[1]
SHUTOVA E Design and evaluation of metaphor processing systems
[J]. Computational Linguistics , 2015 , 41 (4 ): 579 - 623
DOI:10.1162/COLI_a_00233
[本文引用: 1]
[2]
PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation [C]// Proceedings of the 40th Annual Meeting on Association for Computational Linguistics . ACM, 2002: 311–318.
[本文引用: 1]
[3]
LIN C Y. ROUGE: a package for automatic evaluation of summaries [C]// Proceedings of the Annual Meeting of the Association for Computational Linguistics . Barcelona: ACL, 2004: 74–81.
[本文引用: 1]
[4]
LI Y, LIN C, GUERIN F. Nominal metaphor generation with multitask learning [C]// Proceedings of the 15th International Conference on Natural Language Generation . Waterville: ACL, 2022: 225–235.
[本文引用: 3]
[6]
LI J, GALLEY M, BROCKETT C, et al. A diversity-promoting objective function for neural conversation models [C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies . San Diego: ACL, 2016: 110–119.
[本文引用: 1]
[7]
CHAKRABARTY T, ZHANG X, MURESAN S, et al. MERMAID: metaphor generation with symbolism and discriminative decoding [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies . [S.l.]: ACL, 2021: 4250–4261.
[本文引用: 2]
[8]
REIMERS N, GUREVYCH I. Sentence-BERT: sentence embeddings using siamese BERT-networks [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing . Hong Kong: ACL, 2019: 3980–3990.
[本文引用: 1]
[9]
ZHANG T, KISHORE V, WU F, et al. BERTScore: evaluating text generation with BERT [EB/OL]. (2020–02–24)[2025–04–27]. https://arxiv.org/pdf/1904.09675.
[本文引用: 1]
[10]
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics . Minneapolis: ACL, 2019: 4171–4186.
[本文引用: 1]
[11]
HEINTZ I, GABBARD R, SRIVASTAVA M, et al. Automatic extraction of linguistic metaphors with LDA topic modeling [C]// Proceedings of the First Workshop on Metaphor in NLP . Atlanta: ACL, 2013: 58–66.
[本文引用: 1]
[12]
DISTEFANO P V, PATTERSON J D, BEATY R E Automatic scoring of metaphor creativity with large language models
[J]. Creativity Research Journal , 2025 , 37 (4 ): 555 - 569
DOI:10.1080/10400419.2024.2326343
[本文引用: 1]
[13]
CONNEAU A, KHANDELWAL K, GOYAL N, et al. Unsupervised cross-lingual representation learning at scale [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics . [S.l.]: ACL, 2020: 8440–8451.
[本文引用: 1]
[14]
RADFORD A, WU J, CHILD R, et al Language models are unsupervised multitask learners
[J]. OpenAI Blog , 2019 , 1 (8 ): 9
[本文引用: 1]
[15]
LIU Y, ITER D, XU Y, et al. G-EVAL: NLG evaluation using GPT-4 with better human alignment [C]// Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing . Singapore: ACL, 2023: 2511–2522.
[本文引用: 1]
[16]
OpenAI, ACHIAM J, ADLER S, et al. GPT-4 technical report [EB/OL]. (2024–03–04)[2025–04–27]. https://arxiv.org/pdf/2303.08774.
[本文引用: 2]
[17]
WANG J, WANG J, ZHANG X. Chinese metaphor recognition using a multi-stage prompting large language model [C]// Natural Language Processing and Chinese Computing . Singapore: Springer, 2025: 234–246.
[本文引用: 1]
[18]
TONG X, CHOENNI R, LEWIS M, et al. Metaphor understanding challenge dataset for LLMs [C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics . Bangkok: ACL, 2024: 3517–3536.
[本文引用: 1]
[19]
GAO H, ZHANG J, ZHANG P, et al. Consistency rating of semantic transparency: an evaluation method for metaphor competence in idiom understanding tasks [C]// Proceedings of the 31st International Conference on Computational Linguistics . Abu Dhabi: ACL, 2025: 10460–10471.
[本文引用: 1]
[20]
SHAO Y, YAO X, QU X, et al. CMDAG: a Chinese metaphor dataset with annotated grounds as cot for boosting metaphor generation [C]// Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation . Torino: [s.n.], 2024: 3357–3366.
[本文引用: 4]
[21]
WEI J, WANG X, SCHUURMANS D, et al. Chain-of-thought prompting elicits reasoning in large language models [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems . New Orleans: ACM, 2022: 24824–24837.
[本文引用: 1]
[22]
LAKOFF G, JOHNSON M. Metaphors we live by [M]. Chicago: University of Chicago Press, 2003.
[本文引用: 1]
[23]
LAKOFF G, JOHNSON M. Conceptual metaphor in everyday language [M]// SARASVATHY S, DEW N, VENKATARAMAN S. Shaping entrepreneurship research . London: Routledge, 2020: 475–504.
[本文引用: 1]
[24]
LAKOFF G. The contemporary theory of metaphor [M]. Cambridge: Cambridge University Press, 1993.
[本文引用: 1]
[25]
FAUCONNIER G, TURNER M. The way we think: conceptual blending and the mind’s hidden complexities [M]. New York: Basic Books, 2002.
[本文引用: 1]
[26]
KÖVECSES Z, BENCZES R. Metaphor: a practical introduction [M]. 2nd ed. Oxford: Oxford University Press, 2010.
[本文引用: 1]
[27]
GENTNER D, HOLYOAK K J, KOKINOV B N. The analogical mind: perspectives from cognitive science [M]. Cambridge: MIT Press, 2001.
[本文引用: 1]
[28]
KÖVECSES Z. Metaphor in culture: universality and variation [M]. Cambridge: Cambridge University Press, 2007.
[本文引用: 1]
[29]
PEARSON K Contributions to the mathematical theory of evolution
[J]. Philosophical Transactions of the Royal Society of London Series A , 1894 , 185 : 71 - 110
[本文引用: 1]
[30]
MCHUGH M L Interrater reliability: the kappa statistic
[J]. Biochemia Medica , 2012 , 22 (3 ): 276 - 282
[本文引用: 1]
[31]
张明昊, 张东瑜, 林鸿飞. 基于 HowNet 的无监督汉语动词隐喻识别方法[C]// 第二十届中国计算语言学大会论文集. 呼和浩特: [s.n.], 2021: 258–268.
[本文引用: 1]
ZHANG Minghao, ZHANG Dongyu, LIN Hongfei. Unsupervised Chinese verb metaphor recognition method based on HowNet [C]// Proceedings of the 20th Chinese National Conference on Computational Linguistics . Hohhot: [s.n.], 2021: 258–268.
[本文引用: 1]
[32]
ZHANG Z, HAN X, LIU Z, et al. ERNIE: enhanced language representation with informative entities [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics . Florence: ACL, 2019: 1441–1451.
[本文引用: 1]
[33]
BAI J, BAI S, CHU Y, et al. Qwen technical report [EB/OL]. (2023–09–28)[2025–04–27]. https://arxiv.org/pdf/2309.16609.
[本文引用: 1]
[34]
Team GLM. ChatGLM: a family of large language models from GLM-130B to GLM-4 all tools [EB/OL]. (2024–07–30)[2025–04–27]. https://arxiv.org/pdf/2406.12793.
[本文引用: 1]
[35]
HADA R, GUMMA V, DE WYNTER A, et al. Are large language model-based evaluators the solution to scaling up multilingual evaluation? [C]// 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA) . [S.l.]: ACL, 2023: 1051–1070.
[本文引用: 1]
[36]
SONG H, SU H, SHALYMINOV I, et al. FineSurE: fine-grained summarization evaluation using LLMs [C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics . Bangkok: ACL, 2024: 906–922.
[本文引用: 1]
Design and evaluation of metaphor processing systems
1
2015
... 隐喻是语言中广泛应用的修辞手法,能够有效地表达复杂的思想、情感和概念. 隐喻研究作为自然语言处理领域里复杂又具有挑战性的任务,受到越来越多研究者的关注[1 ] . 随着隐喻研究的快速发展,隐喻评估的重要性也日益凸显. ...
1
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
1
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
3
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
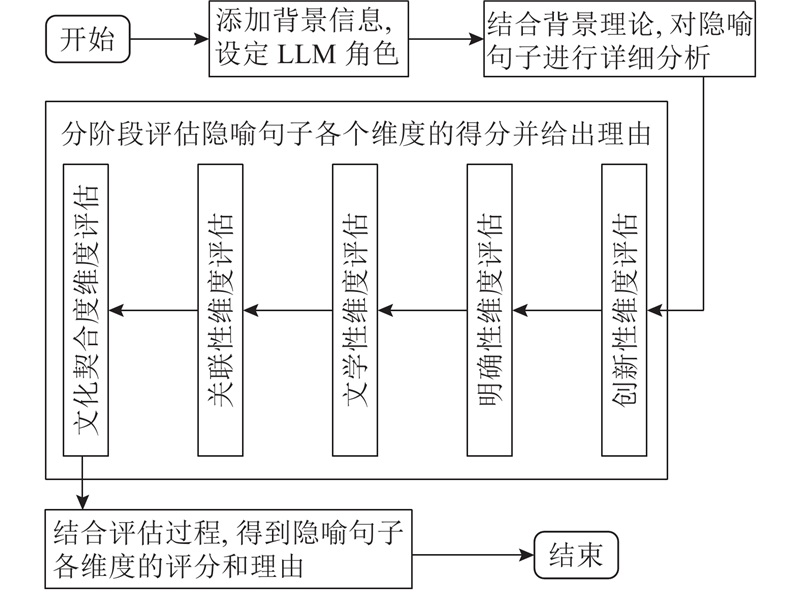
... 根据Li等[4 ,7 ,20 ] 的总结,隐喻评估主要聚焦于隐喻的恰当性、创造性以及清晰度等维度. 为了确保隐喻句子评估的系统性和客观性,本研究在评估指标和认知语言学的基础上,提出包含创新性、明确性、文学性、关联性以及文化契合度等5个维度的评估指标. 该多维度评估指标在包含以往研究聚焦重点的同时,加入中文隐喻评估中需要注意的有关文化背景以及文学表达的评估维度,旨在尽可能全面衡量中文隐喻句子的质量. ...
... 数据收集聚焦于中文隐喻句子,旨在服务于中文隐喻评估的研究. 当前隐喻生成模型的研究方向主要集中在词性和语言分类上,因此数据收集以中文的动词和名词性隐喻为主. 为了使数据集具有代表性且能够提供足够广泛的变化以支持深入分析,收集了多个来源的信息. 隐喻句子来源于多个经过筛选的中文文本资源,其中动词性隐喻主要来自张明昊等[31 ] 构建的动词隐喻数据集. 该数据集专注于中文动词性隐喻,包含丰富的中文动词隐喻实例和详细的注释. 名词性隐喻主要来自Shao等[20 ] 构建的CMDAG中文隐喻数据集和Li等[4 ] 构建的CMC数据集. 这2个数据集中包含多个领域的中文名词性隐喻,涵盖散文、诗歌、歌曲以及小说等常见的体裁. 在这些数据集中挑选约300个名词性隐喻句子和300个动词性隐喻句子. 句子挑选遵循数据多样化的原则,选取不同体裁,不同质量的隐喻句子,保证数据集的多样性. 由于隐喻评估主要服务于隐喻生成任务,用来衡量模型生成隐喻的能力. 为此使用文献[20 ]中的方法,利用GPT-4模型生成隐喻句子,这些模型生成句子质量不一,用来增加数据集的多样性和有效性. ...
CPM: a large-scale generative Chinese pre-trained language model
1
2021
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
1
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
2
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
... 根据Li等[4 ,7 ,20 ] 的总结,隐喻评估主要聚焦于隐喻的恰当性、创造性以及清晰度等维度. 为了确保隐喻句子评估的系统性和客观性,本研究在评估指标和认知语言学的基础上,提出包含创新性、明确性、文学性、关联性以及文化契合度等5个维度的评估指标. 该多维度评估指标在包含以往研究聚焦重点的同时,加入中文隐喻评估中需要注意的有关文化背景以及文学表达的评估维度,旨在尽可能全面衡量中文隐喻句子的质量. ...
1
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
1
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
1
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
1
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
Automatic scoring of metaphor creativity with large language models
1
2025
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
1
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
Language models are unsupervised multitask learners
1
2019
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
1
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
2
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
... 为了证明不同大语言模型在隐喻评估任务上的一致性,选取4个先进的大语言模型:GPT-4[16 ] 、ERNIE-4.0[32 ] 、Qwen2.5[33 ] 和 GLM-4-Plus[34 ] ,通过应用程序编程接口(application programming interface, API)使用. 这些模型各自具备独特的架构设计和技术特点. 1)GPT-4: 作为OpenAI推出的第4代生成式大语言模型,拥有庞大的参数量,通过多模态学习增强对文本的理解能力. 2)ERNIE-4.0: 百度研发的大语言模型,长文本处理能力得到优化,在中文语境下的理解和生成能力突出. 3)Qwen2.5: 由阿里云开发的大模型,它融合了包括图像、文本在内的多种信息源,强调交互式对话能力的提升,使其在模拟人类思维链路处理问题时展现出独特的优势. 4)GLM-4-Plus: 基于大语言模型架构,继承并发展了前几代模型的优点,利用近端策略优化(proximal policy optimization, PPO)算法提升推理能力,能够处理复杂的逻辑问题. GLM-4-Plus在大规模预训练基础上对推理路径生成、多步逻辑推演和指令遵循能力等进行针对性优化,极大增强了模型在中文语料上的适应性. 为了确保实验的可复现性以及实验中评分的稳定性,将所有参与实验模型的温度(temperature)参数设置为0. 温度参数在大语言模型中用于控制生成文本的随机性,Hada等[35 ] 的研究表明,基于大语言模型评估器的评估性能往往会随着温度的升高下降. 此外,将模型的其他参数也统一设置,将最大生成令牌(max_tokens)参数设置为1024 ;将核采样阈值(top_p)参数设置为1.0;将流式输出(stream)参数设置为False;将频率惩罚(frequency penalty)参数设置为0;将存在惩罚(presence penalty)参数设置为0. ...
1
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
1
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
1
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
4
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
... 根据Li等[4 ,7 ,20 ] 的总结,隐喻评估主要聚焦于隐喻的恰当性、创造性以及清晰度等维度. 为了确保隐喻句子评估的系统性和客观性,本研究在评估指标和认知语言学的基础上,提出包含创新性、明确性、文学性、关联性以及文化契合度等5个维度的评估指标. 该多维度评估指标在包含以往研究聚焦重点的同时,加入中文隐喻评估中需要注意的有关文化背景以及文学表达的评估维度,旨在尽可能全面衡量中文隐喻句子的质量. ...
... 数据收集聚焦于中文隐喻句子,旨在服务于中文隐喻评估的研究. 当前隐喻生成模型的研究方向主要集中在词性和语言分类上,因此数据收集以中文的动词和名词性隐喻为主. 为了使数据集具有代表性且能够提供足够广泛的变化以支持深入分析,收集了多个来源的信息. 隐喻句子来源于多个经过筛选的中文文本资源,其中动词性隐喻主要来自张明昊等[31 ] 构建的动词隐喻数据集. 该数据集专注于中文动词性隐喻,包含丰富的中文动词隐喻实例和详细的注释. 名词性隐喻主要来自Shao等[20 ] 构建的CMDAG中文隐喻数据集和Li等[4 ] 构建的CMC数据集. 这2个数据集中包含多个领域的中文名词性隐喻,涵盖散文、诗歌、歌曲以及小说等常见的体裁. 在这些数据集中挑选约300个名词性隐喻句子和300个动词性隐喻句子. 句子挑选遵循数据多样化的原则,选取不同体裁,不同质量的隐喻句子,保证数据集的多样性. 由于隐喻评估主要服务于隐喻生成任务,用来衡量模型生成隐喻的能力. 为此使用文献[20 ]中的方法,利用GPT-4模型生成隐喻句子,这些模型生成句子质量不一,用来增加数据集的多样性和有效性. ...
... 构建的CMC数据集. 这2个数据集中包含多个领域的中文名词性隐喻,涵盖散文、诗歌、歌曲以及小说等常见的体裁. 在这些数据集中挑选约300个名词性隐喻句子和300个动词性隐喻句子. 句子挑选遵循数据多样化的原则,选取不同体裁,不同质量的隐喻句子,保证数据集的多样性. 由于隐喻评估主要服务于隐喻生成任务,用来衡量模型生成隐喻的能力. 为此使用文献[20 ]中的方法,利用GPT-4模型生成隐喻句子,这些模型生成句子质量不一,用来增加数据集的多样性和有效性. ...
1
... 传统的自动评估指标(如BLEU[2 ] 、ROUGE[3 ] ),在计算隐喻研究早期经常被用来评估隐喻生成的质量. 随着预训练模型的发展,文本评估方法不断更新为隐喻评估提供新的思路. 例如,Li等[4 ] 使用困惑度(perplexity, PPL)[5 ] 来评估隐喻生成文本的流利度,使用Dist-1和Dist-2指标[6 ] 来评估生成文本的多样性. Chakrabarty等[7 ] 使用Sentence-BERT[8 ] 来计算句向量之间的语义相似度,并引入BERTScore[9 ] 对隐喻生产句子进行质量评估. 也有研究使用其他预训练模型(如BERT[10 ] 、BART[11 ] 和GPT等)来计算语义相似度. 针对创新性隐喻,Distefano等[12 ] 微调开源预训练模型RoBERTa[13 ] 和GPT-2[14 ] ,进行隐喻的创造性评估. 尽管这些方法为隐喻评估提供了便捷的工具,但它们在捕捉隐喻创造性、语境适配性和深层语义关系等方面仍存在局限. 尤其是在处理复杂或创新性隐喻时,可能无法充分反映隐喻的质量和特点. 人工评估过程费时且成本较高,还可能因评估者的文化背景和个人理解差异而影响评估的客观性. 自从GPT3.5发布以来,大语言模型(large language model,LLM)在文本评估和隐喻领域发展迅速. Liu等[15 ] 提出G-EVAL框架,利用GPT-4[16 ] 评估自然语言生成文本的质量,该方法在文本摘要和对话生成2个任务上优于其他评估方法. Wang等[17 ] 通过生成启发增强式的框架,提高大语言模型识别中文隐喻的能力. Tong等[18 ] 通过构建隐喻理解挑战数据集MUNCH,验证了大语言模型在一定程度上能理解隐喻. Gao等[19 ] 通过基于人类语言逻辑的自校验同义替换(paraphrase augmentation strategy with self-checking,PASS)策略,在成语理解任务上验证了大语言模型能够很好地理解隐喻. 在隐喻生成领域,Shao等[20 ] 创建包含本体、喻体和共性的数据集,通过思维链[21 ] 提示指导大语言模型生成高质量的隐喻句子. ...
1
... 在隐喻理解和生成研究中,概念隐喻理论占据重要地位. Lakoff等[22 ] 提出的概念隐喻理论,以隐喻为核心,深入探讨其本质,展示了语言与隐喻认知结构间的紧密联系. 概念隐喻认为,隐喻不仅是语言现象,更反映人类认知中源域(source domain)与目标域(target domain)之间的系统性映射. 隐喻是指在特定语境下,将一个领域的概念映射到另一个领域[23 ] ,隐喻在本质上并不存在于语言本身,而是存在于它们在应用中将一个域概念映射到另一个域的方式中[24 ] . 通过这种跨域映射,人们以熟悉的概念理解抽象或复杂的事物. 隐喻生成的质量,尤其是创新性和明确性,通常依赖于源域与目标域之间合理且新颖的关联. 因此,概念隐喻为隐喻评估提供了理论依据,强调对深层语义联系、认知合理性和文化适配性的考量. 在实际评估中,理解并应用概念隐喻理论有助于更加系统、准确地判断隐喻生成的质量,弥补传统自动化指标难以触及的认知层面差异. ...
1
... 在隐喻理解和生成研究中,概念隐喻理论占据重要地位. Lakoff等[22 ] 提出的概念隐喻理论,以隐喻为核心,深入探讨其本质,展示了语言与隐喻认知结构间的紧密联系. 概念隐喻认为,隐喻不仅是语言现象,更反映人类认知中源域(source domain)与目标域(target domain)之间的系统性映射. 隐喻是指在特定语境下,将一个领域的概念映射到另一个领域[23 ] ,隐喻在本质上并不存在于语言本身,而是存在于它们在应用中将一个域概念映射到另一个域的方式中[24 ] . 通过这种跨域映射,人们以熟悉的概念理解抽象或复杂的事物. 隐喻生成的质量,尤其是创新性和明确性,通常依赖于源域与目标域之间合理且新颖的关联. 因此,概念隐喻为隐喻评估提供了理论依据,强调对深层语义联系、认知合理性和文化适配性的考量. 在实际评估中,理解并应用概念隐喻理论有助于更加系统、准确地判断隐喻生成的质量,弥补传统自动化指标难以触及的认知层面差异. ...
1
... 在隐喻理解和生成研究中,概念隐喻理论占据重要地位. Lakoff等[22 ] 提出的概念隐喻理论,以隐喻为核心,深入探讨其本质,展示了语言与隐喻认知结构间的紧密联系. 概念隐喻认为,隐喻不仅是语言现象,更反映人类认知中源域(source domain)与目标域(target domain)之间的系统性映射. 隐喻是指在特定语境下,将一个领域的概念映射到另一个领域[23 ] ,隐喻在本质上并不存在于语言本身,而是存在于它们在应用中将一个域概念映射到另一个域的方式中[24 ] . 通过这种跨域映射,人们以熟悉的概念理解抽象或复杂的事物. 隐喻生成的质量,尤其是创新性和明确性,通常依赖于源域与目标域之间合理且新颖的关联. 因此,概念隐喻为隐喻评估提供了理论依据,强调对深层语义联系、认知合理性和文化适配性的考量. 在实际评估中,理解并应用概念隐喻理论有助于更加系统、准确地判断隐喻生成的质量,弥补传统自动化指标难以触及的认知层面差异. ...
1
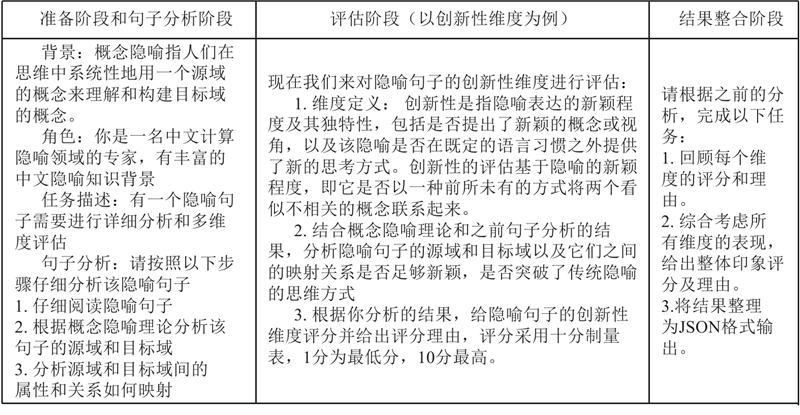
... 1)创新性:在认知语言学中,隐喻被视为创造性的语言使用方式,能够激发新的联想和思考[25 ] . 创新性是指隐喻表达的新颖程度及其独特性,包括是否提出新的概念或视角,以及该隐喻是否在既定的语言习惯之外提供新的思考方式. 2)关联性:在概念隐喻理论中,隐喻的映射过程需要源域和目标域之间存在某种内在的逻辑或相似性[26 ] . 关联性考察隐喻与其所指事物之间的联系强度,即隐喻是否恰当地反映了两者之间的逻辑关系,并增强了对事物的理解. 3)明确性:指隐喻表达是否清晰、易于理解. 在认知语言学中,隐喻的理解过程涉及对喻体特征的选择性投射和跨域校准[27 ] . 如果隐喻表达模糊或存在映射断裂,读者可能难以准确提取喻体的特征,从而影响对隐喻意义的把握. 4)文学性:关注隐喻生成句子的文学艺术价值,包括语言美感、修辞技巧运用、文本连贯性等. 例如“忽如一夜春风来,千树万树梨花开”,这是家喻户晓的描写雪的隐喻诗句,句式工整,修辞巧妙,文学性极高. 5)文化契合度:概念隐喻理论指出,隐喻系统植根于文化具身体验[28 ] . 隐喻的理解受到文化背景和认知框架的影响,不同的文化和社会群体可能具有不同的隐喻系统和认知模式. 文化契合度考量隐喻在特定文化背景下的接受度和适应性,包括它是否符合文化习俗、价值观和信仰等. ...
1
... 1)创新性:在认知语言学中,隐喻被视为创造性的语言使用方式,能够激发新的联想和思考[25 ] . 创新性是指隐喻表达的新颖程度及其独特性,包括是否提出新的概念或视角,以及该隐喻是否在既定的语言习惯之外提供新的思考方式. 2)关联性:在概念隐喻理论中,隐喻的映射过程需要源域和目标域之间存在某种内在的逻辑或相似性[26 ] . 关联性考察隐喻与其所指事物之间的联系强度,即隐喻是否恰当地反映了两者之间的逻辑关系,并增强了对事物的理解. 3)明确性:指隐喻表达是否清晰、易于理解. 在认知语言学中,隐喻的理解过程涉及对喻体特征的选择性投射和跨域校准[27 ] . 如果隐喻表达模糊或存在映射断裂,读者可能难以准确提取喻体的特征,从而影响对隐喻意义的把握. 4)文学性:关注隐喻生成句子的文学艺术价值,包括语言美感、修辞技巧运用、文本连贯性等. 例如“忽如一夜春风来,千树万树梨花开”,这是家喻户晓的描写雪的隐喻诗句,句式工整,修辞巧妙,文学性极高. 5)文化契合度:概念隐喻理论指出,隐喻系统植根于文化具身体验[28 ] . 隐喻的理解受到文化背景和认知框架的影响,不同的文化和社会群体可能具有不同的隐喻系统和认知模式. 文化契合度考量隐喻在特定文化背景下的接受度和适应性,包括它是否符合文化习俗、价值观和信仰等. ...
1
... 1)创新性:在认知语言学中,隐喻被视为创造性的语言使用方式,能够激发新的联想和思考[25 ] . 创新性是指隐喻表达的新颖程度及其独特性,包括是否提出新的概念或视角,以及该隐喻是否在既定的语言习惯之外提供新的思考方式. 2)关联性:在概念隐喻理论中,隐喻的映射过程需要源域和目标域之间存在某种内在的逻辑或相似性[26 ] . 关联性考察隐喻与其所指事物之间的联系强度,即隐喻是否恰当地反映了两者之间的逻辑关系,并增强了对事物的理解. 3)明确性:指隐喻表达是否清晰、易于理解. 在认知语言学中,隐喻的理解过程涉及对喻体特征的选择性投射和跨域校准[27 ] . 如果隐喻表达模糊或存在映射断裂,读者可能难以准确提取喻体的特征,从而影响对隐喻意义的把握. 4)文学性:关注隐喻生成句子的文学艺术价值,包括语言美感、修辞技巧运用、文本连贯性等. 例如“忽如一夜春风来,千树万树梨花开”,这是家喻户晓的描写雪的隐喻诗句,句式工整,修辞巧妙,文学性极高. 5)文化契合度:概念隐喻理论指出,隐喻系统植根于文化具身体验[28 ] . 隐喻的理解受到文化背景和认知框架的影响,不同的文化和社会群体可能具有不同的隐喻系统和认知模式. 文化契合度考量隐喻在特定文化背景下的接受度和适应性,包括它是否符合文化习俗、价值观和信仰等. ...
1
... 1)创新性:在认知语言学中,隐喻被视为创造性的语言使用方式,能够激发新的联想和思考[25 ] . 创新性是指隐喻表达的新颖程度及其独特性,包括是否提出新的概念或视角,以及该隐喻是否在既定的语言习惯之外提供新的思考方式. 2)关联性:在概念隐喻理论中,隐喻的映射过程需要源域和目标域之间存在某种内在的逻辑或相似性[26 ] . 关联性考察隐喻与其所指事物之间的联系强度,即隐喻是否恰当地反映了两者之间的逻辑关系,并增强了对事物的理解. 3)明确性:指隐喻表达是否清晰、易于理解. 在认知语言学中,隐喻的理解过程涉及对喻体特征的选择性投射和跨域校准[27 ] . 如果隐喻表达模糊或存在映射断裂,读者可能难以准确提取喻体的特征,从而影响对隐喻意义的把握. 4)文学性:关注隐喻生成句子的文学艺术价值,包括语言美感、修辞技巧运用、文本连贯性等. 例如“忽如一夜春风来,千树万树梨花开”,这是家喻户晓的描写雪的隐喻诗句,句式工整,修辞巧妙,文学性极高. 5)文化契合度:概念隐喻理论指出,隐喻系统植根于文化具身体验[28 ] . 隐喻的理解受到文化背景和认知框架的影响,不同的文化和社会群体可能具有不同的隐喻系统和认知模式. 文化契合度考量隐喻在特定文化背景下的接受度和适应性,包括它是否符合文化习俗、价值观和信仰等. ...
Contributions to the mathematical theory of evolution
1
1894
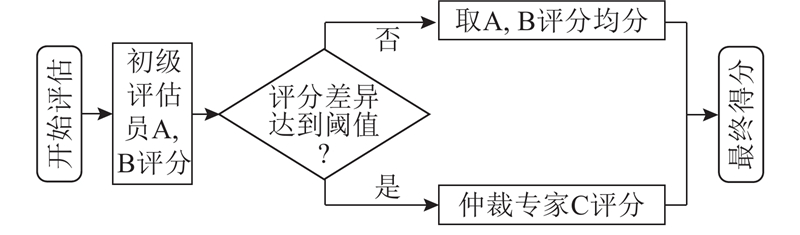
... 在对隐喻句子进行质量评估的过程中,模型和人工评分的一致性是衡量大语言模型在中文隐喻评估任务上可行性和可靠性的重要指标. 本研究采用2种常用的评估指标:皮尔逊相关系数[29 ] 和卡帕(Cohen’s Kappa)系数[30 ] ,它们能够从不同的角度进行大语言模型与人工评分的一致性验证,评估大语言模型在隐喻评估任务上的有效性. 皮尔逊相关系数用于测量2个变量之间的线性关系强度和方向,有效反映大语言模型评分与人工评分之间的整体趋势是否一致;它能够量化模型评分与专家评分之间的关联程度,判断模型在中文隐喻评估任务上的表现是否稳定且可靠. 卡帕系数侧重于评估评分者之间的一致性,尤其适用于分类或评分存在主观性的情况;它不仅考虑评分一致的比例,还纠正了由于随机一致性导致的偏差. 在隐喻评估这个可能存在高度主观性的领域,卡帕系数能够提供严格的检验标准,确保模型评分不仅与人工评分结果相近,而且是在排除偶然因素影响下的真实反映. ...
Interrater reliability: the kappa statistic
1
2012
... 在对隐喻句子进行质量评估的过程中,模型和人工评分的一致性是衡量大语言模型在中文隐喻评估任务上可行性和可靠性的重要指标. 本研究采用2种常用的评估指标:皮尔逊相关系数[29 ] 和卡帕(Cohen’s Kappa)系数[30 ] ,它们能够从不同的角度进行大语言模型与人工评分的一致性验证,评估大语言模型在隐喻评估任务上的有效性. 皮尔逊相关系数用于测量2个变量之间的线性关系强度和方向,有效反映大语言模型评分与人工评分之间的整体趋势是否一致;它能够量化模型评分与专家评分之间的关联程度,判断模型在中文隐喻评估任务上的表现是否稳定且可靠. 卡帕系数侧重于评估评分者之间的一致性,尤其适用于分类或评分存在主观性的情况;它不仅考虑评分一致的比例,还纠正了由于随机一致性导致的偏差. 在隐喻评估这个可能存在高度主观性的领域,卡帕系数能够提供严格的检验标准,确保模型评分不仅与人工评分结果相近,而且是在排除偶然因素影响下的真实反映. ...
1
... 数据收集聚焦于中文隐喻句子,旨在服务于中文隐喻评估的研究. 当前隐喻生成模型的研究方向主要集中在词性和语言分类上,因此数据收集以中文的动词和名词性隐喻为主. 为了使数据集具有代表性且能够提供足够广泛的变化以支持深入分析,收集了多个来源的信息. 隐喻句子来源于多个经过筛选的中文文本资源,其中动词性隐喻主要来自张明昊等[31 ] 构建的动词隐喻数据集. 该数据集专注于中文动词性隐喻,包含丰富的中文动词隐喻实例和详细的注释. 名词性隐喻主要来自Shao等[20 ] 构建的CMDAG中文隐喻数据集和Li等[4 ] 构建的CMC数据集. 这2个数据集中包含多个领域的中文名词性隐喻,涵盖散文、诗歌、歌曲以及小说等常见的体裁. 在这些数据集中挑选约300个名词性隐喻句子和300个动词性隐喻句子. 句子挑选遵循数据多样化的原则,选取不同体裁,不同质量的隐喻句子,保证数据集的多样性. 由于隐喻评估主要服务于隐喻生成任务,用来衡量模型生成隐喻的能力. 为此使用文献[20 ]中的方法,利用GPT-4模型生成隐喻句子,这些模型生成句子质量不一,用来增加数据集的多样性和有效性. ...
1
... 数据收集聚焦于中文隐喻句子,旨在服务于中文隐喻评估的研究. 当前隐喻生成模型的研究方向主要集中在词性和语言分类上,因此数据收集以中文的动词和名词性隐喻为主. 为了使数据集具有代表性且能够提供足够广泛的变化以支持深入分析,收集了多个来源的信息. 隐喻句子来源于多个经过筛选的中文文本资源,其中动词性隐喻主要来自张明昊等[31 ] 构建的动词隐喻数据集. 该数据集专注于中文动词性隐喻,包含丰富的中文动词隐喻实例和详细的注释. 名词性隐喻主要来自Shao等[20 ] 构建的CMDAG中文隐喻数据集和Li等[4 ] 构建的CMC数据集. 这2个数据集中包含多个领域的中文名词性隐喻,涵盖散文、诗歌、歌曲以及小说等常见的体裁. 在这些数据集中挑选约300个名词性隐喻句子和300个动词性隐喻句子. 句子挑选遵循数据多样化的原则,选取不同体裁,不同质量的隐喻句子,保证数据集的多样性. 由于隐喻评估主要服务于隐喻生成任务,用来衡量模型生成隐喻的能力. 为此使用文献[20 ]中的方法,利用GPT-4模型生成隐喻句子,这些模型生成句子质量不一,用来增加数据集的多样性和有效性. ...
1
... 为了证明不同大语言模型在隐喻评估任务上的一致性,选取4个先进的大语言模型:GPT-4[16 ] 、ERNIE-4.0[32 ] 、Qwen2.5[33 ] 和 GLM-4-Plus[34 ] ,通过应用程序编程接口(application programming interface, API)使用. 这些模型各自具备独特的架构设计和技术特点. 1)GPT-4: 作为OpenAI推出的第4代生成式大语言模型,拥有庞大的参数量,通过多模态学习增强对文本的理解能力. 2)ERNIE-4.0: 百度研发的大语言模型,长文本处理能力得到优化,在中文语境下的理解和生成能力突出. 3)Qwen2.5: 由阿里云开发的大模型,它融合了包括图像、文本在内的多种信息源,强调交互式对话能力的提升,使其在模拟人类思维链路处理问题时展现出独特的优势. 4)GLM-4-Plus: 基于大语言模型架构,继承并发展了前几代模型的优点,利用近端策略优化(proximal policy optimization, PPO)算法提升推理能力,能够处理复杂的逻辑问题. GLM-4-Plus在大规模预训练基础上对推理路径生成、多步逻辑推演和指令遵循能力等进行针对性优化,极大增强了模型在中文语料上的适应性. 为了确保实验的可复现性以及实验中评分的稳定性,将所有参与实验模型的温度(temperature)参数设置为0. 温度参数在大语言模型中用于控制生成文本的随机性,Hada等[35 ] 的研究表明,基于大语言模型评估器的评估性能往往会随着温度的升高下降. 此外,将模型的其他参数也统一设置,将最大生成令牌(max_tokens)参数设置为1024 ;将核采样阈值(top_p)参数设置为1.0;将流式输出(stream)参数设置为False;将频率惩罚(frequency penalty)参数设置为0;将存在惩罚(presence penalty)参数设置为0. ...
1
... 为了证明不同大语言模型在隐喻评估任务上的一致性,选取4个先进的大语言模型:GPT-4[16 ] 、ERNIE-4.0[32 ] 、Qwen2.5[33 ] 和 GLM-4-Plus[34 ] ,通过应用程序编程接口(application programming interface, API)使用. 这些模型各自具备独特的架构设计和技术特点. 1)GPT-4: 作为OpenAI推出的第4代生成式大语言模型,拥有庞大的参数量,通过多模态学习增强对文本的理解能力. 2)ERNIE-4.0: 百度研发的大语言模型,长文本处理能力得到优化,在中文语境下的理解和生成能力突出. 3)Qwen2.5: 由阿里云开发的大模型,它融合了包括图像、文本在内的多种信息源,强调交互式对话能力的提升,使其在模拟人类思维链路处理问题时展现出独特的优势. 4)GLM-4-Plus: 基于大语言模型架构,继承并发展了前几代模型的优点,利用近端策略优化(proximal policy optimization, PPO)算法提升推理能力,能够处理复杂的逻辑问题. GLM-4-Plus在大规模预训练基础上对推理路径生成、多步逻辑推演和指令遵循能力等进行针对性优化,极大增强了模型在中文语料上的适应性. 为了确保实验的可复现性以及实验中评分的稳定性,将所有参与实验模型的温度(temperature)参数设置为0. 温度参数在大语言模型中用于控制生成文本的随机性,Hada等[35 ] 的研究表明,基于大语言模型评估器的评估性能往往会随着温度的升高下降. 此外,将模型的其他参数也统一设置,将最大生成令牌(max_tokens)参数设置为1024 ;将核采样阈值(top_p)参数设置为1.0;将流式输出(stream)参数设置为False;将频率惩罚(frequency penalty)参数设置为0;将存在惩罚(presence penalty)参数设置为0. ...
1
... 为了证明不同大语言模型在隐喻评估任务上的一致性,选取4个先进的大语言模型:GPT-4[16 ] 、ERNIE-4.0[32 ] 、Qwen2.5[33 ] 和 GLM-4-Plus[34 ] ,通过应用程序编程接口(application programming interface, API)使用. 这些模型各自具备独特的架构设计和技术特点. 1)GPT-4: 作为OpenAI推出的第4代生成式大语言模型,拥有庞大的参数量,通过多模态学习增强对文本的理解能力. 2)ERNIE-4.0: 百度研发的大语言模型,长文本处理能力得到优化,在中文语境下的理解和生成能力突出. 3)Qwen2.5: 由阿里云开发的大模型,它融合了包括图像、文本在内的多种信息源,强调交互式对话能力的提升,使其在模拟人类思维链路处理问题时展现出独特的优势. 4)GLM-4-Plus: 基于大语言模型架构,继承并发展了前几代模型的优点,利用近端策略优化(proximal policy optimization, PPO)算法提升推理能力,能够处理复杂的逻辑问题. GLM-4-Plus在大规模预训练基础上对推理路径生成、多步逻辑推演和指令遵循能力等进行针对性优化,极大增强了模型在中文语料上的适应性. 为了确保实验的可复现性以及实验中评分的稳定性,将所有参与实验模型的温度(temperature)参数设置为0. 温度参数在大语言模型中用于控制生成文本的随机性,Hada等[35 ] 的研究表明,基于大语言模型评估器的评估性能往往会随着温度的升高下降. 此外,将模型的其他参数也统一设置,将最大生成令牌(max_tokens)参数设置为1024 ;将核采样阈值(top_p)参数设置为1.0;将流式输出(stream)参数设置为False;将频率惩罚(frequency penalty)参数设置为0;将存在惩罚(presence penalty)参数设置为0. ...
1
... 为了证明不同大语言模型在隐喻评估任务上的一致性,选取4个先进的大语言模型:GPT-4[16 ] 、ERNIE-4.0[32 ] 、Qwen2.5[33 ] 和 GLM-4-Plus[34 ] ,通过应用程序编程接口(application programming interface, API)使用. 这些模型各自具备独特的架构设计和技术特点. 1)GPT-4: 作为OpenAI推出的第4代生成式大语言模型,拥有庞大的参数量,通过多模态学习增强对文本的理解能力. 2)ERNIE-4.0: 百度研发的大语言模型,长文本处理能力得到优化,在中文语境下的理解和生成能力突出. 3)Qwen2.5: 由阿里云开发的大模型,它融合了包括图像、文本在内的多种信息源,强调交互式对话能力的提升,使其在模拟人类思维链路处理问题时展现出独特的优势. 4)GLM-4-Plus: 基于大语言模型架构,继承并发展了前几代模型的优点,利用近端策略优化(proximal policy optimization, PPO)算法提升推理能力,能够处理复杂的逻辑问题. GLM-4-Plus在大规模预训练基础上对推理路径生成、多步逻辑推演和指令遵循能力等进行针对性优化,极大增强了模型在中文语料上的适应性. 为了确保实验的可复现性以及实验中评分的稳定性,将所有参与实验模型的温度(temperature)参数设置为0. 温度参数在大语言模型中用于控制生成文本的随机性,Hada等[35 ] 的研究表明,基于大语言模型评估器的评估性能往往会随着温度的升高下降. 此外,将模型的其他参数也统一设置,将最大生成令牌(max_tokens)参数设置为1024 ;将核采样阈值(top_p)参数设置为1.0;将流式输出(stream)参数设置为False;将频率惩罚(frequency penalty)参数设置为0;将存在惩罚(presence penalty)参数设置为0. ...
1
... Song等[36 ] 的研究表明,大语言模型在温度为0的情况下也能生成随机文本,这种随机性增加了对隐喻评估结果稳定性的担忧. 为了验证大语言模型在中文隐喻评估时评分的稳定性和生成理由的一致性,让模型在温度为0的情况下接受5次相同输入的重复采样. 结果表明,重复5次的评估结果相同,给出的理由经人工审查基本一致,这也验证了模型在评估任务上的稳定性. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}