[1]
奉志强, 谢志军, 包正伟, 等 基于改进 YOLOv5的无人机实时密集小目标检测算法
[J]. 航空学报 , 2023 , 44 (3 ): 327106
[本文引用: 1]
FENG Zhi-qiang, XIE Zhi-jun, BAO Zheng-wei, et al Real-time dense small object detection algorithm for UAV based on improved YOLOv5
[J]. Acta Aeronautica et Astronautica Sinica , 2023 , 44 (3 ): 327106
[本文引用: 1]
[2]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779-788.
[本文引用: 1]
[3]
REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 6517-6525.
[4]
REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. [2022-06-20]. https://arxiv.org/abs/1804.02767.
[5]
BOCHKOVSKIY A, WANG C Y, LIA O H. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. [ 2022-06-20] . https://arxiv.org/abs/2004.10934.
[本文引用: 1]
[6]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// European Conference on Computer Vision . [S.l.]: Springer, 2016: 21-37.
[本文引用: 1]
[7]
李科岑, 王晓强, 林浩, 等 深度学习中的单阶段小目标检测方法综述
[J]. 计算机科学与探索 , 2022 , 16 (1 ): 41 - 58
[本文引用: 1]
LI Ke-cen, WANG Xiao-qiang, LIN Hao, et al Survey of one-stage small object detection methods in deep learning
[J]. Journal of Frontiers of Computer Science and Technology , 2022 , 16 (1 ): 41 - 58
[本文引用: 1]
[8]
XIE L C, XUE Y L, YE J Z. UAV aerial photography target detection algorithm based on improved YOLOv5 [C]// Journal of Physics: Conference Series . [S.l.]: IOP Publishing, 2022, 2284(1): 012024.
[本文引用: 1]
[9]
YANG Y Z. Drone-view object detection based on the improved YOLOv5 [C]// Proceedings of the IEEE International Conference on Electrical Engineering , Big Data and Algorithms . Changchun: IEEE, 2022: 612-617.
[本文引用: 1]
[10]
吴萌萌, 张泽斌, 宋尧哲, 等. 基于自适应特征增强的小目标检测网络[J/OL]. 激光与光电子学进展, 2023, 60(6): 0610004. [20222-06-20]. https://www.opticsjournal.net/Articles/OJ7e6f90484b1776fd/References.
[本文引用: 1]
WU Meng-meng, ZHANG Ze-bin, SONG Yao-zhe, et al. Small object detection network based on adaptive feature enhancement [J/OL]. Advances in Laser and Opt-oelectronics , 2023, 60(66): 0610004. [2022-06-20]. https://www.opticsjournal.net/Articles/OJ7e6f90484b1776fd/References.
[本文引用: 1]
[11]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7132-7141.
[本文引用: 1]
[12]
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2117-2125.
[本文引用: 1]
[13]
LI H, XIONG P, AN J, et al. Pyramid attention network for semantic segmentation [EB/OL]. [2022-06-20]. https://arxiv.org/abs/1805.10180.
[本文引用: 1]
[14]
LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8759–8768.
[本文引用: 1]
[15]
ZHANG Y F, REN W, ZHANG Z, et al Focal and efficient IOU loss for accurate bounding box regression
[J]. Neurocomputing , 2022 , 506 : 146 - 157
DOI:10.1016/j.neucom.2022.07.042
[本文引用: 1]
[16]
LI Y , CHEN Y , WANG N , et al. Scale-aware trident networks for object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 6054-6063.
[本文引用: 1]
[17]
CHEN C, ZHANG Y, LV Q, et al. RRNet: a hybrid detector for object detection in drone-captured images [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop . Seoul: IEEE, 2019: 100-108.
[本文引用: 1]
[18]
ZHOU X, WANG D, KRAHENBUHL P. Objects as points [EB/OL]. [ 2022-06-20] . https://arxiv.org/abs/1904.07850.
[本文引用: 1]
[19]
ALI S, SIDDIQUE A, ATES H F, et al. Improved YOLOv4 for aerial object detection [C]// Proceedings of the 29th Signal Processing and Communications Applications Conference . Istanbul: IEEE, 2021: 1-4.
[本文引用: 1]
[20]
ZHAO H, ZHOU Y, ZHANG L, et al Mixed YOLOv3-LITE: a lightweight real-time object detection method
[J]. Sensors , 2020 , 20 (7 ): 1861
DOI:10.3390/s20071861
[本文引用: 1]
[21]
DU D W, WEN L Y, ZHU P F, et al. VisDrone-DET2020: the vision meets drone object detection in image challenge results [C]// Proceedings of the European Conference on Computer Vision . [S.l.]: Springer, 2020: 692-712.
[本文引用: 1]
[22]
YU W P, YANG T J N, CHEN C. Towards resolving the challenge of long-tail distribution in UAV images for object detection [C]// Proceedings of the IEEE Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2021: 3257-3266.
[本文引用: 1]
基于改进 YOLOv5的无人机实时密集小目标检测算法
1
2023
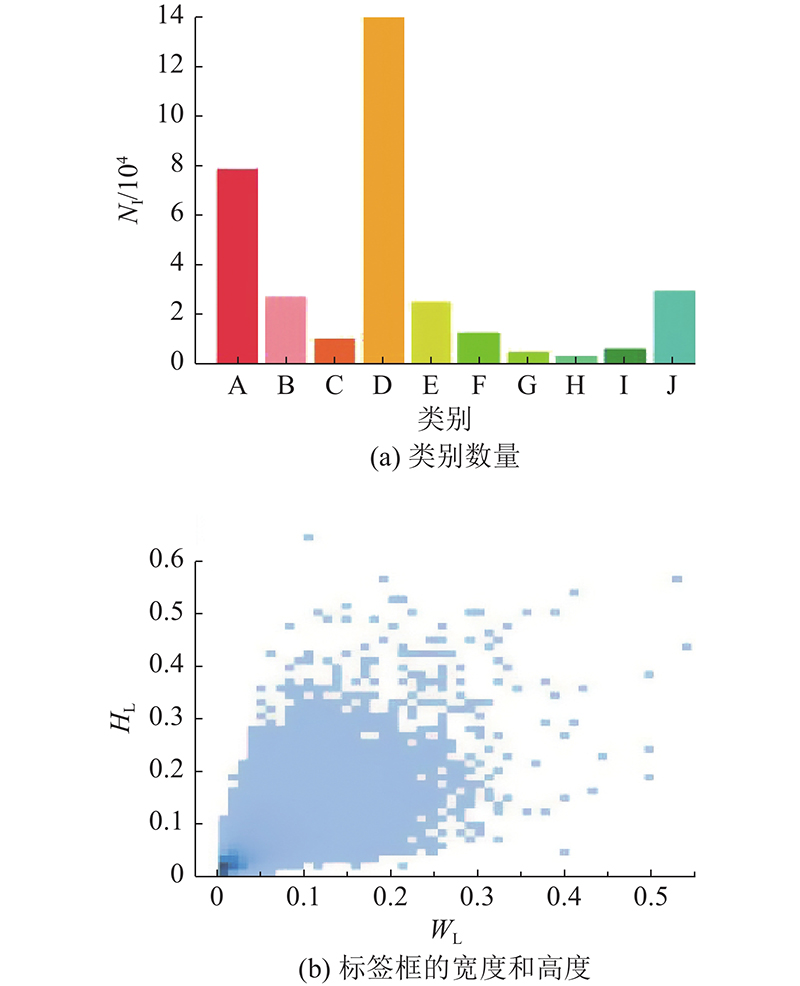
... 无人机具有成本低、灵活性高、操作简单、体积小等优点,可以弥补卫星和载人航空遥感技术的不足. 无人机与基于深度学习的目标检测技术的结合已在智慧农业、智慧城市、交通监控等领域发挥了重要作用[1 ] . 目标检测任务主要面向自然场景图像,但无人机拍摄的图像与自然场景图像存在巨大差异. 1)无人机的飞行高度导致无人机拍摄的图像存在大量分辨率小于32×32 像素的小物体;小物体分布密集,可提取的特征少. 2)在无人机拍摄过程中存在图像背景复杂、目标相互遮挡、拍摄光线不足等问题. 因此,直接将现有算法应用于无人机领域效果较差,研究适用于无人机的目标检测算法有着重大意义. ...
基于改进 YOLOv5的无人机实时密集小目标检测算法
1
2023
... 无人机具有成本低、灵活性高、操作简单、体积小等优点,可以弥补卫星和载人航空遥感技术的不足. 无人机与基于深度学习的目标检测技术的结合已在智慧农业、智慧城市、交通监控等领域发挥了重要作用[1 ] . 目标检测任务主要面向自然场景图像,但无人机拍摄的图像与自然场景图像存在巨大差异. 1)无人机的飞行高度导致无人机拍摄的图像存在大量分辨率小于32×32 像素的小物体;小物体分布密集,可提取的特征少. 2)在无人机拍摄过程中存在图像背景复杂、目标相互遮挡、拍摄光线不足等问题. 因此,直接将现有算法应用于无人机领域效果较差,研究适用于无人机的目标检测算法有着重大意义. ...
1
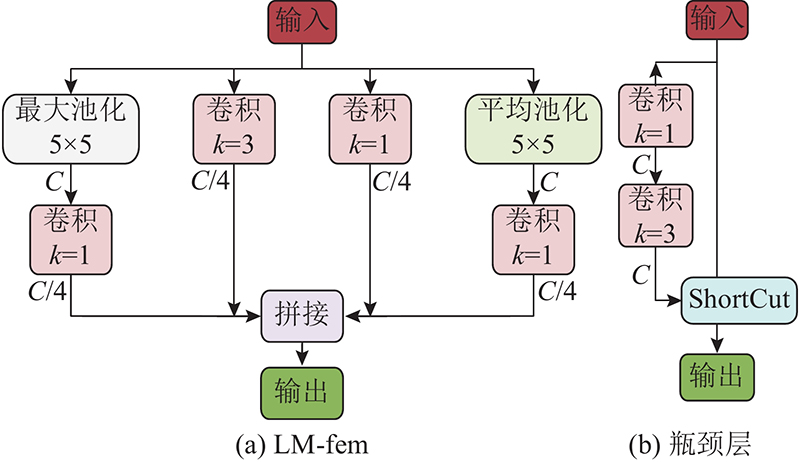
... 基于深度学习的目标检测算法可以分为基于回归的单阶段(one-stage)目标检测算法和基于候选区域的两阶段(two-stage)目标检测算法. 两阶段检测算法分为2个阶段:1)生成目标的候选区域,2)对候选区域中的候选框大小和位置进行预测,生成预测框. 两阶段检测算法识别准确率和定位精度效果较好,但检测速度和实时性较低. 针对两阶段检测算法的缺点,提出基于单阶段检测器的YOLO(you only look once)系列算法[2 -5 ] 和单激发多框探测器(single shot multibox detector,SSD)算法[6 ] . 单阶段检测算法直接对目标的坐标和类别进行回归,这种端到端的检测方式使得检测精度高且检测速度达到45 帧/s[7 ] . 2020年提出的YOLOv5是YOLO系列的第5个版本,该算法在保持较高检测速度的同时显著提高了检测精度,被广泛应用于无人机图像目标检测. Xie等[8 ] 1)在YOLOv5的基础上增加针对小目标的检测头,2)在特征融合层为融合特征分配权重,3)优化损失函数;实验表明,改进后的算法对背景复杂、小目标密集的场景具有很好的检测性能. 但改进后的算法在不同层的特征融合依旧是简单的线性操作(串联或求和),不能根据特征所在场景的不同进行自适应特征权重分配. Yang[9 ] 在YOLOv5网络的颈部增加上采样,形成用于收集小目标特征的特征图,通过沿着通道维度的拼接(concat)形成新的特征提取层,增强了算法的小目标检测能力. 但改进后的算法提取到的小目标特征信息较少,且检测速度较慢,实时性不足以满足实际需求. 吴萌萌等[10 ] 在YOLOv5s的基础上融合特征融合因子,设计改进的自适应双向特征融合模块(M-BiFPN),使网络的特征表达能力提升. M-BiFPN的损失函数设计未考虑数据集长尾分布的特点,因此算法对大目标的检测性能提升不够明显. ...
1
... 基于深度学习的目标检测算法可以分为基于回归的单阶段(one-stage)目标检测算法和基于候选区域的两阶段(two-stage)目标检测算法. 两阶段检测算法分为2个阶段:1)生成目标的候选区域,2)对候选区域中的候选框大小和位置进行预测,生成预测框. 两阶段检测算法识别准确率和定位精度效果较好,但检测速度和实时性较低. 针对两阶段检测算法的缺点,提出基于单阶段检测器的YOLO(you only look once)系列算法[2 -5 ] 和单激发多框探测器(single shot multibox detector,SSD)算法[6 ] . 单阶段检测算法直接对目标的坐标和类别进行回归,这种端到端的检测方式使得检测精度高且检测速度达到45 帧/s[7 ] . 2020年提出的YOLOv5是YOLO系列的第5个版本,该算法在保持较高检测速度的同时显著提高了检测精度,被广泛应用于无人机图像目标检测. Xie等[8 ] 1)在YOLOv5的基础上增加针对小目标的检测头,2)在特征融合层为融合特征分配权重,3)优化损失函数;实验表明,改进后的算法对背景复杂、小目标密集的场景具有很好的检测性能. 但改进后的算法在不同层的特征融合依旧是简单的线性操作(串联或求和),不能根据特征所在场景的不同进行自适应特征权重分配. Yang[9 ] 在YOLOv5网络的颈部增加上采样,形成用于收集小目标特征的特征图,通过沿着通道维度的拼接(concat)形成新的特征提取层,增强了算法的小目标检测能力. 但改进后的算法提取到的小目标特征信息较少,且检测速度较慢,实时性不足以满足实际需求. 吴萌萌等[10 ] 在YOLOv5s的基础上融合特征融合因子,设计改进的自适应双向特征融合模块(M-BiFPN),使网络的特征表达能力提升. M-BiFPN的损失函数设计未考虑数据集长尾分布的特点,因此算法对大目标的检测性能提升不够明显. ...
1
... 基于深度学习的目标检测算法可以分为基于回归的单阶段(one-stage)目标检测算法和基于候选区域的两阶段(two-stage)目标检测算法. 两阶段检测算法分为2个阶段:1)生成目标的候选区域,2)对候选区域中的候选框大小和位置进行预测,生成预测框. 两阶段检测算法识别准确率和定位精度效果较好,但检测速度和实时性较低. 针对两阶段检测算法的缺点,提出基于单阶段检测器的YOLO(you only look once)系列算法[2 -5 ] 和单激发多框探测器(single shot multibox detector,SSD)算法[6 ] . 单阶段检测算法直接对目标的坐标和类别进行回归,这种端到端的检测方式使得检测精度高且检测速度达到45 帧/s[7 ] . 2020年提出的YOLOv5是YOLO系列的第5个版本,该算法在保持较高检测速度的同时显著提高了检测精度,被广泛应用于无人机图像目标检测. Xie等[8 ] 1)在YOLOv5的基础上增加针对小目标的检测头,2)在特征融合层为融合特征分配权重,3)优化损失函数;实验表明,改进后的算法对背景复杂、小目标密集的场景具有很好的检测性能. 但改进后的算法在不同层的特征融合依旧是简单的线性操作(串联或求和),不能根据特征所在场景的不同进行自适应特征权重分配. Yang[9 ] 在YOLOv5网络的颈部增加上采样,形成用于收集小目标特征的特征图,通过沿着通道维度的拼接(concat)形成新的特征提取层,增强了算法的小目标检测能力. 但改进后的算法提取到的小目标特征信息较少,且检测速度较慢,实时性不足以满足实际需求. 吴萌萌等[10 ] 在YOLOv5s的基础上融合特征融合因子,设计改进的自适应双向特征融合模块(M-BiFPN),使网络的特征表达能力提升. M-BiFPN的损失函数设计未考虑数据集长尾分布的特点,因此算法对大目标的检测性能提升不够明显. ...
深度学习中的单阶段小目标检测方法综述
1
2022
... 基于深度学习的目标检测算法可以分为基于回归的单阶段(one-stage)目标检测算法和基于候选区域的两阶段(two-stage)目标检测算法. 两阶段检测算法分为2个阶段:1)生成目标的候选区域,2)对候选区域中的候选框大小和位置进行预测,生成预测框. 两阶段检测算法识别准确率和定位精度效果较好,但检测速度和实时性较低. 针对两阶段检测算法的缺点,提出基于单阶段检测器的YOLO(you only look once)系列算法[2 -5 ] 和单激发多框探测器(single shot multibox detector,SSD)算法[6 ] . 单阶段检测算法直接对目标的坐标和类别进行回归,这种端到端的检测方式使得检测精度高且检测速度达到45 帧/s[7 ] . 2020年提出的YOLOv5是YOLO系列的第5个版本,该算法在保持较高检测速度的同时显著提高了检测精度,被广泛应用于无人机图像目标检测. Xie等[8 ] 1)在YOLOv5的基础上增加针对小目标的检测头,2)在特征融合层为融合特征分配权重,3)优化损失函数;实验表明,改进后的算法对背景复杂、小目标密集的场景具有很好的检测性能. 但改进后的算法在不同层的特征融合依旧是简单的线性操作(串联或求和),不能根据特征所在场景的不同进行自适应特征权重分配. Yang[9 ] 在YOLOv5网络的颈部增加上采样,形成用于收集小目标特征的特征图,通过沿着通道维度的拼接(concat)形成新的特征提取层,增强了算法的小目标检测能力. 但改进后的算法提取到的小目标特征信息较少,且检测速度较慢,实时性不足以满足实际需求. 吴萌萌等[10 ] 在YOLOv5s的基础上融合特征融合因子,设计改进的自适应双向特征融合模块(M-BiFPN),使网络的特征表达能力提升. M-BiFPN的损失函数设计未考虑数据集长尾分布的特点,因此算法对大目标的检测性能提升不够明显. ...
深度学习中的单阶段小目标检测方法综述
1
2022
... 基于深度学习的目标检测算法可以分为基于回归的单阶段(one-stage)目标检测算法和基于候选区域的两阶段(two-stage)目标检测算法. 两阶段检测算法分为2个阶段:1)生成目标的候选区域,2)对候选区域中的候选框大小和位置进行预测,生成预测框. 两阶段检测算法识别准确率和定位精度效果较好,但检测速度和实时性较低. 针对两阶段检测算法的缺点,提出基于单阶段检测器的YOLO(you only look once)系列算法[2 -5 ] 和单激发多框探测器(single shot multibox detector,SSD)算法[6 ] . 单阶段检测算法直接对目标的坐标和类别进行回归,这种端到端的检测方式使得检测精度高且检测速度达到45 帧/s[7 ] . 2020年提出的YOLOv5是YOLO系列的第5个版本,该算法在保持较高检测速度的同时显著提高了检测精度,被广泛应用于无人机图像目标检测. Xie等[8 ] 1)在YOLOv5的基础上增加针对小目标的检测头,2)在特征融合层为融合特征分配权重,3)优化损失函数;实验表明,改进后的算法对背景复杂、小目标密集的场景具有很好的检测性能. 但改进后的算法在不同层的特征融合依旧是简单的线性操作(串联或求和),不能根据特征所在场景的不同进行自适应特征权重分配. Yang[9 ] 在YOLOv5网络的颈部增加上采样,形成用于收集小目标特征的特征图,通过沿着通道维度的拼接(concat)形成新的特征提取层,增强了算法的小目标检测能力. 但改进后的算法提取到的小目标特征信息较少,且检测速度较慢,实时性不足以满足实际需求. 吴萌萌等[10 ] 在YOLOv5s的基础上融合特征融合因子,设计改进的自适应双向特征融合模块(M-BiFPN),使网络的特征表达能力提升. M-BiFPN的损失函数设计未考虑数据集长尾分布的特点,因此算法对大目标的检测性能提升不够明显. ...
1
... 基于深度学习的目标检测算法可以分为基于回归的单阶段(one-stage)目标检测算法和基于候选区域的两阶段(two-stage)目标检测算法. 两阶段检测算法分为2个阶段:1)生成目标的候选区域,2)对候选区域中的候选框大小和位置进行预测,生成预测框. 两阶段检测算法识别准确率和定位精度效果较好,但检测速度和实时性较低. 针对两阶段检测算法的缺点,提出基于单阶段检测器的YOLO(you only look once)系列算法[2 -5 ] 和单激发多框探测器(single shot multibox detector,SSD)算法[6 ] . 单阶段检测算法直接对目标的坐标和类别进行回归,这种端到端的检测方式使得检测精度高且检测速度达到45 帧/s[7 ] . 2020年提出的YOLOv5是YOLO系列的第5个版本,该算法在保持较高检测速度的同时显著提高了检测精度,被广泛应用于无人机图像目标检测. Xie等[8 ] 1)在YOLOv5的基础上增加针对小目标的检测头,2)在特征融合层为融合特征分配权重,3)优化损失函数;实验表明,改进后的算法对背景复杂、小目标密集的场景具有很好的检测性能. 但改进后的算法在不同层的特征融合依旧是简单的线性操作(串联或求和),不能根据特征所在场景的不同进行自适应特征权重分配. Yang[9 ] 在YOLOv5网络的颈部增加上采样,形成用于收集小目标特征的特征图,通过沿着通道维度的拼接(concat)形成新的特征提取层,增强了算法的小目标检测能力. 但改进后的算法提取到的小目标特征信息较少,且检测速度较慢,实时性不足以满足实际需求. 吴萌萌等[10 ] 在YOLOv5s的基础上融合特征融合因子,设计改进的自适应双向特征融合模块(M-BiFPN),使网络的特征表达能力提升. M-BiFPN的损失函数设计未考虑数据集长尾分布的特点,因此算法对大目标的检测性能提升不够明显. ...
1
... 基于深度学习的目标检测算法可以分为基于回归的单阶段(one-stage)目标检测算法和基于候选区域的两阶段(two-stage)目标检测算法. 两阶段检测算法分为2个阶段:1)生成目标的候选区域,2)对候选区域中的候选框大小和位置进行预测,生成预测框. 两阶段检测算法识别准确率和定位精度效果较好,但检测速度和实时性较低. 针对两阶段检测算法的缺点,提出基于单阶段检测器的YOLO(you only look once)系列算法[2 -5 ] 和单激发多框探测器(single shot multibox detector,SSD)算法[6 ] . 单阶段检测算法直接对目标的坐标和类别进行回归,这种端到端的检测方式使得检测精度高且检测速度达到45 帧/s[7 ] . 2020年提出的YOLOv5是YOLO系列的第5个版本,该算法在保持较高检测速度的同时显著提高了检测精度,被广泛应用于无人机图像目标检测. Xie等[8 ] 1)在YOLOv5的基础上增加针对小目标的检测头,2)在特征融合层为融合特征分配权重,3)优化损失函数;实验表明,改进后的算法对背景复杂、小目标密集的场景具有很好的检测性能. 但改进后的算法在不同层的特征融合依旧是简单的线性操作(串联或求和),不能根据特征所在场景的不同进行自适应特征权重分配. Yang[9 ] 在YOLOv5网络的颈部增加上采样,形成用于收集小目标特征的特征图,通过沿着通道维度的拼接(concat)形成新的特征提取层,增强了算法的小目标检测能力. 但改进后的算法提取到的小目标特征信息较少,且检测速度较慢,实时性不足以满足实际需求. 吴萌萌等[10 ] 在YOLOv5s的基础上融合特征融合因子,设计改进的自适应双向特征融合模块(M-BiFPN),使网络的特征表达能力提升. M-BiFPN的损失函数设计未考虑数据集长尾分布的特点,因此算法对大目标的检测性能提升不够明显. ...
1
... 基于深度学习的目标检测算法可以分为基于回归的单阶段(one-stage)目标检测算法和基于候选区域的两阶段(two-stage)目标检测算法. 两阶段检测算法分为2个阶段:1)生成目标的候选区域,2)对候选区域中的候选框大小和位置进行预测,生成预测框. 两阶段检测算法识别准确率和定位精度效果较好,但检测速度和实时性较低. 针对两阶段检测算法的缺点,提出基于单阶段检测器的YOLO(you only look once)系列算法[2 -5 ] 和单激发多框探测器(single shot multibox detector,SSD)算法[6 ] . 单阶段检测算法直接对目标的坐标和类别进行回归,这种端到端的检测方式使得检测精度高且检测速度达到45 帧/s[7 ] . 2020年提出的YOLOv5是YOLO系列的第5个版本,该算法在保持较高检测速度的同时显著提高了检测精度,被广泛应用于无人机图像目标检测. Xie等[8 ] 1)在YOLOv5的基础上增加针对小目标的检测头,2)在特征融合层为融合特征分配权重,3)优化损失函数;实验表明,改进后的算法对背景复杂、小目标密集的场景具有很好的检测性能. 但改进后的算法在不同层的特征融合依旧是简单的线性操作(串联或求和),不能根据特征所在场景的不同进行自适应特征权重分配. Yang[9 ] 在YOLOv5网络的颈部增加上采样,形成用于收集小目标特征的特征图,通过沿着通道维度的拼接(concat)形成新的特征提取层,增强了算法的小目标检测能力. 但改进后的算法提取到的小目标特征信息较少,且检测速度较慢,实时性不足以满足实际需求. 吴萌萌等[10 ] 在YOLOv5s的基础上融合特征融合因子,设计改进的自适应双向特征融合模块(M-BiFPN),使网络的特征表达能力提升. M-BiFPN的损失函数设计未考虑数据集长尾分布的特点,因此算法对大目标的检测性能提升不够明显. ...
1
... 基于深度学习的目标检测算法可以分为基于回归的单阶段(one-stage)目标检测算法和基于候选区域的两阶段(two-stage)目标检测算法. 两阶段检测算法分为2个阶段:1)生成目标的候选区域,2)对候选区域中的候选框大小和位置进行预测,生成预测框. 两阶段检测算法识别准确率和定位精度效果较好,但检测速度和实时性较低. 针对两阶段检测算法的缺点,提出基于单阶段检测器的YOLO(you only look once)系列算法[2 -5 ] 和单激发多框探测器(single shot multibox detector,SSD)算法[6 ] . 单阶段检测算法直接对目标的坐标和类别进行回归,这种端到端的检测方式使得检测精度高且检测速度达到45 帧/s[7 ] . 2020年提出的YOLOv5是YOLO系列的第5个版本,该算法在保持较高检测速度的同时显著提高了检测精度,被广泛应用于无人机图像目标检测. Xie等[8 ] 1)在YOLOv5的基础上增加针对小目标的检测头,2)在特征融合层为融合特征分配权重,3)优化损失函数;实验表明,改进后的算法对背景复杂、小目标密集的场景具有很好的检测性能. 但改进后的算法在不同层的特征融合依旧是简单的线性操作(串联或求和),不能根据特征所在场景的不同进行自适应特征权重分配. Yang[9 ] 在YOLOv5网络的颈部增加上采样,形成用于收集小目标特征的特征图,通过沿着通道维度的拼接(concat)形成新的特征提取层,增强了算法的小目标检测能力. 但改进后的算法提取到的小目标特征信息较少,且检测速度较慢,实时性不足以满足实际需求. 吴萌萌等[10 ] 在YOLOv5s的基础上融合特征融合因子,设计改进的自适应双向特征融合模块(M-BiFPN),使网络的特征表达能力提升. M-BiFPN的损失函数设计未考虑数据集长尾分布的特点,因此算法对大目标的检测性能提升不够明显. ...
1
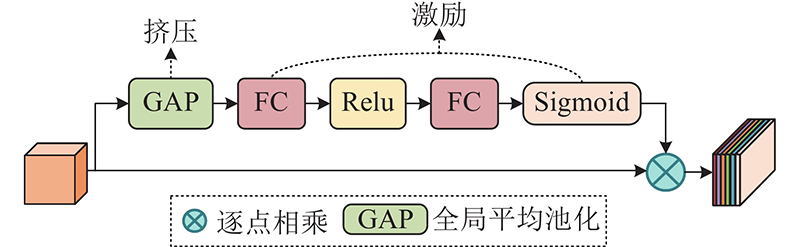
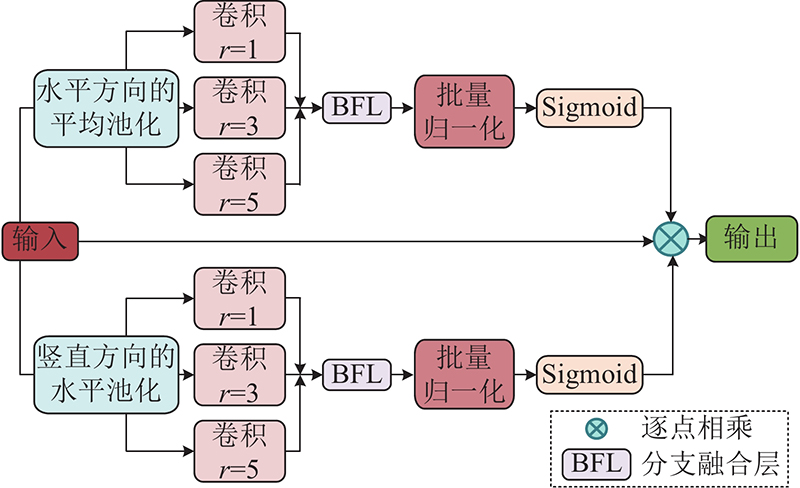
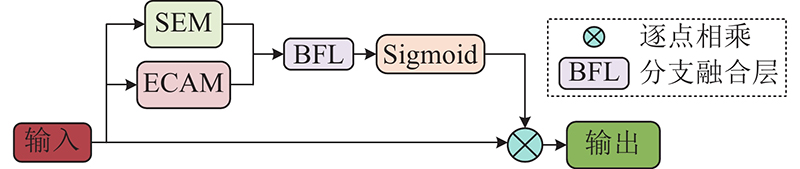
... 挤压激励模块 (squeeze-and-excitation module,SEM[11 ] )关注特征图通道之间的关系,通过生成维持通道间相关性的注意力权重图,让模型学习到不同通道的重要程度从而对其加权,显式建模不同通道之间的关系. SEM的网络结构图如图3 所示. 图中,FC为全连接层,Relu、Sigmoid均为激活函数. SEM模块只考虑通道信息的编码,忽视了空间位置信息,由于空间位置信息的获取对检测无人机的拍摄图像至关重要,本研究提出更加关注空间位置信息的注意力模块(enhanced spatial location attention mechanism,ECAM). ECAM能够从丰富的多尺度上下文信息中过滤无用信息,关注有用信息,其网络结构如图4 所示. ...
1
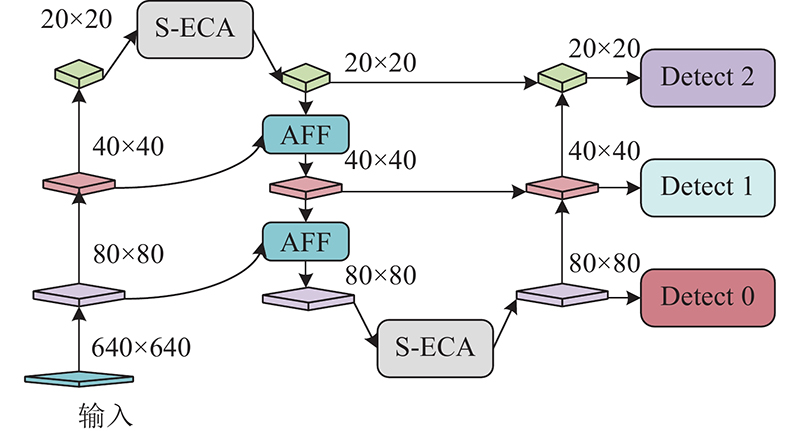
... 针对小目标检测困难的问题,YOLOv5采用自顶向下的特征金字塔网络(feature pyramid network, FPN[12 ] )结构和自底向上的金字塔注意力网络(pixel aggregation network,PAN[13 ] )结构融合浅层信息和深层信息. 来自浅层和深层的特征信息在融合时往往会产生语义冲突,而且YOLOv5s采用的融合方式只是简单拼接或者相加,在融合过程中会赋予浅层特征和深层特征相同的权重. 浅层特征包含更多细节信息,深层特征包含更多语义特征,合理的分配浅层特征和深层特征的融合权重,有利于复杂背景下的密集小目标检测. ...
1
... 针对小目标检测困难的问题,YOLOv5采用自顶向下的特征金字塔网络(feature pyramid network, FPN[12 ] )结构和自底向上的金字塔注意力网络(pixel aggregation network,PAN[13 ] )结构融合浅层信息和深层信息. 来自浅层和深层的特征信息在融合时往往会产生语义冲突,而且YOLOv5s采用的融合方式只是简单拼接或者相加,在融合过程中会赋予浅层特征和深层特征相同的权重. 浅层特征包含更多细节信息,深层特征包含更多语义特征,合理的分配浅层特征和深层特征的融合权重,有利于复杂背景下的密集小目标检测. ...
1
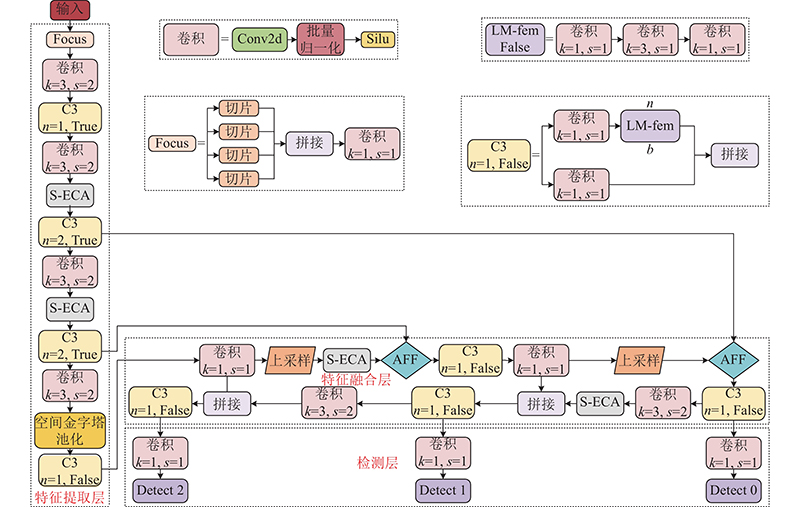
... 本研究将S-ECA模块和AFF模块应用到YOLOv5s的PANet[14 ] 结构中, 提出 $ \mathrm{S}\mathrm{A}\_\mathrm{P}\mathrm{A}\mathrm{N}\mathrm{e}\mathrm{t} $ 图7 所示. ...
Focal and efficient IOU loss for accurate bounding box regression
1
2022
... Evaluation index of detection performance of each model in ablation experiment
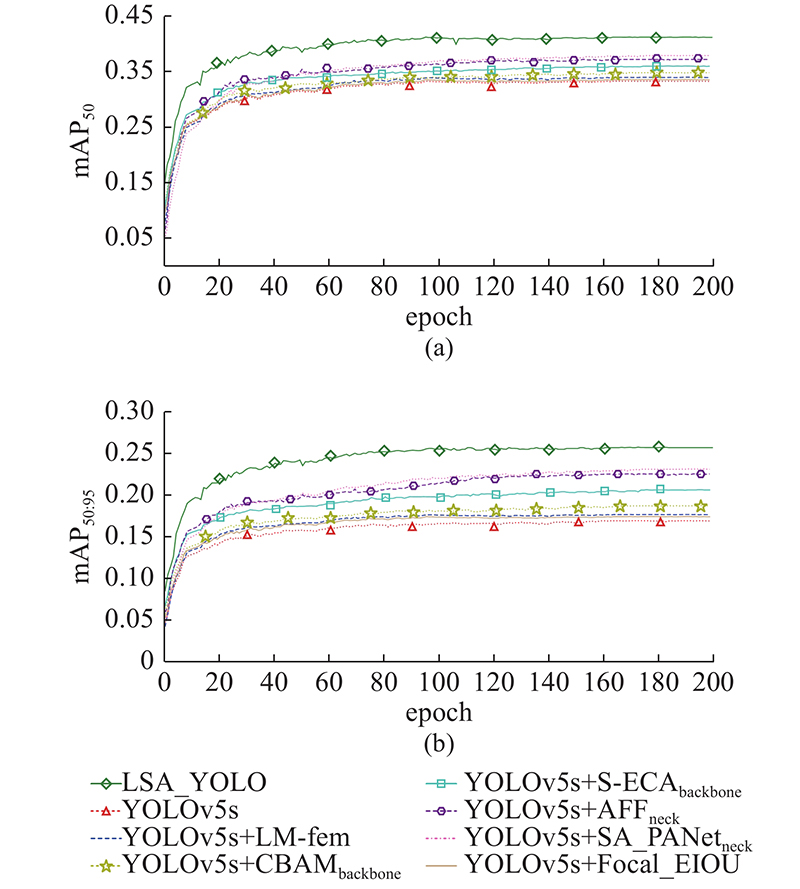
Tab.1 编号 模型 mAP $ {}_{50} $ mAP $ {}_{50:95} $ N P /106 O F /(帧·s−1 ) M /% E /% 1 YOLOv5s 33.2 16.7 6.978 15.5 125 57.5 47.2 2 YOLOv5s+LM-fem 33.9 17.5 6.920 14.9 130 55.0 45.3 3 YOLOv5s+CBAMbackbone 34.7 18.5 7.556 17.5 98 54.2 42.8 4 YOLOv5s+S-ECAbackbone 35.9 20.4 7.540 17.2 105 52.5 39.5 5 YOLOv5s+AFFneck 37.1 22.3 7.015 15.9 111 50.2 37.0 6 YOLOv5s+ $ \mathrm{S}\mathrm{A}\_\mathrm{P}\mathrm{A}\mathrm{N}\mathrm{e}\mathrm{t} $ neck 37.8 22.9 8.135 18.4 95 48.9 35.2 7 YOLOv5s+Focal-EIOU[15 ] 33.5 17.2 7.322 16.1 120 56.6 45.8 8 LSA_YOLO 41.1 25.5 9.038 20.2 50 45.7 31.5
图 9 消融实验中各模型的平均精度均值 ...
1
... Average precision and mean average precision for different algorithms on VisDrone2021 dataset
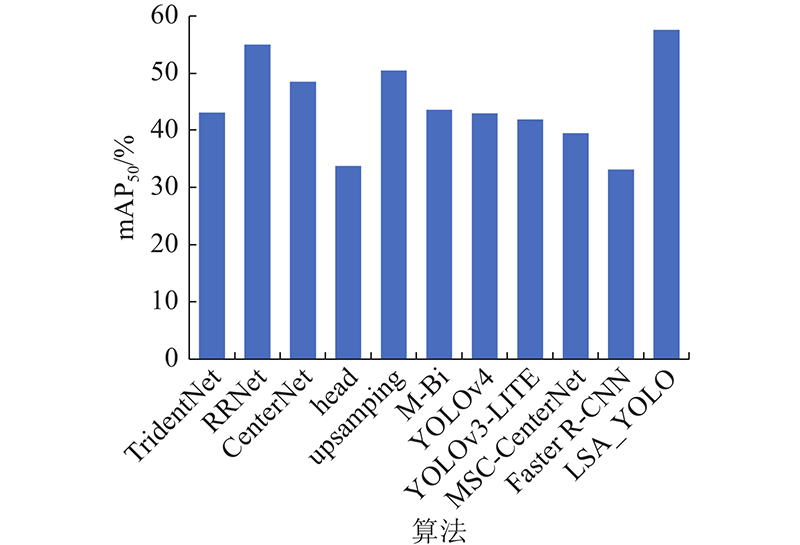
Tab.3 算法 AP/% mAP $ {}_{50} $ A B C D E F G H I J TridentNet[16 ] 22.8 9.0 5.3 46.2 30.7 25.5 21.3 16.0 39.0 17.9 43.1 RRNet[17 ] 30.5 14.8 14.1 51.5 35.8 35.2 28.8 19.0 45.0 26.0 55.0 CenterNet[18 ] 28.0 12.0 8.9 51.2 35.9 27.5 21.0 19.8 37.7 20.9 48.5 YOLOv5+head — — — — — — — — — — 33.8 YOLOv5+upsampling — — — — — — — — — — 50.5 YOLOv5+ M-Bi — — — — — — — — — — 43.6 YOLOv4[19 ] 25.0 13.1 8.5 64.2 22.5 22.6 11.5 8.0 44.5 22.0 43.0 YOLOv3-LITE[20 ] 34.6 22.9 8.0 71.2 31.4 22.1 15.5 7.1 41.3 32.7 41.9 MSC-CenterNet[21 ] 33.5 15.3 12.5 55.2 40.6 32.0 29.2 21.6 42.5 27.4 39.5 Faster R-CNN[22 ] 21.0 14.7 7.5 51.0 30.2 19.6 15.7 9.5 31.6 20.3 33.2 LSA_YOLO 37.2 25.4 18.5 58.6 35.7 35.8 29.4 21.5 47.2 28.4 57.6
图 10 不同算法在VisDrone2021数据集上的平均精度均值柱状图 ...
1
... Average precision and mean average precision for different algorithms on VisDrone2021 dataset
Tab.3 算法 AP/% mAP $ {}_{50} $ A B C D E F G H I J TridentNet[16 ] 22.8 9.0 5.3 46.2 30.7 25.5 21.3 16.0 39.0 17.9 43.1 RRNet[17 ] 30.5 14.8 14.1 51.5 35.8 35.2 28.8 19.0 45.0 26.0 55.0 CenterNet[18 ] 28.0 12.0 8.9 51.2 35.9 27.5 21.0 19.8 37.7 20.9 48.5 YOLOv5+head — — — — — — — — — — 33.8 YOLOv5+upsampling — — — — — — — — — — 50.5 YOLOv5+ M-Bi — — — — — — — — — — 43.6 YOLOv4[19 ] 25.0 13.1 8.5 64.2 22.5 22.6 11.5 8.0 44.5 22.0 43.0 YOLOv3-LITE[20 ] 34.6 22.9 8.0 71.2 31.4 22.1 15.5 7.1 41.3 32.7 41.9 MSC-CenterNet[21 ] 33.5 15.3 12.5 55.2 40.6 32.0 29.2 21.6 42.5 27.4 39.5 Faster R-CNN[22 ] 21.0 14.7 7.5 51.0 30.2 19.6 15.7 9.5 31.6 20.3 33.2 LSA_YOLO 37.2 25.4 18.5 58.6 35.7 35.8 29.4 21.5 47.2 28.4 57.6
图 10 不同算法在VisDrone2021数据集上的平均精度均值柱状图 ...
1
... Average precision and mean average precision for different algorithms on VisDrone2021 dataset
Tab.3 算法 AP/% mAP $ {}_{50} $ A B C D E F G H I J TridentNet[16 ] 22.8 9.0 5.3 46.2 30.7 25.5 21.3 16.0 39.0 17.9 43.1 RRNet[17 ] 30.5 14.8 14.1 51.5 35.8 35.2 28.8 19.0 45.0 26.0 55.0 CenterNet[18 ] 28.0 12.0 8.9 51.2 35.9 27.5 21.0 19.8 37.7 20.9 48.5 YOLOv5+head — — — — — — — — — — 33.8 YOLOv5+upsampling — — — — — — — — — — 50.5 YOLOv5+ M-Bi — — — — — — — — — — 43.6 YOLOv4[19 ] 25.0 13.1 8.5 64.2 22.5 22.6 11.5 8.0 44.5 22.0 43.0 YOLOv3-LITE[20 ] 34.6 22.9 8.0 71.2 31.4 22.1 15.5 7.1 41.3 32.7 41.9 MSC-CenterNet[21 ] 33.5 15.3 12.5 55.2 40.6 32.0 29.2 21.6 42.5 27.4 39.5 Faster R-CNN[22 ] 21.0 14.7 7.5 51.0 30.2 19.6 15.7 9.5 31.6 20.3 33.2 LSA_YOLO 37.2 25.4 18.5 58.6 35.7 35.8 29.4 21.5 47.2 28.4 57.6
图 10 不同算法在VisDrone2021数据集上的平均精度均值柱状图 ...
1
... Average precision and mean average precision for different algorithms on VisDrone2021 dataset
Tab.3 算法 AP/% mAP $ {}_{50} $ A B C D E F G H I J TridentNet[16 ] 22.8 9.0 5.3 46.2 30.7 25.5 21.3 16.0 39.0 17.9 43.1 RRNet[17 ] 30.5 14.8 14.1 51.5 35.8 35.2 28.8 19.0 45.0 26.0 55.0 CenterNet[18 ] 28.0 12.0 8.9 51.2 35.9 27.5 21.0 19.8 37.7 20.9 48.5 YOLOv5+head — — — — — — — — — — 33.8 YOLOv5+upsampling — — — — — — — — — — 50.5 YOLOv5+ M-Bi — — — — — — — — — — 43.6 YOLOv4[19 ] 25.0 13.1 8.5 64.2 22.5 22.6 11.5 8.0 44.5 22.0 43.0 YOLOv3-LITE[20 ] 34.6 22.9 8.0 71.2 31.4 22.1 15.5 7.1 41.3 32.7 41.9 MSC-CenterNet[21 ] 33.5 15.3 12.5 55.2 40.6 32.0 29.2 21.6 42.5 27.4 39.5 Faster R-CNN[22 ] 21.0 14.7 7.5 51.0 30.2 19.6 15.7 9.5 31.6 20.3 33.2 LSA_YOLO 37.2 25.4 18.5 58.6 35.7 35.8 29.4 21.5 47.2 28.4 57.6
图 10 不同算法在VisDrone2021数据集上的平均精度均值柱状图 ...
Mixed YOLOv3-LITE: a lightweight real-time object detection method
1
2020
... Average precision and mean average precision for different algorithms on VisDrone2021 dataset
Tab.3 算法 AP/% mAP $ {}_{50} $ A B C D E F G H I J TridentNet[16 ] 22.8 9.0 5.3 46.2 30.7 25.5 21.3 16.0 39.0 17.9 43.1 RRNet[17 ] 30.5 14.8 14.1 51.5 35.8 35.2 28.8 19.0 45.0 26.0 55.0 CenterNet[18 ] 28.0 12.0 8.9 51.2 35.9 27.5 21.0 19.8 37.7 20.9 48.5 YOLOv5+head — — — — — — — — — — 33.8 YOLOv5+upsampling — — — — — — — — — — 50.5 YOLOv5+ M-Bi — — — — — — — — — — 43.6 YOLOv4[19 ] 25.0 13.1 8.5 64.2 22.5 22.6 11.5 8.0 44.5 22.0 43.0 YOLOv3-LITE[20 ] 34.6 22.9 8.0 71.2 31.4 22.1 15.5 7.1 41.3 32.7 41.9 MSC-CenterNet[21 ] 33.5 15.3 12.5 55.2 40.6 32.0 29.2 21.6 42.5 27.4 39.5 Faster R-CNN[22 ] 21.0 14.7 7.5 51.0 30.2 19.6 15.7 9.5 31.6 20.3 33.2 LSA_YOLO 37.2 25.4 18.5 58.6 35.7 35.8 29.4 21.5 47.2 28.4 57.6
图 10 不同算法在VisDrone2021数据集上的平均精度均值柱状图 ...
1
... Average precision and mean average precision for different algorithms on VisDrone2021 dataset
Tab.3 算法 AP/% mAP $ {}_{50} $ A B C D E F G H I J TridentNet[16 ] 22.8 9.0 5.3 46.2 30.7 25.5 21.3 16.0 39.0 17.9 43.1 RRNet[17 ] 30.5 14.8 14.1 51.5 35.8 35.2 28.8 19.0 45.0 26.0 55.0 CenterNet[18 ] 28.0 12.0 8.9 51.2 35.9 27.5 21.0 19.8 37.7 20.9 48.5 YOLOv5+head — — — — — — — — — — 33.8 YOLOv5+upsampling — — — — — — — — — — 50.5 YOLOv5+ M-Bi — — — — — — — — — — 43.6 YOLOv4[19 ] 25.0 13.1 8.5 64.2 22.5 22.6 11.5 8.0 44.5 22.0 43.0 YOLOv3-LITE[20 ] 34.6 22.9 8.0 71.2 31.4 22.1 15.5 7.1 41.3 32.7 41.9 MSC-CenterNet[21 ] 33.5 15.3 12.5 55.2 40.6 32.0 29.2 21.6 42.5 27.4 39.5 Faster R-CNN[22 ] 21.0 14.7 7.5 51.0 30.2 19.6 15.7 9.5 31.6 20.3 33.2 LSA_YOLO 37.2 25.4 18.5 58.6 35.7 35.8 29.4 21.5 47.2 28.4 57.6
图 10 不同算法在VisDrone2021数据集上的平均精度均值柱状图 ...
1
... Average precision and mean average precision for different algorithms on VisDrone2021 dataset
Tab.3 算法 AP/% mAP $ {}_{50} $ A B C D E F G H I J TridentNet[16 ] 22.8 9.0 5.3 46.2 30.7 25.5 21.3 16.0 39.0 17.9 43.1 RRNet[17 ] 30.5 14.8 14.1 51.5 35.8 35.2 28.8 19.0 45.0 26.0 55.0 CenterNet[18 ] 28.0 12.0 8.9 51.2 35.9 27.5 21.0 19.8 37.7 20.9 48.5 YOLOv5+head — — — — — — — — — — 33.8 YOLOv5+upsampling — — — — — — — — — — 50.5 YOLOv5+ M-Bi — — — — — — — — — — 43.6 YOLOv4[19 ] 25.0 13.1 8.5 64.2 22.5 22.6 11.5 8.0 44.5 22.0 43.0 YOLOv3-LITE[20 ] 34.6 22.9 8.0 71.2 31.4 22.1 15.5 7.1 41.3 32.7 41.9 MSC-CenterNet[21 ] 33.5 15.3 12.5 55.2 40.6 32.0 29.2 21.6 42.5 27.4 39.5 Faster R-CNN[22 ] 21.0 14.7 7.5 51.0 30.2 19.6 15.7 9.5 31.6 20.3 33.2 LSA_YOLO 37.2 25.4 18.5 58.6 35.7 35.8 29.4 21.5 47.2 28.4 57.6
图 10 不同算法在VisDrone2021数据集上的平均精度均值柱状图 ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}