢移动的帧产生了大量不必要的计算. ...
... 视频实例分割 (VIS)任务是多任务问题,在YouTube-VIS 2019[1 ] 挑战中首次提出. 这项任务需要执行对象检测、实例分割和跨帧追踪同一实例等多个任务,这将追踪的概念延伸到了图像实例分割任务中. 早期的工作是在每一帧pipeline中单独和连续地执行每个单独的任务,利用额外的追踪头来建立模型. 以前的模型主要是为了解决图像实例分割的问题而设计的[1 -2 ] . 整个训练流程很复杂,速度很慢. ...
... [1 -2 ]. 整个训练流程很复杂,速度很慢. ...
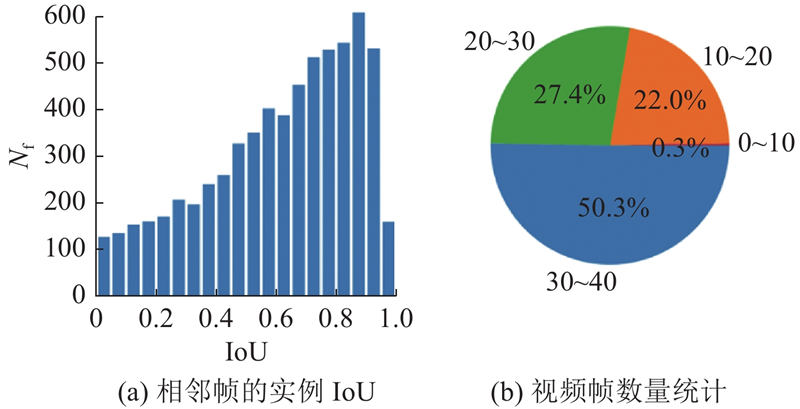
... 在实验中,使用YouTube-VIS 2019[1 ] 作为主要数据集. 它有大约9万张图片,有40个类别,来自近3千种不同的视频. 如图2(a) 所示为同一个实例相邻帧的IoU计算. 图中,N f 为帧的个数. IoU越大,表示该实例越静止. 如图2(b) 所示为VIS数据集里包含不同帧数的视频所占的比例. 图2 的分析体现了视频中由于实例的慢动作和固定摄像机而导致重叠的严重程度. 可以看出,这些视频存在严重的帧内容重合现象,大约一半的视频有30~39帧. 这些数据为模型在Transformer架构前添加动态采样模块提供了支持. DSDDN的采样模块可以在当前帧和之前帧重复度极高的时候,选择跳过当前帧的推理,直接使用之前帧的结果进行轻量的位移计算. 采用该操作,极大地减小了帧的计算成本,使得模型在效率和准确性方面得到了更好的平衡. ...
... 在推理过程中,遵循与训练相同的比例设置. 输入视频被缩小到360像素,以减少计算费用. 该模型只提取前10个实例的预测,因为YouTube-VIS数据集中的大多数帧都不超过10个实例. 受文献[1 ]的启发,本文发现只基于式(14)进行跨视频的实例追踪是不稳定的. 本文为实时关联推理加入了一些线索,在测试阶段,将标签$ n $ $ {\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{{\boldsymbol{y}}}}_{i} $
5
... 视频实例分割 (VIS)任务是多任务问题,在YouTube-VIS 2019[1 ] 挑战中首次提出. 这项任务需要执行对象检测、实例分割和跨帧追踪同一实例等多个任务,这将追踪的概念延伸到了图像实例分割任务中. 早期的工作是在每一帧pipeline中单独和连续地执行每个单独的任务,利用额外的追踪头来建立模型. 以前的模型主要是为了解决图像实例分割的问题而设计的[1 -2 ] . 整个训练流程很复杂,速度很慢. ...
... 本文的方法DSDDN在2个具有挑战性的视频实例分割基准数据集上进行测试,即 YouTube-VIS 2019和YouTube-VIS 2021[2 ] ,以衡量其性能. 其中2019年版本中有2883个视频、40个类别,2021年版本中有3800多个视频. ...
... Comparisons of video instance segmentation on YouTube-VIS 2019 validation dataset
Tab.1 方法 mAP/% AP50/% AP75/% MaskTrack R-CNN 50[8 ] 30.3 51.1 32.6 MaskTrack R-CNN 101[8 ] 41.8 53.0 33.6 MaskProp 50 [10 ] 40.0 — 42.9 MaskProp 101 [10 ] 42.5 — 45.6 *VisTR 50 [11 ] 36.2 59.8 36.9 *VisTR 101 [11 ] 40.1 64.0 45.0 CrossVIS 50 [3 ] 36.3 56.8 38.9 CrossVIS 101[3 ] 36.6 57.3 39.7 CompFeat 50 [31 ] 35.3 56.0 38.6 *IFC 50 [22 ] 41.0 62.1 45.4 STC [32 ] 36.7 57.2 38.6 VSTAM [33 ] 39.0 62.9 41.8 SipMask 50 [2 ] 33.7 54.1 35.8 DSDDN 50 37.5 59.1 41.9 DSDDN 101 39.1 60.7 43.5
遵循表1 的相同设置,使用detectron2[34 ] 来测量推理速度. 除非特别说明,所有用于测量的模型都使用ResNet-50作为CNN主干,将帧尺寸下采样为360像素. DSDDN使用ResNet-50,推理速度v 达到41.2帧/s,mAP达到41.5%,如表2 所示,作为离线模型,在VisTR模型里,设置T = 36. 该设置显著增大了它的推理速度. 与其他实时和近似实时的方法相比,DSDDN获得了更好的表现. 本文方法在所有实时和接近实时的方法中具有竞争力. ...
... Efficiency comparisons on YouTube-VIS-2019 validation set
Tab.2 方法 类型 v /(帧·s−1 )mAP/% MaskTrack R-CNN[8 ] online 32.8 30.3 CrossVIS [3 ] online 39.8 34.8 VisTR [11 ] offline 51.1 36.2 CompFeat[31 ] online 32.8 35.3 SipMask [2 ] online 35.5 33.7 STEm-Seg [35 ] Near Online 4.40 34.6 DSDDN online 40.2 37.5
YouTube-VIS 2021是YouTube-VIS 2019的补充版,完善了视频的类别,扩大了数据集的样本数量. 使用官方实现的方法进行评估. 表3 的结果显示,本文方法超过了大多数最先进的方法. ...
... Accuracy comparison based on YouTube-VIS 2021 validation set
Tab.3 方法 mAP/% AP50/% AP75/% MaskTrack-RCNN [9 ] 28.6 48.9 29.6 SipMask [2 ] 31.7 52.5 34.0 CrossVIS [3 ] 34.2 54.4 37.9 IFC [22 ] 36.6 57.9 39.3 DSDDN 34.8 55.9 37.4
3.3. 消融学习 在YouTube-VIS 2019 验证集上进行实验,使用ResNet-50作为骨干. ...
5
... 使用${\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\boldsymbol{y}}}_{i}$ 3 ]类似,采用一组可学习的实例权重$[{\boldsymbol{\omega} }_{1},{{\boldsymbol{\omega}} }_{2},\cdots ,{{\boldsymbol{\omega}} }_{n}]$ $ n $
... Comparisons of video instance segmentation on YouTube-VIS 2019 validation dataset
Tab.1 方法 mAP/% AP50/% AP75/% MaskTrack R-CNN 50[8 ] 30.3 51.1 32.6 MaskTrack R-CNN 101[8 ] 41.8 53.0 33.6 MaskProp 50 [10 ] 40.0 — 42.9 MaskProp 101 [10 ] 42.5 — 45.6 *VisTR 50 [11 ] 36.2 59.8 36.9 *VisTR 101 [11 ] 40.1 64.0 45.0 CrossVIS 50 [3 ] 36.3 56.8 38.9 CrossVIS 101[3 ] 36.6 57.3 39.7 CompFeat 50 [31 ] 35.3 56.0 38.6 *IFC 50 [22 ] 41.0 62.1 45.4 STC [32 ] 36.7 57.2 38.6 VSTAM [33 ] 39.0 62.9 41.8 SipMask 50 [2 ] 33.7 54.1 35.8 DSDDN 50 37.5 59.1 41.9 DSDDN 101 39.1 60.7 43.5
遵循表1 的相同设置,使用detectron2[34 ] 来测量推理速度. 除非特别说明,所有用于测量的模型都使用ResNet-50作为CNN主干,将帧尺寸下采样为360像素. DSDDN使用ResNet-50,推理速度v 达到41.2帧/s,mAP达到41.5%,如表2 所示,作为离线模型,在VisTR模型里,设置T = 36. 该设置显著增大了它的推理速度. 与其他实时和近似实时的方法相比,DSDDN获得了更好的表现. 本文方法在所有实时和接近实时的方法中具有竞争力. ...
... [
3 ]
36.6 57.3 39.7 CompFeat 50 [31 ] 35.3 56.0 38.6 *IFC 50 [22 ] 41.0 62.1 45.4 STC [32 ] 36.7 57.2 38.6 VSTAM [33 ] 39.0 62.9 41.8 SipMask 50 [2 ] 33.7 54.1 35.8 DSDDN 50 37.5 59.1 41.9 DSDDN 101 39.1 60.7 43.5 遵循表1 的相同设置,使用detectron2[34 ] 来测量推理速度. 除非特别说明,所有用于测量的模型都使用ResNet-50作为CNN主干,将帧尺寸下采样为360像素. DSDDN使用ResNet-50,推理速度v 达到41.2帧/s,mAP达到41.5%,如表2 所示,作为离线模型,在VisTR模型里,设置T = 36. 该设置显著增大了它的推理速度. 与其他实时和近似实时的方法相比,DSDDN获得了更好的表现. 本文方法在所有实时和接近实时的方法中具有竞争力. ...
... Efficiency comparisons on YouTube-VIS-2019 validation set
Tab.2 方法 类型 v /(帧·s−1 )mAP/% MaskTrack R-CNN[8 ] online 32.8 30.3 CrossVIS [3 ] online 39.8 34.8 VisTR [11 ] offline 51.1 36.2 CompFeat[31 ] online 32.8 35.3 SipMask [2 ] online 35.5 33.7 STEm-Seg [35 ] Near Online 4.40 34.6 DSDDN online 40.2 37.5
YouTube-VIS 2021是YouTube-VIS 2019的补充版,完善了视频的类别,扩大了数据集的样本数量. 使用官方实现的方法进行评估. 表3 的结果显示,本文方法超过了大多数最先进的方法. ...
... Accuracy comparison based on YouTube-VIS 2021 validation set
Tab.3 方法 mAP/% AP50/% AP75/% MaskTrack-RCNN [9 ] 28.6 48.9 29.6 SipMask [2 ] 31.7 52.5 34.0 CrossVIS [3 ] 34.2 54.4 37.9 IFC [22 ] 36.6 57.9 39.3 DSDDN 34.8 55.9 37.4
3.3. 消融学习 在YouTube-VIS 2019 验证集上进行实验,使用ResNet-50作为骨干. ...
2
... 视频实例分割(video instance segmentation,VIS)是多任务问题,目的是在视频帧中进行物体检测、实例分割和物体跟踪[1 ] . 许多最先进的方法[1 -4 ] 是将图像实例分割模型[5 -8 ] 扩展到视频领域. 这些逐帧处理的方法可以处理一些简单的情况,但不能解决视频中经常出现的部分遮挡和运动模糊问题. 为了解决该问题,许多方法提出特征聚合的思路,以片段方式作为输入来增强时间上的关联性. Mask-Prop[9 ] 提出增加掩码传播分支,将帧级实例对象掩码从每一帧视频传播到视频片段中的所有其他帧. 以前的视频分割方法是通过输入固定长度的clip来进行推理,该方法有利于提升模糊帧的分割精度,但导致静止或缓慢移动的帧产生了大量不必要的计算. ...
... Liu等[4 , 12 ] 提出了更先进的算法. 这些算法考虑视频的特点,能够同时训练空间和时间维度的模型,改善了结果的性能. 通过利用多帧,这些模型可以处理视频中的典型挑战,即运动模糊和遮挡. 这种聚合提高了每一帧的计算成本,减小了推理速度. 本文的模型作为一种实时方法,旨在以低延迟的方式实现准确的预测. ...
1
... 视频实例分割(video instance segmentation,VIS)是多任务问题,目的是在视频帧中进行物体检测、实例分割和物体跟踪[1 ] . 许多最先进的方法[1 -4 ] 是将图像实例分割模型[5 -8 ] 扩展到视频领域. 这些逐帧处理的方法可以处理一些简单的情况,但不能解决视频中经常出现的部分遮挡和运动模糊问题. 为了解决该问题,许多方法提出特征聚合的思路,以片段方式作为输入来增强时间上的关联性. Mask-Prop[9 ] 提出增加掩码传播分支,将帧级实例对象掩码从每一帧视频传播到视频片段中的所有其他帧. 以前的视频分割方法是通过输入固定长度的clip来进行推理,该方法有利于提升模糊帧的分割精度,但导致静止或缓慢移动的帧产生了大量不必要的计算. ...
5
... 视频实例分割(video instance segmentation,VIS)是多任务问题,目的是在视频帧中进行物体检测、实例分割和物体跟踪[1 ] . 许多最先进的方法[1 -4 ] 是将图像实例分割模型[5 -8 ] 扩展到视频领域. 这些逐帧处理的方法可以处理一些简单的情况,但不能解决视频中经常出现的部分遮挡和运动模糊问题. 为了解决该问题,许多方法提出特征聚合的思路,以片段方式作为输入来增强时间上的关联性. Mask-Prop[9 ] 提出增加掩码传播分支,将帧级实例对象掩码从每一帧视频传播到视频片段中的所有其他帧. 以前的视频分割方法是通过输入固定长度的clip来进行推理,该方法有利于提升模糊帧的分割精度,但导致静止或缓慢移动的帧产生了大量不必要的计算. ...
... YouTube-VIS 2019 验证结果如表1 所示,带*的方法表示离线模型,它们使用更多的参考信息,具有显著的推理延迟. 表中,mAP(mean average precision)为平均精度的平均值,AP50、AP75分别为IoU阈值为50%和75%时的平均精度. 将提出的方法与现有的具有不同骨架的最先进的VIS方法 (如ResNet 50和ResNet 101) 进行比较. 使用mAP指标来进行模型对比. mAP是常用于评估目标检测、实例分割、全景分割等计算机视觉任务性能的指标. mAP结合准确率(precision)和召回率(recall),通过计算在不同置信度阈值下的平均精度来衡量模型的性能. 设计DSDDN,它能够动态采样视频帧,在pipeline里增加对偶可变形操作. 通过AP来衡量准确性,利用本文的实时方法得到了有竞争力的分数. 这表明利用提出的方法可以准确地检测类别、分割实例掩码,并在帧上跟踪物体. 特别地是,若要采用输入为Clip而不是逐帧输入的方法,则须减小Clip的长度T ,使得Clip方法接近于实时逐帧推理. 根据文献[22 ]可知,在IFC[22 ] 中设置T = 5,在MaskProb[8 ] 中设置T = 13,这对实时推理来说存在很小的延迟. ...
... Comparisons of video instance segmentation on YouTube-VIS 2019 validation dataset
Tab.1 方法 mAP/% AP50/% AP75/% MaskTrack R-CNN 50[8 ] 30.3 51.1 32.6 MaskTrack R-CNN 101[8 ] 41.8 53.0 33.6 MaskProp 50 [10 ] 40.0 — 42.9 MaskProp 101 [10 ] 42.5 — 45.6 *VisTR 50 [11 ] 36.2 59.8 36.9 *VisTR 101 [11 ] 40.1 64.0 45.0 CrossVIS 50 [3 ] 36.3 56.8 38.9 CrossVIS 101[3 ] 36.6 57.3 39.7 CompFeat 50 [31 ] 35.3 56.0 38.6 *IFC 50 [22 ] 41.0 62.1 45.4 STC [32 ] 36.7 57.2 38.6 VSTAM [33 ] 39.0 62.9 41.8 SipMask 50 [2 ] 33.7 54.1 35.8 DSDDN 50 37.5 59.1 41.9 DSDDN 101 39.1 60.7 43.5
遵循表1 的相同设置,使用detectron2[34 ] 来测量推理速度. 除非特别说明,所有用于测量的模型都使用ResNet-50作为CNN主干,将帧尺寸下采样为360像素. DSDDN使用ResNet-50,推理速度v 达到41.2帧/s,mAP达到41.5%,如表2 所示,作为离线模型,在VisTR模型里,设置T = 36. 该设置显著增大了它的推理速度. 与其他实时和近似实时的方法相比,DSDDN获得了更好的表现. 本文方法在所有实时和接近实时的方法中具有竞争力. ...
... [
8 ]
41.8 53.0 33.6 MaskProp 50 [10 ] 40.0 — 42.9 MaskProp 101 [10 ] 42.5 — 45.6 *VisTR 50 [11 ] 36.2 59.8 36.9 *VisTR 101 [11 ] 40.1 64.0 45.0 CrossVIS 50 [3 ] 36.3 56.8 38.9 CrossVIS 101[3 ] 36.6 57.3 39.7 CompFeat 50 [31 ] 35.3 56.0 38.6 *IFC 50 [22 ] 41.0 62.1 45.4 STC [32 ] 36.7 57.2 38.6 VSTAM [33 ] 39.0 62.9 41.8 SipMask 50 [2 ] 33.7 54.1 35.8 DSDDN 50 37.5 59.1 41.9 DSDDN 101 39.1 60.7 43.5 遵循表1 的相同设置,使用detectron2[34 ] 来测量推理速度. 除非特别说明,所有用于测量的模型都使用ResNet-50作为CNN主干,将帧尺寸下采样为360像素. DSDDN使用ResNet-50,推理速度v 达到41.2帧/s,mAP达到41.5%,如表2 所示,作为离线模型,在VisTR模型里,设置T = 36. 该设置显著增大了它的推理速度. 与其他实时和近似实时的方法相比,DSDDN获得了更好的表现. 本文方法在所有实时和接近实时的方法中具有竞争力. ...
... Efficiency comparisons on YouTube-VIS-2019 validation set
Tab.2 方法 类型 v /(帧·s−1 )mAP/% MaskTrack R-CNN[8 ] online 32.8 30.3 CrossVIS [3 ] online 39.8 34.8 VisTR [11 ] offline 51.1 36.2 CompFeat[31 ] online 32.8 35.3 SipMask [2 ] online 35.5 33.7 STEm-Seg [35 ] Near Online 4.40 34.6 DSDDN online 40.2 37.5
YouTube-VIS 2021是YouTube-VIS 2019的补充版,完善了视频的类别,扩大了数据集的样本数量. 使用官方实现的方法进行评估. 表3 的结果显示,本文方法超过了大多数最先进的方法. ...
2
... 视频实例分割(video instance segmentation,VIS)是多任务问题,目的是在视频帧中进行物体检测、实例分割和物体跟踪[1 ] . 许多最先进的方法[1 -4 ] 是将图像实例分割模型[5 -8 ] 扩展到视频领域. 这些逐帧处理的方法可以处理一些简单的情况,但不能解决视频中经常出现的部分遮挡和运动模糊问题. 为了解决该问题,许多方法提出特征聚合的思路,以片段方式作为输入来增强时间上的关联性. Mask-Prop[9 ] 提出增加掩码传播分支,将帧级实例对象掩码从每一帧视频传播到视频片段中的所有其他帧. 以前的视频分割方法是通过输入固定长度的clip来进行推理,该方法有利于提升模糊帧的分割精度,但导致静止或缓慢移动的帧产生了大量不必要的计算. ...
... Accuracy comparison based on YouTube-VIS 2021 validation set
Tab.3 方法 mAP/% AP50/% AP75/% MaskTrack-RCNN [9 ] 28.6 48.9 29.6 SipMask [2 ] 31.7 52.5 34.0 CrossVIS [3 ] 34.2 54.4 37.9 IFC [22 ] 36.6 57.9 39.3 DSDDN 34.8 55.9 37.4
3.3. 消融学习 在YouTube-VIS 2019 验证集上进行实验,使用ResNet-50作为骨干. ...
4
... 最近,Transformer[10 ] 模型的提出对VIS任务产生了极大的影响. VisTR[11 ] 被提出,它通过DETR[12 ] 结构处理VIS任务,减少了推理时间,这显示了Transformer在解决VIS领域的任务上有着极大的发展前景. 自注意Transformer训练速度极慢. 这是因为自注意层的参数量是指数级的,它需要使用较长的训练时间来学习稀疏的有意义的位置,这增加了实时模型进行增量学习的成本. 类似的问题在文献[13 ]里也被提及,为了解决该问题,Deformable DETR[13 ] 通过增加空间变形操作,加速Transformer的收敛. 受到相关工作的启发,本文用2个可变形的操作来优化Transformer pipeline,本文方法在时间和空间维度都使用了变性操作,避免了注意力层指数复杂度的计算,减少了逐帧分割的计算量,提高了模型的收敛速度,减少了增量学习的训练成本. ...
... 最近,Transformer[10 ] 受到极大的关注,影响了许多任务. Carion等[12 ] 提出DETR,以消除对许多手工设计的组件的需求. DETR存在收敛速度慢和特征空间分辨率有限的问题. Deformable DETR[12 ] 由于其快速收敛,为利用端到端物体检测器的变体提供了可能性. Sun等[20 -22 ] 将Transformer应用于视频理解,例如视频实例分割(video instance segmentation,VIS)、多物体跟踪(multiple object tracking,MOT). 本文发现,逐片段的处理流程显示出比逐帧的方法更优越的性能,因为后者的方法只利用前一帧的有限时间信息,无法很好地解决图片中的模糊和遮挡问题. ...
... Comparisons of video instance segmentation on YouTube-VIS 2019 validation dataset
Tab.1 方法 mAP/% AP50/% AP75/% MaskTrack R-CNN 50[8 ] 30.3 51.1 32.6 MaskTrack R-CNN 101[8 ] 41.8 53.0 33.6 MaskProp 50 [10 ] 40.0 — 42.9 MaskProp 101 [10 ] 42.5 — 45.6 *VisTR 50 [11 ] 36.2 59.8 36.9 *VisTR 101 [11 ] 40.1 64.0 45.0 CrossVIS 50 [3 ] 36.3 56.8 38.9 CrossVIS 101[3 ] 36.6 57.3 39.7 CompFeat 50 [31 ] 35.3 56.0 38.6 *IFC 50 [22 ] 41.0 62.1 45.4 STC [32 ] 36.7 57.2 38.6 VSTAM [33 ] 39.0 62.9 41.8 SipMask 50 [2 ] 33.7 54.1 35.8 DSDDN 50 37.5 59.1 41.9 DSDDN 101 39.1 60.7 43.5
遵循表1 的相同设置,使用detectron2[34 ] 来测量推理速度. 除非特别说明,所有用于测量的模型都使用ResNet-50作为CNN主干,将帧尺寸下采样为360像素. DSDDN使用ResNet-50,推理速度v 达到41.2帧/s,mAP达到41.5%,如表2 所示,作为离线模型,在VisTR模型里,设置T = 36. 该设置显著增大了它的推理速度. 与其他实时和近似实时的方法相比,DSDDN获得了更好的表现. 本文方法在所有实时和接近实时的方法中具有竞争力. ...
... [
10 ]
42.5 — 45.6 *VisTR 50 [11 ] 36.2 59.8 36.9 *VisTR 101 [11 ] 40.1 64.0 45.0 CrossVIS 50 [3 ] 36.3 56.8 38.9 CrossVIS 101[3 ] 36.6 57.3 39.7 CompFeat 50 [31 ] 35.3 56.0 38.6 *IFC 50 [22 ] 41.0 62.1 45.4 STC [32 ] 36.7 57.2 38.6 VSTAM [33 ] 39.0 62.9 41.8 SipMask 50 [2 ] 33.7 54.1 35.8 DSDDN 50 37.5 59.1 41.9 DSDDN 101 39.1 60.7 43.5 遵循表1 的相同设置,使用detectron2[34 ] 来测量推理速度. 除非特别说明,所有用于测量的模型都使用ResNet-50作为CNN主干,将帧尺寸下采样为360像素. DSDDN使用ResNet-50,推理速度v 达到41.2帧/s,mAP达到41.5%,如表2 所示,作为离线模型,在VisTR模型里,设置T = 36. 该设置显著增大了它的推理速度. 与其他实时和近似实时的方法相比,DSDDN获得了更好的表现. 本文方法在所有实时和接近实时的方法中具有竞争力. ...
5
... 最近,Transformer[10 ] 模型的提出对VIS任务产生了极大的影响. VisTR[11 ] 被提出,它通过DETR[12 ] 结构处理VIS任务,减少了推理时间,这显示了Transformer在解决VIS领域的任务上有着极大的发展前景. 自注意Transformer训练速度极慢. 这是因为自注意层的参数量是指数级的,它需要使用较长的训练时间来学习稀疏的有意义的位置,这增加了实时模型进行增量学习的成本. 类似的问题在文献[13 ]里也被提及,为了解决该问题,Deformable DETR[13 ] 通过增加空间变形操作,加速Transformer的收敛. 受到相关工作的启发,本文用2个可变形的操作来优化Transformer pipeline,本文方法在时间和空间维度都使用了变性操作,避免了注意力层指数复杂度的计算,减少了逐帧分割的计算量,提高了模型的收敛速度,减少了增量学习的训练成本. ...
... 式中:$M_{N_q} $ $1,2, \cdots , N_q $ 11 ,12 ,22 ,25 ],采用Hungarian算法计算双位匹配. DDT的损失为 ...
... Comparisons of video instance segmentation on YouTube-VIS 2019 validation dataset
Tab.1 方法 mAP/% AP50/% AP75/% MaskTrack R-CNN 50[8 ] 30.3 51.1 32.6 MaskTrack R-CNN 101[8 ] 41.8 53.0 33.6 MaskProp 50 [10 ] 40.0 — 42.9 MaskProp 101 [10 ] 42.5 — 45.6 *VisTR 50 [11 ] 36.2 59.8 36.9 *VisTR 101 [11 ] 40.1 64.0 45.0 CrossVIS 50 [3 ] 36.3 56.8 38.9 CrossVIS 101[3 ] 36.6 57.3 39.7 CompFeat 50 [31 ] 35.3 56.0 38.6 *IFC 50 [22 ] 41.0 62.1 45.4 STC [32 ] 36.7 57.2 38.6 VSTAM [33 ] 39.0 62.9 41.8 SipMask 50 [2 ] 33.7 54.1 35.8 DSDDN 50 37.5 59.1 41.9 DSDDN 101 39.1 60.7 43.5
遵循表1 的相同设置,使用detectron2[34 ] 来测量推理速度. 除非特别说明,所有用于测量的模型都使用ResNet-50作为CNN主干,将帧尺寸下采样为360像素. DSDDN使用ResNet-50,推理速度v 达到41.2帧/s,mAP达到41.5%,如表2 所示,作为离线模型,在VisTR模型里,设置T = 36. 该设置显著增大了它的推理速度. 与其他实时和近似实时的方法相比,DSDDN获得了更好的表现. 本文方法在所有实时和接近实时的方法中具有竞争力. ...
... [
11 ]
40.1 64.0 45.0 CrossVIS 50 [3 ] 36.3 56.8 38.9 CrossVIS 101[3 ] 36.6 57.3 39.7 CompFeat 50 [31 ] 35.3 56.0 38.6 *IFC 50 [22 ] 41.0 62.1 45.4 STC [32 ] 36.7 57.2 38.6 VSTAM [33 ] 39.0 62.9 41.8 SipMask 50 [2 ] 33.7 54.1 35.8 DSDDN 50 37.5 59.1 41.9 DSDDN 101 39.1 60.7 43.5 遵循表1 的相同设置,使用detectron2[34 ] 来测量推理速度. 除非特别说明,所有用于测量的模型都使用ResNet-50作为CNN主干,将帧尺寸下采样为360像素. DSDDN使用ResNet-50,推理速度v 达到41.2帧/s,mAP达到41.5%,如表2 所示,作为离线模型,在VisTR模型里,设置T = 36. 该设置显著增大了它的推理速度. 与其他实时和近似实时的方法相比,DSDDN获得了更好的表现. 本文方法在所有实时和接近实时的方法中具有竞争力. ...
... Efficiency comparisons on YouTube-VIS-2019 validation set
Tab.2 方法 类型 v /(帧·s−1 )mAP/% MaskTrack R-CNN[8 ] online 32.8 30.3 CrossVIS [3 ] online 39.8 34.8 VisTR [11 ] offline 51.1 36.2 CompFeat[31 ] online 32.8 35.3 SipMask [2 ] online 35.5 33.7 STEm-Seg [35 ] Near Online 4.40 34.6 DSDDN online 40.2 37.5
YouTube-VIS 2021是YouTube-VIS 2019的补充版,完善了视频的类别,扩大了数据集的样本数量. 使用官方实现的方法进行评估. 表3 的结果显示,本文方法超过了大多数最先进的方法. ...
6
... 最近,Transformer[10 ] 模型的提出对VIS任务产生了极大的影响. VisTR[11 ] 被提出,它通过DETR[12 ] 结构处理VIS任务,减少了推理时间,这显示了Transformer在解决VIS领域的任务上有着极大的发展前景. 自注意Transformer训练速度极慢. 这是因为自注意层的参数量是指数级的,它需要使用较长的训练时间来学习稀疏的有意义的位置,这增加了实时模型进行增量学习的成本. 类似的问题在文献[13 ]里也被提及,为了解决该问题,Deformable DETR[13 ] 通过增加空间变形操作,加速Transformer的收敛. 受到相关工作的启发,本文用2个可变形的操作来优化Transformer pipeline,本文方法在时间和空间维度都使用了变性操作,避免了注意力层指数复杂度的计算,减少了逐帧分割的计算量,提高了模型的收敛速度,减少了增量学习的训练成本. ...
... Liu等[4 , 12 ] 提出了更先进的算法. 这些算法考虑视频的特点,能够同时训练空间和时间维度的模型,改善了结果的性能. 通过利用多帧,这些模型可以处理视频中的典型挑战,即运动模糊和遮挡. 这种聚合提高了每一帧的计算成本,减小了推理速度. 本文的模型作为一种实时方法,旨在以低延迟的方式实现准确的预测. ...
... 最近,Transformer[10 ] 受到极大的关注,影响了许多任务. Carion等[12 ] 提出DETR,以消除对许多手工设计的组件的需求. DETR存在收敛速度慢和特征空间分辨率有限的问题. Deformable DETR[12 ] 由于其快速收敛,为利用端到端物体检测器的变体提供了可能性. Sun等[20 -22 ] 将Transformer应用于视频理解,例如视频实例分割(video instance segmentation,VIS)、多物体跟踪(multiple object tracking,MOT). 本文发现,逐片段的处理流程显示出比逐帧的方法更优越的性能,因为后者的方法只利用前一帧的有限时间信息,无法很好地解决图片中的模糊和遮挡问题. ...
... [12 ]由于其快速收敛,为利用端到端物体检测器的变体提供了可能性. Sun等[20 -22 ] 将Transformer应用于视频理解,例如视频实例分割(video instance segmentation,VIS)、多物体跟踪(multiple object tracking,MOT). 本文发现,逐片段的处理流程显示出比逐帧的方法更优越的性能,因为后者的方法只利用前一帧的有限时间信息,无法很好地解决图片中的模糊和遮挡问题. ...
... 式中:$M_{N_q} $ $1,2, \cdots , N_q $ 11 ,12 ,22 ,25 ],采用Hungarian算法计算双位匹配. DDT的损失为 ...
... 使用原始的Deformable DETR[12 ] 作为代码基础,非特殊强调,大部分的超参数设置遵循IFC[22 ] . 在COCO[29 ] 数据集对模型预训练150个轮次,使用AdamW作为优化器,设置初始化Transformer学习率为$ 2\times 1{0}^{-4} $ $ 2\times 1{0}^{-5} $ $ 1{0}^{-4} $ . 所有的Transformer参数使用Xavier初始化. 所有backbone使用在ImageNet上预训练的参数初始化,冻结batchnorm层. 使用ResNet-50[30 ] 和ResNet-101[30 ] 2个CNN网络作为backbone,通过模型后缀50和101来进行区分. 经过预训练后, 模型在目标数据集上进行训练,此时设置batch size为16,降采样尺寸为360×640. 在目标数据集上训练的轮次数根据backbone不同而有所区别,模型在ResNet-50上训练网络的轮次为10,并从第8个开始降低学习率,在ResNet-101上训练12个轮次,并从第10个开始衰减. ...
7
... 最近,Transformer[10 ] 模型的提出对VIS任务产生了极大的影响. VisTR[11 ] 被提出,它通过DETR[12 ] 结构处理VIS任务,减少了推理时间,这显示了Transformer在解决VIS领域的任务上有着极大的发展前景. 自注意Transformer训练速度极慢. 这是因为自注意层的参数量是指数级的,它需要使用较长的训练时间来学习稀疏的有意义的位置,这增加了实时模型进行增量学习的成本. 类似的问题在文献[13 ]里也被提及,为了解决该问题,Deformable DETR[13 ] 通过增加空间变形操作,加速Transformer的收敛. 受到相关工作的启发,本文用2个可变形的操作来优化Transformer pipeline,本文方法在时间和空间维度都使用了变性操作,避免了注意力层指数复杂度的计算,减少了逐帧分割的计算量,提高了模型的收敛速度,减少了增量学习的训练成本. ...
... [13 ]通过增加空间变形操作,加速Transformer的收敛. 受到相关工作的启发,本文用2个可变形的操作来优化Transformer pipeline,本文方法在时间和空间维度都使用了变性操作,避免了注意力层指数复杂度的计算,减少了逐帧分割的计算量,提高了模型的收敛速度,减少了增量学习的训练成本. ...
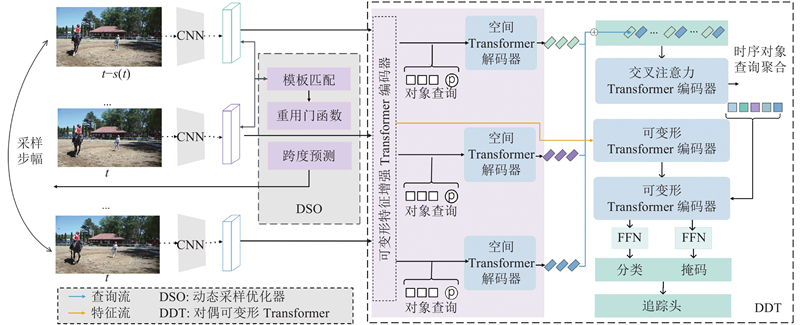
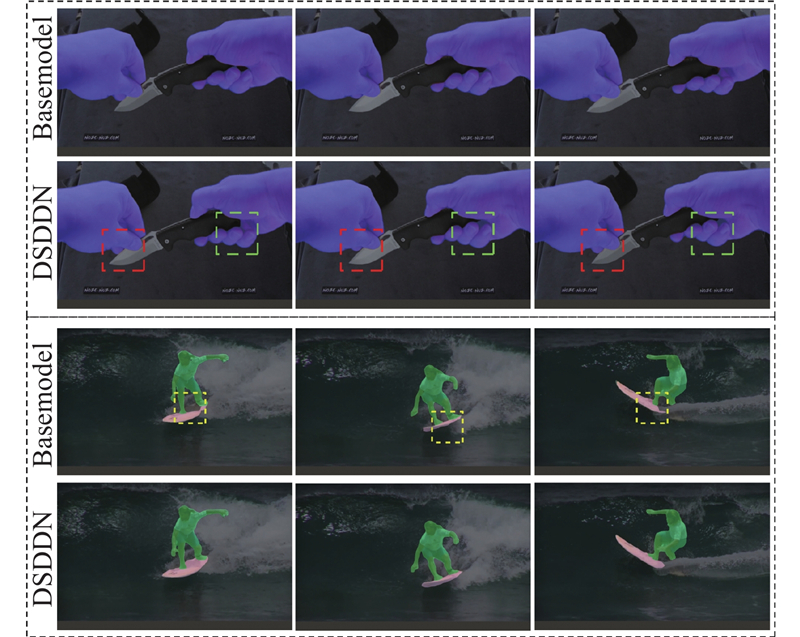
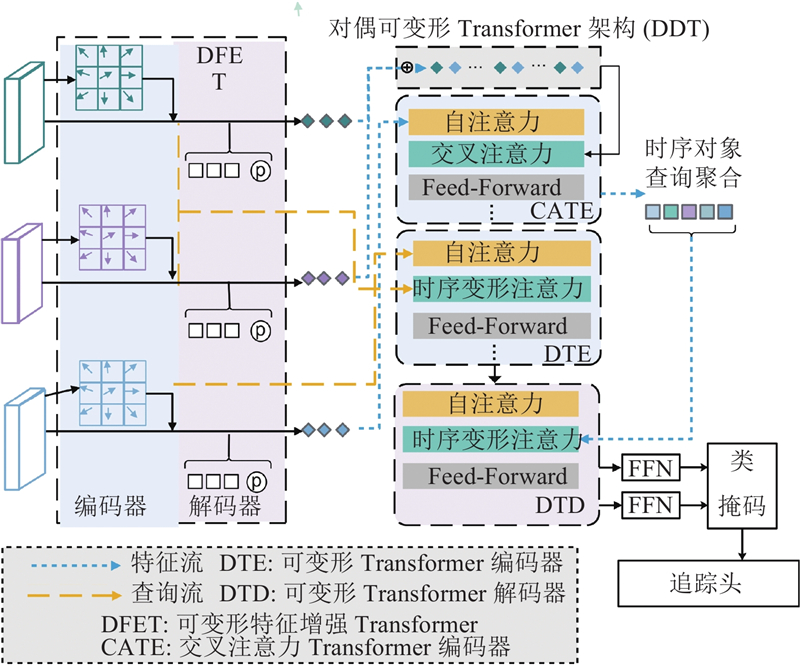
... Park等[14 ] 将重用门(reuse gate)引入半监督的工作,获得了很好的效果. Zhu等[13 , 15 -17 ] 在DETR结构中利用不同的变形操作,提升了网络的训练速度,节省了计算时间. 前人的工作证明重用门操作和变形操作可以极大地提升Transformer的推理速度. 本文提出动态采样对偶可变形网络(dynamic sampling dual deformable network,DSDDN). 这是基于Transformer架构的解决VIS任务的实时模型,使用即插即用的动态采样优化器. 模型由以下2个主要部分组成. 1)动态采样优化器(dynamic sampling optimizer,DSO),用于决定是否重复使用前一帧的分割结果或调整采样步长来预测当前帧的分割结果. 2)双变形Transformer (dual deformable Transformer,DDT),通过增加精心设计的追踪头,将类似DETR的模型扩展到视频实例分割领域. 此外,本文使用对偶变形操作,加强DDT架构中的跨帧特征提取. ...
... 与静态网络相比,动态网络[15 ] 能够以数据的方式使结构或参数适应输入,享有静态模型没有的有利特性. 动态网络最明显的优点是它们可以在测试时按需战略性地分配计算,通过有选择地激活模型组件或子网络,以输入为条件,模型可以在信息量较少的输入空间/时间位置上花费较少的计算成本. 一些工作将动态网络引入到视频实例分割(VIS)或视频物体检测 (VOD)任务中[13 , 18 -19 ] . 本文方法受到这些工作的启发,为视频实例分割任务设计新颖的动态采样策略,以减少不必要的计算. ...
... 本文的目标是减少VIS任务中对高度相似帧的重复计算. 为了解决该问题,提出DSO. 如图3 所示为2个连续帧的特征图之间的差异图,${\boldsymbol{D}}_{{t}}\in {\bf{R}}^{C\times H\times W}$ $ {\boldsymbol{f}}_{{{N}}_{{t}}} $ $\boldsymbol{D}_{t}$ 13 ],使用由2个卷积层、2个最大池化层和1个sigmoid函数组成的门函数. 重用门的概率为 ...
... 本文希望网络在实现高分割精度的同时,最大限度地减少计算资源的消耗. 为了解决该问题,Zhu等[13 ] 引入0~$ {m}_{1} $ $ m $ 13 ]的参数人工设定的,这不稳定,可能会导致性能的急剧下降. 使用$ \mathrm{m}\mathrm{a}\mathrm{x} $ ${P}_{\mathrm{g}\mathrm{a}\mathrm{t}\mathrm{e}}$ $\text{IoU}_{t}^{t-1}$
... ,增大相邻帧之间的IoU. 文献[13 ]的参数人工设定的,这不稳定,可能会导致性能的急剧下降. 使用$ \mathrm{m}\mathrm{a}\mathrm{x} $ ${P}_{\mathrm{g}\mathrm{a}\mathrm{t}\mathrm{e}}$ $\text{IoU}_{t}^{t-1}$
3
... Park等[14 ] 将重用门(reuse gate)引入半监督的工作,获得了很好的效果. Zhu等[13 , 15 -17 ] 在DETR结构中利用不同的变形操作,提升了网络的训练速度,节省了计算时间. 前人的工作证明重用门操作和变形操作可以极大地提升Transformer的推理速度. 本文提出动态采样对偶可变形网络(dynamic sampling dual deformable network,DSDDN). 这是基于Transformer架构的解决VIS任务的实时模型,使用即插即用的动态采样优化器. 模型由以下2个主要部分组成. 1)动态采样优化器(dynamic sampling optimizer,DSO),用于决定是否重复使用前一帧的分割结果或调整采样步长来预测当前帧的分割结果. 2)双变形Transformer (dual deformable Transformer,DDT),通过增加精心设计的追踪头,将类似DETR的模型扩展到视频实例分割领域. 此外,本文使用对偶变形操作,加强DDT架构中的跨帧特征提取. ...
... 在时空转换器中,本文的目标是通过时空转换器架构将每一帧的空间细节联系起来. 考虑特征编码${\left\{\boldsymbol{E}_{i}\right\}}_{i=1}^{s}$ ${\left\{\boldsymbol{Q}_{i}\right\}}_{i=1}^{s}$ ${\left\{{\boldsymbol{E}}_{{i}}\right\}}_{{i}=1}^{{s}}$ [14 ] ,它只注意参照物周围的一小部分关键采样点. 本文可以有效地连接几个帧的特征编码. 让$ q $ $\boldsymbol{z}_{q}$ $\boldsymbol{p}_{1}$
... 交叉注意力Transformer编码器 (CATE) 使用空间查询作为输入,学习不同帧的时间背景. 本文遵循类似于文献[14 ]的从粗到细的空间对象查询聚合策略,选择最确信的k 反馈给交叉注意力层. CATE和DTE的输出都被送到变形Transformer解码器 (DTD) 中,以获得当前帧的结果作为最终输出. ...
3
... Park等[14 ] 将重用门(reuse gate)引入半监督的工作,获得了很好的效果. Zhu等[13 , 15 -17 ] 在DETR结构中利用不同的变形操作,提升了网络的训练速度,节省了计算时间. 前人的工作证明重用门操作和变形操作可以极大地提升Transformer的推理速度. 本文提出动态采样对偶可变形网络(dynamic sampling dual deformable network,DSDDN). 这是基于Transformer架构的解决VIS任务的实时模型,使用即插即用的动态采样优化器. 模型由以下2个主要部分组成. 1)动态采样优化器(dynamic sampling optimizer,DSO),用于决定是否重复使用前一帧的分割结果或调整采样步长来预测当前帧的分割结果. 2)双变形Transformer (dual deformable Transformer,DDT),通过增加精心设计的追踪头,将类似DETR的模型扩展到视频实例分割领域. 此外,本文使用对偶变形操作,加强DDT架构中的跨帧特征提取. ...
... 与静态网络相比,动态网络[15 ] 能够以数据的方式使结构或参数适应输入,享有静态模型没有的有利特性. 动态网络最明显的优点是它们可以在测试时按需战略性地分配计算,通过有选择地激活模型组件或子网络,以输入为条件,模型可以在信息量较少的输入空间/时间位置上花费较少的计算成本. 一些工作将动态网络引入到视频实例分割(VIS)或视频物体检测 (VOD)任务中[13 , 18 -19 ] . 本文方法受到这些工作的启发,为视频实例分割任务设计新颖的动态采样策略,以减少不必要的计算. ...
... 在空间级Transformer中,使用可变形特征增强Transformer编码器 (DFETE) ,它增加了类似于文献[23 ,15 ]的偏移图,增强和压缩从DSO模块里得到的特征图$ {{\boldsymbol{f}}}_{{N}_{t}} $ ${{\boldsymbol{f}}}_{32_{t}}$ ${\left\{{\boldsymbol{f}}_{32_{t}}\right\}}_{{t}=1}^{{s}}$ ${\left\{{\boldsymbol{E}}_{{{{i}}}}\right\}}_{{i}=1}^{{s}}$ 图4 的密虚线箭头) . ${\left\{{\boldsymbol{E}}_{{i}}\right\}}_{{i}=1}^{{s}}$ ${\left\{{\boldsymbol{Q}}_{{i}}\right\}}_{{i}=1}^{{s}}$ 图4 的稀疏虚线箭头) . 通过在编码器模块中使用类似于可变形卷积的偏移图,减少背景噪声对Transformer检测器的影响,提高了提取空间信息的准确性. 具体来说,空间变形操作和时间变形操作解耦,可以并行执行,以加速整个模型的整体运行速度. ...
Dynamic neural networks: a survey
0
2021
1
... Park等[14 ] 将重用门(reuse gate)引入半监督的工作,获得了很好的效果. Zhu等[13 , 15 -17 ] 在DETR结构中利用不同的变形操作,提升了网络的训练速度,节省了计算时间. 前人的工作证明重用门操作和变形操作可以极大地提升Transformer的推理速度. 本文提出动态采样对偶可变形网络(dynamic sampling dual deformable network,DSDDN). 这是基于Transformer架构的解决VIS任务的实时模型,使用即插即用的动态采样优化器. 模型由以下2个主要部分组成. 1)动态采样优化器(dynamic sampling optimizer,DSO),用于决定是否重复使用前一帧的分割结果或调整采样步长来预测当前帧的分割结果. 2)双变形Transformer (dual deformable Transformer,DDT),通过增加精心设计的追踪头,将类似DETR的模型扩展到视频实例分割领域. 此外,本文使用对偶变形操作,加强DDT架构中的跨帧特征提取. ...
Improving video instance segmentation via temporal pyramid routing
1
2022
... 与静态网络相比,动态网络[15 ] 能够以数据的方式使结构或参数适应输入,享有静态模型没有的有利特性. 动态网络最明显的优点是它们可以在测试时按需战略性地分配计算,通过有选择地激活模型组件或子网络,以输入为条件,模型可以在信息量较少的输入空间/时间位置上花费较少的计算成本. 一些工作将动态网络引入到视频实例分割(VIS)或视频物体检测 (VOD)任务中[13 , 18 -19 ] . 本文方法受到这些工作的启发,为视频实例分割任务设计新颖的动态采样策略,以减少不必要的计算. ...
1
... 与静态网络相比,动态网络[15 ] 能够以数据的方式使结构或参数适应输入,享有静态模型没有的有利特性. 动态网络最明显的优点是它们可以在测试时按需战略性地分配计算,通过有选择地激活模型组件或子网络,以输入为条件,模型可以在信息量较少的输入空间/时间位置上花费较少的计算成本. 一些工作将动态网络引入到视频实例分割(VIS)或视频物体检测 (VOD)任务中[13 , 18 -19 ] . 本文方法受到这些工作的启发,为视频实例分割任务设计新颖的动态采样策略,以减少不必要的计算. ...
1
... 最近,Transformer[10 ] 受到极大的关注,影响了许多任务. Carion等[12 ] 提出DETR,以消除对许多手工设计的组件的需求. DETR存在收敛速度慢和特征空间分辨率有限的问题. Deformable DETR[12 ] 由于其快速收敛,为利用端到端物体检测器的变体提供了可能性. Sun等[20 -22 ] 将Transformer应用于视频理解,例如视频实例分割(video instance segmentation,VIS)、多物体跟踪(multiple object tracking,MOT). 本文发现,逐片段的处理流程显示出比逐帧的方法更优越的性能,因为后者的方法只利用前一帧的有限时间信息,无法很好地解决图片中的模糊和遮挡问题. ...
Video instance segmentation using inter-frame communication Transformers
8
2021
... 最近,Transformer[10 ] 受到极大的关注,影响了许多任务. Carion等[12 ] 提出DETR,以消除对许多手工设计的组件的需求. DETR存在收敛速度慢和特征空间分辨率有限的问题. Deformable DETR[12 ] 由于其快速收敛,为利用端到端物体检测器的变体提供了可能性. Sun等[20 -22 ] 将Transformer应用于视频理解,例如视频实例分割(video instance segmentation,VIS)、多物体跟踪(multiple object tracking,MOT). 本文发现,逐片段的处理流程显示出比逐帧的方法更优越的性能,因为后者的方法只利用前一帧的有限时间信息,无法很好地解决图片中的模糊和遮挡问题. ...
... 式中:$M_{N_q} $ $1,2, \cdots , N_q $ 11 ,12 ,22 ,25 ],采用Hungarian算法计算双位匹配. DDT的损失为 ...
... 受文献[22 ]的启发,在DETR中选择基于掩码(mask)的测量方法,而不是基于盒子 (box) 的方法,以达到更好的准确性. ...
... 使用原始的Deformable DETR[12 ] 作为代码基础,非特殊强调,大部分的超参数设置遵循IFC[22 ] . 在COCO[29 ] 数据集对模型预训练150个轮次,使用AdamW作为优化器,设置初始化Transformer学习率为$ 2\times 1{0}^{-4} $ $ 2\times 1{0}^{-5} $ $ 1{0}^{-4} $ . 所有的Transformer参数使用Xavier初始化. 所有backbone使用在ImageNet上预训练的参数初始化,冻结batchnorm层. 使用ResNet-50[30 ] 和ResNet-101[30 ] 2个CNN网络作为backbone,通过模型后缀50和101来进行区分. 经过预训练后, 模型在目标数据集上进行训练,此时设置batch size为16,降采样尺寸为360×640. 在目标数据集上训练的轮次数根据backbone不同而有所区别,模型在ResNet-50上训练网络的轮次为10,并从第8个开始降低学习率,在ResNet-101上训练12个轮次,并从第10个开始衰减. ...
... YouTube-VIS 2019 验证结果如表1 所示,带*的方法表示离线模型,它们使用更多的参考信息,具有显著的推理延迟. 表中,mAP(mean average precision)为平均精度的平均值,AP50、AP75分别为IoU阈值为50%和75%时的平均精度. 将提出的方法与现有的具有不同骨架的最先进的VIS方法 (如ResNet 50和ResNet 101) 进行比较. 使用mAP指标来进行模型对比. mAP是常用于评估目标检测、实例分割、全景分割等计算机视觉任务性能的指标. mAP结合准确率(precision)和召回率(recall),通过计算在不同置信度阈值下的平均精度来衡量模型的性能. 设计DSDDN,它能够动态采样视频帧,在pipeline里增加对偶可变形操作. 通过AP来衡量准确性,利用本文的实时方法得到了有竞争力的分数. 这表明利用提出的方法可以准确地检测类别、分割实例掩码,并在帧上跟踪物体. 特别地是,若要采用输入为Clip而不是逐帧输入的方法,则须减小Clip的长度T ,使得Clip方法接近于实时逐帧推理. 根据文献[22 ]可知,在IFC[22 ] 中设置T = 5,在MaskProb[8 ] 中设置T = 13,这对实时推理来说存在很小的延迟. ...
... [22 ]中设置T = 5,在MaskProb[8 ] 中设置T = 13,这对实时推理来说存在很小的延迟. ...
... Comparisons of video instance segmentation on YouTube-VIS 2019 validation dataset
Tab.1 方法 mAP/% AP50/% AP75/% MaskTrack R-CNN 50[8 ] 30.3 51.1 32.6 MaskTrack R-CNN 101[8 ] 41.8 53.0 33.6 MaskProp 50 [10 ] 40.0 — 42.9 MaskProp 101 [10 ] 42.5 — 45.6 *VisTR 50 [11 ] 36.2 59.8 36.9 *VisTR 101 [11 ] 40.1 64.0 45.0 CrossVIS 50 [3 ] 36.3 56.8 38.9 CrossVIS 101[3 ] 36.6 57.3 39.7 CompFeat 50 [31 ] 35.3 56.0 38.6 *IFC 50 [22 ] 41.0 62.1 45.4 STC [32 ] 36.7 57.2 38.6 VSTAM [33 ] 39.0 62.9 41.8 SipMask 50 [2 ] 33.7 54.1 35.8 DSDDN 50 37.5 59.1 41.9 DSDDN 101 39.1 60.7 43.5
遵循表1 的相同设置,使用detectron2[34 ] 来测量推理速度. 除非特别说明,所有用于测量的模型都使用ResNet-50作为CNN主干,将帧尺寸下采样为360像素. DSDDN使用ResNet-50,推理速度v 达到41.2帧/s,mAP达到41.5%,如表2 所示,作为离线模型,在VisTR模型里,设置T = 36. 该设置显著增大了它的推理速度. 与其他实时和近似实时的方法相比,DSDDN获得了更好的表现. 本文方法在所有实时和接近实时的方法中具有竞争力. ...
... Accuracy comparison based on YouTube-VIS 2021 validation set
Tab.3 方法 mAP/% AP50/% AP75/% MaskTrack-RCNN [9 ] 28.6 48.9 29.6 SipMask [2 ] 31.7 52.5 34.0 CrossVIS [3 ] 34.2 54.4 37.9 IFC [22 ] 36.6 57.9 39.3 DSDDN 34.8 55.9 37.4
3.3. 消融学习 在YouTube-VIS 2019 验证集上进行实验,使用ResNet-50作为骨干. ...
1
... 在空间级Transformer中,使用可变形特征增强Transformer编码器 (DFETE) ,它增加了类似于文献[23 ,15 ]的偏移图,增强和压缩从DSO模块里得到的特征图$ {{\boldsymbol{f}}}_{{N}_{t}} $ ${{\boldsymbol{f}}}_{32_{t}}$ ${\left\{{\boldsymbol{f}}_{32_{t}}\right\}}_{{t}=1}^{{s}}$ ${\left\{{\boldsymbol{E}}_{{{{i}}}}\right\}}_{{i}=1}^{{s}}$ 图4 的密虚线箭头) . ${\left\{{\boldsymbol{E}}_{{i}}\right\}}_{{i}=1}^{{s}}$ ${\left\{{\boldsymbol{Q}}_{{i}}\right\}}_{{i}=1}^{{s}}$ 图4 的稀疏虚线箭头) . 通过在编码器模块中使用类似于可变形卷积的偏移图,减少背景噪声对Transformer检测器的影响,提高了提取空间信息的准确性. 具体来说,空间变形操作和时间变形操作解耦,可以并行执行,以加速整个模型的整体运行速度. ...
2
... 式中:$ {y}_{{N}_{t}} $ $ {S}_{t-1} $ $ \mathrm{D}\mathrm{I}\mathrm{C}\mathrm{E} $ [24 ] . ...
... 式中:$ {L}_{\mathrm{p}\mathrm{o}\mathrm{s}} $ $ {L}_{\mathrm{n}\mathrm{e}\mathrm{g}} $ $ \mathrm{\varnothing } $ ${L}_\text{CEL}$ ${L}_\text{DL}$ ${L}_\text{SFL}$ ${\left\{{\overset{{\smash{\scriptscriptstyle\frown}}}{{\boldsymbol{y}}}}_{i}\right\}}_{i=1}^{{N}_{q}}$ $ {{\boldsymbol{y}}}_{i} $ [24 ] 和sigmoid-focal[26 ] 损失,${{\hat P}_{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\sigma } \left( i \right)}}({\boldsymbol{c}}_i) $ ${\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\sigma } \left( i \right)} $ ${\boldsymbol{c}}_i $ ${{\hat P}_{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\sigma } \left( i \right)}}\left( \varnothing \right)$ ${\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\sigma } \left( i \right)} $ $\varnothing $
1
... 式中:$M_{N_q} $ $1,2, \cdots , N_q $ 11 ,12 ,22 ,25 ],采用Hungarian算法计算双位匹配. DDT的损失为 ...
2
... 式中:$ {L}_{\mathrm{p}\mathrm{o}\mathrm{s}} $ $ {L}_{\mathrm{n}\mathrm{e}\mathrm{g}} $ $ \mathrm{\varnothing } $ ${L}_\text{CEL}$ ${L}_\text{DL}$ ${L}_\text{SFL}$ ${\left\{{\overset{{\smash{\scriptscriptstyle\frown}}}{{\boldsymbol{y}}}}_{i}\right\}}_{i=1}^{{N}_{q}}$ $ {{\boldsymbol{y}}}_{i} $ [24 ] 和sigmoid-focal[26 ] 损失,${{\hat P}_{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\sigma } \left( i \right)}}({\boldsymbol{c}}_i) $ ${\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\sigma } \left( i \right)} $ ${\boldsymbol{c}}_i $ ${{\hat P}_{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\sigma } \left( i \right)}}\left( \varnothing \right)$ ${\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\sigma } \left( i \right)} $ $\varnothing $
... 式中:$ {\alpha }_{t} $ $ \gamma $ 26 ]的定义,设置为$ {\alpha }_{t} $ $ \gamma $
1
... 沿用文献[27 ]的设置,在${\boldsymbol{M}}_{{f}}$ $\left({\boldsymbol{M}}_{{f}}\cdot {\boldsymbol{f}}_{{{N}}_{{t}}}\right)$ [28 ] ,避免刻意的初始化. ...
1
... 沿用文献[27 ]的设置,在${\boldsymbol{M}}_{{f}}$ $\left({\boldsymbol{M}}_{{f}}\cdot {\boldsymbol{f}}_{{{N}}_{{t}}}\right)$ [28 ] ,避免刻意的初始化. ...
1
... 使用原始的Deformable DETR[12 ] 作为代码基础,非特殊强调,大部分的超参数设置遵循IFC[22 ] . 在COCO[29 ] 数据集对模型预训练150个轮次,使用AdamW作为优化器,设置初始化Transformer学习率为$ 2\times 1{0}^{-4} $ $ 2\times 1{0}^{-5} $ $ 1{0}^{-4} $ . 所有的Transformer参数使用Xavier初始化. 所有backbone使用在ImageNet上预训练的参数初始化,冻结batchnorm层. 使用ResNet-50[30 ] 和ResNet-101[30 ] 2个CNN网络作为backbone,通过模型后缀50和101来进行区分. 经过预训练后, 模型在目标数据集上进行训练,此时设置batch size为16,降采样尺寸为360×640. 在目标数据集上训练的轮次数根据backbone不同而有所区别,模型在ResNet-50上训练网络的轮次为10,并从第8个开始降低学习率,在ResNet-101上训练12个轮次,并从第10个开始衰减. ...
2
... 使用原始的Deformable DETR[12 ] 作为代码基础,非特殊强调,大部分的超参数设置遵循IFC[22 ] . 在COCO[29 ] 数据集对模型预训练150个轮次,使用AdamW作为优化器,设置初始化Transformer学习率为$ 2\times 1{0}^{-4} $ $ 2\times 1{0}^{-5} $ $ 1{0}^{-4} $ . 所有的Transformer参数使用Xavier初始化. 所有backbone使用在ImageNet上预训练的参数初始化,冻结batchnorm层. 使用ResNet-50[30 ] 和ResNet-101[30 ] 2个CNN网络作为backbone,通过模型后缀50和101来进行区分. 经过预训练后, 模型在目标数据集上进行训练,此时设置batch size为16,降采样尺寸为360×640. 在目标数据集上训练的轮次数根据backbone不同而有所区别,模型在ResNet-50上训练网络的轮次为10,并从第8个开始降低学习率,在ResNet-101上训练12个轮次,并从第10个开始衰减. ...
... [30 ]2个CNN网络作为backbone,通过模型后缀50和101来进行区分. 经过预训练后, 模型在目标数据集上进行训练,此时设置batch size为16,降采样尺寸为360×640. 在目标数据集上训练的轮次数根据backbone不同而有所区别,模型在ResNet-50上训练网络的轮次为10,并从第8个开始降低学习率,在ResNet-101上训练12个轮次,并从第10个开始衰减. ...
2
... Comparisons of video instance segmentation on YouTube-VIS 2019 validation dataset
Tab.1 方法 mAP/% AP50/% AP75/% MaskTrack R-CNN 50[8 ] 30.3 51.1 32.6 MaskTrack R-CNN 101[8 ] 41.8 53.0 33.6 MaskProp 50 [10 ] 40.0 — 42.9 MaskProp 101 [10 ] 42.5 — 45.6 *VisTR 50 [11 ] 36.2 59.8 36.9 *VisTR 101 [11 ] 40.1 64.0 45.0 CrossVIS 50 [3 ] 36.3 56.8 38.9 CrossVIS 101[3 ] 36.6 57.3 39.7 CompFeat 50 [31 ] 35.3 56.0 38.6 *IFC 50 [22 ] 41.0 62.1 45.4 STC [32 ] 36.7 57.2 38.6 VSTAM [33 ] 39.0 62.9 41.8 SipMask 50 [2 ] 33.7 54.1 35.8 DSDDN 50 37.5 59.1 41.9 DSDDN 101 39.1 60.7 43.5
遵循表1 的相同设置,使用detectron2[34 ] 来测量推理速度. 除非特别说明,所有用于测量的模型都使用ResNet-50作为CNN主干,将帧尺寸下采样为360像素. DSDDN使用ResNet-50,推理速度v 达到41.2帧/s,mAP达到41.5%,如表2 所示,作为离线模型,在VisTR模型里,设置T = 36. 该设置显著增大了它的推理速度. 与其他实时和近似实时的方法相比,DSDDN获得了更好的表现. 本文方法在所有实时和接近实时的方法中具有竞争力. ...
... Efficiency comparisons on YouTube-VIS-2019 validation set
Tab.2 方法 类型 v /(帧·s−1 )mAP/% MaskTrack R-CNN[8 ] online 32.8 30.3 CrossVIS [3 ] online 39.8 34.8 VisTR [11 ] offline 51.1 36.2 CompFeat[31 ] online 32.8 35.3 SipMask [2 ] online 35.5 33.7 STEm-Seg [35 ] Near Online 4.40 34.6 DSDDN online 40.2 37.5
YouTube-VIS 2021是YouTube-VIS 2019的补充版,完善了视频的类别,扩大了数据集的样本数量. 使用官方实现的方法进行评估. 表3 的结果显示,本文方法超过了大多数最先进的方法. ...
1
... Comparisons of video instance segmentation on YouTube-VIS 2019 validation dataset
Tab.1 方法 mAP/% AP50/% AP75/% MaskTrack R-CNN 50[8 ] 30.3 51.1 32.6 MaskTrack R-CNN 101[8 ] 41.8 53.0 33.6 MaskProp 50 [10 ] 40.0 — 42.9 MaskProp 101 [10 ] 42.5 — 45.6 *VisTR 50 [11 ] 36.2 59.8 36.9 *VisTR 101 [11 ] 40.1 64.0 45.0 CrossVIS 50 [3 ] 36.3 56.8 38.9 CrossVIS 101[3 ] 36.6 57.3 39.7 CompFeat 50 [31 ] 35.3 56.0 38.6 *IFC 50 [22 ] 41.0 62.1 45.4 STC [32 ] 36.7 57.2 38.6 VSTAM [33 ] 39.0 62.9 41.8 SipMask 50 [2 ] 33.7 54.1 35.8 DSDDN 50 37.5 59.1 41.9 DSDDN 101 39.1 60.7 43.5
遵循表1 的相同设置,使用detectron2[34 ] 来测量推理速度. 除非特别说明,所有用于测量的模型都使用ResNet-50作为CNN主干,将帧尺寸下采样为360像素. DSDDN使用ResNet-50,推理速度v 达到41.2帧/s,mAP达到41.5%,如表2 所示,作为离线模型,在VisTR模型里,设置T = 36. 该设置显著增大了它的推理速度. 与其他实时和近似实时的方法相比,DSDDN获得了更好的表现. 本文方法在所有实时和接近实时的方法中具有竞争力. ...
Video sparse Transformer with attention-guided memory for video object detection
1
2022
... Comparisons of video instance segmentation on YouTube-VIS 2019 validation dataset
Tab.1 方法 mAP/% AP50/% AP75/% MaskTrack R-CNN 50[8 ] 30.3 51.1 32.6 MaskTrack R-CNN 101[8 ] 41.8 53.0 33.6 MaskProp 50 [10 ] 40.0 — 42.9 MaskProp 101 [10 ] 42.5 — 45.6 *VisTR 50 [11 ] 36.2 59.8 36.9 *VisTR 101 [11 ] 40.1 64.0 45.0 CrossVIS 50 [3 ] 36.3 56.8 38.9 CrossVIS 101[3 ] 36.6 57.3 39.7 CompFeat 50 [31 ] 35.3 56.0 38.6 *IFC 50 [22 ] 41.0 62.1 45.4 STC [32 ] 36.7 57.2 38.6 VSTAM [33 ] 39.0 62.9 41.8 SipMask 50 [2 ] 33.7 54.1 35.8 DSDDN 50 37.5 59.1 41.9 DSDDN 101 39.1 60.7 43.5
遵循表1 的相同设置,使用detectron2[34 ] 来测量推理速度. 除非特别说明,所有用于测量的模型都使用ResNet-50作为CNN主干,将帧尺寸下采样为360像素. DSDDN使用ResNet-50,推理速度v 达到41.2帧/s,mAP达到41.5%,如表2 所示,作为离线模型,在VisTR模型里,设置T = 36. 该设置显著增大了它的推理速度. 与其他实时和近似实时的方法相比,DSDDN获得了更好的表现. 本文方法在所有实时和接近实时的方法中具有竞争力. ...
1
... 遵循表1 的相同设置,使用detectron2[34 ] 来测量推理速度. 除非特别说明,所有用于测量的模型都使用ResNet-50作为CNN主干,将帧尺寸下采样为360像素. DSDDN使用ResNet-50,推理速度v 达到41.2帧/s,mAP达到41.5%,如表2 所示,作为离线模型,在VisTR模型里,设置T = 36. 该设置显著增大了它的推理速度. 与其他实时和近似实时的方法相比,DSDDN获得了更好的表现. 本文方法在所有实时和接近实时的方法中具有竞争力. ...
1
... Efficiency comparisons on YouTube-VIS-2019 validation set
Tab.2 方法 类型 v /(帧·s−1 )mAP/% MaskTrack R-CNN[8 ] online 32.8 30.3 CrossVIS [3 ] online 39.8 34.8 VisTR [11 ] offline 51.1 36.2 CompFeat[31 ] online 32.8 35.3 SipMask [2 ] online 35.5 33.7 STEm-Seg [35 ] Near Online 4.40 34.6 DSDDN online 40.2 37.5
YouTube-VIS 2021是YouTube-VIS 2019的补充版,完善了视频的类别,扩大了数据集的样本数量. 使用官方实现的方法进行评估. 表3 的结果显示,本文方法超过了大多数最先进的方法. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}