[1]
SHI S, GUO C, JIANG L, et al. PV-RCNN: point-voxel feature set abstraction for 3D object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10526−10535.
[本文引用: 1]
[2]
CHABRA R, LENSSEN J, ILG E, et al. Deep local shapes: learning local SDF priors for detailed 3D reconstruction [C]// Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 608−625.
[本文引用: 1]
[3]
HU W, ZHAO H, JIANG L, et al. Bidirectional projection network for cross dimension scene understanding [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . [s. l.]: IEEE, 2021: 14373−14382.
[本文引用: 1]
[4]
DANG J S, YANG J LHPHGCNN: lightweight hierarchical parallel heterogeneous group convolutional neural networks for point cloud scene prediction
[J]. IEEE Transactions on Intelligent Transportation Systems , 2022 , 23 (10 ): 18903 - 18915
DOI:10.1109/TITS.2022.3167910
[本文引用: 1]
[5]
QI C R, SU H, MO K, et al. PointNet: deep learning on point sets for 3D classification and segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 77−85.
[本文引用: 3]
[6]
QI C R, YI L, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space [C]// Advances in Neural Information Processing Systems. Long Beach: MIT Press, 2017: 5099−5108.
[本文引用: 2]
[7]
LAWIN F J, DANELLJAN M, TOSTEBERG P, et al. Deep projective 3D semantic segmentation [C]// International Conference on Computer Analysis of Images and Patterns . Ystad: Springer, 2017: 95−107.
[本文引用: 1]
[8]
BOULCH A, GUERRY J, SAUX B, et al SnapNet: 3D point cloud semantic labeling with 2D deep segmentation networks
[J]. Computer and Graphics , 2018 , 71 : 189 - 198
DOI:10.1016/j.cag.2017.11.010
[本文引用: 2]
[9]
GUERRY J, BOULCH A, LE S, et al. SnapNet-R: consistent 3D multi-view semantic labeling for robotics [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 669−678.
[本文引用: 1]
[10]
CORTINHAL T, TZELEPIS G, ERDAL E, et al. SalsaNext: fast, uncertainty-aware semantic segmentation of LiDAR point clouds [C]// International Symposium on Visual Computing . San Diego: Springer, 2020: 207−222.
[本文引用: 1]
[11]
ÇICEK O, ABDULKADIR A, LIENKAMP S S, et al. 3D U-Net: learning dense volumetric segmentation from sparse annotation [C]// Medical Image Computing and Computer-Assisted Intervention . Athens: Springer, 2016: 424−432.
[本文引用: 1]
[12]
WANG P S, LIU Y, GUO Y X, et al O-CNN: octree-based convolutional neural networks for 3D shape analysis
[J]. ACM Transactions on Graphics , 2017 , 36 (4 ): 1 - 11
[本文引用: 1]
[13]
MENG H Y, GAO L, LAI Y K, et al. VV-Net: voxel VAE net with group convolutions for point cloud segmentation [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 8499−8507.
[本文引用: 1]
[14]
LE T, DUAN Y. PointGrid: a deep network for 3D shape understanding [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 9204−9214.
[本文引用: 1]
[15]
WANG Y, SUN Y, LIU Z, et al Dynamic graph CNN for learning on point clouds
[J]. ACM Transactions on Graphics , 2018 , 38 (5 ): 146 - 158
[本文引用: 1]
[16]
KANG Z H, LI N PyramNet: point cloud pyramid attention network and graph embedding module for classification and segmentation
[J]. Australian Journal of Intelligent Information Processing Systems , 2019 , 16 (2 ): 35 - 43
[本文引用: 1]
[17]
党吉圣, 杨军 多特征融合的三维模型识别与分割
[J]. 西安电子科技大学学报 , 2020 , 47 (4 ): 149 - 157
[本文引用: 1]
DANG Jisheng, YANG Jun 3D model recognition and segmentation based on multi-feature fusion
[J]. Journal of Xidian University , 2020 , 47 (4 ): 149 - 157
[本文引用: 1]
[18]
HU Q Y, YANG B, XIE L H, et al. RandLA-Net: efficient semantic segmentation of large-scale point clouds [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11105−11114.
[本文引用: 3]
[19]
LIU Z J, TANG H T, LIN Y J, et al. Point-voxel CNN for efficient 3D deep learning [C]// Advances in Neural Information Processing Systems . Vancouver: MIT Press, 2019: 963−973.
[本文引用: 1]
[20]
ZHANG F H, FANG J, WAH B, et al. Deep fusionnet for point cloud semantic segmentation [C]// Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 644−663.
[本文引用: 3]
[21]
LIONG V E, NGUYEN T N T, Widjaja S, et al. AMVNet: assertion-based multi-view fusion network for LiDAR semantic segmentation [EB/OL]. (2020-12-09) [2023-02-12]. https://doi.org/10.48550/arXiv.2012.04934.
[本文引用: 1]
[22]
XU J Y, ZHANG R X, DOU J, et al. RPVNet: a deep and efficient range-point-voxel fusion network for LiDAR point cloud segmentation [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 16004−16013.
[本文引用: 1]
[23]
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// Medical Image Computing and Computer-Assisted Intervention . Munich: Springer, 2015: 234−241.
[本文引用: 1]
[24]
GRAHAM B, ENGELCKE M, MAATEN L. 3D semantic segmentation with submanifold sparse convolutional networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 9224−9232.
[本文引用: 1]
[25]
杨军, 张琛. 融合双注意力机制和动态图卷积神经网络的三维点云语义分割 [EB/OL]. (2023-01-10) [2023-02-12]. https://bhxb.buaa.edu.cn/bhzk/article/doi/10.13700/j.bh.1001-5965.2022.0775.
[本文引用: 1]
[26]
ARMENI I, SENER O, ZAMIR A, et al. 3D semantic parsing of large-scale indoor spaces [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 1534−1543.
[本文引用: 1]
[27]
BEHLEY J, GARBADE M, MILIOTO A, et al. SemanticKITTI: a dataset for semantic scene understanding of LiDAR sequences [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9296−9306.
[本文引用: 1]
[28]
TATARCHENKO M, PARK J, KOLTUN V, et al. Tangent convolutions for dense prediction in 3D [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 3887−3896.
[本文引用: 2]
[29]
LI Y, BU R, SUN M, et al. PointCNN: convolution on x-transformed points [C]// Advances in Neural Information Processing Systems . Montréal: MIT Press, 2018: 828−838.
[本文引用: 1]
[30]
LANDRIEU L, SIMONOVSKY M. Large-scale point cloud semantic segmentation with superpoint graphs [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4558−4567.
[本文引用: 2]
[31]
ZHAO H, JIANG L, FU C W, et al. PointWeb: enhancing local neighborhood features for point cloud processing [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5565−5573.
[本文引用: 1]
[32]
JIANG L, ZHAO H S, LIU S, et al. Hierarchical point-edge interaction network for point cloud semantic segmentation [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 10432−10440.
[本文引用: 1]
[33]
WANG L, HUANG Y, HOU Y, et al. Graph attention convolution for point cloud semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 10296−10305.
[本文引用: 1]
[34]
AHN P, YANG J, YI E, et al Projection-based point convolution for efficient point cloud segmentation
[J]. IEEE Access , 2022 , 10 : 15348 - 15358
DOI:10.1109/ACCESS.2022.3144449
[本文引用: 2]
[35]
SHI Q, SAEED A, NICK B. Semantic segmentation for real point cloud scenes via bilateral augmentation and adaptive fusion [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . [s. l.]: IEEE, 2021: 1757−1767.
[本文引用: 2]
[36]
THOMAS H, QI C R, DESCHAUD J E, et al. KPConv: flexible and deformable convolution for point clouds [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 6410−6419.
[本文引用: 2]
[37]
WEI M, WEI Z, ZHOU H, et al AGConv: adaptive graph convolution on 3D point clouds
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2023 , 45 (8 ): 9374 - 9392
[本文引用: 2]
[38]
SHI H Y, LIN G S, WANG H, et al. SpSequenceNet: semantic segmentation network on 4D point clouds [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 4573–4582.
[本文引用: 1]
[39]
DANG J S, YANG J. HPGCNN: hierarchical parallel group convolutional neural networks for point clouds processing [C]// Proceedings of the Asian Conference on Computer Vision . Kyoto: Springer, 2020: 20−37.
[本文引用: 1]
[40]
MILIOTO A, VIZZO Ⅰ, BEHLEY J, et al. RangeNet++: fast and accurate LiDAR semantic segmentation [C]// IEEE/RSJ International Conference on Intelligent Robots and Systems . Macau: IEEE, 2019: 4213−4220.
[本文引用: 1]
[41]
ZHANG Y, ZHOU Z, DAIID P, et al. PolarNet: an improved grid representation for online LiDAR point clouds semantic segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 9598−9607.
[本文引用: 1]
[42]
ALONSO I, RIAZUELO L, MONTESANO L, et al 3D-MiniNet: learning a 2D representation from point clouds for fast and efficient 3D LiDAR semantic segmentation
[J]. IEEE Robotics and Automation Letters , 2020 , 5 (4 ): 5432 - 5439
DOI:10.1109/LRA.2020.3007440
[本文引用: 1]
[43]
杨军, 李博赞 基于自注意力特征融合组卷积神经网络的三维点云语义分割
[J]. 光学精密工程 , 2022 , 30 (7 ): 840 - 853
DOI:10.37188/OPE.20223007.0840
[本文引用: 1]
YANG Jun, LI Bozan Semantic segmentation of 3D point cloud based on self-attention feature fusion group convolutional neural network
[J]. Optics and Precision Engineering , 2022 , 30 (7 ): 840 - 853
DOI:10.37188/OPE.20223007.0840
[本文引用: 1]
[44]
GERDZHEV M, RAZANI R, TAGHAVI E, et al. Tornado-net: multi-view total variation semantic segmentation with diamond inception module [C]// IEEE International Conference on Robotics and Automation . Xi'an: IEEE, 2021: 9543−9549.
[本文引用: 2]
1
... 近年来,随着三维点云采集设备的不断普及与发展,点云数据的获取变得越来越方便,而三维点云语义分割作为目标检测[1 ] 、三维重建[2 ] 、场景理解[3 ] 等计算机视觉领域的关键技术,更是受到众多国内外研究人员的关注,这也成为三维视觉研究领域的重要课题之一. 与二维图像不同,点云数据具有稀疏、不规则以及无序等性质,使得采用传统方法处理和分析点云十分困难[4 ] . 因此,利用深度学习技术来实现点云的语义分割受到了广泛关注. 然而,从无序的点云中有效地学习特征是一个巨大的挑战. 为了克服点云无序性对特征学习的影响,早期的研究大多集中于将三维点云数据转换为规则的结构表示,例如多视图表示和体素化方法. 基于多视图的方法通过从多个视角将3D形状投影为多个2D视图,然后通过卷积神经网络(convolutional neural networks, CNN)提取每个视图的特征,并通过池化聚合得到最终的语义分割结果. 然而,由于投影视图之间的不连续性,这种方法可能会导致部分特征的丢失. 基于体素的方法将点云转化为规则的体素网格,并使用3D卷积神经网络(3D convolutional neural networks, 3DCNN)进行处理. 然而,体素化会导致计算成本和内存消耗的显著增加. 在体素化过程中,网格越小,点云表示越精细,内存需求就越大. 因此,近年来研究者开始关注以原始点云作为输入的端到端的学习方法. PointNet[5 ] 创新性地以原始点云为输入,采用多层感知机(multilayer perceptron, MLP)来学习每个点特征,并使用最大池化(max pooling)函数聚合所有点,提取全局特征. 然而,该方法在特征提取过程中未能考虑局部邻域信息. 于是Qi等[6 ] 在PointNet基础上引入了分组采样,将新方法命名为PointNet++. 该方法首先对输入点云进行最远点采样(farthest point sampling, FPS),并使用k-近邻(k-nearest neighbor, KNN)算法寻找邻域点进行区域划分,然后在局部区域内应用PointNet进行特征学习与提取. 虽然该网络考虑到了对点云局部特征的提取,但在实验过程中发现,其对于点云边缘部分的分割效果并不理想. ...
1
... 近年来,随着三维点云采集设备的不断普及与发展,点云数据的获取变得越来越方便,而三维点云语义分割作为目标检测[1 ] 、三维重建[2 ] 、场景理解[3 ] 等计算机视觉领域的关键技术,更是受到众多国内外研究人员的关注,这也成为三维视觉研究领域的重要课题之一. 与二维图像不同,点云数据具有稀疏、不规则以及无序等性质,使得采用传统方法处理和分析点云十分困难[4 ] . 因此,利用深度学习技术来实现点云的语义分割受到了广泛关注. 然而,从无序的点云中有效地学习特征是一个巨大的挑战. 为了克服点云无序性对特征学习的影响,早期的研究大多集中于将三维点云数据转换为规则的结构表示,例如多视图表示和体素化方法. 基于多视图的方法通过从多个视角将3D形状投影为多个2D视图,然后通过卷积神经网络(convolutional neural networks, CNN)提取每个视图的特征,并通过池化聚合得到最终的语义分割结果. 然而,由于投影视图之间的不连续性,这种方法可能会导致部分特征的丢失. 基于体素的方法将点云转化为规则的体素网格,并使用3D卷积神经网络(3D convolutional neural networks, 3DCNN)进行处理. 然而,体素化会导致计算成本和内存消耗的显著增加. 在体素化过程中,网格越小,点云表示越精细,内存需求就越大. 因此,近年来研究者开始关注以原始点云作为输入的端到端的学习方法. PointNet[5 ] 创新性地以原始点云为输入,采用多层感知机(multilayer perceptron, MLP)来学习每个点特征,并使用最大池化(max pooling)函数聚合所有点,提取全局特征. 然而,该方法在特征提取过程中未能考虑局部邻域信息. 于是Qi等[6 ] 在PointNet基础上引入了分组采样,将新方法命名为PointNet++. 该方法首先对输入点云进行最远点采样(farthest point sampling, FPS),并使用k-近邻(k-nearest neighbor, KNN)算法寻找邻域点进行区域划分,然后在局部区域内应用PointNet进行特征学习与提取. 虽然该网络考虑到了对点云局部特征的提取,但在实验过程中发现,其对于点云边缘部分的分割效果并不理想. ...
1
... 近年来,随着三维点云采集设备的不断普及与发展,点云数据的获取变得越来越方便,而三维点云语义分割作为目标检测[1 ] 、三维重建[2 ] 、场景理解[3 ] 等计算机视觉领域的关键技术,更是受到众多国内外研究人员的关注,这也成为三维视觉研究领域的重要课题之一. 与二维图像不同,点云数据具有稀疏、不规则以及无序等性质,使得采用传统方法处理和分析点云十分困难[4 ] . 因此,利用深度学习技术来实现点云的语义分割受到了广泛关注. 然而,从无序的点云中有效地学习特征是一个巨大的挑战. 为了克服点云无序性对特征学习的影响,早期的研究大多集中于将三维点云数据转换为规则的结构表示,例如多视图表示和体素化方法. 基于多视图的方法通过从多个视角将3D形状投影为多个2D视图,然后通过卷积神经网络(convolutional neural networks, CNN)提取每个视图的特征,并通过池化聚合得到最终的语义分割结果. 然而,由于投影视图之间的不连续性,这种方法可能会导致部分特征的丢失. 基于体素的方法将点云转化为规则的体素网格,并使用3D卷积神经网络(3D convolutional neural networks, 3DCNN)进行处理. 然而,体素化会导致计算成本和内存消耗的显著增加. 在体素化过程中,网格越小,点云表示越精细,内存需求就越大. 因此,近年来研究者开始关注以原始点云作为输入的端到端的学习方法. PointNet[5 ] 创新性地以原始点云为输入,采用多层感知机(multilayer perceptron, MLP)来学习每个点特征,并使用最大池化(max pooling)函数聚合所有点,提取全局特征. 然而,该方法在特征提取过程中未能考虑局部邻域信息. 于是Qi等[6 ] 在PointNet基础上引入了分组采样,将新方法命名为PointNet++. 该方法首先对输入点云进行最远点采样(farthest point sampling, FPS),并使用k-近邻(k-nearest neighbor, KNN)算法寻找邻域点进行区域划分,然后在局部区域内应用PointNet进行特征学习与提取. 虽然该网络考虑到了对点云局部特征的提取,但在实验过程中发现,其对于点云边缘部分的分割效果并不理想. ...
LHPHGCNN: lightweight hierarchical parallel heterogeneous group convolutional neural networks for point cloud scene prediction
1
2022
... 近年来,随着三维点云采集设备的不断普及与发展,点云数据的获取变得越来越方便,而三维点云语义分割作为目标检测[1 ] 、三维重建[2 ] 、场景理解[3 ] 等计算机视觉领域的关键技术,更是受到众多国内外研究人员的关注,这也成为三维视觉研究领域的重要课题之一. 与二维图像不同,点云数据具有稀疏、不规则以及无序等性质,使得采用传统方法处理和分析点云十分困难[4 ] . 因此,利用深度学习技术来实现点云的语义分割受到了广泛关注. 然而,从无序的点云中有效地学习特征是一个巨大的挑战. 为了克服点云无序性对特征学习的影响,早期的研究大多集中于将三维点云数据转换为规则的结构表示,例如多视图表示和体素化方法. 基于多视图的方法通过从多个视角将3D形状投影为多个2D视图,然后通过卷积神经网络(convolutional neural networks, CNN)提取每个视图的特征,并通过池化聚合得到最终的语义分割结果. 然而,由于投影视图之间的不连续性,这种方法可能会导致部分特征的丢失. 基于体素的方法将点云转化为规则的体素网格,并使用3D卷积神经网络(3D convolutional neural networks, 3DCNN)进行处理. 然而,体素化会导致计算成本和内存消耗的显著增加. 在体素化过程中,网格越小,点云表示越精细,内存需求就越大. 因此,近年来研究者开始关注以原始点云作为输入的端到端的学习方法. PointNet[5 ] 创新性地以原始点云为输入,采用多层感知机(multilayer perceptron, MLP)来学习每个点特征,并使用最大池化(max pooling)函数聚合所有点,提取全局特征. 然而,该方法在特征提取过程中未能考虑局部邻域信息. 于是Qi等[6 ] 在PointNet基础上引入了分组采样,将新方法命名为PointNet++. 该方法首先对输入点云进行最远点采样(farthest point sampling, FPS),并使用k-近邻(k-nearest neighbor, KNN)算法寻找邻域点进行区域划分,然后在局部区域内应用PointNet进行特征学习与提取. 虽然该网络考虑到了对点云局部特征的提取,但在实验过程中发现,其对于点云边缘部分的分割效果并不理想. ...
3
... 近年来,随着三维点云采集设备的不断普及与发展,点云数据的获取变得越来越方便,而三维点云语义分割作为目标检测[1 ] 、三维重建[2 ] 、场景理解[3 ] 等计算机视觉领域的关键技术,更是受到众多国内外研究人员的关注,这也成为三维视觉研究领域的重要课题之一. 与二维图像不同,点云数据具有稀疏、不规则以及无序等性质,使得采用传统方法处理和分析点云十分困难[4 ] . 因此,利用深度学习技术来实现点云的语义分割受到了广泛关注. 然而,从无序的点云中有效地学习特征是一个巨大的挑战. 为了克服点云无序性对特征学习的影响,早期的研究大多集中于将三维点云数据转换为规则的结构表示,例如多视图表示和体素化方法. 基于多视图的方法通过从多个视角将3D形状投影为多个2D视图,然后通过卷积神经网络(convolutional neural networks, CNN)提取每个视图的特征,并通过池化聚合得到最终的语义分割结果. 然而,由于投影视图之间的不连续性,这种方法可能会导致部分特征的丢失. 基于体素的方法将点云转化为规则的体素网格,并使用3D卷积神经网络(3D convolutional neural networks, 3DCNN)进行处理. 然而,体素化会导致计算成本和内存消耗的显著增加. 在体素化过程中,网格越小,点云表示越精细,内存需求就越大. 因此,近年来研究者开始关注以原始点云作为输入的端到端的学习方法. PointNet[5 ] 创新性地以原始点云为输入,采用多层感知机(multilayer perceptron, MLP)来学习每个点特征,并使用最大池化(max pooling)函数聚合所有点,提取全局特征. 然而,该方法在特征提取过程中未能考虑局部邻域信息. 于是Qi等[6 ] 在PointNet基础上引入了分组采样,将新方法命名为PointNet++. 该方法首先对输入点云进行最远点采样(farthest point sampling, FPS),并使用k-近邻(k-nearest neighbor, KNN)算法寻找邻域点进行区域划分,然后在局部区域内应用PointNet进行特征学习与提取. 虽然该网络考虑到了对点云局部特征的提取,但在实验过程中发现,其对于点云边缘部分的分割效果并不理想. ...
... Comparison of segmentation accuracy of different methods on S3DIS dataset (Area 5 as a test)
Tab.1 方法 OA/% mIoU/% IoU/% ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet [5 ] 79.3 41.1 88.8 97.3 69.8 0.1 3.9 46.3 10.8 59.0 52.6 5.9 40.3 26.4 33.2 TangentConv [28 ] 82.5 52.6 90.5 97.7 74.0 0.0 20.7 39.0 31.3 77.5 69.4 57.3 38.5 48.8 39.8 PointCNN [29 ] 85.9 57.3 92.3 98.2 79.4 0.0 17.6 22.8 62.1 74.4 80.6 31.7 66.7 62.1 56.7 SPG [30 ] 86.4 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb [31 ] 87.0 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 HPEIN [32 ] 87.2 61.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 58.5 67.8 65.6 49.4 RandLA-Net [18 ] 87.2 62.4 91.1 95.6 80.2 0.0 24.7 62.3 47.7 76.2 83.7 60.2 71.1 65.7 53.8 GACNet [33 ] 87.8 62.8 92.3 98.3 81.9 0.0 20.3 59.1 40.8 78.5 85.8 61.7 70.7 74.7 52.8 PPCNN++ [34 ] — 64.0 94.0 98.5 83.7 0.0 18.6 66.1 61.7 79.4 88.0 49.5 70.1 66.4 56.1 BAAF-Net [35 ] 88.9 65.4 92.9 97.9 82.3 0.0 23.1 65.5 64.9 78.5 87.5 61.4 70.7 68.7 57.2 KPConv [36 ] — 67.1 92.8 97.3 82.4 0.0 23.9 58.0 69.0 81.5 91.0 75.4 75.3 66.7 58.9 AGConv [37 ] 90.0 67.9 93.9 98.4 82.2 0.0 23.9 59.1 71.3 91.5 81.2 75.5 74.9 72.1 58.6 本研究方法 90.8 69.5 94.4 99.2 87.2 0.0 27.2 62.2 72.8 91.8 85.8 79.0 66.7 74.4 62.9
为了定性分析语义分割结果,对Area 5的测试结果进行了可视化,如图4 所示. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,本研究算法能够充分提取不同室内场景的点云特征,并准确地确定物体的边界范围,在某些场景下得到的分割结果已经较接近真实标签. ...
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
2
... 近年来,随着三维点云采集设备的不断普及与发展,点云数据的获取变得越来越方便,而三维点云语义分割作为目标检测[1 ] 、三维重建[2 ] 、场景理解[3 ] 等计算机视觉领域的关键技术,更是受到众多国内外研究人员的关注,这也成为三维视觉研究领域的重要课题之一. 与二维图像不同,点云数据具有稀疏、不规则以及无序等性质,使得采用传统方法处理和分析点云十分困难[4 ] . 因此,利用深度学习技术来实现点云的语义分割受到了广泛关注. 然而,从无序的点云中有效地学习特征是一个巨大的挑战. 为了克服点云无序性对特征学习的影响,早期的研究大多集中于将三维点云数据转换为规则的结构表示,例如多视图表示和体素化方法. 基于多视图的方法通过从多个视角将3D形状投影为多个2D视图,然后通过卷积神经网络(convolutional neural networks, CNN)提取每个视图的特征,并通过池化聚合得到最终的语义分割结果. 然而,由于投影视图之间的不连续性,这种方法可能会导致部分特征的丢失. 基于体素的方法将点云转化为规则的体素网格,并使用3D卷积神经网络(3D convolutional neural networks, 3DCNN)进行处理. 然而,体素化会导致计算成本和内存消耗的显著增加. 在体素化过程中,网格越小,点云表示越精细,内存需求就越大. 因此,近年来研究者开始关注以原始点云作为输入的端到端的学习方法. PointNet[5 ] 创新性地以原始点云为输入,采用多层感知机(multilayer perceptron, MLP)来学习每个点特征,并使用最大池化(max pooling)函数聚合所有点,提取全局特征. 然而,该方法在特征提取过程中未能考虑局部邻域信息. 于是Qi等[6 ] 在PointNet基础上引入了分组采样,将新方法命名为PointNet++. 该方法首先对输入点云进行最远点采样(farthest point sampling, FPS),并使用k-近邻(k-nearest neighbor, KNN)算法寻找邻域点进行区域划分,然后在局部区域内应用PointNet进行特征学习与提取. 虽然该网络考虑到了对点云局部特征的提取,但在实验过程中发现,其对于点云边缘部分的分割效果并不理想. ...
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
1
... 基于投影的方法通常将三维点云转换为鸟瞰图或前视图等二维图像,借鉴已有的图像分割技术进行处理;然后,通过重投影技术将处理结果转换回点云格式,从而获得点云的预测标签. Lawin等[7 ] 通过多视角投影,将3D点云转为2D图像,利用CNN进行处理. 采用多视角融合方法,提高了分割精度和计算效率,但仍存在视角选择复杂、信息丢失和投影畸变等问题. SnapNet[8 ] 提出将3D点云数据投影到多个2D视图,再利用2D深度分割网络处理特征的思路. 其主要创新是通过2D-3D联合优化,将2D分割结果回投影到3D点云中,以提升语义标注的准确性和效率. 采用现有2D分割技术可以大幅提高计算效率和精度,但视角选择和投影误差可能影响模型训练结果. SnapNet-R[9 ] 在SnapNet[8 ] 的基础上,改善输入图像组合的空间结构匹配差异,直接对RGB-D图像进行处理,实现了图像与点云的密集对应,提升了网络模型的分割精度. SalsaNext[10 ] 提出高效的LiDAR点云语义分割方法,该方法引入了基于图卷积网络(graph convolutional networks, GCN)的注意力机制和不确定性估计,提升模型在处理复杂环境中的鲁棒性和准确性;并且提出了像素混合层(pixel-shuffle layer),提高了分割结果的空间分辨率,但在极端稀疏或高度复杂的点云数据上性能有所下降. 尽管基于投影的方法有会丢失信息的问题,但由于2D语义分割技术的成熟,这些方法仍被广泛使用. ...
SnapNet: 3D point cloud semantic labeling with 2D deep segmentation networks
2
2018
... 基于投影的方法通常将三维点云转换为鸟瞰图或前视图等二维图像,借鉴已有的图像分割技术进行处理;然后,通过重投影技术将处理结果转换回点云格式,从而获得点云的预测标签. Lawin等[7 ] 通过多视角投影,将3D点云转为2D图像,利用CNN进行处理. 采用多视角融合方法,提高了分割精度和计算效率,但仍存在视角选择复杂、信息丢失和投影畸变等问题. SnapNet[8 ] 提出将3D点云数据投影到多个2D视图,再利用2D深度分割网络处理特征的思路. 其主要创新是通过2D-3D联合优化,将2D分割结果回投影到3D点云中,以提升语义标注的准确性和效率. 采用现有2D分割技术可以大幅提高计算效率和精度,但视角选择和投影误差可能影响模型训练结果. SnapNet-R[9 ] 在SnapNet[8 ] 的基础上,改善输入图像组合的空间结构匹配差异,直接对RGB-D图像进行处理,实现了图像与点云的密集对应,提升了网络模型的分割精度. SalsaNext[10 ] 提出高效的LiDAR点云语义分割方法,该方法引入了基于图卷积网络(graph convolutional networks, GCN)的注意力机制和不确定性估计,提升模型在处理复杂环境中的鲁棒性和准确性;并且提出了像素混合层(pixel-shuffle layer),提高了分割结果的空间分辨率,但在极端稀疏或高度复杂的点云数据上性能有所下降. 尽管基于投影的方法有会丢失信息的问题,但由于2D语义分割技术的成熟,这些方法仍被广泛使用. ...
... [8 ]的基础上,改善输入图像组合的空间结构匹配差异,直接对RGB-D图像进行处理,实现了图像与点云的密集对应,提升了网络模型的分割精度. SalsaNext[10 ] 提出高效的LiDAR点云语义分割方法,该方法引入了基于图卷积网络(graph convolutional networks, GCN)的注意力机制和不确定性估计,提升模型在处理复杂环境中的鲁棒性和准确性;并且提出了像素混合层(pixel-shuffle layer),提高了分割结果的空间分辨率,但在极端稀疏或高度复杂的点云数据上性能有所下降. 尽管基于投影的方法有会丢失信息的问题,但由于2D语义分割技术的成熟,这些方法仍被广泛使用. ...
1
... 基于投影的方法通常将三维点云转换为鸟瞰图或前视图等二维图像,借鉴已有的图像分割技术进行处理;然后,通过重投影技术将处理结果转换回点云格式,从而获得点云的预测标签. Lawin等[7 ] 通过多视角投影,将3D点云转为2D图像,利用CNN进行处理. 采用多视角融合方法,提高了分割精度和计算效率,但仍存在视角选择复杂、信息丢失和投影畸变等问题. SnapNet[8 ] 提出将3D点云数据投影到多个2D视图,再利用2D深度分割网络处理特征的思路. 其主要创新是通过2D-3D联合优化,将2D分割结果回投影到3D点云中,以提升语义标注的准确性和效率. 采用现有2D分割技术可以大幅提高计算效率和精度,但视角选择和投影误差可能影响模型训练结果. SnapNet-R[9 ] 在SnapNet[8 ] 的基础上,改善输入图像组合的空间结构匹配差异,直接对RGB-D图像进行处理,实现了图像与点云的密集对应,提升了网络模型的分割精度. SalsaNext[10 ] 提出高效的LiDAR点云语义分割方法,该方法引入了基于图卷积网络(graph convolutional networks, GCN)的注意力机制和不确定性估计,提升模型在处理复杂环境中的鲁棒性和准确性;并且提出了像素混合层(pixel-shuffle layer),提高了分割结果的空间分辨率,但在极端稀疏或高度复杂的点云数据上性能有所下降. 尽管基于投影的方法有会丢失信息的问题,但由于2D语义分割技术的成熟,这些方法仍被广泛使用. ...
1
... 基于投影的方法通常将三维点云转换为鸟瞰图或前视图等二维图像,借鉴已有的图像分割技术进行处理;然后,通过重投影技术将处理结果转换回点云格式,从而获得点云的预测标签. Lawin等[7 ] 通过多视角投影,将3D点云转为2D图像,利用CNN进行处理. 采用多视角融合方法,提高了分割精度和计算效率,但仍存在视角选择复杂、信息丢失和投影畸变等问题. SnapNet[8 ] 提出将3D点云数据投影到多个2D视图,再利用2D深度分割网络处理特征的思路. 其主要创新是通过2D-3D联合优化,将2D分割结果回投影到3D点云中,以提升语义标注的准确性和效率. 采用现有2D分割技术可以大幅提高计算效率和精度,但视角选择和投影误差可能影响模型训练结果. SnapNet-R[9 ] 在SnapNet[8 ] 的基础上,改善输入图像组合的空间结构匹配差异,直接对RGB-D图像进行处理,实现了图像与点云的密集对应,提升了网络模型的分割精度. SalsaNext[10 ] 提出高效的LiDAR点云语义分割方法,该方法引入了基于图卷积网络(graph convolutional networks, GCN)的注意力机制和不确定性估计,提升模型在处理复杂环境中的鲁棒性和准确性;并且提出了像素混合层(pixel-shuffle layer),提高了分割结果的空间分辨率,但在极端稀疏或高度复杂的点云数据上性能有所下降. 尽管基于投影的方法有会丢失信息的问题,但由于2D语义分割技术的成熟,这些方法仍被广泛使用. ...
1
... 体素化方法通过将点云转化为体素表示,使复杂的点云结构可以被标准3D卷积神经网络有效地分割和解析,从而有效提高点云处理效率和精度. 3D U-Net[11 ] 提出适用于3D数据的U型网络结构,其使用全三维卷积网络(Fully-3D CNN)对体素进行特征学习,为每个体素赋予语义标签,但其性能受限于体素分辨率与边界处点云划分的不确定性. Wang等[12 ] 提出基于八叉树的卷积神经网络(octree-based convolutional neural networks, O-CNN),用于3D形状分析. 该方法利用八叉树高效地表示、处理稀疏的3D数据,实现了多分辨率层次上的卷积操作. 相比于3D U-Net,O-CNN大幅降低了计算、存储成本. 但八叉树构建过程复杂,并且在处理极度不规则的点云数据时仍面临挑战. 为了捕获体素内稀疏分布的点,Meng等[13 ] 提出结合体素变分自编码器(Voxel VAE)和组卷积(group convolutions)的方法VV-Net. 该方法先利用变分自编码器进行体素表示学习,然后通过组卷积提高了网络的计算效率和特征提取能力. VV-Net具备高效的特征学习能力,能减少计算复杂度和提高分割精度. Le等[14 ] 提出将点云和体素网格相结合的深度网络方法(PointGrid). PointGrid将点云数据嵌入到体素网格中,利用卷积神经网络学习点云的精细结构和体素的空间信息. 该方法有效整合了点云和体素的优势,能提供更精细的3D形状表示. 上述方法在体素化之后仍使用常规的三维卷积,不可避免地带来高计算量和内存消耗的问题. ...
O-CNN: octree-based convolutional neural networks for 3D shape analysis
1
2017
... 体素化方法通过将点云转化为体素表示,使复杂的点云结构可以被标准3D卷积神经网络有效地分割和解析,从而有效提高点云处理效率和精度. 3D U-Net[11 ] 提出适用于3D数据的U型网络结构,其使用全三维卷积网络(Fully-3D CNN)对体素进行特征学习,为每个体素赋予语义标签,但其性能受限于体素分辨率与边界处点云划分的不确定性. Wang等[12 ] 提出基于八叉树的卷积神经网络(octree-based convolutional neural networks, O-CNN),用于3D形状分析. 该方法利用八叉树高效地表示、处理稀疏的3D数据,实现了多分辨率层次上的卷积操作. 相比于3D U-Net,O-CNN大幅降低了计算、存储成本. 但八叉树构建过程复杂,并且在处理极度不规则的点云数据时仍面临挑战. 为了捕获体素内稀疏分布的点,Meng等[13 ] 提出结合体素变分自编码器(Voxel VAE)和组卷积(group convolutions)的方法VV-Net. 该方法先利用变分自编码器进行体素表示学习,然后通过组卷积提高了网络的计算效率和特征提取能力. VV-Net具备高效的特征学习能力,能减少计算复杂度和提高分割精度. Le等[14 ] 提出将点云和体素网格相结合的深度网络方法(PointGrid). PointGrid将点云数据嵌入到体素网格中,利用卷积神经网络学习点云的精细结构和体素的空间信息. 该方法有效整合了点云和体素的优势,能提供更精细的3D形状表示. 上述方法在体素化之后仍使用常规的三维卷积,不可避免地带来高计算量和内存消耗的问题. ...
1
... 体素化方法通过将点云转化为体素表示,使复杂的点云结构可以被标准3D卷积神经网络有效地分割和解析,从而有效提高点云处理效率和精度. 3D U-Net[11 ] 提出适用于3D数据的U型网络结构,其使用全三维卷积网络(Fully-3D CNN)对体素进行特征学习,为每个体素赋予语义标签,但其性能受限于体素分辨率与边界处点云划分的不确定性. Wang等[12 ] 提出基于八叉树的卷积神经网络(octree-based convolutional neural networks, O-CNN),用于3D形状分析. 该方法利用八叉树高效地表示、处理稀疏的3D数据,实现了多分辨率层次上的卷积操作. 相比于3D U-Net,O-CNN大幅降低了计算、存储成本. 但八叉树构建过程复杂,并且在处理极度不规则的点云数据时仍面临挑战. 为了捕获体素内稀疏分布的点,Meng等[13 ] 提出结合体素变分自编码器(Voxel VAE)和组卷积(group convolutions)的方法VV-Net. 该方法先利用变分自编码器进行体素表示学习,然后通过组卷积提高了网络的计算效率和特征提取能力. VV-Net具备高效的特征学习能力,能减少计算复杂度和提高分割精度. Le等[14 ] 提出将点云和体素网格相结合的深度网络方法(PointGrid). PointGrid将点云数据嵌入到体素网格中,利用卷积神经网络学习点云的精细结构和体素的空间信息. 该方法有效整合了点云和体素的优势,能提供更精细的3D形状表示. 上述方法在体素化之后仍使用常规的三维卷积,不可避免地带来高计算量和内存消耗的问题. ...
1
... 体素化方法通过将点云转化为体素表示,使复杂的点云结构可以被标准3D卷积神经网络有效地分割和解析,从而有效提高点云处理效率和精度. 3D U-Net[11 ] 提出适用于3D数据的U型网络结构,其使用全三维卷积网络(Fully-3D CNN)对体素进行特征学习,为每个体素赋予语义标签,但其性能受限于体素分辨率与边界处点云划分的不确定性. Wang等[12 ] 提出基于八叉树的卷积神经网络(octree-based convolutional neural networks, O-CNN),用于3D形状分析. 该方法利用八叉树高效地表示、处理稀疏的3D数据,实现了多分辨率层次上的卷积操作. 相比于3D U-Net,O-CNN大幅降低了计算、存储成本. 但八叉树构建过程复杂,并且在处理极度不规则的点云数据时仍面临挑战. 为了捕获体素内稀疏分布的点,Meng等[13 ] 提出结合体素变分自编码器(Voxel VAE)和组卷积(group convolutions)的方法VV-Net. 该方法先利用变分自编码器进行体素表示学习,然后通过组卷积提高了网络的计算效率和特征提取能力. VV-Net具备高效的特征学习能力,能减少计算复杂度和提高分割精度. Le等[14 ] 提出将点云和体素网格相结合的深度网络方法(PointGrid). PointGrid将点云数据嵌入到体素网格中,利用卷积神经网络学习点云的精细结构和体素的空间信息. 该方法有效整合了点云和体素的优势,能提供更精细的3D形状表示. 上述方法在体素化之后仍使用常规的三维卷积,不可避免地带来高计算量和内存消耗的问题. ...
Dynamic graph CNN for learning on point clouds
1
2018
... 基于点云的方法直接对不规则点云进行处理. Wang等[15 ] 提出动态图卷积神经网络(dynamic graph CNN, DGCNN),将点云数据表示为动态图结构,通过自适应地构建和更新图,使网络能够有效地捕捉点云的局部和全局特征. 这有效解决了不同大小和密度的点云数据处理问题,能提供高度灵活性和可扩展性,并且对几何变换具有鲁棒性,但该方法需要额外的计算资源用于动态图构建和更新. Kang等[16 ] 采用金字塔结构的注意力机制,以多尺度方式捕捉点云的局部、全局特征,并结合图嵌入模块进行特征聚合和表示学习. 该方法使用金字塔注意力模块,能够高效地处理多尺度信息,并提高特征表达能力和分割精度. 为此,党吉圣等[17 ] 提出多特征融合的三维模型识别与分割方法,解决了忽略高级全局单点特征和低级局部几何特征关系的问题. 该方法通过增加卷积核宽度和网络深度构建全局单点网络;同时,利用注意力融合层学习全局单点特征与局部几何特征之间的隐含关系,实现充分挖掘细粒度几何特征的目的. 虽然该方法提高了识别和分割效果,但模型复杂度较高,在处理大规模数据时可能存在瓶颈. 为了解决大规模点云采样的问题,Hu等[18 ] 提出高效的语义分割方法(RandLA-Net),该方法采用随机点采样策略和轻量级的局部特征聚合模块,通过逐层减少点云密度并保留重要特征,提高处理大规模点云的效率和精度. ...
PyramNet: point cloud pyramid attention network and graph embedding module for classification and segmentation
1
2019
... 基于点云的方法直接对不规则点云进行处理. Wang等[15 ] 提出动态图卷积神经网络(dynamic graph CNN, DGCNN),将点云数据表示为动态图结构,通过自适应地构建和更新图,使网络能够有效地捕捉点云的局部和全局特征. 这有效解决了不同大小和密度的点云数据处理问题,能提供高度灵活性和可扩展性,并且对几何变换具有鲁棒性,但该方法需要额外的计算资源用于动态图构建和更新. Kang等[16 ] 采用金字塔结构的注意力机制,以多尺度方式捕捉点云的局部、全局特征,并结合图嵌入模块进行特征聚合和表示学习. 该方法使用金字塔注意力模块,能够高效地处理多尺度信息,并提高特征表达能力和分割精度. 为此,党吉圣等[17 ] 提出多特征融合的三维模型识别与分割方法,解决了忽略高级全局单点特征和低级局部几何特征关系的问题. 该方法通过增加卷积核宽度和网络深度构建全局单点网络;同时,利用注意力融合层学习全局单点特征与局部几何特征之间的隐含关系,实现充分挖掘细粒度几何特征的目的. 虽然该方法提高了识别和分割效果,但模型复杂度较高,在处理大规模数据时可能存在瓶颈. 为了解决大规模点云采样的问题,Hu等[18 ] 提出高效的语义分割方法(RandLA-Net),该方法采用随机点采样策略和轻量级的局部特征聚合模块,通过逐层减少点云密度并保留重要特征,提高处理大规模点云的效率和精度. ...
多特征融合的三维模型识别与分割
1
2020
... 基于点云的方法直接对不规则点云进行处理. Wang等[15 ] 提出动态图卷积神经网络(dynamic graph CNN, DGCNN),将点云数据表示为动态图结构,通过自适应地构建和更新图,使网络能够有效地捕捉点云的局部和全局特征. 这有效解决了不同大小和密度的点云数据处理问题,能提供高度灵活性和可扩展性,并且对几何变换具有鲁棒性,但该方法需要额外的计算资源用于动态图构建和更新. Kang等[16 ] 采用金字塔结构的注意力机制,以多尺度方式捕捉点云的局部、全局特征,并结合图嵌入模块进行特征聚合和表示学习. 该方法使用金字塔注意力模块,能够高效地处理多尺度信息,并提高特征表达能力和分割精度. 为此,党吉圣等[17 ] 提出多特征融合的三维模型识别与分割方法,解决了忽略高级全局单点特征和低级局部几何特征关系的问题. 该方法通过增加卷积核宽度和网络深度构建全局单点网络;同时,利用注意力融合层学习全局单点特征与局部几何特征之间的隐含关系,实现充分挖掘细粒度几何特征的目的. 虽然该方法提高了识别和分割效果,但模型复杂度较高,在处理大规模数据时可能存在瓶颈. 为了解决大规模点云采样的问题,Hu等[18 ] 提出高效的语义分割方法(RandLA-Net),该方法采用随机点采样策略和轻量级的局部特征聚合模块,通过逐层减少点云密度并保留重要特征,提高处理大规模点云的效率和精度. ...
多特征融合的三维模型识别与分割
1
2020
... 基于点云的方法直接对不规则点云进行处理. Wang等[15 ] 提出动态图卷积神经网络(dynamic graph CNN, DGCNN),将点云数据表示为动态图结构,通过自适应地构建和更新图,使网络能够有效地捕捉点云的局部和全局特征. 这有效解决了不同大小和密度的点云数据处理问题,能提供高度灵活性和可扩展性,并且对几何变换具有鲁棒性,但该方法需要额外的计算资源用于动态图构建和更新. Kang等[16 ] 采用金字塔结构的注意力机制,以多尺度方式捕捉点云的局部、全局特征,并结合图嵌入模块进行特征聚合和表示学习. 该方法使用金字塔注意力模块,能够高效地处理多尺度信息,并提高特征表达能力和分割精度. 为此,党吉圣等[17 ] 提出多特征融合的三维模型识别与分割方法,解决了忽略高级全局单点特征和低级局部几何特征关系的问题. 该方法通过增加卷积核宽度和网络深度构建全局单点网络;同时,利用注意力融合层学习全局单点特征与局部几何特征之间的隐含关系,实现充分挖掘细粒度几何特征的目的. 虽然该方法提高了识别和分割效果,但模型复杂度较高,在处理大规模数据时可能存在瓶颈. 为了解决大规模点云采样的问题,Hu等[18 ] 提出高效的语义分割方法(RandLA-Net),该方法采用随机点采样策略和轻量级的局部特征聚合模块,通过逐层减少点云密度并保留重要特征,提高处理大规模点云的效率和精度. ...
3
... 基于点云的方法直接对不规则点云进行处理. Wang等[15 ] 提出动态图卷积神经网络(dynamic graph CNN, DGCNN),将点云数据表示为动态图结构,通过自适应地构建和更新图,使网络能够有效地捕捉点云的局部和全局特征. 这有效解决了不同大小和密度的点云数据处理问题,能提供高度灵活性和可扩展性,并且对几何变换具有鲁棒性,但该方法需要额外的计算资源用于动态图构建和更新. Kang等[16 ] 采用金字塔结构的注意力机制,以多尺度方式捕捉点云的局部、全局特征,并结合图嵌入模块进行特征聚合和表示学习. 该方法使用金字塔注意力模块,能够高效地处理多尺度信息,并提高特征表达能力和分割精度. 为此,党吉圣等[17 ] 提出多特征融合的三维模型识别与分割方法,解决了忽略高级全局单点特征和低级局部几何特征关系的问题. 该方法通过增加卷积核宽度和网络深度构建全局单点网络;同时,利用注意力融合层学习全局单点特征与局部几何特征之间的隐含关系,实现充分挖掘细粒度几何特征的目的. 虽然该方法提高了识别和分割效果,但模型复杂度较高,在处理大规模数据时可能存在瓶颈. 为了解决大规模点云采样的问题,Hu等[18 ] 提出高效的语义分割方法(RandLA-Net),该方法采用随机点采样策略和轻量级的局部特征聚合模块,通过逐层减少点云密度并保留重要特征,提高处理大规模点云的效率和精度. ...
... Comparison of segmentation accuracy of different methods on S3DIS dataset (Area 5 as a test)
Tab.1 方法 OA/% mIoU/% IoU/% ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet [5 ] 79.3 41.1 88.8 97.3 69.8 0.1 3.9 46.3 10.8 59.0 52.6 5.9 40.3 26.4 33.2 TangentConv [28 ] 82.5 52.6 90.5 97.7 74.0 0.0 20.7 39.0 31.3 77.5 69.4 57.3 38.5 48.8 39.8 PointCNN [29 ] 85.9 57.3 92.3 98.2 79.4 0.0 17.6 22.8 62.1 74.4 80.6 31.7 66.7 62.1 56.7 SPG [30 ] 86.4 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb [31 ] 87.0 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 HPEIN [32 ] 87.2 61.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 58.5 67.8 65.6 49.4 RandLA-Net [18 ] 87.2 62.4 91.1 95.6 80.2 0.0 24.7 62.3 47.7 76.2 83.7 60.2 71.1 65.7 53.8 GACNet [33 ] 87.8 62.8 92.3 98.3 81.9 0.0 20.3 59.1 40.8 78.5 85.8 61.7 70.7 74.7 52.8 PPCNN++ [34 ] — 64.0 94.0 98.5 83.7 0.0 18.6 66.1 61.7 79.4 88.0 49.5 70.1 66.4 56.1 BAAF-Net [35 ] 88.9 65.4 92.9 97.9 82.3 0.0 23.1 65.5 64.9 78.5 87.5 61.4 70.7 68.7 57.2 KPConv [36 ] — 67.1 92.8 97.3 82.4 0.0 23.9 58.0 69.0 81.5 91.0 75.4 75.3 66.7 58.9 AGConv [37 ] 90.0 67.9 93.9 98.4 82.2 0.0 23.9 59.1 71.3 91.5 81.2 75.5 74.9 72.1 58.6 本研究方法 90.8 69.5 94.4 99.2 87.2 0.0 27.2 62.2 72.8 91.8 85.8 79.0 66.7 74.4 62.9
为了定性分析语义分割结果,对Area 5的测试结果进行了可视化,如图4 所示. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,本研究算法能够充分提取不同室内场景的点云特征,并准确地确定物体的边界范围,在某些场景下得到的分割结果已经较接近真实标签. ...
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
1
... 一些学者结合以上2种或几种方法提出多模态融合的网络对点云进行语义分割. Liu等[19 ] 将基于点的方法和基于体素的方法相结合,提出点体素卷积模块,在低分辨率体素中执行三维卷积来捕获点云的上下文特征,同时使用简单的MLP来提取逐点特征,最后将这2种特征结合起来,使网络具有较小的内存占用和良好的数据局部性、规律性等优点,但低分辨率的体素难免会导致丢失一些小物体信息. Zhang等[20 ] 提出深度融合网络架构(FusionNet),包括一个独特的基于体素的“mini-PointNet”点云表示模块和一个用于大规模3D语义分割的新特征聚合模块. 通过聚合邻域体素和对应点之间的特征,减少了邻域搜索的时间消耗,对于大规模点云分割结果有所提升. Liong等[21 ] 设计了一种融合方法,通过分别计算范围视图(range view, RV)和鸟瞰视图(bird’s eye view, BEV)2个不同视图输出的单独点标签,并使用PointNet网络来优化2个分支产生的不确定预测结果. Xu等[22 ] 分别提取深度图、点、体素的特征,并将3个分支得到的差异性特征通过哈希映射进行自适应交互融合,并将融合后的结果输入到编码器-解码器结构进行语义标签预测,显著提高了分割精度. ...
3
... 一些学者结合以上2种或几种方法提出多模态融合的网络对点云进行语义分割. Liu等[19 ] 将基于点的方法和基于体素的方法相结合,提出点体素卷积模块,在低分辨率体素中执行三维卷积来捕获点云的上下文特征,同时使用简单的MLP来提取逐点特征,最后将这2种特征结合起来,使网络具有较小的内存占用和良好的数据局部性、规律性等优点,但低分辨率的体素难免会导致丢失一些小物体信息. Zhang等[20 ] 提出深度融合网络架构(FusionNet),包括一个独特的基于体素的“mini-PointNet”点云表示模块和一个用于大规模3D语义分割的新特征聚合模块. 通过聚合邻域体素和对应点之间的特征,减少了邻域搜索的时间消耗,对于大规模点云分割结果有所提升. Liong等[21 ] 设计了一种融合方法,通过分别计算范围视图(range view, RV)和鸟瞰视图(bird’s eye view, BEV)2个不同视图输出的单独点标签,并使用PointNet网络来优化2个分支产生的不确定预测结果. Xu等[22 ] 分别提取深度图、点、体素的特征,并将3个分支得到的差异性特征通过哈希映射进行自适应交互融合,并将融合后的结果输入到编码器-解码器结构进行语义标签预测,显著提高了分割精度. ...
... SemanticKITTI数据集包含德国卡尔斯鲁厄附近的市内交通、居民区、高速公路场景和乡村道路场景,是目前最大的汽车激光雷达点云数据集. 该数据集由22个点云序列组成,00~07、09~10序列作为训练集,08序列作为验证集并生成可视化结果,一共包含23201帧3D点云场景;11~21序列作为测试集,一共包含20351帧3D点云场景. 训练集中每点都有自己的标签,人为进行了语义标注,共有19种类别标签. 如表2 所示为本研究方法在SemanticKITTI数据集上与目前主流方法的场景语义分割定量结果的对比. 可以看出,本研究算法的mIoU为62.7%,超过了同为点云与体素融合的方法FusionNet[20 ] ,并且在其中7个类别上取得了最好的分割结果. FusionNet只考虑将点云与体素的方法相结合,忽略了对边界信息的处理,而本研究提出了边界点估计模块用来预测可能的边界点,并在局部特征提取中对邻域点的特征进行有选择的聚合. TORNADONet算法[44 ] 融合了2种基于投影的方法进行语义分割,然而在投影过程中,点云原有的拓扑结构不可避免地会丢失或改变,导致基于投影的方法无法完整地对几何信息进行建模. 而本研究算法通过对点云进行体素化并使用稀疏卷积,解决了点云稀疏分布的问题,也能通过体素分支提取到感受野更大的上下文特征. ...
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
1
... 一些学者结合以上2种或几种方法提出多模态融合的网络对点云进行语义分割. Liu等[19 ] 将基于点的方法和基于体素的方法相结合,提出点体素卷积模块,在低分辨率体素中执行三维卷积来捕获点云的上下文特征,同时使用简单的MLP来提取逐点特征,最后将这2种特征结合起来,使网络具有较小的内存占用和良好的数据局部性、规律性等优点,但低分辨率的体素难免会导致丢失一些小物体信息. Zhang等[20 ] 提出深度融合网络架构(FusionNet),包括一个独特的基于体素的“mini-PointNet”点云表示模块和一个用于大规模3D语义分割的新特征聚合模块. 通过聚合邻域体素和对应点之间的特征,减少了邻域搜索的时间消耗,对于大规模点云分割结果有所提升. Liong等[21 ] 设计了一种融合方法,通过分别计算范围视图(range view, RV)和鸟瞰视图(bird’s eye view, BEV)2个不同视图输出的单独点标签,并使用PointNet网络来优化2个分支产生的不确定预测结果. Xu等[22 ] 分别提取深度图、点、体素的特征,并将3个分支得到的差异性特征通过哈希映射进行自适应交互融合,并将融合后的结果输入到编码器-解码器结构进行语义标签预测,显著提高了分割精度. ...
1
... 一些学者结合以上2种或几种方法提出多模态融合的网络对点云进行语义分割. Liu等[19 ] 将基于点的方法和基于体素的方法相结合,提出点体素卷积模块,在低分辨率体素中执行三维卷积来捕获点云的上下文特征,同时使用简单的MLP来提取逐点特征,最后将这2种特征结合起来,使网络具有较小的内存占用和良好的数据局部性、规律性等优点,但低分辨率的体素难免会导致丢失一些小物体信息. Zhang等[20 ] 提出深度融合网络架构(FusionNet),包括一个独特的基于体素的“mini-PointNet”点云表示模块和一个用于大规模3D语义分割的新特征聚合模块. 通过聚合邻域体素和对应点之间的特征,减少了邻域搜索的时间消耗,对于大规模点云分割结果有所提升. Liong等[21 ] 设计了一种融合方法,通过分别计算范围视图(range view, RV)和鸟瞰视图(bird’s eye view, BEV)2个不同视图输出的单独点标签,并使用PointNet网络来优化2个分支产生的不确定预测结果. Xu等[22 ] 分别提取深度图、点、体素的特征,并将3个分支得到的差异性特征通过哈希映射进行自适应交互融合,并将融合后的结果输入到编码器-解码器结构进行语义标签预测,显著提高了分割精度. ...
1
... 本研究构建的基于边界点估计与稀疏卷积神经网络的三维点云语义分割网络架构主要由体素分支和点分支2部分组成,网络结构如图1 所示. 体素分支主要包括:体素化(Voxelize)、稀疏卷积(Sparse Convolution)和解体素化(Devoxelize). 点分支主要包括:边界点估计(boundary point estimation, BPE)模块、改进的边缘卷积(EdgeConv++)模块、空间注意力机制(spatial attention mechanism, SAM)模块和通道注意力机制(channel attention mechanism, CAM)模块. 首先将原始点云进行体素化,将体素化后的点云数据输入到U-Net[23 ] 特征提取网络中经过稀疏卷积得到场景的语义信息,然后进行解体素化得到每个点的语义信息,再将每个点的语义标签输入到BPE模块中得到预测的边界点. 在通过EdgeConv++模块提取局部邻域特征时,如果中心点的邻域点中包含边界点,那么将舍弃掉相应的邻域点特征,从而避免属于不同类别的局部特征相互污染,然后依次经过SAM和CAM模块对得到的局部特征进行增强,最后将点分支得到的局部特征与体素分支得到的上下文特征相融合,产生最终的三维点云语义分割结果. ...
1
... 由于点云数据的稀疏性,将点云体素化会产生大量空体素,采用常规的三维卷积直接进行特征学习容易浪费大量硬件资源,而降低体素分辨率又会导致丢失部分小物体的细节信息. 受文献[24 ]的启发,本研究引入稀疏卷积替代常规三维卷积用来提取体素特征,从而在使用高分辨率体素进行卷积运算时减少不必要的内存消耗. 稀疏卷积本质上还是卷积操作,但具体的计算过程与普通卷积有较大的不同. 在稀疏卷积神经网络中,只有当卷积核的中心对应的点为非空时,才进行卷积运算,这样便保证了进行步长为1的稀疏卷积在运算时不会使非空白点数增加. ...
1
... 通过将本研究提出的BPE模块与文献[25 ]中的EdgeConv++模块、SAM模块和CAM模块相结合进行局部特征提取. 在聚合局部特征时,只允许在每个对象区域内共享信息,防止特征跨边界传播. 局部特征可以提供更多的细节信息,但混合不同类别的局部特征肯定会破坏这些细节信息,为此,本研究采取的具体做法如下. ...
1
... 为了评估所构建的基于边界点估计与稀疏卷积神经网络的三维点云语义分割模型的有效性,选用流行的大规模室内场景数据集S3DIS[26 ] 和大规模室外场景数据集SemanticKITTI[27 ] 进行实验. 评估指标采用总体准确率(overall accuracy, OA)和平均交并比(mean intersection-over-union, mIoU). ...
1
... 为了评估所构建的基于边界点估计与稀疏卷积神经网络的三维点云语义分割模型的有效性,选用流行的大规模室内场景数据集S3DIS[26 ] 和大规模室外场景数据集SemanticKITTI[27 ] 进行实验. 评估指标采用总体准确率(overall accuracy, OA)和平均交并比(mean intersection-over-union, mIoU). ...
2
... Comparison of segmentation accuracy of different methods on S3DIS dataset (Area 5 as a test)
Tab.1 方法 OA/% mIoU/% IoU/% ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet [5 ] 79.3 41.1 88.8 97.3 69.8 0.1 3.9 46.3 10.8 59.0 52.6 5.9 40.3 26.4 33.2 TangentConv [28 ] 82.5 52.6 90.5 97.7 74.0 0.0 20.7 39.0 31.3 77.5 69.4 57.3 38.5 48.8 39.8 PointCNN [29 ] 85.9 57.3 92.3 98.2 79.4 0.0 17.6 22.8 62.1 74.4 80.6 31.7 66.7 62.1 56.7 SPG [30 ] 86.4 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb [31 ] 87.0 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 HPEIN [32 ] 87.2 61.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 58.5 67.8 65.6 49.4 RandLA-Net [18 ] 87.2 62.4 91.1 95.6 80.2 0.0 24.7 62.3 47.7 76.2 83.7 60.2 71.1 65.7 53.8 GACNet [33 ] 87.8 62.8 92.3 98.3 81.9 0.0 20.3 59.1 40.8 78.5 85.8 61.7 70.7 74.7 52.8 PPCNN++ [34 ] — 64.0 94.0 98.5 83.7 0.0 18.6 66.1 61.7 79.4 88.0 49.5 70.1 66.4 56.1 BAAF-Net [35 ] 88.9 65.4 92.9 97.9 82.3 0.0 23.1 65.5 64.9 78.5 87.5 61.4 70.7 68.7 57.2 KPConv [36 ] — 67.1 92.8 97.3 82.4 0.0 23.9 58.0 69.0 81.5 91.0 75.4 75.3 66.7 58.9 AGConv [37 ] 90.0 67.9 93.9 98.4 82.2 0.0 23.9 59.1 71.3 91.5 81.2 75.5 74.9 72.1 58.6 本研究方法 90.8 69.5 94.4 99.2 87.2 0.0 27.2 62.2 72.8 91.8 85.8 79.0 66.7 74.4 62.9
为了定性分析语义分割结果,对Area 5的测试结果进行了可视化,如图4 所示. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,本研究算法能够充分提取不同室内场景的点云特征,并准确地确定物体的边界范围,在某些场景下得到的分割结果已经较接近真实标签. ...
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
1
... Comparison of segmentation accuracy of different methods on S3DIS dataset (Area 5 as a test)
Tab.1 方法 OA/% mIoU/% IoU/% ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet [5 ] 79.3 41.1 88.8 97.3 69.8 0.1 3.9 46.3 10.8 59.0 52.6 5.9 40.3 26.4 33.2 TangentConv [28 ] 82.5 52.6 90.5 97.7 74.0 0.0 20.7 39.0 31.3 77.5 69.4 57.3 38.5 48.8 39.8 PointCNN [29 ] 85.9 57.3 92.3 98.2 79.4 0.0 17.6 22.8 62.1 74.4 80.6 31.7 66.7 62.1 56.7 SPG [30 ] 86.4 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb [31 ] 87.0 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 HPEIN [32 ] 87.2 61.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 58.5 67.8 65.6 49.4 RandLA-Net [18 ] 87.2 62.4 91.1 95.6 80.2 0.0 24.7 62.3 47.7 76.2 83.7 60.2 71.1 65.7 53.8 GACNet [33 ] 87.8 62.8 92.3 98.3 81.9 0.0 20.3 59.1 40.8 78.5 85.8 61.7 70.7 74.7 52.8 PPCNN++ [34 ] — 64.0 94.0 98.5 83.7 0.0 18.6 66.1 61.7 79.4 88.0 49.5 70.1 66.4 56.1 BAAF-Net [35 ] 88.9 65.4 92.9 97.9 82.3 0.0 23.1 65.5 64.9 78.5 87.5 61.4 70.7 68.7 57.2 KPConv [36 ] — 67.1 92.8 97.3 82.4 0.0 23.9 58.0 69.0 81.5 91.0 75.4 75.3 66.7 58.9 AGConv [37 ] 90.0 67.9 93.9 98.4 82.2 0.0 23.9 59.1 71.3 91.5 81.2 75.5 74.9 72.1 58.6 本研究方法 90.8 69.5 94.4 99.2 87.2 0.0 27.2 62.2 72.8 91.8 85.8 79.0 66.7 74.4 62.9
为了定性分析语义分割结果,对Area 5的测试结果进行了可视化,如图4 所示. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,本研究算法能够充分提取不同室内场景的点云特征,并准确地确定物体的边界范围,在某些场景下得到的分割结果已经较接近真实标签. ...
2
... Comparison of segmentation accuracy of different methods on S3DIS dataset (Area 5 as a test)
Tab.1 方法 OA/% mIoU/% IoU/% ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet [5 ] 79.3 41.1 88.8 97.3 69.8 0.1 3.9 46.3 10.8 59.0 52.6 5.9 40.3 26.4 33.2 TangentConv [28 ] 82.5 52.6 90.5 97.7 74.0 0.0 20.7 39.0 31.3 77.5 69.4 57.3 38.5 48.8 39.8 PointCNN [29 ] 85.9 57.3 92.3 98.2 79.4 0.0 17.6 22.8 62.1 74.4 80.6 31.7 66.7 62.1 56.7 SPG [30 ] 86.4 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb [31 ] 87.0 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 HPEIN [32 ] 87.2 61.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 58.5 67.8 65.6 49.4 RandLA-Net [18 ] 87.2 62.4 91.1 95.6 80.2 0.0 24.7 62.3 47.7 76.2 83.7 60.2 71.1 65.7 53.8 GACNet [33 ] 87.8 62.8 92.3 98.3 81.9 0.0 20.3 59.1 40.8 78.5 85.8 61.7 70.7 74.7 52.8 PPCNN++ [34 ] — 64.0 94.0 98.5 83.7 0.0 18.6 66.1 61.7 79.4 88.0 49.5 70.1 66.4 56.1 BAAF-Net [35 ] 88.9 65.4 92.9 97.9 82.3 0.0 23.1 65.5 64.9 78.5 87.5 61.4 70.7 68.7 57.2 KPConv [36 ] — 67.1 92.8 97.3 82.4 0.0 23.9 58.0 69.0 81.5 91.0 75.4 75.3 66.7 58.9 AGConv [37 ] 90.0 67.9 93.9 98.4 82.2 0.0 23.9 59.1 71.3 91.5 81.2 75.5 74.9 72.1 58.6 本研究方法 90.8 69.5 94.4 99.2 87.2 0.0 27.2 62.2 72.8 91.8 85.8 79.0 66.7 74.4 62.9
为了定性分析语义分割结果,对Area 5的测试结果进行了可视化,如图4 所示. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,本研究算法能够充分提取不同室内场景的点云特征,并准确地确定物体的边界范围,在某些场景下得到的分割结果已经较接近真实标签. ...
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
1
... Comparison of segmentation accuracy of different methods on S3DIS dataset (Area 5 as a test)
Tab.1 方法 OA/% mIoU/% IoU/% ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet [5 ] 79.3 41.1 88.8 97.3 69.8 0.1 3.9 46.3 10.8 59.0 52.6 5.9 40.3 26.4 33.2 TangentConv [28 ] 82.5 52.6 90.5 97.7 74.0 0.0 20.7 39.0 31.3 77.5 69.4 57.3 38.5 48.8 39.8 PointCNN [29 ] 85.9 57.3 92.3 98.2 79.4 0.0 17.6 22.8 62.1 74.4 80.6 31.7 66.7 62.1 56.7 SPG [30 ] 86.4 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb [31 ] 87.0 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 HPEIN [32 ] 87.2 61.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 58.5 67.8 65.6 49.4 RandLA-Net [18 ] 87.2 62.4 91.1 95.6 80.2 0.0 24.7 62.3 47.7 76.2 83.7 60.2 71.1 65.7 53.8 GACNet [33 ] 87.8 62.8 92.3 98.3 81.9 0.0 20.3 59.1 40.8 78.5 85.8 61.7 70.7 74.7 52.8 PPCNN++ [34 ] — 64.0 94.0 98.5 83.7 0.0 18.6 66.1 61.7 79.4 88.0 49.5 70.1 66.4 56.1 BAAF-Net [35 ] 88.9 65.4 92.9 97.9 82.3 0.0 23.1 65.5 64.9 78.5 87.5 61.4 70.7 68.7 57.2 KPConv [36 ] — 67.1 92.8 97.3 82.4 0.0 23.9 58.0 69.0 81.5 91.0 75.4 75.3 66.7 58.9 AGConv [37 ] 90.0 67.9 93.9 98.4 82.2 0.0 23.9 59.1 71.3 91.5 81.2 75.5 74.9 72.1 58.6 本研究方法 90.8 69.5 94.4 99.2 87.2 0.0 27.2 62.2 72.8 91.8 85.8 79.0 66.7 74.4 62.9
为了定性分析语义分割结果,对Area 5的测试结果进行了可视化,如图4 所示. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,本研究算法能够充分提取不同室内场景的点云特征,并准确地确定物体的边界范围,在某些场景下得到的分割结果已经较接近真实标签. ...
1
... Comparison of segmentation accuracy of different methods on S3DIS dataset (Area 5 as a test)
Tab.1 方法 OA/% mIoU/% IoU/% ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet [5 ] 79.3 41.1 88.8 97.3 69.8 0.1 3.9 46.3 10.8 59.0 52.6 5.9 40.3 26.4 33.2 TangentConv [28 ] 82.5 52.6 90.5 97.7 74.0 0.0 20.7 39.0 31.3 77.5 69.4 57.3 38.5 48.8 39.8 PointCNN [29 ] 85.9 57.3 92.3 98.2 79.4 0.0 17.6 22.8 62.1 74.4 80.6 31.7 66.7 62.1 56.7 SPG [30 ] 86.4 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb [31 ] 87.0 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 HPEIN [32 ] 87.2 61.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 58.5 67.8 65.6 49.4 RandLA-Net [18 ] 87.2 62.4 91.1 95.6 80.2 0.0 24.7 62.3 47.7 76.2 83.7 60.2 71.1 65.7 53.8 GACNet [33 ] 87.8 62.8 92.3 98.3 81.9 0.0 20.3 59.1 40.8 78.5 85.8 61.7 70.7 74.7 52.8 PPCNN++ [34 ] — 64.0 94.0 98.5 83.7 0.0 18.6 66.1 61.7 79.4 88.0 49.5 70.1 66.4 56.1 BAAF-Net [35 ] 88.9 65.4 92.9 97.9 82.3 0.0 23.1 65.5 64.9 78.5 87.5 61.4 70.7 68.7 57.2 KPConv [36 ] — 67.1 92.8 97.3 82.4 0.0 23.9 58.0 69.0 81.5 91.0 75.4 75.3 66.7 58.9 AGConv [37 ] 90.0 67.9 93.9 98.4 82.2 0.0 23.9 59.1 71.3 91.5 81.2 75.5 74.9 72.1 58.6 本研究方法 90.8 69.5 94.4 99.2 87.2 0.0 27.2 62.2 72.8 91.8 85.8 79.0 66.7 74.4 62.9
为了定性分析语义分割结果,对Area 5的测试结果进行了可视化,如图4 所示. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,本研究算法能够充分提取不同室内场景的点云特征,并准确地确定物体的边界范围,在某些场景下得到的分割结果已经较接近真实标签. ...
1
... Comparison of segmentation accuracy of different methods on S3DIS dataset (Area 5 as a test)
Tab.1 方法 OA/% mIoU/% IoU/% ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet [5 ] 79.3 41.1 88.8 97.3 69.8 0.1 3.9 46.3 10.8 59.0 52.6 5.9 40.3 26.4 33.2 TangentConv [28 ] 82.5 52.6 90.5 97.7 74.0 0.0 20.7 39.0 31.3 77.5 69.4 57.3 38.5 48.8 39.8 PointCNN [29 ] 85.9 57.3 92.3 98.2 79.4 0.0 17.6 22.8 62.1 74.4 80.6 31.7 66.7 62.1 56.7 SPG [30 ] 86.4 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb [31 ] 87.0 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 HPEIN [32 ] 87.2 61.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 58.5 67.8 65.6 49.4 RandLA-Net [18 ] 87.2 62.4 91.1 95.6 80.2 0.0 24.7 62.3 47.7 76.2 83.7 60.2 71.1 65.7 53.8 GACNet [33 ] 87.8 62.8 92.3 98.3 81.9 0.0 20.3 59.1 40.8 78.5 85.8 61.7 70.7 74.7 52.8 PPCNN++ [34 ] — 64.0 94.0 98.5 83.7 0.0 18.6 66.1 61.7 79.4 88.0 49.5 70.1 66.4 56.1 BAAF-Net [35 ] 88.9 65.4 92.9 97.9 82.3 0.0 23.1 65.5 64.9 78.5 87.5 61.4 70.7 68.7 57.2 KPConv [36 ] — 67.1 92.8 97.3 82.4 0.0 23.9 58.0 69.0 81.5 91.0 75.4 75.3 66.7 58.9 AGConv [37 ] 90.0 67.9 93.9 98.4 82.2 0.0 23.9 59.1 71.3 91.5 81.2 75.5 74.9 72.1 58.6 本研究方法 90.8 69.5 94.4 99.2 87.2 0.0 27.2 62.2 72.8 91.8 85.8 79.0 66.7 74.4 62.9
为了定性分析语义分割结果,对Area 5的测试结果进行了可视化,如图4 所示. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,本研究算法能够充分提取不同室内场景的点云特征,并准确地确定物体的边界范围,在某些场景下得到的分割结果已经较接近真实标签. ...
Projection-based point convolution for efficient point cloud segmentation
2
2022
... 为了验证所提算法的有效性,与一些经典算法在S3DIS数据集上进行分割对比实验,结果如表1 所示. 表中,IoU为各类别分割精度. 可以看出,本研究算法获得了69.5%的mIoU和90.8%的OA,并在13个类别中的7个类别上获得了最佳分割结果. 与目前基于点的最优方法AGConv[37 ] 相比,本研究算法的mIoU和OA这2个分割精度评价指标均较高,主要由于AGConv提出的自适应核重点关注不同语义部分的点之间的不同关系,并未考虑融合不同表示形式的点云特征. PPCNN++[34 ] 提出基于投影的点卷积(projection-based point convolution, PPConv),融合了点方法与投影方法,虽然避免了体素方法造成的内存消耗问题,但投影方法由于需要降维应用了二维卷积运算,难免会丢失信息,而本研究通过引入稀疏卷积解决了传统体素方法计算复杂的问题,较该方法在mIoU上提高了5.5%. 与常规的6折交叉验证方法不同,本研究将S3DIS数据集的Area 5区域单独作为测试区域,而将Area 1~Area 4和Area 6区域用于训练. Area 5和其他区域中的房间有所不同,包含的物体存在差异,所以对网络模型的要求更高. 本研究算法通过融合基于体素分支的上下文信息与基于点分支的局部特征得到更具鉴别力的特征,同时所提出的边界点估计模块,将体素分支得到的初始点语义标签作为输入预测出可能的边界点,从而在聚合局部特征时避免不同特征之间的相互污染,进一步提高了点云语义分割的精度. ...
... Comparison of segmentation accuracy of different methods on S3DIS dataset (Area 5 as a test)
Tab.1 方法 OA/% mIoU/% IoU/% ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet [5 ] 79.3 41.1 88.8 97.3 69.8 0.1 3.9 46.3 10.8 59.0 52.6 5.9 40.3 26.4 33.2 TangentConv [28 ] 82.5 52.6 90.5 97.7 74.0 0.0 20.7 39.0 31.3 77.5 69.4 57.3 38.5 48.8 39.8 PointCNN [29 ] 85.9 57.3 92.3 98.2 79.4 0.0 17.6 22.8 62.1 74.4 80.6 31.7 66.7 62.1 56.7 SPG [30 ] 86.4 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb [31 ] 87.0 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 HPEIN [32 ] 87.2 61.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 58.5 67.8 65.6 49.4 RandLA-Net [18 ] 87.2 62.4 91.1 95.6 80.2 0.0 24.7 62.3 47.7 76.2 83.7 60.2 71.1 65.7 53.8 GACNet [33 ] 87.8 62.8 92.3 98.3 81.9 0.0 20.3 59.1 40.8 78.5 85.8 61.7 70.7 74.7 52.8 PPCNN++ [34 ] — 64.0 94.0 98.5 83.7 0.0 18.6 66.1 61.7 79.4 88.0 49.5 70.1 66.4 56.1 BAAF-Net [35 ] 88.9 65.4 92.9 97.9 82.3 0.0 23.1 65.5 64.9 78.5 87.5 61.4 70.7 68.7 57.2 KPConv [36 ] — 67.1 92.8 97.3 82.4 0.0 23.9 58.0 69.0 81.5 91.0 75.4 75.3 66.7 58.9 AGConv [37 ] 90.0 67.9 93.9 98.4 82.2 0.0 23.9 59.1 71.3 91.5 81.2 75.5 74.9 72.1 58.6 本研究方法 90.8 69.5 94.4 99.2 87.2 0.0 27.2 62.2 72.8 91.8 85.8 79.0 66.7 74.4 62.9
为了定性分析语义分割结果,对Area 5的测试结果进行了可视化,如图4 所示. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,本研究算法能够充分提取不同室内场景的点云特征,并准确地确定物体的边界范围,在某些场景下得到的分割结果已经较接近真实标签. ...
2
... Comparison of segmentation accuracy of different methods on S3DIS dataset (Area 5 as a test)
Tab.1 方法 OA/% mIoU/% IoU/% ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet [5 ] 79.3 41.1 88.8 97.3 69.8 0.1 3.9 46.3 10.8 59.0 52.6 5.9 40.3 26.4 33.2 TangentConv [28 ] 82.5 52.6 90.5 97.7 74.0 0.0 20.7 39.0 31.3 77.5 69.4 57.3 38.5 48.8 39.8 PointCNN [29 ] 85.9 57.3 92.3 98.2 79.4 0.0 17.6 22.8 62.1 74.4 80.6 31.7 66.7 62.1 56.7 SPG [30 ] 86.4 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb [31 ] 87.0 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 HPEIN [32 ] 87.2 61.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 58.5 67.8 65.6 49.4 RandLA-Net [18 ] 87.2 62.4 91.1 95.6 80.2 0.0 24.7 62.3 47.7 76.2 83.7 60.2 71.1 65.7 53.8 GACNet [33 ] 87.8 62.8 92.3 98.3 81.9 0.0 20.3 59.1 40.8 78.5 85.8 61.7 70.7 74.7 52.8 PPCNN++ [34 ] — 64.0 94.0 98.5 83.7 0.0 18.6 66.1 61.7 79.4 88.0 49.5 70.1 66.4 56.1 BAAF-Net [35 ] 88.9 65.4 92.9 97.9 82.3 0.0 23.1 65.5 64.9 78.5 87.5 61.4 70.7 68.7 57.2 KPConv [36 ] — 67.1 92.8 97.3 82.4 0.0 23.9 58.0 69.0 81.5 91.0 75.4 75.3 66.7 58.9 AGConv [37 ] 90.0 67.9 93.9 98.4 82.2 0.0 23.9 59.1 71.3 91.5 81.2 75.5 74.9 72.1 58.6 本研究方法 90.8 69.5 94.4 99.2 87.2 0.0 27.2 62.2 72.8 91.8 85.8 79.0 66.7 74.4 62.9
为了定性分析语义分割结果,对Area 5的测试结果进行了可视化,如图4 所示. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,本研究算法能够充分提取不同室内场景的点云特征,并准确地确定物体的边界范围,在某些场景下得到的分割结果已经较接近真实标签. ...
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
2
... Comparison of segmentation accuracy of different methods on S3DIS dataset (Area 5 as a test)
Tab.1 方法 OA/% mIoU/% IoU/% ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet [5 ] 79.3 41.1 88.8 97.3 69.8 0.1 3.9 46.3 10.8 59.0 52.6 5.9 40.3 26.4 33.2 TangentConv [28 ] 82.5 52.6 90.5 97.7 74.0 0.0 20.7 39.0 31.3 77.5 69.4 57.3 38.5 48.8 39.8 PointCNN [29 ] 85.9 57.3 92.3 98.2 79.4 0.0 17.6 22.8 62.1 74.4 80.6 31.7 66.7 62.1 56.7 SPG [30 ] 86.4 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb [31 ] 87.0 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 HPEIN [32 ] 87.2 61.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 58.5 67.8 65.6 49.4 RandLA-Net [18 ] 87.2 62.4 91.1 95.6 80.2 0.0 24.7 62.3 47.7 76.2 83.7 60.2 71.1 65.7 53.8 GACNet [33 ] 87.8 62.8 92.3 98.3 81.9 0.0 20.3 59.1 40.8 78.5 85.8 61.7 70.7 74.7 52.8 PPCNN++ [34 ] — 64.0 94.0 98.5 83.7 0.0 18.6 66.1 61.7 79.4 88.0 49.5 70.1 66.4 56.1 BAAF-Net [35 ] 88.9 65.4 92.9 97.9 82.3 0.0 23.1 65.5 64.9 78.5 87.5 61.4 70.7 68.7 57.2 KPConv [36 ] — 67.1 92.8 97.3 82.4 0.0 23.9 58.0 69.0 81.5 91.0 75.4 75.3 66.7 58.9 AGConv [37 ] 90.0 67.9 93.9 98.4 82.2 0.0 23.9 59.1 71.3 91.5 81.2 75.5 74.9 72.1 58.6 本研究方法 90.8 69.5 94.4 99.2 87.2 0.0 27.2 62.2 72.8 91.8 85.8 79.0 66.7 74.4 62.9
为了定性分析语义分割结果,对Area 5的测试结果进行了可视化,如图4 所示. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,本研究算法能够充分提取不同室内场景的点云特征,并准确地确定物体的边界范围,在某些场景下得到的分割结果已经较接近真实标签. ...
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
AGConv: adaptive graph convolution on 3D point clouds
2
2023
... 为了验证所提算法的有效性,与一些经典算法在S3DIS数据集上进行分割对比实验,结果如表1 所示. 表中,IoU为各类别分割精度. 可以看出,本研究算法获得了69.5%的mIoU和90.8%的OA,并在13个类别中的7个类别上获得了最佳分割结果. 与目前基于点的最优方法AGConv[37 ] 相比,本研究算法的mIoU和OA这2个分割精度评价指标均较高,主要由于AGConv提出的自适应核重点关注不同语义部分的点之间的不同关系,并未考虑融合不同表示形式的点云特征. PPCNN++[34 ] 提出基于投影的点卷积(projection-based point convolution, PPConv),融合了点方法与投影方法,虽然避免了体素方法造成的内存消耗问题,但投影方法由于需要降维应用了二维卷积运算,难免会丢失信息,而本研究通过引入稀疏卷积解决了传统体素方法计算复杂的问题,较该方法在mIoU上提高了5.5%. 与常规的6折交叉验证方法不同,本研究将S3DIS数据集的Area 5区域单独作为测试区域,而将Area 1~Area 4和Area 6区域用于训练. Area 5和其他区域中的房间有所不同,包含的物体存在差异,所以对网络模型的要求更高. 本研究算法通过融合基于体素分支的上下文信息与基于点分支的局部特征得到更具鉴别力的特征,同时所提出的边界点估计模块,将体素分支得到的初始点语义标签作为输入预测出可能的边界点,从而在聚合局部特征时避免不同特征之间的相互污染,进一步提高了点云语义分割的精度. ...
... Comparison of segmentation accuracy of different methods on S3DIS dataset (Area 5 as a test)
Tab.1 方法 OA/% mIoU/% IoU/% ceiling floor wall beam column window door table chair sofa bookcase board clutter PointNet [5 ] 79.3 41.1 88.8 97.3 69.8 0.1 3.9 46.3 10.8 59.0 52.6 5.9 40.3 26.4 33.2 TangentConv [28 ] 82.5 52.6 90.5 97.7 74.0 0.0 20.7 39.0 31.3 77.5 69.4 57.3 38.5 48.8 39.8 PointCNN [29 ] 85.9 57.3 92.3 98.2 79.4 0.0 17.6 22.8 62.1 74.4 80.6 31.7 66.7 62.1 56.7 SPG [30 ] 86.4 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb [31 ] 87.0 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 HPEIN [32 ] 87.2 61.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 58.5 67.8 65.6 49.4 RandLA-Net [18 ] 87.2 62.4 91.1 95.6 80.2 0.0 24.7 62.3 47.7 76.2 83.7 60.2 71.1 65.7 53.8 GACNet [33 ] 87.8 62.8 92.3 98.3 81.9 0.0 20.3 59.1 40.8 78.5 85.8 61.7 70.7 74.7 52.8 PPCNN++ [34 ] — 64.0 94.0 98.5 83.7 0.0 18.6 66.1 61.7 79.4 88.0 49.5 70.1 66.4 56.1 BAAF-Net [35 ] 88.9 65.4 92.9 97.9 82.3 0.0 23.1 65.5 64.9 78.5 87.5 61.4 70.7 68.7 57.2 KPConv [36 ] — 67.1 92.8 97.3 82.4 0.0 23.9 58.0 69.0 81.5 91.0 75.4 75.3 66.7 58.9 AGConv [37 ] 90.0 67.9 93.9 98.4 82.2 0.0 23.9 59.1 71.3 91.5 81.2 75.5 74.9 72.1 58.6 本研究方法 90.8 69.5 94.4 99.2 87.2 0.0 27.2 62.2 72.8 91.8 85.8 79.0 66.7 74.4 62.9
为了定性分析语义分割结果,对Area 5的测试结果进行了可视化,如图4 所示. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,本研究算法能够充分提取不同室内场景的点云特征,并准确地确定物体的边界范围,在某些场景下得到的分割结果已经较接近真实标签. ...
1
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
1
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
1
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
1
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
3D-MiniNet: learning a 2D representation from point clouds for fast and efficient 3D LiDAR semantic segmentation
1
2020
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
基于自注意力特征融合组卷积神经网络的三维点云语义分割
1
2022
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
基于自注意力特征融合组卷积神经网络的三维点云语义分割
1
2022
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...
2
... SemanticKITTI数据集包含德国卡尔斯鲁厄附近的市内交通、居民区、高速公路场景和乡村道路场景,是目前最大的汽车激光雷达点云数据集. 该数据集由22个点云序列组成,00~07、09~10序列作为训练集,08序列作为验证集并生成可视化结果,一共包含23201帧3D点云场景;11~21序列作为测试集,一共包含20351帧3D点云场景. 训练集中每点都有自己的标签,人为进行了语义标注,共有19种类别标签. 如表2 所示为本研究方法在SemanticKITTI数据集上与目前主流方法的场景语义分割定量结果的对比. 可以看出,本研究算法的mIoU为62.7%,超过了同为点云与体素融合的方法FusionNet[20 ] ,并且在其中7个类别上取得了最好的分割结果. FusionNet只考虑将点云与体素的方法相结合,忽略了对边界信息的处理,而本研究提出了边界点估计模块用来预测可能的边界点,并在局部特征提取中对邻域点的特征进行有选择的聚合. TORNADONet算法[44 ] 融合了2种基于投影的方法进行语义分割,然而在投影过程中,点云原有的拓扑结构不可避免地会丢失或改变,导致基于投影的方法无法完整地对几何信息进行建模. 而本研究算法通过对点云进行体素化并使用稀疏卷积,解决了点云稀疏分布的问题,也能通过体素分支提取到感受野更大的上下文特征. ...
... Comparison of segmentation accuracy of different methods on SemanticKITTI dataset
Tab.2 方法 mIoU/% IoU/% road side- par- other-ground buil- car truck bicy- motor- other-vehicle vegeta- trunk terrain per- bicy- motor- fence pole traffic-sign PointNet [5 ] 14.6 61.6 35.7 15.8 1.4 41.4 46.3 0.1 1.3 0.3 0.8 31.0 4.6 17.6 0.2 0.2 0.0 12.9 2.4 3.7 SPG [30 ] 17.4 45.0 28.5 1.6 0.6 64.3 49.3 0.1 0.2 0.2 0.8 48.9 27.2 24.6 0.3 2.7 0.1 20.8 15.9 0.8 PointNet++ [6 ] 20.1 72.0 41.8 18.7 5.6 62.3 53.7 0.9 1.9 0.2 0.2 46.5 13.8 30.0 0.9 1.0 0.0 16.9 6.0 8.9 TangentConv [28 ] 40.9 83.9 63.9 33.4 15.4 83.4 90.8 15.2 2.7 16.5 12.1 79.5 49.3 58.1 23.0 28.4 8.1 49.0 35.8 28.5 SpSequenceNet [38 ] 43.1 90.1 73.9 57.6 27.1 91.2 88.5 29.2 24.0 0.0 22.7 84.0 66.0 65.7 6.3 0.0 0.0 67.7 50.8 48.7 HPGCNN [39 ] 50.5 89.5 73.6 58.8 34.6 91.2 93.1 21.0 6.5 17.6 23.3 84.4 65.9 70.0 32.1 30.0 14.7 65.5 45.5 41.5 RangeNet++ [40 ] 52.2 91.8 75.2 65.0 27.8 87.4 91.4 25.7 25.7 34.4 23.0 80.5 55.1 64.6 38.3 38.8 4.8 58.6 47.9 55.9 RandLA-Net [18 ] 53.9 90.7 73.7 60.3 20.4 86.9 94.2 40.1 26.0 25.8 38.9 81.4 61.3 66.8 49.2 48.2 7.2 56.3 49.2 47.7 PolarNet [41 ] 54.3 90.8 74.4 61.7 21.7 90.0 93.8 22.9 40.3 30.1 28.5 84.0 65.5 67.8 43.2 40.2 5.6 61.3 51.8 57.5 3D-MiniNet [42 ] 55.8 91.6 74.5 64.2 25.4 89.4 90.5 28.5 42.3 42.1 29.4 82.8 60.8 66.7 47.8 44.1 14.5 60.8 48.0 56.6 SAFFGCNN [43 ] 56.6 89.9 73.9 63.5 35.1 91.5 95.0 38.3 33.2 35.1 28.7 84.4 67.1 69.5 45.3 43.5 7.3 66.1 54.3 53.7 KPConv [36 ] 58.8 88.8 72.7 61.3 31.6 90.5 96.0 33.4 30.2 42.5 31.6 84.8 69.2 69.1 61.5 61.6 11.8 64.2 56.4 48.4 BAAF-Net [35 ] 59.9 90.9 74.4 62.2 23.6 89.8 95.4 48.7 31.8 35.5 46.7 82.7 63.4 67.9 49.5 55.7 53.0 60.8 53.7 52.0 TORNADONet [44 ] 61.1 90.8 75.3 65.3 27.5 89.6 93.1 43.1 53.0 44.4 39.4 84.1 64.3 69.6 61.6 56.7 20.2 62.9 55.0 64.2 FusionNet [20 ] 61.3 91.8 77.1 68.8 30.8 92.5 95.3 41.8 47.5 37.7 34.5 84.5 69.8 68.5 59.5 56.8 11.9 69.4 60.0 66.5 本研究方法 62.7 92.7 78.5 71.6 31.5 91.4 95.5 40.9 46.1 48.0 42.2 85.2 68.4 70.2 63.9 54.3 23.8 68.6 56.7 62.8
如图5 所示为本研究算法在SemanticKITTI数据集上的分割可视化结果. 图中,红色椭圆标注的区域为重点关注区域. 可以看出,即使在处理稀疏性较大的大规模室外点云数据时,本研究算法仍然能够产生较好的分割效果,原因在于体素分支能够使用稀疏卷积避免内存消耗并提取到更大感受野的上下文特征,增强了点云特征的丰富性,从而提高语义分割结果精度. ...


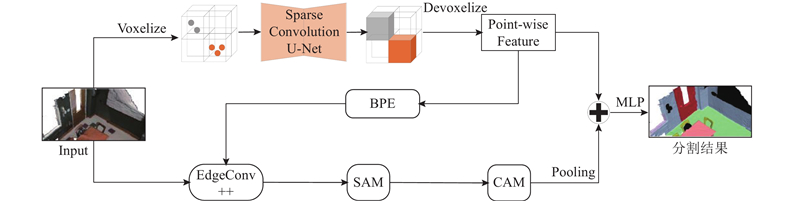
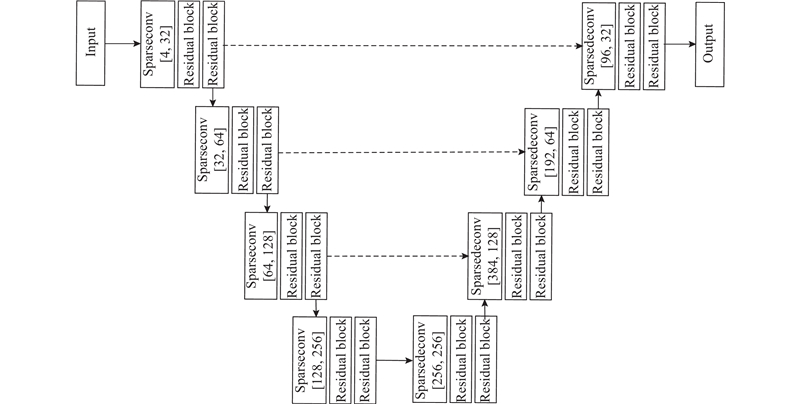
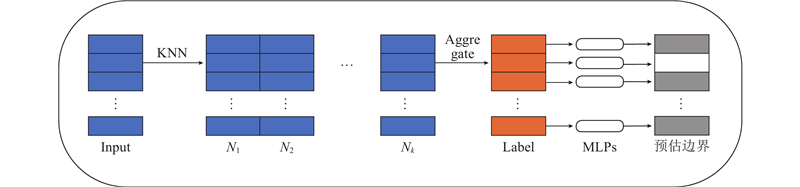
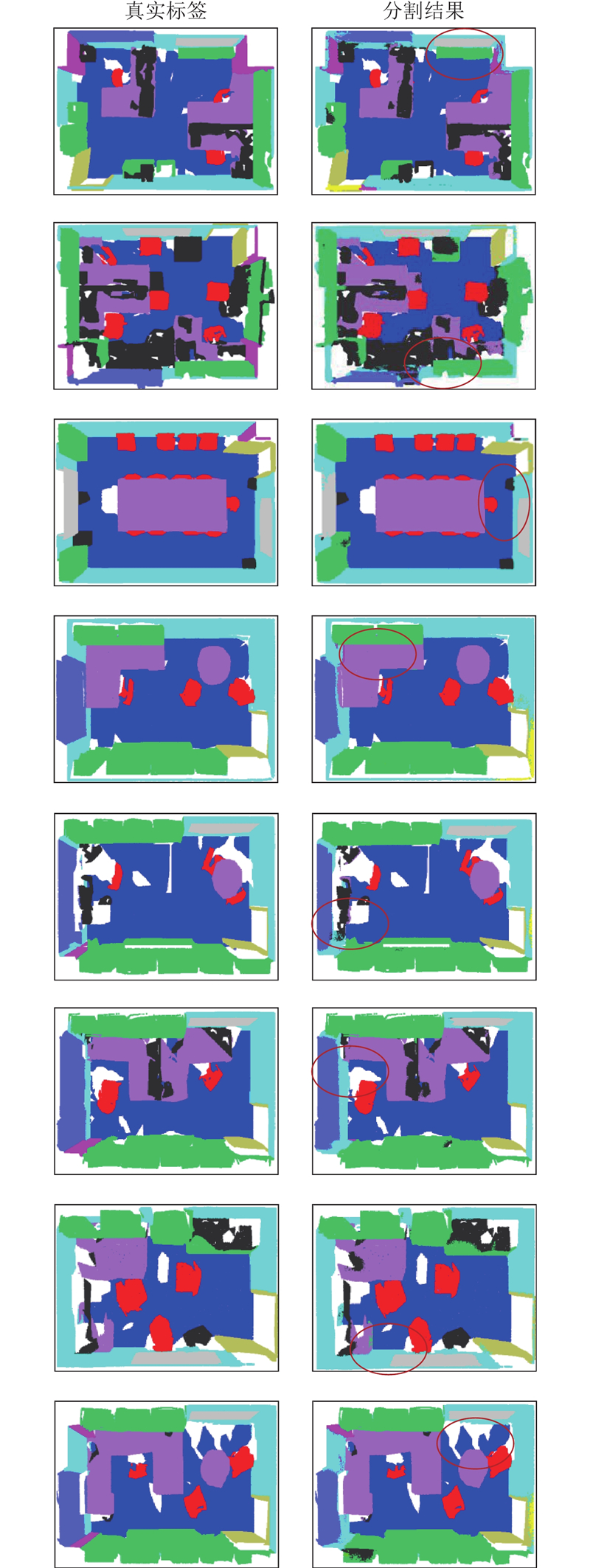
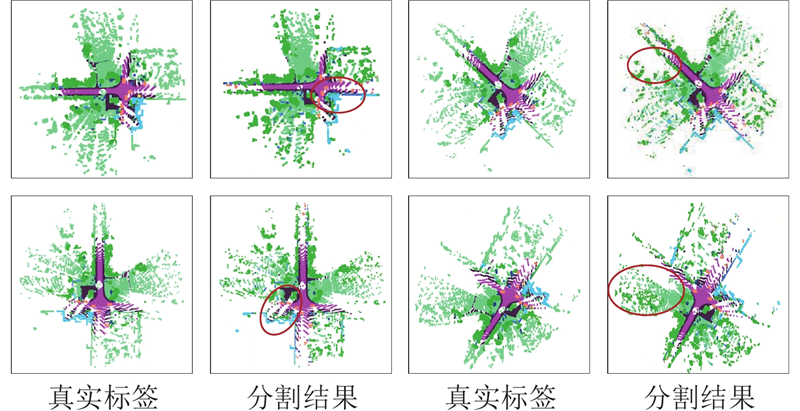
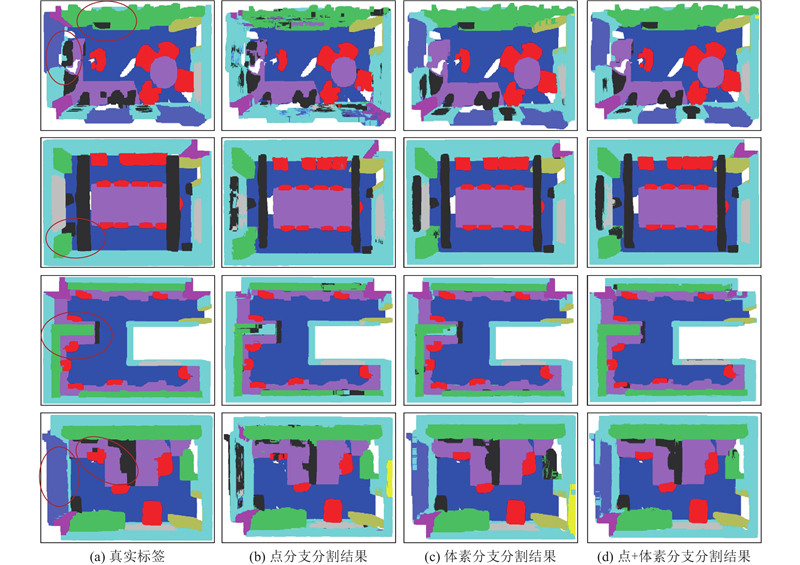

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}