[1]
LIU Y X, YUAN Y X, LIU M Ground-aware monocular 3D object detection for autonomous driving
[J]. IEEE Robotics and Automation Letters , 2021 , 6 (2 ): 919 - 926
DOI:10.1109/LRA.2021.3052442
[本文引用: 1]
[2]
SIMONELLI A, BULÒ S R, PORZI L, et al. Disentangling monocular 3D object detection [C]// IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 1991–1999.
[本文引用: 1]
[3]
WANG Y, CHAO W L, GARG D, et al. Pseudo-LiDAR from visual depth estimation: bridging the gap in 3D object detection for autonomous driving [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 8445–8453.
[本文引用: 1]
[4]
MA X Z, LIU S N, XIA Z Y, et al. Rethinking pseudo-LiDAR representation [C]// European Conference on Computer Vision . Glasgow: Springer, 2020: 311–327.
[本文引用: 1]
[5]
PENG L, LIU F, YU Z X, et al. LiDAR point cloud guided monocular 3D object detection [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 123–139.
[本文引用: 1]
[6]
HONG Y, DAI H, DING Y. Cross-modality knowledge distillation network for monocular 3D object detection [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 87–104.
[本文引用: 1]
[7]
LIU Z D, ZHOU D F, LU F X, et al. AutoShape: real-time shape-aware monocular 3D object detection [C]/ / IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 15641–15650.
[本文引用: 2]
[8]
张峻宁, 苏群星, 刘鹏远, 等 基于空间约束的自适应单目3D物体检测算法
[J]. 浙江大学学报: 工学版 , 2020 , 54 (6 ): 1138 - 1146
[本文引用: 1]
ZHANG Junning, SU Qunxing, LIU Pengyuan, et al Adaptive monocular 3D object detection algorithm based on spatial constraint
[J]. Journal of Zhejiang University: Engineering Science , 2020 , 54 (6 ): 1138 - 1146
[本文引用: 1]
[9]
LI Y Y, CHEN Y T, HE J W, et al. Densely constrained depth estimator for monocular 3D object detection [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 718–734.
[本文引用: 2]
[10]
LU Y, MA X Z, YANG L, et al. Geometry uncertainty projection network for monocular 3D object detection [C]// IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 3111–3121.
[本文引用: 3]
[11]
LIU Z C, WU Z Z, TÓTH R. SMOKE: single-stage monocular 3D object detection via keypoint estimation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops . Seattle: IEEE, 2020: 996–997.
[本文引用: 1]
[12]
BRAZIL G, LIU X M. M3D-RPN: monocular 3D region proposal network for object detection [C]// IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9287–9296.
[本文引用: 1]
[13]
ZHANG R R, QIU H, WANG T, et al. MonoDETR: depth-guided transformer for monocular 3D object detection [C]// IEEE/CVF International Conference on Computer Vision . Paris: IEEE, 2023: 9155–9166.
[本文引用: 1]
[14]
HUANG K C, WU T H, SU H T, et al. MonoDTR: monocular 3D object detection with depth-aware transformer [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 4012–4021.
[本文引用: 2]
[15]
YU F, WANG D Q, SHELHAMER E, et al. Deep layer aggregation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 2403–2412.
[本文引用: 1]
[16]
ZHOU X Y, WANG D Q, KRÄHENBÜHL P. Objects as points [EB/OL]. (2019–04–25)[2023–11–29]. https://arxiv.org/pdf/1904.07850.
[本文引用: 1]
[17]
PENG L, WU X P, YANG Z, et al. DID-M3D: decoupling instance depth for monocular 3D object detection [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 71–88.
[本文引用: 2]
[18]
GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite [C]// IEEE Conference on Computer Vision and Pattern Recognition . Providence: IEEE, 2012: 3354–3361.
[本文引用: 1]
[19]
MOUSAVIAN A, ANGUELOV D, FLYNN J, et al. 3D bounding box estimation using deep learning and geometry [C]// IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 7074–7082.
[本文引用: 1]
[20]
SUN P, KRETZSCHMAR H, DOTIWALLA X, et al. Scalability in perception for autonomous driving: Waymo open dataset [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 2446–2454.
[本文引用: 1]
[21]
READING C, HARAKEH A, CHAE J, et al. Categorical depth distribution network for monocular 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 8555–8564.
[本文引用: 2]
[22]
MA X Z, ZHANG Y M, XU D, et al. Delving into localization errors for monocular 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 4721–4730.
[本文引用: 1]
[23]
KUMAR A, BRAZIL G, LIU X M. GrooMeD-NMS: grouped mathematically differentiable NMS for monocular 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 8973–8983.
[本文引用: 1]
[24]
ZHOU Y S, HE Y, ZHU H Z, et al. Monocular 3D object detection: an extrinsic parameter free approach [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 7556–7566.
[本文引用: 1]
[25]
ZHANG Y P, LU J W, ZHOU J. Objects are different: flexible monocular 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 3289–3298.
[本文引用: 1]
[26]
WANG L, ZHANG L, ZHU Y, et al. Progressive coordinate transforms for monocular 3D object detection [C]// The 35th International Conference on Neural Information Processing Systems . [S. l.]: Curran Associates, 2021: 13364–13377.
[本文引用: 1]
[27]
QIN Z Q, LI X. MonoGround: detecting monocular 3D objects from the ground [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 3793–3802.
[本文引用: 1]
[28]
GU J Q, WU B J, FAN L B, et al. Homography loss for monocular 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 1080–1089.
[本文引用: 1]
[29]
LIAN Q, LI P L, CHEN X Z. MonoJSG: joint semantic and geometric cost volume for monocular 3D object detection [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 1070–1079.
[本文引用: 1]
[30]
KUMAR A, BRAZIL G, CORONA E, et al. DEVIANT: depth equivariant network for monocular 3D object detection [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 664–683.
[本文引用: 1]
[31]
ZHOU Z Y, DU L, YE X Q, et al SGM3D: stereo guided monocular 3D object detection
[J]. IEEE Robotics and Automation Letters , 2022 , 7 (4 ): 10478 - 10485
DOI:10.1109/LRA.2022.3191849
[本文引用: 1]
[32]
LIU X P, XUE N, WU T F. Learning auxiliary monocular contexts helps monocular 3D object detection [C]// AAAI Conference on Artificial Intelligence . Vancouver: AAAI, 2022: 1810–1818.
[本文引用: 1]
[33]
SHI X P, CHEN Z X, KIM T K. Multivariate probabilistic monocular 3D object detection [C]// IEEE/CVF Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2023: 4281–4290.
[本文引用: 1]
[34]
ZHU M H, GE L T, WANG P Q, et al. MonoEdge: monocular 3D object detection using local perspectives [C]// IEEE/CVF Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2023: 643–652.
[本文引用: 1]
Ground-aware monocular 3D object detection for autonomous driving
1
2021
... Liu等[1 -2 ] 探索了从单目图像检测3D目标的固有不适定性问题,指出准确地预测深度信息是提高单目3D目标检测性能的关键. Pseudo-LiDAR[3 ] 、PatchNet[4 ] 直接借助专门的深度预测模型来预测每个像素的深度值,将图像特征转换成伪点云,输入已有基于激光点云的3D目标检测模型中,实现目标的检测和定位. 这些方法的预测准确度严重依赖深度预测模型预测的深度结果,且整体模型参数量和复杂度很大,不利于实际应用部署. LPCG-Monoflex[5 ] 利用基于激光点云的3D目标检测模型从大量激光雷达数据中生成伪标签,再用这些伪标签进一步监督单目3D目标检测模型训练;CMKD[6 ] 以知识蒸馏的方式,利用基于激光雷达的3D目标检测模型对单目3D目标检测模型进行监督训练. 以上2种方法只在训练阶段涉及基于激光雷达的3D目标检测模型,在实际应用推理时仅使用单目3D目标检测模型,模型的大小和性能都大幅度提升,但是需要大量数据支撑,且在一定程度上依赖基于激光雷达的3D目标检测模型的性能. 为了避免使用基于激光雷达的检测模型,AutoShape[7 ] 、MSAC[8 ] 、DCD[9 ] 等模型利用目标的几何关系和投影约束来提升深度预测的准确性,改善目标的定位和姿态估计,但是几何关系和投影约束的计算复杂度非常高,对相机的内、外参数要求精确,还存在投影误差放大的问题. Lu等[10 ] 提出几何不确定性投影方法来减小投影误差放大对深度预测造成的不可控影响. 还有一些模型,如SMOKE[11 ] 和M3D-RPN[12 ] 利用卷积神经网络直接回归预测目标3D中心点在图像上的投影坐标、深度、尺寸和朝向角;在实际推理阶段,通过结合相机的内、外参数和预测的深度值,将投影坐标转换,得到3D中心点的空间坐标. 虽然SMOKE和M3D-RPN的模型较小且计算复杂度较低,符合实际部署的要求,但是深度信息预测不准确,模型的准确性有待提升. ...
1
... Liu等[1 -2 ] 探索了从单目图像检测3D目标的固有不适定性问题,指出准确地预测深度信息是提高单目3D目标检测性能的关键. Pseudo-LiDAR[3 ] 、PatchNet[4 ] 直接借助专门的深度预测模型来预测每个像素的深度值,将图像特征转换成伪点云,输入已有基于激光点云的3D目标检测模型中,实现目标的检测和定位. 这些方法的预测准确度严重依赖深度预测模型预测的深度结果,且整体模型参数量和复杂度很大,不利于实际应用部署. LPCG-Monoflex[5 ] 利用基于激光点云的3D目标检测模型从大量激光雷达数据中生成伪标签,再用这些伪标签进一步监督单目3D目标检测模型训练;CMKD[6 ] 以知识蒸馏的方式,利用基于激光雷达的3D目标检测模型对单目3D目标检测模型进行监督训练. 以上2种方法只在训练阶段涉及基于激光雷达的3D目标检测模型,在实际应用推理时仅使用单目3D目标检测模型,模型的大小和性能都大幅度提升,但是需要大量数据支撑,且在一定程度上依赖基于激光雷达的3D目标检测模型的性能. 为了避免使用基于激光雷达的检测模型,AutoShape[7 ] 、MSAC[8 ] 、DCD[9 ] 等模型利用目标的几何关系和投影约束来提升深度预测的准确性,改善目标的定位和姿态估计,但是几何关系和投影约束的计算复杂度非常高,对相机的内、外参数要求精确,还存在投影误差放大的问题. Lu等[10 ] 提出几何不确定性投影方法来减小投影误差放大对深度预测造成的不可控影响. 还有一些模型,如SMOKE[11 ] 和M3D-RPN[12 ] 利用卷积神经网络直接回归预测目标3D中心点在图像上的投影坐标、深度、尺寸和朝向角;在实际推理阶段,通过结合相机的内、外参数和预测的深度值,将投影坐标转换,得到3D中心点的空间坐标. 虽然SMOKE和M3D-RPN的模型较小且计算复杂度较低,符合实际部署的要求,但是深度信息预测不准确,模型的准确性有待提升. ...
1
... Liu等[1 -2 ] 探索了从单目图像检测3D目标的固有不适定性问题,指出准确地预测深度信息是提高单目3D目标检测性能的关键. Pseudo-LiDAR[3 ] 、PatchNet[4 ] 直接借助专门的深度预测模型来预测每个像素的深度值,将图像特征转换成伪点云,输入已有基于激光点云的3D目标检测模型中,实现目标的检测和定位. 这些方法的预测准确度严重依赖深度预测模型预测的深度结果,且整体模型参数量和复杂度很大,不利于实际应用部署. LPCG-Monoflex[5 ] 利用基于激光点云的3D目标检测模型从大量激光雷达数据中生成伪标签,再用这些伪标签进一步监督单目3D目标检测模型训练;CMKD[6 ] 以知识蒸馏的方式,利用基于激光雷达的3D目标检测模型对单目3D目标检测模型进行监督训练. 以上2种方法只在训练阶段涉及基于激光雷达的3D目标检测模型,在实际应用推理时仅使用单目3D目标检测模型,模型的大小和性能都大幅度提升,但是需要大量数据支撑,且在一定程度上依赖基于激光雷达的3D目标检测模型的性能. 为了避免使用基于激光雷达的检测模型,AutoShape[7 ] 、MSAC[8 ] 、DCD[9 ] 等模型利用目标的几何关系和投影约束来提升深度预测的准确性,改善目标的定位和姿态估计,但是几何关系和投影约束的计算复杂度非常高,对相机的内、外参数要求精确,还存在投影误差放大的问题. Lu等[10 ] 提出几何不确定性投影方法来减小投影误差放大对深度预测造成的不可控影响. 还有一些模型,如SMOKE[11 ] 和M3D-RPN[12 ] 利用卷积神经网络直接回归预测目标3D中心点在图像上的投影坐标、深度、尺寸和朝向角;在实际推理阶段,通过结合相机的内、外参数和预测的深度值,将投影坐标转换,得到3D中心点的空间坐标. 虽然SMOKE和M3D-RPN的模型较小且计算复杂度较低,符合实际部署的要求,但是深度信息预测不准确,模型的准确性有待提升. ...
1
... Liu等[1 -2 ] 探索了从单目图像检测3D目标的固有不适定性问题,指出准确地预测深度信息是提高单目3D目标检测性能的关键. Pseudo-LiDAR[3 ] 、PatchNet[4 ] 直接借助专门的深度预测模型来预测每个像素的深度值,将图像特征转换成伪点云,输入已有基于激光点云的3D目标检测模型中,实现目标的检测和定位. 这些方法的预测准确度严重依赖深度预测模型预测的深度结果,且整体模型参数量和复杂度很大,不利于实际应用部署. LPCG-Monoflex[5 ] 利用基于激光点云的3D目标检测模型从大量激光雷达数据中生成伪标签,再用这些伪标签进一步监督单目3D目标检测模型训练;CMKD[6 ] 以知识蒸馏的方式,利用基于激光雷达的3D目标检测模型对单目3D目标检测模型进行监督训练. 以上2种方法只在训练阶段涉及基于激光雷达的3D目标检测模型,在实际应用推理时仅使用单目3D目标检测模型,模型的大小和性能都大幅度提升,但是需要大量数据支撑,且在一定程度上依赖基于激光雷达的3D目标检测模型的性能. 为了避免使用基于激光雷达的检测模型,AutoShape[7 ] 、MSAC[8 ] 、DCD[9 ] 等模型利用目标的几何关系和投影约束来提升深度预测的准确性,改善目标的定位和姿态估计,但是几何关系和投影约束的计算复杂度非常高,对相机的内、外参数要求精确,还存在投影误差放大的问题. Lu等[10 ] 提出几何不确定性投影方法来减小投影误差放大对深度预测造成的不可控影响. 还有一些模型,如SMOKE[11 ] 和M3D-RPN[12 ] 利用卷积神经网络直接回归预测目标3D中心点在图像上的投影坐标、深度、尺寸和朝向角;在实际推理阶段,通过结合相机的内、外参数和预测的深度值,将投影坐标转换,得到3D中心点的空间坐标. 虽然SMOKE和M3D-RPN的模型较小且计算复杂度较低,符合实际部署的要求,但是深度信息预测不准确,模型的准确性有待提升. ...
1
... Liu等[1 -2 ] 探索了从单目图像检测3D目标的固有不适定性问题,指出准确地预测深度信息是提高单目3D目标检测性能的关键. Pseudo-LiDAR[3 ] 、PatchNet[4 ] 直接借助专门的深度预测模型来预测每个像素的深度值,将图像特征转换成伪点云,输入已有基于激光点云的3D目标检测模型中,实现目标的检测和定位. 这些方法的预测准确度严重依赖深度预测模型预测的深度结果,且整体模型参数量和复杂度很大,不利于实际应用部署. LPCG-Monoflex[5 ] 利用基于激光点云的3D目标检测模型从大量激光雷达数据中生成伪标签,再用这些伪标签进一步监督单目3D目标检测模型训练;CMKD[6 ] 以知识蒸馏的方式,利用基于激光雷达的3D目标检测模型对单目3D目标检测模型进行监督训练. 以上2种方法只在训练阶段涉及基于激光雷达的3D目标检测模型,在实际应用推理时仅使用单目3D目标检测模型,模型的大小和性能都大幅度提升,但是需要大量数据支撑,且在一定程度上依赖基于激光雷达的3D目标检测模型的性能. 为了避免使用基于激光雷达的检测模型,AutoShape[7 ] 、MSAC[8 ] 、DCD[9 ] 等模型利用目标的几何关系和投影约束来提升深度预测的准确性,改善目标的定位和姿态估计,但是几何关系和投影约束的计算复杂度非常高,对相机的内、外参数要求精确,还存在投影误差放大的问题. Lu等[10 ] 提出几何不确定性投影方法来减小投影误差放大对深度预测造成的不可控影响. 还有一些模型,如SMOKE[11 ] 和M3D-RPN[12 ] 利用卷积神经网络直接回归预测目标3D中心点在图像上的投影坐标、深度、尺寸和朝向角;在实际推理阶段,通过结合相机的内、外参数和预测的深度值,将投影坐标转换,得到3D中心点的空间坐标. 虽然SMOKE和M3D-RPN的模型较小且计算复杂度较低,符合实际部署的要求,但是深度信息预测不准确,模型的准确性有待提升. ...
1
... Liu等[1 -2 ] 探索了从单目图像检测3D目标的固有不适定性问题,指出准确地预测深度信息是提高单目3D目标检测性能的关键. Pseudo-LiDAR[3 ] 、PatchNet[4 ] 直接借助专门的深度预测模型来预测每个像素的深度值,将图像特征转换成伪点云,输入已有基于激光点云的3D目标检测模型中,实现目标的检测和定位. 这些方法的预测准确度严重依赖深度预测模型预测的深度结果,且整体模型参数量和复杂度很大,不利于实际应用部署. LPCG-Monoflex[5 ] 利用基于激光点云的3D目标检测模型从大量激光雷达数据中生成伪标签,再用这些伪标签进一步监督单目3D目标检测模型训练;CMKD[6 ] 以知识蒸馏的方式,利用基于激光雷达的3D目标检测模型对单目3D目标检测模型进行监督训练. 以上2种方法只在训练阶段涉及基于激光雷达的3D目标检测模型,在实际应用推理时仅使用单目3D目标检测模型,模型的大小和性能都大幅度提升,但是需要大量数据支撑,且在一定程度上依赖基于激光雷达的3D目标检测模型的性能. 为了避免使用基于激光雷达的检测模型,AutoShape[7 ] 、MSAC[8 ] 、DCD[9 ] 等模型利用目标的几何关系和投影约束来提升深度预测的准确性,改善目标的定位和姿态估计,但是几何关系和投影约束的计算复杂度非常高,对相机的内、外参数要求精确,还存在投影误差放大的问题. Lu等[10 ] 提出几何不确定性投影方法来减小投影误差放大对深度预测造成的不可控影响. 还有一些模型,如SMOKE[11 ] 和M3D-RPN[12 ] 利用卷积神经网络直接回归预测目标3D中心点在图像上的投影坐标、深度、尺寸和朝向角;在实际推理阶段,通过结合相机的内、外参数和预测的深度值,将投影坐标转换,得到3D中心点的空间坐标. 虽然SMOKE和M3D-RPN的模型较小且计算复杂度较低,符合实际部署的要求,但是深度信息预测不准确,模型的准确性有待提升. ...
2
... Liu等[1 -2 ] 探索了从单目图像检测3D目标的固有不适定性问题,指出准确地预测深度信息是提高单目3D目标检测性能的关键. Pseudo-LiDAR[3 ] 、PatchNet[4 ] 直接借助专门的深度预测模型来预测每个像素的深度值,将图像特征转换成伪点云,输入已有基于激光点云的3D目标检测模型中,实现目标的检测和定位. 这些方法的预测准确度严重依赖深度预测模型预测的深度结果,且整体模型参数量和复杂度很大,不利于实际应用部署. LPCG-Monoflex[5 ] 利用基于激光点云的3D目标检测模型从大量激光雷达数据中生成伪标签,再用这些伪标签进一步监督单目3D目标检测模型训练;CMKD[6 ] 以知识蒸馏的方式,利用基于激光雷达的3D目标检测模型对单目3D目标检测模型进行监督训练. 以上2种方法只在训练阶段涉及基于激光雷达的3D目标检测模型,在实际应用推理时仅使用单目3D目标检测模型,模型的大小和性能都大幅度提升,但是需要大量数据支撑,且在一定程度上依赖基于激光雷达的3D目标检测模型的性能. 为了避免使用基于激光雷达的检测模型,AutoShape[7 ] 、MSAC[8 ] 、DCD[9 ] 等模型利用目标的几何关系和投影约束来提升深度预测的准确性,改善目标的定位和姿态估计,但是几何关系和投影约束的计算复杂度非常高,对相机的内、外参数要求精确,还存在投影误差放大的问题. Lu等[10 ] 提出几何不确定性投影方法来减小投影误差放大对深度预测造成的不可控影响. 还有一些模型,如SMOKE[11 ] 和M3D-RPN[12 ] 利用卷积神经网络直接回归预测目标3D中心点在图像上的投影坐标、深度、尺寸和朝向角;在实际推理阶段,通过结合相机的内、外参数和预测的深度值,将投影坐标转换,得到3D中心点的空间坐标. 虽然SMOKE和M3D-RPN的模型较小且计算复杂度较低,符合实际部署的要求,但是深度信息预测不准确,模型的准确性有待提升. ...
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
基于空间约束的自适应单目3D物体检测算法
1
2020
... Liu等[1 -2 ] 探索了从单目图像检测3D目标的固有不适定性问题,指出准确地预测深度信息是提高单目3D目标检测性能的关键. Pseudo-LiDAR[3 ] 、PatchNet[4 ] 直接借助专门的深度预测模型来预测每个像素的深度值,将图像特征转换成伪点云,输入已有基于激光点云的3D目标检测模型中,实现目标的检测和定位. 这些方法的预测准确度严重依赖深度预测模型预测的深度结果,且整体模型参数量和复杂度很大,不利于实际应用部署. LPCG-Monoflex[5 ] 利用基于激光点云的3D目标检测模型从大量激光雷达数据中生成伪标签,再用这些伪标签进一步监督单目3D目标检测模型训练;CMKD[6 ] 以知识蒸馏的方式,利用基于激光雷达的3D目标检测模型对单目3D目标检测模型进行监督训练. 以上2种方法只在训练阶段涉及基于激光雷达的3D目标检测模型,在实际应用推理时仅使用单目3D目标检测模型,模型的大小和性能都大幅度提升,但是需要大量数据支撑,且在一定程度上依赖基于激光雷达的3D目标检测模型的性能. 为了避免使用基于激光雷达的检测模型,AutoShape[7 ] 、MSAC[8 ] 、DCD[9 ] 等模型利用目标的几何关系和投影约束来提升深度预测的准确性,改善目标的定位和姿态估计,但是几何关系和投影约束的计算复杂度非常高,对相机的内、外参数要求精确,还存在投影误差放大的问题. Lu等[10 ] 提出几何不确定性投影方法来减小投影误差放大对深度预测造成的不可控影响. 还有一些模型,如SMOKE[11 ] 和M3D-RPN[12 ] 利用卷积神经网络直接回归预测目标3D中心点在图像上的投影坐标、深度、尺寸和朝向角;在实际推理阶段,通过结合相机的内、外参数和预测的深度值,将投影坐标转换,得到3D中心点的空间坐标. 虽然SMOKE和M3D-RPN的模型较小且计算复杂度较低,符合实际部署的要求,但是深度信息预测不准确,模型的准确性有待提升. ...
基于空间约束的自适应单目3D物体检测算法
1
2020
... Liu等[1 -2 ] 探索了从单目图像检测3D目标的固有不适定性问题,指出准确地预测深度信息是提高单目3D目标检测性能的关键. Pseudo-LiDAR[3 ] 、PatchNet[4 ] 直接借助专门的深度预测模型来预测每个像素的深度值,将图像特征转换成伪点云,输入已有基于激光点云的3D目标检测模型中,实现目标的检测和定位. 这些方法的预测准确度严重依赖深度预测模型预测的深度结果,且整体模型参数量和复杂度很大,不利于实际应用部署. LPCG-Monoflex[5 ] 利用基于激光点云的3D目标检测模型从大量激光雷达数据中生成伪标签,再用这些伪标签进一步监督单目3D目标检测模型训练;CMKD[6 ] 以知识蒸馏的方式,利用基于激光雷达的3D目标检测模型对单目3D目标检测模型进行监督训练. 以上2种方法只在训练阶段涉及基于激光雷达的3D目标检测模型,在实际应用推理时仅使用单目3D目标检测模型,模型的大小和性能都大幅度提升,但是需要大量数据支撑,且在一定程度上依赖基于激光雷达的3D目标检测模型的性能. 为了避免使用基于激光雷达的检测模型,AutoShape[7 ] 、MSAC[8 ] 、DCD[9 ] 等模型利用目标的几何关系和投影约束来提升深度预测的准确性,改善目标的定位和姿态估计,但是几何关系和投影约束的计算复杂度非常高,对相机的内、外参数要求精确,还存在投影误差放大的问题. Lu等[10 ] 提出几何不确定性投影方法来减小投影误差放大对深度预测造成的不可控影响. 还有一些模型,如SMOKE[11 ] 和M3D-RPN[12 ] 利用卷积神经网络直接回归预测目标3D中心点在图像上的投影坐标、深度、尺寸和朝向角;在实际推理阶段,通过结合相机的内、外参数和预测的深度值,将投影坐标转换,得到3D中心点的空间坐标. 虽然SMOKE和M3D-RPN的模型较小且计算复杂度较低,符合实际部署的要求,但是深度信息预测不准确,模型的准确性有待提升. ...
2
... Liu等[1 -2 ] 探索了从单目图像检测3D目标的固有不适定性问题,指出准确地预测深度信息是提高单目3D目标检测性能的关键. Pseudo-LiDAR[3 ] 、PatchNet[4 ] 直接借助专门的深度预测模型来预测每个像素的深度值,将图像特征转换成伪点云,输入已有基于激光点云的3D目标检测模型中,实现目标的检测和定位. 这些方法的预测准确度严重依赖深度预测模型预测的深度结果,且整体模型参数量和复杂度很大,不利于实际应用部署. LPCG-Monoflex[5 ] 利用基于激光点云的3D目标检测模型从大量激光雷达数据中生成伪标签,再用这些伪标签进一步监督单目3D目标检测模型训练;CMKD[6 ] 以知识蒸馏的方式,利用基于激光雷达的3D目标检测模型对单目3D目标检测模型进行监督训练. 以上2种方法只在训练阶段涉及基于激光雷达的3D目标检测模型,在实际应用推理时仅使用单目3D目标检测模型,模型的大小和性能都大幅度提升,但是需要大量数据支撑,且在一定程度上依赖基于激光雷达的3D目标检测模型的性能. 为了避免使用基于激光雷达的检测模型,AutoShape[7 ] 、MSAC[8 ] 、DCD[9 ] 等模型利用目标的几何关系和投影约束来提升深度预测的准确性,改善目标的定位和姿态估计,但是几何关系和投影约束的计算复杂度非常高,对相机的内、外参数要求精确,还存在投影误差放大的问题. Lu等[10 ] 提出几何不确定性投影方法来减小投影误差放大对深度预测造成的不可控影响. 还有一些模型,如SMOKE[11 ] 和M3D-RPN[12 ] 利用卷积神经网络直接回归预测目标3D中心点在图像上的投影坐标、深度、尺寸和朝向角;在实际推理阶段,通过结合相机的内、外参数和预测的深度值,将投影坐标转换,得到3D中心点的空间坐标. 虽然SMOKE和M3D-RPN的模型较小且计算复杂度较低,符合实际部署的要求,但是深度信息预测不准确,模型的准确性有待提升. ...
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
3
... Liu等[1 -2 ] 探索了从单目图像检测3D目标的固有不适定性问题,指出准确地预测深度信息是提高单目3D目标检测性能的关键. Pseudo-LiDAR[3 ] 、PatchNet[4 ] 直接借助专门的深度预测模型来预测每个像素的深度值,将图像特征转换成伪点云,输入已有基于激光点云的3D目标检测模型中,实现目标的检测和定位. 这些方法的预测准确度严重依赖深度预测模型预测的深度结果,且整体模型参数量和复杂度很大,不利于实际应用部署. LPCG-Monoflex[5 ] 利用基于激光点云的3D目标检测模型从大量激光雷达数据中生成伪标签,再用这些伪标签进一步监督单目3D目标检测模型训练;CMKD[6 ] 以知识蒸馏的方式,利用基于激光雷达的3D目标检测模型对单目3D目标检测模型进行监督训练. 以上2种方法只在训练阶段涉及基于激光雷达的3D目标检测模型,在实际应用推理时仅使用单目3D目标检测模型,模型的大小和性能都大幅度提升,但是需要大量数据支撑,且在一定程度上依赖基于激光雷达的3D目标检测模型的性能. 为了避免使用基于激光雷达的检测模型,AutoShape[7 ] 、MSAC[8 ] 、DCD[9 ] 等模型利用目标的几何关系和投影约束来提升深度预测的准确性,改善目标的定位和姿态估计,但是几何关系和投影约束的计算复杂度非常高,对相机的内、外参数要求精确,还存在投影误差放大的问题. Lu等[10 ] 提出几何不确定性投影方法来减小投影误差放大对深度预测造成的不可控影响. 还有一些模型,如SMOKE[11 ] 和M3D-RPN[12 ] 利用卷积神经网络直接回归预测目标3D中心点在图像上的投影坐标、深度、尺寸和朝向角;在实际推理阶段,通过结合相机的内、外参数和预测的深度值,将投影坐标转换,得到3D中心点的空间坐标. 虽然SMOKE和M3D-RPN的模型较小且计算复杂度较低,符合实际部署的要求,但是深度信息预测不准确,模型的准确性有待提升. ...
... 如图1 所示,上下文信息增强和深度引导模型主要由5个部分组成:特征编码、高效的上下文信息增强模块、2D预测、特征对齐和3D预测. 特征编码部分以由单个相机捕获的RGB图像$ {\boldsymbol{I}} \in {{\bf{R}}^{H \times W \times 3}} $ H 为图像的高度,W 为图像的宽度),经过单目3D目标检测模型中应用最广泛的特征提取主干网络[15 ] (特征编码器DLA34和特征解码器DLAup)得到特征图$ {\boldsymbol{F}} \in {{\bf{R}}^{H/4 \times W/4 \times C}} $ C 为通道数;经过本研究构建模块进一步扩大感受野,并在不同尺度上自适应地聚合丰富的上下文信息,得到增强后的特征图. 在2D预测部分,基于CenterNet[16 ] 无锚框的方法预测2D目标框属性,包括热力图、2D中心点偏差和2D尺寸. 在特征对齐部分,为了更好地在目标区域内进行预测,减少背景噪声干扰,根据2D检测结果得到每个目标在特征图中的对应区域,利用特征提取(RoIAlign)操作将每个目标对应区域的特征统一对齐成7×7大小的特征图,按照GUPNet[10 ] 将目标的空间坐标(coord maps)与目标特征图进行拼接,为后续3D目标检测提供空间位置信息. 3D属性预测包括3D尺寸、3D中心点投影偏差、朝向角和深度及其不确定度,其中深度及其不确定度预测按照DID-M3D[17 ] 模型中提出的方式进行预测,将实例深度分解为属性深度和视觉深度,同时预测对应深度的不确定度. 通过深度误差加权损失进一步监督深度和长度的预测,最终得到目标框的预测结果. ...
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
... Liu等[1 -2 ] 探索了从单目图像检测3D目标的固有不适定性问题,指出准确地预测深度信息是提高单目3D目标检测性能的关键. Pseudo-LiDAR[3 ] 、PatchNet[4 ] 直接借助专门的深度预测模型来预测每个像素的深度值,将图像特征转换成伪点云,输入已有基于激光点云的3D目标检测模型中,实现目标的检测和定位. 这些方法的预测准确度严重依赖深度预测模型预测的深度结果,且整体模型参数量和复杂度很大,不利于实际应用部署. LPCG-Monoflex[5 ] 利用基于激光点云的3D目标检测模型从大量激光雷达数据中生成伪标签,再用这些伪标签进一步监督单目3D目标检测模型训练;CMKD[6 ] 以知识蒸馏的方式,利用基于激光雷达的3D目标检测模型对单目3D目标检测模型进行监督训练. 以上2种方法只在训练阶段涉及基于激光雷达的3D目标检测模型,在实际应用推理时仅使用单目3D目标检测模型,模型的大小和性能都大幅度提升,但是需要大量数据支撑,且在一定程度上依赖基于激光雷达的3D目标检测模型的性能. 为了避免使用基于激光雷达的检测模型,AutoShape[7 ] 、MSAC[8 ] 、DCD[9 ] 等模型利用目标的几何关系和投影约束来提升深度预测的准确性,改善目标的定位和姿态估计,但是几何关系和投影约束的计算复杂度非常高,对相机的内、外参数要求精确,还存在投影误差放大的问题. Lu等[10 ] 提出几何不确定性投影方法来减小投影误差放大对深度预测造成的不可控影响. 还有一些模型,如SMOKE[11 ] 和M3D-RPN[12 ] 利用卷积神经网络直接回归预测目标3D中心点在图像上的投影坐标、深度、尺寸和朝向角;在实际推理阶段,通过结合相机的内、外参数和预测的深度值,将投影坐标转换,得到3D中心点的空间坐标. 虽然SMOKE和M3D-RPN的模型较小且计算复杂度较低,符合实际部署的要求,但是深度信息预测不准确,模型的准确性有待提升. ...
1
... Liu等[1 -2 ] 探索了从单目图像检测3D目标的固有不适定性问题,指出准确地预测深度信息是提高单目3D目标检测性能的关键. Pseudo-LiDAR[3 ] 、PatchNet[4 ] 直接借助专门的深度预测模型来预测每个像素的深度值,将图像特征转换成伪点云,输入已有基于激光点云的3D目标检测模型中,实现目标的检测和定位. 这些方法的预测准确度严重依赖深度预测模型预测的深度结果,且整体模型参数量和复杂度很大,不利于实际应用部署. LPCG-Monoflex[5 ] 利用基于激光点云的3D目标检测模型从大量激光雷达数据中生成伪标签,再用这些伪标签进一步监督单目3D目标检测模型训练;CMKD[6 ] 以知识蒸馏的方式,利用基于激光雷达的3D目标检测模型对单目3D目标检测模型进行监督训练. 以上2种方法只在训练阶段涉及基于激光雷达的3D目标检测模型,在实际应用推理时仅使用单目3D目标检测模型,模型的大小和性能都大幅度提升,但是需要大量数据支撑,且在一定程度上依赖基于激光雷达的3D目标检测模型的性能. 为了避免使用基于激光雷达的检测模型,AutoShape[7 ] 、MSAC[8 ] 、DCD[9 ] 等模型利用目标的几何关系和投影约束来提升深度预测的准确性,改善目标的定位和姿态估计,但是几何关系和投影约束的计算复杂度非常高,对相机的内、外参数要求精确,还存在投影误差放大的问题. Lu等[10 ] 提出几何不确定性投影方法来减小投影误差放大对深度预测造成的不可控影响. 还有一些模型,如SMOKE[11 ] 和M3D-RPN[12 ] 利用卷积神经网络直接回归预测目标3D中心点在图像上的投影坐标、深度、尺寸和朝向角;在实际推理阶段,通过结合相机的内、外参数和预测的深度值,将投影坐标转换,得到3D中心点的空间坐标. 虽然SMOKE和M3D-RPN的模型较小且计算复杂度较低,符合实际部署的要求,但是深度信息预测不准确,模型的准确性有待提升. ...
1
... 上述单目3D目标检测方法均基于卷积神经网络构建,通过串联多个小卷积核的卷积来扩大感受野,增强上下文信息的提取能力. Transformer结构被引入计算机视觉任务,通过自注意力机制捕捉长距离依赖关系,提取丰富的上下文信息,在图像分类、分割和检测等多个领域中显著提升了模型的性能. MonoDETR[13 ] 、MonoDTR[14 ] 利用自注意力机制全局聚合上下文信息和深度特征,通过深度线索得到位置编码嵌入模型以得到更好的深度预测结果. 但是,Transformer结构的计算复杂度较高,尤其在3D目标检测中,输入图像的分辨率一般为384×1 280,Transformer结构如何高效处理高分辨率图像成为目标检测的挑战. 在卷积神经网络中,大核卷积有效地扩大感受野,提取丰富的上下文信息,如何将大核卷积应用于单目3D目标检测值得深入研究. 为了准确预测目标的3D属性,本研究构建高效的上下文信息增强模块,利用大核卷积捕捉图像的上下文信息;为了降低大核卷积的参数量和计算量,采用深度可分离卷积和条形卷积进一步优化大核卷积. 为了探索3D预测框各个属性的预测结果对目标检测精度的影响,进行数据和实验分析,提出基于深度误差的损失权重,监督目标的长度和深度预测,提高长度和深度预测的准确性. ...
2
... 上述单目3D目标检测方法均基于卷积神经网络构建,通过串联多个小卷积核的卷积来扩大感受野,增强上下文信息的提取能力. Transformer结构被引入计算机视觉任务,通过自注意力机制捕捉长距离依赖关系,提取丰富的上下文信息,在图像分类、分割和检测等多个领域中显著提升了模型的性能. MonoDETR[13 ] 、MonoDTR[14 ] 利用自注意力机制全局聚合上下文信息和深度特征,通过深度线索得到位置编码嵌入模型以得到更好的深度预测结果. 但是,Transformer结构的计算复杂度较高,尤其在3D目标检测中,输入图像的分辨率一般为384×1 280,Transformer结构如何高效处理高分辨率图像成为目标检测的挑战. 在卷积神经网络中,大核卷积有效地扩大感受野,提取丰富的上下文信息,如何将大核卷积应用于单目3D目标检测值得深入研究. 为了准确预测目标的3D属性,本研究构建高效的上下文信息增强模块,利用大核卷积捕捉图像的上下文信息;为了降低大核卷积的参数量和计算量,采用深度可分离卷积和条形卷积进一步优化大核卷积. 为了探索3D预测框各个属性的预测结果对目标检测精度的影响,进行数据和实验分析,提出基于深度误差的损失权重,监督目标的长度和深度预测,提高长度和深度预测的准确性. ...
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
... 如图1 所示,上下文信息增强和深度引导模型主要由5个部分组成:特征编码、高效的上下文信息增强模块、2D预测、特征对齐和3D预测. 特征编码部分以由单个相机捕获的RGB图像$ {\boldsymbol{I}} \in {{\bf{R}}^{H \times W \times 3}} $ H 为图像的高度,W 为图像的宽度),经过单目3D目标检测模型中应用最广泛的特征提取主干网络[15 ] (特征编码器DLA34和特征解码器DLAup)得到特征图$ {\boldsymbol{F}} \in {{\bf{R}}^{H/4 \times W/4 \times C}} $ C 为通道数;经过本研究构建模块进一步扩大感受野,并在不同尺度上自适应地聚合丰富的上下文信息,得到增强后的特征图. 在2D预测部分,基于CenterNet[16 ] 无锚框的方法预测2D目标框属性,包括热力图、2D中心点偏差和2D尺寸. 在特征对齐部分,为了更好地在目标区域内进行预测,减少背景噪声干扰,根据2D检测结果得到每个目标在特征图中的对应区域,利用特征提取(RoIAlign)操作将每个目标对应区域的特征统一对齐成7×7大小的特征图,按照GUPNet[10 ] 将目标的空间坐标(coord maps)与目标特征图进行拼接,为后续3D目标检测提供空间位置信息. 3D属性预测包括3D尺寸、3D中心点投影偏差、朝向角和深度及其不确定度,其中深度及其不确定度预测按照DID-M3D[17 ] 模型中提出的方式进行预测,将实例深度分解为属性深度和视觉深度,同时预测对应深度的不确定度. 通过深度误差加权损失进一步监督深度和长度的预测,最终得到目标框的预测结果. ...
1
... 如图1 所示,上下文信息增强和深度引导模型主要由5个部分组成:特征编码、高效的上下文信息增强模块、2D预测、特征对齐和3D预测. 特征编码部分以由单个相机捕获的RGB图像$ {\boldsymbol{I}} \in {{\bf{R}}^{H \times W \times 3}} $ H 为图像的高度,W 为图像的宽度),经过单目3D目标检测模型中应用最广泛的特征提取主干网络[15 ] (特征编码器DLA34和特征解码器DLAup)得到特征图$ {\boldsymbol{F}} \in {{\bf{R}}^{H/4 \times W/4 \times C}} $ C 为通道数;经过本研究构建模块进一步扩大感受野,并在不同尺度上自适应地聚合丰富的上下文信息,得到增强后的特征图. 在2D预测部分,基于CenterNet[16 ] 无锚框的方法预测2D目标框属性,包括热力图、2D中心点偏差和2D尺寸. 在特征对齐部分,为了更好地在目标区域内进行预测,减少背景噪声干扰,根据2D检测结果得到每个目标在特征图中的对应区域,利用特征提取(RoIAlign)操作将每个目标对应区域的特征统一对齐成7×7大小的特征图,按照GUPNet[10 ] 将目标的空间坐标(coord maps)与目标特征图进行拼接,为后续3D目标检测提供空间位置信息. 3D属性预测包括3D尺寸、3D中心点投影偏差、朝向角和深度及其不确定度,其中深度及其不确定度预测按照DID-M3D[17 ] 模型中提出的方式进行预测,将实例深度分解为属性深度和视觉深度,同时预测对应深度的不确定度. 通过深度误差加权损失进一步监督深度和长度的预测,最终得到目标框的预测结果. ...
2
... 如图1 所示,上下文信息增强和深度引导模型主要由5个部分组成:特征编码、高效的上下文信息增强模块、2D预测、特征对齐和3D预测. 特征编码部分以由单个相机捕获的RGB图像$ {\boldsymbol{I}} \in {{\bf{R}}^{H \times W \times 3}} $ H 为图像的高度,W 为图像的宽度),经过单目3D目标检测模型中应用最广泛的特征提取主干网络[15 ] (特征编码器DLA34和特征解码器DLAup)得到特征图$ {\boldsymbol{F}} \in {{\bf{R}}^{H/4 \times W/4 \times C}} $ C 为通道数;经过本研究构建模块进一步扩大感受野,并在不同尺度上自适应地聚合丰富的上下文信息,得到增强后的特征图. 在2D预测部分,基于CenterNet[16 ] 无锚框的方法预测2D目标框属性,包括热力图、2D中心点偏差和2D尺寸. 在特征对齐部分,为了更好地在目标区域内进行预测,减少背景噪声干扰,根据2D检测结果得到每个目标在特征图中的对应区域,利用特征提取(RoIAlign)操作将每个目标对应区域的特征统一对齐成7×7大小的特征图,按照GUPNet[10 ] 将目标的空间坐标(coord maps)与目标特征图进行拼接,为后续3D目标检测提供空间位置信息. 3D属性预测包括3D尺寸、3D中心点投影偏差、朝向角和深度及其不确定度,其中深度及其不确定度预测按照DID-M3D[17 ] 模型中提出的方式进行预测,将实例深度分解为属性深度和视觉深度,同时预测对应深度的不确定度. 通过深度误差加权损失进一步监督深度和长度的预测,最终得到目标框的预测结果. ...
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
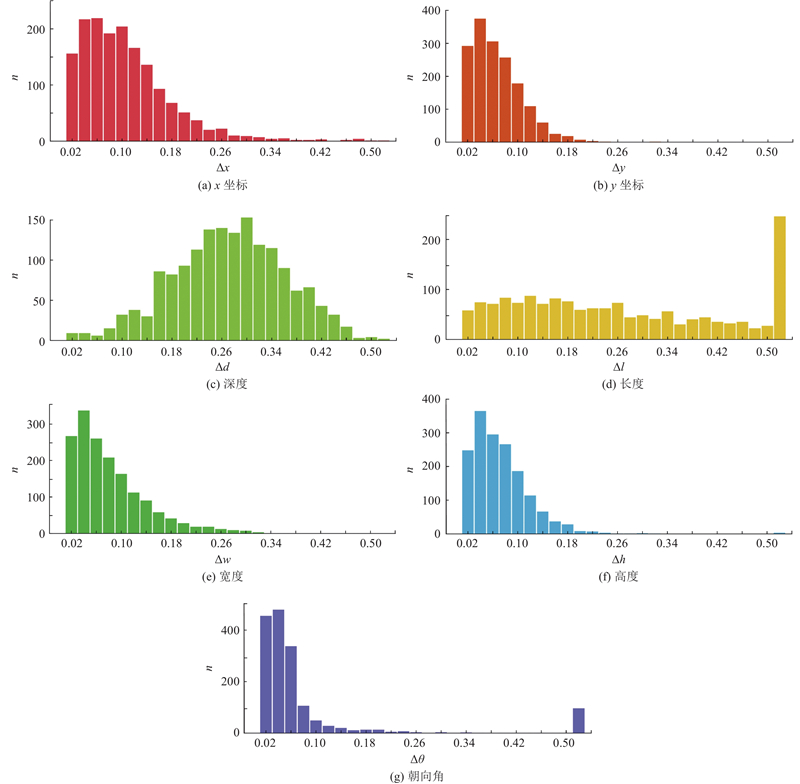
... 为了探索对模型检测结果影响较大的潜在因素,在KITTI[18 ] 数据集上统计基线模型的3D预测框各个属性{x , y , d , l , w , h , θ }的预测误差,各个属性的预测误差等于预测值与真实值之差的绝对值. 其中{x , y , d }为3D框中心点在相机坐标系下的位置坐标,l 、w 、h 为3D框的长、宽、高,θ 为3D框的朝向角. 判断目标是否被正确检测的标准是计算预测框与真实框之间的交并比(intersection over union, IoU). 当IoU$ \geqslant $ 0.7 时,说明预测框较好地检测出对应目标;当交并比IoU$ \leqslant $ 0.5 时,说明预测框与目标真实框误差很大. 对于现有方法IoU$ \in $ (0.5 , 0.7)的预测框,如果能够提高3D属性的预测精度,则有希望使预测框与真实框的IoU$\geqslant $ 0.7 ,从而提升算法检测效果. 本研究以DID-M3D方法为基线方法,对IoU$ \in $ (0.5 , 0.7)的预测框各个属性的预测误差进行直方图统计,统计结果如图2 所示. 由图可知, 3D属性{x , y , w , h , θ }的预测误差分布趋势基本一致,大部分预测误差集中在较小的数值范围内. 目标的朝向角在误差超过0.5时的数量激增,进一步观察朝向角预测误差较大的情况,发现当朝向角接近0、±π/2和±π时,由于目标几何场景特征信息严重丢失,模型对朝向角的预测值与真实值之间符号相反,导致预测误差较大. d 和l 的预测误差分布存在明显不同. 在自动驾驶场景中,3D目标通过相机投影到2D图像平面时,深度信息会严重丢失;对于大部分同向或逆向行驶的车辆,长度信息投影到2D图像平面上也会受到较大影响. 因此,深度和长度比其他3D属性更难预测,对应的预测误差相对较大. 针对以上实验结果分析,本研究认为:减小目标长度和深度的预测误差能够提升预测框的准确性,使得原来在IoU阈值边缘的预测框符合目标检测的要求. 本研究提出深度误差加权损失函数,进一步监督长度和深度预测,提高模型的预测精度. 深度误差加权损失函数表达式为 ...
1
... 式中:$ {d}_{j} $ $ {d}_{j}^{\mathrm{g}\mathrm{t}} $ $ {u}_{j} $ $ {L}_{\theta } $ [19 ] 监督,将$ \left[-\text{π},\text{π}\right] $ n 个有重叠的格子,网络预测目标的朝向角属于每个格子的置信度$ {L}_{\mathrm{c}\mathrm{o}\mathrm{n}\mathrm{f}} $ $ {L}_{\mathrm{l}\mathrm{o}\mathrm{c}} $ . 最终目标的朝向角等于置信度最高格子的中心角度加上残差角度. ...
1
... 使用单目3D目标检测任务中常用的数据集KITTI、Waymo[20 ] 进行模型训练和性能对比. ...
2
... Waymo是3D目标检测领域中规模较大的公开数据集,包含798个训练序列和202个验证序列,每个序列包含2.0×105 个样本. CaDNN[21 ] 是在该数据集上进行实验的单目3D目标检测模型,它以每3帧采样一次的方式构建训练数据集,考虑到硬件资源和时间成本,本研究以50帧为间隔进行采样,以构建相应的数据集. 由于Waymo标签中没有遮挡程度和截断程度,评价检测精度时除了整体的检测精度,通常还会按照目标深度值划分为(0, 30]、(30, 50]和(50, +∞)共3个级别进行评价. ...
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
SGM3D: stereo guided monocular 3D object detection
1
2022
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...
1
... Comparison of monocular 3D object detection accuracy for different object detection models in KITTI test set
% Tab.1 模型 发表位置 $ {{\mathrm{AP}}_{{\mathrm{3D}}}}|{R_{40}} $ $ {{\mathrm{AP}}_{{\mathrm{BEV}}}}|{R_{40}} $ 简单 中等 困难 简单 中等 困难 CaDDN[21 ] CVPR21 19.17 13.41 11.46 27.94 18.91 17.19 Monodle[22 ] CVPR21 17.23 12.26 10.29 24.79 18.89 16.00 GrooMeD-NMS[23 ] CVPR21 18.10 12.32 9.65 26.19 18.27 14.05 MonoEF[24 ] CVPR21 21.29 13.87 11.71 29.03 19.70 17.26 MonoFlex[25 ] CVPR21 19.94 13.89 12.07 28.23 19.75 16.89 AutoShape[7 ] ICCV21 22.47 14.17 11.36 30.66 20.08 15.95 GUPNet[10 ] ICCV21 22.26 15.02 13.12 30.29 21.19 18.20 PCT[26 ] NeurIPS21 21.00 13.37 11.31 29.65 19.03 15.92 MonoGround[27 ] CVPR22 21.37 14.36 12.62 30.07 20.47 17.74 HomoLoss[28 ] CVPR22 21.75 14.94 13.07 29.60 20.68 17.81 MonoDTR[14 ] CVPR22 21.99 15.39 12.73 28.59 20.38 17.14 MonoJSG[29 ] CVPR22 24.69 16.14 13.64 32.59 21.26 18.18 DCD[9 ] ECCV22 23.81 15.90 13.21 32.55 21.50 18.25 DEVIANT[30 ] ECCV22 21.88 14.46 11.89 29.65 20.44 17.43 DID-M3D[17 ] ECCV22 24.40 16.29 13.75 32.95 22.76 19.83 SGM3D[31 ] RAL22 22.46 14.65 12.97 31.49 21.37 18.43 MonoCon[32 ] AAAI22 22.50 16.46 13.95 31.12 22.10 19.00 MonoRCNN++[33 ] WACV23 20.08 13.72 11.34 — — — MonoEdge[34 ] WACV23 21.08 14.47 12.73 28.80 20.35 17.57 本研究 — 26.74 16.67 14.33 34.73 22.84 19.52
2.5. 消融实验 对方法的组合,大核卷积核大小的选择和深度误差加权损失超参数的设置进行消融实验. 为了验证深度误差加权损失的普适性,在Waymo上进行深度误差加权损失的消融实验. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}