[1]
袁公萍, 汤一平, 韩旺明, 等 基于深度卷积神经网络的车型识别方法
[J]. 浙江大学学报: 工学版 , 2018 , 52 (4 ): 694 - 702
[本文引用: 1]
YUAN Gong-ping, TANG Yi-ping, HAN Wang-ming, et al Vehicle recognition method based on deep convolution neural network
[J]. Journal of Zhejiang University: Engineering Science , 2018 , 52 (4 ): 694 - 702
[本文引用: 1]
[2]
CAI H P. Fast detection of multiple textureless 3D objects [C] // International Conference on Computer Vision Systems . Petersburg: ICCVS, 2013: 103-112.
[本文引用: 1]
[3]
养明起. 基于深度神经网络的视觉位姿估计[M]. 安徽: 中国科学技术大学, 2018.
[本文引用: 1]
[4]
HODAN T, HALUZAS P. T-LESS: an RGB-D dataset for 6D pose estimation of texture-less objects [C] // IEEE Winter Conference on Applications of Computer Vision . Santa Rosa: IEEE WCACS, 2017: 880-888.
[本文引用: 1]
[5]
OHNO K, TSUBOUCHI T, SHIGEMATSU B, et al Differential GPS and odometry-based outdoor navigation of a mobile robot
[J]. Advanced Robotics , 2004 , 18 (6 ): 611 - 635
DOI:10.1163/1568553041257431
[本文引用: 1]
[6]
FUENTES P J, RUIZE A J, RENDON J M Visual simultaneous localization and mapping: a survey
[J]. Artificial Intelligence Review , 2012 , 43 (1 ): 55 - 81
[7]
ENDRES F, HESS J, STURM J, et al 3D mapping with an RGB-D camera
[J]. IEEE Transactions on Robotics , 2014 , 30 (1 ): 177 - 187
DOI:10.1109/TRO.2013.2279412
[本文引用: 1]
[8]
HODAN T, ZABULIS X. Detection and fine 3D pose estimation of texture-less objects in RGB-D images [C] // IEEE International Conference on Computer Vision . Sydney: IEEE CVPR, 2014: 4421-4428.
[本文引用: 1]
[10]
柳培忠, 阮晓虎, 田震, 等 一种基于多特征融合的视频目标跟踪方法
[J]. 智能系统学报 , 2015 , (57 ): 319 - 324
[本文引用: 1]
LIU Pei-zhong, RUAN Xiao-hu, TIAN Zhen, et al A video target tracking method based on multi-feature fusion
[J]. Journal of Intelligent Systems , 2015 , (57 ): 319 - 324
[本文引用: 1]
[11]
贾祝广, 孙效玉, 王斌, 等 无人驾驶技术研究及展望
[J]. 矿业装备 , 2014 , (5 ): 44 - 47
[本文引用: 1]
JIA Zhu-guang, SUN Xiao-yu, WANG Bin, et al Research and prospect of unmanned driving technology
[J]. Mining Equipment , 2014 , (5 ): 44 - 47
[本文引用: 1]
[12]
RUSU R B, BRADSKI G, THIBAUX R. Fast 3D recognition and pose using the viewpoint feature histogram [C] // IEEE/RSJ International Conference on Intelligent Robots and Systems . Taiwan: IEEE ICIRS, 2010: 148-154.
[本文引用: 1]
[13]
YU X, TANNER S. Pose-CNN: a convolutional neural network for 6D object pose estimation in cluttered scenes [C] // IEEE Conference on Computer Vision and Pattern Recognition . Saltlake: IEEE CVPR, 2018.
[本文引用: 2]
[14]
RAD M, LEPETIT V. BB8: a scalable, accurate, robust to partial occlusion method for predicting the 3D poses of challenging objects without using depth [C] // IEEE International Conference on Computer Vision . Venice: IEEE ICCV, 2017: 3848-3856.
[本文引用: 1]
[15]
KEHL W, MANHARDT F, TOMBARI F, et al. Ssd-6D: making RGB-based 3D detection and 6D pose estimation great again [C] // IEEE International Conference on Computer Vision . Venice: IEEE ICCV, 2017: 1530-1538.
[本文引用: 1]
[16]
REDMON J, FARHADI A. YOLO9000: Better, faster, stronger [C] // IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE CVPR, 2017: 6517-6525.
[本文引用: 1]
[17]
BANSAL A, RUSSELL B, GUPTA A. Marr revisited: 2D-3D alignment via surface normal prediction [C] // IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE CVPR, 2016: 5965-5974.
[本文引用: 1]
[18]
CHABOT F, CHAOUCH M, RABARISOA J, et al. Deep manta: a coarsetone many-task network for joint 2D and 3D vehicle analysis from monocular image [C] // IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE CVPR, 2017: 1827-1836.
[本文引用: 2]
[19]
谢雨宁. 融合形态学与特征点检测的建筑物自动三维重建关键技术研究[D]. 南京: 东南大学, 2016.
[本文引用: 3]
XIE Yu-ning. Research on key technologies of automatic 3D reconstruction of buildings fused with morphology and feature detection [D]. Nanjing: Southeast University, 2016.
[本文引用: 3]
[20]
HEDAU V, HOIEM D, FORSYTH D. Thinking inside the box: using appearance models and context based on room geometry [C] // European Conference on Computer Vision . Heraklion: ECCV, 2010: 224-237.
[本文引用: 4]
[21]
CHEN X, KUNDU K, ZHANG Z, MA et al. Monocular 3D object detection for autonomous driving [C] // IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE CVPR, 2016: 2147-2156.
[本文引用: 3]
[22]
YANG S, SCHERER S. CubeSLAM: monocular 3D object detection and SLAM without prior models [C] // IEEE Conference on Computer Vision and Pattern Recognition . Saltlake: IEEE CVPR, 2018: 1-16.
[本文引用: 17]
[23]
宋欣, 王正玑, 程章林, 等 多分辨率线段提取方法及线段语义分析
[J]. 集成技术 , 2018 , 7 (9 ): 67 - 78
[本文引用: 1]
SONG Xin, WANG Zheng-ju, CHENG Zhang-lin, et al Multiresolution line segment extraction method and semantics analysis
[J]. Integrated Technology , 2018 , 7 (9 ): 67 - 78
[本文引用: 1]
[24]
SONG S, LICHTENBERG S P, XIAO J. Sun RGB-D: a RGB-D scene understanding benchmark suite [C] // IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE CVPR, 2015: 567-576.
[本文引用: 1]
[25]
GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite [C] // IEEE Conference on Computer Vision and Pattern Recognition . Rhode: IEEE CVPR, 2012: 3354–3361.
[本文引用: 1]
[26]
XIAO J, RUSSELL B, TORRALBA A. Localizing 3D cuboids in single-view images [C] // 25th International Conference on Neural Information Processing Systems . Cambodia: NIPSF 2012: 746-754.
[本文引用: 3]
[27]
CHOI W, CHAO Y W, PANTOFARU C, et al. Understanding indoor scenes using 3D geometric phrases [C] // IEEE Conference on Computer Vision and Pattern Recognition . Oregon: IEEE CVPR, 2013 : 33-40.
[本文引用: 3]
[28]
MOUSAVIAN A, ANGUEALOV D, FLYNN J, et al. 3D bounding box estimation using deep learning and geometry [C] // IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE CVPR, 2017: 5632-5640.
[本文引用: 2]
[29]
XIANG Y, CHOI W, LIN Y, et al. Subcategory-aware convolutional neural networks for object proposals and detection [C] // Applications of Computer Vision . Santa Rosa: IEEE ACV, 2017: 924-933.
[本文引用: 3]
[30]
梁苍, 曹宁, 冯晔 改进的基于gLoG滤波实时消失点检测算法
[J]. 国外电子测量技术 , 2018 , 37 (12 ): 36 - 40
[本文引用: 1]
LIANG Cang, CAO Ning, FENG Ye Improved real-time vanishing point detection algorithm based on gLoG filter
[J]. Foreign Electronic Measurement Technology , 2018 , 37 (12 ): 36 - 40
[本文引用: 1]
基于深度卷积神经网络的车型识别方法
1
2018
... 基于图像的目标物体检测技术在目标跟踪[1 -2 ] 、增强现实[3 -4 ] 、无人驾驶[5 -7 ] 等领域应用广泛. 目前,基于单目相机的目标物体检测技术凭借较低的成本在工业领域逐渐流行,但是大部分方法都需要额外的先验信息. 根据先验信息的种类可以将目标物体检测方法分为以下2种: ...
基于深度卷积神经网络的车型识别方法
1
2018
... 基于图像的目标物体检测技术在目标跟踪[1 -2 ] 、增强现实[3 -4 ] 、无人驾驶[5 -7 ] 等领域应用广泛. 目前,基于单目相机的目标物体检测技术凭借较低的成本在工业领域逐渐流行,但是大部分方法都需要额外的先验信息. 根据先验信息的种类可以将目标物体检测方法分为以下2种: ...
1
... 基于图像的目标物体检测技术在目标跟踪[1 -2 ] 、增强现实[3 -4 ] 、无人驾驶[5 -7 ] 等领域应用广泛. 目前,基于单目相机的目标物体检测技术凭借较低的成本在工业领域逐渐流行,但是大部分方法都需要额外的先验信息. 根据先验信息的种类可以将目标物体检测方法分为以下2种: ...
1
... 基于图像的目标物体检测技术在目标跟踪[1 -2 ] 、增强现实[3 -4 ] 、无人驾驶[5 -7 ] 等领域应用广泛. 目前,基于单目相机的目标物体检测技术凭借较低的成本在工业领域逐渐流行,但是大部分方法都需要额外的先验信息. 根据先验信息的种类可以将目标物体检测方法分为以下2种: ...
1
... 基于图像的目标物体检测技术在目标跟踪[1 -2 ] 、增强现实[3 -4 ] 、无人驾驶[5 -7 ] 等领域应用广泛. 目前,基于单目相机的目标物体检测技术凭借较低的成本在工业领域逐渐流行,但是大部分方法都需要额外的先验信息. 根据先验信息的种类可以将目标物体检测方法分为以下2种: ...
Differential GPS and odometry-based outdoor navigation of a mobile robot
1
2004
... 基于图像的目标物体检测技术在目标跟踪[1 -2 ] 、增强现实[3 -4 ] 、无人驾驶[5 -7 ] 等领域应用广泛. 目前,基于单目相机的目标物体检测技术凭借较低的成本在工业领域逐渐流行,但是大部分方法都需要额外的先验信息. 根据先验信息的种类可以将目标物体检测方法分为以下2种: ...
Visual simultaneous localization and mapping: a survey
0
2012
3D mapping with an RGB-D camera
1
2014
... 基于图像的目标物体检测技术在目标跟踪[1 -2 ] 、增强现实[3 -4 ] 、无人驾驶[5 -7 ] 等领域应用广泛. 目前,基于单目相机的目标物体检测技术凭借较低的成本在工业领域逐渐流行,但是大部分方法都需要额外的先验信息. 根据先验信息的种类可以将目标物体检测方法分为以下2种: ...
1
... 1)基于手工标记或已知特征点、线匹配的目标检测. 例如,Hodan等[8 -9 ] 利用已知特征点(线)的2D-3D对应关系,提出了基于二维局部特征描述子的目标检测算法,其在变化的光照条件下以及被用于检测复杂形状时比其他方法鲁棒性更强. ...
Distinctive image features from scale-invariant keypoints
1
2004
... 1)基于手工标记或已知特征点、线匹配的目标检测. 例如,Hodan等[8 -9 ] 利用已知特征点(线)的2D-3D对应关系,提出了基于二维局部特征描述子的目标检测算法,其在变化的光照条件下以及被用于检测复杂形状时比其他方法鲁棒性更强. ...
一种基于多特征融合的视频目标跟踪方法
1
2015
... 2)基于先验目标的2D-3D轮廓匹配检测. 柳培忠等[10 ] 利用已有的CAD模版信息,提出了一种不断聚类匹配的位姿检测方法,该方法具有估计精度高、匹配速度快的特点. ...
一种基于多特征融合的视频目标跟踪方法
1
2015
... 2)基于先验目标的2D-3D轮廓匹配检测. 柳培忠等[10 ] 利用已有的CAD模版信息,提出了一种不断聚类匹配的位姿检测方法,该方法具有估计精度高、匹配速度快的特点. ...
无人驾驶技术研究及展望
1
2014
... 上述方法都需要依赖先验信息,但该信息在实际环境中获取困难,这也是单目方法在增强现实、无人驾驶等领域发展受限制的原因[11 ] . ...
无人驾驶技术研究及展望
1
2014
... 上述方法都需要依赖先验信息,但该信息在实际环境中获取困难,这也是单目方法在增强现实、无人驾驶等领域发展受限制的原因[11 ] . ...
1
... 随着人工智能的发展,不少学者开始将深度学习网络(CNN)用于物体的位姿估计[12 ] ,例如PoseCNN[13 ] 、BB8[14 ] 、SSD-6D[15 ] 等,利用模版匹配训练估计单目图像中物体对应的最佳位姿. 虽然训练后的CNN模型能更准确地检测目标,但是这些CNN模型在训练中同样需要大量的先验目标数据集[16 -18 ] . 综上所述,无论是传统方法还是深度学习算法都是基于先验信息对目标物体进行检测. ...
2
... 随着人工智能的发展,不少学者开始将深度学习网络(CNN)用于物体的位姿估计[12 ] ,例如PoseCNN[13 ] 、BB8[14 ] 、SSD-6D[15 ] 等,利用模版匹配训练估计单目图像中物体对应的最佳位姿. 虽然训练后的CNN模型能更准确地检测目标,但是这些CNN模型在训练中同样需要大量的先验目标数据集[16 -18 ] . 综上所述,无论是传统方法还是深度学习算法都是基于先验信息对目标物体进行检测. ...
... 对于室外场景,本文将深度学习网络SubCNN模型[13 ] 作为分割目标物、2D边界框提取的模型,并利用所提算法进行3D目标检测. 为了弱化2D检测的影响,只是选择IoU>0.7的提案,同时与3D-Cube[22 ] 一样,对全部目标提案以及前10个提案进行结果分析. 表4 给出了不同算法的目标3D框检测精度, 可视化结果如图6 所示. ...
1
... 随着人工智能的发展,不少学者开始将深度学习网络(CNN)用于物体的位姿估计[12 ] ,例如PoseCNN[13 ] 、BB8[14 ] 、SSD-6D[15 ] 等,利用模版匹配训练估计单目图像中物体对应的最佳位姿. 虽然训练后的CNN模型能更准确地检测目标,但是这些CNN模型在训练中同样需要大量的先验目标数据集[16 -18 ] . 综上所述,无论是传统方法还是深度学习算法都是基于先验信息对目标物体进行检测. ...
1
... 随着人工智能的发展,不少学者开始将深度学习网络(CNN)用于物体的位姿估计[12 ] ,例如PoseCNN[13 ] 、BB8[14 ] 、SSD-6D[15 ] 等,利用模版匹配训练估计单目图像中物体对应的最佳位姿. 虽然训练后的CNN模型能更准确地检测目标,但是这些CNN模型在训练中同样需要大量的先验目标数据集[16 -18 ] . 综上所述,无论是传统方法还是深度学习算法都是基于先验信息对目标物体进行检测. ...
1
... 随着人工智能的发展,不少学者开始将深度学习网络(CNN)用于物体的位姿估计[12 ] ,例如PoseCNN[13 ] 、BB8[14 ] 、SSD-6D[15 ] 等,利用模版匹配训练估计单目图像中物体对应的最佳位姿. 虽然训练后的CNN模型能更准确地检测目标,但是这些CNN模型在训练中同样需要大量的先验目标数据集[16 -18 ] . 综上所述,无论是传统方法还是深度学习算法都是基于先验信息对目标物体进行检测. ...
1
... 针对此问题,Bansal等[17 ] 提出了一种不需要先验信息的3D立方体检测方法,该方法的原理是基于消失点(vanishing point,VP)的投影光线生成3D立方体. Chabot等[18 ] 构建了一个具有类别属性的辨别检测器,扩大了对不同对象类别的长方体检测. 谢雨宁[19 ] 结合M估计子抽样一致性(M-estimator sample and consensus,MSAC)算法,提出了一种适用于目标建筑物的检测方法. Hedau等[20 ] 针对地面上的目标,通过对在地面上的目标进行3D边界框采样,基于上下文特征优化3D边界框. 与文献[20 ]的研究相似,Chen等[21 ] 假设3D物体投影后紧贴于2D边界框,对满足VP光线投射的3D边界进行组合,生成多个3D物体的包围盒,并基于上下文特征选择最合适的3D边界框. 在此基础上,Yang等[22 ] 将上述研究应用于道路场景,提出了一种单目的3D目标检测算法(简称3D-Cube),该方法可以在没有目标大小、方向等信息的情况下,仅利用相机的高度信息实现3D目标检测,极大地提高了基于单目的3D目标检测能力. 然而,在文献[20 ]的研究中,假定目标物体的位姿位于相机位姿的[−45°,45°]范围,需要采样每一个角度,并根据采样的角度确定目标空间投影关系,因而计算复杂,且目标位姿精度与角度采样频率十分相关. ...
2
... 随着人工智能的发展,不少学者开始将深度学习网络(CNN)用于物体的位姿估计[12 ] ,例如PoseCNN[13 ] 、BB8[14 ] 、SSD-6D[15 ] 等,利用模版匹配训练估计单目图像中物体对应的最佳位姿. 虽然训练后的CNN模型能更准确地检测目标,但是这些CNN模型在训练中同样需要大量的先验目标数据集[16 -18 ] . 综上所述,无论是传统方法还是深度学习算法都是基于先验信息对目标物体进行检测. ...
... 针对此问题,Bansal等[17 ] 提出了一种不需要先验信息的3D立方体检测方法,该方法的原理是基于消失点(vanishing point,VP)的投影光线生成3D立方体. Chabot等[18 ] 构建了一个具有类别属性的辨别检测器,扩大了对不同对象类别的长方体检测. 谢雨宁[19 ] 结合M估计子抽样一致性(M-estimator sample and consensus,MSAC)算法,提出了一种适用于目标建筑物的检测方法. Hedau等[20 ] 针对地面上的目标,通过对在地面上的目标进行3D边界框采样,基于上下文特征优化3D边界框. 与文献[20 ]的研究相似,Chen等[21 ] 假设3D物体投影后紧贴于2D边界框,对满足VP光线投射的3D边界进行组合,生成多个3D物体的包围盒,并基于上下文特征选择最合适的3D边界框. 在此基础上,Yang等[22 ] 将上述研究应用于道路场景,提出了一种单目的3D目标检测算法(简称3D-Cube),该方法可以在没有目标大小、方向等信息的情况下,仅利用相机的高度信息实现3D目标检测,极大地提高了基于单目的3D目标检测能力. 然而,在文献[20 ]的研究中,假定目标物体的位姿位于相机位姿的[−45°,45°]范围,需要采样每一个角度,并根据采样的角度确定目标空间投影关系,因而计算复杂,且目标位姿精度与角度采样频率十分相关. ...
3
... 针对此问题,Bansal等[17 ] 提出了一种不需要先验信息的3D立方体检测方法,该方法的原理是基于消失点(vanishing point,VP)的投影光线生成3D立方体. Chabot等[18 ] 构建了一个具有类别属性的辨别检测器,扩大了对不同对象类别的长方体检测. 谢雨宁[19 ] 结合M估计子抽样一致性(M-estimator sample and consensus,MSAC)算法,提出了一种适用于目标建筑物的检测方法. Hedau等[20 ] 针对地面上的目标,通过对在地面上的目标进行3D边界框采样,基于上下文特征优化3D边界框. 与文献[20 ]的研究相似,Chen等[21 ] 假设3D物体投影后紧贴于2D边界框,对满足VP光线投射的3D边界进行组合,生成多个3D物体的包围盒,并基于上下文特征选择最合适的3D边界框. 在此基础上,Yang等[22 ] 将上述研究应用于道路场景,提出了一种单目的3D目标检测算法(简称3D-Cube),该方法可以在没有目标大小、方向等信息的情况下,仅利用相机的高度信息实现3D目标检测,极大地提高了基于单目的3D目标检测能力. 然而,在文献[20 ]的研究中,假定目标物体的位姿位于相机位姿的[−45°,45°]范围,需要采样每一个角度,并根据采样的角度确定目标空间投影关系,因而计算复杂,且目标位姿精度与角度采样频率十分相关. ...
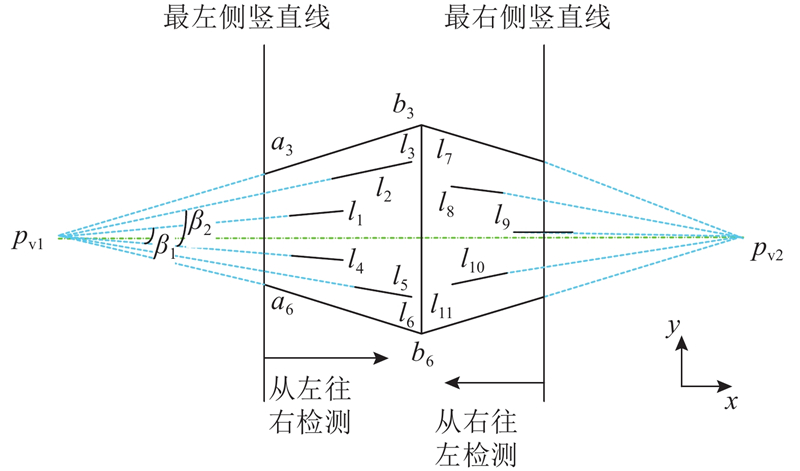
... 每次迭代估计VP之后,将小于距离阈值的直线从选择集中剔除,然后进行下一个VP的迭代估计. 根据谢雨宁[19 ] 的研究,越长的直线段越可能是物体轮廓的特点,为了缩短计算时间,随机从较长的直线段中挑选最小样本集. 依据经验,一般从全部剩余检测线段中挑选前30%的长直线段作为最小样本集,然后根据合适的距离函数对直线进行分类,常用的是VP到直线的距离函数,但是该距离函数不适用于远距离的直线. 本文将VP与特征点形成的直线与直线段组成的夹角的正弦绝对值作为衡量VP到直线的距离函数,具体为 ...
... 分析大量的地面场景发现,物体的轮廓直线往往是图中VP方向上开合度最大的直线[19 ] . 这里开合度定义为水平方向的直线与水平线的夹角,或者竖直方向的直线与垂线的夹角. 为此,本文根据此规律确定物体3D框的第一个角点和轮廓线,然后结合3个消失点分析剩余的角点. ...
3
... 针对此问题,Bansal等[17 ] 提出了一种不需要先验信息的3D立方体检测方法,该方法的原理是基于消失点(vanishing point,VP)的投影光线生成3D立方体. Chabot等[18 ] 构建了一个具有类别属性的辨别检测器,扩大了对不同对象类别的长方体检测. 谢雨宁[19 ] 结合M估计子抽样一致性(M-estimator sample and consensus,MSAC)算法,提出了一种适用于目标建筑物的检测方法. Hedau等[20 ] 针对地面上的目标,通过对在地面上的目标进行3D边界框采样,基于上下文特征优化3D边界框. 与文献[20 ]的研究相似,Chen等[21 ] 假设3D物体投影后紧贴于2D边界框,对满足VP光线投射的3D边界进行组合,生成多个3D物体的包围盒,并基于上下文特征选择最合适的3D边界框. 在此基础上,Yang等[22 ] 将上述研究应用于道路场景,提出了一种单目的3D目标检测算法(简称3D-Cube),该方法可以在没有目标大小、方向等信息的情况下,仅利用相机的高度信息实现3D目标检测,极大地提高了基于单目的3D目标检测能力. 然而,在文献[20 ]的研究中,假定目标物体的位姿位于相机位姿的[−45°,45°]范围,需要采样每一个角度,并根据采样的角度确定目标空间投影关系,因而计算复杂,且目标位姿精度与角度采样频率十分相关. ...
... 每次迭代估计VP之后,将小于距离阈值的直线从选择集中剔除,然后进行下一个VP的迭代估计. 根据谢雨宁[19 ] 的研究,越长的直线段越可能是物体轮廓的特点,为了缩短计算时间,随机从较长的直线段中挑选最小样本集. 依据经验,一般从全部剩余检测线段中挑选前30%的长直线段作为最小样本集,然后根据合适的距离函数对直线进行分类,常用的是VP到直线的距离函数,但是该距离函数不适用于远距离的直线. 本文将VP与特征点形成的直线与直线段组成的夹角的正弦绝对值作为衡量VP到直线的距离函数,具体为 ...
... 分析大量的地面场景发现,物体的轮廓直线往往是图中VP方向上开合度最大的直线[19 ] . 这里开合度定义为水平方向的直线与水平线的夹角,或者竖直方向的直线与垂线的夹角. 为此,本文根据此规律确定物体3D框的第一个角点和轮廓线,然后结合3个消失点分析剩余的角点. ...
4
... 针对此问题,Bansal等[17 ] 提出了一种不需要先验信息的3D立方体检测方法,该方法的原理是基于消失点(vanishing point,VP)的投影光线生成3D立方体. Chabot等[18 ] 构建了一个具有类别属性的辨别检测器,扩大了对不同对象类别的长方体检测. 谢雨宁[19 ] 结合M估计子抽样一致性(M-estimator sample and consensus,MSAC)算法,提出了一种适用于目标建筑物的检测方法. Hedau等[20 ] 针对地面上的目标,通过对在地面上的目标进行3D边界框采样,基于上下文特征优化3D边界框. 与文献[20 ]的研究相似,Chen等[21 ] 假设3D物体投影后紧贴于2D边界框,对满足VP光线投射的3D边界进行组合,生成多个3D物体的包围盒,并基于上下文特征选择最合适的3D边界框. 在此基础上,Yang等[22 ] 将上述研究应用于道路场景,提出了一种单目的3D目标检测算法(简称3D-Cube),该方法可以在没有目标大小、方向等信息的情况下,仅利用相机的高度信息实现3D目标检测,极大地提高了基于单目的3D目标检测能力. 然而,在文献[20 ]的研究中,假定目标物体的位姿位于相机位姿的[−45°,45°]范围,需要采样每一个角度,并根据采样的角度确定目标空间投影关系,因而计算复杂,且目标位姿精度与角度采样频率十分相关. ...
... 针对地面上的目标,通过对在地面上的目标进行3D边界框采样,基于上下文特征优化3D边界框. 与文献[20 ]的研究相似,Chen等[21 ] 假设3D物体投影后紧贴于2D边界框,对满足VP光线投射的3D边界进行组合,生成多个3D物体的包围盒,并基于上下文特征选择最合适的3D边界框. 在此基础上,Yang等[22 ] 将上述研究应用于道路场景,提出了一种单目的3D目标检测算法(简称3D-Cube),该方法可以在没有目标大小、方向等信息的情况下,仅利用相机的高度信息实现3D目标检测,极大地提高了基于单目的3D目标检测能力. 然而,在文献[20 ]的研究中,假定目标物体的位姿位于相机位姿的[−45°,45°]范围,需要采样每一个角度,并根据采样的角度确定目标空间投影关系,因而计算复杂,且目标位姿精度与角度采样频率十分相关. ...
... 将上述研究应用于道路场景,提出了一种单目的3D目标检测算法(简称3D-Cube),该方法可以在没有目标大小、方向等信息的情况下,仅利用相机的高度信息实现3D目标检测,极大地提高了基于单目的3D目标检测能力. 然而,在文献[20 ]的研究中,假定目标物体的位姿位于相机位姿的[−45°,45°]范围,需要采样每一个角度,并根据采样的角度确定目标空间投影关系,因而计算复杂,且目标位姿精度与角度采样频率十分相关. ...
... 根据VP透视原理,在立方体边框采样一个角,然后结合3个消失点就可以估计目标物体的3D边界框. Hedau等[20 -22 ] 通过对2D边框顶部直线进行详尽的顶角采样,并依据该角预测3D边界框,再通过评价指标评选出其中最优的3D边界框. 虽然采用该方法能获得较好的估计结果,但是计算过程复杂. 为了减小计算量并提高3D边界框的估计精度,本文结合消失点、轮廓、顶点之间的几何信息,提出一种基于物体轮廓直线的目标3D框检测算法. ...
3
... 针对此问题,Bansal等[17 ] 提出了一种不需要先验信息的3D立方体检测方法,该方法的原理是基于消失点(vanishing point,VP)的投影光线生成3D立方体. Chabot等[18 ] 构建了一个具有类别属性的辨别检测器,扩大了对不同对象类别的长方体检测. 谢雨宁[19 ] 结合M估计子抽样一致性(M-estimator sample and consensus,MSAC)算法,提出了一种适用于目标建筑物的检测方法. Hedau等[20 ] 针对地面上的目标,通过对在地面上的目标进行3D边界框采样,基于上下文特征优化3D边界框. 与文献[20 ]的研究相似,Chen等[21 ] 假设3D物体投影后紧贴于2D边界框,对满足VP光线投射的3D边界进行组合,生成多个3D物体的包围盒,并基于上下文特征选择最合适的3D边界框. 在此基础上,Yang等[22 ] 将上述研究应用于道路场景,提出了一种单目的3D目标检测算法(简称3D-Cube),该方法可以在没有目标大小、方向等信息的情况下,仅利用相机的高度信息实现3D目标检测,极大地提高了基于单目的3D目标检测能力. 然而,在文献[20 ]的研究中,假定目标物体的位姿位于相机位姿的[−45°,45°]范围,需要采样每一个角度,并根据采样的角度确定目标空间投影关系,因而计算复杂,且目标位姿精度与角度采样频率十分相关. ...
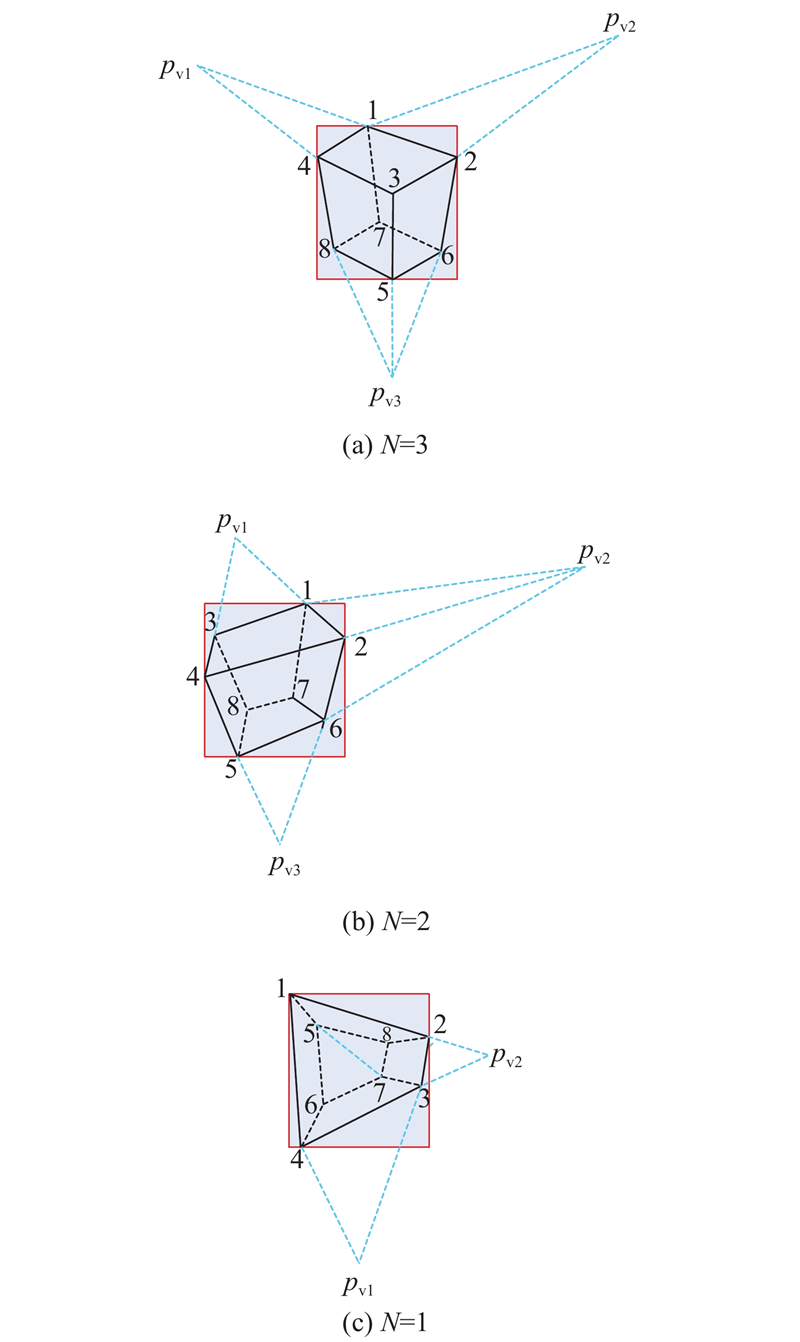
... 根据目标3D框是紧贴于2D边界框的假设[22 ] ,连接轮廓W 和对应的VP,可认为其与2D边界框产生的交点是3D边界框的角点. 需要注意的是,该连线一般会与2D边界框产生2个交点,按照就近原则,确定离边界更近的交点为3D边界框的角点,再结合3个消失点就可以估计出目标物体的3D框,不同情形下的VP与立方体角点关系如图3 所示[21 ] . ...
... Error rate of VP calculated by different algorithms
Tab.1 % 算法 $600 \times 450$ $500 \times 375$ $400 \times 300$ $300 \times 224$ MSAC 0.074 0.085 0.091 0.098 3D-Cube[21 ] 0.053 0.062 0.070 0.074 本文算法 0.051 0.059 0.067 0.072
表2 给出了采用不同算法计算VP所需的运算时间T . 在实验中同样设置4种不同分辨率( $600 \times 450$ $500 \times 375$ $400 \times 300$ $300 \times 225$ [22 ] 算法,所提算法的运算时间更短,并且图片尺寸越大,运算速度越快. 虽然所提算法的运算时间不及原始算法MSAC,但是其检测精度更高. ...
17
... 针对此问题,Bansal等[17 ] 提出了一种不需要先验信息的3D立方体检测方法,该方法的原理是基于消失点(vanishing point,VP)的投影光线生成3D立方体. Chabot等[18 ] 构建了一个具有类别属性的辨别检测器,扩大了对不同对象类别的长方体检测. 谢雨宁[19 ] 结合M估计子抽样一致性(M-estimator sample and consensus,MSAC)算法,提出了一种适用于目标建筑物的检测方法. Hedau等[20 ] 针对地面上的目标,通过对在地面上的目标进行3D边界框采样,基于上下文特征优化3D边界框. 与文献[20 ]的研究相似,Chen等[21 ] 假设3D物体投影后紧贴于2D边界框,对满足VP光线投射的3D边界进行组合,生成多个3D物体的包围盒,并基于上下文特征选择最合适的3D边界框. 在此基础上,Yang等[22 ] 将上述研究应用于道路场景,提出了一种单目的3D目标检测算法(简称3D-Cube),该方法可以在没有目标大小、方向等信息的情况下,仅利用相机的高度信息实现3D目标检测,极大地提高了基于单目的3D目标检测能力. 然而,在文献[20 ]的研究中,假定目标物体的位姿位于相机位姿的[−45°,45°]范围,需要采样每一个角度,并根据采样的角度确定目标空间投影关系,因而计算复杂,且目标位姿精度与角度采样频率十分相关. ...
... 针对此问题,本文在文献[22 ]研究的基础上,进一步优化3D物体检测技术,提出一种基于空间约束的自适应单目3D物体检测算法. 首先引入MSAC算法估计VP,通过改进直线检测和结合地面物体的几何约束,提出一种改进的MSAC消失点估计算法; 其次,针对单目视图中物体3D框角点估计困难的问题,提出一种基于物体轮廓直线的目标3D边界框检测算法. ...
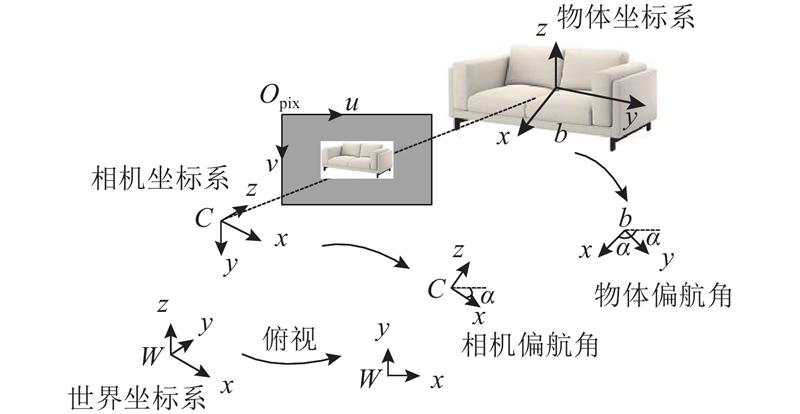
... VP是指空间中2个平行线在透视投影中的交点. 根据VP透视投影原理,已知目标物体的旋转矩阵和目标物的一个角点位置,利用VP可求解目标立方体的其他角点. Yang等[22 ] 对目标旋转矩阵和3D框顶角进行详尽采样,以确定3个方向的VP,但是该方法在复杂环境中容易失效且运算复杂. 为此,引入MSAC算法,提出一种基于几何约束的MSAC消失点估计算法. ...
... 本研究中3个消失点正好对应于空间物体的x 、y 、z 轴,可通过MSAC计算得到. 首先利用线段检测器(line segment detector,LSD)算法[22 ] 检测出图像中的直线,再利用MSAC对检测到的直线进行VP估计,其中MSAC算法主要分为2个部分,并依次迭代完成. ...
... 根据VP透视原理,在立方体边框采样一个角,然后结合3个消失点就可以估计目标物体的3D边界框. Hedau等[20 -22 ] 通过对2D边框顶部直线进行详尽的顶角采样,并依据该角预测3D边界框,再通过评价指标评选出其中最优的3D边界框. 虽然采用该方法能获得较好的估计结果,但是计算过程复杂. 为了减小计算量并提高3D边界框的估计精度,本文结合消失点、轮廓、顶点之间的几何信息,提出一种基于物体轮廓直线的目标3D框检测算法. ...
... 2)假设目标3D边界框紧贴于2D边界框[22 ] ,则越靠近2D边框的直线越可能是物体轮廓. ...
... 根据目标3D框是紧贴于2D边界框的假设[22 ] ,连接轮廓W 和对应的VP,可认为其与2D边界框产生的交点是3D边界框的角点. 需要注意的是,该连线一般会与2D边界框产生2个交点,按照就近原则,确定离边界更近的交点为3D边界框的角点,再结合3个消失点就可以估计出目标物体的3D框,不同情形下的VP与立方体角点关系如图3 所示[21 ] . ...
... 在单目图像中目标物体的采样有多种方式,如:语义分割、HOG特征等. 本文针对地面场景选择深度学习网络YOLOV2作为分割目标物、提取2D边界框的模型,该模型具有识别精度高、鲁棒性强的特点. 此外,为了验证算法效果,引入成本函数[22 ] 评价本文算法的有效性. 当成本函数大于经验阈值时,需要重新确定轮廓线和第一个角点. 设O 为目标2D边框,M 为估计的3D边界盒,具体的成本函数为 ...
... 本文针对文献[22 ] 的算法运算量大、估计精度不高的问题,改进MSAC消失点的计算方法和基于轮廓直线的3D框检测步骤,在保证运行效率和检测精度的前提下,提出一种空间约束单目3D物体边界框的检测算法. ...
... 所有实验均在Ubuntu16.04系统下完成,电脑配置如下:CPU(2.0 GHz Intel i7),运行内存为8 GB. 实验数据分别来自Sun RGB-D[24 ] 和KITTI[25 ] 数据集. 主要进行以下研究:1)验证VP位置精度;2)比较3D-Cube[22 ] 、Primitive[26 ] 、3dgp[27 ] 、Deep[28 ] 、SubCNN[29 ] 以及本文改进算法对于目标物体检测、3D包围盒估计的效果;3)验证所提算法的室外检测性能. ...
... 表2 给出了采用不同算法计算VP所需的运算时间T . 在实验中同样设置4种不同分辨率( $600 \times 450$ $500 \times 375$ $400 \times 300$ $300 \times 225$ [22 ] 算法,所提算法的运算时间更短,并且图片尺寸越大,运算速度越快. 虽然所提算法的运算时间不及原始算法MSAC,但是其检测精度更高. ...
... Calculation time of VP by different algorithms
Tab.2 ms 算法 $600 \times 450$ $500 \times 375$ $400 \times 300$ $300 \times 224$ MSAC 72 57 45 39 3D-Cube[22 ] 163 128 96 77 本文算法 102 82 67 58
2.2. 目标物体检测 为了评价目标3D边界框的效果,引入交并比(3D intersection over union,IoU)指标评价估计的3D框,该指标是指产生的候选框与原标记框的交叠率,即其交集与并集的比值. 当IoU<25%时,认为估计的3D框错误. 参考3D-Cube[22 ] 的目标3D框计算方法,根据相机位姿和相机内参计算物体的3D边界框. 另外,本文没有利用先验的CAD模型,只是利用相机的高度作为尺度,因此在实验中只是比较了与相机高度接近的地面物体. ...
... 为了评价目标3D边界框的效果,引入交并比(3D intersection over union,IoU)指标评价估计的3D框,该指标是指产生的候选框与原标记框的交叠率,即其交集与并集的比值. 当IoU<25%时,认为估计的3D框错误. 参考3D-Cube[22 ] 的目标3D框计算方法,根据相机位姿和相机内参计算物体的3D边界框. 另外,本文没有利用先验的CAD模型,只是利用相机的高度作为尺度,因此在实验中只是比较了与相机高度接近的地面物体. ...
... 首先, 利用文献[29 ]的方法训练Sun RGB-D数据集中的目标物体, 并将其作为验证和对比的标准; 然后,将所提算法估计的结果与其他2个深度学习模型[26 -27 ] 以及3D-Cube方法比较, 具体结果如表3 所示. 在所有比较的算法中,所提算法在指标“IoU”上的精度是最高. 相比于3D-Cube[22 ] ,本文算法对室内场景物体的3D框检测具有更好的精度,其3D框更紧密地贴合目标物体本身,即使应用在非3D标准物体上(见图5 ),估计的3D框从视觉上、IoU指标上都满足实际物体的尺寸. 以图中黑色椅子为例,所提算法更好地包围了椅子的下边部分,估计的角点更靠近于真实物体角点,比例更加合适. 原因是本文在基于MSAC求解VP的方法中,建立了VP与空间中目标的空间透视投射关系,利用更多的约束关系求解VP,因而提高了VP的位置精度;基于检测的物体轮廓线寻找角点,充分利用了图像中目标的直线信息,缩短了计算时间并提高了角点估计的准确率. 因而在与3D-Cube算法精度相近的情况下,所有算法,具有计算量更小、耗时更短的优势,由此验证了本文改进算法用于估计VP位置的有效性. ...
... Comparison of detection accuracy and quantity of different algorithms in Sun RGB-D data set
Tab.3 算法 IOU N t 注:1)表示仅对前10个目标提案进行结果分析 Primitive[26 ] 0.36 125 3dgp[27 ] 0.42 221 3D-Cube[22 ] 0.40 1904 3D-Cube1) 0.48 270 本文算法 0.42 1958 本文算法1) 0.51 320
图 5 不同算法的3D检测效果可视化 ...
... 对于室外场景,本文将深度学习网络SubCNN模型[13 ] 作为分割目标物、2D边界框提取的模型,并利用所提算法进行3D目标检测. 为了弱化2D检测的影响,只是选择IoU>0.7的提案,同时与3D-Cube[22 ] 一样,对全部目标提案以及前10个提案进行结果分析. 表4 给出了不同算法的目标3D框检测精度, 可视化结果如图6 所示. ...
... Comparison of detection accuracy and quantity of different algorithms on KITTI dataset
Tab.4 算法 IoU N t 注:1)表示仅对前10个目标提案进行结果分析 Deep[28 ] 0.33 10 957 SUBCNN[29 ] 0.21 8 730 3D-Cube[22 ] 0.20 10 571 3D-Cube1) 0.36 10 571 本文算法 0.21 10 593 本文算法1) 0.38 10 593
图 6 不同算法在KITTI数据集上的3D检测效果可视化 ...
多分辨率线段提取方法及线段语义分析
1
2018
... 根据MSAC算法要求,计算VP位置的前提是从图中至少检测出2条平行长直线,但是由于图像像素模糊等问题,1条直线常被检测为2条直线,造成VP位置的计算偏差. 为了提取连续性更强、完整度更高的长直线,参考宋欣等[23 ] 的研究,采用最小二乘法对每个VP方向上开合度最高的直线进行合并,并剔除短小直线和干扰直线; 建立相机偏航角与VP的约束关系,并结合MSAC算法对目标框中的直线进行分类,最后计算VP的位置. ...
多分辨率线段提取方法及线段语义分析
1
2018
... 根据MSAC算法要求,计算VP位置的前提是从图中至少检测出2条平行长直线,但是由于图像像素模糊等问题,1条直线常被检测为2条直线,造成VP位置的计算偏差. 为了提取连续性更强、完整度更高的长直线,参考宋欣等[23 ] 的研究,采用最小二乘法对每个VP方向上开合度最高的直线进行合并,并剔除短小直线和干扰直线; 建立相机偏航角与VP的约束关系,并结合MSAC算法对目标框中的直线进行分类,最后计算VP的位置. ...
1
... 所有实验均在Ubuntu16.04系统下完成,电脑配置如下:CPU(2.0 GHz Intel i7),运行内存为8 GB. 实验数据分别来自Sun RGB-D[24 ] 和KITTI[25 ] 数据集. 主要进行以下研究:1)验证VP位置精度;2)比较3D-Cube[22 ] 、Primitive[26 ] 、3dgp[27 ] 、Deep[28 ] 、SubCNN[29 ] 以及本文改进算法对于目标物体检测、3D包围盒估计的效果;3)验证所提算法的室外检测性能. ...
1
... 所有实验均在Ubuntu16.04系统下完成,电脑配置如下:CPU(2.0 GHz Intel i7),运行内存为8 GB. 实验数据分别来自Sun RGB-D[24 ] 和KITTI[25 ] 数据集. 主要进行以下研究:1)验证VP位置精度;2)比较3D-Cube[22 ] 、Primitive[26 ] 、3dgp[27 ] 、Deep[28 ] 、SubCNN[29 ] 以及本文改进算法对于目标物体检测、3D包围盒估计的效果;3)验证所提算法的室外检测性能. ...
3
... 所有实验均在Ubuntu16.04系统下完成,电脑配置如下:CPU(2.0 GHz Intel i7),运行内存为8 GB. 实验数据分别来自Sun RGB-D[24 ] 和KITTI[25 ] 数据集. 主要进行以下研究:1)验证VP位置精度;2)比较3D-Cube[22 ] 、Primitive[26 ] 、3dgp[27 ] 、Deep[28 ] 、SubCNN[29 ] 以及本文改进算法对于目标物体检测、3D包围盒估计的效果;3)验证所提算法的室外检测性能. ...
... 首先, 利用文献[29 ]的方法训练Sun RGB-D数据集中的目标物体, 并将其作为验证和对比的标准; 然后,将所提算法估计的结果与其他2个深度学习模型[26 -27 ] 以及3D-Cube方法比较, 具体结果如表3 所示. 在所有比较的算法中,所提算法在指标“IoU”上的精度是最高. 相比于3D-Cube[22 ] ,本文算法对室内场景物体的3D框检测具有更好的精度,其3D框更紧密地贴合目标物体本身,即使应用在非3D标准物体上(见图5 ),估计的3D框从视觉上、IoU指标上都满足实际物体的尺寸. 以图中黑色椅子为例,所提算法更好地包围了椅子的下边部分,估计的角点更靠近于真实物体角点,比例更加合适. 原因是本文在基于MSAC求解VP的方法中,建立了VP与空间中目标的空间透视投射关系,利用更多的约束关系求解VP,因而提高了VP的位置精度;基于检测的物体轮廓线寻找角点,充分利用了图像中目标的直线信息,缩短了计算时间并提高了角点估计的准确率. 因而在与3D-Cube算法精度相近的情况下,所有算法,具有计算量更小、耗时更短的优势,由此验证了本文改进算法用于估计VP位置的有效性. ...
... Comparison of detection accuracy and quantity of different algorithms in Sun RGB-D data set
Tab.3 算法 IOU N t 注:1)表示仅对前10个目标提案进行结果分析 Primitive[26 ] 0.36 125 3dgp[27 ] 0.42 221 3D-Cube[22 ] 0.40 1904 3D-Cube1) 0.48 270 本文算法 0.42 1958 本文算法1) 0.51 320
图 5 不同算法的3D检测效果可视化 ...
3
... 所有实验均在Ubuntu16.04系统下完成,电脑配置如下:CPU(2.0 GHz Intel i7),运行内存为8 GB. 实验数据分别来自Sun RGB-D[24 ] 和KITTI[25 ] 数据集. 主要进行以下研究:1)验证VP位置精度;2)比较3D-Cube[22 ] 、Primitive[26 ] 、3dgp[27 ] 、Deep[28 ] 、SubCNN[29 ] 以及本文改进算法对于目标物体检测、3D包围盒估计的效果;3)验证所提算法的室外检测性能. ...
... 首先, 利用文献[29 ]的方法训练Sun RGB-D数据集中的目标物体, 并将其作为验证和对比的标准; 然后,将所提算法估计的结果与其他2个深度学习模型[26 -27 ] 以及3D-Cube方法比较, 具体结果如表3 所示. 在所有比较的算法中,所提算法在指标“IoU”上的精度是最高. 相比于3D-Cube[22 ] ,本文算法对室内场景物体的3D框检测具有更好的精度,其3D框更紧密地贴合目标物体本身,即使应用在非3D标准物体上(见图5 ),估计的3D框从视觉上、IoU指标上都满足实际物体的尺寸. 以图中黑色椅子为例,所提算法更好地包围了椅子的下边部分,估计的角点更靠近于真实物体角点,比例更加合适. 原因是本文在基于MSAC求解VP的方法中,建立了VP与空间中目标的空间透视投射关系,利用更多的约束关系求解VP,因而提高了VP的位置精度;基于检测的物体轮廓线寻找角点,充分利用了图像中目标的直线信息,缩短了计算时间并提高了角点估计的准确率. 因而在与3D-Cube算法精度相近的情况下,所有算法,具有计算量更小、耗时更短的优势,由此验证了本文改进算法用于估计VP位置的有效性. ...
... Comparison of detection accuracy and quantity of different algorithms in Sun RGB-D data set
Tab.3 算法 IOU N t 注:1)表示仅对前10个目标提案进行结果分析 Primitive[26 ] 0.36 125 3dgp[27 ] 0.42 221 3D-Cube[22 ] 0.40 1904 3D-Cube1) 0.48 270 本文算法 0.42 1958 本文算法1) 0.51 320
图 5 不同算法的3D检测效果可视化 ...
2
... 所有实验均在Ubuntu16.04系统下完成,电脑配置如下:CPU(2.0 GHz Intel i7),运行内存为8 GB. 实验数据分别来自Sun RGB-D[24 ] 和KITTI[25 ] 数据集. 主要进行以下研究:1)验证VP位置精度;2)比较3D-Cube[22 ] 、Primitive[26 ] 、3dgp[27 ] 、Deep[28 ] 、SubCNN[29 ] 以及本文改进算法对于目标物体检测、3D包围盒估计的效果;3)验证所提算法的室外检测性能. ...
... Comparison of detection accuracy and quantity of different algorithms on KITTI dataset
Tab.4 算法 IoU N t 注:1)表示仅对前10个目标提案进行结果分析 Deep[28 ] 0.33 10 957 SUBCNN[29 ] 0.21 8 730 3D-Cube[22 ] 0.20 10 571 3D-Cube1) 0.36 10 571 本文算法 0.21 10 593 本文算法1) 0.38 10 593
图 6 不同算法在KITTI数据集上的3D检测效果可视化 ...
3
... 所有实验均在Ubuntu16.04系统下完成,电脑配置如下:CPU(2.0 GHz Intel i7),运行内存为8 GB. 实验数据分别来自Sun RGB-D[24 ] 和KITTI[25 ] 数据集. 主要进行以下研究:1)验证VP位置精度;2)比较3D-Cube[22 ] 、Primitive[26 ] 、3dgp[27 ] 、Deep[28 ] 、SubCNN[29 ] 以及本文改进算法对于目标物体检测、3D包围盒估计的效果;3)验证所提算法的室外检测性能. ...
... 首先, 利用文献[29 ]的方法训练Sun RGB-D数据集中的目标物体, 并将其作为验证和对比的标准; 然后,将所提算法估计的结果与其他2个深度学习模型[26 -27 ] 以及3D-Cube方法比较, 具体结果如表3 所示. 在所有比较的算法中,所提算法在指标“IoU”上的精度是最高. 相比于3D-Cube[22 ] ,本文算法对室内场景物体的3D框检测具有更好的精度,其3D框更紧密地贴合目标物体本身,即使应用在非3D标准物体上(见图5 ),估计的3D框从视觉上、IoU指标上都满足实际物体的尺寸. 以图中黑色椅子为例,所提算法更好地包围了椅子的下边部分,估计的角点更靠近于真实物体角点,比例更加合适. 原因是本文在基于MSAC求解VP的方法中,建立了VP与空间中目标的空间透视投射关系,利用更多的约束关系求解VP,因而提高了VP的位置精度;基于检测的物体轮廓线寻找角点,充分利用了图像中目标的直线信息,缩短了计算时间并提高了角点估计的准确率. 因而在与3D-Cube算法精度相近的情况下,所有算法,具有计算量更小、耗时更短的优势,由此验证了本文改进算法用于估计VP位置的有效性. ...
... Comparison of detection accuracy and quantity of different algorithms on KITTI dataset
Tab.4 算法 IoU N t 注:1)表示仅对前10个目标提案进行结果分析 Deep[28 ] 0.33 10 957 SUBCNN[29 ] 0.21 8 730 3D-Cube[22 ] 0.20 10 571 3D-Cube1) 0.36 10 571 本文算法 0.21 10 593 本文算法1) 0.38 10 593
图 6 不同算法在KITTI数据集上的3D检测效果可视化 ...
改进的基于gLoG滤波实时消失点检测算法
1
2018
... 从SUN-RGBD数据集中选取50幅图像进行验证,根据已知的相机位姿,手工标记出图像目标的VP,主要验证改进算法的计算精度和运算效率. 为了评价采用本文算法得到的VP与手工标记的VP的位置误差,将文献[30 ] 研究中的误差率 ${D_{{\rm{Nor}}}}$
改进的基于gLoG滤波实时消失点检测算法
1
2018
... 从SUN-RGBD数据集中选取50幅图像进行验证,根据已知的相机位姿,手工标记出图像目标的VP,主要验证改进算法的计算精度和运算效率. 为了评价采用本文算法得到的VP与手工标记的VP的位置误差,将文献[30 ] 研究中的误差率 ${D_{{\rm{Nor}}}}$





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}