| 计算机技术与控制工程 |
|

|
|
|
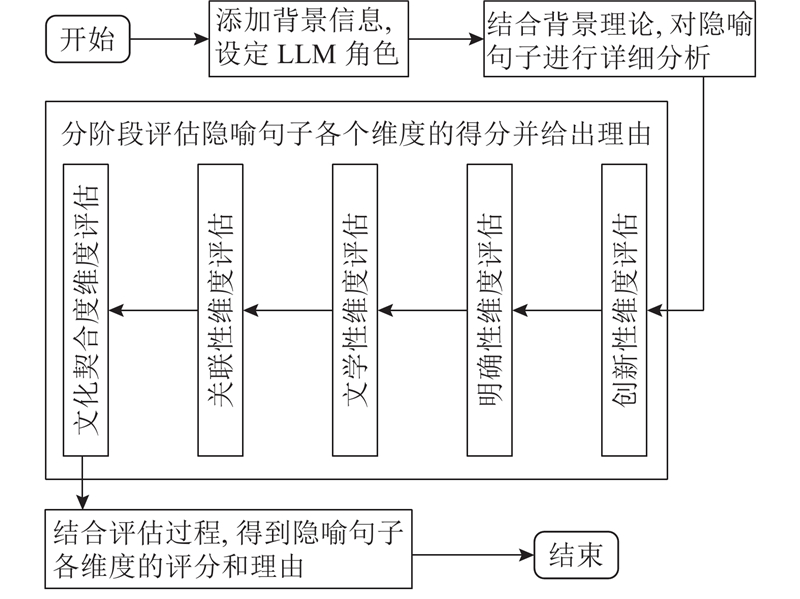
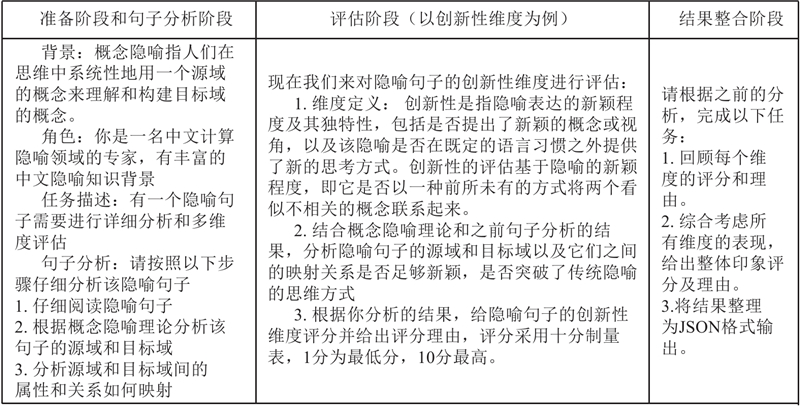
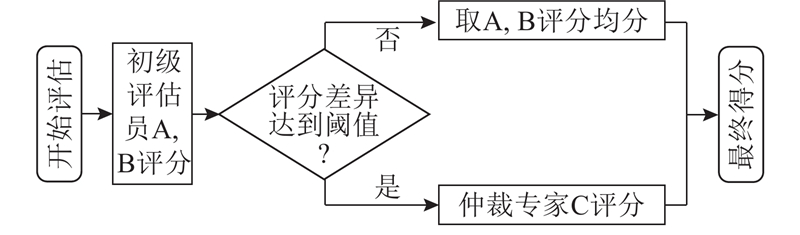
| 基于大语言模型的中文隐喻多维度评估 |
黄孝喜( ),查正超,陆诗佳 ),查正超,陆诗佳 |
| 杭州电子科技大学 计算机学院,浙江 杭州 310018 |
|
| Multi-dimensional evaluation of Chinese metaphors based on large language models |
| Xiaoxi HUANG(),Zhengchao ZHA,Shijia LU |
| School of Computer Science, Hangzhou Dianzi University, Hangzhou 310018, China |
| 1 |
SHUTOVA E Design and evaluation of metaphor processing systems[J]. Computational Linguistics, 2015, 41 (4): 579- 623
doi: 10.1162/COLI_a_00233
|
| 2 |
PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. ACM, 2002: 311–318.
|
| 3 |
LIN C Y. ROUGE: a package for automatic evaluation of summaries [C]// Proceedings of the Annual Meeting of the Association for Computational Linguistics. Barcelona: ACL, 2004: 74–81.
|
| 4 |
LI Y, LIN C, GUERIN F. Nominal metaphor generation with multitask learning [C]// Proceedings of the 15th International Conference on Natural Language Generation. Waterville: ACL, 2022: 225–235.
|
| 5 |
ZHANG Z, HAN X, ZHOU H, et al CPM: a large-scale generative Chinese pre-trained language model[J]. AI Open, 2021, 2: 93- 99
doi: 10.1016/j.aiopen.2021.07.001
|
| 6 |
LI J, GALLEY M, BROCKETT C, et al. A diversity-promoting objective function for neural conversation models [C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego: ACL, 2016: 110–119.
|
| 7 |
CHAKRABARTY T, ZHANG X, MURESAN S, et al. MERMAID: metaphor generation with symbolism and discriminative decoding [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. [S.l.]: ACL, 2021: 4250–4261.
|
| 8 |
REIMERS N, GUREVYCH I. Sentence-BERT: sentence embeddings using siamese BERT-networks [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong: ACL, 2019: 3980–3990.
|
| 9 |
ZHANG T, KISHORE V, WU F, et al. BERTScore: evaluating text generation with BERT [EB/OL]. (2020–02–24)[2025–04–27]. https://arxiv.org/pdf/1904.09675.
|
| 10 |
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics. Minneapolis: ACL, 2019: 4171–4186.
|
| 11 |
HEINTZ I, GABBARD R, SRIVASTAVA M, et al. Automatic extraction of linguistic metaphors with LDA topic modeling [C]// Proceedings of the First Workshop on Metaphor in NLP. Atlanta: ACL, 2013: 58–66.
|
| 12 |
DISTEFANO P V, PATTERSON J D, BEATY R E Automatic scoring of metaphor creativity with large language models[J]. Creativity Research Journal, 2025, 37 (4): 555- 569
doi: 10.1080/10400419.2024.2326343
|
| 13 |
CONNEAU A, KHANDELWAL K, GOYAL N, et al. Unsupervised cross-lingual representation learning at scale [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. [S.l.]: ACL, 2020: 8440–8451.
|
| 14 |
RADFORD A, WU J, CHILD R, et al Language models are unsupervised multitask learners[J]. OpenAI Blog, 2019, 1 (8): 9
|
| 15 |
LIU Y, ITER D, XU Y, et al. G-EVAL: NLG evaluation using GPT-4 with better human alignment [C]// Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Singapore: ACL, 2023: 2511–2522.
|
| 16 |
OpenAI, ACHIAM J, ADLER S, et al. GPT-4 technical report [EB/OL]. (2024–03–04)[2025–04–27]. https://arxiv.org/pdf/2303.08774.
|
| 17 |
WANG J, WANG J, ZHANG X. Chinese metaphor recognition using a multi-stage prompting large language model [C]// Natural Language Processing and Chinese Computing. Singapore: Springer, 2025: 234–246.
|
| 18 |
TONG X, CHOENNI R, LEWIS M, et al. Metaphor understanding challenge dataset for LLMs [C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. Bangkok: ACL, 2024: 3517–3536.
|
| 19 |
GAO H, ZHANG J, ZHANG P, et al. Consistency rating of semantic transparency: an evaluation method for metaphor competence in idiom understanding tasks [C]// Proceedings of the 31st International Conference on Computational Linguistics. Abu Dhabi: ACL, 2025: 10460–10471.
|
| 20 |
SHAO Y, YAO X, QU X, et al. CMDAG: a Chinese metaphor dataset with annotated grounds as cot for boosting metaphor generation [C]// Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation. Torino: [s.n.], 2024: 3357–3366.
|
| 21 |
WEI J, WANG X, SCHUURMANS D, et al. Chain-of-thought prompting elicits reasoning in large language models [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans: ACM, 2022: 24824–24837.
|
| 22 |
LAKOFF G, JOHNSON M. Metaphors we live by [M]. Chicago: University of Chicago Press, 2003.
|
| 23 |
LAKOFF G, JOHNSON M. Conceptual metaphor in everyday language [M]// SARASVATHY S, DEW N, VENKATARAMAN S. Shaping entrepreneurship research. London: Routledge, 2020: 475–504.
|
| 24 |
LAKOFF G. The contemporary theory of metaphor [M]. Cambridge: Cambridge University Press, 1993.
|
| 25 |
FAUCONNIER G, TURNER M. The way we think: conceptual blending and the mind’s hidden complexities [M]. New York: Basic Books, 2002.
|
| 26 |
KÖVECSES Z, BENCZES R. Metaphor: a practical introduction [M]. 2nd ed. Oxford: Oxford University Press, 2010.
|
| 27 |
GENTNER D, HOLYOAK K J, KOKINOV B N. The analogical mind: perspectives from cognitive science [M]. Cambridge: MIT Press, 2001.
|
| 28 |
KÖVECSES Z. Metaphor in culture: universality and variation [M]. Cambridge: Cambridge University Press, 2007.
|
| 29 |
PEARSON K Contributions to the mathematical theory of evolution[J]. Philosophical Transactions of the Royal Society of London Series A, 1894, 185: 71- 110
|
| 30 |
MCHUGH M L Interrater reliability: the kappa statistic[J]. Biochemia Medica, 2012, 22 (3): 276- 282
|
| 31 |
张明昊, 张东瑜, 林鸿飞. 基于 HowNet 的无监督汉语动词隐喻识别方法[C]// 第二十届中国计算语言学大会论文集. 呼和浩特: [s.n.], 2021: 258–268.
ZHANG Minghao, ZHANG Dongyu, LIN Hongfei. Unsupervised Chinese verb metaphor recognition method based on HowNet [C]// Proceedings of the 20th Chinese National Conference on Computational Linguistics. Hohhot: [s.n.], 2021: 258–268.
|
| 32 |
ZHANG Z, HAN X, LIU Z, et al. ERNIE: enhanced language representation with informative entities [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence: ACL, 2019: 1441–1451.
|
| 33 |
BAI J, BAI S, CHU Y, et al. Qwen technical report [EB/OL]. (2023–09–28)[2025–04–27]. https://arxiv.org/pdf/2309.16609.
|
| 34 |
Team GLM. ChatGLM: a family of large language models from GLM-130B to GLM-4 all tools [EB/OL]. (2024–07–30)[2025–04–27]. https://arxiv.org/pdf/2406.12793.
|
| 35 |
HADA R, GUMMA V, DE WYNTER A, et al. Are large language model-based evaluators the solution to scaling up multilingual evaluation? [C]// 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). [S.l.]: ACL, 2023: 1051–1070.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|