1. College of Information, North China University of Technology, Beijing 100144, China 2. Beijing Key Laboratory on Integration and Analysis of Large-scale Stream Data, North China University of Technology, Beijing 100144, China
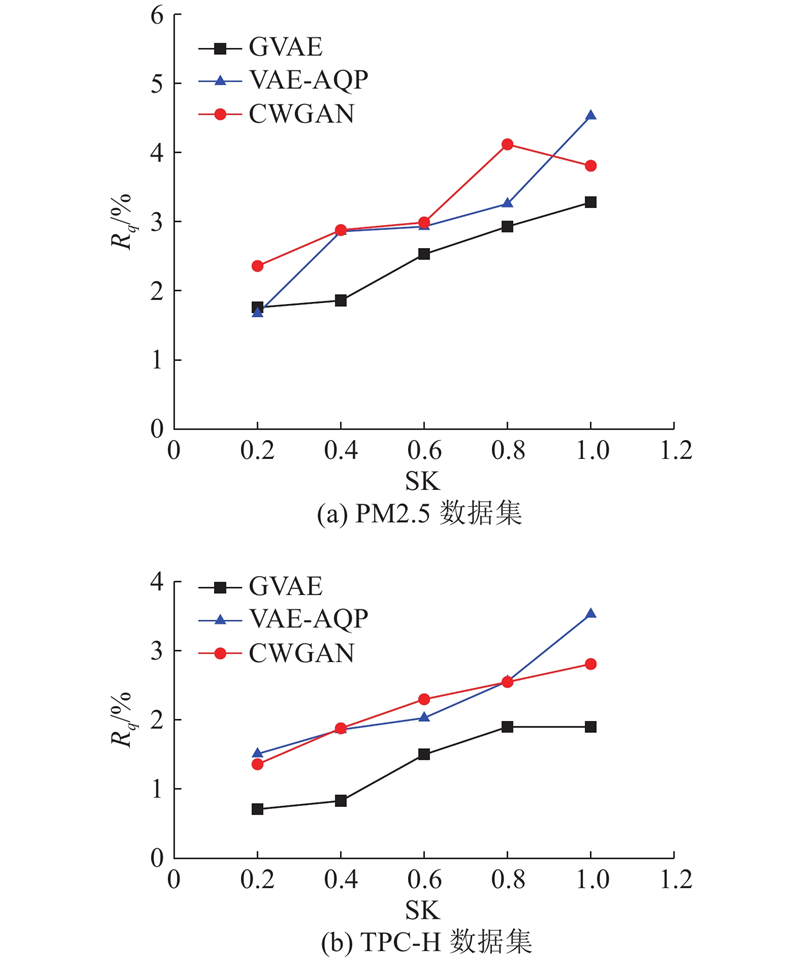
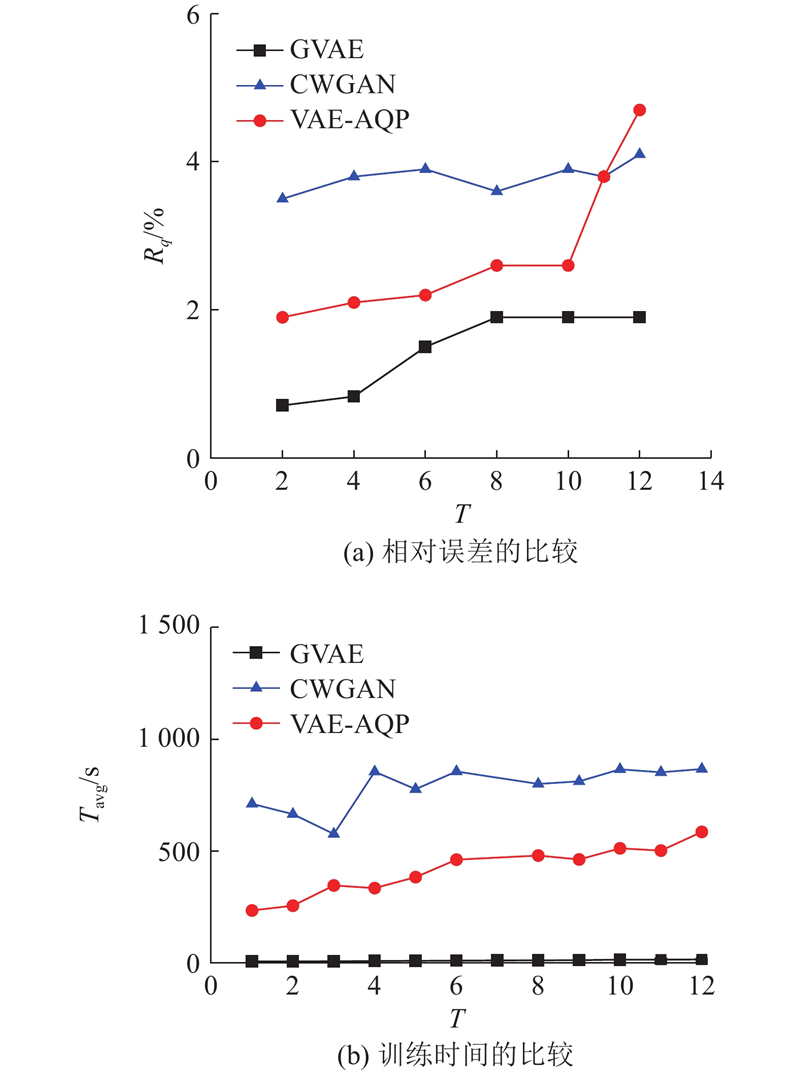
An optimized variational self-encoder-based approximate aggregation query method was proposed for the problem of imbalanced distribution of biased data, which makes it difficult to sample biased distribution data with traditional approximate aggregation query methods. The effect of approximate aggregation query method on the accuracy of approximate aggregation query for biased distribution data was analyzed. The bias-distributed data were hierarchically grouped in the preprocessing stage, and the network structure and loss function of the variational self-encoder generation model were optimized to reduce the approximate aggregated query relative error. The experimental results show that the query relative error of the approximate aggregation query is smaller for skewness distribution data compared with the benchmark method, and the rising trend of the query relative error is smoother as the skewness coefficient increases.
Longsen HUANG,Jun FANG,Yunliang ZHOU,Zhicheng GUO. Optimization method of approximate aggregate query based on variational auto-encoder. Journal of ZheJiang University (Engineering Science), 2024, 58(5): 931-940.
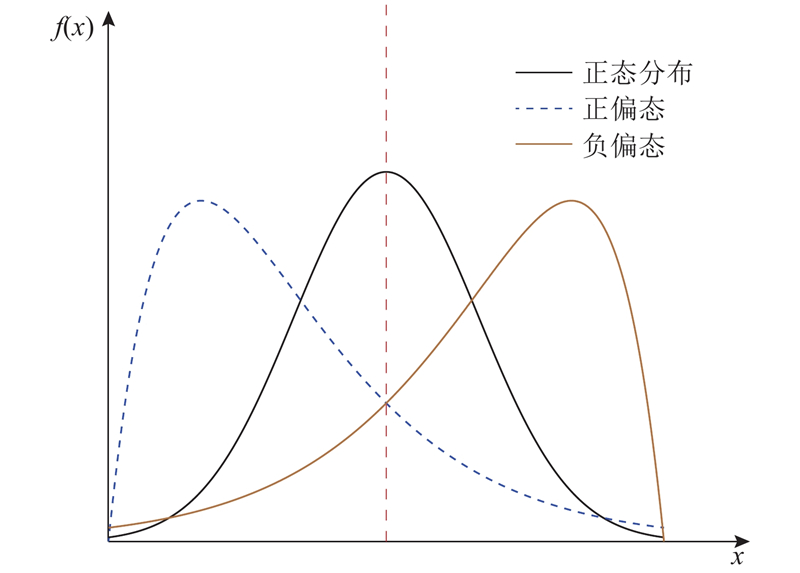
Fig.1Comparison of left-skewed and right-skewed distribution with normal distribution
年份
月份
ρB/(μg·m?3)
CBWD
IWS/(m·s?1)
2010
1
129
NE
1.79
2011
5
62
CV
0.89
2012
7
126
SE
20.57
Tab.1Example of PM2.5 dataset
Field
SK
Rq/%
VAE-AQP
CWGAN
Year
0
2.90
3.38
Month
?0.009
3.80
3.91
CBWD
?0.114
4.01
5.27
PM25
1.802
6.38
7.59
Tab.2Relative errors of bias coefficients for different data under different models
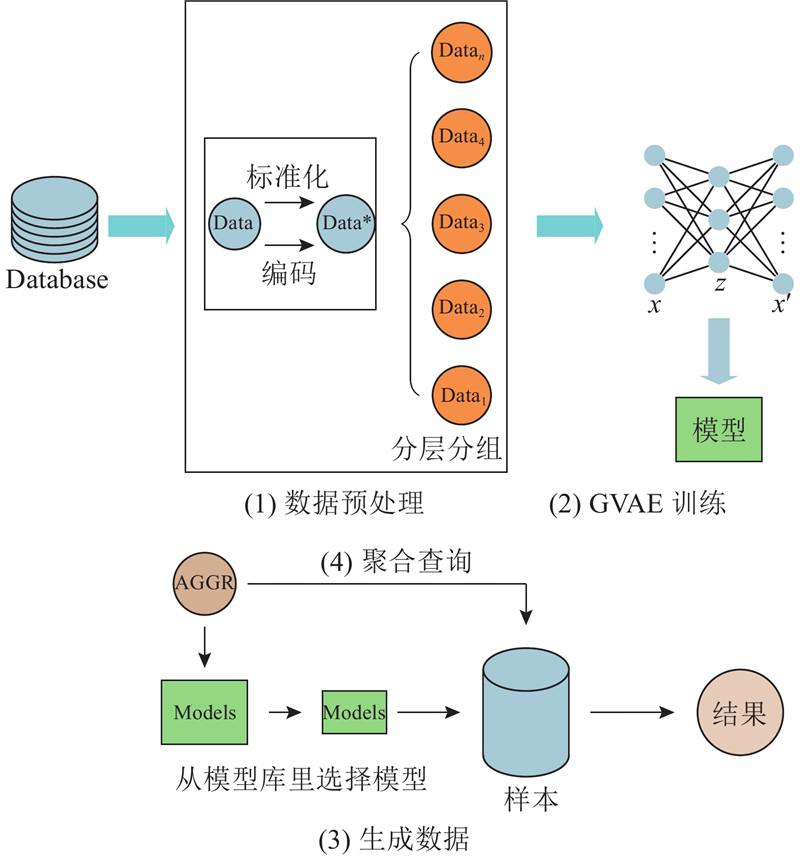
Fig.2Flowchart of GVAE method
算法 1 分层分组算法
输入: 已编码和标准化的数据$ {\mathrm{Data}} $,数据量$ N $,聚合查询语句$ Q $,有$ K $个层,每层$ i $大小为$ {N}_{i} $,分组基数为$ n $输出: 分组后的数据$ \mathrm{S}\mathrm{a}\mathrm{m}\mathrm{p}\mathrm{l}\mathrm{e} $ 1)计算每层 $ i $ 占总体的比例 $ {f}_{i}={N}_{{i}}/N $. 2)对于每个层$ i $,计算出需要从该层抽取的样本数量 $ {n}_{i}=\lfloor {f}_{i} n\rfloor $. 3)计算分组数$ {\mathrm{Group}}={\mathrm{div}}\;(N,n) $ . 4)记录已经被抽取的样本数量 $ {m}_{\mathrm{g}}=0 $. 5)for each $ g $ in ${\mathrm{ Group }}$do6) for each layer $ i $do7) 如果$ {n}_{i}\le $ 0,则跳过该层i. 8) 如果$ {m}_{{\mathrm{g}}} > n $,则跳出循环. 9) for each n in layer i in random order do10) 如果已经从该层中抽取了$ {n}_{i} $个样本,$ {{\mathrm{Sample}}}_{g} $ = $ {n}_{i} $,跳出循环. 11)以相等概率从该层中抽取一个样本,并将其记录下来. 12) $ {m}_{{\mathrm{g}}} $增加1. 13) end for14) end for15)end for
Ng
$ {T}_{\mathrm{a}\mathrm{v}\mathrm{g}} $/s
Acc/%
100
13.26
96.20
1000
16.13
98.10
10000
124.02
98.24
Tab.3Comparison of subgroup bases
分组方式
数据取值
mean
Std
KL
区间分组
总体
?0.006 5
0.961 4
$ 6.599\times {10}^{-5} $
区间分组
总体
?0.004 1
0.976 2
$ 6.218\times {10}^{-5} $
区间分组
单列
?0.021 2
1.002 5
$ 2.751\times {10}^{-4} $
区间分组
单列
0.010 7
0.996 9
$ 2.616\times {10}^{-4} $
分层分组
总体
0.003 6
0.993 0
$ 4.957\times {10}^{-7} $
分层分组
总体
0.002 9
0.993 3
$ 4.923\times {10}^{-7} $
分层分组
单列
0.001 1
0.999 8
0
分层分组
单列
0.001 1
0.999 8
0
Tab.4Comparison of sample distribution for interval grouping
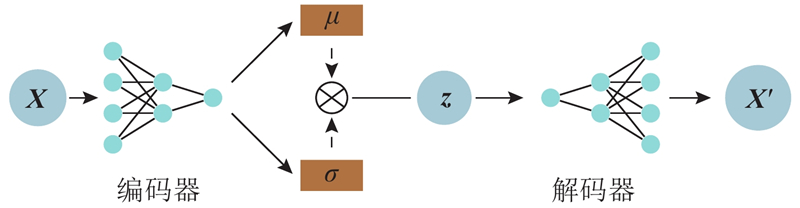
Fig.3Neural network structure of variational auto-encoder
Fig.5Relative errors for queries with different bias coefficients
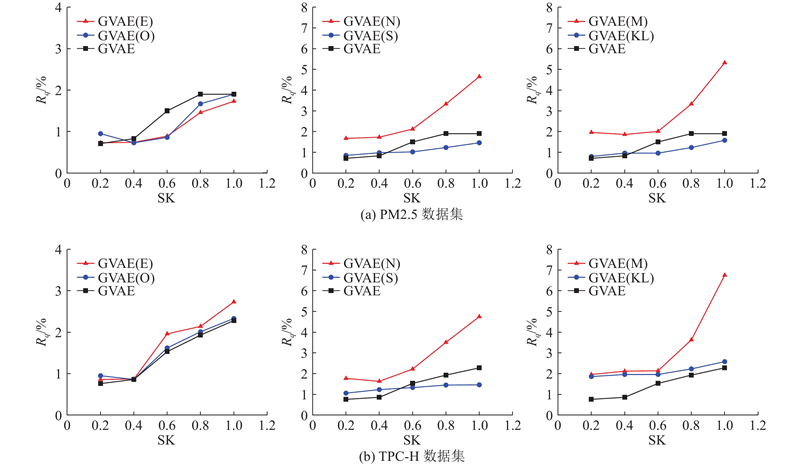
Fig.6Ablation experiment with different dataset and skewed coefficient
Fig.7Model comparison in different dimensions
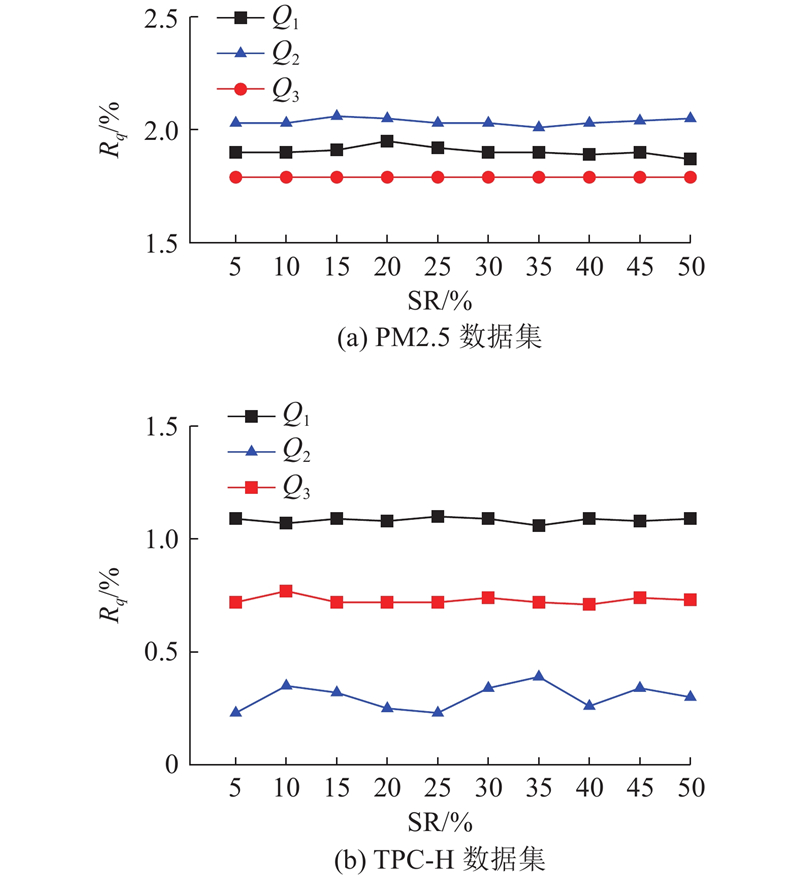
Fig.8Relative error of different sampling rate
[1]
CHAUDURI S, DING B, KANDULA S. Approximate query processing: no silver bullet [C]// Proceedings of the 2017 ACM International Conference on Management of Data . New York: ACM, 2017: 511-519.
[2]
ZHANG Meifan, WANG Hongzhi LAQP: learning-based approximate query processing[J]. Information Sciences, 2021, 546: 1113- 1134
doi: 10.1016/j.ins.2020.09.070
[3]
LI Kaiyu, LI Guoliang. Approximate query processing: what is new and where to go? a survey on approximate query processing [J]. Data Science and Engineering , 2018: 379-397.
[4]
SANCA V, AILAMAKI A. Sampling-based AQP in modern analytical engines [C]// Proceedings of the 18th International Workshop on Data Management on New Hardware . New York: ACM, 2022: 1-8.
[5]
MA Qingzhi, TRIANTAFILLOU P. Dbest: revisiting approximate query processing engines with machine learning models [C]// Proceedings of the 2019 International Conference on Management of Data . New York: ACM, 2019: 1553-1570.
[6]
MA Qingzhi, SHANGHOOSHABAD A M, ALMASI M, et al. Learned approximate query processing: make it light, accurate and fast [C]// Conference on Innovative Data Systems. New York: ACM, 2021.
[7]
HILPRECHT B, SCHMIDT A, KULESSA M, et al DeepDB: learn from data, not from queries![J]. Proceedings of the VLDB Endowment, 2020, 13 (7): 992- 1005
doi: 10.14778/3384345.3384349
[8]
LEE T, PARK C S, NAM K, et al. Query transformation for approximate query processing using synthetic data from deep generative models [C]// IEEE International Conference on Consumer Electronics-Asia . Yeosu: IEEE, 2022: 1-4.
[9]
SHEORAN N, MITRA S, PORWAL V, et al. Conditional generative model based predicate-aware query approximation [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Palo Alto: AAAI, 2022, 36(8): 8259-8266.
[10]
OLKEN F, ROTEM D. Simple random sampling from relational databases [C]// Proceedings of the 12th International Conference on Very Large Data Bases . San Francisco: Morgan Kaufmann Publishers Inc, 1986: 160-169.
[11]
PENG Jinglin, ZHANG Dongxiang, WANG Jiannan, et al. Aqp++ connecting approximate query processing with aggregate precomputation for interactive analytics [C]// Proceedings of the 2018 International Conference on Management of Data . New York: ACM, 2018: 1477-1492.
[12]
HASAN S, THIRUMURUGANATHAN S, AUGUSTINE J, et al. Deep learning models for selectivity estimation of multi-attribute queries [C]// Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data . New York: ACM, 2020: 1035-1050.
[13]
LI Feifei, WU Bin, YI Ke, et al. Wander join: online aggregation via random walks [C]// Proceedings of the 2016 International Conference on Management of Data . New York: ACM, 2016: 615-629.
[14]
CHAUDHURI S, DAYAL U Data warehousing and OLAP for decision support[J]. ACM Sigmod Record, 1997, 26 (2): 507- 508
doi: 10.1145/253262.253373
[15]
AGARWAL S, MOZAFARI B, PANDA A, et al. BlinkDB: queries with bounded errors and bounded response times on very large data [C]// Proceedings of the 8th ACM European conference on computer systems . New York: ACM, 2013: 29-42.
[16]
CORMODE G, GAROFALAKIS M, HAAS P J, et al Synopses for massive data: samples, histograms, wavelets, sketches[J]. Foundations and Trends in Databases, 2011, 4 (1-3): 1- 294
doi: 10.1561/1900000004
[17]
LI Kaiyu, ZHANG Yong, LI Guoliang, et al. Bounded approximate query processing [J]. IEEE Transactions on Knowledge and Data Engineering , 2019, 31(12): 2262-2276.
[18]
LEE T, NAM K, PARK C S, et al. Exploiting machine learning models for approximate query processing [C]// IEEE International Conference on Big Data . Osaka: IEEE, 2022: 6752-6754.
[19]
KINGMA D P, WELLING M. Auto-encoding variational Bayes [EB/OL]. (2013-12-20). https://doi.org/10.48550/arXiv.1312.6114.
[20]
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [EB/OL].[2023-10-14]. https://arxiv.org/abs/1406.2661.
[21]
THIRUMURUGANATHAN S, HASAN S, KOUDAS N, et al. Approximate query processing for data exploration using deep generative models [C]// IEEE 36th International Conference on Data Engineering . Los Alamitos: IEEE, 2020: 1309-1320.
[22]
ZHANG Meifang, WANG Hongzhi. Approximate query processing for group-by queries based on conditional generative models [EB/OL]. (2021-01-08). https://doi.org/10.48550/arXiv.2101.02914.
TSOUMAKAS G, KATAKIS I Multi-label classification: an overview[J]. International Journal of Data Warehousing and Mining, 2007, 3 (3): 1- 13
doi: 10.4018/jdwm.2007070101
[25]
FU Hao, LI Chunyuan, LIU Xiaodong, et al. Cyclical annealing schedule: a simple approach to mitigating KL vanishing [C]// Proceedings of NAACL-HLT . Stroudsburg: ACL, 2019: 240-250.
HU Li-sha, WANG Su-zhen, CHEN Yi-qiang, GAO Chen-long, HU Chun-yu, JIANG Xin-long, CHEN Zhen-yu, GAO Xing-yu. Fall detection algorithms based on wearable device: a review[J]. Journal of ZheJiang University (Engineering Science), 2018, 52(9): 1717-1728.