1. Faculty of Information Technology, Beijing University of Technology, Beijing 100124, China 2. Beijing Key Laboratory of Trusted Computing, Beijing 100124, China 3. National Engineering Laboratory for Critical Technologies of Information Security Classified Protection, Beijing 100124, China 4. Artificial Intelligence and Machine Learning (AIML) Lab, School of Computer Science, Carlton University, Ottawa K1S 5B6, Canada
A code vulnerability detection method based on contextual feature fusion was proposed in the view of high false positive rate and the high false negative rate of existing code vulnerability detection methods. The code features were decoupled into code block local features and context global features. The code block local features focused on the semantics of key tokens and short distance dependencies. The context global features were obtained by fusing code block local features to capture long-distance dependencies of code line context. The feature learning ability of the model was improved by collaborating the learning of local and global information. The programming mode of code vulnerabilities was discovered more accurately. A code vulnerability comparison mapping module was introduced to widen the distance between positive and negative samples in embedded space. The model can accurately distinguish between positive and negative samples. The experimental results show that the precision rate is improved by a maximum of 29% and the recall rate is improved by a maximum of 16% on the real data set mixed with 9 software source code.
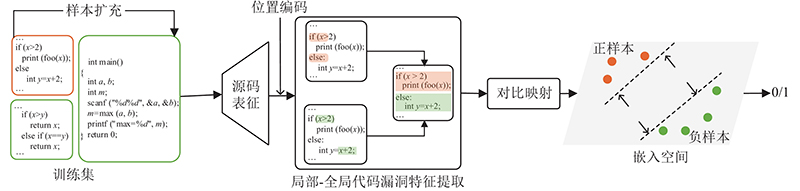
Fig.1General framework of code vulnerability detection method based on contextual feature fusion
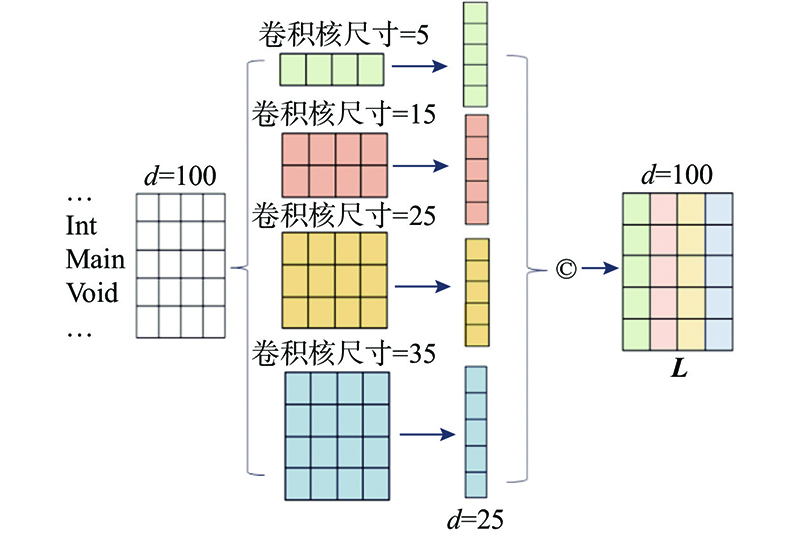
Fig.2Code local feature extraction module
Fig.3Code global feature fusion module
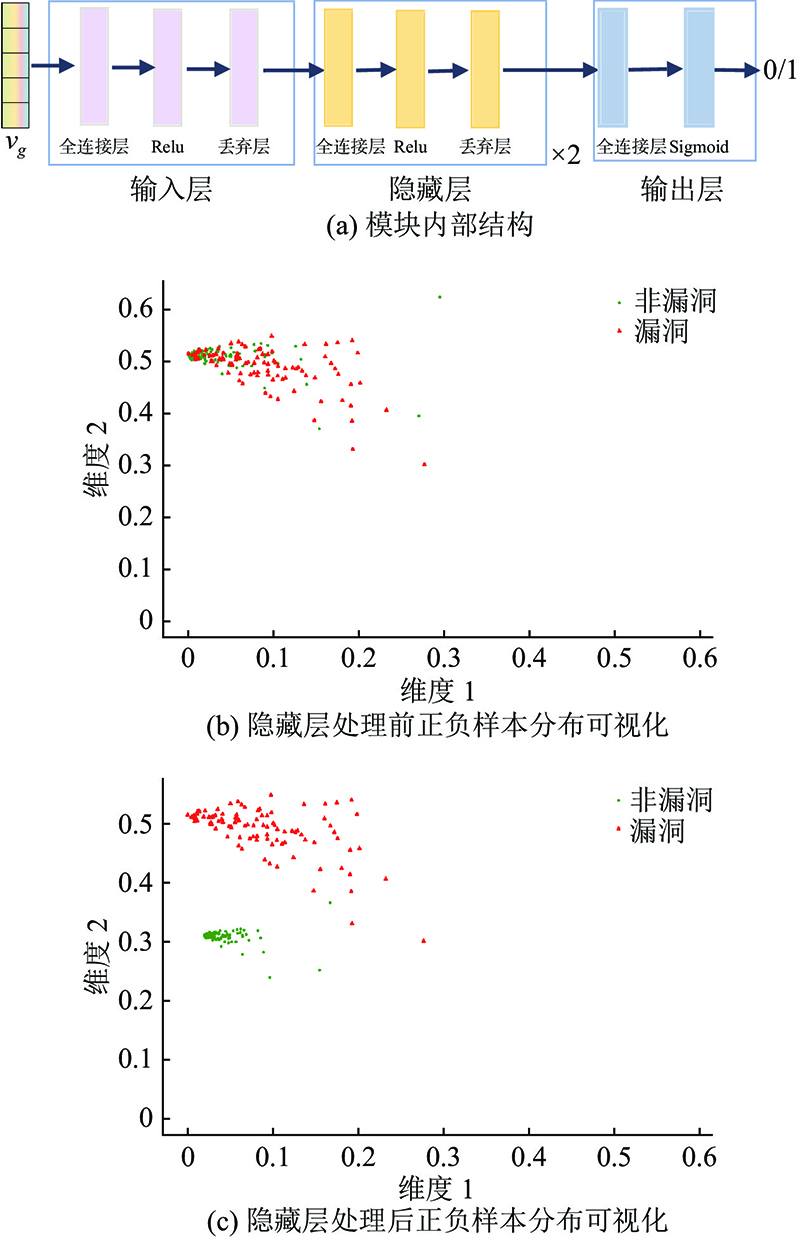
Fig.4Code vulnerability comparison mapping module
开源软件项目
Nnon
Nvul
Asterisk
17 755
94
FFmpeg
5 552
249
HTTPD
3 850
57
LibPNG
577
45
LibTIFF
731
123
OpenSSL
7 068
159
Pidgin
8 626
29
VLC Player
6 115
44
Xen
9 023
671
总计
59 297
1 471
Tab.1Number of functions in dataset
训练集
测试集
验证集
Nvul
Nnon
Nvul
Nnon
Nvul
Nnon
883
35 575
294
11 861
289
11 855
Tab.2Number of functions in training set, test set, validation set
l
K=1
K=10
K=20
K=50
P@K%
R@K%
P@K%
R@K%
P@K%
R@K%
P@K%
R@K%
1 500
98
40
22
94
20
95
20
95
1 800
99
41
23
97
11
98
6
99
2 000
97
40
22
91
14
93
14
93
Tab.3Results of different token sequence length l%
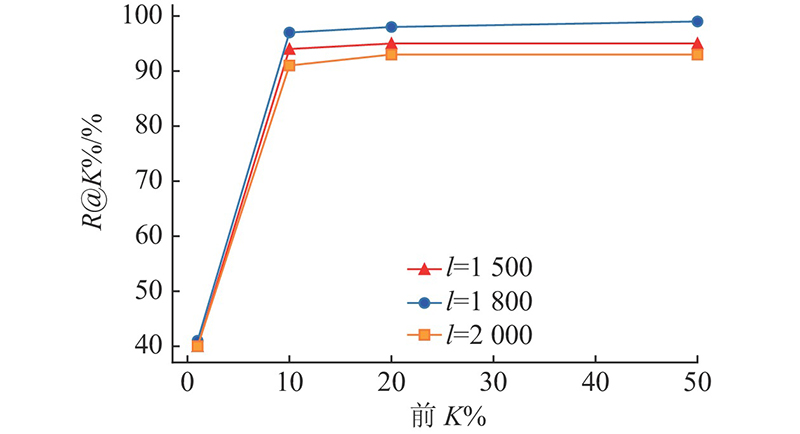
Fig.5Top K% recall rate corresponding to different token sequences length
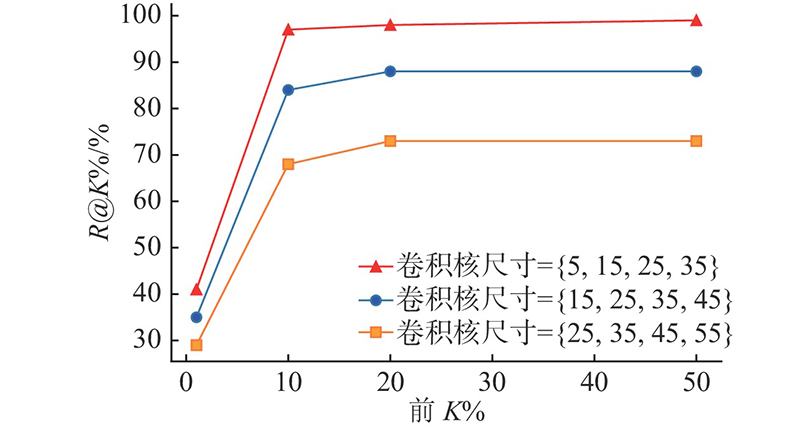
卷积核 尺寸
K=1
K=10
K=20
K=50
P@K%
R@K%
P@K%
R@K%
P@K%
R@K%
P@K%
R@K%
{5,15,25,35}
99
41
23
97
11
98
6
99
{15,25,35,45}
85
35
20
84
14
88
14
88
{25,35,45,55}
71
29
16
68
11
73
11
73
Tab.4Results of different convolutional kernel sizes %
Fig.6TopK% recall rate corresponding to different convolutional kernel sizes
%
模型
K=1
K=10
K=20
K=50
P@K%
R@K%
P@K%
R@K%
P@K%
R@K%
P@K%
R@K%
Bi-LSTM[21]
54
22
18
75
10
87
5
99
Text-CNN[21]
70
29
20
81
11
90
5
97
DNN[21]
44
18
15
62
10
80
5
96
本研究方法
99
41
23
97
11
98
6
99
Tab.5Precision and recall rate of comparative experiment with Bi-LSTM、Text-CNN、DNN
模型
ACC/%
F1/%
Devign[32]
89.27
41.12
本研究方法
96.62
79.83
Tab.6Accuracy and F1 score results of comparative experiment with Devign
是否使用 样本平衡 方法
K=1
K=10
K=20
K=50
P@K%
R@K%
P@K%
R@K%
P@K%
R@K%
P@K%
R@K%
否
95
39
21
90
16
92
16
92
是
99
41
23
97
11
98
6
99
Tab.7Ablation experiment results of sample balancing method %
模型
代码局部特 征提取模块
代码全局特 征融合模块
代码漏洞对 比映射模块
M1
√
√
√
M2
×
√
√
M3
√
×
√
M4
√
√
×
Tab.8Ablation of different modules
模型
K=1
K=10
K=20
K=50
P@K%
R@K%
P@K%
R@K%
P@K%
R@K%
P@K%
R@K%
M1
99
41
23
97
11
98
6
99
M2
57
23
27
41
27
41
27
41
M3
63
26
14
61
11
66
11
66
M4
66
27
32
50
32
50
32
50
Tab.9Ablation experiment results of different modules
Fig.7Top K% recall rate corresponding to ablation of modules
[1]
SECURESOFTWARE. Rough auditing tool for security(rats)[EB/OL]. [2021-12-23]. http://www.securesoftware.com/resources/download_rats.html.
[2]
WHEELER D A. Flawfinder software official website[EB/OL]. [2018-08-02]. https://www.dwheeler.com/flawfinder/.
[3]
JANG J, AGRAWAL A, BRUMLEY D. Redebug: finding unpatched code clones in entire os distributions[C]// IEEE Symposium on Security and Privacy. California: IEEE Computer Society, 2012: 48-62.
[4]
KIM S, WOO S, LEE H, et al. Vuddy: a scalable approach for vulnerable code clone discovery[C]// IEEE Symposium on Security and Privacy (SP). San Jose: IEEE Computer Society, 2017: 595-614.
[5]
AVGERINOS T, CHA S K, REBERT A, et al Automatic exploit generation[J]. Communications of the ACM, 2014, 57 (2): 74- 84
doi: 10.1145/2560217.2560219
[6]
RAMOS D A, ENGLER D. Under-constrained symbolic execution: correctness checking for real code[C]// Proceedings of the24th USENIX Security Symposium (USENIX Security 15). Washington: USENIX Association, 2015: 49-64.
[7]
NEUHAUS S, ZIMMERMANN T, HOLLER C, et al. Predicting vulnerable software components[C]// Proceedings of the 14th ACM Conference on Computer and Communications Security. Alexandria: ACM, 2007: 529-540.
[8]
SHIN Y, WILLIAMS L. An empirical model to predict security vulnerabilities using code complexity metrics[C]// Proceedings of the 2nd ACM-IEEE International Symposium on Empirical Software Engineering and Measurement. Kaiserslautern: ACM, 2008: 315-317.
[9]
SHIN Y, WILLIAMS L Can traditional fault prediction models be used for vulnerability prediction?[J]. Empirical Software Engineering, 2013, 18 (1): 25- 59
doi: 10.1007/s10664-011-9190-8
[10]
PERL H, DECHAND S, SMITH M, et al. Vccfinder: finding potential vulnerabilities in open-source projects to assist code audits[C]// Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. Denver: ACM, 2015: 426-437.
[11]
SHIN Y, MENEELY A, WILLIAMS L, et al Evaluating complexity, code churn and developer activity metrics as indicators of software vulnerabilities[J]. IEEE Transactions on Software Engineering, 2010, 37 (6): 772- 787
[12]
GHAFFARIAN S M, SHAHRIARI H R Software vulnerability analysis and discovery using machine-learning and data-mining techniques: a survey[J]. ACM Computing Surveys (CSUR), 2017, 50 (4): 1- 36
[13]
LIU L, DE VEL O, HAN Q-L, et al Detecting and preventing cyber insider threats: a survey[J]. IEEE Communications Surveys and Tutorials, 2018, 20 (2): 1397- 1417
doi: 10.1109/COMST.2018.2800740
[14]
SUN N, ZHANG J, RIMBA P, et al Data-driven cybersecurity incident prediction: a survey[J]. IEEE Communications Surveys and Tutorials, 2018, 21 (2): 1744- 1772
[15]
JIANG J, WEN S, YU S, et al Identifying propagation sources in networks: state-of-the-art and comparative studies[J]. IEEE Communications Surveys and Tutorials, 2016, 19 (1): 465- 481
[16]
WU T, WEN S, XIANG Y, et al Twitter spam detection: survey of new approaches and comparative study[J]. Computers and Security, 2018, 76: 265- 284
doi: 10.1016/j.cose.2017.11.013
[17]
GOODFELLOW I, BENGIO Y, COURVILLE A. Deep learning [M]. Cambridge, Massachusetts, USA: MIT press, 2016.
[18]
SESTILI C D, SNAVELY W S, VANHOUDNOS N M. Towards security defect prediction with AI [EB/OL]. [2018-08-29]. https://doi.org/10.48550/arXiv.1808.09897.
[19]
LI Z, ZOU D, XU S, et al Sysevr: a framework for using deep learning to detect software vulnerabilities[J]. IEEE Transactions on Dependable and Secure Computing, 2021, 19 (4): 2244- 2258
[20]
DAM H K, TRAN T, PHAM T, et al. Automatic feature learning for vulnerability prediction [EB/OL]. [2017-08-08]. https://doi.org/10.48550/arXiv.1708.02368.
[21]
LIN G, XIAO W, ZHANG J, et al. Deep learning-based vulnerable function detection: A benchmark[C]// International Conference on Information and Communications Security. Beijing: Springer, 2019: 219-232.
[22]
LI Z, ZOU D, XU S, et al. Vuldeepecker: a deep learning-based system for vulnerability detection [EB/OL]. [2018-01-05]. https://doi.org/10.48550/arXiv.1801.01681.
[23]
LIN G, ZHANG J, LUO W, et al Cross-project transfer representation learning for vulnerable function discovery[J]. IEEE Transactions on Industrial Informatics, 2018, 14 (7): 3289- 3297
doi: 10.1109/TII.2018.2821768
[24]
段旭, 吴敬征, 罗天悦, 等 基于代码属性图及注意力双向 LSTM 的漏洞挖掘方法[J]. 软件学报, 2020, 31 (11): 3404- 3420 DUAN Xu, WU Jing-zheng, LUO Tian-yue, et al Vulnerability mining method based on code property graph and attention BiLSTM[J]. Journal of Software, 2020, 31 (11): 3404- 3420
[25]
PENG H, MOU L, LI G, et al. Building program vector representations for deep learning [C]// International Conference on Knowledge Science, Engineering and Management. Chongqing: Springer, 2015: 547-553.
[26]
LEE Y J, CHOI S H, KIM C, et al. Learning binary code with deep learning to detect software weakness[C]// KSII the 9th International Conference on Internet (ICONI). Vientiane: Symposium, 2017: 245-249.
[27]
RUSSELL R, KIM L, HAMILTON L, et al. Automated vulnerability detection in source code using deep representation learning [C]// 17th IEEE International Conference on Machine Learning and Applications (ICMLA). Orlando: Institute of Electrical and Electronics Engineers, 2018: 757-762.
[28]
AL-ALYAN A, AL-AHMADI S Robust URL phishing detection based on deep learning[J]. KSII Transactions on Internet and Information Systems (TIIS), 2020, 14 (7): 2752- 2768
[29]
YAMAGUCHI F, LOTTMANN M, RIECK K. Generalized vulnerability extrapolation using abstract syntax trees[C]// Proceedings of the 28th Annual Computer Security Applications Conference. Orlando: ACM, 2012: 359-368.
[30]
SUNEJA S, ZHENG Y, ZHUANG Y, et al. Learning to map source code to software vulnerability using code-as-a-graph [EB/OL]. [2020-06-15]. https://arxiv.org/abs/2006.08614.
[31]
YAMAGUCHI F, GOLDE N, ARP D, et al. Modeling and discovering vulnerabilities with code property graphs[C]// IEEE Symposium on Security and Privacy. Berkeley: IEEE Computer Society, 2014: 590-604.
[32]
ZHOU Y, LIU S, SIOW J, et al. Devign: effective vulnerability identification by learning comprehensive program semantics via graph neural networks [C]// Proceedings of the 33rd Conference on Neural Information Processing Systems. Vancouver: NIPS Foundation, 2019: 10197-10207.
[33]
CAO S, SUN X, BO L, et al Bgnn4vd: constructing bidirectional graph neural-network for vulnerability detection[J]. Information and Software Technology, 2021, 136: 106576
doi: 10.1016/j.infsof.2021.106576
[34]
CHAWLA N V, BOWYER K W, HALL L O, et al Smote: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16: 321- 357
doi: 10.1613/jair.953
[35]
AGRAWAL A, MENZIES T. Is" better data" better than" better data miners"? [C]// IEEE/ACM 40th International Conference on Software Engineering. Gothenburg: ACM, 2018: 1050-1061.