[1]
SUNDERMEYER M, MARTON Z C, DURNER M, et al Augmented autoencoders: implicit 3D orientation learning for 6D object detection
[J]. International Journal of Computer Vision , 2020 , 128 : 714 - 729
DOI:10.1007/s11263-019-01243-8
[本文引用: 2]
[2]
WADIM K , FABIAN M , FEDERICO T, et al. SSD-6D: making RGB-based 3D detection and 6D pose estimation great again [C]// IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 1521–1529.
[本文引用: 1]
[3]
DI Y, MANHARDT F, WANG G, et al. SO-POSE: exploiting self-occlusion for direct 6D pose estimation [C]// International Conference on Computer Vision . Montreal: IEEE, 2021: 12396-12405.
[本文引用: 1]
[4]
WANG G, MANHARDT F, TOMBARI F, et al. GDR-NET: geometry-guided direct regression network for monocular 6D object pose estimation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Montreal: IEEE, 2021: 1661–16621.
[本文引用: 5]
[5]
刘城. 手腕型操作中操作者手部的主动视觉追踪方法研究[D]. 武汉: 武汉理工大学, 2020.
[本文引用: 1]
LIU Cheng. Research on active vision tracking method of operator’s hand in wrist-type operation[D]. Wuhan: Wuhan University of Technology, 2020.
[本文引用: 1]
[6]
戈振鹏. 基于主动视觉和强化学习的机械臂装配研究[D]. 成都: 电子科技大学, 2022.
[本文引用: 1]
GE Zhen-peng. Research on robotic assembly based on active vision and reinforcement learning[D]. Chengdu: University of Electronic Technology, 2022.
[本文引用: 1]
[7]
ZHOU Y, BARNES C, LU J W, et al. On the continuity of rotation representations in neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019. 3: 5745-5753.
[本文引用: 1]
[8]
KUNDU A, LI Y, REHG J M. 3D-RCNN: instance-level 3D object reconstruction via render and compare [C]// IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018. 3: 3559–3568.
[本文引用: 1]
[9]
LI Z G, WANG G, JI X Y. CDPN: coordinates-based disentangled pose network for real time rgb-based 6-DoF object pose estimation [C]// IEEE International Conference on Computer Vision . Seoul: IEEE, 2019. 1: 7678–7687.
[本文引用: 1]
[10]
VOLODYMYR M, NICOLAS H, ALEX G, et al. Recurrent models of visual attention[C]// Conference and Workshop on Neural Information Processing Systems . Montreal: [s.n.], 2014: 136–145.
[本文引用: 2]
[11]
JAMIE S, BEN G, CHRISTOPHER Z, et al. Scene coordinate regression forests for camera relocalization in RGB-D images[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Portland: IEEE, 2013: 2930-2937.
[本文引用: 1]
[12]
ADAM P, SAM G, FRANCISCO M, et al. Pytorch: an imperative style, high-performance deep learning library [C]// Advances in Neural Information Processing Systems . [s.l.]: Manning publications, 2019, 5: 8026–8037.
[本文引用: 2]
[13]
LIU L Y, JIANG H M, HE P C, et al. On the variance of the adaptive learning rate and beyond [C]// International Conference on Learning Representations . Vancouver: [s.n.], 2020.
[本文引用: 1]
[14]
WAIL M, NICOLAS P, NORBERT K. Multi-view object recognition using view-point invariant shape relations and appearance information [C]// IEEE International Conference on Robotics and Automation . Guangzhou: [s.n.], 2013: 4230–4237.
[本文引用: 1]
[15]
LI Y, WANG G, JI X Y, et al. Deepim: deep iterative matching for 6D pose estimation[C]// Proceedings of the European Conference on Computer Vision . Munich: [s.n.], 2018: 683-698.
[本文引用: 1]
[16]
HU Y L, PASCAL F, WANG W, et al. Single-stage 6D object pose estimation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Detroit: IEEE, 2020: 2930-2939.
[本文引用: 2]
[17]
VINCENT L, FRANCESC M N, PASCAL F. EPnP: an accurate O(N) solution to the PnP problem[J]. International Journal of Computer Vision , 2009, (81): 155–166.
[本文引用: 1]
[18]
吕成志. 面向复杂场景的目标六自由度姿态估计关键技术研究[D]. 广州: 华南理工大学, 2020.
[本文引用: 1]
LV Cheng-zhi. Research on key technologies of object six degree of freedom pose estimation for complex scenes[D]. Guangzhou: South China University of Technology, 2020.
[本文引用: 1]
[19]
YU X, TANNER S, VENKATRAMAN N, et al. POSECNN: a convolutional neural network for 6D object pose estimation in cluttered scenes [C]// Robotics: Science and Systems . Pittsburgh: [s.n.], 2018.
[本文引用: 2]
[20]
YANN L, JUSTIN C, MATHIEU A, et al. Cosypose: consistent multi-view multi-object 6D pose estimation [C]// European Conference on Computer Vision . Glasgow: [s.n.], 2020: 574–591.
[本文引用: 1]
[21]
刘建伟, 宋志妍 循环神经网络研究综述
[J]. 控制与决策 , 2022 , 37 (11 ): 2753 - 2768
[本文引用: 1]
LIU Jian-wei, SONG Zhi-yan Research on recurrent neural network
[J]. Journal of Computer Applications , 2022 , 37 (11 ): 2753 - 2768
[本文引用: 1]
[22]
NIALL M, JESUS M D R, PAUL M. Recurrent convolutional network for video-based person re-identification [C]// IEEE International Conference on Computer Vision . Las Vegas: IEEE, 2016: 1325-1334.
[本文引用: 1]
[23]
胡代弟, 李锐君. 基于主动视觉的机械表面疲劳损伤裂纹检测[J]. 制造业自动化, 2022, 44(5): 170-174.
[本文引用: 1]
HU Dai-di, LI Rui-jun. Mechanical surface fatigue damage crack detection based on active vision[J]. Manufacturing Automation . 2022, 44(5) : 170-174.
[本文引用: 1]
[24]
罗宇. 基于深度学习的目标姿态估计与机械臂抓取研究[D]. 广州: 广东工业大学, 2020.
[本文引用: 1]
LUO Yu. Research on target attitude estimation and manipulator grab based on deep learning[D]. Guangzhou: Guangdong University of Technology, 2020.
[本文引用: 1]
Augmented autoencoders: implicit 3D orientation learning for 6D object detection
2
2020
... 物体6D姿态包括三维平移及三维旋转. 三维平移指从相机坐标系原点开始沿x 、y 、z 轴移动到被观察物体局部坐标系原点经历的变化,用向量t x 、y 、z 方向产生的旋转变化,一般采用3×3 矩阵R [1 ] 提出通过对嵌入空间的学习来得到物体位姿,在此基础上Wadim等[2 ] 提出通过对位姿空间进行离散化的方式对物体姿态进行直接预测. 直接法虽然在一定程度上提高了预测精度,但与通过建立2D-3D对应关系估计物体6D姿态的间接法相比,准确度较低. Di等[3 ] 为了提高端到端6D姿态估计的准确性,提出SO-Pose框架. 该框架将单个RGB图像作为输入,利用self-occlution 和 2D-3D对应关系来为3D空间中的每个对象建立2层表示,再将2个输出进行融合后,直接回归六自由度位姿参数. 由于该框架结合了跨层一致性和对应自遮挡6D姿势的性质,其在一些难度较大的数据集上的位姿估计准确性以及鲁棒性超越了其他方法. 间接法虽然能提高估计准确性,但须通过EPnP算法对物体位姿进行估计且无法与自监督学习技术进行结合. 因此,Wang等[4 ] 将直接法与间接法相结合以提高准确度,但以单一视角对物体信息进行推测难免有失偏颇,并且对一些遮挡严重的场景,无法保证对其估计的准确性. ...
... 选用YCB-Video Dataset与LM-O数据集进行实验,在训练中使用颜色增强[1 ] 防止过拟合. 由于YCB-Video Dataset中对称对象的数量较多,采用逻辑回归模型. 如表1 所示为Binocular-RNN与其他方法在YCB-Video Dataset上的对比结果. 表中,Ref表示是否对方法得出的结果进行优化,M 表示YCB-Video Dataset中模型的数量,t s 为训练单个对象的消耗时间. Binocular-RNN综合2个不同视角得到的信息,因此即使在各场景物体遮挡度较大的情况下,其预测性能较其他以单一视角对物体姿态进行检测的技术也更加优异. 具体而言,在以单一物体对网络训练时,Binocular-RNN的ADD或ADDS指标得分是PoseCNN得分的2.66倍,是GDR-Net得分的1.15倍. 循环卷积网络可以自动学习提取与重新识别相关的时空特征,可以长时间保留输入信息[21 ] . 同时,RNN有反馈连接,允许它随着时间重新记忆和利用信息[22 ] . 将Binocular-RNN网络拆解为RNN网络和CNN网络,结果表明仅使用本网络拆解下的循环网络无法完成实验. 同时将Binocular-RNN网络与不使用循环网络的CNN网络相比,Binocular-RNN网络ADD或ADDS指标得分是其的3.08倍,表明将循环网络嵌入到网络体系结构中提高了网络的性能. ...
1
... 物体6D姿态包括三维平移及三维旋转. 三维平移指从相机坐标系原点开始沿x 、y 、z 轴移动到被观察物体局部坐标系原点经历的变化,用向量t x 、y 、z 方向产生的旋转变化,一般采用3×3 矩阵R [1 ] 提出通过对嵌入空间的学习来得到物体位姿,在此基础上Wadim等[2 ] 提出通过对位姿空间进行离散化的方式对物体姿态进行直接预测. 直接法虽然在一定程度上提高了预测精度,但与通过建立2D-3D对应关系估计物体6D姿态的间接法相比,准确度较低. Di等[3 ] 为了提高端到端6D姿态估计的准确性,提出SO-Pose框架. 该框架将单个RGB图像作为输入,利用self-occlution 和 2D-3D对应关系来为3D空间中的每个对象建立2层表示,再将2个输出进行融合后,直接回归六自由度位姿参数. 由于该框架结合了跨层一致性和对应自遮挡6D姿势的性质,其在一些难度较大的数据集上的位姿估计准确性以及鲁棒性超越了其他方法. 间接法虽然能提高估计准确性,但须通过EPnP算法对物体位姿进行估计且无法与自监督学习技术进行结合. 因此,Wang等[4 ] 将直接法与间接法相结合以提高准确度,但以单一视角对物体信息进行推测难免有失偏颇,并且对一些遮挡严重的场景,无法保证对其估计的准确性. ...
1
... 物体6D姿态包括三维平移及三维旋转. 三维平移指从相机坐标系原点开始沿x 、y 、z 轴移动到被观察物体局部坐标系原点经历的变化,用向量t x 、y 、z 方向产生的旋转变化,一般采用3×3 矩阵R [1 ] 提出通过对嵌入空间的学习来得到物体位姿,在此基础上Wadim等[2 ] 提出通过对位姿空间进行离散化的方式对物体姿态进行直接预测. 直接法虽然在一定程度上提高了预测精度,但与通过建立2D-3D对应关系估计物体6D姿态的间接法相比,准确度较低. Di等[3 ] 为了提高端到端6D姿态估计的准确性,提出SO-Pose框架. 该框架将单个RGB图像作为输入,利用self-occlution 和 2D-3D对应关系来为3D空间中的每个对象建立2层表示,再将2个输出进行融合后,直接回归六自由度位姿参数. 由于该框架结合了跨层一致性和对应自遮挡6D姿势的性质,其在一些难度较大的数据集上的位姿估计准确性以及鲁棒性超越了其他方法. 间接法虽然能提高估计准确性,但须通过EPnP算法对物体位姿进行估计且无法与自监督学习技术进行结合. 因此,Wang等[4 ] 将直接法与间接法相结合以提高准确度,但以单一视角对物体信息进行推测难免有失偏颇,并且对一些遮挡严重的场景,无法保证对其估计的准确性. ...
5
... 物体6D姿态包括三维平移及三维旋转. 三维平移指从相机坐标系原点开始沿x 、y 、z 轴移动到被观察物体局部坐标系原点经历的变化,用向量t x 、y 、z 方向产生的旋转变化,一般采用3×3 矩阵R [1 ] 提出通过对嵌入空间的学习来得到物体位姿,在此基础上Wadim等[2 ] 提出通过对位姿空间进行离散化的方式对物体姿态进行直接预测. 直接法虽然在一定程度上提高了预测精度,但与通过建立2D-3D对应关系估计物体6D姿态的间接法相比,准确度较低. Di等[3 ] 为了提高端到端6D姿态估计的准确性,提出SO-Pose框架. 该框架将单个RGB图像作为输入,利用self-occlution 和 2D-3D对应关系来为3D空间中的每个对象建立2层表示,再将2个输出进行融合后,直接回归六自由度位姿参数. 由于该框架结合了跨层一致性和对应自遮挡6D姿势的性质,其在一些难度较大的数据集上的位姿估计准确性以及鲁棒性超越了其他方法. 间接法虽然能提高估计准确性,但须通过EPnP算法对物体位姿进行估计且无法与自监督学习技术进行结合. 因此,Wang等[4 ] 将直接法与间接法相结合以提高准确度,但以单一视角对物体信息进行推测难免有失偏颇,并且对一些遮挡严重的场景,无法保证对其估计的准确性. ...
... 借鉴Wang等[4 ] 所提出的解耦方式,无论物体如何旋转或缩放,该技术都可以准确地检测并跟踪物体中心(δ x ,δ y δ z
... Binocular-RNN整体网络结构框架和流程如图2 所示. 整个网络包含2阶段,第1阶段由2个几何引导的直接回归网络GDR-Net[4 ] 组成,第2阶段为利用循环神经网络对不同视角信息进行汇总并回归6D对象的姿态的BPatch-PnP模块. ...
... 在6D位姿估计时,首先向BinocularRNN喂入大小为256×256像素的RoI区域. 然后,通过GDR-Net[4 ] 预测3个空间大小为64×64像素的中间几何特征地图,包括密集响应图(dense correspondences map) M 2D-3D 、表面区域注意力图(surface region attention map) M SRA 及可见对象掩码图(visible object mask) M vis . 最后,通过2D卷积BPatch-PnP模块直接对不同视角几何特征进行汇总并回归6D姿态. 其中M vis 利用L1损失函数进行归一化后可以去除M 2D-3D 及M SRA 中的无关区域,然后通过对底层密集坐标图(dense coordinates maps) M XYZ M 2D-3D . BPatch-PnP模块由6个卷积层组成,内核大小为3×3, stride=2,卷积层后为深度学习归一化方式(group normalization)及ReLU 激活函数. 在处理完成后,由3个全连接(FC)层对数据进行扁平化处理,参考 Volodymyr等[10 ] 提出的Recurrent models中的循环结构对几何特征进行汇总并将数据尺寸降至256像素后由2个平行的FC层输出参数为R a6D (见式(8))的3D旋转R t SITE (见式(9))的3D平移t
... 在使用Yolov5探测器对图像尺寸为640×480像素的图像物体进行预测时,用GDR-Net预测单个对象需要约22 ms,同时预测8个对象需要约35 ms[4 ] . Binocular-RNN在预测单个对象需要约23 ms,预测8个对象需要约35ms. 但相对于主动视觉预测时间大于等于100 ms[23 ] 的情况而言,实时性已经得到了大幅度提高. ...
1
... 与静态图像识别相反,人类在判断物体位置时往往使用主动识别法,依据一定策略引导感官运动进而更好地了解周围环境,如坐在扶手椅上通过旋转观察身后的人或走到窗前观察外面的雨. 易于收集且带标签的大型图像数据集的出现,使得主动视觉技术取得了显著进展. 例如,刘城[5 ] 在利用卷积神经网络(convolutional neural network,CNN)识别动态手势之后,采用Kalman滤波算法处理动态手势,结果发现提出的方法对动态手势的轨迹预测具有较高的精度,能达到对操作者手部主动视觉追踪的目的. 戈振鹏[6 ] 针对夹爪在夹取物体时,夹爪遮挡以及自遮挡造成单视角估计下的误差不确定的问题,提出基于随机抽样一致算法(random sample consensus, RANSAC)的单目多视位姿估计算法(SCMV-RANSAC). 相对其他方法,该算法可以降低平均平移误差68.27%. 主动视觉可以通过多个视角对物体进行识别以提高准确度,但训练深度网络对下一个视角进行预测耗时较长. ...
1
... 与静态图像识别相反,人类在判断物体位置时往往使用主动识别法,依据一定策略引导感官运动进而更好地了解周围环境,如坐在扶手椅上通过旋转观察身后的人或走到窗前观察外面的雨. 易于收集且带标签的大型图像数据集的出现,使得主动视觉技术取得了显著进展. 例如,刘城[5 ] 在利用卷积神经网络(convolutional neural network,CNN)识别动态手势之后,采用Kalman滤波算法处理动态手势,结果发现提出的方法对动态手势的轨迹预测具有较高的精度,能达到对操作者手部主动视觉追踪的目的. 戈振鹏[6 ] 针对夹爪在夹取物体时,夹爪遮挡以及自遮挡造成单视角估计下的误差不确定的问题,提出基于随机抽样一致算法(random sample consensus, RANSAC)的单目多视位姿估计算法(SCMV-RANSAC). 相对其他方法,该算法可以降低平均平移误差68.27%. 主动视觉可以通过多个视角对物体进行识别以提高准确度,但训练深度网络对下一个视角进行预测耗时较长. ...
1
... 与静态图像识别相反,人类在判断物体位置时往往使用主动识别法,依据一定策略引导感官运动进而更好地了解周围环境,如坐在扶手椅上通过旋转观察身后的人或走到窗前观察外面的雨. 易于收集且带标签的大型图像数据集的出现,使得主动视觉技术取得了显著进展. 例如,刘城[5 ] 在利用卷积神经网络(convolutional neural network,CNN)识别动态手势之后,采用Kalman滤波算法处理动态手势,结果发现提出的方法对动态手势的轨迹预测具有较高的精度,能达到对操作者手部主动视觉追踪的目的. 戈振鹏[6 ] 针对夹爪在夹取物体时,夹爪遮挡以及自遮挡造成单视角估计下的误差不确定的问题,提出基于随机抽样一致算法(random sample consensus, RANSAC)的单目多视位姿估计算法(SCMV-RANSAC). 相对其他方法,该算法可以降低平均平移误差68.27%. 主动视觉可以通过多个视角对物体进行识别以提高准确度,但训练深度网络对下一个视角进行预测耗时较长. ...
1
... 与静态图像识别相反,人类在判断物体位置时往往使用主动识别法,依据一定策略引导感官运动进而更好地了解周围环境,如坐在扶手椅上通过旋转观察身后的人或走到窗前观察外面的雨. 易于收集且带标签的大型图像数据集的出现,使得主动视觉技术取得了显著进展. 例如,刘城[5 ] 在利用卷积神经网络(convolutional neural network,CNN)识别动态手势之后,采用Kalman滤波算法处理动态手势,结果发现提出的方法对动态手势的轨迹预测具有较高的精度,能达到对操作者手部主动视觉追踪的目的. 戈振鹏[6 ] 针对夹爪在夹取物体时,夹爪遮挡以及自遮挡造成单视角估计下的误差不确定的问题,提出基于随机抽样一致算法(random sample consensus, RANSAC)的单目多视位姿估计算法(SCMV-RANSAC). 相对其他方法,该算法可以降低平均平移误差68.27%. 主动视觉可以通过多个视角对物体进行识别以提高准确度,但训练深度网络对下一个视角进行预测耗时较长. ...
1
... 借鉴Zhou等[7 ] 提出的在SO(3)空间的连续六维表示R R 6D 为R
1
... 考虑对放大后的感兴趣区域(region of interest,RoI)的后续处理,使用R 6D 对3D旋转进行参数化并用R a6D [8 ] 表示网络预测旋转R6d 的异中心. ...
1
... 使用SITE[9 ] 对平移向量进行参数化. 给定尺寸s 0 = max (w , h ),w 、h 分别为宽、高,检测到包围界面中心(c x c y r=s zoom /s 0 , 缩放大小系数为s zoom ,网络回归尺度不变的平移参数t SITE =[δ x δ y δ z
2
... 在6D位姿估计时,首先向BinocularRNN喂入大小为256×256像素的RoI区域. 然后,通过GDR-Net[4 ] 预测3个空间大小为64×64像素的中间几何特征地图,包括密集响应图(dense correspondences map) M 2D-3D 、表面区域注意力图(surface region attention map) M SRA 及可见对象掩码图(visible object mask) M vis . 最后,通过2D卷积BPatch-PnP模块直接对不同视角几何特征进行汇总并回归6D姿态. 其中M vis 利用L1损失函数进行归一化后可以去除M 2D-3D 及M SRA 中的无关区域,然后通过对底层密集坐标图(dense coordinates maps) M XYZ M 2D-3D . BPatch-PnP模块由6个卷积层组成,内核大小为3×3, stride=2,卷积层后为深度学习归一化方式(group normalization)及ReLU 激活函数. 在处理完成后,由3个全连接(FC)层对数据进行扁平化处理,参考 Volodymyr等[10 ] 提出的Recurrent models中的循环结构对几何特征进行汇总并将数据尺寸降至256像素后由2个平行的FC层输出参数为R a6D (见式(8))的3D旋转R t SITE (见式(9))的3D平移t
... 在Synthetic Sphere、LM、LM-O和YCB-Video这4个数据集上展开实验. 采用模型点平均距离(ADD)、平均最近点距离(ADDS)、平移误差和角度误差作为6D对象位姿评价指标. ADD 用于判别转换后的模型点平均偏差是否小于物体直径10% (0.1d );当对象对称时,可采用ADDS对模型点的最近平均距离误差进行测量. 并且,在将该指标用于YCB-Video时,可通过改变距离阈值来计算ADD或ADDS的曲线下面积 (area under curve,AUC). 平移误差和旋转误差[10 ] 用于度量旋转误差是否小于n °,平移误差是否小于n cm. 此外,考虑到一些物体具有的对称性的情况,误差取值为物体所有可能地面真实姿态的最小误差[15 ] . ...
1
... 式(13)表示element-wise乘法,只使用可见区域来对M XYZ M SRA 进行管理. Binocular-RNN总损失可以概括为L Bin =L Pose +L Geom . 所提出的Binocular-RNN可以基于任何对象检测器实现,并以端到端方式对其进行训练,无须采用三阶段训练策略[11 ] . ...
2
... 所有实验都使用PyTorch[12 ] 实现. 使用Ranger优化器[13 ] 以端到端的方式对所有网络进行训练,批处理规模为24,基本学习率为1×10−4 ,在网络训练到了72%后通过余弦计划(cosine schedule)[14 ] 对其进行退火处理. ...
... 使用LM数据集[12 ] 进行实验,为160个批次的所有对象训练一个单一的Binocular-RNN,在训练中不采取任何的颜色增强措施,使用Faster-RCNN检测图像中目标物体. ...
1
... 所有实验都使用PyTorch[12 ] 实现. 使用Ranger优化器[13 ] 以端到端的方式对所有网络进行训练,批处理规模为24,基本学习率为1×10−4 ,在网络训练到了72%后通过余弦计划(cosine schedule)[14 ] 对其进行退火处理. ...
1
... 所有实验都使用PyTorch[12 ] 实现. 使用Ranger优化器[13 ] 以端到端的方式对所有网络进行训练,批处理规模为24,基本学习率为1×10−4 ,在网络训练到了72%后通过余弦计划(cosine schedule)[14 ] 对其进行退火处理. ...
1
... 在Synthetic Sphere、LM、LM-O和YCB-Video这4个数据集上展开实验. 采用模型点平均距离(ADD)、平均最近点距离(ADDS)、平移误差和角度误差作为6D对象位姿评价指标. ADD 用于判别转换后的模型点平均偏差是否小于物体直径10% (0.1d );当对象对称时,可采用ADDS对模型点的最近平均距离误差进行测量. 并且,在将该指标用于YCB-Video时,可通过改变距离阈值来计算ADD或ADDS的曲线下面积 (area under curve,AUC). 平移误差和旋转误差[10 ] 用于度量旋转误差是否小于n °,平移误差是否小于n cm. 此外,考虑到一些物体具有的对称性的情况,误差取值为物体所有可能地面真实姿态的最小误差[15 ] . ...
2
... 在Synthetic Sphere数据集的基础上,将Binocular-RNN网络中BPatch-PnP[16 ] 、基于RANSAC的EPnP[17 ] 和基于学习的PnP进行比较. 首先,利用数据集提供的姿态生成M XYZ σ 2 ), σ∈U [0,0.03](坐标图已在[0,1.00]中归一化,选择0.03). 在测试时,对相对ADD误差及测试集中不同水平噪声和离群值的直径进行记录. ...
... Comparison of Binocular-RNN with other methods on YCB-Video Dataset
Tab.1 方法 Ref m Acc(ADD(S))/ AUC/% t s /ms ADDS ADD(S) Only-RNN — 1 — — — — Only-CNN — 1 18.4 62.3 59.6 35 Only-CNN — M 15.6 — — — Binocular-RNN — 1 56.7 90.8 85.2 23 Binocular-RNN — M 70.5 93.4 89.6 — PoseCNN[19 ] — 1 21.3 75.9 61.3 24 GDR-Net — 1 49.1 89.1 80.2 22 GDR-Net — M 60.1 91.6 84.4 — Single-Stage[16 ] — M 53.9 — — — DeepIM[19 ] √ 1 — 88.1 81.9 25 CosyPose[20 ] √ 1 — 89.8 84.5 25
如表2 所示为Binocular-RNN与其他方法在LM-O上的对比结果,数据选用指标为ADD或ADDS. 当使用“Real+syn”进行训练时,Binocular-RNN的性能与PVNet、Single-Stage、GDR-NET等网络相近. 利用每个对象训练一个网络能够轻易超越目前的技术水平. 利用“Real+PBR”训练的Binocular-RNN的性能甚至超过了基于精细化的方法DeepIM. ...
1
... 在Synthetic Sphere数据集的基础上,将Binocular-RNN网络中BPatch-PnP[16 ] 、基于RANSAC的EPnP[17 ] 和基于学习的PnP进行比较. 首先,利用数据集提供的姿态生成M XYZ σ 2 ), σ∈U [0,0.03](坐标图已在[0,1.00]中归一化,选择0.03). 在测试时,对相对ADD误差及测试集中不同水平噪声和离群值的直径进行记录. ...
1
... 实验对比结果如图4 所示. 图中,e 为误差. 基于RANSAC的EPnP在噪声极小时(σ =0~0.005)较精确,但随着噪声水平的增加(σ >0.015),基于学习的PnP方法更具精确性和鲁棒性[18 ] . BPatch-PnP利用几何对应图,在对噪声和异常值的鲁棒性上明显高于其他方法. 当异常值为10%,噪声水平为0.05时,BPatch-PnP误差分别为EPnP、PnP的6.33%、19.38%. ...
1
... 实验对比结果如图4 所示. 图中,e 为误差. 基于RANSAC的EPnP在噪声极小时(σ =0~0.005)较精确,但随着噪声水平的增加(σ >0.015),基于学习的PnP方法更具精确性和鲁棒性[18 ] . BPatch-PnP利用几何对应图,在对噪声和异常值的鲁棒性上明显高于其他方法. 当异常值为10%,噪声水平为0.05时,BPatch-PnP误差分别为EPnP、PnP的6.33%、19.38%. ...
2
... Comparison of Binocular-RNN with other methods on YCB-Video Dataset
Tab.1 方法 Ref m Acc(ADD(S))/ AUC/% t s /ms ADDS ADD(S) Only-RNN — 1 — — — — Only-CNN — 1 18.4 62.3 59.6 35 Only-CNN — M 15.6 — — — Binocular-RNN — 1 56.7 90.8 85.2 23 Binocular-RNN — M 70.5 93.4 89.6 — PoseCNN[19 ] — 1 21.3 75.9 61.3 24 GDR-Net — 1 49.1 89.1 80.2 22 GDR-Net — M 60.1 91.6 84.4 — Single-Stage[16 ] — M 53.9 — — — DeepIM[19 ] √ 1 — 88.1 81.9 25 CosyPose[20 ] √ 1 — 89.8 84.5 25
如表2 所示为Binocular-RNN与其他方法在LM-O上的对比结果,数据选用指标为ADD或ADDS. 当使用“Real+syn”进行训练时,Binocular-RNN的性能与PVNet、Single-Stage、GDR-NET等网络相近. 利用每个对象训练一个网络能够轻易超越目前的技术水平. 利用“Real+PBR”训练的Binocular-RNN的性能甚至超过了基于精细化的方法DeepIM. ...
... [
19 ]
√ 1 — 88.1 81.9 25 CosyPose[20 ] √ 1 — 89.8 84.5 25 如表2 所示为Binocular-RNN与其他方法在LM-O上的对比结果,数据选用指标为ADD或ADDS. 当使用“Real+syn”进行训练时,Binocular-RNN的性能与PVNet、Single-Stage、GDR-NET等网络相近. 利用每个对象训练一个网络能够轻易超越目前的技术水平. 利用“Real+PBR”训练的Binocular-RNN的性能甚至超过了基于精细化的方法DeepIM. ...
1
... Comparison of Binocular-RNN with other methods on YCB-Video Dataset
Tab.1 方法 Ref m Acc(ADD(S))/ AUC/% t s /ms ADDS ADD(S) Only-RNN — 1 — — — — Only-CNN — 1 18.4 62.3 59.6 35 Only-CNN — M 15.6 — — — Binocular-RNN — 1 56.7 90.8 85.2 23 Binocular-RNN — M 70.5 93.4 89.6 — PoseCNN[19 ] — 1 21.3 75.9 61.3 24 GDR-Net — 1 49.1 89.1 80.2 22 GDR-Net — M 60.1 91.6 84.4 — Single-Stage[16 ] — M 53.9 — — — DeepIM[19 ] √ 1 — 88.1 81.9 25 CosyPose[20 ] √ 1 — 89.8 84.5 25
如表2 所示为Binocular-RNN与其他方法在LM-O上的对比结果,数据选用指标为ADD或ADDS. 当使用“Real+syn”进行训练时,Binocular-RNN的性能与PVNet、Single-Stage、GDR-NET等网络相近. 利用每个对象训练一个网络能够轻易超越目前的技术水平. 利用“Real+PBR”训练的Binocular-RNN的性能甚至超过了基于精细化的方法DeepIM. ...
循环神经网络研究综述
1
2022
... 选用YCB-Video Dataset与LM-O数据集进行实验,在训练中使用颜色增强[1 ] 防止过拟合. 由于YCB-Video Dataset中对称对象的数量较多,采用逻辑回归模型. 如表1 所示为Binocular-RNN与其他方法在YCB-Video Dataset上的对比结果. 表中,Ref表示是否对方法得出的结果进行优化,M 表示YCB-Video Dataset中模型的数量,t s 为训练单个对象的消耗时间. Binocular-RNN综合2个不同视角得到的信息,因此即使在各场景物体遮挡度较大的情况下,其预测性能较其他以单一视角对物体姿态进行检测的技术也更加优异. 具体而言,在以单一物体对网络训练时,Binocular-RNN的ADD或ADDS指标得分是PoseCNN得分的2.66倍,是GDR-Net得分的1.15倍. 循环卷积网络可以自动学习提取与重新识别相关的时空特征,可以长时间保留输入信息[21 ] . 同时,RNN有反馈连接,允许它随着时间重新记忆和利用信息[22 ] . 将Binocular-RNN网络拆解为RNN网络和CNN网络,结果表明仅使用本网络拆解下的循环网络无法完成实验. 同时将Binocular-RNN网络与不使用循环网络的CNN网络相比,Binocular-RNN网络ADD或ADDS指标得分是其的3.08倍,表明将循环网络嵌入到网络体系结构中提高了网络的性能. ...
循环神经网络研究综述
1
2022
... 选用YCB-Video Dataset与LM-O数据集进行实验,在训练中使用颜色增强[1 ] 防止过拟合. 由于YCB-Video Dataset中对称对象的数量较多,采用逻辑回归模型. 如表1 所示为Binocular-RNN与其他方法在YCB-Video Dataset上的对比结果. 表中,Ref表示是否对方法得出的结果进行优化,M 表示YCB-Video Dataset中模型的数量,t s 为训练单个对象的消耗时间. Binocular-RNN综合2个不同视角得到的信息,因此即使在各场景物体遮挡度较大的情况下,其预测性能较其他以单一视角对物体姿态进行检测的技术也更加优异. 具体而言,在以单一物体对网络训练时,Binocular-RNN的ADD或ADDS指标得分是PoseCNN得分的2.66倍,是GDR-Net得分的1.15倍. 循环卷积网络可以自动学习提取与重新识别相关的时空特征,可以长时间保留输入信息[21 ] . 同时,RNN有反馈连接,允许它随着时间重新记忆和利用信息[22 ] . 将Binocular-RNN网络拆解为RNN网络和CNN网络,结果表明仅使用本网络拆解下的循环网络无法完成实验. 同时将Binocular-RNN网络与不使用循环网络的CNN网络相比,Binocular-RNN网络ADD或ADDS指标得分是其的3.08倍,表明将循环网络嵌入到网络体系结构中提高了网络的性能. ...
1
... 选用YCB-Video Dataset与LM-O数据集进行实验,在训练中使用颜色增强[1 ] 防止过拟合. 由于YCB-Video Dataset中对称对象的数量较多,采用逻辑回归模型. 如表1 所示为Binocular-RNN与其他方法在YCB-Video Dataset上的对比结果. 表中,Ref表示是否对方法得出的结果进行优化,M 表示YCB-Video Dataset中模型的数量,t s 为训练单个对象的消耗时间. Binocular-RNN综合2个不同视角得到的信息,因此即使在各场景物体遮挡度较大的情况下,其预测性能较其他以单一视角对物体姿态进行检测的技术也更加优异. 具体而言,在以单一物体对网络训练时,Binocular-RNN的ADD或ADDS指标得分是PoseCNN得分的2.66倍,是GDR-Net得分的1.15倍. 循环卷积网络可以自动学习提取与重新识别相关的时空特征,可以长时间保留输入信息[21 ] . 同时,RNN有反馈连接,允许它随着时间重新记忆和利用信息[22 ] . 将Binocular-RNN网络拆解为RNN网络和CNN网络,结果表明仅使用本网络拆解下的循环网络无法完成实验. 同时将Binocular-RNN网络与不使用循环网络的CNN网络相比,Binocular-RNN网络ADD或ADDS指标得分是其的3.08倍,表明将循环网络嵌入到网络体系结构中提高了网络的性能. ...
1
... 在使用Yolov5探测器对图像尺寸为640×480像素的图像物体进行预测时,用GDR-Net预测单个对象需要约22 ms,同时预测8个对象需要约35 ms[4 ] . Binocular-RNN在预测单个对象需要约23 ms,预测8个对象需要约35ms. 但相对于主动视觉预测时间大于等于100 ms[23 ] 的情况而言,实时性已经得到了大幅度提高. ...
1
... 在使用Yolov5探测器对图像尺寸为640×480像素的图像物体进行预测时,用GDR-Net预测单个对象需要约22 ms,同时预测8个对象需要约35 ms[4 ] . Binocular-RNN在预测单个对象需要约23 ms,预测8个对象需要约35ms. 但相对于主动视觉预测时间大于等于100 ms[23 ] 的情况而言,实时性已经得到了大幅度提高. ...
1
... 实验表明该方法较GDR-Net及其他以单一视角对物体姿态进行检测的技术更加优异. 具体而言,在以单一物体对网络进行训练时,Binocular-RNN ADD或ADDS得分为PoseCNN的2.66倍,为GDR-Net的1.15倍. 利用“real+PBR”[24 ] 训练的Binocular-RNN的性能甚至超过了基于精细化的方法DeepIM. 实时性相对主动视觉得到了大幅度提高. ...
1
... 实验表明该方法较GDR-Net及其他以单一视角对物体姿态进行检测的技术更加优异. 具体而言,在以单一物体对网络进行训练时,Binocular-RNN ADD或ADDS得分为PoseCNN的2.66倍,为GDR-Net的1.15倍. 利用“real+PBR”[24 ] 训练的Binocular-RNN的性能甚至超过了基于精细化的方法DeepIM. 实时性相对主动视觉得到了大幅度提高. ...


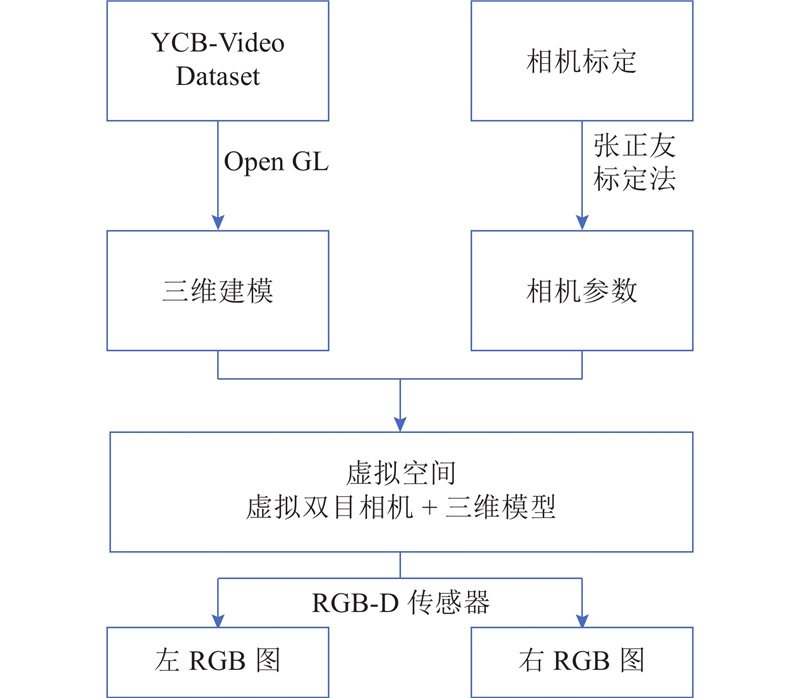
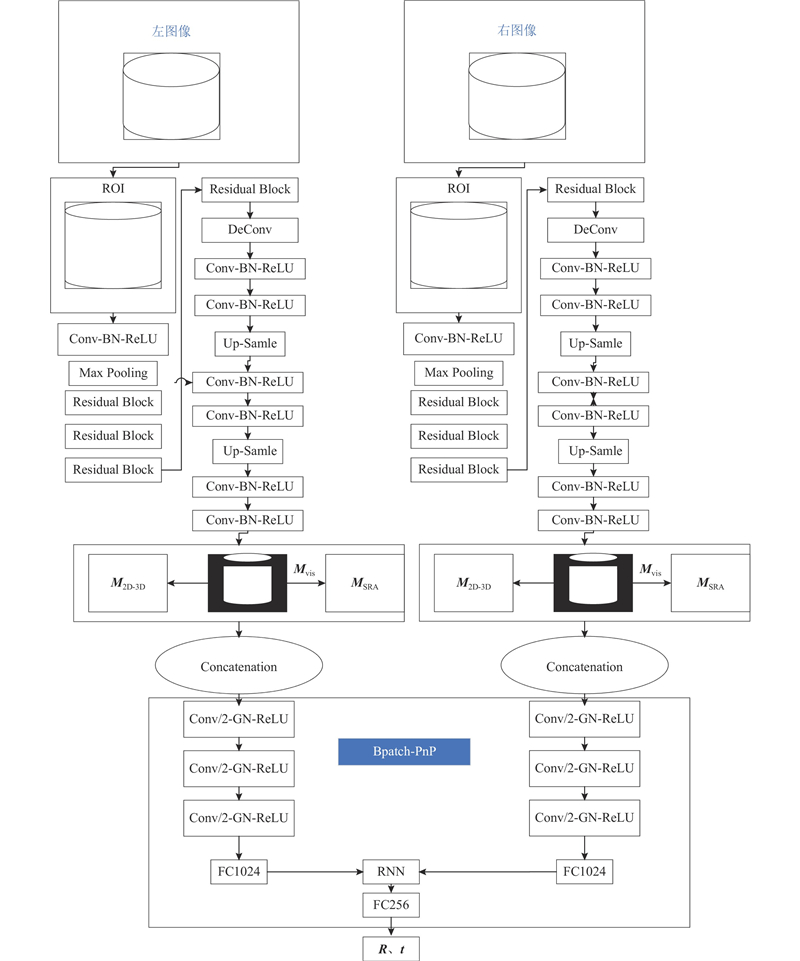
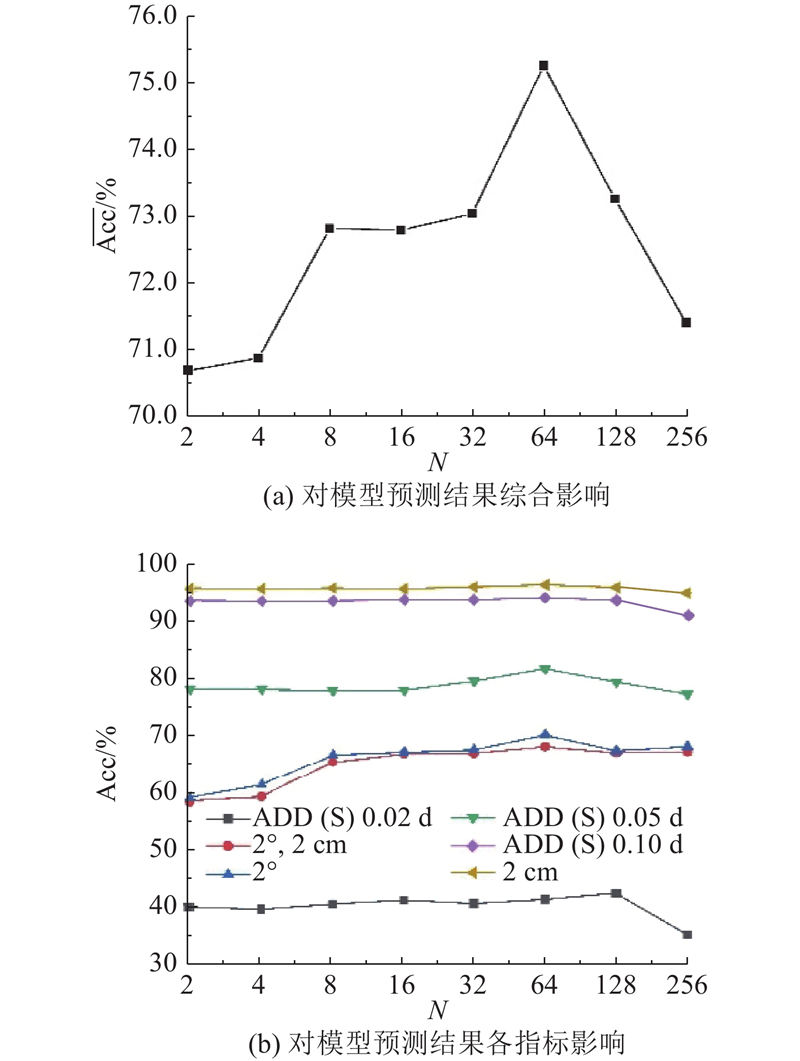

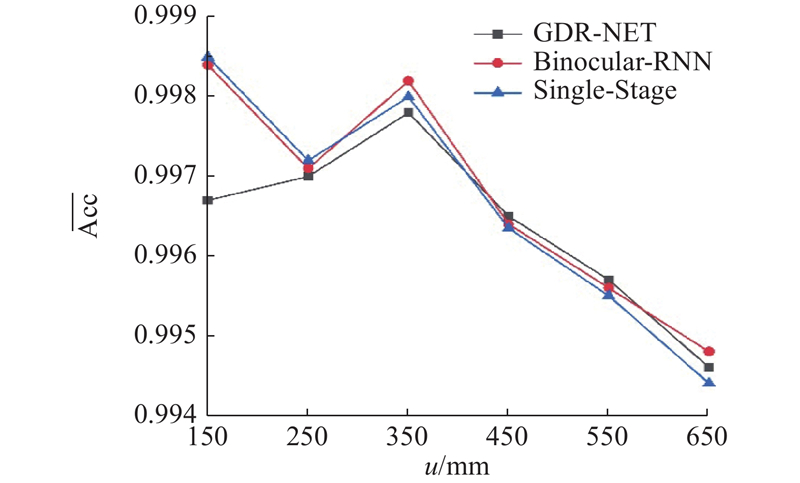

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}