[1]
XIAO D, KANG Z, FU Y, et al Csswin-UNet: a Swin-UNet network for semantic segmentation of remote sensing images by aggregating contextual information and extracting spatial information
[J]. International Journal of Remote Sensing , 2023 , 44 (23 ): 7598 - 7625
DOI:10.1080/01431161.2023.2285738
[本文引用: 1]
[2]
冯志成, 杨杰, 陈智超 基于轻量级Transformer的城市路网提取方法
[J]. 浙江大学学报: 工学版 , 2024 , 58 (1 ): 40 - 49
[本文引用: 1]
FENG Zhicheng, YANG Jie, CHEN Zhichao Urban road network extraction method based on lightweight Transformer
[J]. Journal of Zhejiang University: Engineering Science , 2024 , 58 (1 ): 40 - 49
[本文引用: 1]
[3]
PAN T, ZUO R, WANG Z Geological mapping via convolutional neural network based on remote sensing and geochemical survey data in vegetation coverage areas
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2023 , 16 : 3485 - 3494
DOI:10.1109/JSTARS.2023.3260584
[本文引用: 1]
[4]
JIA P, CHEN C, ZHANG D, et al Semantic segmentation of deep learning remote sensing images based on band combination principle: application in urban planning and land use
[J]. Computer Communications , 2024 , 217 : 97 - 106
DOI:10.1016/j.comcom.2024.01.032
[本文引用: 1]
[5]
ZHENG Z, ZHONG Y, WANG J, et al Building damage assessment for rapid disaster response with a deep object-based semantic change detection framework: from natural disasters to man-made disasters
[J]. Remote Sensing of Environment , 2021 , 265 : 112636
DOI:10.1016/j.rse.2021.112636
[本文引用: 1]
[6]
FU J, LIU J, TIAN H, et al. Dual attention network for scene segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 3141–3149.
[本文引用: 7]
[7]
HU X, ZHANG P, ZHANG Q, et al GLSANet: global-local self-attention network for remote sensing image semantic segmentation
[J]. IEEE Geoscience and Remote Sensing Letters , 2023 , 20 : 6000105
[本文引用: 1]
[8]
CHEN H, QIN Y, LIU X, et al An improved DeepLabv3+ lightweight network for remote-sensing image semantic segmentation
[J]. Complex and Intelligent Systems , 2024 , 10 (2 ): 2839 - 2849
DOI:10.1007/s40747-023-01304-z
[本文引用: 1]
[9]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An Image is worth 16x16 words: Transformers for image recognition at scale [EB/OL]. (2021−06−03)[2024−05−20]. https://arxiv.org/pdf/2010.11929.
[本文引用: 1]
[10]
ZHENG S, LU J, ZHAO H, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with Transformers [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 6877–6886.
[本文引用: 1]
[11]
WANG L, LI R, DUAN C, et al A novel Transformer based semantic segmentation scheme for fine-resolution remote sensing images
[J]. IEEE Geoscience and Remote Sensing Letters , 2022 , 19 : 6506105
[本文引用: 1]
[12]
GAO L, LIU H, YANG M, et al STransFuse: fusing swin Transformer and convolutional neural network for remote sensing image semantic segmentation
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2021 , 14 : 10990 - 11003
DOI:10.1109/JSTARS.2021.3119654
[本文引用: 1]
[13]
雷涛, 翟钰杰, 许叶彤, 等 基于边缘引导和动态可变形Transformer的遥感图像变化检测
[J]. 电子学报 , 2024 , 52 (1 ): 107 - 117
DOI:10.12263/DZXB.20230583
[本文引用: 1]
LEI Tao, ZHAI Yujie, XU Yetong, et al Edge guided and dynamically deformable Transformer network for remote sensing images change detection
[J]. Acta Electronica Sinica , 2024 , 52 (1 ): 107 - 117
DOI:10.12263/DZXB.20230583
[本文引用: 1]
[14]
ZHANG Q, YANG Y B ResT: an efficient Transformer for visual recognition
[J]. Advances in Neural Information Processing Systems , 2021 , 34 : 15475 - 15485
[本文引用: 1]
[15]
YUAN L, CHEN Y, WANG T, et al. Tokens-to-token ViT: training vision Transformers from scratch on ImageNet [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 538–547.
[本文引用: 1]
[16]
ULYANOV D, VEDALDI A, LEMPITSKY V. Instance normalization: the missing ingredient for fast stylization [EB/OL]. (2017−11−06) [2024−05−20]. https://arxiv.org/pdf/1607.08022.
[本文引用: 1]
[17]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7132–7141.
[本文引用: 1]
[18]
HE X, ZHOU Y, ZHAO J, et al Swin Transformer embedding UNet for remote sensing image semantic segmentation
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2022 , 60 : 4408715
[本文引用: 1]
[19]
STERGIOU A, POPPE R, KALLIATAKIS G. Refining activation downsampling with SoftPool [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 10337–10346.
[本文引用: 1]
[20]
何小英, 徐伟铭, 潘凯祥, 等 基于Swin Transformer与卷积神经网络的高分遥感影像分类
[J]. 激光与光电子学进展 , 2024 , 61 (14 ): 1428002
DOI:10.3788/LOP232003
[本文引用: 1]
HE Xiaoying, XU Weiming, PAN Kaixiang, et al Classification of high-resolution remote sensing images based on Swin Transformer and convolutional neural network
[J]. Laser and Optoelectronics Progress , 2024 , 61 (14 ): 1428002
DOI:10.3788/LOP232003
[本文引用: 1]
[21]
XU Z, ZHANG W, ZHANG T, et al Efficient Transformer for remote sensing image segmentation
[J]. Remote Sensing , 2021 , 13 (18 ): 3585
DOI:10.3390/rs13183585
[本文引用: 1]
[22]
WANG D, ZHANG J, DU B, et al. SAMRS: scaling-up remote sensing segmentation dataset with segment anything model [EB/OL]. (2023−10−13)[2024−05−20]. https://arxiv.org/pdf/2305.02034.
[本文引用: 1]
[23]
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 3431–3440.
[本文引用: 6]
[24]
SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5693–5703.
[本文引用: 6]
[25]
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [EB/OL]. (2017−12−05) [2024−05−20]. https://arxiv.org/pdf/1706.05587.
[本文引用: 6]
[26]
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// Medical Image Computing and Computer-Assisted Intervention . [S.l.]: Springer, 2015: 234–241.
[本文引用: 6]
[27]
XIE E, WANG W, YU Z, et al. SegFormer: simple and efficient design for semantic segmentation with Transformers [EB/OL]. (2021−10−28)[2024−05−20]. https://arxiv.org/pdf/2105.15203.
[本文引用: 6]
[28]
CHEN J, LU Y, YU Q, et al. TransUNet: Transformers make strong encoders for medical image segmentation [EB/OL]. (2021−02−08)[2024−05−20]. https://arxiv.org/pdf/2102.04306.
[本文引用: 6]
[29]
CAO H, WANG Y, CHEN J, et al. Swin-UNet: UNet-like pure Transformer for medical image segmentation [C]// Computer Vision – ECCV 2022 Workshops . [S.l.]: Springer, 2023: 205–218.
[本文引用: 6]
Csswin-UNet: a Swin-UNet network for semantic segmentation of remote sensing images by aggregating contextual information and extracting spatial information
1
2023
... 语义分割是遥感图像处理领域的关键技术[1 -2 ] ,通过将图像像素分配给不同的语义类别,实现对地物目标的精细识别和区分,对于地质调查[3 ] 、城市规划[4 ] 和灾害检测[5 ] 等应用具有重要意义. ...
基于轻量级Transformer的城市路网提取方法
1
2024
... 语义分割是遥感图像处理领域的关键技术[1 -2 ] ,通过将图像像素分配给不同的语义类别,实现对地物目标的精细识别和区分,对于地质调查[3 ] 、城市规划[4 ] 和灾害检测[5 ] 等应用具有重要意义. ...
基于轻量级Transformer的城市路网提取方法
1
2024
... 语义分割是遥感图像处理领域的关键技术[1 -2 ] ,通过将图像像素分配给不同的语义类别,实现对地物目标的精细识别和区分,对于地质调查[3 ] 、城市规划[4 ] 和灾害检测[5 ] 等应用具有重要意义. ...
Geological mapping via convolutional neural network based on remote sensing and geochemical survey data in vegetation coverage areas
1
2023
... 语义分割是遥感图像处理领域的关键技术[1 -2 ] ,通过将图像像素分配给不同的语义类别,实现对地物目标的精细识别和区分,对于地质调查[3 ] 、城市规划[4 ] 和灾害检测[5 ] 等应用具有重要意义. ...
Semantic segmentation of deep learning remote sensing images based on band combination principle: application in urban planning and land use
1
2024
... 语义分割是遥感图像处理领域的关键技术[1 -2 ] ,通过将图像像素分配给不同的语义类别,实现对地物目标的精细识别和区分,对于地质调查[3 ] 、城市规划[4 ] 和灾害检测[5 ] 等应用具有重要意义. ...
Building damage assessment for rapid disaster response with a deep object-based semantic change detection framework: from natural disasters to man-made disasters
1
2021
... 语义分割是遥感图像处理领域的关键技术[1 -2 ] ,通过将图像像素分配给不同的语义类别,实现对地物目标的精细识别和区分,对于地质调查[3 ] 、城市规划[4 ] 和灾害检测[5 ] 等应用具有重要意义. ...
7
... 根据不同的模型基本单元,主流的遥感图像分割方法有基于CNN的,也有基于Transformer的. 由于遥感图像中物体尺度小、辨识难度高,研究者通常会引入注意力机制或改进网络结构来增强CNN的特征提取能力. DANet[6 ] 引入通道注意力机制和空间注意力机制来增强有用特征. Hu等[7 ] 将全局孔状注意力机制和局部窗口自注意力机制进行融合,可以同时考虑全局语义特征和局部结构特征. Chen等[8 ] 引入空间金字塔池化模块来捕获多尺度特征,并在解码器中加入残差模块来丰富低维边缘特征. 尽管基于CNN的分割方法效果不错,但CNN固有的局部空间提取能力无法有效捕获全局信息,且实际感受野远小于理论感受野. 随着深度学习的不断发展,基于Transformer的分割方法被逐渐应用于遥感图像分割任务中. 由于基于自注意力机制的Transformer结构在自然语言处理领域取得巨大成功,众多学者将它应用于计算机视觉领域. Dosovitskiy等[9 ] 提出ViT(vision Transformer)结构,将Transformer应用于图像分类中,有效地捕获图像的全局信息. Zheng等[10 ] 将Transformer用作编码器应用于语义分割任务,超越传统CNN架构的分割效果. Wang等[11 ] 将具有多尺度特性的Swin-Transformer作为编码器,使分割效果显著提升. 基于Transformer的分割方法通过自注意力机制可以有效捕获全局信息,但计算复杂度高,在提取低维语义信息上存在限制. ...
... 将CETUNet与主流经典模型:FCN[23 ] 、DANet[6 ] 、HRNet[24 ] 、DeepLabV3[25 ] 、UNet[26 ] 、Segformer[27 ] 、TransUNet[28 ] 和SwinUNet[29 ] 进行对比. 在对比模型中,前5种基于CNN架构,后3种基于Transformer架构. ...
... Comparison of segmentation results of different models in ISPRS Vaihingen dataset
Tab.1 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 78.81 85.45 65.56 74.76 24.25 86.49 65.56 DANet[6 ] 77.80 84.81 63.55 68.33 36.05 84.99 66.11 HRNet[24 ] 78.35 82.72 63.21 75.94 38.49 86.17 67.74 DeepLabV3[25 ] 79.28 86.34 66.05 77.22 30.49 86.34 67.88 Segformer[27 ] 78.88 83.18 61.04 75.39 45.22 85.94 68.74 UNet[26 ] 77.38 83.85 61.04 75.05 34.03 84.43 66.27 TransUNet[28 ] 76.68 81.05 63.46 74.08 46.53 84.80 68.36 SwinUNet[29 ] 74.16 77.85 62.01 73.46 35.62 83.50 64.62 本研究 79.98 84.88 65.27 74.44 57.69 86.51 72.45
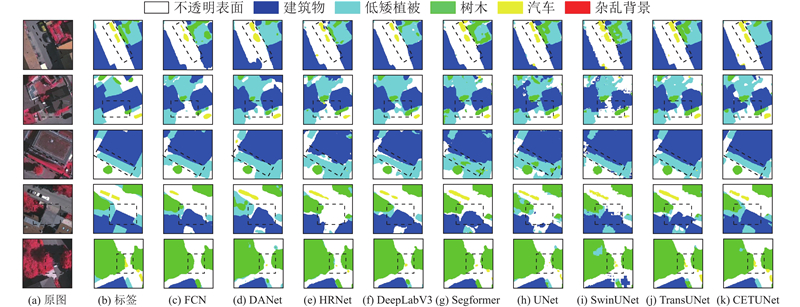
图 7 不同模型在ISPRS Vaihingen数据集上的可视化分割结果 ...
... Comparison of segmentation results of different models in ISPRS Postdam dataset
Tab.2 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 76.31 83.23 64.65 66.03 68.78 86.04 71.80 DANet[6 ] 77.34 82.52 64.73 70.78 79.87 86.94 75.05 HRNet[24 ] 79.11 84.97 67.95 70.53 81.65 87.78 76.84 DeepLabV3[25 ] 78.90 85.23 68.68 70.91 83.17 87.73 77.38 Segformer[27 ] 79.96 86.70 69.72 65.21 77.64 87.09 75.85 UNet[26 ] 76.86 83.74 65.90 63.69 79.13 86.01 73.86 TransUNet[28 ] 79.79 86.13 68.94 66.30 78.63 86.41 75.96 SwinUNet[29 ] 73.01 76.29 61.74 54.27 68.88 80.49 66.83 本研究 86.05 92.60 74.93 73.68 84.17 90.50 82.29
3.1.3. SAMRS 数据集 SAMRS的3个子数据集中部分类别的样本数量有限,为此分别从子数据集中筛选4类特征明显、样本数量较多且具有代表性的类别用于实验. 如表3 所示为在SAMRS SOTA数据集上不同模型的对比结果. 由表可知,CETUNet在参与对比的模型中表现最佳,MIoU=88.81%,OA=94.98%,各类别的分割效果良好;在大尺度目标大车和小尺度目标小车上,CETUNet都有较好的分割精度,表明所提模型可以较好分割不同尺度的地表物体. 相比与其他对比模型,CETUNet的MIoU至少提高了2.72个百分点,OA至少提高了1.61个百分点. 如表4 所示为在SAMRS SIOR数据集上不同模型的对比结果. 由表可知,CETUNet的性能表现最佳,MIoU=97.29%,OA=98.93%;在大尺度目标(棒球场)和小尺度目标(飞机)类别上,IoU=98.65%和94.38%,进一步表明所提模型具有较好的多尺度特征提取能力. 如表5 所示为在SAMRS FAST数据集上不同模型的对比结果. 由表可知,CETUNet的MIoU=86.65%,OA=93.45%,在汽车类别上获得最佳的IoU,为63.93%,在其他类别分割结果中也都表现良好. 相比与其他对比模型,CETUNet的MIoU至少提高了1.33个百分点,OA至少提高了0.56个百分点. CETUNet在SAMRS的3个不同空间分辨率遥感图像数据集上均具有不错的性能表现,验证了所提模型的有效性. ...
... Comparison of segmentation results of different models in SAMRS SOTA dataset
Tab.3 模型 IoU/% OA/% MIoU/% 大车 游泳池 飞机 小车 FCN[23 ] 72.28 68.57 80.53 80.31 84.85 75.42 DANet[6 ] 70.54 77.65 72.14 71.24 82.14 72.89 HRNet[24 ] 77.61 79.78 83.28 83.12 85.45 75.16 DeepLabV3[25 ] 83.20 82.69 91.12 87.37 93.37 86.09 Segformer[27 ] 73.49 85.79 74.81 76.24 87.26 77.58 UNet[26 ] 75.61 74.34 80.37 83.08 87.75 78.35 TransUNet[28 ] 79.24 81.07 91.38 83.98 91.59 83.91 SwinUNet[29 ] 64.92 77.92 64.42 66.90 78.77 68.54 本研究 87.05 84.42 92.98 90.78 94.98 88.81
表 4 不同模型在SAMRS SIOR数据集上的分割结果对比 ...
... Comparison of segmentation results of different models in SAMRS SIOR dataset
Tab.4 模型 IoU/% OA/% MIoU/% 飞机 棒球场 轮船 网球场 FCN[23 ] 82.29 95.61 95.41 95.59 96.97 92.22 DANet[6 ] 78.32 96.11 96.03 96.36 94.59 91.71 HRNet[24 ] 83.01 93.62 94.74 95.67 96.47 91.76 DeepLabV3[25 ] 90.34 96.10 97.69 95.34 97.83 94.87 Segformer[27 ] 73.65 94.10 95.19 91.43 92.65 88.59 UNet[26 ] 77.38 92.03 92.34 96.62 93.47 89.59 TransUNet[28 ] 92.76 96.45 97.18 97.48 97.88 95.97 SwinUNet[29 ] 80.88 95.43 92.65 93.85 94.49 90.70 本研究 94.38 98.65 97.77 98.38 98.93 97.29
表 5 不同模型在SAMRS FAST数据集上的分割结果比较 ...
... Comparison of segmentation results of different models in SAMRS FAST dataset
Tab.5 模型 IoU/% OA/% MIoU/% 棒球场 桥梁 足球场 汽车 FCN[23 ] 80.21 94.17 90.26 63.76 90.63 82.10 DANet[6 ] 84.97 87.29 91.66 55.01 87.88 80.23 HRNet[24 ] 92.32 84.83 91.83 51.51 88.64 80.12 DeepLabV3[25 ] 93.57 95.75 96.98 54.97 92.89 85.32 Segformer[27 ] 87.95 93.87 94.48 42.71 86.77 79.75 UNet[26 ] 84.30 92.78 93.53 59.70 90.21 82.58 TransUNet[28 ] 94.46 85.84 95.66 60.33 91.83 84.07 SwinUNet[29 ] 87.83 90.05 95.29 43.72 87.49 79.22 本研究 93.79 92.91 95.98 63.93 93.45 86.65
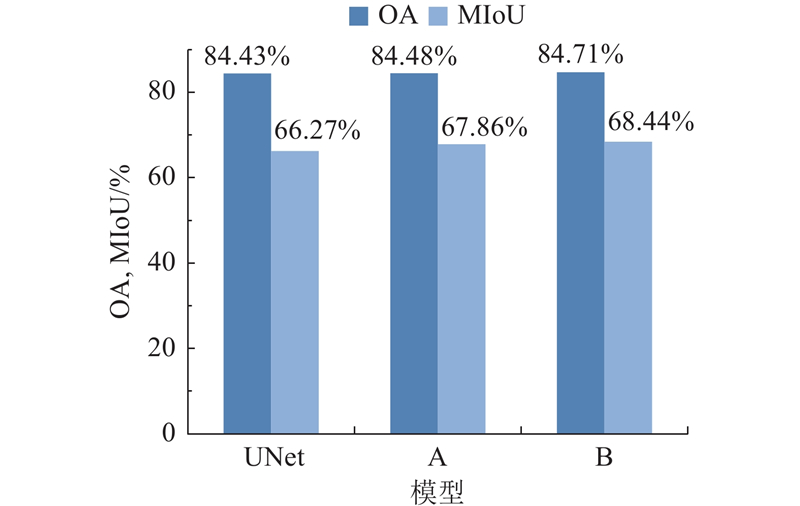
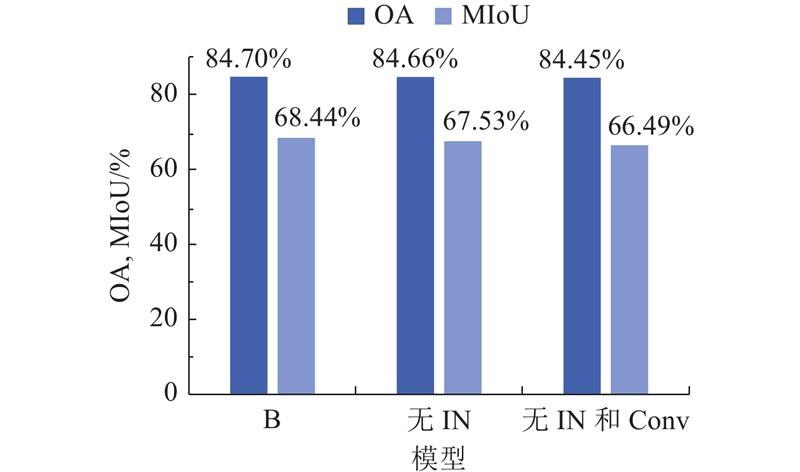
3.2. 消融实验 为了验证所提网络的结构和2个重要模块的有效性,在ISPRS Vaihingen数据集上进行消融实验. ...
GLSANet: global-local self-attention network for remote sensing image semantic segmentation
1
2023
... 根据不同的模型基本单元,主流的遥感图像分割方法有基于CNN的,也有基于Transformer的. 由于遥感图像中物体尺度小、辨识难度高,研究者通常会引入注意力机制或改进网络结构来增强CNN的特征提取能力. DANet[6 ] 引入通道注意力机制和空间注意力机制来增强有用特征. Hu等[7 ] 将全局孔状注意力机制和局部窗口自注意力机制进行融合,可以同时考虑全局语义特征和局部结构特征. Chen等[8 ] 引入空间金字塔池化模块来捕获多尺度特征,并在解码器中加入残差模块来丰富低维边缘特征. 尽管基于CNN的分割方法效果不错,但CNN固有的局部空间提取能力无法有效捕获全局信息,且实际感受野远小于理论感受野. 随着深度学习的不断发展,基于Transformer的分割方法被逐渐应用于遥感图像分割任务中. 由于基于自注意力机制的Transformer结构在自然语言处理领域取得巨大成功,众多学者将它应用于计算机视觉领域. Dosovitskiy等[9 ] 提出ViT(vision Transformer)结构,将Transformer应用于图像分类中,有效地捕获图像的全局信息. Zheng等[10 ] 将Transformer用作编码器应用于语义分割任务,超越传统CNN架构的分割效果. Wang等[11 ] 将具有多尺度特性的Swin-Transformer作为编码器,使分割效果显著提升. 基于Transformer的分割方法通过自注意力机制可以有效捕获全局信息,但计算复杂度高,在提取低维语义信息上存在限制. ...
An improved DeepLabv3+ lightweight network for remote-sensing image semantic segmentation
1
2024
... 根据不同的模型基本单元,主流的遥感图像分割方法有基于CNN的,也有基于Transformer的. 由于遥感图像中物体尺度小、辨识难度高,研究者通常会引入注意力机制或改进网络结构来增强CNN的特征提取能力. DANet[6 ] 引入通道注意力机制和空间注意力机制来增强有用特征. Hu等[7 ] 将全局孔状注意力机制和局部窗口自注意力机制进行融合,可以同时考虑全局语义特征和局部结构特征. Chen等[8 ] 引入空间金字塔池化模块来捕获多尺度特征,并在解码器中加入残差模块来丰富低维边缘特征. 尽管基于CNN的分割方法效果不错,但CNN固有的局部空间提取能力无法有效捕获全局信息,且实际感受野远小于理论感受野. 随着深度学习的不断发展,基于Transformer的分割方法被逐渐应用于遥感图像分割任务中. 由于基于自注意力机制的Transformer结构在自然语言处理领域取得巨大成功,众多学者将它应用于计算机视觉领域. Dosovitskiy等[9 ] 提出ViT(vision Transformer)结构,将Transformer应用于图像分类中,有效地捕获图像的全局信息. Zheng等[10 ] 将Transformer用作编码器应用于语义分割任务,超越传统CNN架构的分割效果. Wang等[11 ] 将具有多尺度特性的Swin-Transformer作为编码器,使分割效果显著提升. 基于Transformer的分割方法通过自注意力机制可以有效捕获全局信息,但计算复杂度高,在提取低维语义信息上存在限制. ...
1
... 根据不同的模型基本单元,主流的遥感图像分割方法有基于CNN的,也有基于Transformer的. 由于遥感图像中物体尺度小、辨识难度高,研究者通常会引入注意力机制或改进网络结构来增强CNN的特征提取能力. DANet[6 ] 引入通道注意力机制和空间注意力机制来增强有用特征. Hu等[7 ] 将全局孔状注意力机制和局部窗口自注意力机制进行融合,可以同时考虑全局语义特征和局部结构特征. Chen等[8 ] 引入空间金字塔池化模块来捕获多尺度特征,并在解码器中加入残差模块来丰富低维边缘特征. 尽管基于CNN的分割方法效果不错,但CNN固有的局部空间提取能力无法有效捕获全局信息,且实际感受野远小于理论感受野. 随着深度学习的不断发展,基于Transformer的分割方法被逐渐应用于遥感图像分割任务中. 由于基于自注意力机制的Transformer结构在自然语言处理领域取得巨大成功,众多学者将它应用于计算机视觉领域. Dosovitskiy等[9 ] 提出ViT(vision Transformer)结构,将Transformer应用于图像分类中,有效地捕获图像的全局信息. Zheng等[10 ] 将Transformer用作编码器应用于语义分割任务,超越传统CNN架构的分割效果. Wang等[11 ] 将具有多尺度特性的Swin-Transformer作为编码器,使分割效果显著提升. 基于Transformer的分割方法通过自注意力机制可以有效捕获全局信息,但计算复杂度高,在提取低维语义信息上存在限制. ...
1
... 根据不同的模型基本单元,主流的遥感图像分割方法有基于CNN的,也有基于Transformer的. 由于遥感图像中物体尺度小、辨识难度高,研究者通常会引入注意力机制或改进网络结构来增强CNN的特征提取能力. DANet[6 ] 引入通道注意力机制和空间注意力机制来增强有用特征. Hu等[7 ] 将全局孔状注意力机制和局部窗口自注意力机制进行融合,可以同时考虑全局语义特征和局部结构特征. Chen等[8 ] 引入空间金字塔池化模块来捕获多尺度特征,并在解码器中加入残差模块来丰富低维边缘特征. 尽管基于CNN的分割方法效果不错,但CNN固有的局部空间提取能力无法有效捕获全局信息,且实际感受野远小于理论感受野. 随着深度学习的不断发展,基于Transformer的分割方法被逐渐应用于遥感图像分割任务中. 由于基于自注意力机制的Transformer结构在自然语言处理领域取得巨大成功,众多学者将它应用于计算机视觉领域. Dosovitskiy等[9 ] 提出ViT(vision Transformer)结构,将Transformer应用于图像分类中,有效地捕获图像的全局信息. Zheng等[10 ] 将Transformer用作编码器应用于语义分割任务,超越传统CNN架构的分割效果. Wang等[11 ] 将具有多尺度特性的Swin-Transformer作为编码器,使分割效果显著提升. 基于Transformer的分割方法通过自注意力机制可以有效捕获全局信息,但计算复杂度高,在提取低维语义信息上存在限制. ...
A novel Transformer based semantic segmentation scheme for fine-resolution remote sensing images
1
2022
... 根据不同的模型基本单元,主流的遥感图像分割方法有基于CNN的,也有基于Transformer的. 由于遥感图像中物体尺度小、辨识难度高,研究者通常会引入注意力机制或改进网络结构来增强CNN的特征提取能力. DANet[6 ] 引入通道注意力机制和空间注意力机制来增强有用特征. Hu等[7 ] 将全局孔状注意力机制和局部窗口自注意力机制进行融合,可以同时考虑全局语义特征和局部结构特征. Chen等[8 ] 引入空间金字塔池化模块来捕获多尺度特征,并在解码器中加入残差模块来丰富低维边缘特征. 尽管基于CNN的分割方法效果不错,但CNN固有的局部空间提取能力无法有效捕获全局信息,且实际感受野远小于理论感受野. 随着深度学习的不断发展,基于Transformer的分割方法被逐渐应用于遥感图像分割任务中. 由于基于自注意力机制的Transformer结构在自然语言处理领域取得巨大成功,众多学者将它应用于计算机视觉领域. Dosovitskiy等[9 ] 提出ViT(vision Transformer)结构,将Transformer应用于图像分类中,有效地捕获图像的全局信息. Zheng等[10 ] 将Transformer用作编码器应用于语义分割任务,超越传统CNN架构的分割效果. Wang等[11 ] 将具有多尺度特性的Swin-Transformer作为编码器,使分割效果显著提升. 基于Transformer的分割方法通过自注意力机制可以有效捕获全局信息,但计算复杂度高,在提取低维语义信息上存在限制. ...
STransFuse: fusing swin Transformer and convolutional neural network for remote sensing image semantic segmentation
1
2021
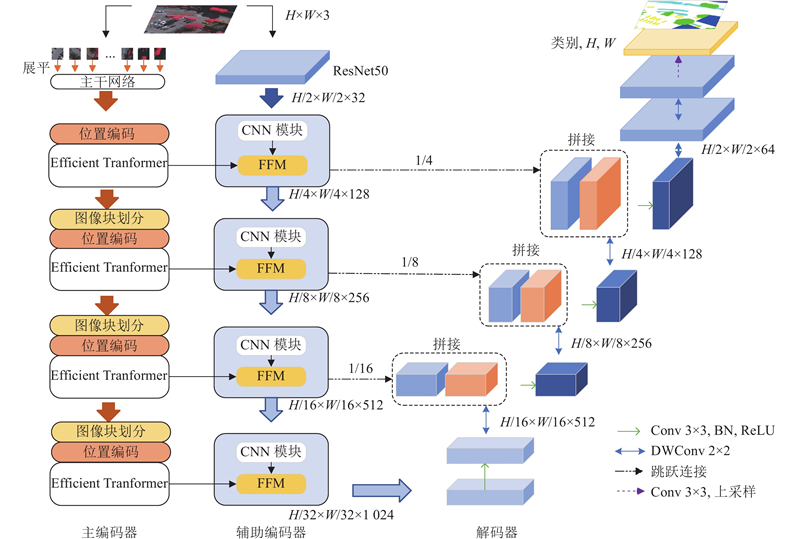
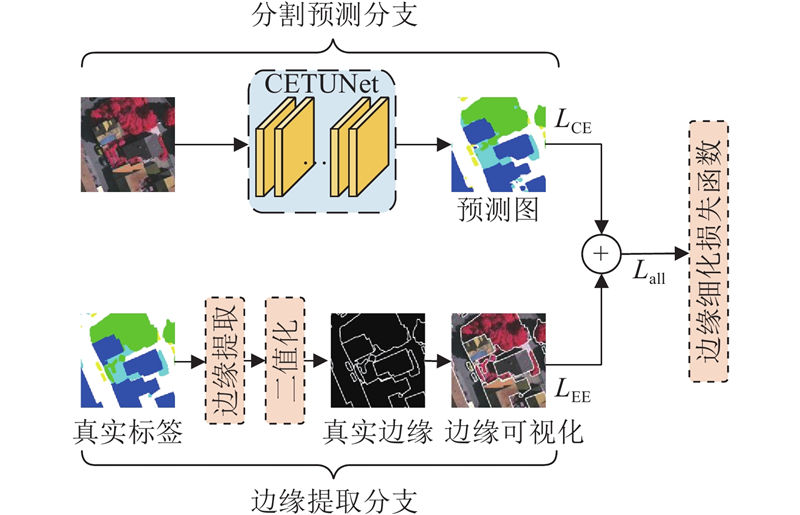
... CNN模型在特征提取前期采用小尺度卷积核,导致感受野不足,Transformer能够很好地补充全局上下文信息. 许多学者将CNN与Transformer结合应用于遥感图像分割领域. Gao等[12 ] 混合CNN与Transformer作为编码器,使遥感图像的分割效果显著增强. 雷涛等[13 ] 将动态可变形Transformer和CNN进行混合,有效提高了模型多尺度特征提取能力. 上述研究结合CNN和Transformer的优点,有效突破单一模型的限制,但存在以下问题:1)传统Transformer使用固定大小的绝对位置编码,无法充分表达遥感图像中复杂的空间结构关系. 2)简单直接的融合方法不能充分发挥两者的优势. 3)在分割相邻目标时,目标的边缘分割效果不佳. 本研究1)将Efficient Transformer[14 ] 作为主编码器,将CNN作为辅助编码器,构建双编码结构. Efficient Transformer模块采用卷积式位置编码,动态解析遥感图像中的复杂空间结构关系;CNN模块使用残差网络,充分提取图像中的局部细节信息. 2)采用具有精细化融合策略的特征融合模块(feature fusion module,FFM)融合2个编码器的特征信息. 3)提出边缘细化损失函数(edge thinning loss,ETL),通过改善损失函数来缓解边缘分割不准确的问题. ...
基于边缘引导和动态可变形Transformer的遥感图像变化检测
1
2024
... CNN模型在特征提取前期采用小尺度卷积核,导致感受野不足,Transformer能够很好地补充全局上下文信息. 许多学者将CNN与Transformer结合应用于遥感图像分割领域. Gao等[12 ] 混合CNN与Transformer作为编码器,使遥感图像的分割效果显著增强. 雷涛等[13 ] 将动态可变形Transformer和CNN进行混合,有效提高了模型多尺度特征提取能力. 上述研究结合CNN和Transformer的优点,有效突破单一模型的限制,但存在以下问题:1)传统Transformer使用固定大小的绝对位置编码,无法充分表达遥感图像中复杂的空间结构关系. 2)简单直接的融合方法不能充分发挥两者的优势. 3)在分割相邻目标时,目标的边缘分割效果不佳. 本研究1)将Efficient Transformer[14 ] 作为主编码器,将CNN作为辅助编码器,构建双编码结构. Efficient Transformer模块采用卷积式位置编码,动态解析遥感图像中的复杂空间结构关系;CNN模块使用残差网络,充分提取图像中的局部细节信息. 2)采用具有精细化融合策略的特征融合模块(feature fusion module,FFM)融合2个编码器的特征信息. 3)提出边缘细化损失函数(edge thinning loss,ETL),通过改善损失函数来缓解边缘分割不准确的问题. ...
基于边缘引导和动态可变形Transformer的遥感图像变化检测
1
2024
... CNN模型在特征提取前期采用小尺度卷积核,导致感受野不足,Transformer能够很好地补充全局上下文信息. 许多学者将CNN与Transformer结合应用于遥感图像分割领域. Gao等[12 ] 混合CNN与Transformer作为编码器,使遥感图像的分割效果显著增强. 雷涛等[13 ] 将动态可变形Transformer和CNN进行混合,有效提高了模型多尺度特征提取能力. 上述研究结合CNN和Transformer的优点,有效突破单一模型的限制,但存在以下问题:1)传统Transformer使用固定大小的绝对位置编码,无法充分表达遥感图像中复杂的空间结构关系. 2)简单直接的融合方法不能充分发挥两者的优势. 3)在分割相邻目标时,目标的边缘分割效果不佳. 本研究1)将Efficient Transformer[14 ] 作为主编码器,将CNN作为辅助编码器,构建双编码结构. Efficient Transformer模块采用卷积式位置编码,动态解析遥感图像中的复杂空间结构关系;CNN模块使用残差网络,充分提取图像中的局部细节信息. 2)采用具有精细化融合策略的特征融合模块(feature fusion module,FFM)融合2个编码器的特征信息. 3)提出边缘细化损失函数(edge thinning loss,ETL),通过改善损失函数来缓解边缘分割不准确的问题. ...
ResT: an efficient Transformer for visual recognition
1
2021
... CNN模型在特征提取前期采用小尺度卷积核,导致感受野不足,Transformer能够很好地补充全局上下文信息. 许多学者将CNN与Transformer结合应用于遥感图像分割领域. Gao等[12 ] 混合CNN与Transformer作为编码器,使遥感图像的分割效果显著增强. 雷涛等[13 ] 将动态可变形Transformer和CNN进行混合,有效提高了模型多尺度特征提取能力. 上述研究结合CNN和Transformer的优点,有效突破单一模型的限制,但存在以下问题:1)传统Transformer使用固定大小的绝对位置编码,无法充分表达遥感图像中复杂的空间结构关系. 2)简单直接的融合方法不能充分发挥两者的优势. 3)在分割相邻目标时,目标的边缘分割效果不佳. 本研究1)将Efficient Transformer[14 ] 作为主编码器,将CNN作为辅助编码器,构建双编码结构. Efficient Transformer模块采用卷积式位置编码,动态解析遥感图像中的复杂空间结构关系;CNN模块使用残差网络,充分提取图像中的局部细节信息. 2)采用具有精细化融合策略的特征融合模块(feature fusion module,FFM)融合2个编码器的特征信息. 3)提出边缘细化损失函数(edge thinning loss,ETL),通过改善损失函数来缓解边缘分割不准确的问题. ...
1
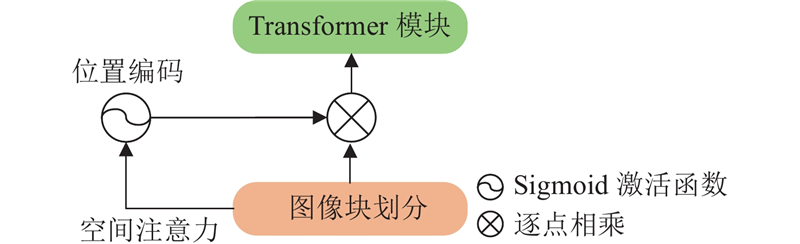
... 传统的ViT将输入图像进行切分后再展平,得到切片序列. 这种简单的标记方法不具备提取多尺度特征信息的能力[15 ] ,本研究的图像块划分部分采用分层编码的方式来提取不同尺度的全局信息. 传统Transformer中的位置编码固定,当输入图像和位置编码大小不匹配时须通过插值操作来适应输入序列的长度,而插值操作易造成图像边缘模糊. 本研究利用结合逐像素注意力(pixel-wise attention,PA)的卷积式位置编码来缓解边缘模糊问题,其中深度卷积f DW 为输入序列分配权重,再通过Sigmoid函数f s 进行调整,计算式为 ...
1
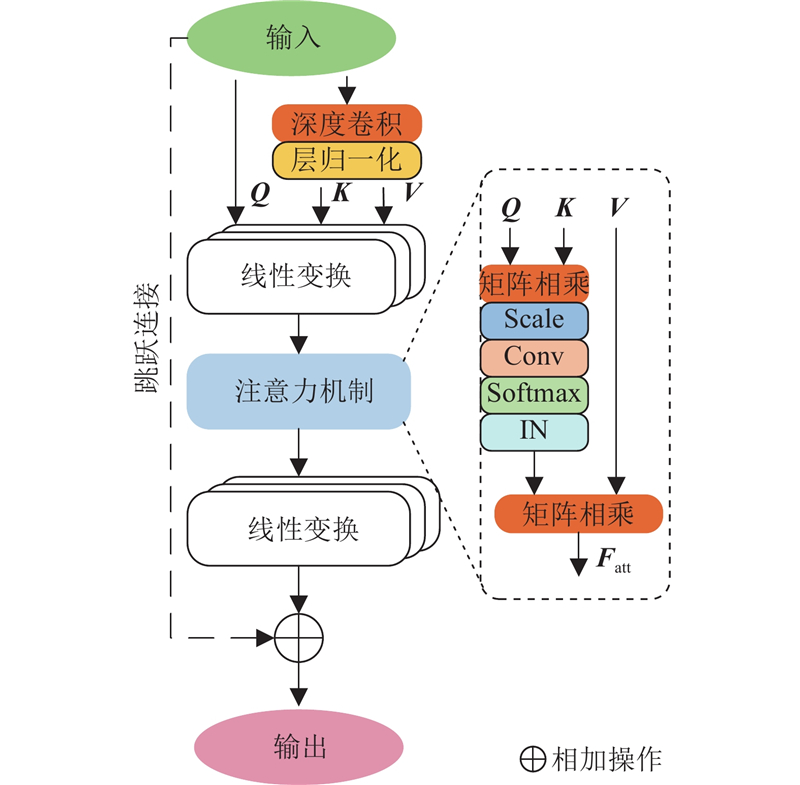
... 式中:$ l\in \{0,\cdot \cdot \cdot ,L-1\} $ L 为编码阶段的特征提取层数;f LN 为层归一化;f MLP 为多层感知器. 高效多头注意力模块f EMSA 与上一层的输出残差连接得到${{z'}_{ l+1}} $ . 如图3 所示,EMSA模块由1×1卷积、深度卷积、层归一化、线性层、实例层归一化[16 ] (instance normalization,IN)和Softmax激活函数组成. 与多头注意力类似,输入特征通过线性变换来获得查询矩阵Q s 倍;经过层归一化调整得到键矩阵K V s 由EMSA中注意力头的数量k 自适应得到,即s=k /8. 在注意力机制中,将Q K T 进行矩阵相乘,获得注意力矩阵并添加缩放因子(Scale)强化模型泛化性. 卷积Conv可以对各注意力头之间的交互进行建模,但会削弱注意力头的独立性和位置感知能力,为此引入实例层归一化来恢复和增强注意力头之间的多样性能力: ...
1
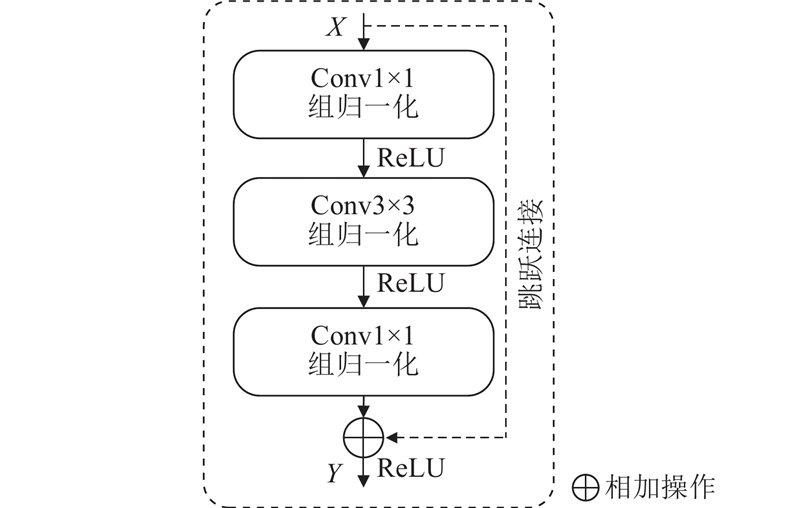
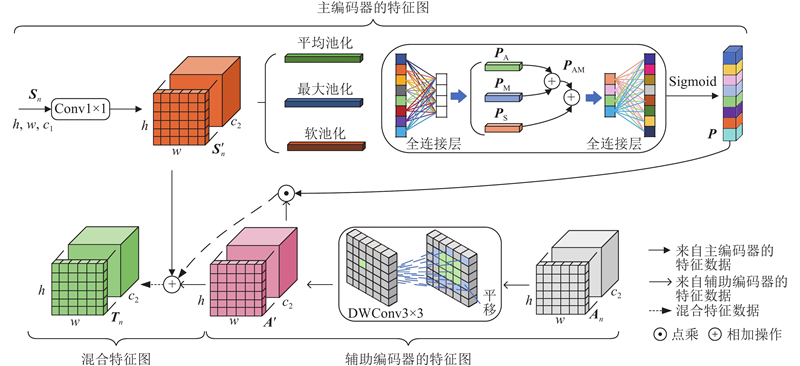
... 在遥感图像分割任务中,结合局部细节信息和上下文信息至关重要. CNN在提取局部特征方面表现出色[17 ] ,Efficient Transformer在捕获长距离特征信息方面具有优势,本研究设计如图5 所示的特征融合模块,充分发挥两者的优点. 图中,S n A n n 层的主编码器和辅助编码器的输出. 为了提高辅助编码器的特征细化能力,将A n [18 ] ,将S n P AM . 使用该池化操作时容易丢失图像中的信息,为此同时使用具有指数加权累加特性软池化[19 ] 操作来计算全局特征权重矩阵P S ,尽可能减少池化操作过程中信息的丢失. 经池化处理后的全局特征P ${\boldsymbol{A}}'_{n} $ T n
Swin Transformer embedding UNet for remote sensing image semantic segmentation
1
2022
... 在遥感图像分割任务中,结合局部细节信息和上下文信息至关重要. CNN在提取局部特征方面表现出色[17 ] ,Efficient Transformer在捕获长距离特征信息方面具有优势,本研究设计如图5 所示的特征融合模块,充分发挥两者的优点. 图中,S n A n n 层的主编码器和辅助编码器的输出. 为了提高辅助编码器的特征细化能力,将A n [18 ] ,将S n P AM . 使用该池化操作时容易丢失图像中的信息,为此同时使用具有指数加权累加特性软池化[19 ] 操作来计算全局特征权重矩阵P S ,尽可能减少池化操作过程中信息的丢失. 经池化处理后的全局特征P ${\boldsymbol{A}}'_{n} $ T n
1
... 在遥感图像分割任务中,结合局部细节信息和上下文信息至关重要. CNN在提取局部特征方面表现出色[17 ] ,Efficient Transformer在捕获长距离特征信息方面具有优势,本研究设计如图5 所示的特征融合模块,充分发挥两者的优点. 图中,S n A n n 层的主编码器和辅助编码器的输出. 为了提高辅助编码器的特征细化能力,将A n [18 ] ,将S n P AM . 使用该池化操作时容易丢失图像中的信息,为此同时使用具有指数加权累加特性软池化[19 ] 操作来计算全局特征权重矩阵P S ,尽可能减少池化操作过程中信息的丢失. 经池化处理后的全局特征P ${\boldsymbol{A}}'_{n} $ T n
基于Swin Transformer与卷积神经网络的高分遥感影像分类
1
2024
... ISPRS Vaihingen数据集[20 ] 包含有33张航拍影像,空间分辨率约为9 cm,图片大小范围:1 900×1 900至3 000×3 000. 数据集中16张图片用于模型训练,其余17张用于测试. ...
基于Swin Transformer与卷积神经网络的高分遥感影像分类
1
2024
... ISPRS Vaihingen数据集[20 ] 包含有33张航拍影像,空间分辨率约为9 cm,图片大小范围:1 900×1 900至3 000×3 000. 数据集中16张图片用于模型训练,其余17张用于测试. ...
Efficient Transformer for remote sensing image segmentation
1
2021
... ISPRS Potsdam数据集[21 ] 包含38张6 000×6 000像素的航拍影像,空间分辨率为5 cm. 标签类别与ISPRS Vaihingen数据集一致,其中24张图片用于模型训练,其余14张用于测试. ...
1
... SAMRS数据集[22 ] 包含3个不同分辨率的遥感图像分割数据子集:SOTA、SIOR和FAST. SAMRS SOTA数据集包含18个类别共17 480张大小为1 024×1 024像素的遥感图像和标签,其中16 678张用于模型训练,802张用于测试. SAMRS SIOR数据集包含20个类别共23 461张大小为800×800像素的遥感图像和标签,其中20 111张图片用于模型训练,3 350张用于测试. SAMRS FAST包含37个类别共64 147张大小为600×600像素的遥感图像和标签,其中57 747张用于模型训练,6 400张用于测试. ...
6
... 将CETUNet与主流经典模型:FCN[23 ] 、DANet[6 ] 、HRNet[24 ] 、DeepLabV3[25 ] 、UNet[26 ] 、Segformer[27 ] 、TransUNet[28 ] 和SwinUNet[29 ] 进行对比. 在对比模型中,前5种基于CNN架构,后3种基于Transformer架构. ...
... Comparison of segmentation results of different models in ISPRS Vaihingen dataset
Tab.1 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 78.81 85.45 65.56 74.76 24.25 86.49 65.56 DANet[6 ] 77.80 84.81 63.55 68.33 36.05 84.99 66.11 HRNet[24 ] 78.35 82.72 63.21 75.94 38.49 86.17 67.74 DeepLabV3[25 ] 79.28 86.34 66.05 77.22 30.49 86.34 67.88 Segformer[27 ] 78.88 83.18 61.04 75.39 45.22 85.94 68.74 UNet[26 ] 77.38 83.85 61.04 75.05 34.03 84.43 66.27 TransUNet[28 ] 76.68 81.05 63.46 74.08 46.53 84.80 68.36 SwinUNet[29 ] 74.16 77.85 62.01 73.46 35.62 83.50 64.62 本研究 79.98 84.88 65.27 74.44 57.69 86.51 72.45
图 7 不同模型在ISPRS Vaihingen数据集上的可视化分割结果 ...
... Comparison of segmentation results of different models in ISPRS Postdam dataset
Tab.2 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 76.31 83.23 64.65 66.03 68.78 86.04 71.80 DANet[6 ] 77.34 82.52 64.73 70.78 79.87 86.94 75.05 HRNet[24 ] 79.11 84.97 67.95 70.53 81.65 87.78 76.84 DeepLabV3[25 ] 78.90 85.23 68.68 70.91 83.17 87.73 77.38 Segformer[27 ] 79.96 86.70 69.72 65.21 77.64 87.09 75.85 UNet[26 ] 76.86 83.74 65.90 63.69 79.13 86.01 73.86 TransUNet[28 ] 79.79 86.13 68.94 66.30 78.63 86.41 75.96 SwinUNet[29 ] 73.01 76.29 61.74 54.27 68.88 80.49 66.83 本研究 86.05 92.60 74.93 73.68 84.17 90.50 82.29
3.1.3. SAMRS 数据集 SAMRS的3个子数据集中部分类别的样本数量有限,为此分别从子数据集中筛选4类特征明显、样本数量较多且具有代表性的类别用于实验. 如表3 所示为在SAMRS SOTA数据集上不同模型的对比结果. 由表可知,CETUNet在参与对比的模型中表现最佳,MIoU=88.81%,OA=94.98%,各类别的分割效果良好;在大尺度目标大车和小尺度目标小车上,CETUNet都有较好的分割精度,表明所提模型可以较好分割不同尺度的地表物体. 相比与其他对比模型,CETUNet的MIoU至少提高了2.72个百分点,OA至少提高了1.61个百分点. 如表4 所示为在SAMRS SIOR数据集上不同模型的对比结果. 由表可知,CETUNet的性能表现最佳,MIoU=97.29%,OA=98.93%;在大尺度目标(棒球场)和小尺度目标(飞机)类别上,IoU=98.65%和94.38%,进一步表明所提模型具有较好的多尺度特征提取能力. 如表5 所示为在SAMRS FAST数据集上不同模型的对比结果. 由表可知,CETUNet的MIoU=86.65%,OA=93.45%,在汽车类别上获得最佳的IoU,为63.93%,在其他类别分割结果中也都表现良好. 相比与其他对比模型,CETUNet的MIoU至少提高了1.33个百分点,OA至少提高了0.56个百分点. CETUNet在SAMRS的3个不同空间分辨率遥感图像数据集上均具有不错的性能表现,验证了所提模型的有效性. ...
... Comparison of segmentation results of different models in SAMRS SOTA dataset
Tab.3 模型 IoU/% OA/% MIoU/% 大车 游泳池 飞机 小车 FCN[23 ] 72.28 68.57 80.53 80.31 84.85 75.42 DANet[6 ] 70.54 77.65 72.14 71.24 82.14 72.89 HRNet[24 ] 77.61 79.78 83.28 83.12 85.45 75.16 DeepLabV3[25 ] 83.20 82.69 91.12 87.37 93.37 86.09 Segformer[27 ] 73.49 85.79 74.81 76.24 87.26 77.58 UNet[26 ] 75.61 74.34 80.37 83.08 87.75 78.35 TransUNet[28 ] 79.24 81.07 91.38 83.98 91.59 83.91 SwinUNet[29 ] 64.92 77.92 64.42 66.90 78.77 68.54 本研究 87.05 84.42 92.98 90.78 94.98 88.81
表 4 不同模型在SAMRS SIOR数据集上的分割结果对比 ...
... Comparison of segmentation results of different models in SAMRS SIOR dataset
Tab.4 模型 IoU/% OA/% MIoU/% 飞机 棒球场 轮船 网球场 FCN[23 ] 82.29 95.61 95.41 95.59 96.97 92.22 DANet[6 ] 78.32 96.11 96.03 96.36 94.59 91.71 HRNet[24 ] 83.01 93.62 94.74 95.67 96.47 91.76 DeepLabV3[25 ] 90.34 96.10 97.69 95.34 97.83 94.87 Segformer[27 ] 73.65 94.10 95.19 91.43 92.65 88.59 UNet[26 ] 77.38 92.03 92.34 96.62 93.47 89.59 TransUNet[28 ] 92.76 96.45 97.18 97.48 97.88 95.97 SwinUNet[29 ] 80.88 95.43 92.65 93.85 94.49 90.70 本研究 94.38 98.65 97.77 98.38 98.93 97.29
表 5 不同模型在SAMRS FAST数据集上的分割结果比较 ...
... Comparison of segmentation results of different models in SAMRS FAST dataset
Tab.5 模型 IoU/% OA/% MIoU/% 棒球场 桥梁 足球场 汽车 FCN[23 ] 80.21 94.17 90.26 63.76 90.63 82.10 DANet[6 ] 84.97 87.29 91.66 55.01 87.88 80.23 HRNet[24 ] 92.32 84.83 91.83 51.51 88.64 80.12 DeepLabV3[25 ] 93.57 95.75 96.98 54.97 92.89 85.32 Segformer[27 ] 87.95 93.87 94.48 42.71 86.77 79.75 UNet[26 ] 84.30 92.78 93.53 59.70 90.21 82.58 TransUNet[28 ] 94.46 85.84 95.66 60.33 91.83 84.07 SwinUNet[29 ] 87.83 90.05 95.29 43.72 87.49 79.22 本研究 93.79 92.91 95.98 63.93 93.45 86.65
3.2. 消融实验 为了验证所提网络的结构和2个重要模块的有效性,在ISPRS Vaihingen数据集上进行消融实验. ...
6
... 将CETUNet与主流经典模型:FCN[23 ] 、DANet[6 ] 、HRNet[24 ] 、DeepLabV3[25 ] 、UNet[26 ] 、Segformer[27 ] 、TransUNet[28 ] 和SwinUNet[29 ] 进行对比. 在对比模型中,前5种基于CNN架构,后3种基于Transformer架构. ...
... Comparison of segmentation results of different models in ISPRS Vaihingen dataset
Tab.1 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 78.81 85.45 65.56 74.76 24.25 86.49 65.56 DANet[6 ] 77.80 84.81 63.55 68.33 36.05 84.99 66.11 HRNet[24 ] 78.35 82.72 63.21 75.94 38.49 86.17 67.74 DeepLabV3[25 ] 79.28 86.34 66.05 77.22 30.49 86.34 67.88 Segformer[27 ] 78.88 83.18 61.04 75.39 45.22 85.94 68.74 UNet[26 ] 77.38 83.85 61.04 75.05 34.03 84.43 66.27 TransUNet[28 ] 76.68 81.05 63.46 74.08 46.53 84.80 68.36 SwinUNet[29 ] 74.16 77.85 62.01 73.46 35.62 83.50 64.62 本研究 79.98 84.88 65.27 74.44 57.69 86.51 72.45
图 7 不同模型在ISPRS Vaihingen数据集上的可视化分割结果 ...
... Comparison of segmentation results of different models in ISPRS Postdam dataset
Tab.2 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 76.31 83.23 64.65 66.03 68.78 86.04 71.80 DANet[6 ] 77.34 82.52 64.73 70.78 79.87 86.94 75.05 HRNet[24 ] 79.11 84.97 67.95 70.53 81.65 87.78 76.84 DeepLabV3[25 ] 78.90 85.23 68.68 70.91 83.17 87.73 77.38 Segformer[27 ] 79.96 86.70 69.72 65.21 77.64 87.09 75.85 UNet[26 ] 76.86 83.74 65.90 63.69 79.13 86.01 73.86 TransUNet[28 ] 79.79 86.13 68.94 66.30 78.63 86.41 75.96 SwinUNet[29 ] 73.01 76.29 61.74 54.27 68.88 80.49 66.83 本研究 86.05 92.60 74.93 73.68 84.17 90.50 82.29
3.1.3. SAMRS 数据集 SAMRS的3个子数据集中部分类别的样本数量有限,为此分别从子数据集中筛选4类特征明显、样本数量较多且具有代表性的类别用于实验. 如表3 所示为在SAMRS SOTA数据集上不同模型的对比结果. 由表可知,CETUNet在参与对比的模型中表现最佳,MIoU=88.81%,OA=94.98%,各类别的分割效果良好;在大尺度目标大车和小尺度目标小车上,CETUNet都有较好的分割精度,表明所提模型可以较好分割不同尺度的地表物体. 相比与其他对比模型,CETUNet的MIoU至少提高了2.72个百分点,OA至少提高了1.61个百分点. 如表4 所示为在SAMRS SIOR数据集上不同模型的对比结果. 由表可知,CETUNet的性能表现最佳,MIoU=97.29%,OA=98.93%;在大尺度目标(棒球场)和小尺度目标(飞机)类别上,IoU=98.65%和94.38%,进一步表明所提模型具有较好的多尺度特征提取能力. 如表5 所示为在SAMRS FAST数据集上不同模型的对比结果. 由表可知,CETUNet的MIoU=86.65%,OA=93.45%,在汽车类别上获得最佳的IoU,为63.93%,在其他类别分割结果中也都表现良好. 相比与其他对比模型,CETUNet的MIoU至少提高了1.33个百分点,OA至少提高了0.56个百分点. CETUNet在SAMRS的3个不同空间分辨率遥感图像数据集上均具有不错的性能表现,验证了所提模型的有效性. ...
... Comparison of segmentation results of different models in SAMRS SOTA dataset
Tab.3 模型 IoU/% OA/% MIoU/% 大车 游泳池 飞机 小车 FCN[23 ] 72.28 68.57 80.53 80.31 84.85 75.42 DANet[6 ] 70.54 77.65 72.14 71.24 82.14 72.89 HRNet[24 ] 77.61 79.78 83.28 83.12 85.45 75.16 DeepLabV3[25 ] 83.20 82.69 91.12 87.37 93.37 86.09 Segformer[27 ] 73.49 85.79 74.81 76.24 87.26 77.58 UNet[26 ] 75.61 74.34 80.37 83.08 87.75 78.35 TransUNet[28 ] 79.24 81.07 91.38 83.98 91.59 83.91 SwinUNet[29 ] 64.92 77.92 64.42 66.90 78.77 68.54 本研究 87.05 84.42 92.98 90.78 94.98 88.81
表 4 不同模型在SAMRS SIOR数据集上的分割结果对比 ...
... Comparison of segmentation results of different models in SAMRS SIOR dataset
Tab.4 模型 IoU/% OA/% MIoU/% 飞机 棒球场 轮船 网球场 FCN[23 ] 82.29 95.61 95.41 95.59 96.97 92.22 DANet[6 ] 78.32 96.11 96.03 96.36 94.59 91.71 HRNet[24 ] 83.01 93.62 94.74 95.67 96.47 91.76 DeepLabV3[25 ] 90.34 96.10 97.69 95.34 97.83 94.87 Segformer[27 ] 73.65 94.10 95.19 91.43 92.65 88.59 UNet[26 ] 77.38 92.03 92.34 96.62 93.47 89.59 TransUNet[28 ] 92.76 96.45 97.18 97.48 97.88 95.97 SwinUNet[29 ] 80.88 95.43 92.65 93.85 94.49 90.70 本研究 94.38 98.65 97.77 98.38 98.93 97.29
表 5 不同模型在SAMRS FAST数据集上的分割结果比较 ...
... Comparison of segmentation results of different models in SAMRS FAST dataset
Tab.5 模型 IoU/% OA/% MIoU/% 棒球场 桥梁 足球场 汽车 FCN[23 ] 80.21 94.17 90.26 63.76 90.63 82.10 DANet[6 ] 84.97 87.29 91.66 55.01 87.88 80.23 HRNet[24 ] 92.32 84.83 91.83 51.51 88.64 80.12 DeepLabV3[25 ] 93.57 95.75 96.98 54.97 92.89 85.32 Segformer[27 ] 87.95 93.87 94.48 42.71 86.77 79.75 UNet[26 ] 84.30 92.78 93.53 59.70 90.21 82.58 TransUNet[28 ] 94.46 85.84 95.66 60.33 91.83 84.07 SwinUNet[29 ] 87.83 90.05 95.29 43.72 87.49 79.22 本研究 93.79 92.91 95.98 63.93 93.45 86.65
3.2. 消融实验 为了验证所提网络的结构和2个重要模块的有效性,在ISPRS Vaihingen数据集上进行消融实验. ...
6
... 将CETUNet与主流经典模型:FCN[23 ] 、DANet[6 ] 、HRNet[24 ] 、DeepLabV3[25 ] 、UNet[26 ] 、Segformer[27 ] 、TransUNet[28 ] 和SwinUNet[29 ] 进行对比. 在对比模型中,前5种基于CNN架构,后3种基于Transformer架构. ...
... Comparison of segmentation results of different models in ISPRS Vaihingen dataset
Tab.1 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 78.81 85.45 65.56 74.76 24.25 86.49 65.56 DANet[6 ] 77.80 84.81 63.55 68.33 36.05 84.99 66.11 HRNet[24 ] 78.35 82.72 63.21 75.94 38.49 86.17 67.74 DeepLabV3[25 ] 79.28 86.34 66.05 77.22 30.49 86.34 67.88 Segformer[27 ] 78.88 83.18 61.04 75.39 45.22 85.94 68.74 UNet[26 ] 77.38 83.85 61.04 75.05 34.03 84.43 66.27 TransUNet[28 ] 76.68 81.05 63.46 74.08 46.53 84.80 68.36 SwinUNet[29 ] 74.16 77.85 62.01 73.46 35.62 83.50 64.62 本研究 79.98 84.88 65.27 74.44 57.69 86.51 72.45
图 7 不同模型在ISPRS Vaihingen数据集上的可视化分割结果 ...
... Comparison of segmentation results of different models in ISPRS Postdam dataset
Tab.2 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 76.31 83.23 64.65 66.03 68.78 86.04 71.80 DANet[6 ] 77.34 82.52 64.73 70.78 79.87 86.94 75.05 HRNet[24 ] 79.11 84.97 67.95 70.53 81.65 87.78 76.84 DeepLabV3[25 ] 78.90 85.23 68.68 70.91 83.17 87.73 77.38 Segformer[27 ] 79.96 86.70 69.72 65.21 77.64 87.09 75.85 UNet[26 ] 76.86 83.74 65.90 63.69 79.13 86.01 73.86 TransUNet[28 ] 79.79 86.13 68.94 66.30 78.63 86.41 75.96 SwinUNet[29 ] 73.01 76.29 61.74 54.27 68.88 80.49 66.83 本研究 86.05 92.60 74.93 73.68 84.17 90.50 82.29
3.1.3. SAMRS 数据集 SAMRS的3个子数据集中部分类别的样本数量有限,为此分别从子数据集中筛选4类特征明显、样本数量较多且具有代表性的类别用于实验. 如表3 所示为在SAMRS SOTA数据集上不同模型的对比结果. 由表可知,CETUNet在参与对比的模型中表现最佳,MIoU=88.81%,OA=94.98%,各类别的分割效果良好;在大尺度目标大车和小尺度目标小车上,CETUNet都有较好的分割精度,表明所提模型可以较好分割不同尺度的地表物体. 相比与其他对比模型,CETUNet的MIoU至少提高了2.72个百分点,OA至少提高了1.61个百分点. 如表4 所示为在SAMRS SIOR数据集上不同模型的对比结果. 由表可知,CETUNet的性能表现最佳,MIoU=97.29%,OA=98.93%;在大尺度目标(棒球场)和小尺度目标(飞机)类别上,IoU=98.65%和94.38%,进一步表明所提模型具有较好的多尺度特征提取能力. 如表5 所示为在SAMRS FAST数据集上不同模型的对比结果. 由表可知,CETUNet的MIoU=86.65%,OA=93.45%,在汽车类别上获得最佳的IoU,为63.93%,在其他类别分割结果中也都表现良好. 相比与其他对比模型,CETUNet的MIoU至少提高了1.33个百分点,OA至少提高了0.56个百分点. CETUNet在SAMRS的3个不同空间分辨率遥感图像数据集上均具有不错的性能表现,验证了所提模型的有效性. ...
... Comparison of segmentation results of different models in SAMRS SOTA dataset
Tab.3 模型 IoU/% OA/% MIoU/% 大车 游泳池 飞机 小车 FCN[23 ] 72.28 68.57 80.53 80.31 84.85 75.42 DANet[6 ] 70.54 77.65 72.14 71.24 82.14 72.89 HRNet[24 ] 77.61 79.78 83.28 83.12 85.45 75.16 DeepLabV3[25 ] 83.20 82.69 91.12 87.37 93.37 86.09 Segformer[27 ] 73.49 85.79 74.81 76.24 87.26 77.58 UNet[26 ] 75.61 74.34 80.37 83.08 87.75 78.35 TransUNet[28 ] 79.24 81.07 91.38 83.98 91.59 83.91 SwinUNet[29 ] 64.92 77.92 64.42 66.90 78.77 68.54 本研究 87.05 84.42 92.98 90.78 94.98 88.81
表 4 不同模型在SAMRS SIOR数据集上的分割结果对比 ...
... Comparison of segmentation results of different models in SAMRS SIOR dataset
Tab.4 模型 IoU/% OA/% MIoU/% 飞机 棒球场 轮船 网球场 FCN[23 ] 82.29 95.61 95.41 95.59 96.97 92.22 DANet[6 ] 78.32 96.11 96.03 96.36 94.59 91.71 HRNet[24 ] 83.01 93.62 94.74 95.67 96.47 91.76 DeepLabV3[25 ] 90.34 96.10 97.69 95.34 97.83 94.87 Segformer[27 ] 73.65 94.10 95.19 91.43 92.65 88.59 UNet[26 ] 77.38 92.03 92.34 96.62 93.47 89.59 TransUNet[28 ] 92.76 96.45 97.18 97.48 97.88 95.97 SwinUNet[29 ] 80.88 95.43 92.65 93.85 94.49 90.70 本研究 94.38 98.65 97.77 98.38 98.93 97.29
表 5 不同模型在SAMRS FAST数据集上的分割结果比较 ...
... Comparison of segmentation results of different models in SAMRS FAST dataset
Tab.5 模型 IoU/% OA/% MIoU/% 棒球场 桥梁 足球场 汽车 FCN[23 ] 80.21 94.17 90.26 63.76 90.63 82.10 DANet[6 ] 84.97 87.29 91.66 55.01 87.88 80.23 HRNet[24 ] 92.32 84.83 91.83 51.51 88.64 80.12 DeepLabV3[25 ] 93.57 95.75 96.98 54.97 92.89 85.32 Segformer[27 ] 87.95 93.87 94.48 42.71 86.77 79.75 UNet[26 ] 84.30 92.78 93.53 59.70 90.21 82.58 TransUNet[28 ] 94.46 85.84 95.66 60.33 91.83 84.07 SwinUNet[29 ] 87.83 90.05 95.29 43.72 87.49 79.22 本研究 93.79 92.91 95.98 63.93 93.45 86.65
3.2. 消融实验 为了验证所提网络的结构和2个重要模块的有效性,在ISPRS Vaihingen数据集上进行消融实验. ...
6
... 将CETUNet与主流经典模型:FCN[23 ] 、DANet[6 ] 、HRNet[24 ] 、DeepLabV3[25 ] 、UNet[26 ] 、Segformer[27 ] 、TransUNet[28 ] 和SwinUNet[29 ] 进行对比. 在对比模型中,前5种基于CNN架构,后3种基于Transformer架构. ...
... Comparison of segmentation results of different models in ISPRS Vaihingen dataset
Tab.1 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 78.81 85.45 65.56 74.76 24.25 86.49 65.56 DANet[6 ] 77.80 84.81 63.55 68.33 36.05 84.99 66.11 HRNet[24 ] 78.35 82.72 63.21 75.94 38.49 86.17 67.74 DeepLabV3[25 ] 79.28 86.34 66.05 77.22 30.49 86.34 67.88 Segformer[27 ] 78.88 83.18 61.04 75.39 45.22 85.94 68.74 UNet[26 ] 77.38 83.85 61.04 75.05 34.03 84.43 66.27 TransUNet[28 ] 76.68 81.05 63.46 74.08 46.53 84.80 68.36 SwinUNet[29 ] 74.16 77.85 62.01 73.46 35.62 83.50 64.62 本研究 79.98 84.88 65.27 74.44 57.69 86.51 72.45
图 7 不同模型在ISPRS Vaihingen数据集上的可视化分割结果 ...
... Comparison of segmentation results of different models in ISPRS Postdam dataset
Tab.2 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 76.31 83.23 64.65 66.03 68.78 86.04 71.80 DANet[6 ] 77.34 82.52 64.73 70.78 79.87 86.94 75.05 HRNet[24 ] 79.11 84.97 67.95 70.53 81.65 87.78 76.84 DeepLabV3[25 ] 78.90 85.23 68.68 70.91 83.17 87.73 77.38 Segformer[27 ] 79.96 86.70 69.72 65.21 77.64 87.09 75.85 UNet[26 ] 76.86 83.74 65.90 63.69 79.13 86.01 73.86 TransUNet[28 ] 79.79 86.13 68.94 66.30 78.63 86.41 75.96 SwinUNet[29 ] 73.01 76.29 61.74 54.27 68.88 80.49 66.83 本研究 86.05 92.60 74.93 73.68 84.17 90.50 82.29
3.1.3. SAMRS 数据集 SAMRS的3个子数据集中部分类别的样本数量有限,为此分别从子数据集中筛选4类特征明显、样本数量较多且具有代表性的类别用于实验. 如表3 所示为在SAMRS SOTA数据集上不同模型的对比结果. 由表可知,CETUNet在参与对比的模型中表现最佳,MIoU=88.81%,OA=94.98%,各类别的分割效果良好;在大尺度目标大车和小尺度目标小车上,CETUNet都有较好的分割精度,表明所提模型可以较好分割不同尺度的地表物体. 相比与其他对比模型,CETUNet的MIoU至少提高了2.72个百分点,OA至少提高了1.61个百分点. 如表4 所示为在SAMRS SIOR数据集上不同模型的对比结果. 由表可知,CETUNet的性能表现最佳,MIoU=97.29%,OA=98.93%;在大尺度目标(棒球场)和小尺度目标(飞机)类别上,IoU=98.65%和94.38%,进一步表明所提模型具有较好的多尺度特征提取能力. 如表5 所示为在SAMRS FAST数据集上不同模型的对比结果. 由表可知,CETUNet的MIoU=86.65%,OA=93.45%,在汽车类别上获得最佳的IoU,为63.93%,在其他类别分割结果中也都表现良好. 相比与其他对比模型,CETUNet的MIoU至少提高了1.33个百分点,OA至少提高了0.56个百分点. CETUNet在SAMRS的3个不同空间分辨率遥感图像数据集上均具有不错的性能表现,验证了所提模型的有效性. ...
... Comparison of segmentation results of different models in SAMRS SOTA dataset
Tab.3 模型 IoU/% OA/% MIoU/% 大车 游泳池 飞机 小车 FCN[23 ] 72.28 68.57 80.53 80.31 84.85 75.42 DANet[6 ] 70.54 77.65 72.14 71.24 82.14 72.89 HRNet[24 ] 77.61 79.78 83.28 83.12 85.45 75.16 DeepLabV3[25 ] 83.20 82.69 91.12 87.37 93.37 86.09 Segformer[27 ] 73.49 85.79 74.81 76.24 87.26 77.58 UNet[26 ] 75.61 74.34 80.37 83.08 87.75 78.35 TransUNet[28 ] 79.24 81.07 91.38 83.98 91.59 83.91 SwinUNet[29 ] 64.92 77.92 64.42 66.90 78.77 68.54 本研究 87.05 84.42 92.98 90.78 94.98 88.81
表 4 不同模型在SAMRS SIOR数据集上的分割结果对比 ...
... Comparison of segmentation results of different models in SAMRS SIOR dataset
Tab.4 模型 IoU/% OA/% MIoU/% 飞机 棒球场 轮船 网球场 FCN[23 ] 82.29 95.61 95.41 95.59 96.97 92.22 DANet[6 ] 78.32 96.11 96.03 96.36 94.59 91.71 HRNet[24 ] 83.01 93.62 94.74 95.67 96.47 91.76 DeepLabV3[25 ] 90.34 96.10 97.69 95.34 97.83 94.87 Segformer[27 ] 73.65 94.10 95.19 91.43 92.65 88.59 UNet[26 ] 77.38 92.03 92.34 96.62 93.47 89.59 TransUNet[28 ] 92.76 96.45 97.18 97.48 97.88 95.97 SwinUNet[29 ] 80.88 95.43 92.65 93.85 94.49 90.70 本研究 94.38 98.65 97.77 98.38 98.93 97.29
表 5 不同模型在SAMRS FAST数据集上的分割结果比较 ...
... Comparison of segmentation results of different models in SAMRS FAST dataset
Tab.5 模型 IoU/% OA/% MIoU/% 棒球场 桥梁 足球场 汽车 FCN[23 ] 80.21 94.17 90.26 63.76 90.63 82.10 DANet[6 ] 84.97 87.29 91.66 55.01 87.88 80.23 HRNet[24 ] 92.32 84.83 91.83 51.51 88.64 80.12 DeepLabV3[25 ] 93.57 95.75 96.98 54.97 92.89 85.32 Segformer[27 ] 87.95 93.87 94.48 42.71 86.77 79.75 UNet[26 ] 84.30 92.78 93.53 59.70 90.21 82.58 TransUNet[28 ] 94.46 85.84 95.66 60.33 91.83 84.07 SwinUNet[29 ] 87.83 90.05 95.29 43.72 87.49 79.22 本研究 93.79 92.91 95.98 63.93 93.45 86.65
3.2. 消融实验 为了验证所提网络的结构和2个重要模块的有效性,在ISPRS Vaihingen数据集上进行消融实验. ...
6
... 将CETUNet与主流经典模型:FCN[23 ] 、DANet[6 ] 、HRNet[24 ] 、DeepLabV3[25 ] 、UNet[26 ] 、Segformer[27 ] 、TransUNet[28 ] 和SwinUNet[29 ] 进行对比. 在对比模型中,前5种基于CNN架构,后3种基于Transformer架构. ...
... Comparison of segmentation results of different models in ISPRS Vaihingen dataset
Tab.1 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 78.81 85.45 65.56 74.76 24.25 86.49 65.56 DANet[6 ] 77.80 84.81 63.55 68.33 36.05 84.99 66.11 HRNet[24 ] 78.35 82.72 63.21 75.94 38.49 86.17 67.74 DeepLabV3[25 ] 79.28 86.34 66.05 77.22 30.49 86.34 67.88 Segformer[27 ] 78.88 83.18 61.04 75.39 45.22 85.94 68.74 UNet[26 ] 77.38 83.85 61.04 75.05 34.03 84.43 66.27 TransUNet[28 ] 76.68 81.05 63.46 74.08 46.53 84.80 68.36 SwinUNet[29 ] 74.16 77.85 62.01 73.46 35.62 83.50 64.62 本研究 79.98 84.88 65.27 74.44 57.69 86.51 72.45
图 7 不同模型在ISPRS Vaihingen数据集上的可视化分割结果 ...
... Comparison of segmentation results of different models in ISPRS Postdam dataset
Tab.2 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 76.31 83.23 64.65 66.03 68.78 86.04 71.80 DANet[6 ] 77.34 82.52 64.73 70.78 79.87 86.94 75.05 HRNet[24 ] 79.11 84.97 67.95 70.53 81.65 87.78 76.84 DeepLabV3[25 ] 78.90 85.23 68.68 70.91 83.17 87.73 77.38 Segformer[27 ] 79.96 86.70 69.72 65.21 77.64 87.09 75.85 UNet[26 ] 76.86 83.74 65.90 63.69 79.13 86.01 73.86 TransUNet[28 ] 79.79 86.13 68.94 66.30 78.63 86.41 75.96 SwinUNet[29 ] 73.01 76.29 61.74 54.27 68.88 80.49 66.83 本研究 86.05 92.60 74.93 73.68 84.17 90.50 82.29
3.1.3. SAMRS 数据集 SAMRS的3个子数据集中部分类别的样本数量有限,为此分别从子数据集中筛选4类特征明显、样本数量较多且具有代表性的类别用于实验. 如表3 所示为在SAMRS SOTA数据集上不同模型的对比结果. 由表可知,CETUNet在参与对比的模型中表现最佳,MIoU=88.81%,OA=94.98%,各类别的分割效果良好;在大尺度目标大车和小尺度目标小车上,CETUNet都有较好的分割精度,表明所提模型可以较好分割不同尺度的地表物体. 相比与其他对比模型,CETUNet的MIoU至少提高了2.72个百分点,OA至少提高了1.61个百分点. 如表4 所示为在SAMRS SIOR数据集上不同模型的对比结果. 由表可知,CETUNet的性能表现最佳,MIoU=97.29%,OA=98.93%;在大尺度目标(棒球场)和小尺度目标(飞机)类别上,IoU=98.65%和94.38%,进一步表明所提模型具有较好的多尺度特征提取能力. 如表5 所示为在SAMRS FAST数据集上不同模型的对比结果. 由表可知,CETUNet的MIoU=86.65%,OA=93.45%,在汽车类别上获得最佳的IoU,为63.93%,在其他类别分割结果中也都表现良好. 相比与其他对比模型,CETUNet的MIoU至少提高了1.33个百分点,OA至少提高了0.56个百分点. CETUNet在SAMRS的3个不同空间分辨率遥感图像数据集上均具有不错的性能表现,验证了所提模型的有效性. ...
... Comparison of segmentation results of different models in SAMRS SOTA dataset
Tab.3 模型 IoU/% OA/% MIoU/% 大车 游泳池 飞机 小车 FCN[23 ] 72.28 68.57 80.53 80.31 84.85 75.42 DANet[6 ] 70.54 77.65 72.14 71.24 82.14 72.89 HRNet[24 ] 77.61 79.78 83.28 83.12 85.45 75.16 DeepLabV3[25 ] 83.20 82.69 91.12 87.37 93.37 86.09 Segformer[27 ] 73.49 85.79 74.81 76.24 87.26 77.58 UNet[26 ] 75.61 74.34 80.37 83.08 87.75 78.35 TransUNet[28 ] 79.24 81.07 91.38 83.98 91.59 83.91 SwinUNet[29 ] 64.92 77.92 64.42 66.90 78.77 68.54 本研究 87.05 84.42 92.98 90.78 94.98 88.81
表 4 不同模型在SAMRS SIOR数据集上的分割结果对比 ...
... Comparison of segmentation results of different models in SAMRS SIOR dataset
Tab.4 模型 IoU/% OA/% MIoU/% 飞机 棒球场 轮船 网球场 FCN[23 ] 82.29 95.61 95.41 95.59 96.97 92.22 DANet[6 ] 78.32 96.11 96.03 96.36 94.59 91.71 HRNet[24 ] 83.01 93.62 94.74 95.67 96.47 91.76 DeepLabV3[25 ] 90.34 96.10 97.69 95.34 97.83 94.87 Segformer[27 ] 73.65 94.10 95.19 91.43 92.65 88.59 UNet[26 ] 77.38 92.03 92.34 96.62 93.47 89.59 TransUNet[28 ] 92.76 96.45 97.18 97.48 97.88 95.97 SwinUNet[29 ] 80.88 95.43 92.65 93.85 94.49 90.70 本研究 94.38 98.65 97.77 98.38 98.93 97.29
表 5 不同模型在SAMRS FAST数据集上的分割结果比较 ...
... Comparison of segmentation results of different models in SAMRS FAST dataset
Tab.5 模型 IoU/% OA/% MIoU/% 棒球场 桥梁 足球场 汽车 FCN[23 ] 80.21 94.17 90.26 63.76 90.63 82.10 DANet[6 ] 84.97 87.29 91.66 55.01 87.88 80.23 HRNet[24 ] 92.32 84.83 91.83 51.51 88.64 80.12 DeepLabV3[25 ] 93.57 95.75 96.98 54.97 92.89 85.32 Segformer[27 ] 87.95 93.87 94.48 42.71 86.77 79.75 UNet[26 ] 84.30 92.78 93.53 59.70 90.21 82.58 TransUNet[28 ] 94.46 85.84 95.66 60.33 91.83 84.07 SwinUNet[29 ] 87.83 90.05 95.29 43.72 87.49 79.22 本研究 93.79 92.91 95.98 63.93 93.45 86.65
3.2. 消融实验 为了验证所提网络的结构和2个重要模块的有效性,在ISPRS Vaihingen数据集上进行消融实验. ...
6
... 将CETUNet与主流经典模型:FCN[23 ] 、DANet[6 ] 、HRNet[24 ] 、DeepLabV3[25 ] 、UNet[26 ] 、Segformer[27 ] 、TransUNet[28 ] 和SwinUNet[29 ] 进行对比. 在对比模型中,前5种基于CNN架构,后3种基于Transformer架构. ...
... Comparison of segmentation results of different models in ISPRS Vaihingen dataset
Tab.1 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 78.81 85.45 65.56 74.76 24.25 86.49 65.56 DANet[6 ] 77.80 84.81 63.55 68.33 36.05 84.99 66.11 HRNet[24 ] 78.35 82.72 63.21 75.94 38.49 86.17 67.74 DeepLabV3[25 ] 79.28 86.34 66.05 77.22 30.49 86.34 67.88 Segformer[27 ] 78.88 83.18 61.04 75.39 45.22 85.94 68.74 UNet[26 ] 77.38 83.85 61.04 75.05 34.03 84.43 66.27 TransUNet[28 ] 76.68 81.05 63.46 74.08 46.53 84.80 68.36 SwinUNet[29 ] 74.16 77.85 62.01 73.46 35.62 83.50 64.62 本研究 79.98 84.88 65.27 74.44 57.69 86.51 72.45
图 7 不同模型在ISPRS Vaihingen数据集上的可视化分割结果 ...
... Comparison of segmentation results of different models in ISPRS Postdam dataset
Tab.2 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 76.31 83.23 64.65 66.03 68.78 86.04 71.80 DANet[6 ] 77.34 82.52 64.73 70.78 79.87 86.94 75.05 HRNet[24 ] 79.11 84.97 67.95 70.53 81.65 87.78 76.84 DeepLabV3[25 ] 78.90 85.23 68.68 70.91 83.17 87.73 77.38 Segformer[27 ] 79.96 86.70 69.72 65.21 77.64 87.09 75.85 UNet[26 ] 76.86 83.74 65.90 63.69 79.13 86.01 73.86 TransUNet[28 ] 79.79 86.13 68.94 66.30 78.63 86.41 75.96 SwinUNet[29 ] 73.01 76.29 61.74 54.27 68.88 80.49 66.83 本研究 86.05 92.60 74.93 73.68 84.17 90.50 82.29
3.1.3. SAMRS 数据集 SAMRS的3个子数据集中部分类别的样本数量有限,为此分别从子数据集中筛选4类特征明显、样本数量较多且具有代表性的类别用于实验. 如表3 所示为在SAMRS SOTA数据集上不同模型的对比结果. 由表可知,CETUNet在参与对比的模型中表现最佳,MIoU=88.81%,OA=94.98%,各类别的分割效果良好;在大尺度目标大车和小尺度目标小车上,CETUNet都有较好的分割精度,表明所提模型可以较好分割不同尺度的地表物体. 相比与其他对比模型,CETUNet的MIoU至少提高了2.72个百分点,OA至少提高了1.61个百分点. 如表4 所示为在SAMRS SIOR数据集上不同模型的对比结果. 由表可知,CETUNet的性能表现最佳,MIoU=97.29%,OA=98.93%;在大尺度目标(棒球场)和小尺度目标(飞机)类别上,IoU=98.65%和94.38%,进一步表明所提模型具有较好的多尺度特征提取能力. 如表5 所示为在SAMRS FAST数据集上不同模型的对比结果. 由表可知,CETUNet的MIoU=86.65%,OA=93.45%,在汽车类别上获得最佳的IoU,为63.93%,在其他类别分割结果中也都表现良好. 相比与其他对比模型,CETUNet的MIoU至少提高了1.33个百分点,OA至少提高了0.56个百分点. CETUNet在SAMRS的3个不同空间分辨率遥感图像数据集上均具有不错的性能表现,验证了所提模型的有效性. ...
... Comparison of segmentation results of different models in SAMRS SOTA dataset
Tab.3 模型 IoU/% OA/% MIoU/% 大车 游泳池 飞机 小车 FCN[23 ] 72.28 68.57 80.53 80.31 84.85 75.42 DANet[6 ] 70.54 77.65 72.14 71.24 82.14 72.89 HRNet[24 ] 77.61 79.78 83.28 83.12 85.45 75.16 DeepLabV3[25 ] 83.20 82.69 91.12 87.37 93.37 86.09 Segformer[27 ] 73.49 85.79 74.81 76.24 87.26 77.58 UNet[26 ] 75.61 74.34 80.37 83.08 87.75 78.35 TransUNet[28 ] 79.24 81.07 91.38 83.98 91.59 83.91 SwinUNet[29 ] 64.92 77.92 64.42 66.90 78.77 68.54 本研究 87.05 84.42 92.98 90.78 94.98 88.81
表 4 不同模型在SAMRS SIOR数据集上的分割结果对比 ...
... Comparison of segmentation results of different models in SAMRS SIOR dataset
Tab.4 模型 IoU/% OA/% MIoU/% 飞机 棒球场 轮船 网球场 FCN[23 ] 82.29 95.61 95.41 95.59 96.97 92.22 DANet[6 ] 78.32 96.11 96.03 96.36 94.59 91.71 HRNet[24 ] 83.01 93.62 94.74 95.67 96.47 91.76 DeepLabV3[25 ] 90.34 96.10 97.69 95.34 97.83 94.87 Segformer[27 ] 73.65 94.10 95.19 91.43 92.65 88.59 UNet[26 ] 77.38 92.03 92.34 96.62 93.47 89.59 TransUNet[28 ] 92.76 96.45 97.18 97.48 97.88 95.97 SwinUNet[29 ] 80.88 95.43 92.65 93.85 94.49 90.70 本研究 94.38 98.65 97.77 98.38 98.93 97.29
表 5 不同模型在SAMRS FAST数据集上的分割结果比较 ...
... Comparison of segmentation results of different models in SAMRS FAST dataset
Tab.5 模型 IoU/% OA/% MIoU/% 棒球场 桥梁 足球场 汽车 FCN[23 ] 80.21 94.17 90.26 63.76 90.63 82.10 DANet[6 ] 84.97 87.29 91.66 55.01 87.88 80.23 HRNet[24 ] 92.32 84.83 91.83 51.51 88.64 80.12 DeepLabV3[25 ] 93.57 95.75 96.98 54.97 92.89 85.32 Segformer[27 ] 87.95 93.87 94.48 42.71 86.77 79.75 UNet[26 ] 84.30 92.78 93.53 59.70 90.21 82.58 TransUNet[28 ] 94.46 85.84 95.66 60.33 91.83 84.07 SwinUNet[29 ] 87.83 90.05 95.29 43.72 87.49 79.22 本研究 93.79 92.91 95.98 63.93 93.45 86.65
3.2. 消融实验 为了验证所提网络的结构和2个重要模块的有效性,在ISPRS Vaihingen数据集上进行消融实验. ...
6
... 将CETUNet与主流经典模型:FCN[23 ] 、DANet[6 ] 、HRNet[24 ] 、DeepLabV3[25 ] 、UNet[26 ] 、Segformer[27 ] 、TransUNet[28 ] 和SwinUNet[29 ] 进行对比. 在对比模型中,前5种基于CNN架构,后3种基于Transformer架构. ...
... Comparison of segmentation results of different models in ISPRS Vaihingen dataset
Tab.1 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 78.81 85.45 65.56 74.76 24.25 86.49 65.56 DANet[6 ] 77.80 84.81 63.55 68.33 36.05 84.99 66.11 HRNet[24 ] 78.35 82.72 63.21 75.94 38.49 86.17 67.74 DeepLabV3[25 ] 79.28 86.34 66.05 77.22 30.49 86.34 67.88 Segformer[27 ] 78.88 83.18 61.04 75.39 45.22 85.94 68.74 UNet[26 ] 77.38 83.85 61.04 75.05 34.03 84.43 66.27 TransUNet[28 ] 76.68 81.05 63.46 74.08 46.53 84.80 68.36 SwinUNet[29 ] 74.16 77.85 62.01 73.46 35.62 83.50 64.62 本研究 79.98 84.88 65.27 74.44 57.69 86.51 72.45
图 7 不同模型在ISPRS Vaihingen数据集上的可视化分割结果 ...
... Comparison of segmentation results of different models in ISPRS Postdam dataset
Tab.2 模型 IoU/% OA/% MIoU/% 不透明表面 建筑物 低矮植被 树木 汽车 FCN[23 ] 76.31 83.23 64.65 66.03 68.78 86.04 71.80 DANet[6 ] 77.34 82.52 64.73 70.78 79.87 86.94 75.05 HRNet[24 ] 79.11 84.97 67.95 70.53 81.65 87.78 76.84 DeepLabV3[25 ] 78.90 85.23 68.68 70.91 83.17 87.73 77.38 Segformer[27 ] 79.96 86.70 69.72 65.21 77.64 87.09 75.85 UNet[26 ] 76.86 83.74 65.90 63.69 79.13 86.01 73.86 TransUNet[28 ] 79.79 86.13 68.94 66.30 78.63 86.41 75.96 SwinUNet[29 ] 73.01 76.29 61.74 54.27 68.88 80.49 66.83 本研究 86.05 92.60 74.93 73.68 84.17 90.50 82.29
3.1.3. SAMRS 数据集 SAMRS的3个子数据集中部分类别的样本数量有限,为此分别从子数据集中筛选4类特征明显、样本数量较多且具有代表性的类别用于实验. 如表3 所示为在SAMRS SOTA数据集上不同模型的对比结果. 由表可知,CETUNet在参与对比的模型中表现最佳,MIoU=88.81%,OA=94.98%,各类别的分割效果良好;在大尺度目标大车和小尺度目标小车上,CETUNet都有较好的分割精度,表明所提模型可以较好分割不同尺度的地表物体. 相比与其他对比模型,CETUNet的MIoU至少提高了2.72个百分点,OA至少提高了1.61个百分点. 如表4 所示为在SAMRS SIOR数据集上不同模型的对比结果. 由表可知,CETUNet的性能表现最佳,MIoU=97.29%,OA=98.93%;在大尺度目标(棒球场)和小尺度目标(飞机)类别上,IoU=98.65%和94.38%,进一步表明所提模型具有较好的多尺度特征提取能力. 如表5 所示为在SAMRS FAST数据集上不同模型的对比结果. 由表可知,CETUNet的MIoU=86.65%,OA=93.45%,在汽车类别上获得最佳的IoU,为63.93%,在其他类别分割结果中也都表现良好. 相比与其他对比模型,CETUNet的MIoU至少提高了1.33个百分点,OA至少提高了0.56个百分点. CETUNet在SAMRS的3个不同空间分辨率遥感图像数据集上均具有不错的性能表现,验证了所提模型的有效性. ...
... Comparison of segmentation results of different models in SAMRS SOTA dataset
Tab.3 模型 IoU/% OA/% MIoU/% 大车 游泳池 飞机 小车 FCN[23 ] 72.28 68.57 80.53 80.31 84.85 75.42 DANet[6 ] 70.54 77.65 72.14 71.24 82.14 72.89 HRNet[24 ] 77.61 79.78 83.28 83.12 85.45 75.16 DeepLabV3[25 ] 83.20 82.69 91.12 87.37 93.37 86.09 Segformer[27 ] 73.49 85.79 74.81 76.24 87.26 77.58 UNet[26 ] 75.61 74.34 80.37 83.08 87.75 78.35 TransUNet[28 ] 79.24 81.07 91.38 83.98 91.59 83.91 SwinUNet[29 ] 64.92 77.92 64.42 66.90 78.77 68.54 本研究 87.05 84.42 92.98 90.78 94.98 88.81
表 4 不同模型在SAMRS SIOR数据集上的分割结果对比 ...
... Comparison of segmentation results of different models in SAMRS SIOR dataset
Tab.4 模型 IoU/% OA/% MIoU/% 飞机 棒球场 轮船 网球场 FCN[23 ] 82.29 95.61 95.41 95.59 96.97 92.22 DANet[6 ] 78.32 96.11 96.03 96.36 94.59 91.71 HRNet[24 ] 83.01 93.62 94.74 95.67 96.47 91.76 DeepLabV3[25 ] 90.34 96.10 97.69 95.34 97.83 94.87 Segformer[27 ] 73.65 94.10 95.19 91.43 92.65 88.59 UNet[26 ] 77.38 92.03 92.34 96.62 93.47 89.59 TransUNet[28 ] 92.76 96.45 97.18 97.48 97.88 95.97 SwinUNet[29 ] 80.88 95.43 92.65 93.85 94.49 90.70 本研究 94.38 98.65 97.77 98.38 98.93 97.29
表 5 不同模型在SAMRS FAST数据集上的分割结果比较 ...
... Comparison of segmentation results of different models in SAMRS FAST dataset
Tab.5 模型 IoU/% OA/% MIoU/% 棒球场 桥梁 足球场 汽车 FCN[23 ] 80.21 94.17 90.26 63.76 90.63 82.10 DANet[6 ] 84.97 87.29 91.66 55.01 87.88 80.23 HRNet[24 ] 92.32 84.83 91.83 51.51 88.64 80.12 DeepLabV3[25 ] 93.57 95.75 96.98 54.97 92.89 85.32 Segformer[27 ] 87.95 93.87 94.48 42.71 86.77 79.75 UNet[26 ] 84.30 92.78 93.53 59.70 90.21 82.58 TransUNet[28 ] 94.46 85.84 95.66 60.33 91.83 84.07 SwinUNet[29 ] 87.83 90.05 95.29 43.72 87.49 79.22 本研究 93.79 92.91 95.98 63.93 93.45 86.65
3.2. 消融实验 为了验证所提网络的结构和2个重要模块的有效性,在ISPRS Vaihingen数据集上进行消融实验. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}