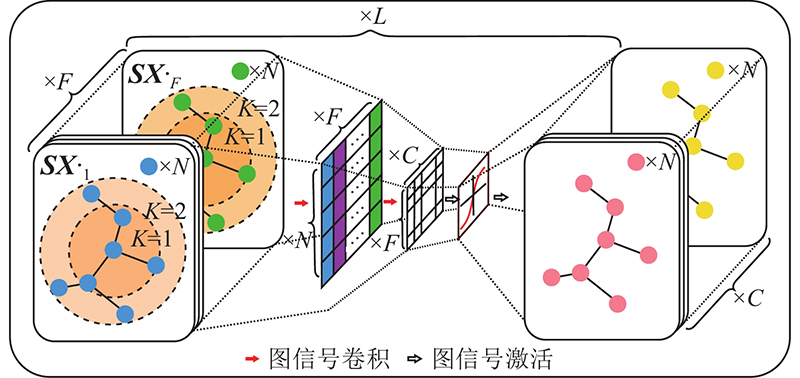
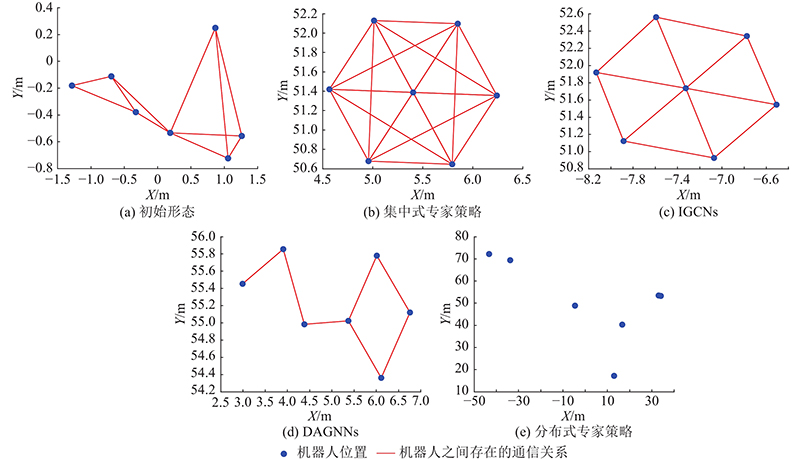
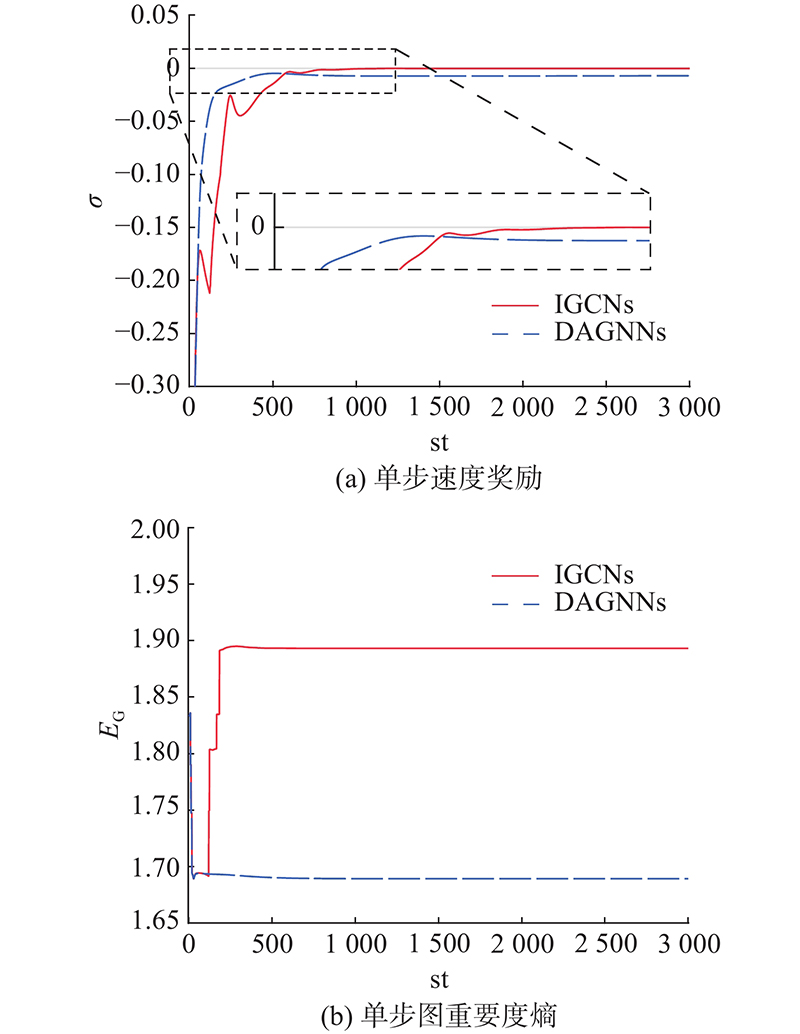
A distributed swarm control strategy based on graph convolutional imitation learning was proposed to deal with the cooperative control of robot swarms under restricted communication conditions. The strategy aimed to improve swarm robustness and enhance the success rate of avoiding swarm splitting based on achieving intra-swarm obstacle avoidance and velocity consistency. A quantitative evaluation index of swarm robustness based on entropy evaluation was proposed to establish the connection between the balanced distribution of node and link importance and cluster robustness. The importance-correlated graph convolutional networks were proposed to realize feature extraction and weighted aggregation of non-Euclidean data under restricted communication conditions. A centralized expert strategy was designed to improve swarm robustness, and the graph convolutional imitation learning method was adopted. Furthermore, a distributed swarm cooperative control strategy was obtained by imitating the centralized expert strategy. Simulation experiments demonstrate that the resulting distributed strategy achieves control effects close to those of the centralized expert strategy based on restricted communication conditions.
ZHOU Z, YAO W, MA J, et al. Simatch: a simulation system for highly dynamic confrontations between multi-robot systems [C]// 2018 Chinese Automation Congress. Xi’an: IEEE, 2018: 3934-3939.
REYNOLDS C W. Flocks, herds and schools: a distributed behavioral model [C]// Proceedings of the 14th annual conference on Computer graphics and interactive techniques. New York: Association for Computing Machinery, 1987: 25-34.
PROROK A, KUMAR V. Privacy-preserving vehicle assignment for mobility-on-demand systems [C]// 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems. Vancouver: IEEE, 2017: 1869-1876.
LI L, BAYUELO A, BOBADILLA L, et al. Coordinated multi-robot planning while preserving individual privacy [C]// 2019 International Conference on Robotics and Automation. Montreal: IEEE, 2019: 2188-2194.
LI Q, GAMA F, RIBEIRO A, et al. Graph neural networks for decentralized multi-robot path planning [C]// 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. Las Vegas: IEEE, 2020: 11785-11792.
HU T K, GAMA F, CHEN T, et al. VGAI: end-to-end learning of vision-based decentralized controllers for robot swarms [C]// ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Toronto: IEEE, 2021: 4900-4904.
GAMA F, TOLSTAYA E, RIBEIRO A. Graph neural networks for decentralized controllers [C]// ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Toronto: IEEE, 2021: 5260-5264.
JIANG Y, HU A, HE M. Evaluation method for the network reliability based on the entropy measures [C]// 2009 International Conference on Networks Security, Wireless Communications and Trusted Computing. Wuhan: IEEE, 2009, 2: 423-426.
TANNER H G, JADBABAIE A, PAPPAS G J. Stable flocking of mobile agents, part I: fixed topology [C]// 42nd IEEE International Conference on Decision and Control. Maui: IEEE, 2003, 2: 2010-2015.
TANNER H G, JADBABAIE A, PAPPAS G J. Stable flocking of mobile agents, part II: dynamic topology [C]// 42nd IEEE International Conference on Decision and Control. Maui: IEEE, 2003, 2: 2016-2021.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}