[1]
童佳乐. 基于改进实例分割的煤矿电机车障碍物检测技术研究 [D]. 淮南: 安徽理工大学, 2023: 1–102.
[本文引用: 1]
TONG Jiale. Research on obstacle detection technology of coal mine electric locomotive based on improved instance segmentation [D]. Huainan: Anhui University of Science and Technology, 2023: 1–102.
[本文引用: 1]
[2]
杨豚, 郭永存, 王爽, 等 煤矿井下无人驾驶轨道电机车障碍物识别
[J]. 浙江大学学报: 工学版 , 2024 , 58 (1 ): 29 - 39
[本文引用: 2]
YANG Tun, GUO Yongcun, WANG Shuang, et al Obstacle recognition of unmanned rail electric locomotive in underground coal mine
[J]. Journal of Zhejiang University: Engineering Science , 2024 , 58 (1 ): 29 - 39
[本文引用: 2]
[3]
卫星, 刘邵凡, 杨国强, 等 基于改进双边分割网络的井下轨道检测算法
[J]. 计算机应用研究 , 2020 , 37 (Suppl.1 ): 348 - 350
[本文引用: 1]
WEI Xing, LIU Shaofan, YANG Guoqiang, et al An underground track detection algorithm based on improved bilateral segmentation network
[J]. Application Research of Computers , 2020 , 37 (Suppl.1 ): 348 - 350
[本文引用: 1]
[5]
TONG J, WANG S, GUO Y, et al Obstacle detection method of underground electric locomotive rail based on instance segmentation
[J]. Transportation Research Record: Journal of the Transportation Research Board , 2024 , 2678 (6 ): 708 - 723
DOI:10.1177/03611981231198842
[本文引用: 1]
[6]
PIRASTEH S, VARSHOSAZ M, BADRLOO S, et al Developing an expansion-based obstacle detection using panoptic segmentation
[J]. Journal of Field Robotics , 2024 , 41 (5 ): 1245 - 1264
[本文引用: 1]
[7]
YANG T, GUO Y, LI D, et al Vision-Based obstacle detection in dangerous region of coal mine driverless rail electric locomotives
[J]. Measurement , 2025 , 239 : 115514
DOI:10.1016/j.measurement.2024.115514
[本文引用: 1]
[8]
马天, 石妍, 石炜璐, 等 基于非对称编解码结构的井下轨道异物分割方法
[J]. 光电子· 激光 , 2026 , 37 (1 ): 10 - 20
DOI:10.16136/j.joel.2026.01.0453
[本文引用: 1]
MA Tian, SHI Yan, SHI Weilu, et al Foreign object segmentation method of underground track based on asymmetric codec structure
[J]. Journal of Optoelectronics · Laser , 2026 , 37 (1 ): 10 - 20
DOI:10.16136/j.joel.2026.01.0453
[本文引用: 1]
[9]
POUDEL R P K, LIWICKI S, CIPOLLA R. Fast-SCNN: fast semantic segmentation network [EB/OL]. (2019–02–12)[2025–01–11]. https://arxiv.org/pdf/1902.04502.
[本文引用: 1]
[10]
LI H, XIONG P, FAN H, et al. DFANet: deep feature aggregation for real-time semantic segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2020: 9514–9523.
[本文引用: 1]
[11]
WATANABE S, HORI T, KARITA S, et al. ESPnet: end-to-end speech processing toolkit [C]// Proceedings of the Interspeech 2018 . [S.l.]: ISCA, 2018: 2207–2211.
[本文引用: 1]
[12]
YU C, WANG J, PENG C, et al. BiSeNet: bilateral segmentation network for real-time semantic segmentation [C]// Computer Vision – ECCV 2018 . [S.l.]: Springer, 2018: 334–349.
[本文引用: 1]
[13]
FAN M, LAI S, HUANG J, et al. Rethinking BiSeNet for real-time semantic segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 9711–9720.
[本文引用: 1]
[14]
LEE J, KIM D, PONCE J, et al. SFNet: learning object-aware semantic correspondence [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2020: 2273–2282.
[本文引用: 1]
[15]
PENG J, LIU Y, TANG S, et al. PP-LiteSeg: a superior real-time semantic segmentation model [EB/OL]. (2022–04–06)[2025–01–11]. https://arxiv.org/pdf/2204.02681.
[本文引用: 1]
[16]
WANG J, GOU C, WU Q, et al. RTFormer: efficient design for real-time semantic segmentation with transformer [EB/OL]. (2022–10–13)[ 2025–01–11]. https://arxiv.org/pdf/2210.07124.
[本文引用: 1]
[17]
WANG A, CHEN H, LIU L, et al. YOLOv10: real-time end-to-end object detection [EB/OL]. (2024–10–30)[2025–01–11]. https://arxiv.org/pdf/2405.14458.
[本文引用: 1]
[18]
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// Medical Image Computing and Computer-Assisted Intervention . [S.l.]: Springer, 2015: 234–241.
[本文引用: 1]
[19]
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 6230–6239.
[本文引用: 1]
[20]
WANG J, SUN K, CHENG T, et al Deep high-resolution representation learning for visual recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2021 , 43 (10 ): 3349 - 3364
DOI:10.1109/TPAMI.2020.2983686
[本文引用: 1]
[21]
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]// Computer Vision – ECCV 2018 . [S.l.]: Springer, 2018: 833–851.
[本文引用: 1]
[22]
XIE E, WANG W, YU Z, et al. SegFormer: simple and efficient design for semantic segmentation with transformers [EB/OL]. (2021–10–28) [ 2025–01–11]. https://arxiv.org/pdf/2105.15203.
[本文引用: 1]
1
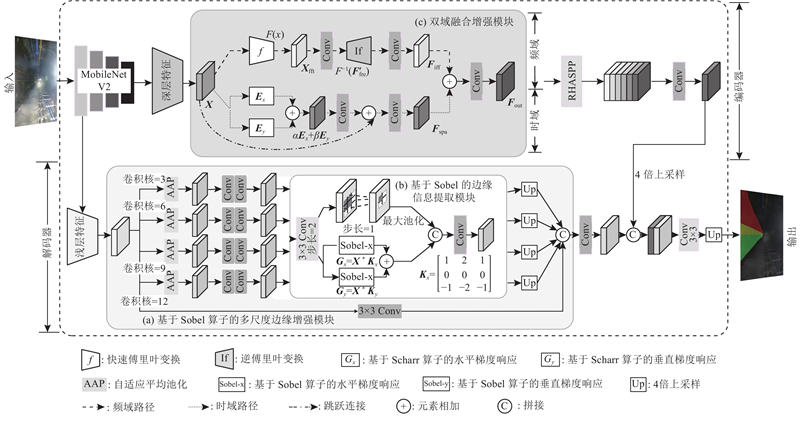
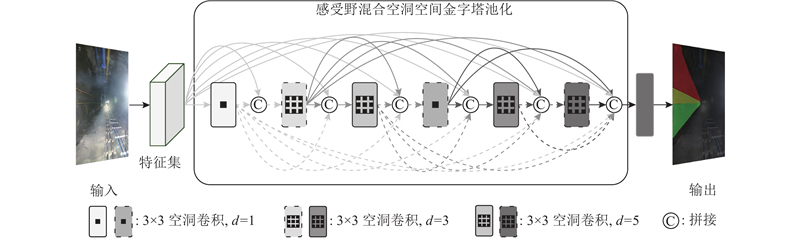
... 为了提高矿山的安全性和生产效率,减少能源消耗和碳排放,持续推动采矿智能化建设的进步,智慧矿山逐渐成为矿业绿色发展的必然趋势. 建设智慧矿山的关键在于智能设备可以获得全面的环境信息,保证设备的稳定性与可靠性. 矿井电机车具有运行频繁、运输量大和运行距离长等特点[1 ] ,是煤矿井下重要运输设备. 中国大部分井下轨道电机车主要依靠人工驾驶,煤矿井下地质条件复杂、光照条件差、司机疲劳驾驶等都是诱发运输事故的原因. 煤矿井下无人驾驶电机车技术可以缓解司机繁重的井下工作,在一定程度上避免井下运输事故发生. ...
1
... 为了提高矿山的安全性和生产效率,减少能源消耗和碳排放,持续推动采矿智能化建设的进步,智慧矿山逐渐成为矿业绿色发展的必然趋势. 建设智慧矿山的关键在于智能设备可以获得全面的环境信息,保证设备的稳定性与可靠性. 矿井电机车具有运行频繁、运输量大和运行距离长等特点[1 ] ,是煤矿井下重要运输设备. 中国大部分井下轨道电机车主要依靠人工驾驶,煤矿井下地质条件复杂、光照条件差、司机疲劳驾驶等都是诱发运输事故的原因. 煤矿井下无人驾驶电机车技术可以缓解司机繁重的井下工作,在一定程度上避免井下运输事故发生. ...
煤矿井下无人驾驶轨道电机车障碍物识别
2
2024
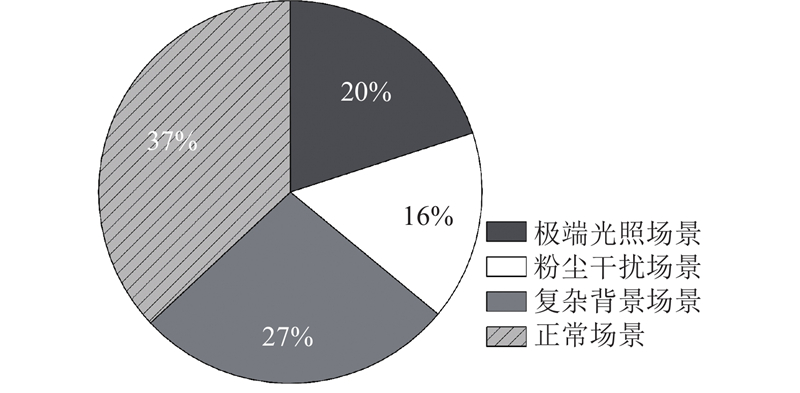
... 在电机车行驶过程中有效的检测出轨道区域,对井下无人驾驶技术的发展有重要的研究意义. 常用的煤矿井下轨道识别方法有激光雷达、红外摄像头、基于计算机视觉的图像分割等方法. 井下环境使用激光雷达和红外摄像头,存在设备成本高、易受粉尘与温度干扰等问题,使得此类方法难以在巷道内实现精确且稳定的轨道识别. 相比之下,构建针对井下环境的深度学习模型,基于计算机视觉的图像分割方法能够对复杂背景、弱光照和粉尘环境下的轨道目标进行精确分割,在不断积累的井下数据和多样化的场景训练下逐步提升模型的鲁棒性. 可见,基于计算机视觉的图像分割方法具有成本低、部署灵活、精度高且易于拓展的特点,适合作为井下无人运输系统轨道区域的识别方法,相关研究在降低人工成本与减少事故风险方面具有重要意义. 随着智慧矿山的提出与发展,基于计算机视觉的识别技术被广泛应用于矿山领域场景[2 ] . 卫星等[3 ] 通过在双边网络中改进金字塔结构来获取更大感受野,提高井下轨道的检测精度. 周华平等[4 ] 在实时语义分割网络中,通过增加能够细化特征的特征融合模块,让网络更适合井下轨道检测. 这2种方法都能够很好满足井下轨道检测的实时性要求,但在井下巷道低光照环境中误检率较高. Tong等[5 ] 采用实例分割方法准确识别并分割出轨道上的危险物体(如杂物、岩块). Pirasteh等[6 ] 通过全景分割的方法同时关注语义和实例信息,为障碍物识别提供了全面的场景理解. 上述2种方法虽然提升了网络的准确度,但无法满足环境实时性的需求. 杨豚等[2 ] 基于改进YOLOv5[7 ] 模型,实现对无人驾驶电机车障碍物精准实时检测. 马天等[8 ] 基于改进非对称解码结构实现对井下轨道异物的分割,在保持精度的同时提升了计算效率. 越来越多应用在煤矿领域的深度学习算法偏向在矿井复杂环境中实现精度与速度的均衡,适用于井下边缘设备的检测方法有助于实现煤矿智能化与无人化的目标. ...
... [2 ]基于改进YOLOv5[7 ] 模型,实现对无人驾驶电机车障碍物精准实时检测. 马天等[8 ] 基于改进非对称解码结构实现对井下轨道异物的分割,在保持精度的同时提升了计算效率. 越来越多应用在煤矿领域的深度学习算法偏向在矿井复杂环境中实现精度与速度的均衡,适用于井下边缘设备的检测方法有助于实现煤矿智能化与无人化的目标. ...
煤矿井下无人驾驶轨道电机车障碍物识别
2
2024
... 在电机车行驶过程中有效的检测出轨道区域,对井下无人驾驶技术的发展有重要的研究意义. 常用的煤矿井下轨道识别方法有激光雷达、红外摄像头、基于计算机视觉的图像分割等方法. 井下环境使用激光雷达和红外摄像头,存在设备成本高、易受粉尘与温度干扰等问题,使得此类方法难以在巷道内实现精确且稳定的轨道识别. 相比之下,构建针对井下环境的深度学习模型,基于计算机视觉的图像分割方法能够对复杂背景、弱光照和粉尘环境下的轨道目标进行精确分割,在不断积累的井下数据和多样化的场景训练下逐步提升模型的鲁棒性. 可见,基于计算机视觉的图像分割方法具有成本低、部署灵活、精度高且易于拓展的特点,适合作为井下无人运输系统轨道区域的识别方法,相关研究在降低人工成本与减少事故风险方面具有重要意义. 随着智慧矿山的提出与发展,基于计算机视觉的识别技术被广泛应用于矿山领域场景[2 ] . 卫星等[3 ] 通过在双边网络中改进金字塔结构来获取更大感受野,提高井下轨道的检测精度. 周华平等[4 ] 在实时语义分割网络中,通过增加能够细化特征的特征融合模块,让网络更适合井下轨道检测. 这2种方法都能够很好满足井下轨道检测的实时性要求,但在井下巷道低光照环境中误检率较高. Tong等[5 ] 采用实例分割方法准确识别并分割出轨道上的危险物体(如杂物、岩块). Pirasteh等[6 ] 通过全景分割的方法同时关注语义和实例信息,为障碍物识别提供了全面的场景理解. 上述2种方法虽然提升了网络的准确度,但无法满足环境实时性的需求. 杨豚等[2 ] 基于改进YOLOv5[7 ] 模型,实现对无人驾驶电机车障碍物精准实时检测. 马天等[8 ] 基于改进非对称解码结构实现对井下轨道异物的分割,在保持精度的同时提升了计算效率. 越来越多应用在煤矿领域的深度学习算法偏向在矿井复杂环境中实现精度与速度的均衡,适用于井下边缘设备的检测方法有助于实现煤矿智能化与无人化的目标. ...
... [2 ]基于改进YOLOv5[7 ] 模型,实现对无人驾驶电机车障碍物精准实时检测. 马天等[8 ] 基于改进非对称解码结构实现对井下轨道异物的分割,在保持精度的同时提升了计算效率. 越来越多应用在煤矿领域的深度学习算法偏向在矿井复杂环境中实现精度与速度的均衡,适用于井下边缘设备的检测方法有助于实现煤矿智能化与无人化的目标. ...
基于改进双边分割网络的井下轨道检测算法
1
2020
... 在电机车行驶过程中有效的检测出轨道区域,对井下无人驾驶技术的发展有重要的研究意义. 常用的煤矿井下轨道识别方法有激光雷达、红外摄像头、基于计算机视觉的图像分割等方法. 井下环境使用激光雷达和红外摄像头,存在设备成本高、易受粉尘与温度干扰等问题,使得此类方法难以在巷道内实现精确且稳定的轨道识别. 相比之下,构建针对井下环境的深度学习模型,基于计算机视觉的图像分割方法能够对复杂背景、弱光照和粉尘环境下的轨道目标进行精确分割,在不断积累的井下数据和多样化的场景训练下逐步提升模型的鲁棒性. 可见,基于计算机视觉的图像分割方法具有成本低、部署灵活、精度高且易于拓展的特点,适合作为井下无人运输系统轨道区域的识别方法,相关研究在降低人工成本与减少事故风险方面具有重要意义. 随着智慧矿山的提出与发展,基于计算机视觉的识别技术被广泛应用于矿山领域场景[2 ] . 卫星等[3 ] 通过在双边网络中改进金字塔结构来获取更大感受野,提高井下轨道的检测精度. 周华平等[4 ] 在实时语义分割网络中,通过增加能够细化特征的特征融合模块,让网络更适合井下轨道检测. 这2种方法都能够很好满足井下轨道检测的实时性要求,但在井下巷道低光照环境中误检率较高. Tong等[5 ] 采用实例分割方法准确识别并分割出轨道上的危险物体(如杂物、岩块). Pirasteh等[6 ] 通过全景分割的方法同时关注语义和实例信息,为障碍物识别提供了全面的场景理解. 上述2种方法虽然提升了网络的准确度,但无法满足环境实时性的需求. 杨豚等[2 ] 基于改进YOLOv5[7 ] 模型,实现对无人驾驶电机车障碍物精准实时检测. 马天等[8 ] 基于改进非对称解码结构实现对井下轨道异物的分割,在保持精度的同时提升了计算效率. 越来越多应用在煤矿领域的深度学习算法偏向在矿井复杂环境中实现精度与速度的均衡,适用于井下边缘设备的检测方法有助于实现煤矿智能化与无人化的目标. ...
基于改进双边分割网络的井下轨道检测算法
1
2020
... 在电机车行驶过程中有效的检测出轨道区域,对井下无人驾驶技术的发展有重要的研究意义. 常用的煤矿井下轨道识别方法有激光雷达、红外摄像头、基于计算机视觉的图像分割等方法. 井下环境使用激光雷达和红外摄像头,存在设备成本高、易受粉尘与温度干扰等问题,使得此类方法难以在巷道内实现精确且稳定的轨道识别. 相比之下,构建针对井下环境的深度学习模型,基于计算机视觉的图像分割方法能够对复杂背景、弱光照和粉尘环境下的轨道目标进行精确分割,在不断积累的井下数据和多样化的场景训练下逐步提升模型的鲁棒性. 可见,基于计算机视觉的图像分割方法具有成本低、部署灵活、精度高且易于拓展的特点,适合作为井下无人运输系统轨道区域的识别方法,相关研究在降低人工成本与减少事故风险方面具有重要意义. 随着智慧矿山的提出与发展,基于计算机视觉的识别技术被广泛应用于矿山领域场景[2 ] . 卫星等[3 ] 通过在双边网络中改进金字塔结构来获取更大感受野,提高井下轨道的检测精度. 周华平等[4 ] 在实时语义分割网络中,通过增加能够细化特征的特征融合模块,让网络更适合井下轨道检测. 这2种方法都能够很好满足井下轨道检测的实时性要求,但在井下巷道低光照环境中误检率较高. Tong等[5 ] 采用实例分割方法准确识别并分割出轨道上的危险物体(如杂物、岩块). Pirasteh等[6 ] 通过全景分割的方法同时关注语义和实例信息,为障碍物识别提供了全面的场景理解. 上述2种方法虽然提升了网络的准确度,但无法满足环境实时性的需求. 杨豚等[2 ] 基于改进YOLOv5[7 ] 模型,实现对无人驾驶电机车障碍物精准实时检测. 马天等[8 ] 基于改进非对称解码结构实现对井下轨道异物的分割,在保持精度的同时提升了计算效率. 越来越多应用在煤矿领域的深度学习算法偏向在矿井复杂环境中实现精度与速度的均衡,适用于井下边缘设备的检测方法有助于实现煤矿智能化与无人化的目标. ...
基于改进BiSeNet的煤矿井下轨道检测算法
1
2021
... 在电机车行驶过程中有效的检测出轨道区域,对井下无人驾驶技术的发展有重要的研究意义. 常用的煤矿井下轨道识别方法有激光雷达、红外摄像头、基于计算机视觉的图像分割等方法. 井下环境使用激光雷达和红外摄像头,存在设备成本高、易受粉尘与温度干扰等问题,使得此类方法难以在巷道内实现精确且稳定的轨道识别. 相比之下,构建针对井下环境的深度学习模型,基于计算机视觉的图像分割方法能够对复杂背景、弱光照和粉尘环境下的轨道目标进行精确分割,在不断积累的井下数据和多样化的场景训练下逐步提升模型的鲁棒性. 可见,基于计算机视觉的图像分割方法具有成本低、部署灵活、精度高且易于拓展的特点,适合作为井下无人运输系统轨道区域的识别方法,相关研究在降低人工成本与减少事故风险方面具有重要意义. 随着智慧矿山的提出与发展,基于计算机视觉的识别技术被广泛应用于矿山领域场景[2 ] . 卫星等[3 ] 通过在双边网络中改进金字塔结构来获取更大感受野,提高井下轨道的检测精度. 周华平等[4 ] 在实时语义分割网络中,通过增加能够细化特征的特征融合模块,让网络更适合井下轨道检测. 这2种方法都能够很好满足井下轨道检测的实时性要求,但在井下巷道低光照环境中误检率较高. Tong等[5 ] 采用实例分割方法准确识别并分割出轨道上的危险物体(如杂物、岩块). Pirasteh等[6 ] 通过全景分割的方法同时关注语义和实例信息,为障碍物识别提供了全面的场景理解. 上述2种方法虽然提升了网络的准确度,但无法满足环境实时性的需求. 杨豚等[2 ] 基于改进YOLOv5[7 ] 模型,实现对无人驾驶电机车障碍物精准实时检测. 马天等[8 ] 基于改进非对称解码结构实现对井下轨道异物的分割,在保持精度的同时提升了计算效率. 越来越多应用在煤矿领域的深度学习算法偏向在矿井复杂环境中实现精度与速度的均衡,适用于井下边缘设备的检测方法有助于实现煤矿智能化与无人化的目标. ...
基于改进BiSeNet的煤矿井下轨道检测算法
1
2021
... 在电机车行驶过程中有效的检测出轨道区域,对井下无人驾驶技术的发展有重要的研究意义. 常用的煤矿井下轨道识别方法有激光雷达、红外摄像头、基于计算机视觉的图像分割等方法. 井下环境使用激光雷达和红外摄像头,存在设备成本高、易受粉尘与温度干扰等问题,使得此类方法难以在巷道内实现精确且稳定的轨道识别. 相比之下,构建针对井下环境的深度学习模型,基于计算机视觉的图像分割方法能够对复杂背景、弱光照和粉尘环境下的轨道目标进行精确分割,在不断积累的井下数据和多样化的场景训练下逐步提升模型的鲁棒性. 可见,基于计算机视觉的图像分割方法具有成本低、部署灵活、精度高且易于拓展的特点,适合作为井下无人运输系统轨道区域的识别方法,相关研究在降低人工成本与减少事故风险方面具有重要意义. 随着智慧矿山的提出与发展,基于计算机视觉的识别技术被广泛应用于矿山领域场景[2 ] . 卫星等[3 ] 通过在双边网络中改进金字塔结构来获取更大感受野,提高井下轨道的检测精度. 周华平等[4 ] 在实时语义分割网络中,通过增加能够细化特征的特征融合模块,让网络更适合井下轨道检测. 这2种方法都能够很好满足井下轨道检测的实时性要求,但在井下巷道低光照环境中误检率较高. Tong等[5 ] 采用实例分割方法准确识别并分割出轨道上的危险物体(如杂物、岩块). Pirasteh等[6 ] 通过全景分割的方法同时关注语义和实例信息,为障碍物识别提供了全面的场景理解. 上述2种方法虽然提升了网络的准确度,但无法满足环境实时性的需求. 杨豚等[2 ] 基于改进YOLOv5[7 ] 模型,实现对无人驾驶电机车障碍物精准实时检测. 马天等[8 ] 基于改进非对称解码结构实现对井下轨道异物的分割,在保持精度的同时提升了计算效率. 越来越多应用在煤矿领域的深度学习算法偏向在矿井复杂环境中实现精度与速度的均衡,适用于井下边缘设备的检测方法有助于实现煤矿智能化与无人化的目标. ...
Obstacle detection method of underground electric locomotive rail based on instance segmentation
1
2024
... 在电机车行驶过程中有效的检测出轨道区域,对井下无人驾驶技术的发展有重要的研究意义. 常用的煤矿井下轨道识别方法有激光雷达、红外摄像头、基于计算机视觉的图像分割等方法. 井下环境使用激光雷达和红外摄像头,存在设备成本高、易受粉尘与温度干扰等问题,使得此类方法难以在巷道内实现精确且稳定的轨道识别. 相比之下,构建针对井下环境的深度学习模型,基于计算机视觉的图像分割方法能够对复杂背景、弱光照和粉尘环境下的轨道目标进行精确分割,在不断积累的井下数据和多样化的场景训练下逐步提升模型的鲁棒性. 可见,基于计算机视觉的图像分割方法具有成本低、部署灵活、精度高且易于拓展的特点,适合作为井下无人运输系统轨道区域的识别方法,相关研究在降低人工成本与减少事故风险方面具有重要意义. 随着智慧矿山的提出与发展,基于计算机视觉的识别技术被广泛应用于矿山领域场景[2 ] . 卫星等[3 ] 通过在双边网络中改进金字塔结构来获取更大感受野,提高井下轨道的检测精度. 周华平等[4 ] 在实时语义分割网络中,通过增加能够细化特征的特征融合模块,让网络更适合井下轨道检测. 这2种方法都能够很好满足井下轨道检测的实时性要求,但在井下巷道低光照环境中误检率较高. Tong等[5 ] 采用实例分割方法准确识别并分割出轨道上的危险物体(如杂物、岩块). Pirasteh等[6 ] 通过全景分割的方法同时关注语义和实例信息,为障碍物识别提供了全面的场景理解. 上述2种方法虽然提升了网络的准确度,但无法满足环境实时性的需求. 杨豚等[2 ] 基于改进YOLOv5[7 ] 模型,实现对无人驾驶电机车障碍物精准实时检测. 马天等[8 ] 基于改进非对称解码结构实现对井下轨道异物的分割,在保持精度的同时提升了计算效率. 越来越多应用在煤矿领域的深度学习算法偏向在矿井复杂环境中实现精度与速度的均衡,适用于井下边缘设备的检测方法有助于实现煤矿智能化与无人化的目标. ...
Developing an expansion-based obstacle detection using panoptic segmentation
1
2024
... 在电机车行驶过程中有效的检测出轨道区域,对井下无人驾驶技术的发展有重要的研究意义. 常用的煤矿井下轨道识别方法有激光雷达、红外摄像头、基于计算机视觉的图像分割等方法. 井下环境使用激光雷达和红外摄像头,存在设备成本高、易受粉尘与温度干扰等问题,使得此类方法难以在巷道内实现精确且稳定的轨道识别. 相比之下,构建针对井下环境的深度学习模型,基于计算机视觉的图像分割方法能够对复杂背景、弱光照和粉尘环境下的轨道目标进行精确分割,在不断积累的井下数据和多样化的场景训练下逐步提升模型的鲁棒性. 可见,基于计算机视觉的图像分割方法具有成本低、部署灵活、精度高且易于拓展的特点,适合作为井下无人运输系统轨道区域的识别方法,相关研究在降低人工成本与减少事故风险方面具有重要意义. 随着智慧矿山的提出与发展,基于计算机视觉的识别技术被广泛应用于矿山领域场景[2 ] . 卫星等[3 ] 通过在双边网络中改进金字塔结构来获取更大感受野,提高井下轨道的检测精度. 周华平等[4 ] 在实时语义分割网络中,通过增加能够细化特征的特征融合模块,让网络更适合井下轨道检测. 这2种方法都能够很好满足井下轨道检测的实时性要求,但在井下巷道低光照环境中误检率较高. Tong等[5 ] 采用实例分割方法准确识别并分割出轨道上的危险物体(如杂物、岩块). Pirasteh等[6 ] 通过全景分割的方法同时关注语义和实例信息,为障碍物识别提供了全面的场景理解. 上述2种方法虽然提升了网络的准确度,但无法满足环境实时性的需求. 杨豚等[2 ] 基于改进YOLOv5[7 ] 模型,实现对无人驾驶电机车障碍物精准实时检测. 马天等[8 ] 基于改进非对称解码结构实现对井下轨道异物的分割,在保持精度的同时提升了计算效率. 越来越多应用在煤矿领域的深度学习算法偏向在矿井复杂环境中实现精度与速度的均衡,适用于井下边缘设备的检测方法有助于实现煤矿智能化与无人化的目标. ...
Vision-Based obstacle detection in dangerous region of coal mine driverless rail electric locomotives
1
2025
... 在电机车行驶过程中有效的检测出轨道区域,对井下无人驾驶技术的发展有重要的研究意义. 常用的煤矿井下轨道识别方法有激光雷达、红外摄像头、基于计算机视觉的图像分割等方法. 井下环境使用激光雷达和红外摄像头,存在设备成本高、易受粉尘与温度干扰等问题,使得此类方法难以在巷道内实现精确且稳定的轨道识别. 相比之下,构建针对井下环境的深度学习模型,基于计算机视觉的图像分割方法能够对复杂背景、弱光照和粉尘环境下的轨道目标进行精确分割,在不断积累的井下数据和多样化的场景训练下逐步提升模型的鲁棒性. 可见,基于计算机视觉的图像分割方法具有成本低、部署灵活、精度高且易于拓展的特点,适合作为井下无人运输系统轨道区域的识别方法,相关研究在降低人工成本与减少事故风险方面具有重要意义. 随着智慧矿山的提出与发展,基于计算机视觉的识别技术被广泛应用于矿山领域场景[2 ] . 卫星等[3 ] 通过在双边网络中改进金字塔结构来获取更大感受野,提高井下轨道的检测精度. 周华平等[4 ] 在实时语义分割网络中,通过增加能够细化特征的特征融合模块,让网络更适合井下轨道检测. 这2种方法都能够很好满足井下轨道检测的实时性要求,但在井下巷道低光照环境中误检率较高. Tong等[5 ] 采用实例分割方法准确识别并分割出轨道上的危险物体(如杂物、岩块). Pirasteh等[6 ] 通过全景分割的方法同时关注语义和实例信息,为障碍物识别提供了全面的场景理解. 上述2种方法虽然提升了网络的准确度,但无法满足环境实时性的需求. 杨豚等[2 ] 基于改进YOLOv5[7 ] 模型,实现对无人驾驶电机车障碍物精准实时检测. 马天等[8 ] 基于改进非对称解码结构实现对井下轨道异物的分割,在保持精度的同时提升了计算效率. 越来越多应用在煤矿领域的深度学习算法偏向在矿井复杂环境中实现精度与速度的均衡,适用于井下边缘设备的检测方法有助于实现煤矿智能化与无人化的目标. ...
基于非对称编解码结构的井下轨道异物分割方法
1
2026
... 在电机车行驶过程中有效的检测出轨道区域,对井下无人驾驶技术的发展有重要的研究意义. 常用的煤矿井下轨道识别方法有激光雷达、红外摄像头、基于计算机视觉的图像分割等方法. 井下环境使用激光雷达和红外摄像头,存在设备成本高、易受粉尘与温度干扰等问题,使得此类方法难以在巷道内实现精确且稳定的轨道识别. 相比之下,构建针对井下环境的深度学习模型,基于计算机视觉的图像分割方法能够对复杂背景、弱光照和粉尘环境下的轨道目标进行精确分割,在不断积累的井下数据和多样化的场景训练下逐步提升模型的鲁棒性. 可见,基于计算机视觉的图像分割方法具有成本低、部署灵活、精度高且易于拓展的特点,适合作为井下无人运输系统轨道区域的识别方法,相关研究在降低人工成本与减少事故风险方面具有重要意义. 随着智慧矿山的提出与发展,基于计算机视觉的识别技术被广泛应用于矿山领域场景[2 ] . 卫星等[3 ] 通过在双边网络中改进金字塔结构来获取更大感受野,提高井下轨道的检测精度. 周华平等[4 ] 在实时语义分割网络中,通过增加能够细化特征的特征融合模块,让网络更适合井下轨道检测. 这2种方法都能够很好满足井下轨道检测的实时性要求,但在井下巷道低光照环境中误检率较高. Tong等[5 ] 采用实例分割方法准确识别并分割出轨道上的危险物体(如杂物、岩块). Pirasteh等[6 ] 通过全景分割的方法同时关注语义和实例信息,为障碍物识别提供了全面的场景理解. 上述2种方法虽然提升了网络的准确度,但无法满足环境实时性的需求. 杨豚等[2 ] 基于改进YOLOv5[7 ] 模型,实现对无人驾驶电机车障碍物精准实时检测. 马天等[8 ] 基于改进非对称解码结构实现对井下轨道异物的分割,在保持精度的同时提升了计算效率. 越来越多应用在煤矿领域的深度学习算法偏向在矿井复杂环境中实现精度与速度的均衡,适用于井下边缘设备的检测方法有助于实现煤矿智能化与无人化的目标. ...
基于非对称编解码结构的井下轨道异物分割方法
1
2026
... 在电机车行驶过程中有效的检测出轨道区域,对井下无人驾驶技术的发展有重要的研究意义. 常用的煤矿井下轨道识别方法有激光雷达、红外摄像头、基于计算机视觉的图像分割等方法. 井下环境使用激光雷达和红外摄像头,存在设备成本高、易受粉尘与温度干扰等问题,使得此类方法难以在巷道内实现精确且稳定的轨道识别. 相比之下,构建针对井下环境的深度学习模型,基于计算机视觉的图像分割方法能够对复杂背景、弱光照和粉尘环境下的轨道目标进行精确分割,在不断积累的井下数据和多样化的场景训练下逐步提升模型的鲁棒性. 可见,基于计算机视觉的图像分割方法具有成本低、部署灵活、精度高且易于拓展的特点,适合作为井下无人运输系统轨道区域的识别方法,相关研究在降低人工成本与减少事故风险方面具有重要意义. 随着智慧矿山的提出与发展,基于计算机视觉的识别技术被广泛应用于矿山领域场景[2 ] . 卫星等[3 ] 通过在双边网络中改进金字塔结构来获取更大感受野,提高井下轨道的检测精度. 周华平等[4 ] 在实时语义分割网络中,通过增加能够细化特征的特征融合模块,让网络更适合井下轨道检测. 这2种方法都能够很好满足井下轨道检测的实时性要求,但在井下巷道低光照环境中误检率较高. Tong等[5 ] 采用实例分割方法准确识别并分割出轨道上的危险物体(如杂物、岩块). Pirasteh等[6 ] 通过全景分割的方法同时关注语义和实例信息,为障碍物识别提供了全面的场景理解. 上述2种方法虽然提升了网络的准确度,但无法满足环境实时性的需求. 杨豚等[2 ] 基于改进YOLOv5[7 ] 模型,实现对无人驾驶电机车障碍物精准实时检测. 马天等[8 ] 基于改进非对称解码结构实现对井下轨道异物的分割,在保持精度的同时提升了计算效率. 越来越多应用在煤矿领域的深度学习算法偏向在矿井复杂环境中实现精度与速度的均衡,适用于井下边缘设备的检测方法有助于实现煤矿智能化与无人化的目标. ...
1
... Performance metrics comparison of various models on mine-track segmentation dataset
Tab.2 模型 骨干名称 n p /106 mIoU/% FPS(帧·s−1 ) Fast-SCNN[9 ] — 1.44 81.75 21.7 DFANet[10 ] — 7.80 84.50 23.2 ESPNet[11 ] ESP 2.75 80.51 29.6 BiSeNetv1[12 ] ResNet18 4.90 86.21 31.3 STDC[13 ] STDC1 8.29 88.18 19.2 SFNet[14 ] ResNet18 13.81 87.33 15.2 PP-LiteSeg-B[15 ] STDC2 12.25 90.34 17.1 RTFormer-Base[16 ] — 16.87 91.71 17.3 YOLOv10n[17 ] CSPNet 5.70 86.60 44.4 U-Net[18 ] Vgg 24.89 78.89 — PSPNet[19 ] ResNet50 46.71 83.46 — HRNet[20 ] HRNet_W32 29.54 89.29 — DeeplabV3+[21 ] Xception 54.71 93.95 — SegFormer-B2[22 ] MiT-B2 27.35 84.20 — HPRTSNet MobileNetV2 9.88 92.44 23.5
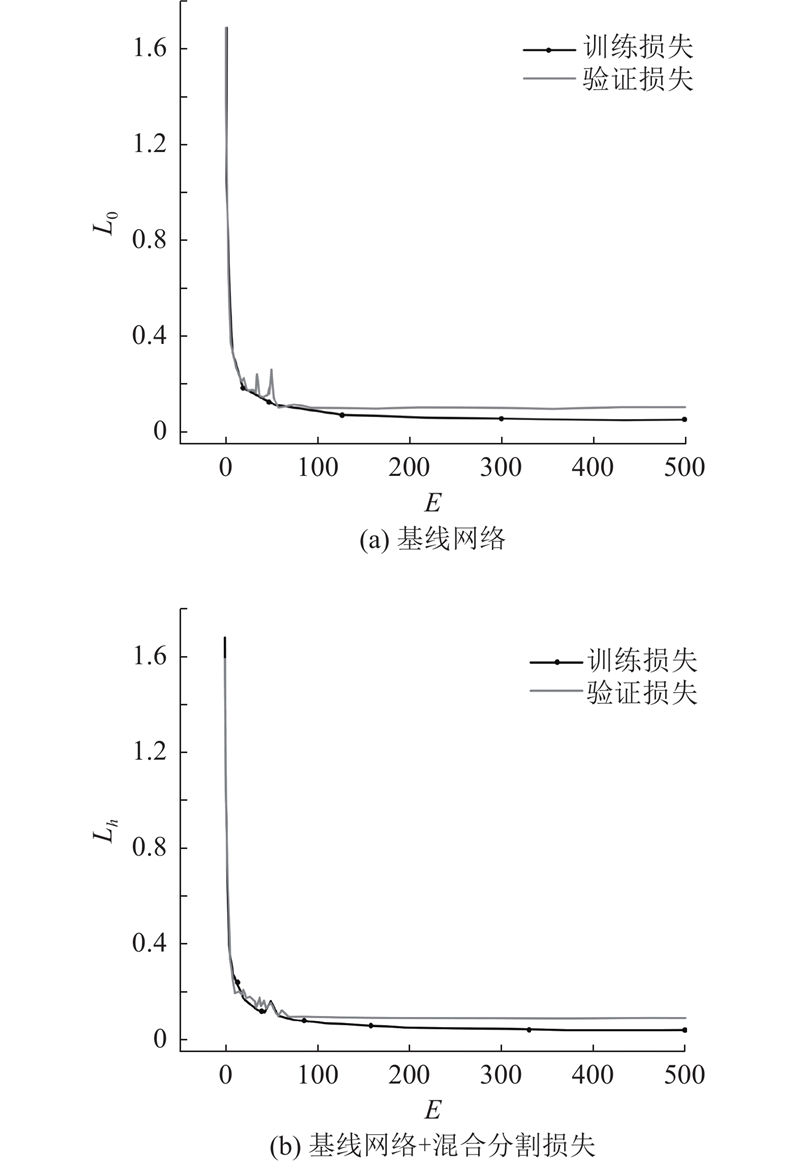
2.6. 模型性能定性分析 在测试集中对比不同模型在实际场景中的分割效果,结果如图7 所示,其中框线标记的是分割效果欠佳的部分. 可以看出,HPRTSNet在自建矿井轨道分割数据集上比其他分割模型的分割结果好,并且边缘处理更加准确;BiseNetv1的分割掩码出现分割不完整的情况且边缘粗糙;PP-LiteSeg-B处理轨道边缘的效果欠佳,该模型的分割效果不如HPRTSNet. 此外,HPRTSNet在识别地下巷道的轨道区域及其周边环境的准确性比其他模型高,且边缘的处理效果较为理想. 对比实验结果证明了所提模型的有效性和鲁棒性. ...
1
... Performance metrics comparison of various models on mine-track segmentation dataset
Tab.2 模型 骨干名称 n p /106 mIoU/% FPS(帧·s−1 ) Fast-SCNN[9 ] — 1.44 81.75 21.7 DFANet[10 ] — 7.80 84.50 23.2 ESPNet[11 ] ESP 2.75 80.51 29.6 BiSeNetv1[12 ] ResNet18 4.90 86.21 31.3 STDC[13 ] STDC1 8.29 88.18 19.2 SFNet[14 ] ResNet18 13.81 87.33 15.2 PP-LiteSeg-B[15 ] STDC2 12.25 90.34 17.1 RTFormer-Base[16 ] — 16.87 91.71 17.3 YOLOv10n[17 ] CSPNet 5.70 86.60 44.4 U-Net[18 ] Vgg 24.89 78.89 — PSPNet[19 ] ResNet50 46.71 83.46 — HRNet[20 ] HRNet_W32 29.54 89.29 — DeeplabV3+[21 ] Xception 54.71 93.95 — SegFormer-B2[22 ] MiT-B2 27.35 84.20 — HPRTSNet MobileNetV2 9.88 92.44 23.5
2.6. 模型性能定性分析 在测试集中对比不同模型在实际场景中的分割效果,结果如图7 所示,其中框线标记的是分割效果欠佳的部分. 可以看出,HPRTSNet在自建矿井轨道分割数据集上比其他分割模型的分割结果好,并且边缘处理更加准确;BiseNetv1的分割掩码出现分割不完整的情况且边缘粗糙;PP-LiteSeg-B处理轨道边缘的效果欠佳,该模型的分割效果不如HPRTSNet. 此外,HPRTSNet在识别地下巷道的轨道区域及其周边环境的准确性比其他模型高,且边缘的处理效果较为理想. 对比实验结果证明了所提模型的有效性和鲁棒性. ...
1
... Performance metrics comparison of various models on mine-track segmentation dataset
Tab.2 模型 骨干名称 n p /106 mIoU/% FPS(帧·s−1 ) Fast-SCNN[9 ] — 1.44 81.75 21.7 DFANet[10 ] — 7.80 84.50 23.2 ESPNet[11 ] ESP 2.75 80.51 29.6 BiSeNetv1[12 ] ResNet18 4.90 86.21 31.3 STDC[13 ] STDC1 8.29 88.18 19.2 SFNet[14 ] ResNet18 13.81 87.33 15.2 PP-LiteSeg-B[15 ] STDC2 12.25 90.34 17.1 RTFormer-Base[16 ] — 16.87 91.71 17.3 YOLOv10n[17 ] CSPNet 5.70 86.60 44.4 U-Net[18 ] Vgg 24.89 78.89 — PSPNet[19 ] ResNet50 46.71 83.46 — HRNet[20 ] HRNet_W32 29.54 89.29 — DeeplabV3+[21 ] Xception 54.71 93.95 — SegFormer-B2[22 ] MiT-B2 27.35 84.20 — HPRTSNet MobileNetV2 9.88 92.44 23.5
2.6. 模型性能定性分析 在测试集中对比不同模型在实际场景中的分割效果,结果如图7 所示,其中框线标记的是分割效果欠佳的部分. 可以看出,HPRTSNet在自建矿井轨道分割数据集上比其他分割模型的分割结果好,并且边缘处理更加准确;BiseNetv1的分割掩码出现分割不完整的情况且边缘粗糙;PP-LiteSeg-B处理轨道边缘的效果欠佳,该模型的分割效果不如HPRTSNet. 此外,HPRTSNet在识别地下巷道的轨道区域及其周边环境的准确性比其他模型高,且边缘的处理效果较为理想. 对比实验结果证明了所提模型的有效性和鲁棒性. ...
1
... Performance metrics comparison of various models on mine-track segmentation dataset
Tab.2 模型 骨干名称 n p /106 mIoU/% FPS(帧·s−1 ) Fast-SCNN[9 ] — 1.44 81.75 21.7 DFANet[10 ] — 7.80 84.50 23.2 ESPNet[11 ] ESP 2.75 80.51 29.6 BiSeNetv1[12 ] ResNet18 4.90 86.21 31.3 STDC[13 ] STDC1 8.29 88.18 19.2 SFNet[14 ] ResNet18 13.81 87.33 15.2 PP-LiteSeg-B[15 ] STDC2 12.25 90.34 17.1 RTFormer-Base[16 ] — 16.87 91.71 17.3 YOLOv10n[17 ] CSPNet 5.70 86.60 44.4 U-Net[18 ] Vgg 24.89 78.89 — PSPNet[19 ] ResNet50 46.71 83.46 — HRNet[20 ] HRNet_W32 29.54 89.29 — DeeplabV3+[21 ] Xception 54.71 93.95 — SegFormer-B2[22 ] MiT-B2 27.35 84.20 — HPRTSNet MobileNetV2 9.88 92.44 23.5
2.6. 模型性能定性分析 在测试集中对比不同模型在实际场景中的分割效果,结果如图7 所示,其中框线标记的是分割效果欠佳的部分. 可以看出,HPRTSNet在自建矿井轨道分割数据集上比其他分割模型的分割结果好,并且边缘处理更加准确;BiseNetv1的分割掩码出现分割不完整的情况且边缘粗糙;PP-LiteSeg-B处理轨道边缘的效果欠佳,该模型的分割效果不如HPRTSNet. 此外,HPRTSNet在识别地下巷道的轨道区域及其周边环境的准确性比其他模型高,且边缘的处理效果较为理想. 对比实验结果证明了所提模型的有效性和鲁棒性. ...
1
... Performance metrics comparison of various models on mine-track segmentation dataset
Tab.2 模型 骨干名称 n p /106 mIoU/% FPS(帧·s−1 ) Fast-SCNN[9 ] — 1.44 81.75 21.7 DFANet[10 ] — 7.80 84.50 23.2 ESPNet[11 ] ESP 2.75 80.51 29.6 BiSeNetv1[12 ] ResNet18 4.90 86.21 31.3 STDC[13 ] STDC1 8.29 88.18 19.2 SFNet[14 ] ResNet18 13.81 87.33 15.2 PP-LiteSeg-B[15 ] STDC2 12.25 90.34 17.1 RTFormer-Base[16 ] — 16.87 91.71 17.3 YOLOv10n[17 ] CSPNet 5.70 86.60 44.4 U-Net[18 ] Vgg 24.89 78.89 — PSPNet[19 ] ResNet50 46.71 83.46 — HRNet[20 ] HRNet_W32 29.54 89.29 — DeeplabV3+[21 ] Xception 54.71 93.95 — SegFormer-B2[22 ] MiT-B2 27.35 84.20 — HPRTSNet MobileNetV2 9.88 92.44 23.5
2.6. 模型性能定性分析 在测试集中对比不同模型在实际场景中的分割效果,结果如图7 所示,其中框线标记的是分割效果欠佳的部分. 可以看出,HPRTSNet在自建矿井轨道分割数据集上比其他分割模型的分割结果好,并且边缘处理更加准确;BiseNetv1的分割掩码出现分割不完整的情况且边缘粗糙;PP-LiteSeg-B处理轨道边缘的效果欠佳,该模型的分割效果不如HPRTSNet. 此外,HPRTSNet在识别地下巷道的轨道区域及其周边环境的准确性比其他模型高,且边缘的处理效果较为理想. 对比实验结果证明了所提模型的有效性和鲁棒性. ...
1
... Performance metrics comparison of various models on mine-track segmentation dataset
Tab.2 模型 骨干名称 n p /106 mIoU/% FPS(帧·s−1 ) Fast-SCNN[9 ] — 1.44 81.75 21.7 DFANet[10 ] — 7.80 84.50 23.2 ESPNet[11 ] ESP 2.75 80.51 29.6 BiSeNetv1[12 ] ResNet18 4.90 86.21 31.3 STDC[13 ] STDC1 8.29 88.18 19.2 SFNet[14 ] ResNet18 13.81 87.33 15.2 PP-LiteSeg-B[15 ] STDC2 12.25 90.34 17.1 RTFormer-Base[16 ] — 16.87 91.71 17.3 YOLOv10n[17 ] CSPNet 5.70 86.60 44.4 U-Net[18 ] Vgg 24.89 78.89 — PSPNet[19 ] ResNet50 46.71 83.46 — HRNet[20 ] HRNet_W32 29.54 89.29 — DeeplabV3+[21 ] Xception 54.71 93.95 — SegFormer-B2[22 ] MiT-B2 27.35 84.20 — HPRTSNet MobileNetV2 9.88 92.44 23.5
2.6. 模型性能定性分析 在测试集中对比不同模型在实际场景中的分割效果,结果如图7 所示,其中框线标记的是分割效果欠佳的部分. 可以看出,HPRTSNet在自建矿井轨道分割数据集上比其他分割模型的分割结果好,并且边缘处理更加准确;BiseNetv1的分割掩码出现分割不完整的情况且边缘粗糙;PP-LiteSeg-B处理轨道边缘的效果欠佳,该模型的分割效果不如HPRTSNet. 此外,HPRTSNet在识别地下巷道的轨道区域及其周边环境的准确性比其他模型高,且边缘的处理效果较为理想. 对比实验结果证明了所提模型的有效性和鲁棒性. ...
1
... Performance metrics comparison of various models on mine-track segmentation dataset
Tab.2 模型 骨干名称 n p /106 mIoU/% FPS(帧·s−1 ) Fast-SCNN[9 ] — 1.44 81.75 21.7 DFANet[10 ] — 7.80 84.50 23.2 ESPNet[11 ] ESP 2.75 80.51 29.6 BiSeNetv1[12 ] ResNet18 4.90 86.21 31.3 STDC[13 ] STDC1 8.29 88.18 19.2 SFNet[14 ] ResNet18 13.81 87.33 15.2 PP-LiteSeg-B[15 ] STDC2 12.25 90.34 17.1 RTFormer-Base[16 ] — 16.87 91.71 17.3 YOLOv10n[17 ] CSPNet 5.70 86.60 44.4 U-Net[18 ] Vgg 24.89 78.89 — PSPNet[19 ] ResNet50 46.71 83.46 — HRNet[20 ] HRNet_W32 29.54 89.29 — DeeplabV3+[21 ] Xception 54.71 93.95 — SegFormer-B2[22 ] MiT-B2 27.35 84.20 — HPRTSNet MobileNetV2 9.88 92.44 23.5
2.6. 模型性能定性分析 在测试集中对比不同模型在实际场景中的分割效果,结果如图7 所示,其中框线标记的是分割效果欠佳的部分. 可以看出,HPRTSNet在自建矿井轨道分割数据集上比其他分割模型的分割结果好,并且边缘处理更加准确;BiseNetv1的分割掩码出现分割不完整的情况且边缘粗糙;PP-LiteSeg-B处理轨道边缘的效果欠佳,该模型的分割效果不如HPRTSNet. 此外,HPRTSNet在识别地下巷道的轨道区域及其周边环境的准确性比其他模型高,且边缘的处理效果较为理想. 对比实验结果证明了所提模型的有效性和鲁棒性. ...
1
... Performance metrics comparison of various models on mine-track segmentation dataset
Tab.2 模型 骨干名称 n p /106 mIoU/% FPS(帧·s−1 ) Fast-SCNN[9 ] — 1.44 81.75 21.7 DFANet[10 ] — 7.80 84.50 23.2 ESPNet[11 ] ESP 2.75 80.51 29.6 BiSeNetv1[12 ] ResNet18 4.90 86.21 31.3 STDC[13 ] STDC1 8.29 88.18 19.2 SFNet[14 ] ResNet18 13.81 87.33 15.2 PP-LiteSeg-B[15 ] STDC2 12.25 90.34 17.1 RTFormer-Base[16 ] — 16.87 91.71 17.3 YOLOv10n[17 ] CSPNet 5.70 86.60 44.4 U-Net[18 ] Vgg 24.89 78.89 — PSPNet[19 ] ResNet50 46.71 83.46 — HRNet[20 ] HRNet_W32 29.54 89.29 — DeeplabV3+[21 ] Xception 54.71 93.95 — SegFormer-B2[22 ] MiT-B2 27.35 84.20 — HPRTSNet MobileNetV2 9.88 92.44 23.5
2.6. 模型性能定性分析 在测试集中对比不同模型在实际场景中的分割效果,结果如图7 所示,其中框线标记的是分割效果欠佳的部分. 可以看出,HPRTSNet在自建矿井轨道分割数据集上比其他分割模型的分割结果好,并且边缘处理更加准确;BiseNetv1的分割掩码出现分割不完整的情况且边缘粗糙;PP-LiteSeg-B处理轨道边缘的效果欠佳,该模型的分割效果不如HPRTSNet. 此外,HPRTSNet在识别地下巷道的轨道区域及其周边环境的准确性比其他模型高,且边缘的处理效果较为理想. 对比实验结果证明了所提模型的有效性和鲁棒性. ...
1
... Performance metrics comparison of various models on mine-track segmentation dataset
Tab.2 模型 骨干名称 n p /106 mIoU/% FPS(帧·s−1 ) Fast-SCNN[9 ] — 1.44 81.75 21.7 DFANet[10 ] — 7.80 84.50 23.2 ESPNet[11 ] ESP 2.75 80.51 29.6 BiSeNetv1[12 ] ResNet18 4.90 86.21 31.3 STDC[13 ] STDC1 8.29 88.18 19.2 SFNet[14 ] ResNet18 13.81 87.33 15.2 PP-LiteSeg-B[15 ] STDC2 12.25 90.34 17.1 RTFormer-Base[16 ] — 16.87 91.71 17.3 YOLOv10n[17 ] CSPNet 5.70 86.60 44.4 U-Net[18 ] Vgg 24.89 78.89 — PSPNet[19 ] ResNet50 46.71 83.46 — HRNet[20 ] HRNet_W32 29.54 89.29 — DeeplabV3+[21 ] Xception 54.71 93.95 — SegFormer-B2[22 ] MiT-B2 27.35 84.20 — HPRTSNet MobileNetV2 9.88 92.44 23.5
2.6. 模型性能定性分析 在测试集中对比不同模型在实际场景中的分割效果,结果如图7 所示,其中框线标记的是分割效果欠佳的部分. 可以看出,HPRTSNet在自建矿井轨道分割数据集上比其他分割模型的分割结果好,并且边缘处理更加准确;BiseNetv1的分割掩码出现分割不完整的情况且边缘粗糙;PP-LiteSeg-B处理轨道边缘的效果欠佳,该模型的分割效果不如HPRTSNet. 此外,HPRTSNet在识别地下巷道的轨道区域及其周边环境的准确性比其他模型高,且边缘的处理效果较为理想. 对比实验结果证明了所提模型的有效性和鲁棒性. ...
1
... Performance metrics comparison of various models on mine-track segmentation dataset
Tab.2 模型 骨干名称 n p /106 mIoU/% FPS(帧·s−1 ) Fast-SCNN[9 ] — 1.44 81.75 21.7 DFANet[10 ] — 7.80 84.50 23.2 ESPNet[11 ] ESP 2.75 80.51 29.6 BiSeNetv1[12 ] ResNet18 4.90 86.21 31.3 STDC[13 ] STDC1 8.29 88.18 19.2 SFNet[14 ] ResNet18 13.81 87.33 15.2 PP-LiteSeg-B[15 ] STDC2 12.25 90.34 17.1 RTFormer-Base[16 ] — 16.87 91.71 17.3 YOLOv10n[17 ] CSPNet 5.70 86.60 44.4 U-Net[18 ] Vgg 24.89 78.89 — PSPNet[19 ] ResNet50 46.71 83.46 — HRNet[20 ] HRNet_W32 29.54 89.29 — DeeplabV3+[21 ] Xception 54.71 93.95 — SegFormer-B2[22 ] MiT-B2 27.35 84.20 — HPRTSNet MobileNetV2 9.88 92.44 23.5
2.6. 模型性能定性分析 在测试集中对比不同模型在实际场景中的分割效果,结果如图7 所示,其中框线标记的是分割效果欠佳的部分. 可以看出,HPRTSNet在自建矿井轨道分割数据集上比其他分割模型的分割结果好,并且边缘处理更加准确;BiseNetv1的分割掩码出现分割不完整的情况且边缘粗糙;PP-LiteSeg-B处理轨道边缘的效果欠佳,该模型的分割效果不如HPRTSNet. 此外,HPRTSNet在识别地下巷道的轨道区域及其周边环境的准确性比其他模型高,且边缘的处理效果较为理想. 对比实验结果证明了所提模型的有效性和鲁棒性. ...
1
... Performance metrics comparison of various models on mine-track segmentation dataset
Tab.2 模型 骨干名称 n p /106 mIoU/% FPS(帧·s−1 ) Fast-SCNN[9 ] — 1.44 81.75 21.7 DFANet[10 ] — 7.80 84.50 23.2 ESPNet[11 ] ESP 2.75 80.51 29.6 BiSeNetv1[12 ] ResNet18 4.90 86.21 31.3 STDC[13 ] STDC1 8.29 88.18 19.2 SFNet[14 ] ResNet18 13.81 87.33 15.2 PP-LiteSeg-B[15 ] STDC2 12.25 90.34 17.1 RTFormer-Base[16 ] — 16.87 91.71 17.3 YOLOv10n[17 ] CSPNet 5.70 86.60 44.4 U-Net[18 ] Vgg 24.89 78.89 — PSPNet[19 ] ResNet50 46.71 83.46 — HRNet[20 ] HRNet_W32 29.54 89.29 — DeeplabV3+[21 ] Xception 54.71 93.95 — SegFormer-B2[22 ] MiT-B2 27.35 84.20 — HPRTSNet MobileNetV2 9.88 92.44 23.5
2.6. 模型性能定性分析 在测试集中对比不同模型在实际场景中的分割效果,结果如图7 所示,其中框线标记的是分割效果欠佳的部分. 可以看出,HPRTSNet在自建矿井轨道分割数据集上比其他分割模型的分割结果好,并且边缘处理更加准确;BiseNetv1的分割掩码出现分割不完整的情况且边缘粗糙;PP-LiteSeg-B处理轨道边缘的效果欠佳,该模型的分割效果不如HPRTSNet. 此外,HPRTSNet在识别地下巷道的轨道区域及其周边环境的准确性比其他模型高,且边缘的处理效果较为理想. 对比实验结果证明了所提模型的有效性和鲁棒性. ...
Deep high-resolution representation learning for visual recognition
1
2021
... Performance metrics comparison of various models on mine-track segmentation dataset
Tab.2 模型 骨干名称 n p /106 mIoU/% FPS(帧·s−1 ) Fast-SCNN[9 ] — 1.44 81.75 21.7 DFANet[10 ] — 7.80 84.50 23.2 ESPNet[11 ] ESP 2.75 80.51 29.6 BiSeNetv1[12 ] ResNet18 4.90 86.21 31.3 STDC[13 ] STDC1 8.29 88.18 19.2 SFNet[14 ] ResNet18 13.81 87.33 15.2 PP-LiteSeg-B[15 ] STDC2 12.25 90.34 17.1 RTFormer-Base[16 ] — 16.87 91.71 17.3 YOLOv10n[17 ] CSPNet 5.70 86.60 44.4 U-Net[18 ] Vgg 24.89 78.89 — PSPNet[19 ] ResNet50 46.71 83.46 — HRNet[20 ] HRNet_W32 29.54 89.29 — DeeplabV3+[21 ] Xception 54.71 93.95 — SegFormer-B2[22 ] MiT-B2 27.35 84.20 — HPRTSNet MobileNetV2 9.88 92.44 23.5
2.6. 模型性能定性分析 在测试集中对比不同模型在实际场景中的分割效果,结果如图7 所示,其中框线标记的是分割效果欠佳的部分. 可以看出,HPRTSNet在自建矿井轨道分割数据集上比其他分割模型的分割结果好,并且边缘处理更加准确;BiseNetv1的分割掩码出现分割不完整的情况且边缘粗糙;PP-LiteSeg-B处理轨道边缘的效果欠佳,该模型的分割效果不如HPRTSNet. 此外,HPRTSNet在识别地下巷道的轨道区域及其周边环境的准确性比其他模型高,且边缘的处理效果较为理想. 对比实验结果证明了所提模型的有效性和鲁棒性. ...
1
... Performance metrics comparison of various models on mine-track segmentation dataset
Tab.2 模型 骨干名称 n p /106 mIoU/% FPS(帧·s−1 ) Fast-SCNN[9 ] — 1.44 81.75 21.7 DFANet[10 ] — 7.80 84.50 23.2 ESPNet[11 ] ESP 2.75 80.51 29.6 BiSeNetv1[12 ] ResNet18 4.90 86.21 31.3 STDC[13 ] STDC1 8.29 88.18 19.2 SFNet[14 ] ResNet18 13.81 87.33 15.2 PP-LiteSeg-B[15 ] STDC2 12.25 90.34 17.1 RTFormer-Base[16 ] — 16.87 91.71 17.3 YOLOv10n[17 ] CSPNet 5.70 86.60 44.4 U-Net[18 ] Vgg 24.89 78.89 — PSPNet[19 ] ResNet50 46.71 83.46 — HRNet[20 ] HRNet_W32 29.54 89.29 — DeeplabV3+[21 ] Xception 54.71 93.95 — SegFormer-B2[22 ] MiT-B2 27.35 84.20 — HPRTSNet MobileNetV2 9.88 92.44 23.5
2.6. 模型性能定性分析 在测试集中对比不同模型在实际场景中的分割效果,结果如图7 所示,其中框线标记的是分割效果欠佳的部分. 可以看出,HPRTSNet在自建矿井轨道分割数据集上比其他分割模型的分割结果好,并且边缘处理更加准确;BiseNetv1的分割掩码出现分割不完整的情况且边缘粗糙;PP-LiteSeg-B处理轨道边缘的效果欠佳,该模型的分割效果不如HPRTSNet. 此外,HPRTSNet在识别地下巷道的轨道区域及其周边环境的准确性比其他模型高,且边缘的处理效果较为理想. 对比实验结果证明了所提模型的有效性和鲁棒性. ...
1
... Performance metrics comparison of various models on mine-track segmentation dataset
Tab.2 模型 骨干名称 n p /106 mIoU/% FPS(帧·s−1 ) Fast-SCNN[9 ] — 1.44 81.75 21.7 DFANet[10 ] — 7.80 84.50 23.2 ESPNet[11 ] ESP 2.75 80.51 29.6 BiSeNetv1[12 ] ResNet18 4.90 86.21 31.3 STDC[13 ] STDC1 8.29 88.18 19.2 SFNet[14 ] ResNet18 13.81 87.33 15.2 PP-LiteSeg-B[15 ] STDC2 12.25 90.34 17.1 RTFormer-Base[16 ] — 16.87 91.71 17.3 YOLOv10n[17 ] CSPNet 5.70 86.60 44.4 U-Net[18 ] Vgg 24.89 78.89 — PSPNet[19 ] ResNet50 46.71 83.46 — HRNet[20 ] HRNet_W32 29.54 89.29 — DeeplabV3+[21 ] Xception 54.71 93.95 — SegFormer-B2[22 ] MiT-B2 27.35 84.20 — HPRTSNet MobileNetV2 9.88 92.44 23.5
2.6. 模型性能定性分析 在测试集中对比不同模型在实际场景中的分割效果,结果如图7 所示,其中框线标记的是分割效果欠佳的部分. 可以看出,HPRTSNet在自建矿井轨道分割数据集上比其他分割模型的分割结果好,并且边缘处理更加准确;BiseNetv1的分割掩码出现分割不完整的情况且边缘粗糙;PP-LiteSeg-B处理轨道边缘的效果欠佳,该模型的分割效果不如HPRTSNet. 此外,HPRTSNet在识别地下巷道的轨道区域及其周边环境的准确性比其他模型高,且边缘的处理效果较为理想. 对比实验结果证明了所提模型的有效性和鲁棒性. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}