

现有面向交叉口场景的智能网联车辆运动规划方法大致可分为2类:基于规则和基于学习的方法. Waymo、Uber、百度等公司均从可靠性角度采用基于规则的运动规划模型,如智能驾驶模型(intelligent driver model,IDM)[4]、最优速度模型[5]. 该类模型仅适用预先定义的规则,缺乏处理高冲突交通场景的动态协商能力,在紧急情况下感知耗时较长可能导致反应时间不足. 近年来机器学习和深度学习算法快速发展,基于学习的运动规划方法逐渐成为热点[6],将环境数据直接输入由神经网络组成的运动规划模型,能够适应各种不同的环境和任务,并且无须手动设计运动规划模型. Yang等[7]提出端到端的车辆运动规划模型,利用Udacity 数据集训练卷积神经网络,预测更新车辆速度和转向角;Thu 等[8]采用递归神经网络和Transformer网络融合点云与图像数据,通过长短时记忆神经网络(long short term memory,LSTM)生成车辆局部路径. 上述基于深度学习的方法方需要大量数据训练神经网络模型,数据依赖性强且泛化性较差. 强化学习(reinforcement learning,RL)由于无须大量标记训练数据,在自动驾驶领域中广泛应用. Isele 等[9]用占据栅格表示交叉口区域状态,利用RL运动规划算法计算得到车辆期望加速度,但该方法只适用特定的交叉口拓扑. Gunarathna等[10]提出基于Q学习的RL方法用于交叉口车辆通行决策,相比基于规则的方法通行时间更短,但未考虑交叉口处车辆交互碰撞风险. 深度强化学习(deep reinforcement learning,DRL)结合RL的表征学习能力和深度学习 (deep learning, DL)的决策能力,使智能体能在更高维度的环境中学习并做出运动决策[11-13]. Kamran等[12]等采用深度Q网络(deep Q-network,DQN)进行交叉口车辆实时速度规划,将风险预测纳入奖励函数. 但DQN算法的动作空间离散,不适用于处理连续动作空间,为此部分学者提出采用深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法解决智能车辆连续决策问题[14-15]. Li等[16]构建基于DDPG算法的智能汽车纵向运动决策方法,根据无信号交叉口处周围车辆运动状态更新自车加速度,但算法容易受到动作噪声和过估计问题的影响,结果不稳定. 为了提升连续动作空间下DRL算法稳定性,Fujimoto等[17]提出双延迟深度确定性策略梯度(twin delayed DDPG,TD3)算法,较好地避免了DDPG算法过估计问题. 裴晓飞等[18]提出构建基于TD3算法的换道决策模型,但仅以车头间距为安全性评价指标,无法准确评估动态交通环境下驾驶行为的安全性.
针对以上分析,考虑到无信号交叉口处智能网联车辆左转运动过程中可能与不同驾驶风格的周围车辆交互,且周围车辆行驶意图多变,本研究首先提出基于TCN-Transformer的周围车辆行驶意图预测模型,接着考虑车辆运动状态、行驶意图及驾驶风格等信息设计状态空间,综合行车安全性、通行效率以及舒适性等因素构建奖励函数,提出基于TD3算法的智能网联车辆运动规划模型,并通过Carla平台搭建仿真场景进行模型有效性验证.
1. 基于TCN-Transformer的周围车辆行驶意图预测
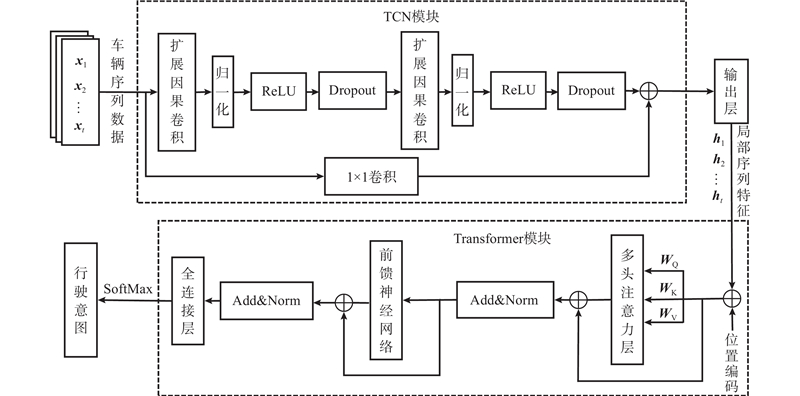
TCN-Transformer网络的整体结构如图1所示. 该网络首先通过TCN模块的多个卷积层和残差块将车辆行驶数据转换为局部特征序列,然后利用Transformer模块的多头注意力层和前馈神经网络将提取的局部特征序列转化为全局特征序列,接着采用全连接层将全局特征序列映射到预测输出空间,最后通过SoftMax函数进行归一化处理得到行驶意图预测结果. 网络输入的驾驶特征序列如下:
图 1
式中:
TCN模块采用残差块替代卷积层,通过2轮扩展因果卷积、归一化、ReLU激活函数和Dropout增强模型对驾驶序列数据的表征学习能力、减少过拟合问题、提高模型的泛化能力,然后通过一维卷积层确保输出特征维度与输入的相同. 其中,扩展因果卷积可保证训练过程不涉及未来时刻数据,同时通过增大卷积核长度和扩张因子增加卷积层的感受野,提高模型对长距离依赖关系的学习能力,具体表达式如下:
式中:
TCN模块输出的局部特征序列如下:
式中:
Transformer模块主要由自注意力层和前馈神经网络组成,将TCN模块输出的局部特征序列ht转换为全局特征序列zt,采用LayerNorm进行数据归一化:
式中:
该网络最终通过全连接层和Softmax层获取周围车辆行驶意图预测结果:
式中:
2. 智能网联车辆运动规划模型
2.1. 算法描述
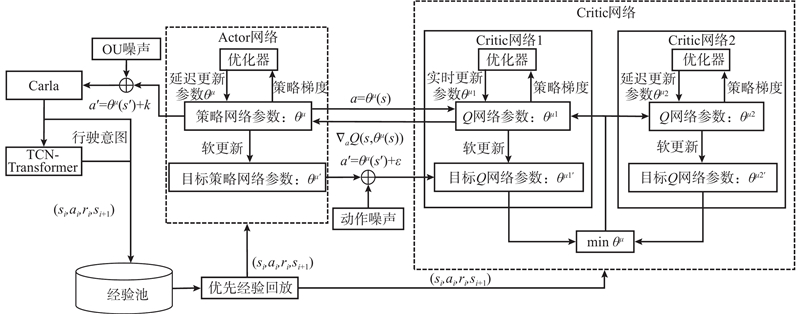
在预测周围车辆在交叉口的行驶意图基础上,采用无模型强化学习TD3算法进行无信号交叉口智能网联车辆左转运动规划,网络结构如图2所示. 强化学习的理论基础是马尔可夫决策(Markov decision process,MDP),因此将车辆左转运动规划转化为MDP最大化预期累积奖励问题,可用四元组<S,A,R,p>进行描述,其中S、A、R、p分别为状态空间、动作空间、奖励函数和状态转移概率. TD3算法在DDPG算法的基础上进行改进,DDPG算法是基于动作评价(Actor-Critic)框架的强化学习算法,包含一个Actor网络和一个Critic网络. Critic网络用于估计状态-动作对的Q值,其目标是最小化Q函数和目标Q函数之间的均方误差,其更新公式如下:
图 2
式中:
Actor网络用于学习策略,直接输出动作信号,其目标是最大化Critic网络输出的Q值,其更新公式如下:
式中:
DDPG算法容易受到环境噪声的影响,目标网络的更新速度较慢,可能导致Q函数的过度估计. 针对以上问题,TD3算法主要有以下改进:1)通过2个Critic网络计算动作价值,选取两者间的较小值作为估计值,避免出现过度估计的问题;2)对网络进行延迟策略更新,使Critic网络的更新频率高于Actor网络的,降低近似动作值函数的方差;3)采用平滑目标策略,在计算Q函数时加入服从正态分布噪声用于提高算法鲁棒性.
2.2. 问题建模
2.2.1. 状态空间
状态空间是对智能网联车辆自身状态和周围环境信息的整体描述,是保证深度强化学习算法有效性的关键. 假设智能网联车辆通过V2V通信获取周围车辆状态信息,通过GPS和CAN总线获取自车状态信息. 在获取周围车辆行驶意图后,利用三阶贝塞尔曲线拟合自车和周围转向车辆的轨迹. 三阶贝塞尔曲线定义如下:
式中:
定义冲突点为自车和周围车辆预测路径的交点,将周围第i个车辆的状态信息表示为
式中:
自车状态信息表示为
式中:
故状态空间表示为
2.2.2. 动作空间
动作空间表示智能网联车辆可采取的动作集合. 给定无信号交叉口处智能网联车辆的行驶路径,只研究最优运动策略,因此动作空间定义如下:
式中:
2.2.3. 奖励函数
1)安全性奖励函数. 为了保证智能网联车辆行驶安全性,在无信号交叉口通行过程中除了避免车辆发生碰撞外,还应使行车风险处于安全水平内. 当碰撞发生时,奖励函数给予极大惩罚;当无碰撞发生时,利用行车风险场理论[21]计算行车风险水平. 行车风险场是表征环境中人-车-路各要素对驾驶风险影响程度的一种“物理场”,将结合驾驶风格的风险场理论用于构建奖励函数:
式中:Ev为当前行车风险场强,Mi为周围第i辆车的等效质量,
设定行车风险安全阈值为
2)效率奖励函数. 为了提高无信号交叉口处智能网联车辆通行效率,定义速度奖励项
式中:
3)舒适性奖励函数. 车辆频繁急加速或急减速会给乘客带来较大的惯性冲击,影响乘坐舒适性,因此定义舒适性奖励函数如下:
式中:a、j分别为自车的加速度、冲击度,
综合考虑安全性、通行效率以及舒适性要求构建总奖励函数:
式中:
3. 试验与分析
实验硬件配置为Intel(R) Core(TM) i5-12400F,基础频率为2.50 GHz,GPU使用NVIDIA GeForce RTX
3.1. 模块性能分析
采用德国IND数据集中2个无信号交叉口实际驾驶轨迹数据进行周围车辆行驶意图预测算法训练及测试,交叉口场景如图3所示,数据采样频率为25 Hz,筛选得到左转、直行、右转各800条车辆轨迹数据,其中80%作为训练集,20%作为测试集. 基于TCN-Transformer的周围车辆行驶意图预测算法具体参数设置如下:TCN模块由3个卷积层组成,每个卷积层的卷积核大小为3,扩张因子设置为1;Transformer模块中multi-head为8,隐藏层大小为512,每个多头自注意力机制和全连接层后面都采用LayerNorm进行归一化处理,利用Dropout正则化以防止过拟合,损失函数选择交叉熵代价函数;整个算法学习率为0.001,优化器选用Adam,训练批次大小为16,训练轮次设为30.
图 3

为了验证所提TCN-Transformer算法的周围车辆意图预测性能,将所提算法与CNN-Transformer算法、LSTM算法进行对比测试,并统计车辆到达停止线时3种算法的意图预测准确率,结果如表1所示. 表中,
表 1 不同算法意图预测结果对比
Tab.1
| 算法 | 实际意图 | 预测意图 | FPS | ||||
| 直行 | 右转 | 左转 | |||||
| CNN-Transformer | 直行 | 149 | 20 | 21 | 93.1 | 333 | |
| 右转 | 6 | 134 | 2 | 83.8 | |||
| 左转 | 5 | 6 | 137 | 85.6 | |||
| LSTM | 直行 | 153 | 18 | 14 | 95.6 | 300 | |
| 右转 | 5 | 141 | 2 | 88.1 | |||
| 左转 | 2 | 1 | 144 | 90.0 | |||
| TCN-Transformer | 直行 | 157 | 5 | 4 | 98.1 | 250 | |
| 右转 | 3 | 154 | 0 | 96.3 | |||
| 左转 | 0 | 4 | 156 | 97.5 | |||
为了进一步分析所提TCN-Transformer算法提前预测交叉口处周围车辆行驶意图的能力,将周围车辆所在车道的停止线作为参考位置,选取车辆到达停止线前20 m至通过停止线后5 m区域作为被测路段对算法进行测试,并与LSTM算法进行对比,结果如图4所示. 图中, f为频率, F为累积频率. 可以看出,2种算法对直行车辆都有较好的意图预测能力;所提算法在−7.5 m处能对超过73%的转向车辆进行准确的意图预测,但该处LSTM算法准确预测的累积频率仅为20%,在−2.5 m处所提算法的累积频率比LSTM算法的累积频率高19%. 这说明相比于LSTM算法,所提TCN-Transformer算法对转向意图有更早的预测能力且预测准确率更高,原因在于所提算法通过采用更大感受视野的卷积核、多层卷积和自注意力机制等方式处理车辆序列数据的长期依赖关系和局部特征关系,能够更为有效地捕捉转向特征.
图 4

3.2. 完整模型性能分析
3.2.1. 仿真场景构建
式中:
通过调整IDM算法中
图 5
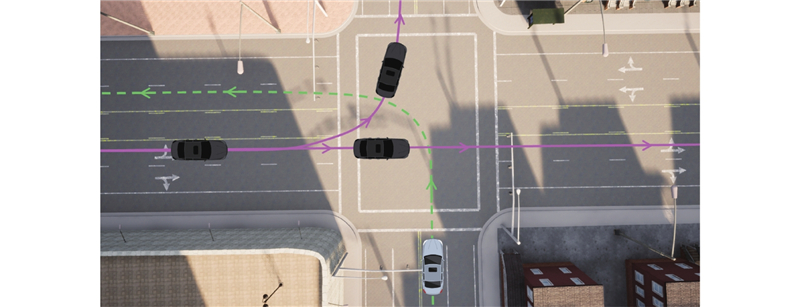
图 5 车辆运动规划算法训练场景
Fig.5 Training scenario of vehicle motion planning algorithms
表 2 TD3模型的超参数设置
Tab.2
| 参数名称 | 数值 |
| 折扣因子 | 0.99 |
| Actor网络学习率 | |
| Critic网络学习率 | |
| 学习率衰减间隔 | 2×104 |
| 批次大小 | 64 |
| 经验池大小 | 3×105 |
| 初始探索概率 | 0.5 |
| 最小探索概率 | 0.05 |
| 探索概率衰减步数 | 2×104 |
| 策略频率 | 2 |
3.2.2. 训练结果
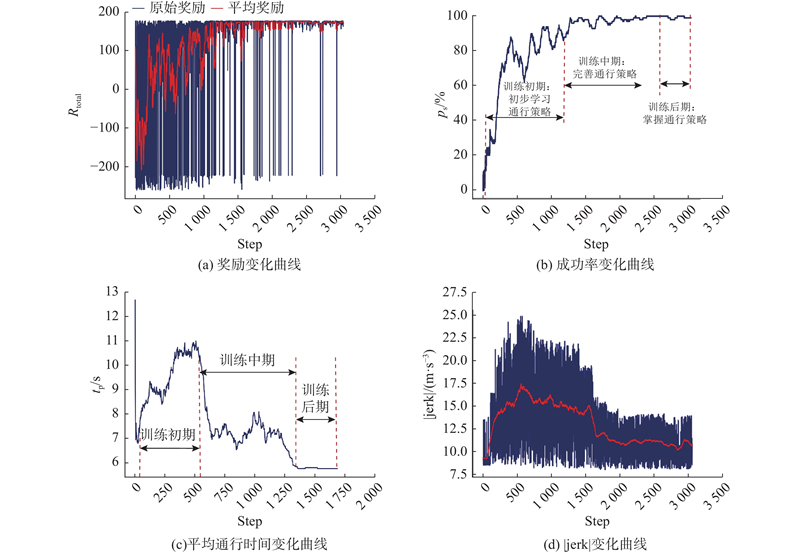
为了初步验证基于TCN-Transformer-TD3算法的智能网联车辆左转运动规划方法性能,共训练
图 6
3.2.3. 算法性能测试
1)定性分析. 为了验证本研究所提算法在安全性、通行效率以及舒适性方面的优势,将所提算法与IDM、TCN-Transformer-DDPG进行对比,其中TCN-Transformer-DDPG与所提算法的状态空间、动作空间和奖励函数均相同. 在测试场景中为周围车辆设置相同的初始速度和驾驶风格 ,生成的运动规划结果如图7所示. 图中,3种曲线分别代表3种算法的规划结果. 可以看出,在早期进入无信号交叉口阶段,采用所提算法和TCN-Transformer-DDPG算法时智能网联车辆均选择提前减速驶近交叉口,而IDM算法此时未选择减速策略,导致行车风险迅速升至高风险状态;在与周围车辆交互阶段,所提算法选择在交叉口处低速通行,当风险值升高时实时调整自车速度平稳通过交叉口,而TCN-Transformer-DDPG算法在风险值升高时出现频繁加减速现象,使得舒适性变差, IDM在高风险状态时选择减速停车让行策略,导致通行时间最长.
图 7
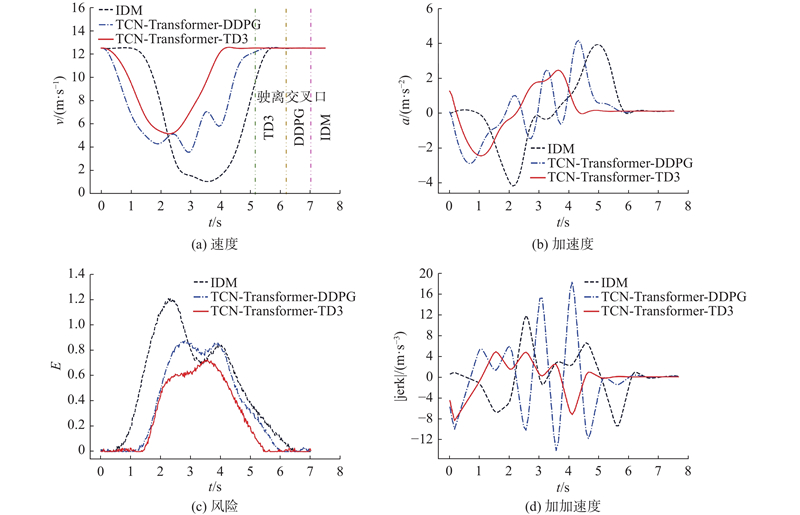
在整个通行过程中,所提算法所用通行时间最短,并且加速度变化更为平稳,风险值和加加速度值始终处于安全奖励和舒适性的要求范围之内且均低于2种对比算法,说明所提算法在通行效率、安全性和舒适性方面均优于其他2种算法的.
2)定量分析. 为了进一步量化分析所提算法性能,在测试场景中对IDM、TCN-Transformer-DDPG 、TD3和所提TCN-Transformer-TD3算法分别进行100个回合的测试,随机设定周围车辆驾驶风格,采用成功率、通行时间、行驶风险最大值以及加加速度绝对值的最大值作为评估指标,测试结果如图8所示. 可以看出:所提算法成功率受周围车辆驾驶风格影响最小,且平均成功率比其他3种算法分别高11%、8%和5%,说明所提算法对不同驾驶风格周围车辆的适应能力更强;所提算法和TD3算法得到的最大风险值位于安全性奖励要求范围内,没有出现风险值大于1的高风险工况,但其他2种算法均多次出现高风险工况;所提算法得到的交叉口通行时间分布区间范围明显小于其他3种算法的;所提算法的加加速度最大值的绝对值的区间范围小于其他3种算法的,且满足驾驶舒适性要求,值越小则舒适性越好. 也就是说,本研究所提算法的安全性、行驶效率以及舒适性均优于其他2种算法的. 原因在于IDM算法主要通过一些固定的规则和先验知识来生成驾驶策略,未考虑环境动态变化的不确定性,无法根据交叉口交通流交互产生的潜在碰撞风险实时动态调整通行策略,导致行驶效率和安全性较差;DDPG算法采用单个目标网络评估策略性能,使得目标网络参数更新慢同时对部分动作价值估值过高,车辆在交叉口处极可能出现不必要的加减速之类的危险行为;不带意图预测模块的TD3算法无法准确判断冲突点,容易产生非最优的车辆通行策略;所提算法根据实时预测得到的周围车辆行驶意图与运动参数信息及时调整通行策略,通过目标策略平滑化和延迟策略更新解决DDPG算法估值过高的问题,从而选择出更优动作,有效降低行驶风险水平并提升决策合理性和驾驶舒适性.
图 8
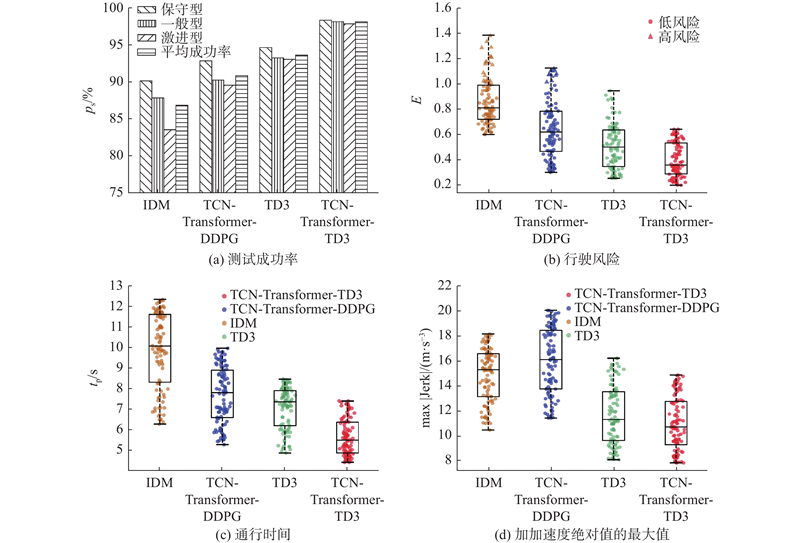
图 8 4种算法定量分析结果对比
Fig.8 Comparison of results of quantitative analysis of four algorithms
3)场景适应性验证. 为了分析所提TCN-Transformer-TD3运动规划算法对复杂场景的适应能力,设计2种不同场景将所提算法与IDM算法、不考虑意图预测的TD3算法、TCN-Transformer-DDPG算法以及LSTM-TD3算法进行对比. 场景1在原测试场景基础上加入自东向南左转交通流,每小时车流量约为
图 9
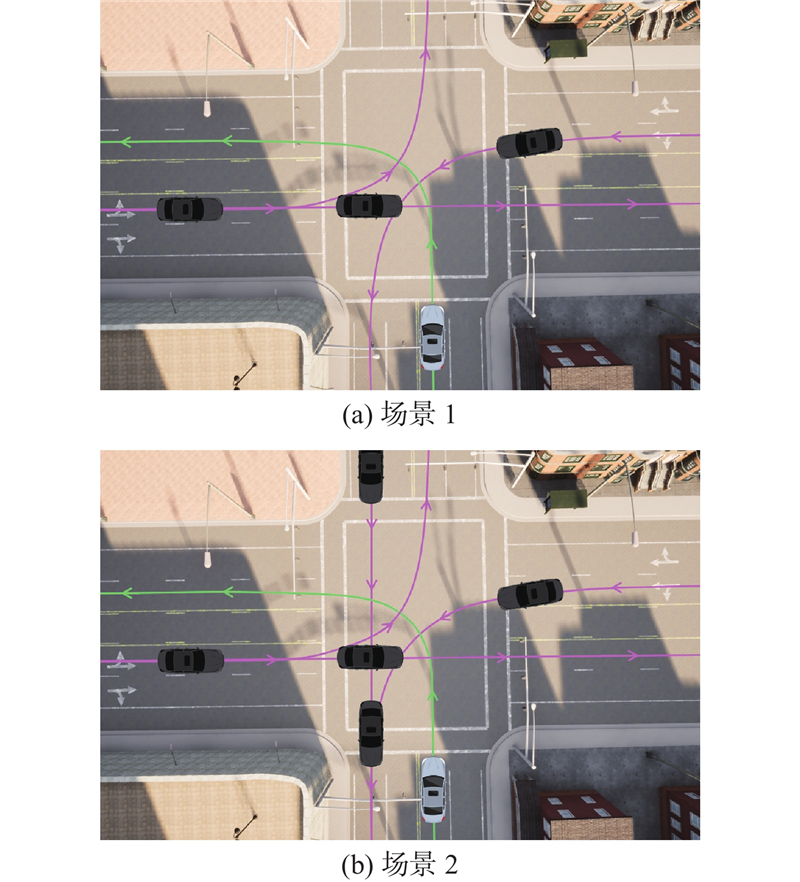
图 9 不同车流方向和车流密度的交叉口场景示意图
Fig.9 Schematic diagram of intersection scenarios with various traffic flow directions and densities
表 3 不同场景下各算法运行成功率和平均通行时间
Tab.3
| 算法 | 场景 | tp/s | Ps/% |
| IDM | 1 | 16.2 | 67.4 |
| 2 | 25.8 | 59.4 | |
| TD3 | 1 | 10.5 | 78.2 |
| 2 | 16.4 | 65.8 | |
| TCN-Transformer-DDPG | 1 | 11.8 | 89.4 |
| 2 | 15.6 | 80.2 | |
| LSTM-TD3 | 1 | 9.1 | 90.2 |
| 2 | 12.6 | 84.8 | |
| TCN-Transformer-TD3 | 1 | 8.3 | 94.2 |
| 2 | 11.4 | 92.1 |
4. 结 语
所提算法能够在周围车辆到达无信号交叉口停止线前准确识别其行驶意图,对直行、右转、左转的意图识别准确率分别为98.1%、96.3%、97.5%. 相比其他算法,通过考虑行车风险、周围车辆转向意图和驾驶风格等信息生成的交叉口最优通行策略所用通行时间最短,整个过程中加速度变化平稳,风险值和加加速度值始终处于安全奖励和舒适性的要求范围之内,能够满足安全性、通行效率和舒适性要求,且对不同车流方向和交通流密度的交叉口交互场景均有良好的适应能力. 该算法目前仅考虑了车间交互影响,今后研究中将进一步探索如何将包括行人和非机动车在内的运动障碍物的影响纳入到通行策略中,以提高智能网联车辆在复杂城市交通环境中的决策能力.
参考文献
A review of surrogate safety measures and their applications in connected and automated vehicles safety modeling
[J].DOI:10.1016/j.aap.2021.106157 [本文引用: 1]
基于Q学习模型的无信号交叉口离散车队控制
[J].
Discrete platoon control at an unsignalized intersection based on Q-learning model
[J].
基于风险预测的自动驾驶车辆行为决策模型
[J].
Decision-making model of autonomous vehicle behavior based on risk prediction
[J].
Enhanced intelligent driver model to access the impact of driving strategies on traffic capacity
[J].DOI:10.1098/rsta.2010.0084 [本文引用: 1]
基于最优速度的弯道跟驰模型及其稳定性分析
[J].
Curve car following model based on optimal velocity and its stability analysis
[J].
移动机器人运动规划中的深度强化学习方法
[J].
Deep reinforcement learning for motion planning of mobile robots
[J].
Deep reinforcement learning for autonomous driving: a survey
[J].
Conditional DQN-based motion planning with fuzzy logic for autonomous driving
[J].
仿驾驶员DDPG汽车纵向自动驾驶决策方法
[J].
A driver-like decision-making method for longitudinal autonomous driving based on DDPG
[J].
基于强化学习的多目标车辆跟随决策算法
[J].
Multi-objective vehicle following decision algorithm based on reinforcement learning
[J].
Continuous decision-making for autonomous driving at intersections using deep deterministic policy gradient
[J].DOI:10.1049/itr2.12107 [本文引用: 1]
基于 TD3 算法的人机混驾交通环境自动驾驶汽车换道研究
[J].DOI:10.3969/j.issn.1001-7372.2021.11.020 [本文引用: 1]
Lane changing of autonomous vehicle based on TD3 algorithm in human-machine hybrid driving environment
[J].DOI:10.3969/j.issn.1001-7372.2021.11.020 [本文引用: 1]
车联网背景下的机动车辆轨迹预测模型
[J].
Vehicle trajectory prediction model in the context of internet of vehicles
[J].
基于人-车-路协同的行车风险场概念, 原理及建模
[J].DOI:10.3969/j.issn.1001-7372.2016.01.014 [本文引用: 1]
Concept, principle and modeling of driving risk field based on driver-vehicle-road interaction
[J].DOI:10.3969/j.issn.1001-7372.2016.01.014 [本文引用: 1]
基于逆向强化学习的纵向自动驾驶决策方法
[J].
Reinforcement learning a decision-making method for longitudinal autonomous driving based on inverse
[J].
考虑交互轨迹预测的自动驾驶运动规划算法
[J].
Motion planning algorithm of autonomous driving considering interactive trajectory prediction
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}