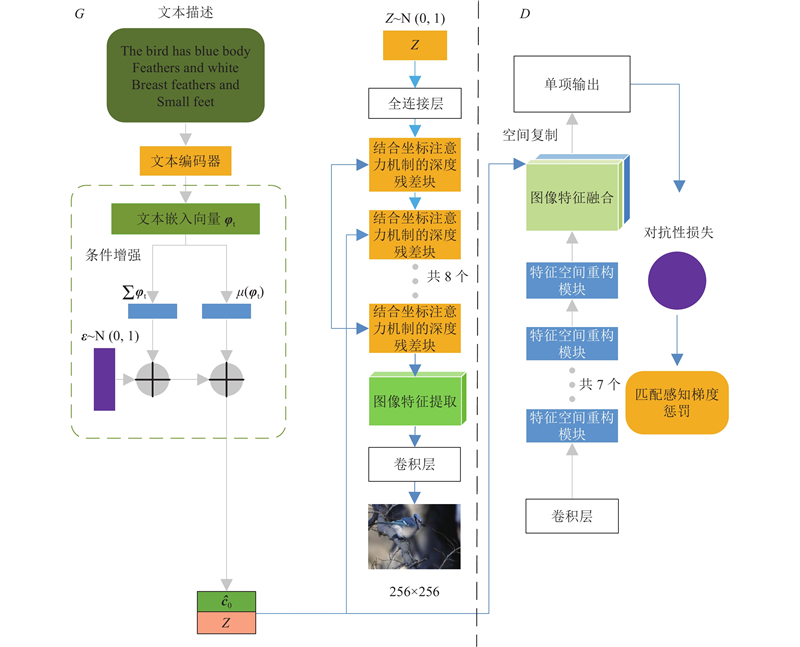
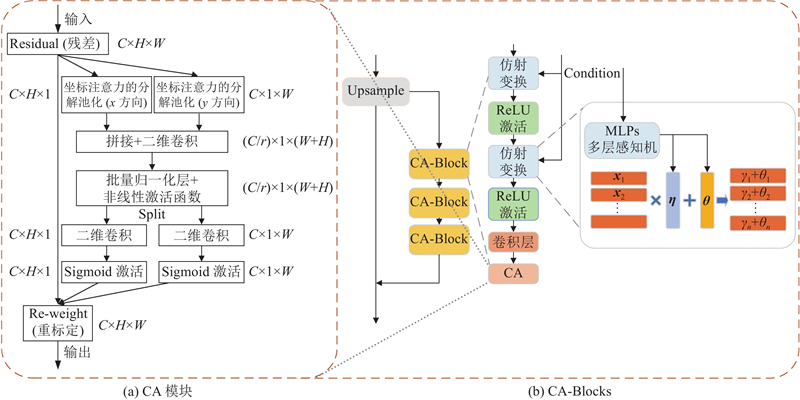
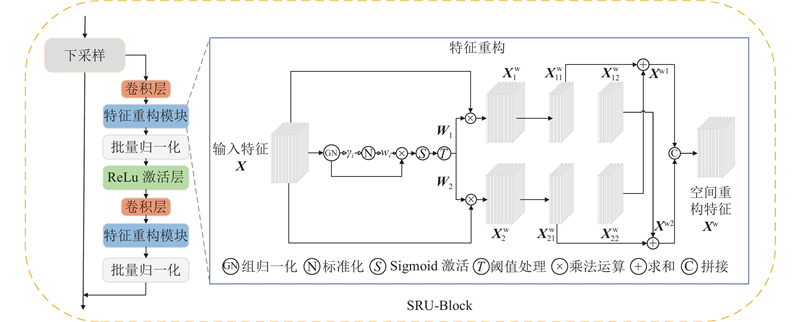
| 计算机技术 |
|

|
|
|
| 基于生成对抗网络和坐标注意力机制的文本生成图像算法 |
李云红( ),张琪琪,陈锦妮,陈伟重,苏雪平,梁成名 ),张琪琪,陈锦妮,陈伟重,苏雪平,梁成名 |
| 西安工程大学 电子信息学院,陕西 西安 710048 |
|
| Text-to-image generation algorithm based on generative adversarial network and coordinate attention mechanism |
| Yunhong LI(),Qiqi ZHANG,Jinni CHEN,Weichong CHEN,Xueping SU,Chengming LIANG |
| School of Electronics and Information, Xi’an Polytechnic University, Xi’an 710048, China |
引用本文:
李云红,张琪琪,陈锦妮,陈伟重,苏雪平,梁成名. 基于生成对抗网络和坐标注意力机制的文本生成图像算法[J]. 浙江大学学报(工学版), 2026, 60(6): 1213-1220.
Yunhong LI,Qiqi ZHANG,Jinni CHEN,Weichong CHEN,Xueping SU,Chengming LIANG. Text-to-image generation algorithm based on generative adversarial network and coordinate attention mechanism. Journal of ZheJiang University (Engineering Science), 2026, 60(6): 1213-1220.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2026.06.008
或
https://www.zjujournals.com/eng/CN/Y2026/V60/I6/1213
|
| 1 |
曹寅, 秦俊平, 马千里, 等 文本生成图像研究综述[J]. 浙江大学学报: 工学版, 2024, 58 (2): 219- 238
CAO Yin, QIN Junping, MA Qianli, et al Survey of text-to-image synthesis[J]. Journal of Zhejiang University: Engineering Science, 2024, 58 (2): 219- 238
|
| 2 |
李云红, 朱绵云, 任劼, 等 改进深度卷积生成式对抗网络的文本生成图像[J]. 北京航空航天大学学报, 2023, 49 (8): 1875- 1883
LI Yunhong, ZHU Mianyun, REN Jie, et al Text-to-image synthesis based on modified deep convolutional generative adversarial network[J]. Journal of Beijing University of Aeronautics and Astronautics, 2023, 49 (8): 1875- 1883
doi: 10.13700/j.bh.1001-5965.2021.0588
|
| 3 |
梁成名, 李云红, 李丽敏, 等 结合语义分割图的注意力机制文本生成图像[J]. 空军工程大学学报, 2024, 25 (4): 118- 127
LIANG Chengming, LI Yunhong, LI Limin, et al A semantic segmentation graph in combination with attention mechanism text generation images[J]. Journal of Air Force Engineering University, 2024, 25 (4): 118- 127
doi: 10.3969/j.issn.2097-1915.2024.04.016
|
| 4 |
李丰, 文益民 融合多尺度视觉和文本语义特征的图像描述生成算法[J]. 山东大学学报: 工学版, 2025, 55 (3): 80- 87
LI Feng, WEN Yimin Multi-scale visual and textual semantic feature fusion for image captioning[J]. Journal of Shandong University: Engineering Science, 2025, 55 (3): 80- 87
doi: 10.6040/j.issn.1672-3961.0.2024.018
|
| 5 |
周刚, 李捍东, 陈烨烨 基于对比学习的文本生成图像[J]. 软件工程, 2025, 28 (2): 37- 41
ZHOU Gang, LI Handong, CHEN Yeye Text-to-image generation based on contrastive learning[J]. Software Engineering, 2025, 28 (2): 37- 41
|
| 6 |
ZHANG H, XU T, LI H, et al. StackGAN: text to photo-realistic image synthesis with stacked generative adversarial networks [C]//Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 5908–5916.
|
| 7 |
XU T, ZHANG P, HUANG Q, et al. AttnGAN: fine-grained text to image generation with attentional generative adversarial networks [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 1316–1324.
|
| 8 |
TAO M, TANG H, WU F, et al. DF-GAN: a simple and effective baseline for text-to-image synthesis [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 16494–16504.
|
| 9 |
YE S, WANG H, TAN M, et al Recurrent affine transformation for text-to-image synthesis[J]. IEEE Transactions on Multimedia, 2024, 26: 462- 473
doi: 10.1109/TMM.2023.3266607
|
| 10 |
HÖLLEIN L, BOŽIČ A, MÜLLER N, et al. ViewDiff: 3D-consistent image generation with text-to-image models [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 5043–5052.
|
| 11 |
SHIRAKAWA T, UCHIDA S. NoiseCollage: a layout-aware text-to-image diffusion model based on noise cropping and merging [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 8921-8930.
|
| 12 |
GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of Wasserstein GANs [C]//Advances in Neural Information Processing Systems. Long Beach: Curran Associates, Inc., 2017.
|
| 13 |
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]//Advances in Neural Information Processing Systems. Cambridge: MIT Press, 2014: 2672-2680.
|
| 14 |
WAH C, BRANSON S, WELINDER P, et al. The caltech-UCSD birds-200-2011 dataset [R]. Pasadena: California Institute of Technology, 2011.
|
| 15 |
NILSBACK M E, ZISSERMAN A. Automated flower classification over a large number of classes [C]//Proceedings of the 6th Indian Conference on Computer Vision, Graphics and Image Processing. Bhubaneswar: IEEE, 2009: 722–729.
|
| 16 |
SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs [C]// Proceedings of Advances in Neural Information Processing Systems. Barcelona: Curran Associates, Inc., 2016: 2234–2242.
|
| 17 |
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium [C]//Proceedings of the Neural Information Processing Systems. Long Beach: Curran Associates, Inc., 2017.
|
| 18 |
ZHU M, PAN P, CHEN W, et al. DM-GAN: dynamic memory generative adversarial networks for text-to-image synthesis [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2020: 5795–5803.
|
| 19 |
ZHANG H, XU T, LI H, et al StackGAN: realistic image synthesis with stacked generative adversarial networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41 (8): 1947- 1962
doi: 10.1109/TPAMI.2018.2856256
|
| 20 |
RUAN S, ZHANG Y, ZHANG K, et al. DAE-GAN: dynamic aspect-aware GAN for text-to-image synthesis [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2022: 13940–13949.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|