[29]
HUANG Yansong, YAO Xifan, JING Xuan, et al DQN-based AGV path planning for situations with multi-starts and multi-targets
[J]. Computer Integrated Manufacturing Systems , 2023 , 29 (8 ): 2550 - 2562
[本文引用: 1]
[30]
XING B, WANG X, LIU Z The wide-area coverage path planning strategy for deep-sea mining vehicle cluster based on deep reinforcement learning
[J]. Journal of Marine Science and Engineering , 2024 , 12 (2 ): 316
DOI:10.3390/jmse12020316
[本文引用: 1]
[31]
王童, 李骜, 宋海荦, 等 基于分层深度强化学习的移动机器人导航方法
[J]. 控制与决策 , 2022 , 37 (11 ): 2799 - 2807
[本文引用: 1]
WANG Tong, LI Ao, SONG Hailuo, et al Navigation method for mobile robot based on hierarchical deep reinforcement learning
[J]. Control and Decision , 2022 , 37 (11 ): 2799 - 2807
[本文引用: 1]
[32]
徐杨, 熊举举, 李论, 等 采用改进的YOLOv5s检测花椒簇
[J]. 农业工程学报 , 2023 , 39 (16 ): 283 - 290
DOI:10.11975/j.issn.1002-6819.202306119
[本文引用: 1]
XU Yang, XIONG Juju, LI Lun, et al Detecting pepper cluster using improved YOLOv5s
[J]. Transactions of the Chinese Society of Agricultural Engineering , 2023 , 39 (16 ): 283 - 290
DOI:10.11975/j.issn.1002-6819.202306119
[本文引用: 1]
[1]
刘宇庭, 郭世杰, 唐术锋, 等 改进A*与ROA-DWA融合的机器人路径规划
[J]. 浙江大学学报: 工学版 , 2024 , 58 (2 ): 360 - 369
[本文引用: 1]
LIU Yuting, GUO Shijie, TANG Shufeng, et al Path planning based on fusion of improved A* and ROA-DWA for robot
[J]. Journal of Zhejiang University: Engineering Science , 2024 , 58 (2 ): 360 - 369
[本文引用: 1]
[2]
章一鸣, 姚文广, 陈海进 动态环境下自主机器人的双机制切向避障
[J]. 浙江大学学报: 工学版 , 2024 , 58 (4 ): 779 - 789
[本文引用: 1]
ZHANG Yiming, YAO Wenguang, CHEN Haijin Dual-mechanism tangential obstacle avoidance of autonomous robots in dynamic environment
[J]. Journal of Zhejiang University: Engineering Science , 2024 , 58 (4 ): 779 - 789
[本文引用: 1]
[3]
侯文慧, 周传起, 程炎, 等 基于轻量化U-Net网络的果园垄间路径识别方法
[J]. 农业机械学报 , 2024 , 55 (2 ): 16 - 27
DOI:10.6041/j.issn.1000-1298.2024.02.002
[本文引用: 1]
HOU Wenhui, ZHOU Chuanqi, CHENG Yan, et al Path recognition method of orchard ridges based on lightweight U-Net
[J]. Transactions of the Chinese Society for Agricultural Machinery , 2024 , 55 (2 ): 16 - 27
DOI:10.6041/j.issn.1000-1298.2024.02.002
[本文引用: 1]
[4]
张万枝, 赵威, 李玉华, 等 基于改进A* 算法+LM-BZS算法的农业机器人路径规划
[J]. 农业机械学报 , 2024 , 55 (8 ): 81 - 92
DOI:10.6041/j.issn.1000-1298.2024.08.007
[本文引用: 1]
ZHANG Wanzhi, ZHAO Wei, LI Yuhua, et al Path planning of agricultural robot based on improved A* and LM-BZS algorithms
[J]. Transactions of the Chinese Society for Agricultural Machinery , 2024 , 55 (8 ): 81 - 92
DOI:10.6041/j.issn.1000-1298.2024.08.007
[本文引用: 1]
[5]
张万枝, 白文静, 吕钊钦, 等 线性时变模型预测控制器提高农业车辆导航路径自动跟踪精度
[J]. 农业工程学报 , 2017 , 33 (13 ): 104 - 111
DOI:10.11975/j.issn.1002-6819.2017.13.014
ZHANG Wanzhi, BAI Wenjing, LÜ Zhaoqin, et al Linear time-varying model predictive controller improving precision of navigation path automatic tracking for agricultural vehicle
[J]. Transactions of the Chinese Society of Agricultural Engineering , 2017 , 33 (13 ): 104 - 111
DOI:10.11975/j.issn.1002-6819.2017.13.014
[6]
刘正铎, 张万枝, 吕钊钦, 等 基于非线性模型的农用车路径跟踪控制器设计与试验
[J]. 农业机械学报 , 2018 , 49 (7 ): 23 - 30
DOI:10.6041/j.issn.1000-1298.2018.07.003
[本文引用: 1]
LIU Zhengduo, ZHANG Wanzhi, LÜ Zhaoqin, et al Design and test of path tracking controller based on nonlinear model prediction
[J]. Transactions of the Chinese Society for Agricultural Machinery , 2018 , 49 (7 ): 23 - 30
DOI:10.6041/j.issn.1000-1298.2018.07.003
[本文引用: 1]
[7]
刘天湖, 张迪, 郑琰, 等 基于改进RRT* 算法的菠萝采收机导航路径规划
[J]. 农业工程学报 , 2022 , 38 (23 ): 20 - 28
DOI:10.11975/j.issn.1002-6819.2022.23.003
[本文引用: 1]
LIU Tianhu, ZHANG Di, ZHENG Yan, et al Navigation path planning of the pineapple harvester based on improved RRT* algorithm
[J]. Transactions of the Chinese Society of Agricultural Engineering , 2022 , 38 (23 ): 20 - 28
DOI:10.11975/j.issn.1002-6819.2022.23.003
[本文引用: 1]
[9]
景云鹏, 金志坤, 刘刚 基于改进蚁群算法的农田平地导航三维路径规划方法
[J]. 农业机械学报 , 2020 , 51 (Suppl.1 ): 333 - 339
[本文引用: 1]
JING Yunpeng, JIN Zhikun, LIU Gang Three dimensional path planning method for navigation of farmland leveling based on improved ant colony algorithm
[J]. Transactions of the Chinese Society for Agricultural Machinery , 2020 , 51 (Suppl.1 ): 333 - 339
[本文引用: 1]
[11]
崔永杰, 王寅初, 何智, 等 基于改进RRT算法的猕猴桃采摘机器人全局路径规划
[J]. 农业机械学报 , 2022 , 53 (6 ): 151 - 158
DOI:10.6041/j.issn.1000-1298.2022.06.015
CUI Yongjie, WANG Yinchu, HE Zhi, et al Global path planning of kiwifruit harvesting robot based on improved RRT algorithm
[J]. Transactions of the Chinese Society for Agricultural Machinery , 2022 , 53 (6 ): 151 - 158
DOI:10.6041/j.issn.1000-1298.2022.06.015
[12]
陈凯, 解印山, 李彦明, 等 多约束情形下的农机全覆盖路径规划方法
[J]. 农业机械学报 , 2022 , 53 (5 ): 17 - 26
DOI:10.6041/j.issn.1000-1298.2022.05.002
[本文引用: 1]
CHEN Kai, XIE Yinshan, LI Yanming, et al Full coverage path planning method of agricultural machinery under multiple constraints
[J]. Transactions of the Chinese Society for Agricultural Machinery , 2022 , 53 (5 ): 17 - 26
DOI:10.6041/j.issn.1000-1298.2022.05.002
[本文引用: 1]
[13]
谢秋菊, 王圣超, MUSABIMANA J, 等 基于深度强化学习的猪舍环境控制策略优化与能耗分析
[J]. 农业机械学报 , 2023 , 54 (11 ): 376 - 384
DOI:10.6041/j.issn.1000-1298.2023.11.036
[本文引用: 1]
XIE Qiuju, WANG Shengchao, MUSABIMANA J, et al Pig building environment optimization control and energy consumption analysis based on deep reinforcement learning
[J]. Transactions of the Chinese Society for Agricultural Machinery , 2023 , 54 (11 ): 376 - 384
DOI:10.6041/j.issn.1000-1298.2023.11.036
[本文引用: 1]
[14]
熊俊涛, 李中行, 陈淑绵, 等 基于深度强化学习的虚拟机器人采摘路径避障规划
[J]. 农业机械学报 , 2020 , 51 (Suppl.2 ): 1 - 10
DOI:10.6041/j.issn.1000-1298.2020.S2.001
[本文引用: 1]
XIONG Juntao, LI Zhonghang, CHEN Shumian, et al Obstacle avoidance planning of virtual robot picking path based on deep reinforcement learning
[J]. Transactions of the Chinese Society for Agricultural Machinery , 2020 , 51 (Suppl.2 ): 1 - 10
DOI:10.6041/j.issn.1000-1298.2020.S2.001
[本文引用: 1]
[15]
IYENGAR K, SPURGEON S, STOYANOV D Deep reinforcement learning for concentric tube robot path following
[J]. IEEE Transactions on Medical Robotics and Bionics , 2024 , 6 (1 ): 18 - 29
DOI:10.1109/TMRB.2023.3310037
[本文引用: 1]
[16]
赵淼, 谢良, 林文静, 等 基于动态选择预测器的深度强化学习投资组合模型
[J]. 计算机科学 , 2024 , 51 (4 ): 344 - 352
DOI:10.11896/jsjkx.230100048
[本文引用: 1]
ZHAO Miao, XIE Liang, LIN Wenjing, et al Deep reinforcement learning portfolio model based on dynamic selectors
[J]. Computer Science , 2024 , 51 (4 ): 344 - 352
DOI:10.11896/jsjkx.230100048
[本文引用: 1]
[17]
GAO A, LU S, XU R, et al Deep reinforcement learning based planning method in state space for lunar rovers
[J]. Engineering Applications of Artificial Intelligence , 2024 , 127 : 107287
DOI:10.1016/j.engappai.2023.107287
[本文引用: 1]
[18]
刘飞, 唐方慧, 刘琳婷, 等 基于Dueling DQN算法的列车运行图节能优化研究
[J]. 都市快轨交通 , 2024 , 37 (2 ): 39 - 46
DOI:10.3969/j.issn.1672-6073.2024.02.006
[本文引用: 1]
LIU Fei, TANG Fanghui, LIU Linting, et al Energy saving optimization of train operation timetable based on a Dueling DQN algorithm
[J]. Urban Rapid Rail Transit , 2024 , 37 (2 ): 39 - 46
DOI:10.3969/j.issn.1672-6073.2024.02.006
[本文引用: 1]
[19]
李航, 廖映华, 黄波 基于改进DQN算法的茶叶采摘机械手路径规划
[J]. 中国农机化学报 , 2023 , 44 (8 ): 198 - 205
[本文引用: 1]
LI Hang, LIAO Yinghua, HUANG Bo Research on path planning of tea picking manipulator based on improved DQN
[J]. Journal of Chinese Agricultural Mechanization , 2023 , 44 (8 ): 198 - 205
[本文引用: 1]
[20]
林俊强, 王红军, 邹湘军, 等 基于DPPO的移动采摘机器人避障路径规划及仿真
[J]. 系统仿真学报 , 2023 , 35 (8 ): 1692 - 1704
[本文引用: 1]
LIN Junqiang, WANG Hongjun, ZOU Xiangjun, et al Obstacle avoidance path planning and simulation of mobile picking robot based on DPPO
[J]. Journal of System Simulation , 2023 , 35 (8 ): 1692 - 1704
[本文引用: 1]
[21]
熊春源, 熊俊涛, 杨振刚, 等 基于深度强化学习的柑橘采摘机械臂路径规划方法
[J]. 华南农业大学学报 , 2023 , 44 (3 ): 473 - 483
DOI:10.7671/j.issn.1001-411X.202206024
[本文引用: 1]
XIONG Chunyuan, XIONG Juntao, YANG Zhengang, et al Path planning method for citrus picking manipulator based on deep reinforcement learning
[J]. Journal of South China Agricultural University , 2023 , 44 (3 ): 473 - 483
DOI:10.7671/j.issn.1001-411X.202206024
[本文引用: 1]
[22]
WANG Y, LU C, WU P, et al Path planning for unmanned surface vehicle based on improved Q-Learning algorithm
[J]. Ocean Engineering , 2024 , 292 : 116510
DOI:10.1016/j.oceaneng.2023.116510
[本文引用: 1]
[23]
ZHOU Q, LIAN Y, WU J, et al An optimized Q-Learning algorithm for mobile robot local path planning
[J]. Knowledge-Based Systems , 2024 , 286 : 111400
DOI:10.1016/j.knosys.2024.111400
[本文引用: 1]
[24]
史殿习, 彭滢璇, 杨焕焕, 等 基于DQN的多智能体深度强化学习运动规划方法
[J]. 计算机科学 , 2024 , 51 (2 ): 268 - 277
DOI:10.11896/jsjkx.230500113
[本文引用: 1]
SHI Dianxi, PENG Yingxuan, YANG Huanhuan, et al DQN-based multi-agent motion planning method with deep reinforcement learning
[J]. Computer Science , 2024 , 51 (2 ): 268 - 277
DOI:10.11896/jsjkx.230500113
[本文引用: 1]
[25]
MIRANDA V R F, NETO A A, FREITAS G M, et al Generalization in deep reinforcement learning for robotic navigation by reward shaping
[J]. IEEE Transactions on Industrial Electronics , 2024 , 71 (6 ): 6013 - 6020
DOI:10.1109/TIE.2023.3290244
[本文引用: 1]
[26]
王鑫, 仲伟志, 王俊智, 等 基于深度强化学习的无人机路径规划与无线电测绘
[J]. 应用科学学报 , 2024 , 42 (2 ): 200 - 210
DOI:10.3969/j.issn.0255-8297.2024.02.002
WANG Xin, ZHONG Weizhi, WANG Junzhi, et al UAV path planning and radio mapping based on deep reinforcement learning
[J]. Journal of Applied Sciences , 2024 , 42 (2 ): 200 - 210
DOI:10.3969/j.issn.0255-8297.2024.02.002
[27]
SAGA R, KOZONO R, TSURUMI Y, et al Deep-reinforcement learning-based route planning with obstacle avoidance for autonomous vessels
[J]. Artificial Life and Robotics , 2024 , 29 (1 ): 136 - 144
DOI:10.1007/s10015-023-00909-4
[本文引用: 1]
[28]
胡洁, 张亚莉, 王团, 等 基于深度强化学习的农田节点数据无人机采集方法
[J]. 农业工程学报 , 2022 , 38 (22 ): 41 - 51
DOI:10.11975/j.issn.1002-6819.2022.22.005
[本文引用: 1]
HU Jie, ZHANG Yali, WANG Tuan, et al UAV collection methods for the farmland nodes data based on deep reinforcement learning
[J]. Transactions of the Chinese Society of Agricultural Engineering , 2022 , 38 (22 ): 41 - 51
DOI:10.11975/j.issn.1002-6819.2022.22.005
[本文引用: 1]
[29]
黄岩松, 姚锡凡, 景轩, 等 基于深度Q网络的多起点多终点AGV路径规划
[J]. 计算机集成制造系统 , 2023 , 29 (8 ): 2550 - 2562
[本文引用: 1]
基于深度Q网络的多起点多终点AGV路径规划
1
2023
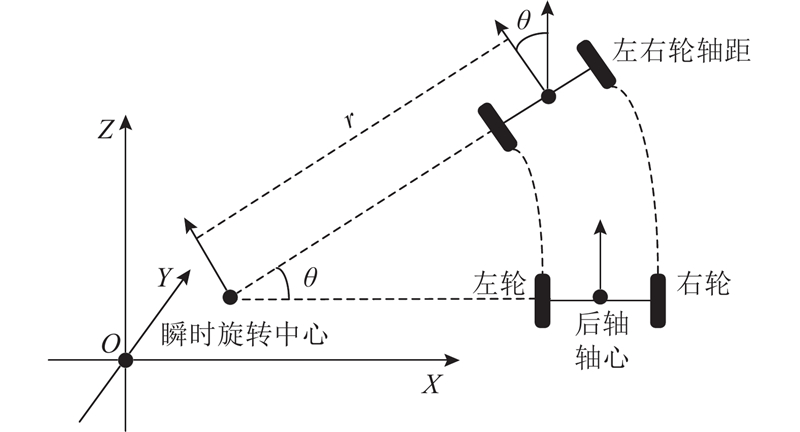
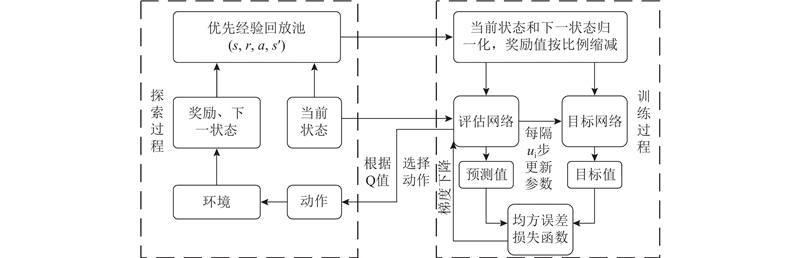
... 式中:Q (s,a;w )为动作价值函数,w 为模型参数,q (s,a )为的动作Q值. 利用经验回放机制将每个时间步智能体与环境交互得到的转移样本{s t a t r t s t+ 1[25 -27 ] . 采用评估网络和目标网络并行方式计算时间差分目标值,以此计算损失函数,通过梯度下降方法更新评估网络参数[28 ] ,再利用延时同步目标网络参数的方式防止过拟合[29 -30 ] . 时间差分目标值计算式、损失函数和网络参数更新式分别为 ...
The wide-area coverage path planning strategy for deep-sea mining vehicle cluster based on deep reinforcement learning
1
2024
... 式中:Q (s,a;w )为动作价值函数,w 为模型参数,q (s,a )为的动作Q值. 利用经验回放机制将每个时间步智能体与环境交互得到的转移样本{s t a t r t s t+ 1[25 -27 ] . 采用评估网络和目标网络并行方式计算时间差分目标值,以此计算损失函数,通过梯度下降方法更新评估网络参数[28 ] ,再利用延时同步目标网络参数的方式防止过拟合[29 -30 ] . 时间差分目标值计算式、损失函数和网络参数更新式分别为 ...
基于分层深度强化学习的移动机器人导航方法
1
2022
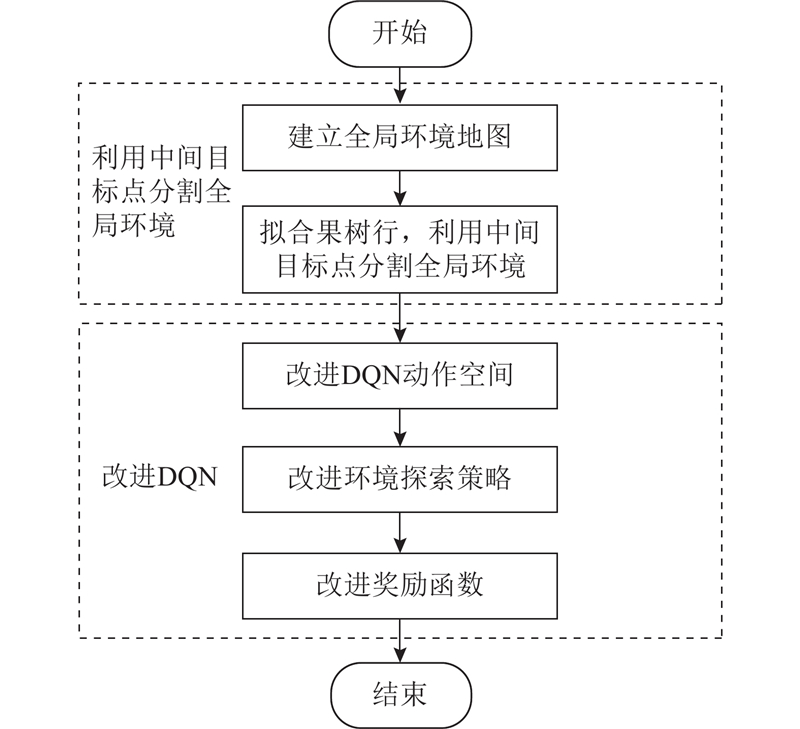
... 传统DQN在进行动态路径规划时仍存在奖励稀疏、收敛缓慢的问题[31 ] ,为了保证机器人的作业效率和稳定性,须进行算法改进. 以前向弓字形作业方式为基础,拟合路径边界,将整体环境分为多条可通行路径,在起点和终点之间设置多个中间目标点,以此将复杂的整体路径切分为多条简单路径,提高机器人到达终点的成功率,加快算法收敛速度. 本研究所提路径规划方法的整体流程如图1 所示. ...
基于分层深度强化学习的移动机器人导航方法
1
2022
... 传统DQN在进行动态路径规划时仍存在奖励稀疏、收敛缓慢的问题[31 ] ,为了保证机器人的作业效率和稳定性,须进行算法改进. 以前向弓字形作业方式为基础,拟合路径边界,将整体环境分为多条可通行路径,在起点和终点之间设置多个中间目标点,以此将复杂的整体路径切分为多条简单路径,提高机器人到达终点的成功率,加快算法收敛速度. 本研究所提路径规划方法的整体流程如图1 所示. ...
采用改进的YOLOv5s检测花椒簇
1
2023
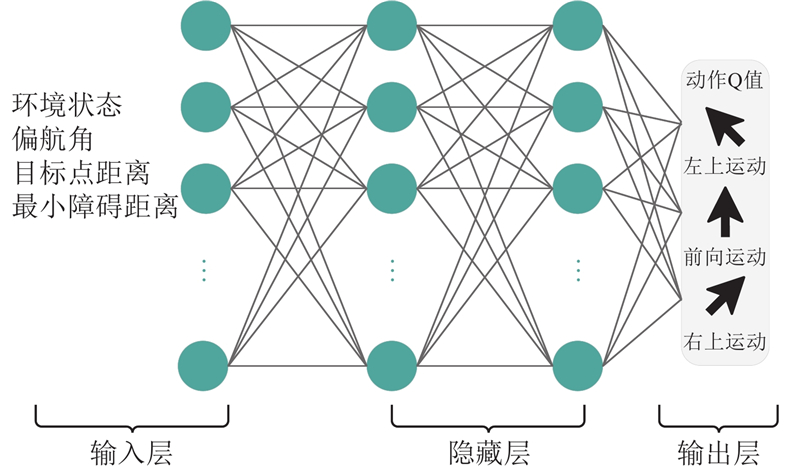
... 如图6 所示,本研究提出的路径规划方法为4层网络结构,其中输入层为28个神经元,隐藏层为2层,每层包含128个神经元,输出层为3个神经元,激活函数为ReLU函数[32 ] ,在输出层之前利用Dropout函数随机使部分神经元失活,防止过拟合现象发生[33 ] . ...
采用改进的YOLOv5s检测花椒簇
1
2023
... 如图6 所示,本研究提出的路径规划方法为4层网络结构,其中输入层为28个神经元,隐藏层为2层,每层包含128个神经元,输出层为3个神经元,激活函数为ReLU函数[32 ] ,在输出层之前利用Dropout函数随机使部分神经元失活,防止过拟合现象发生[33 ] . ...
基于Dropout改进的SRGAN网络DrSRGAN
1
2023
... 如图6 所示,本研究提出的路径规划方法为4层网络结构,其中输入层为28个神经元,隐藏层为2层,每层包含128个神经元,输出层为3个神经元,激活函数为ReLU函数[32 ] ,在输出层之前利用Dropout函数随机使部分神经元失活,防止过拟合现象发生[33 ] . ...
基于Dropout改进的SRGAN网络DrSRGAN
1
2023
... 如图6 所示,本研究提出的路径规划方法为4层网络结构,其中输入层为28个神经元,隐藏层为2层,每层包含128个神经元,输出层为3个神经元,激活函数为ReLU函数[32 ] ,在输出层之前利用Dropout函数随机使部分神经元失活,防止过拟合现象发生[33 ] . ...
改进A*与ROA-DWA融合的机器人路径规划
1
2024
... 随着人工智能技术的快速发展,自动导航作业机器人已应用到农业生产的各个方面[1 -2 ] . 农业机器人在进行自动导航作业前,须根据先验环境进行路径规划[3 ] . 路径规划是农业自动导航的核心技术,机器人须在不碰撞障碍物的前提下规划出寻路代价较低的作业路径,以提高工作效率和作业稳定性[4 -6 ] . ...
改进A*与ROA-DWA融合的机器人路径规划
1
2024
... 随着人工智能技术的快速发展,自动导航作业机器人已应用到农业生产的各个方面[1 -2 ] . 农业机器人在进行自动导航作业前,须根据先验环境进行路径规划[3 ] . 路径规划是农业自动导航的核心技术,机器人须在不碰撞障碍物的前提下规划出寻路代价较低的作业路径,以提高工作效率和作业稳定性[4 -6 ] . ...
动态环境下自主机器人的双机制切向避障
1
2024
... 随着人工智能技术的快速发展,自动导航作业机器人已应用到农业生产的各个方面[1 -2 ] . 农业机器人在进行自动导航作业前,须根据先验环境进行路径规划[3 ] . 路径规划是农业自动导航的核心技术,机器人须在不碰撞障碍物的前提下规划出寻路代价较低的作业路径,以提高工作效率和作业稳定性[4 -6 ] . ...
动态环境下自主机器人的双机制切向避障
1
2024
... 随着人工智能技术的快速发展,自动导航作业机器人已应用到农业生产的各个方面[1 -2 ] . 农业机器人在进行自动导航作业前,须根据先验环境进行路径规划[3 ] . 路径规划是农业自动导航的核心技术,机器人须在不碰撞障碍物的前提下规划出寻路代价较低的作业路径,以提高工作效率和作业稳定性[4 -6 ] . ...
基于轻量化U-Net网络的果园垄间路径识别方法
1
2024
... 随着人工智能技术的快速发展,自动导航作业机器人已应用到农业生产的各个方面[1 -2 ] . 农业机器人在进行自动导航作业前,须根据先验环境进行路径规划[3 ] . 路径规划是农业自动导航的核心技术,机器人须在不碰撞障碍物的前提下规划出寻路代价较低的作业路径,以提高工作效率和作业稳定性[4 -6 ] . ...
基于轻量化U-Net网络的果园垄间路径识别方法
1
2024
... 随着人工智能技术的快速发展,自动导航作业机器人已应用到农业生产的各个方面[1 -2 ] . 农业机器人在进行自动导航作业前,须根据先验环境进行路径规划[3 ] . 路径规划是农业自动导航的核心技术,机器人须在不碰撞障碍物的前提下规划出寻路代价较低的作业路径,以提高工作效率和作业稳定性[4 -6 ] . ...
基于改进A* 算法+LM-BZS算法的农业机器人路径规划
1
2024
... 随着人工智能技术的快速发展,自动导航作业机器人已应用到农业生产的各个方面[1 -2 ] . 农业机器人在进行自动导航作业前,须根据先验环境进行路径规划[3 ] . 路径规划是农业自动导航的核心技术,机器人须在不碰撞障碍物的前提下规划出寻路代价较低的作业路径,以提高工作效率和作业稳定性[4 -6 ] . ...
基于改进A* 算法+LM-BZS算法的农业机器人路径规划
1
2024
... 随着人工智能技术的快速发展,自动导航作业机器人已应用到农业生产的各个方面[1 -2 ] . 农业机器人在进行自动导航作业前,须根据先验环境进行路径规划[3 ] . 路径规划是农业自动导航的核心技术,机器人须在不碰撞障碍物的前提下规划出寻路代价较低的作业路径,以提高工作效率和作业稳定性[4 -6 ] . ...
线性时变模型预测控制器提高农业车辆导航路径自动跟踪精度
0
2017
线性时变模型预测控制器提高农业车辆导航路径自动跟踪精度
0
2017
基于非线性模型的农用车路径跟踪控制器设计与试验
1
2018
... 随着人工智能技术的快速发展,自动导航作业机器人已应用到农业生产的各个方面[1 -2 ] . 农业机器人在进行自动导航作业前,须根据先验环境进行路径规划[3 ] . 路径规划是农业自动导航的核心技术,机器人须在不碰撞障碍物的前提下规划出寻路代价较低的作业路径,以提高工作效率和作业稳定性[4 -6 ] . ...
基于非线性模型的农用车路径跟踪控制器设计与试验
1
2018
... 随着人工智能技术的快速发展,自动导航作业机器人已应用到农业生产的各个方面[1 -2 ] . 农业机器人在进行自动导航作业前,须根据先验环境进行路径规划[3 ] . 路径规划是农业自动导航的核心技术,机器人须在不碰撞障碍物的前提下规划出寻路代价较低的作业路径,以提高工作效率和作业稳定性[4 -6 ] . ...
基于改进RRT* 算法的菠萝采收机导航路径规划
1
2022
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于改进RRT* 算法的菠萝采收机导航路径规划
1
2022
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于改进A* 与DWA算法融合的温室机器人路径规划
1
2021
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于改进A* 与DWA算法融合的温室机器人路径规划
1
2021
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于改进蚁群算法的农田平地导航三维路径规划方法
1
2020
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于改进蚁群算法的农田平地导航三维路径规划方法
1
2020
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
番茄温室内移动喷药机器人的路径规划研究
1
2024
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
番茄温室内移动喷药机器人的路径规划研究
1
2024
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于改进RRT算法的猕猴桃采摘机器人全局路径规划
0
2022
基于改进RRT算法的猕猴桃采摘机器人全局路径规划
0
2022
多约束情形下的农机全覆盖路径规划方法
1
2022
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
多约束情形下的农机全覆盖路径规划方法
1
2022
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于深度强化学习的猪舍环境控制策略优化与能耗分析
1
2023
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于深度强化学习的猪舍环境控制策略优化与能耗分析
1
2023
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于深度强化学习的虚拟机器人采摘路径避障规划
1
2020
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于深度强化学习的虚拟机器人采摘路径避障规划
1
2020
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
Deep reinforcement learning for concentric tube robot path following
1
2024
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于动态选择预测器的深度强化学习投资组合模型
1
2024
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于动态选择预测器的深度强化学习投资组合模型
1
2024
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
Deep reinforcement learning based planning method in state space for lunar rovers
1
2024
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于Dueling DQN算法的列车运行图节能优化研究
1
2024
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于Dueling DQN算法的列车运行图节能优化研究
1
2024
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于改进DQN算法的茶叶采摘机械手路径规划
1
2023
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于改进DQN算法的茶叶采摘机械手路径规划
1
2023
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于DPPO的移动采摘机器人避障路径规划及仿真
1
2023
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于DPPO的移动采摘机器人避障路径规划及仿真
1
2023
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于深度强化学习的柑橘采摘机械臂路径规划方法
1
2023
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
基于深度强化学习的柑橘采摘机械臂路径规划方法
1
2023
... 农业机器人路径规划主要分为传统路径规划和基于深度强化学习的路径规划. 传统路径规划主要分为采样式搜索算法和启发式搜索算法,常见的有快速扩展随机树(rapidly-exploration random tree,RRT)算法、A*算法、蚁群算法等. 刘天湖等[7 ] 提出应用于菠萝采收机器人领域的改进RRT算法;劳彩莲等[8 ] 将A*算法和动态窗口法(dynamic window approach,DWA)进行融合,应用于温室机器人路径规划;景云鹏等[9 ] 提出基于改进蚁群算法的农田机器人路径规划方法. 传统路径规划属于搜索式的非学习类算法,在农业机器人自主导航过程中对环境的自适应能力较弱,作业场景尺寸发生变化或切换作业场景后,须重新搜索路径;新路径因折线段偏多、折线角度偏大而不能直接使用,须融合其他改进算法进行二次平滑处理,降低了工作效率[10 -12 ] . 基于深度强化学习的路径规划是将深度学习的感知能力和强化学习的决策能力相结合,通过控制智能体在大规模、复杂环境中进行学习和决策来获得最大奖励值[13 -14 ] ,能够解决农业机器人在自动导航过程中对环境自适应调整能力不足的问题. 其中在路径规划上应用广泛的深度Q网络算法(deep Q-Network,DQN),它通过神经网络计算每个动作的Q值并选择最优动作与环境进行交互[15 -16 ] ,存在难以找到目标点、奖励稀疏、收敛缓慢等问题[17 -18 ] . 为此,有学者进行了算法改进. 李航等[19 ] 针对茶叶采摘场景提出基于采摘点空间位置和中间难度点结合的方式改进奖励函数,改善了奖励稀疏问题,但存在奖励值振荡剧烈,探索效率偏低的问题. 林俊强等[20 ] 提出针对果园场景的基于人工势场法思想的多维奖励函数,提高了移动采摘机器人的导航成功率,但机器人在复杂场景中的自适应能力较弱,增加了碰撞风险. 熊春源等[21 ] 针对柑橘种植园场景提出以人工势场法结合长短时记忆(long short-term memory, LSTM)方式改进的深度强化学习算法,降低了柑橘采摘机械的路径规划时间和路径长度,但训练过程存在陷入局部最优、收敛速度缓慢的问题. ...
Path planning for unmanned surface vehicle based on improved Q-Learning algorithm
1
2024
... 传统DQN是针对强化学习算法Q-Learning的改进算法[22 ] ,Q-Learning算法的核心是将状态和动作构建成Q表来存储动作Q值,并根据Q值选取能够获得最大收益的动作[23 ] . 传统DQN通过神经网络代替Q-Learning算法中的Q表,根据当前状态s 选出最优动作a ,能够有效解决因状态空间过大引发的维度灾难问题[24 ] . 将神经网络近似函数表示为 ...
An optimized Q-Learning algorithm for mobile robot local path planning
1
2024
... 传统DQN是针对强化学习算法Q-Learning的改进算法[22 ] ,Q-Learning算法的核心是将状态和动作构建成Q表来存储动作Q值,并根据Q值选取能够获得最大收益的动作[23 ] . 传统DQN通过神经网络代替Q-Learning算法中的Q表,根据当前状态s 选出最优动作a ,能够有效解决因状态空间过大引发的维度灾难问题[24 ] . 将神经网络近似函数表示为 ...
基于DQN的多智能体深度强化学习运动规划方法
1
2024
... 传统DQN是针对强化学习算法Q-Learning的改进算法[22 ] ,Q-Learning算法的核心是将状态和动作构建成Q表来存储动作Q值,并根据Q值选取能够获得最大收益的动作[23 ] . 传统DQN通过神经网络代替Q-Learning算法中的Q表,根据当前状态s 选出最优动作a ,能够有效解决因状态空间过大引发的维度灾难问题[24 ] . 将神经网络近似函数表示为 ...
基于DQN的多智能体深度强化学习运动规划方法
1
2024
... 传统DQN是针对强化学习算法Q-Learning的改进算法[22 ] ,Q-Learning算法的核心是将状态和动作构建成Q表来存储动作Q值,并根据Q值选取能够获得最大收益的动作[23 ] . 传统DQN通过神经网络代替Q-Learning算法中的Q表,根据当前状态s 选出最优动作a ,能够有效解决因状态空间过大引发的维度灾难问题[24 ] . 将神经网络近似函数表示为 ...
Generalization in deep reinforcement learning for robotic navigation by reward shaping
1
2024
... 式中:Q (s,a;w )为动作价值函数,w 为模型参数,q (s,a )为的动作Q值. 利用经验回放机制将每个时间步智能体与环境交互得到的转移样本{s t a t r t s t+ 1[25 -27 ] . 采用评估网络和目标网络并行方式计算时间差分目标值,以此计算损失函数,通过梯度下降方法更新评估网络参数[28 ] ,再利用延时同步目标网络参数的方式防止过拟合[29 -30 ] . 时间差分目标值计算式、损失函数和网络参数更新式分别为 ...
基于深度强化学习的无人机路径规划与无线电测绘
0
2024
基于深度强化学习的无人机路径规划与无线电测绘
0
2024
Deep-reinforcement learning-based route planning with obstacle avoidance for autonomous vessels
1
2024
... 式中:Q (s,a;w )为动作价值函数,w 为模型参数,q (s,a )为的动作Q值. 利用经验回放机制将每个时间步智能体与环境交互得到的转移样本{s t a t r t s t+ 1[25 -27 ] . 采用评估网络和目标网络并行方式计算时间差分目标值,以此计算损失函数,通过梯度下降方法更新评估网络参数[28 ] ,再利用延时同步目标网络参数的方式防止过拟合[29 -30 ] . 时间差分目标值计算式、损失函数和网络参数更新式分别为 ...
基于深度强化学习的农田节点数据无人机采集方法
1
2022
... 式中:Q (s,a;w )为动作价值函数,w 为模型参数,q (s,a )为的动作Q值. 利用经验回放机制将每个时间步智能体与环境交互得到的转移样本{s t a t r t s t+ 1[25 -27 ] . 采用评估网络和目标网络并行方式计算时间差分目标值,以此计算损失函数,通过梯度下降方法更新评估网络参数[28 ] ,再利用延时同步目标网络参数的方式防止过拟合[29 -30 ] . 时间差分目标值计算式、损失函数和网络参数更新式分别为 ...
基于深度强化学习的农田节点数据无人机采集方法
1
2022
... 式中:Q (s,a;w )为动作价值函数,w 为模型参数,q (s,a )为的动作Q值. 利用经验回放机制将每个时间步智能体与环境交互得到的转移样本{s t a t r t s t+ 1[25 -27 ] . 采用评估网络和目标网络并行方式计算时间差分目标值,以此计算损失函数,通过梯度下降方法更新评估网络参数[28 ] ,再利用延时同步目标网络参数的方式防止过拟合[29 -30 ] . 时间差分目标值计算式、损失函数和网络参数更新式分别为 ...
基于深度Q网络的多起点多终点AGV路径规划
1
2023
... 式中:Q (s,a;w )为动作价值函数,w 为模型参数,q (s,a )为的动作Q值. 利用经验回放机制将每个时间步智能体与环境交互得到的转移样本{s t a t r t s t+ 1[25 -27 ] . 采用评估网络和目标网络并行方式计算时间差分目标值,以此计算损失函数,通过梯度下降方法更新评估网络参数[28 ] ,再利用延时同步目标网络参数的方式防止过拟合[29 -30 ] . 时间差分目标值计算式、损失函数和网络参数更新式分别为 ...


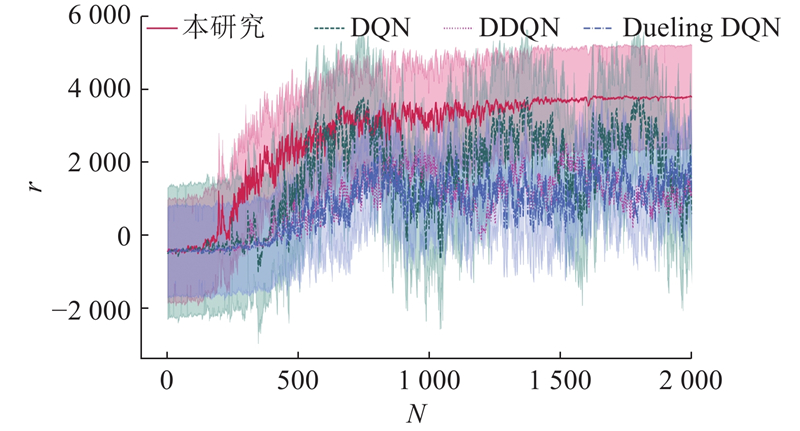
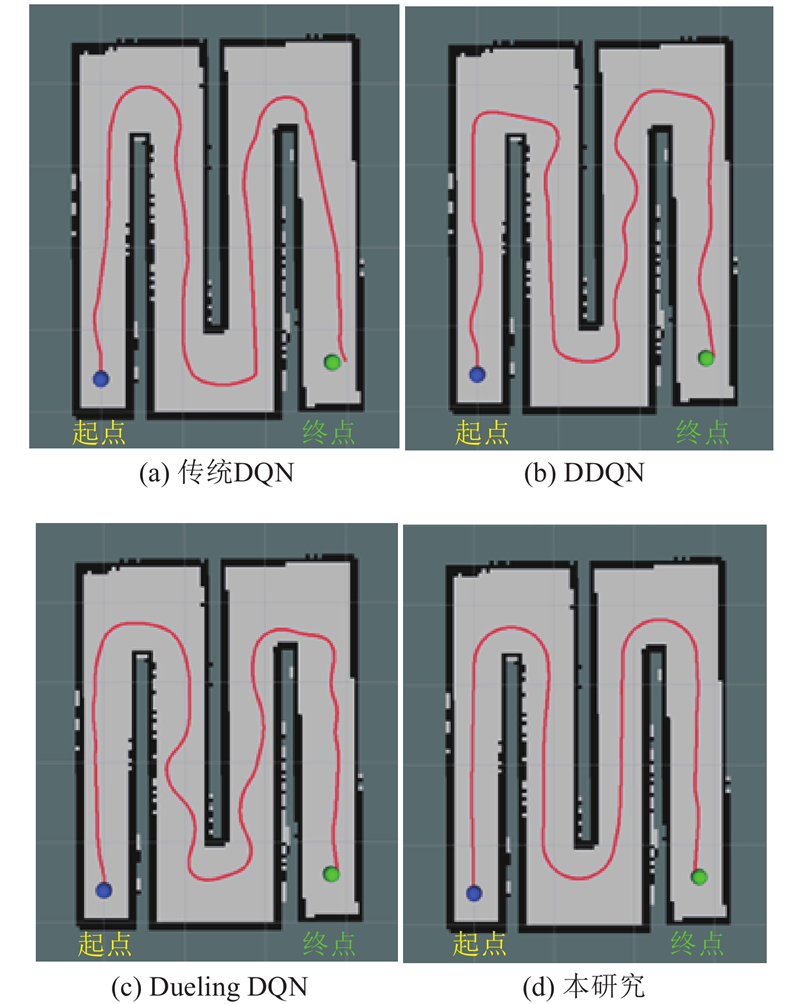



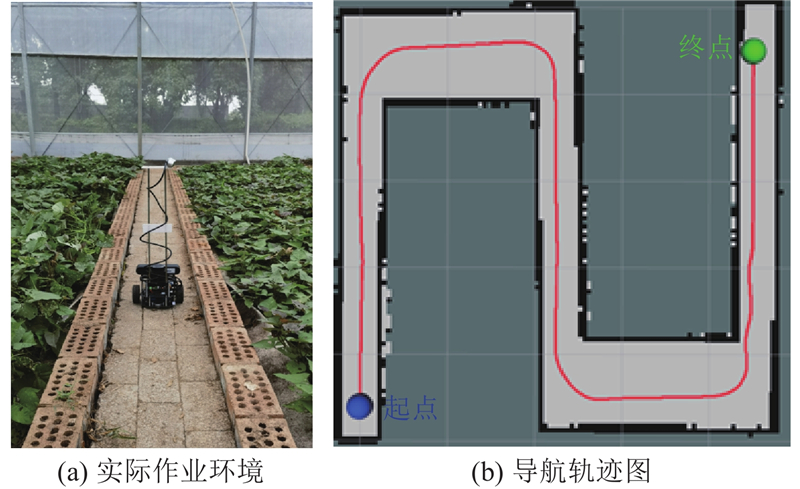

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}