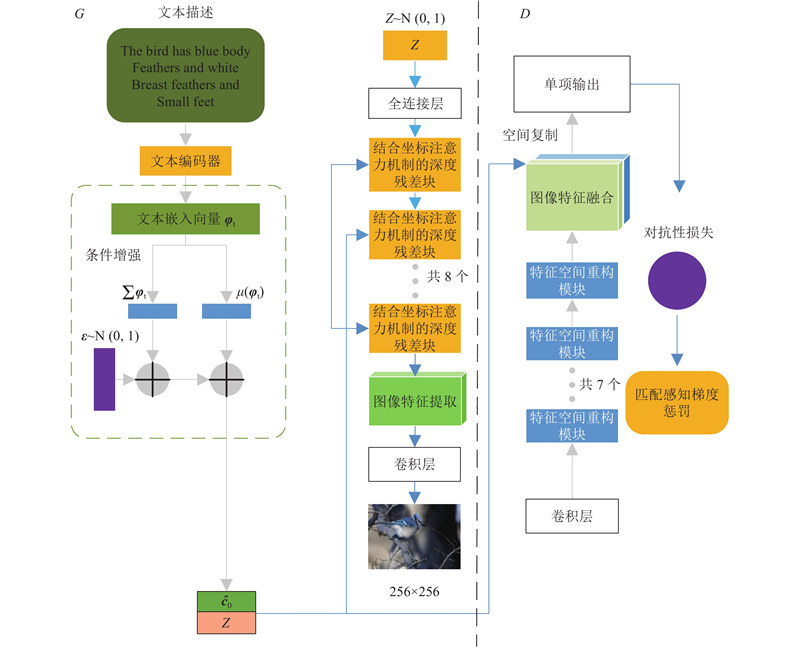
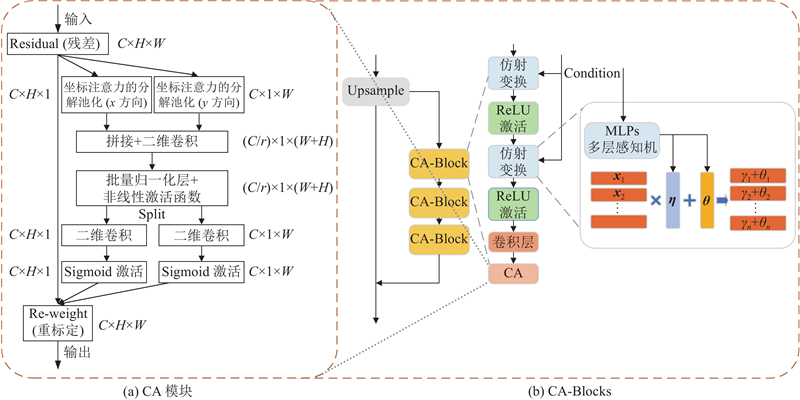
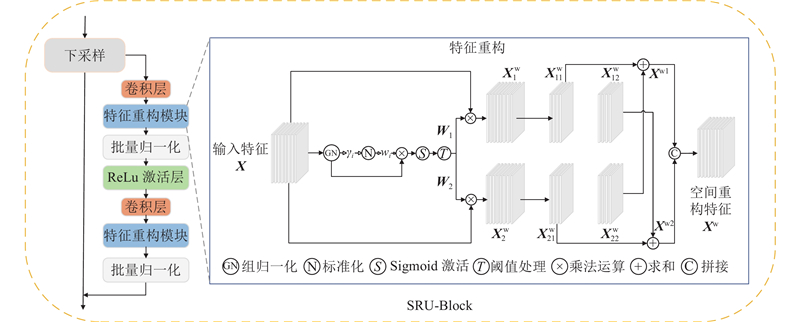
A text-to-image generation algorithm based on coordinate attention mechanism and generative adversarial network (CAT-GAN) was proposed in order to address the issue of poor diversity and low overall quality in the image generated by adversarial network. The conditional enhancement was used to calculate the mean and covariance matrix of the text feature vector, generating conditional variable to replace the original high-dimensional text feature and solve the sparsity problem. The coordinate attention mechanism was introduced into the residual block of the generator network to form a deep fusion module combined with the coordinate attention mechanism (CA-Block). The long-term dependency relationship of feature between channels can be captured while retaining the precise position of feature and enhancing the representation of the target object. The spatial reconstruction unit was introduced into the discriminator network to form a feature space reconstruction module (SRU-Block). Redundant feature was separated via weight assignment and reconstruction, enhancing the discriminator’s ability to represent feature. The model was tested and verified using the CUB-200, Oxford-102 Flowers and COCO dataset. The experimental results showed that the IS and FID index value of the proposed model (CAT-GAN) were the best compared with models such as StackGAN++, AttnGAN, DAE-GAN, DM-GAN, DT-GAN and DF-GAN. The IS index value reached 5.13, 4.10 and 31.81, and the FID index value reached 14.34, 16.76 and 26.36. The proposed model has better visualization effect, proving the effectiveness of the proposed method.
ZHANG H, XU T, LI H, et al. StackGAN: text to photo-realistic image synthesis with stacked generative adversarial networks [C]//Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 5908–5916.
XU T, ZHANG P, HUANG Q, et al. AttnGAN: fine-grained text to image generation with attentional generative adversarial networks [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 1316–1324.
TAO M, TANG H, WU F, et al. DF-GAN: a simple and effective baseline for text-to-image synthesis [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 16494–16504.
HÖLLEIN L, BOŽIČ A, MÜLLER N, et al. ViewDiff: 3D-consistent image generation with text-to-image models [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 5043–5052.
SHIRAKAWA T, UCHIDA S. NoiseCollage: a layout-aware text-to-image diffusion model based on noise cropping and merging [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 8921-8930.
GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of Wasserstein GANs [C]//Advances in Neural Information Processing Systems. Long Beach: Curran Associates, Inc., 2017.
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]//Advances in Neural Information Processing Systems. Cambridge: MIT Press, 2014: 2672-2680.
NILSBACK M E, ZISSERMAN A. Automated flower classification over a large number of classes [C]//Proceedings of the 6th Indian Conference on Computer Vision, Graphics and Image Processing. Bhubaneswar: IEEE, 2009: 722–729.
SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs [C]// Proceedings of Advances in Neural Information ProcessingSystems. Barcelona: Curran Associates, Inc., 2016: 2234–2242.
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium [C]//Proceedings of the Neural Information Processing Systems. Long Beach: Curran Associates, Inc., 2017.
ZHU M, PAN P, CHEN W, et al. DM-GAN: dynamic memory generative adversarial networks for text-to-image synthesis [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2020: 5795–5803.
RUAN S, ZHANG Y, ZHANG K, et al. DAE-GAN: dynamic aspect-aware GAN for text-to-image synthesis [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2022: 13940–13949.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}