|
|
|
| Large-scale empirical study on machine learning related questions on Stack Overflow |
Zhi-yuan WAN1( ),Jia-heng TAO2,Jia-kun LIANG2,Zhen-gong CAI2,*(),Cheng CHANG1,Lin QIAO3,Qiao-ni ZHOU3 ),Jia-heng TAO2,Jia-kun LIANG2,Zhen-gong CAI2,*(),Cheng CHANG1,Lin QIAO3,Qiao-ni ZHOU3 |
1. College of Computer Science and Technology, Zhejiang University, Hangzhou 310027, China
2. Colloge of Software Technology, Zhejiang University, Ningbo 315048, China
3. Information and Communication Branch, State Grid Liaoning Electric Power Supply Co. Ltd, Shenyang 110006, China |
|
|
|
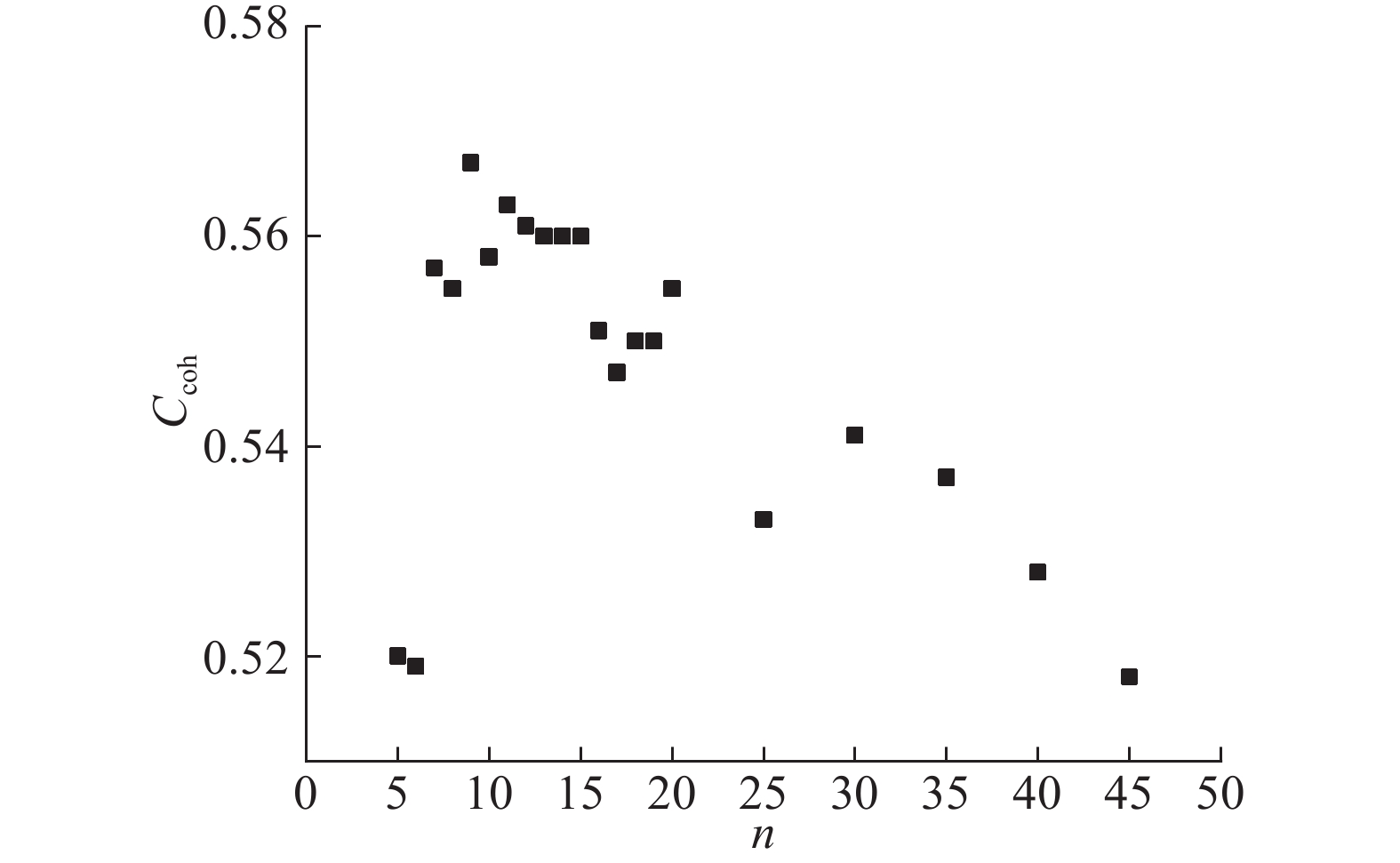
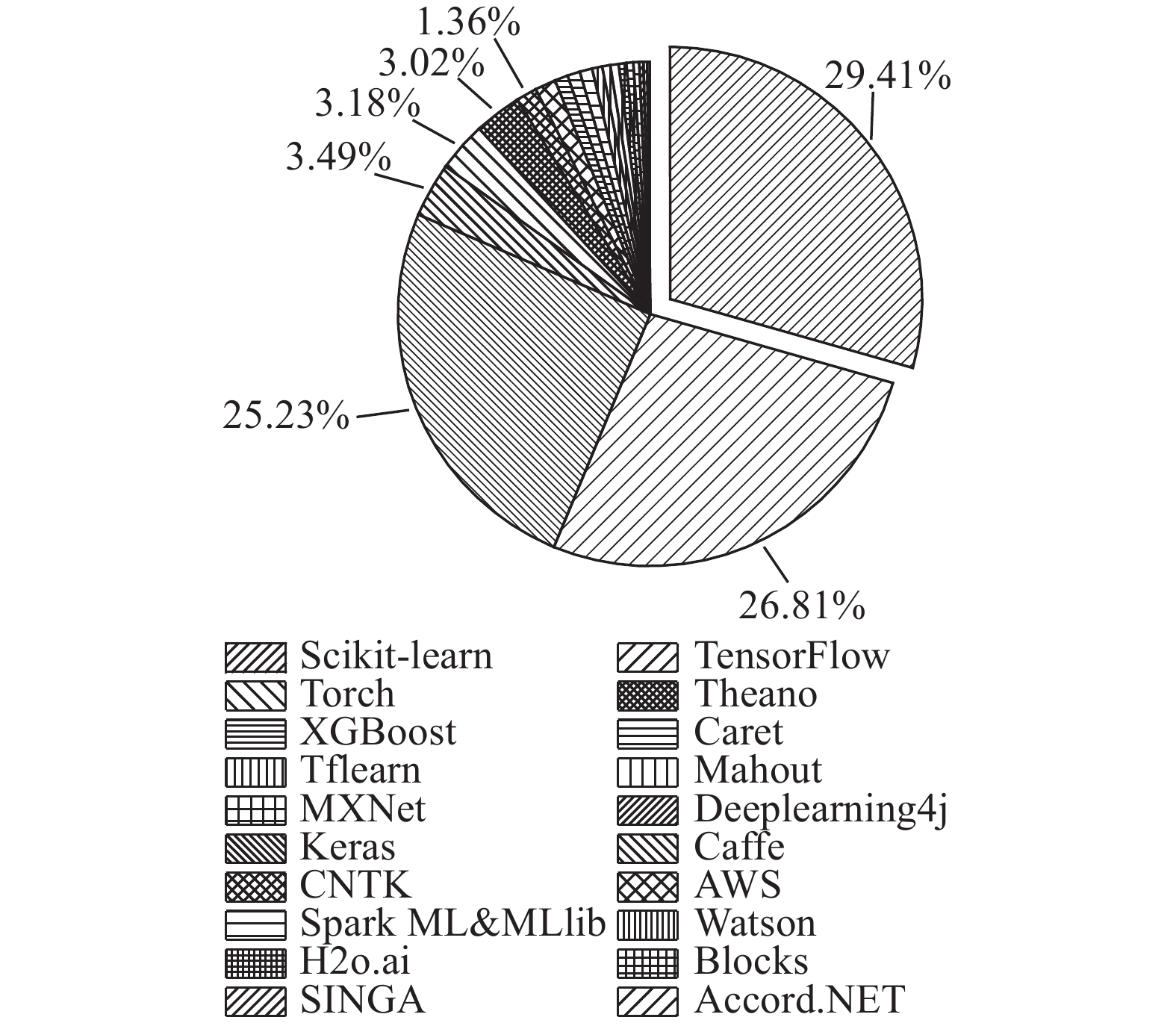
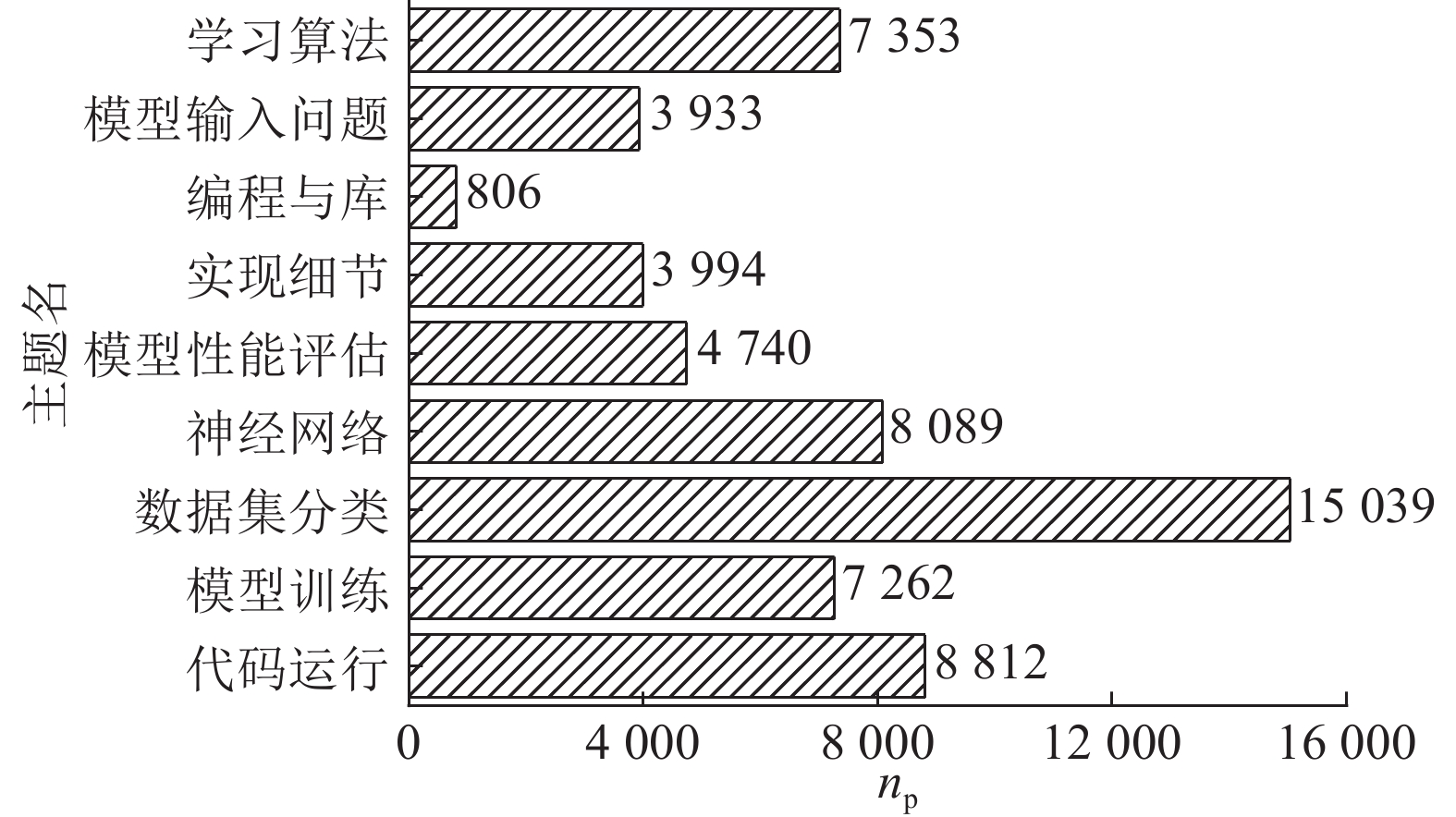
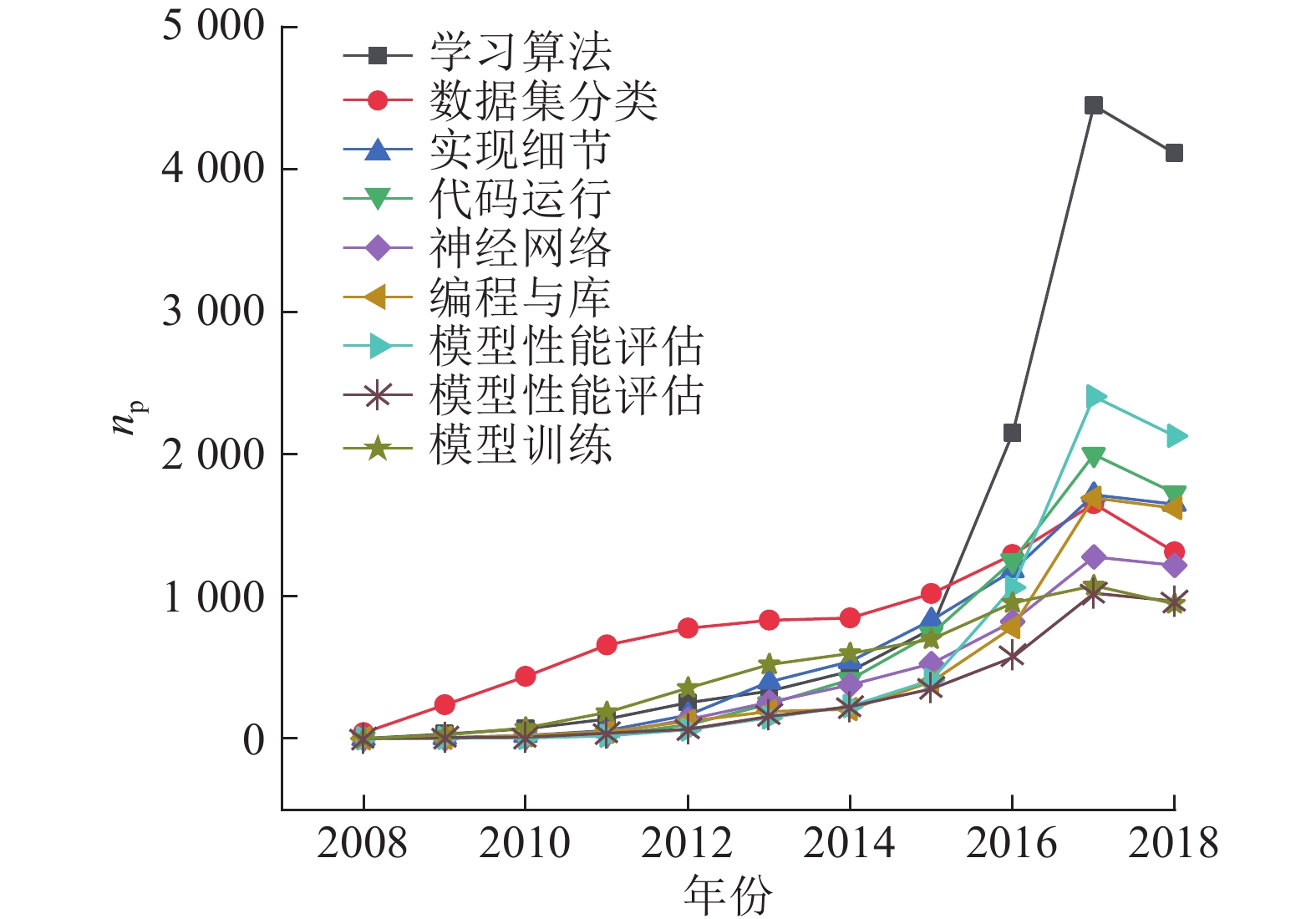
Abstract By using filtered tags, 60 028 machine learning related questions were extracted from more than 41.78 million posts on an online Q & A website, Stack Overflow, in order to investigate the topic distribution and trends related to machine learning. Extracted question posts were analyzed by counting the amount of discussion on each machine learning platform, and top three most frequently discussed machine learning platforms were discovered, i.e. Scikit-learn, TensorFlow and Keras, accounting for 58% of these posts. Latent Dirichlet allocation (LDA) topic model training was conducted to further explore discussion topics related to machine learning. A progressive search approach was proposed for number of topics in adaptive LDA, which discovered the optimal number of topics with topic coherence coefficient, in order to obtain the optimal topic numbers for LDA models. Nine discussion topics related to machine learning were discovered, which fell into three broad categories, i.e. code-related, model-related, and theory-related. In addition, the popularity and difficulty of different topics were analyzed according to the view counts and comment counts of question posts.
|
|
Received: 23 October 2018
Published: 17 May 2019
|
|
|
|
Corresponding Authors:
Zhen-gong CAI
E-mail: wanzhiyuan@zju.edu.cn;cstcaizg@zju.edu.cn
|
Stack Overflow上机器学习相关问题的大规模实证研究
为了调查机器学习相关主题分布和发展趋势,从在线问答网站Stack Overflow上,利用过滤标签,从4 178多万帖子中提取出60 028个与机器学习相关的问题帖. 通过分析问题帖,统计各个机器学习平台的讨论量,发现Scikit-learn、TensorFlow、Keras是前3位频繁被讨论的机器学习平台,占总讨论量的58%. 为了进一步分析机器学习相关讨论主题,进行潜在狄利克雷分布(LDA)主题模型训练,提出自适应LDA中的主题数渐进搜索方法,采用主题一致性系数评估输出结果,获得主题最佳数量,从而发现9个讨论主题,分属3个类别:代码相关、模型相关、理论相关. 基于主题中问题帖的浏览数、评论数,分析不同主题的流行度和回答困难程度.
关键词:
实证研究,
机器学习,
Stack Overflow,
潜在狄利克雷分布(LDA),
主题一致性
|
|
| [1] |
GY?NGYI Z, KOUTRIKA G, PEDERSEN J, et al. Questioning yahoo! answers [R]. Stanford: Stanford InfoLab, 2007.
|
|
|
| [2] |
ADAMIC L A, ZHANG J, BAKSHY E, et al. Knowledge sharing and yahoo answers: everyone knows something [C]// Proceedings of the 17th International Conference on World Wide Web. Beijing: ACM, 2008: 665–674.
|
|
|
| [3] |
BARUA A, THOMAS S W, HASSAN A E What are developers talking about? an analysis of topics and trends in stack overflow[J]. Empirical Software Engineering, 2014, 19 (3): 619- 654
doi: 10.1007/s10664-012-9231-y
|
|
|
| [4] |
ROSEN C, SHIHAB E What are mobile developers asking about? a large scale study using stack overflow[J]. Empirical Software Engineering, 2016, 21 (3): 1192- 1223
doi: 10.1007/s10664-015-9379-3
|
|
|
| [5] |
LINARES-VáSQUEZ M, DIT B, POSHYVANYK D. An exploratory analysis of mobile development issues using stack overflow [C]// 10th IEEE Working Conference on Mining Software Repositories. San Francisco: IEEE, 2013: 93–96.
|
|
|
| [6] |
YANG X L, LO D, XIA X, et al What security questions do developers ask? a large-scale study of stack overflow posts[J]. Journal of Computer Science and Technology, 2016, 31 (5): 910- 924
doi: 10.1007/s11390-016-1672-0
|
|
|
| [7] |
BEYER S, PINZGER M. A manual categorization of android app development issues on Stack Overflow [C]// International Conference on Software Maintenance and Evolution. Victoria: IEEE, 2014: 531–535.
|
|
|
| [8] |
NADI S, KRüGER S, MEZINI M, et al. Jumping through hoops: why do Java developers struggle with cryptography APIs? [C]// Proceedings of the 38th International Conference on Software Engineering. Texas: ACM, 2016: 935–946.
|
|
|
| [9] |
HINDLE A, GODFREY M W, HOLT R C. What's hot and what's not: windowed developer topic analysis [C]// IEEE International Conference on Software Maintenance. Edmonton: IEEE, 2009: 339–348.
|
|
|
| [10] |
NEUHAUS S, ZIMMERMANN T. Security trend analysis with cve topic models [C]// 21st International Symposium on Software Reliability Engineering. San Jose: IEEE, 2010: 111–120.
|
|
|
| [11] |
THOMAS S W, ADAMS B, HASSAN A E, et al. Modeling the evolution of topics in source code histories [C]// Proceedings of the 8th Working Conference on Mining Software Repositories. Hawaii: ACM, 2011: 173–182.
|
|
|
| [12] |
TREUDE C, BARZILAY O, STOREY M A. How do programmers ask and answer questions on the web? Nier track [C]// 33rd International Conference on Software Engineering. Hawaii: IEEE, 2011: 804–807.
|
|
|
| [13] |
MAMYKINA L, MANOIM B, MITTAL M, et al. Design lessons from the fastest Q&A site in the west [C]// Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. Vancouver: ACM, 2011: 2857–2866.
|
|
|
| [14] |
XIA X, LO D, WANG X, et al. Tag recommendation in software information sites [C]// 10th IEEE Working Conference on Mining Software Repositories. New Jersey: IEEE, 2013: 287–296.
|
|
|
| [15] |
WANG S, LO D, VASILESCU B, et al. EnTagRec: an enhanced tag recommendation system for software information sites [C]// International Conference on Software Maintenance and Evolution. Victoria: IEEE, 2014: 291–300.
|
|
|
| [16] |
ASUNCION H U, ASUNCION A U, TAYLOR R N. Software traceability with topic modeling [C]// 32nd International Conference on Software Engineering. Cap Town: IEEE, 2010, 1: 95–104.
|
|
|
| [17] |
THOMAS S W. Mining software repositories using topic models [C]// Proceedings of the 33rd International Conference on Software Engineering. Hawaii: ACM, 2011: 1138–1139.
|
|
|
| [18] |
PANICHELLA A, DIT B, OLIVETO R, et al. How to effectively use topic models for software engineering tasks? an approach based on genetic algorithms [C]// Proceedings of the 2013 International Conference on Software Engineering. San Francisco: IEEE, 2013: 522–531.
|
|
|
| [19] |
GEORGE H. Parameter estimation for text analysis [R]. Darmstadt: University of Leipzig, 2009.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|