[1]
HEARST M A, DUMAIS S T, OSUNA E, et al Support vector machines
[J]. IEEE Intelligent Systems and Their Applications , 1998 , 13 (4 ): 18 - 28
DOI:10.1109/5254.708428
[本文引用: 1]
[2]
BEJA-BATTAIS P. Overview of AdaBoost : reconciling its views to better understand its dynamics [EB/OL]. (2023-10-06)[2025-04-18]. https://arxiv.org/abs/2310.18323
[本文引用: 1]
[3]
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 1]
[4]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779–788.
[本文引用: 1]
[5]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector [C]// European Conference on Computer Vision (ECCV) 2016 . Cham: Springer International Publishing, 2016: 21–37.
[本文引用: 1]
[6]
GUPTA P, PAREEK B, SINGAL G, et al Edge device based military vehicle detection and classification from UAV
[J]. Multimedia Tools and Applications , 2022 , 81 (14 ): 19813 - 19834
DOI:10.1007/s11042-021-11242-y
[本文引用: 1]
[8]
SUN Y, SHAO Z, CHENG G, et al Road and car extraction using UAV images via efficient dual contextual parsing network
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2022 , 60 : 5632113
[本文引用: 1]
[9]
HAMZENEJADI M H, MOHSENI H Fine-tuned YOLOv5 for real-time vehicle detection in UAV imagery: architectural improvements and performance boost
[J]. Expert Systems with Applications , 2023 , 231 : 120845
DOI:10.1016/j.eswa.2023.120845
[本文引用: 1]
[10]
YING Z, ZHOU J, ZHAI Y, et al Large-scale high-altitude UAV-based vehicle detection via pyramid dual pooling attention path aggregation network
[J]. IEEE Transactions on Intelligent Transportation Systems , 2024 , 25 (10 ): 14426 - 14444
DOI:10.1109/TITS.2024.3396915
[本文引用: 1]
[11]
HUI Y, WANG J, LI B STF-YOLO: a small target detection algorithm for UAV remote sensing images based on improved SwinTransformer and class weighted classification decoupling head
[J]. Measurement , 2024 , 224 : 113936
DOI:10.1016/j.measurement.2023.113936
[本文引用: 1]
[14]
梁燕, 何孝武, 邵凯, 等 改进YOLOv8的无人机航拍图像目标检测算法
[J]. 计算机工程与应用 , 2025 , 61 (1 ): 121 - 130
DOI:10.3778/j.issn.1002-8331.2405-0459
[本文引用: 1]
LIANG Yan, HE Xiaowu, SHAO Kai, et al Target detection algorithm for UAV images based on improved YOLOv8
[J]. Computer Engineering and Applications , 2025 , 61 (1 ): 121 - 130
DOI:10.3778/j.issn.1002-8331.2405-0459
[本文引用: 1]
[15]
JOCHER G, CHAURASIA A, QIU J. Ultralytics YOLOv8 [EB/OL]. (2023-01-28)[2025-04-18]. https://github.com/ultralytics/ultralytics.
[本文引用: 1]
[16]
XUE Y, JIN G, SHEN T, et al SmallTrack: wavelet pooling and graph enhanced classification for UAV small object tracking
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2023 , 61 : 5618815
[本文引用: 1]
[17]
LI C, LI L, GENG Y, et al. YOLOv6 v3. 0: a full-scale reloading [EB/OL]. (2023-01-13)[2025-04-18]. https://arxiv.org/abs/2301.05586.
[本文引用: 2]
[18]
ZHANG Z Drone-YOLO: an efficient neural network method for target detection in drone images
[J]. Drones , 2023 , 7 (8 ): 526
DOI:10.3390/drones7080526
[本文引用: 3]
[19]
ZHANG Y F, REN W, ZHANG Z, et al Focal and efficient IOU loss for accurate bounding box regression
[J]. Neurocomputing , 2022 , 506 : 146 - 157
DOI:10.1016/j.neucom.2022.07.042
[本文引用: 1]
[20]
YANG X, YAN J, MING Q, et al. Rethinking rotated object detection with Gaussian Wasserstein distance loss [C]// International Conference on Machine Learning (ICML) . Virtual Event: PMLR, 2021: 11830–11841.
[本文引用: 1]
[21]
DU D, ZHU P, WEN L, et al. VisDrone-DET2019: the Vision Meets Drone Object Detection in Image Challenge Results [C]// 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW) . Seoul: IEEE, 2019: 213–226.
[本文引用: 1]
[22]
SUN Y, CAO B, ZHU P, et al Drone-based RGB-infrared cross-modality vehicle detection via uncertainty-aware learning
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2022 , 32 (10 ): 6700 - 6713
DOI:10.1109/TCSVT.2022.3168279
[本文引用: 1]
[23]
WANG C-Y, YEH I-H, LIAO H. YOLOv9: learning what you want to learn using programmable gradient information [EB/OL]. (2024-02-21)[2025-04-18]. https://arxiv.org/abs/2402.13616.
[本文引用: 1]
[24]
WANG A, CHEN H, LIU L, et al. YOLOv10: real-time end-to-end object detection [EB/OL]. (2023-05-23)[2025-04-18]. https://arxiv.org/abs/2405.14458.
[本文引用: 1]
[25]
CHOLLET F. Xception: deep learning with depthwise separable convolutions [C]// IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1800–1807.
[本文引用: 1]
[26]
XIAO Y, XU T, XIN Y, et al. FBRT-YOLO: faster and better for real-time aerial image detection [EB/OL]. (2025-04-29)[2025-04-18]. https://arxiv.org/abs/2504.20670.
[本文引用: 1]
[27]
TIAN D, YAN X, ZHOU D, et al IV-YOLO: a lightweight dual-branch object detection network
[J]. Sensors , 2024 , 24 (19 ): 6181
DOI:10.3390/s24196181
[本文引用: 1]
Support vector machines
1
1998
... 目前,基于无人机航拍图像的车辆检测方法主要包括传统图像处理与深度学习2类. 前者通常通过人工提取车辆的外观特征(如形状、纹理、颜色),结合支持向量机 (SVM)[1 ] 与AdaBoost[2 ] 等分类器进行识别,但特征表达能力有限,难以适应小目标与复杂背景,检测精度和泛化性能均受限制. 随着深度学习的发展,卷积神经网络在目标检测中取得显著突破,逐步主导无人机图像检测研究. 此类方法主要分为二阶段与单阶段检测器:前者如Faster R-CNN[3 ] 通过先生成候选区域再进行精细分类与定位,具备较高检测精度,但计算开销较大,难以满足实时性要求;后者如You Only Look Once (YOLO)[4 ] 系列与Single Shot MultiBox Detector[5 ] 将定位与分类融合为统一回归任务,具备更快的推理速度和较高的部署灵活性. 因此,在无人机航拍车辆检测中,研究者主要对一阶段检测器进行改进,以提升实时性与检测精度. 主要方法如下. ...
1
... 目前,基于无人机航拍图像的车辆检测方法主要包括传统图像处理与深度学习2类. 前者通常通过人工提取车辆的外观特征(如形状、纹理、颜色),结合支持向量机 (SVM)[1 ] 与AdaBoost[2 ] 等分类器进行识别,但特征表达能力有限,难以适应小目标与复杂背景,检测精度和泛化性能均受限制. 随着深度学习的发展,卷积神经网络在目标检测中取得显著突破,逐步主导无人机图像检测研究. 此类方法主要分为二阶段与单阶段检测器:前者如Faster R-CNN[3 ] 通过先生成候选区域再进行精细分类与定位,具备较高检测精度,但计算开销较大,难以满足实时性要求;后者如You Only Look Once (YOLO)[4 ] 系列与Single Shot MultiBox Detector[5 ] 将定位与分类融合为统一回归任务,具备更快的推理速度和较高的部署灵活性. 因此,在无人机航拍车辆检测中,研究者主要对一阶段检测器进行改进,以提升实时性与检测精度. 主要方法如下. ...
Faster R-CNN: towards real-time object detection with region proposal networks
1
2017
... 目前,基于无人机航拍图像的车辆检测方法主要包括传统图像处理与深度学习2类. 前者通常通过人工提取车辆的外观特征(如形状、纹理、颜色),结合支持向量机 (SVM)[1 ] 与AdaBoost[2 ] 等分类器进行识别,但特征表达能力有限,难以适应小目标与复杂背景,检测精度和泛化性能均受限制. 随着深度学习的发展,卷积神经网络在目标检测中取得显著突破,逐步主导无人机图像检测研究. 此类方法主要分为二阶段与单阶段检测器:前者如Faster R-CNN[3 ] 通过先生成候选区域再进行精细分类与定位,具备较高检测精度,但计算开销较大,难以满足实时性要求;后者如You Only Look Once (YOLO)[4 ] 系列与Single Shot MultiBox Detector[5 ] 将定位与分类融合为统一回归任务,具备更快的推理速度和较高的部署灵活性. 因此,在无人机航拍车辆检测中,研究者主要对一阶段检测器进行改进,以提升实时性与检测精度. 主要方法如下. ...
1
... 目前,基于无人机航拍图像的车辆检测方法主要包括传统图像处理与深度学习2类. 前者通常通过人工提取车辆的外观特征(如形状、纹理、颜色),结合支持向量机 (SVM)[1 ] 与AdaBoost[2 ] 等分类器进行识别,但特征表达能力有限,难以适应小目标与复杂背景,检测精度和泛化性能均受限制. 随着深度学习的发展,卷积神经网络在目标检测中取得显著突破,逐步主导无人机图像检测研究. 此类方法主要分为二阶段与单阶段检测器:前者如Faster R-CNN[3 ] 通过先生成候选区域再进行精细分类与定位,具备较高检测精度,但计算开销较大,难以满足实时性要求;后者如You Only Look Once (YOLO)[4 ] 系列与Single Shot MultiBox Detector[5 ] 将定位与分类融合为统一回归任务,具备更快的推理速度和较高的部署灵活性. 因此,在无人机航拍车辆检测中,研究者主要对一阶段检测器进行改进,以提升实时性与检测精度. 主要方法如下. ...
1
... 目前,基于无人机航拍图像的车辆检测方法主要包括传统图像处理与深度学习2类. 前者通常通过人工提取车辆的外观特征(如形状、纹理、颜色),结合支持向量机 (SVM)[1 ] 与AdaBoost[2 ] 等分类器进行识别,但特征表达能力有限,难以适应小目标与复杂背景,检测精度和泛化性能均受限制. 随着深度学习的发展,卷积神经网络在目标检测中取得显著突破,逐步主导无人机图像检测研究. 此类方法主要分为二阶段与单阶段检测器:前者如Faster R-CNN[3 ] 通过先生成候选区域再进行精细分类与定位,具备较高检测精度,但计算开销较大,难以满足实时性要求;后者如You Only Look Once (YOLO)[4 ] 系列与Single Shot MultiBox Detector[5 ] 将定位与分类融合为统一回归任务,具备更快的推理速度和较高的部署灵活性. 因此,在无人机航拍车辆检测中,研究者主要对一阶段检测器进行改进,以提升实时性与检测精度. 主要方法如下. ...
Edge device based military vehicle detection and classification from UAV
1
2022
... 1)提升实时检测性能. 针对无人机航拍场景下计算资源有限、处理需快速的特点,部分研究通过轻量化设计、优化卷积结构或削减冗余特征以提升检测速度并满足实时性要求. Gupta等[6 ] 构建了6772 张军民融合的航拍图像数据集,并在边缘平台对SSD-Mobilenet v2与Tiny-YOLOv3进行量化对比,结果显示后者在实时性与准确率方面表现良好,但由于模型结构较旧且样本规模有限,在复杂遮挡条件下的鲁棒性仍显不足. 史涛等[7 ] 提出YOLOv8-CX,结合C2f-DCN、SPPF-LSKA与CF-FPN等模块,在提升多尺度特征表达能力的同时,将推理速度提升至112.6帧/s,满足实时检测需求,但在密集小目标或强遮挡场景中,鲁棒性仍存在瓶颈. ...
优化改进YOLOv8实现实时无人机车辆检测的算法
1
2024
... 1)提升实时检测性能. 针对无人机航拍场景下计算资源有限、处理需快速的特点,部分研究通过轻量化设计、优化卷积结构或削减冗余特征以提升检测速度并满足实时性要求. Gupta等[6 ] 构建了6772 张军民融合的航拍图像数据集,并在边缘平台对SSD-Mobilenet v2与Tiny-YOLOv3进行量化对比,结果显示后者在实时性与准确率方面表现良好,但由于模型结构较旧且样本规模有限,在复杂遮挡条件下的鲁棒性仍显不足. 史涛等[7 ] 提出YOLOv8-CX,结合C2f-DCN、SPPF-LSKA与CF-FPN等模块,在提升多尺度特征表达能力的同时,将推理速度提升至112.6帧/s,满足实时检测需求,但在密集小目标或强遮挡场景中,鲁棒性仍存在瓶颈. ...
优化改进YOLOv8实现实时无人机车辆检测的算法
1
2024
... 1)提升实时检测性能. 针对无人机航拍场景下计算资源有限、处理需快速的特点,部分研究通过轻量化设计、优化卷积结构或削减冗余特征以提升检测速度并满足实时性要求. Gupta等[6 ] 构建了6772 张军民融合的航拍图像数据集,并在边缘平台对SSD-Mobilenet v2与Tiny-YOLOv3进行量化对比,结果显示后者在实时性与准确率方面表现良好,但由于模型结构较旧且样本规模有限,在复杂遮挡条件下的鲁棒性仍显不足. 史涛等[7 ] 提出YOLOv8-CX,结合C2f-DCN、SPPF-LSKA与CF-FPN等模块,在提升多尺度特征表达能力的同时,将推理速度提升至112.6帧/s,满足实时检测需求,但在密集小目标或强遮挡场景中,鲁棒性仍存在瓶颈. ...
Road and car extraction using UAV images via efficient dual contextual parsing network
1
2022
... 2)增强检测精度. 为了应对无人机航拍图像中多尺度、密集小目标及复杂背景干扰,研究常引入Transformer结构、上下文信息、注意力机制或跨尺度融合,以提升检测精度与适应性,但往往带来计算开销增加与推理速度下降. Sun等[8 ] 提出双重上下文解析网络以增强城市道路环境中的上下文感知能力,从而提升小目标和遮挡场景下的检测精度,但未考虑模型的推理效率. Hamzenejadi等[9 ] 在YOLOv5中引入注意力机制与轻量卷积,以提升多视角下的小目标检测能力,但融合结构导致延迟增加. Ying等[10 ] 提出融合空间与语义注意力的信息增强网络,以提升250~400 m视角下检测鲁棒性,但在复杂场景下的推理速度有所下降. Hui等[11 ] 提出的STF-YOLO模型结合Transformer与CNN,在VisDrone数据集上表现优异,但计算开销显著增加,难以满足实时性要求. 姜贸翔等[12 ] 在RT-DETR的基础上引入SimAM注意力、细粒度残差与多分支交互机制,显著增强了空间感知与全局建模能力,但其DETR架构限制了推理速度. 李彬等[13 ] 将RFCBAMConv、DFPC金字塔卷积与DyHead集成至YOLOv11n,检测精度提升至mAP@0.5=77.1%,但多分支与全局增强机制显著增加计算负担. 梁艳等[14 ] 提出TS-YOLO算法,其结合了EFEM、DCWF与PSDH模块,精度提升至mAP@0.5=71.9%,但整体复杂度高、推理速度下降. ...
Fine-tuned YOLOv5 for real-time vehicle detection in UAV imagery: architectural improvements and performance boost
1
2023
... 2)增强检测精度. 为了应对无人机航拍图像中多尺度、密集小目标及复杂背景干扰,研究常引入Transformer结构、上下文信息、注意力机制或跨尺度融合,以提升检测精度与适应性,但往往带来计算开销增加与推理速度下降. Sun等[8 ] 提出双重上下文解析网络以增强城市道路环境中的上下文感知能力,从而提升小目标和遮挡场景下的检测精度,但未考虑模型的推理效率. Hamzenejadi等[9 ] 在YOLOv5中引入注意力机制与轻量卷积,以提升多视角下的小目标检测能力,但融合结构导致延迟增加. Ying等[10 ] 提出融合空间与语义注意力的信息增强网络,以提升250~400 m视角下检测鲁棒性,但在复杂场景下的推理速度有所下降. Hui等[11 ] 提出的STF-YOLO模型结合Transformer与CNN,在VisDrone数据集上表现优异,但计算开销显著增加,难以满足实时性要求. 姜贸翔等[12 ] 在RT-DETR的基础上引入SimAM注意力、细粒度残差与多分支交互机制,显著增强了空间感知与全局建模能力,但其DETR架构限制了推理速度. 李彬等[13 ] 将RFCBAMConv、DFPC金字塔卷积与DyHead集成至YOLOv11n,检测精度提升至mAP@0.5=77.1%,但多分支与全局增强机制显著增加计算负担. 梁艳等[14 ] 提出TS-YOLO算法,其结合了EFEM、DCWF与PSDH模块,精度提升至mAP@0.5=71.9%,但整体复杂度高、推理速度下降. ...
Large-scale high-altitude UAV-based vehicle detection via pyramid dual pooling attention path aggregation network
1
2024
... 2)增强检测精度. 为了应对无人机航拍图像中多尺度、密集小目标及复杂背景干扰,研究常引入Transformer结构、上下文信息、注意力机制或跨尺度融合,以提升检测精度与适应性,但往往带来计算开销增加与推理速度下降. Sun等[8 ] 提出双重上下文解析网络以增强城市道路环境中的上下文感知能力,从而提升小目标和遮挡场景下的检测精度,但未考虑模型的推理效率. Hamzenejadi等[9 ] 在YOLOv5中引入注意力机制与轻量卷积,以提升多视角下的小目标检测能力,但融合结构导致延迟增加. Ying等[10 ] 提出融合空间与语义注意力的信息增强网络,以提升250~400 m视角下检测鲁棒性,但在复杂场景下的推理速度有所下降. Hui等[11 ] 提出的STF-YOLO模型结合Transformer与CNN,在VisDrone数据集上表现优异,但计算开销显著增加,难以满足实时性要求. 姜贸翔等[12 ] 在RT-DETR的基础上引入SimAM注意力、细粒度残差与多分支交互机制,显著增强了空间感知与全局建模能力,但其DETR架构限制了推理速度. 李彬等[13 ] 将RFCBAMConv、DFPC金字塔卷积与DyHead集成至YOLOv11n,检测精度提升至mAP@0.5=77.1%,但多分支与全局增强机制显著增加计算负担. 梁艳等[14 ] 提出TS-YOLO算法,其结合了EFEM、DCWF与PSDH模块,精度提升至mAP@0.5=71.9%,但整体复杂度高、推理速度下降. ...
STF-YOLO: a small target detection algorithm for UAV remote sensing images based on improved SwinTransformer and class weighted classification decoupling head
1
2024
... 2)增强检测精度. 为了应对无人机航拍图像中多尺度、密集小目标及复杂背景干扰,研究常引入Transformer结构、上下文信息、注意力机制或跨尺度融合,以提升检测精度与适应性,但往往带来计算开销增加与推理速度下降. Sun等[8 ] 提出双重上下文解析网络以增强城市道路环境中的上下文感知能力,从而提升小目标和遮挡场景下的检测精度,但未考虑模型的推理效率. Hamzenejadi等[9 ] 在YOLOv5中引入注意力机制与轻量卷积,以提升多视角下的小目标检测能力,但融合结构导致延迟增加. Ying等[10 ] 提出融合空间与语义注意力的信息增强网络,以提升250~400 m视角下检测鲁棒性,但在复杂场景下的推理速度有所下降. Hui等[11 ] 提出的STF-YOLO模型结合Transformer与CNN,在VisDrone数据集上表现优异,但计算开销显著增加,难以满足实时性要求. 姜贸翔等[12 ] 在RT-DETR的基础上引入SimAM注意力、细粒度残差与多分支交互机制,显著增强了空间感知与全局建模能力,但其DETR架构限制了推理速度. 李彬等[13 ] 将RFCBAMConv、DFPC金字塔卷积与DyHead集成至YOLOv11n,检测精度提升至mAP@0.5=77.1%,但多分支与全局增强机制显著增加计算负担. 梁艳等[14 ] 提出TS-YOLO算法,其结合了EFEM、DCWF与PSDH模块,精度提升至mAP@0.5=71.9%,但整体复杂度高、推理速度下降. ...
改进RT-DETR的无人机图像目标检测算法
1
2025
... 2)增强检测精度. 为了应对无人机航拍图像中多尺度、密集小目标及复杂背景干扰,研究常引入Transformer结构、上下文信息、注意力机制或跨尺度融合,以提升检测精度与适应性,但往往带来计算开销增加与推理速度下降. Sun等[8 ] 提出双重上下文解析网络以增强城市道路环境中的上下文感知能力,从而提升小目标和遮挡场景下的检测精度,但未考虑模型的推理效率. Hamzenejadi等[9 ] 在YOLOv5中引入注意力机制与轻量卷积,以提升多视角下的小目标检测能力,但融合结构导致延迟增加. Ying等[10 ] 提出融合空间与语义注意力的信息增强网络,以提升250~400 m视角下检测鲁棒性,但在复杂场景下的推理速度有所下降. Hui等[11 ] 提出的STF-YOLO模型结合Transformer与CNN,在VisDrone数据集上表现优异,但计算开销显著增加,难以满足实时性要求. 姜贸翔等[12 ] 在RT-DETR的基础上引入SimAM注意力、细粒度残差与多分支交互机制,显著增强了空间感知与全局建模能力,但其DETR架构限制了推理速度. 李彬等[13 ] 将RFCBAMConv、DFPC金字塔卷积与DyHead集成至YOLOv11n,检测精度提升至mAP@0.5=77.1%,但多分支与全局增强机制显著增加计算负担. 梁艳等[14 ] 提出TS-YOLO算法,其结合了EFEM、DCWF与PSDH模块,精度提升至mAP@0.5=71.9%,但整体复杂度高、推理速度下降. ...
改进RT-DETR的无人机图像目标检测算法
1
2025
... 2)增强检测精度. 为了应对无人机航拍图像中多尺度、密集小目标及复杂背景干扰,研究常引入Transformer结构、上下文信息、注意力机制或跨尺度融合,以提升检测精度与适应性,但往往带来计算开销增加与推理速度下降. Sun等[8 ] 提出双重上下文解析网络以增强城市道路环境中的上下文感知能力,从而提升小目标和遮挡场景下的检测精度,但未考虑模型的推理效率. Hamzenejadi等[9 ] 在YOLOv5中引入注意力机制与轻量卷积,以提升多视角下的小目标检测能力,但融合结构导致延迟增加. Ying等[10 ] 提出融合空间与语义注意力的信息增强网络,以提升250~400 m视角下检测鲁棒性,但在复杂场景下的推理速度有所下降. Hui等[11 ] 提出的STF-YOLO模型结合Transformer与CNN,在VisDrone数据集上表现优异,但计算开销显著增加,难以满足实时性要求. 姜贸翔等[12 ] 在RT-DETR的基础上引入SimAM注意力、细粒度残差与多分支交互机制,显著增强了空间感知与全局建模能力,但其DETR架构限制了推理速度. 李彬等[13 ] 将RFCBAMConv、DFPC金字塔卷积与DyHead集成至YOLOv11n,检测精度提升至mAP@0.5=77.1%,但多分支与全局增强机制显著增加计算负担. 梁艳等[14 ] 提出TS-YOLO算法,其结合了EFEM、DCWF与PSDH模块,精度提升至mAP@0.5=71.9%,但整体复杂度高、推理速度下降. ...
改进YOLOv11n的无人机小目标检测算法
1
2025
... 2)增强检测精度. 为了应对无人机航拍图像中多尺度、密集小目标及复杂背景干扰,研究常引入Transformer结构、上下文信息、注意力机制或跨尺度融合,以提升检测精度与适应性,但往往带来计算开销增加与推理速度下降. Sun等[8 ] 提出双重上下文解析网络以增强城市道路环境中的上下文感知能力,从而提升小目标和遮挡场景下的检测精度,但未考虑模型的推理效率. Hamzenejadi等[9 ] 在YOLOv5中引入注意力机制与轻量卷积,以提升多视角下的小目标检测能力,但融合结构导致延迟增加. Ying等[10 ] 提出融合空间与语义注意力的信息增强网络,以提升250~400 m视角下检测鲁棒性,但在复杂场景下的推理速度有所下降. Hui等[11 ] 提出的STF-YOLO模型结合Transformer与CNN,在VisDrone数据集上表现优异,但计算开销显著增加,难以满足实时性要求. 姜贸翔等[12 ] 在RT-DETR的基础上引入SimAM注意力、细粒度残差与多分支交互机制,显著增强了空间感知与全局建模能力,但其DETR架构限制了推理速度. 李彬等[13 ] 将RFCBAMConv、DFPC金字塔卷积与DyHead集成至YOLOv11n,检测精度提升至mAP@0.5=77.1%,但多分支与全局增强机制显著增加计算负担. 梁艳等[14 ] 提出TS-YOLO算法,其结合了EFEM、DCWF与PSDH模块,精度提升至mAP@0.5=71.9%,但整体复杂度高、推理速度下降. ...
改进YOLOv11n的无人机小目标检测算法
1
2025
... 2)增强检测精度. 为了应对无人机航拍图像中多尺度、密集小目标及复杂背景干扰,研究常引入Transformer结构、上下文信息、注意力机制或跨尺度融合,以提升检测精度与适应性,但往往带来计算开销增加与推理速度下降. Sun等[8 ] 提出双重上下文解析网络以增强城市道路环境中的上下文感知能力,从而提升小目标和遮挡场景下的检测精度,但未考虑模型的推理效率. Hamzenejadi等[9 ] 在YOLOv5中引入注意力机制与轻量卷积,以提升多视角下的小目标检测能力,但融合结构导致延迟增加. Ying等[10 ] 提出融合空间与语义注意力的信息增强网络,以提升250~400 m视角下检测鲁棒性,但在复杂场景下的推理速度有所下降. Hui等[11 ] 提出的STF-YOLO模型结合Transformer与CNN,在VisDrone数据集上表现优异,但计算开销显著增加,难以满足实时性要求. 姜贸翔等[12 ] 在RT-DETR的基础上引入SimAM注意力、细粒度残差与多分支交互机制,显著增强了空间感知与全局建模能力,但其DETR架构限制了推理速度. 李彬等[13 ] 将RFCBAMConv、DFPC金字塔卷积与DyHead集成至YOLOv11n,检测精度提升至mAP@0.5=77.1%,但多分支与全局增强机制显著增加计算负担. 梁艳等[14 ] 提出TS-YOLO算法,其结合了EFEM、DCWF与PSDH模块,精度提升至mAP@0.5=71.9%,但整体复杂度高、推理速度下降. ...
改进YOLOv8的无人机航拍图像目标检测算法
1
2025
... 2)增强检测精度. 为了应对无人机航拍图像中多尺度、密集小目标及复杂背景干扰,研究常引入Transformer结构、上下文信息、注意力机制或跨尺度融合,以提升检测精度与适应性,但往往带来计算开销增加与推理速度下降. Sun等[8 ] 提出双重上下文解析网络以增强城市道路环境中的上下文感知能力,从而提升小目标和遮挡场景下的检测精度,但未考虑模型的推理效率. Hamzenejadi等[9 ] 在YOLOv5中引入注意力机制与轻量卷积,以提升多视角下的小目标检测能力,但融合结构导致延迟增加. Ying等[10 ] 提出融合空间与语义注意力的信息增强网络,以提升250~400 m视角下检测鲁棒性,但在复杂场景下的推理速度有所下降. Hui等[11 ] 提出的STF-YOLO模型结合Transformer与CNN,在VisDrone数据集上表现优异,但计算开销显著增加,难以满足实时性要求. 姜贸翔等[12 ] 在RT-DETR的基础上引入SimAM注意力、细粒度残差与多分支交互机制,显著增强了空间感知与全局建模能力,但其DETR架构限制了推理速度. 李彬等[13 ] 将RFCBAMConv、DFPC金字塔卷积与DyHead集成至YOLOv11n,检测精度提升至mAP@0.5=77.1%,但多分支与全局增强机制显著增加计算负担. 梁艳等[14 ] 提出TS-YOLO算法,其结合了EFEM、DCWF与PSDH模块,精度提升至mAP@0.5=71.9%,但整体复杂度高、推理速度下降. ...
改进YOLOv8的无人机航拍图像目标检测算法
1
2025
... 2)增强检测精度. 为了应对无人机航拍图像中多尺度、密集小目标及复杂背景干扰,研究常引入Transformer结构、上下文信息、注意力机制或跨尺度融合,以提升检测精度与适应性,但往往带来计算开销增加与推理速度下降. Sun等[8 ] 提出双重上下文解析网络以增强城市道路环境中的上下文感知能力,从而提升小目标和遮挡场景下的检测精度,但未考虑模型的推理效率. Hamzenejadi等[9 ] 在YOLOv5中引入注意力机制与轻量卷积,以提升多视角下的小目标检测能力,但融合结构导致延迟增加. Ying等[10 ] 提出融合空间与语义注意力的信息增强网络,以提升250~400 m视角下检测鲁棒性,但在复杂场景下的推理速度有所下降. Hui等[11 ] 提出的STF-YOLO模型结合Transformer与CNN,在VisDrone数据集上表现优异,但计算开销显著增加,难以满足实时性要求. 姜贸翔等[12 ] 在RT-DETR的基础上引入SimAM注意力、细粒度残差与多分支交互机制,显著增强了空间感知与全局建模能力,但其DETR架构限制了推理速度. 李彬等[13 ] 将RFCBAMConv、DFPC金字塔卷积与DyHead集成至YOLOv11n,检测精度提升至mAP@0.5=77.1%,但多分支与全局增强机制显著增加计算负担. 梁艳等[14 ] 提出TS-YOLO算法,其结合了EFEM、DCWF与PSDH模块,精度提升至mAP@0.5=71.9%,但整体复杂度高、推理速度下降. ...
1
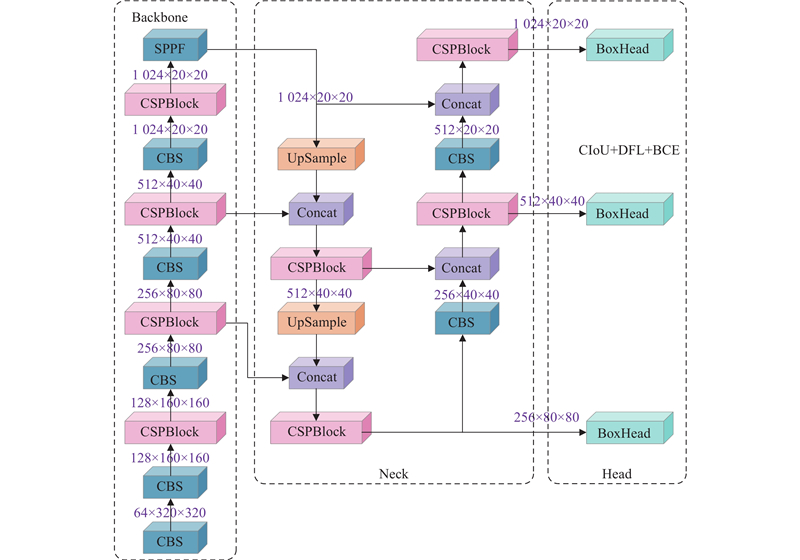
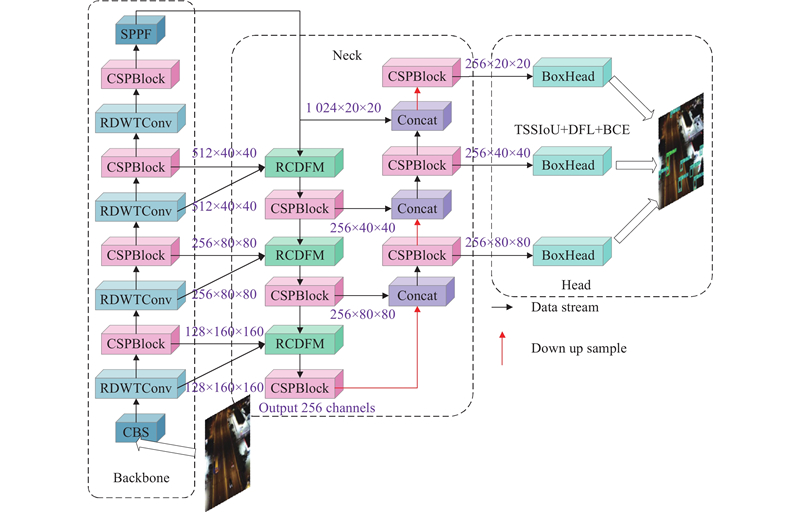
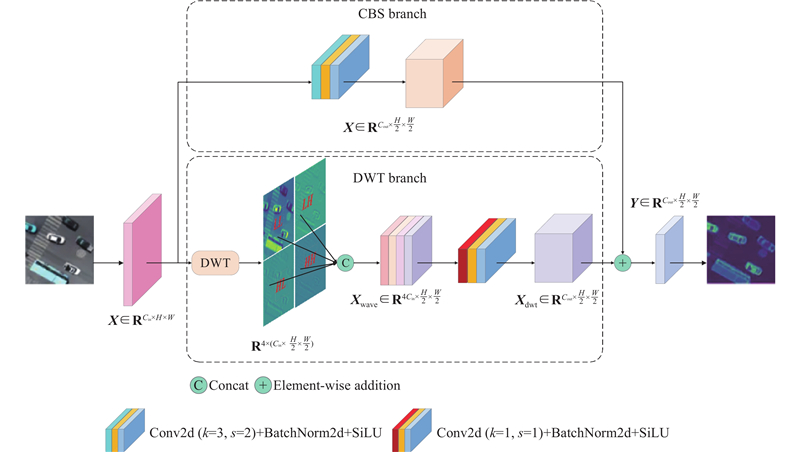
... 即便在理想场景下,尽管Jocher等[15 ] 提出的的YOLOv8n 在精度、速度与轻量化之间实现较好平衡,但在密集遮挡、低光照及复杂背景等场景下,仍面临小目标与多尺度目标检测精度明显下降的问题,难以兼顾精度与实时检测,进一步反映出当前方法在复杂环境下的适应性不足. 因此,为了提升复杂场景下无人机航拍图像的多尺度车辆检测性能,本研究以YOLOv8n为基线模型,提出面向复杂场景下的实时多尺度车辆检测算法. 主要贡献如下. 1)为了增强复杂场景下小目标在纹理、边缘与尺度变化下的感知能力,针对下采样阶段易导致高频信息损失的问题,首次提出残差连接离散小波变换卷积 (residual connected discrete wavelet transform Conv, RDWTConv),可在降采样同时保留高频细节,提升小目标的细粒度特征表征能力. 2)为了引导复杂场景下多尺度目标的语义与细节协同表征能力,针对不同语义特征之间缺乏有效的耦合问题,首次提出残差感知跨尺度动态融合模块 (residual-aware cross-scale dynamic fusion module, RCDFM),通过分支残差路径引导高层语义与浅层细节的融合,增强Head阶段的空间信息表达能力,从而提升多尺度目标检测性能. 3)为了强化复杂场景下对多尺度目标的边界框几何适应能力,针对高空航拍中目标尺度与形状变化显著引发的定位偏差问题,首次提出TSSIoU损失,有效提升对多尺度目标的鲁棒定位精度. 4)为了提升复杂场景下多尺度车辆检测性能,提出具备扩展性与计算效率的CF-YOLO框架,在保持实时性的同时兼顾高精度检测. ...
SmallTrack: wavelet pooling and graph enhanced classification for UAV small object tracking
1
2023
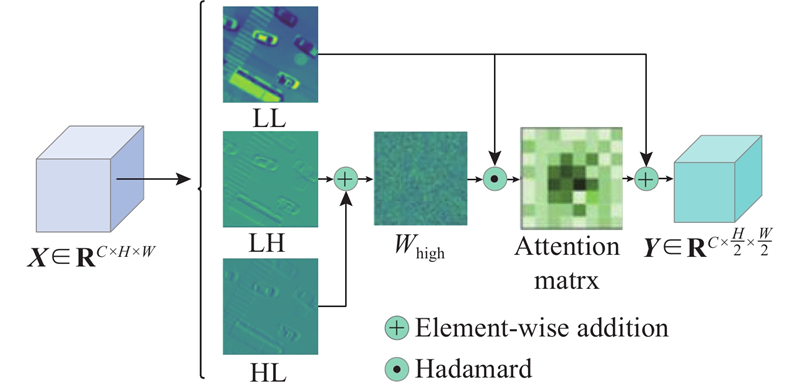
... 离散小波变换 (discrete wavelet transform,DWT)因在时频域中具备良好的局部性特征,近年来被广泛应用于深度学习中的特征压缩与细节保持任务. 如图3 所示为小波池化层(wavelet pooling layer, WPL)结构图[16 ] ,其对输入特征图执行DWT分解,获得3个频域子带:Low–Low (${\mathrm{ LL}} $ ) 、Low–High ($ {\mathrm{LH }}$ ) 和High–Low ($ {\mathrm{HL}} $ ). 其中,$ {\mathrm{LL}} $ $ {\mathrm{LH}} $ ${\mathrm{ HL}} $
2
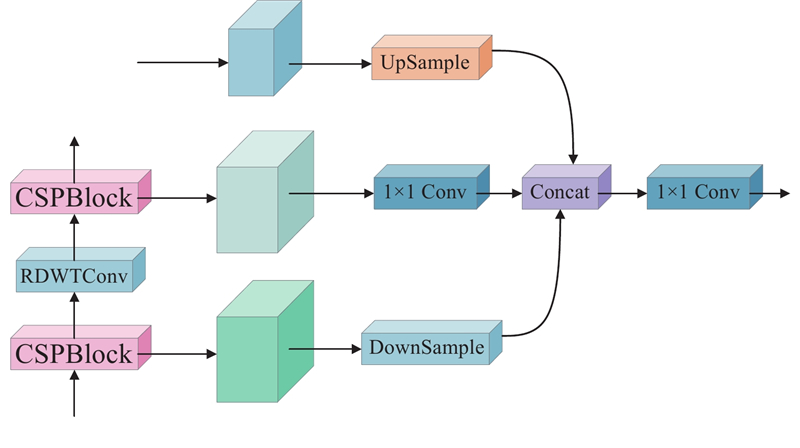
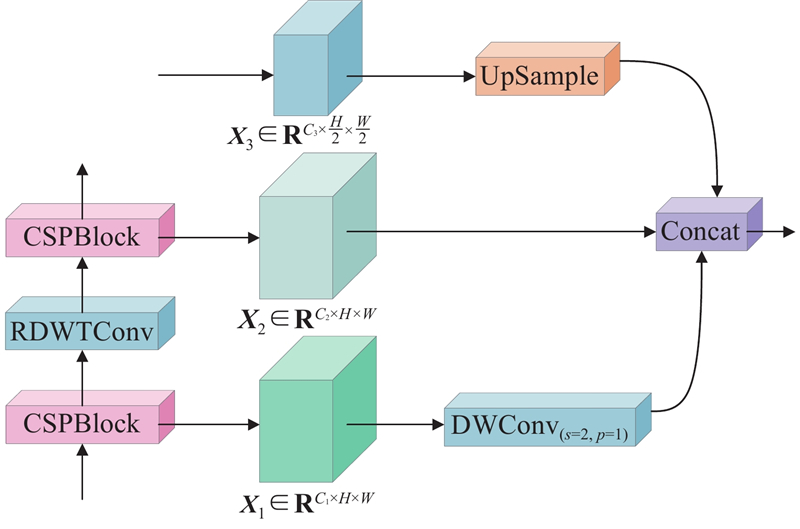
... 当前多尺度特征融合策略普遍通过上下采样实现高低层特征对齐与拼接,以增强特征表达的一致性与判别性. 如图5 所示为Birectional Concatenate (BiC) [17 ] 结构图,通过上下采样实现特征对齐后拼接融合,在一定程度上提升了空间一致性,但该结构在语义层次差异显著、尺度差异大的目标检测任务中适应性较差,易引发检测偏差. 如图6 所示为Sandwich-fusion (SF)[18 ] 结构图,在BiC基础上引入深度可分离卷积压缩浅层特征后与上采样的语义特征拼接融合,虽能缓解冗余计算问题,但仍难以针对不同语义层次间的差异性进行动态调节,复杂场景下多尺度目标检测的鲁棒性受限. ...
... Performance comparison of RCDFM (VisDrone Dataset)
Tab.2 Methods mAP@0.5/% mAP@0.5:0.95/% Params/106 GFLOPs/109 Concat 32.4 18.7 3.01 8.1 BiC[17 ] 33.1 19.2 3.05 8.4 SF[18 ] 32.8 19.0 3.02 8.3 RCDFM 34.3 19.9 3.07 8.4
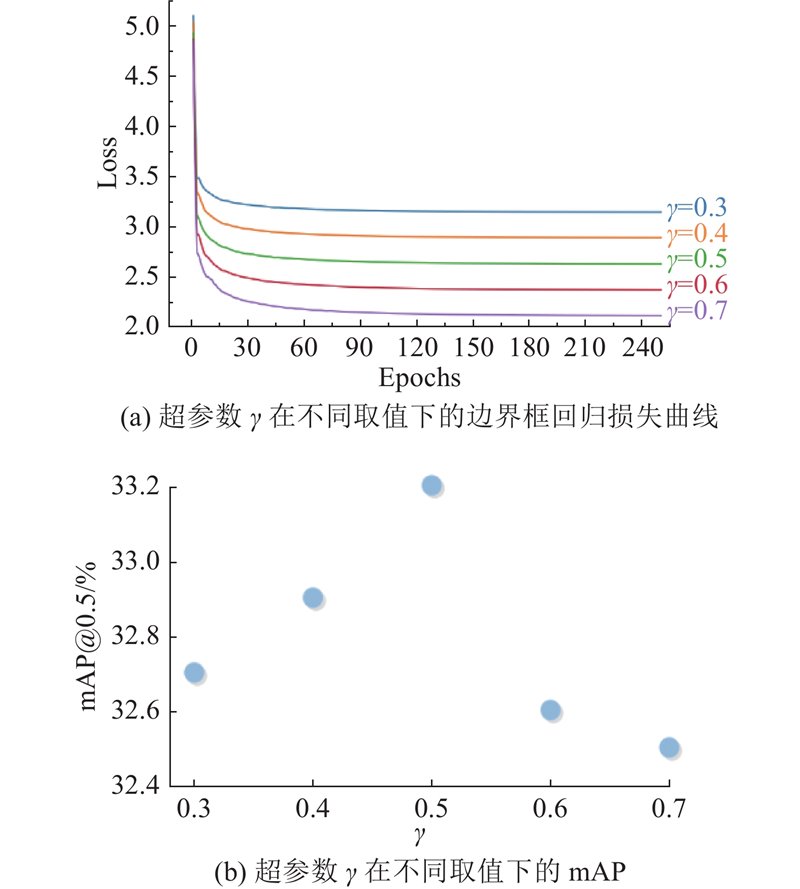
2.5. 边界框损失函数分析 如表3 所示比较了在YOLOv8n Head中引入不同边界框回归损失函数后的性能变化. 与基线CIoU相比,DIoU和SIoU的引入导致P 指标明显下降,表明模型控制误检的能力降低. 采用GIoU或EIoU,mAP@0.5与mAP@0.5:0.95略有提升,定位精度有所改善,但整体检测性能提升有限. 相比之下,使用提出的TSSIoU损失,P 、R 、mAP@0.5与mAP@0.5:0.95指标均取得最佳结果,表明该损失通过引入尺度和形状适应项,能够更准确地约束边界框几何关系,提升召回能力并有效控制误检,从而增强复杂环境下多尺度车辆检测的精度与鲁棒性. ...
Drone-YOLO: an efficient neural network method for target detection in drone images
3
2023
... 当前多尺度特征融合策略普遍通过上下采样实现高低层特征对齐与拼接,以增强特征表达的一致性与判别性. 如图5 所示为Birectional Concatenate (BiC) [17 ] 结构图,通过上下采样实现特征对齐后拼接融合,在一定程度上提升了空间一致性,但该结构在语义层次差异显著、尺度差异大的目标检测任务中适应性较差,易引发检测偏差. 如图6 所示为Sandwich-fusion (SF)[18 ] 结构图,在BiC基础上引入深度可分离卷积压缩浅层特征后与上采样的语义特征拼接融合,虽能缓解冗余计算问题,但仍难以针对不同语义层次间的差异性进行动态调节,复杂场景下多尺度目标检测的鲁棒性受限. ...
... Performance comparison of different downsampling modules (VisDrone Dataset)
Tab.1 Methods P /%R /%mAP@ mAP@ Params/6 GFLOPs/9 CBS 44.5 32.3 32.4 18.7 3.01 8.1 DWT 43.4 32.3 32.3 18.7 2.79 7.6 RDWTConv 45.1 33.2 33.7 19.6 3.18 8.5 ADown[23 ] 43.4 30.8 31.1 17.8 2.72 7.4 SCDown[24 ] 44.6 33.1 33.0 19.0 2.66 7.6 DWConv[25 ] 43.1 31.2 31.2 17.8 2.62 7.2 RepVGGBlock[18 ] 43.7 32.6 32.7 18.9 3.05 8.2
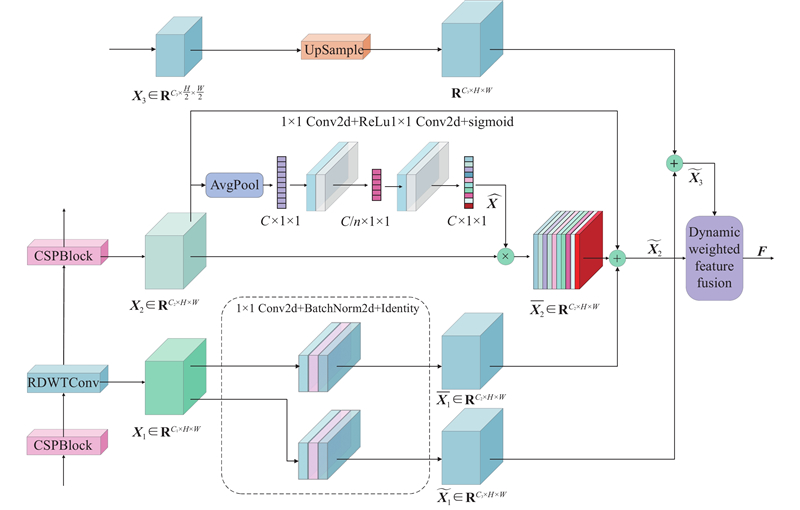
2.4. RCDFM模块性能分析 如表2 所示展示了在YOLOv8n的Neck中,使用BiC、SF和RCDFM替代原始Concat结构的检测性能. 三者均优于Concat,表明改进的特征融合机制可提升检测效果. 其中,RCDFM在仅增加0.6×106 参数量和0.3×109 计算量的条件下,使mAP@0.5和mAP@0.5:0.95分别提升1.9和1.2个百分点. 该结果表明,RCDFM能动态调节高层语义与浅层细节差异,提升在密集、遮挡和低光照等复杂背景下多尺度目标的检测精度,显著增强跨尺度信息交互的鲁棒性. ...
... Performance comparison of RCDFM (VisDrone Dataset)
Tab.2 Methods mAP@0.5/% mAP@0.5:0.95/% Params/106 GFLOPs/109 Concat 32.4 18.7 3.01 8.1 BiC[17 ] 33.1 19.2 3.05 8.4 SF[18 ] 32.8 19.0 3.02 8.3 RCDFM 34.3 19.9 3.07 8.4
2.5. 边界框损失函数分析 如表3 所示比较了在YOLOv8n Head中引入不同边界框回归损失函数后的性能变化. 与基线CIoU相比,DIoU和SIoU的引入导致P 指标明显下降,表明模型控制误检的能力降低. 采用GIoU或EIoU,mAP@0.5与mAP@0.5:0.95略有提升,定位精度有所改善,但整体检测性能提升有限. 相比之下,使用提出的TSSIoU损失,P 、R 、mAP@0.5与mAP@0.5:0.95指标均取得最佳结果,表明该损失通过引入尺度和形状适应项,能够更准确地约束边界框几何关系,提升召回能力并有效控制误检,从而增强复杂环境下多尺度车辆检测的精度与鲁棒性. ...
Focal and efficient IOU loss for accurate bounding box regression
1
2022
... YOLOv8的原始边界框损失函数为CIoU,其通过在IoU项外加入中心距离与长宽比惩罚来提升边界框回归精度,但其宽高约束以角度差形式呈现,在小目标或长宽比极端的情况下对实际几何差异不敏感,特别在复杂背景与遮挡场景中更易出现边缘模糊,导致梯度对尺度偏差响应较弱. EIoU[19 ] 在CIoU的基础上进一步将宽、高拆分并按外接框尺度归一化,使几何误差中心距、宽度差、高度差可独立回传梯度,从而缓解对小目标和长宽比失衡目标的收敛滞后. EIoU的表达式如下: ...
1
... 为了增强EIoU对多尺度目标的适应性,特别是在复杂背景、遮挡及视角变化显著的航拍场景下,提出TSSIoU损失函数. 该损失借鉴了Gaussian Wasserstein Distance (GWD)[20 ] 在旋转框检测中利用Wasserstein距离刻画几何尺度差异的思想,以充分发挥Wasserstein距离在度量边界框几何差异方面的优势. ...
1
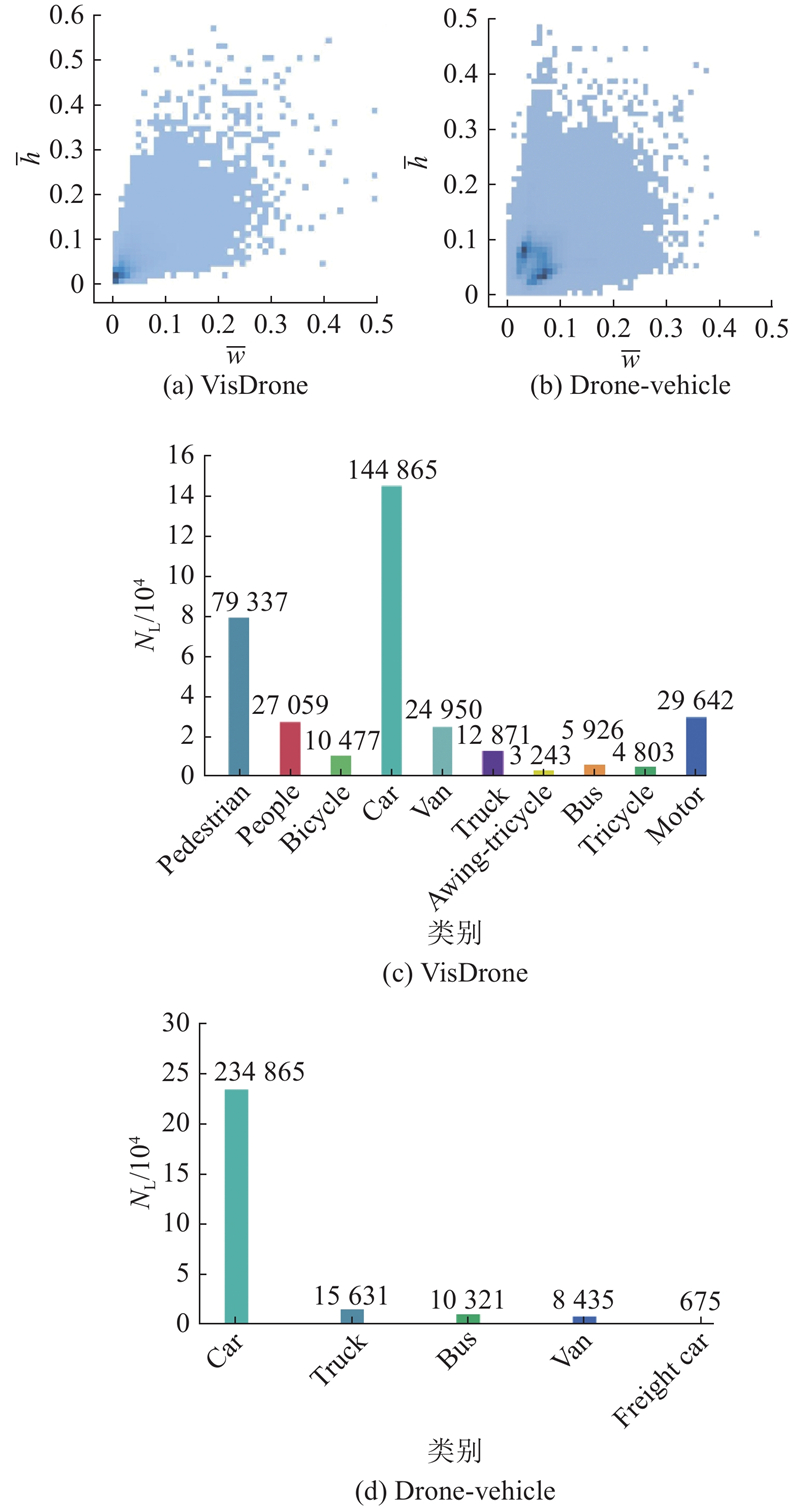
... 实验采用的大型公开数据集VisDrone[21 ] 和Drone-Vehicle[22 ] 均来源于真实无人机航拍场景,涵盖多种飞行高度与拍摄角度,包含遮挡、密集及夜间低光照等复杂场景,目标呈现明显的多尺度分布,且小尺度目标占比较高,充分体现了数据集的复杂性与多样性. Drone-Vehicle含训练集 17990 张、验证集 1465 张、测试集 8980 张图像. VisDrone则包含训练集 6 471张、验证集 548 张、测试集 1610 张图像. 整体数据规模充足,能有效支撑多场景、多尺度条件下的算法适应性与泛化性评估. ...
Drone-based RGB-infrared cross-modality vehicle detection via uncertainty-aware learning
1
2022
... 实验采用的大型公开数据集VisDrone[21 ] 和Drone-Vehicle[22 ] 均来源于真实无人机航拍场景,涵盖多种飞行高度与拍摄角度,包含遮挡、密集及夜间低光照等复杂场景,目标呈现明显的多尺度分布,且小尺度目标占比较高,充分体现了数据集的复杂性与多样性. Drone-Vehicle含训练集 17990 张、验证集 1465 张、测试集 8980 张图像. VisDrone则包含训练集 6 471张、验证集 548 张、测试集 1610 张图像. 整体数据规模充足,能有效支撑多场景、多尺度条件下的算法适应性与泛化性评估. ...
1
... Performance comparison of different downsampling modules (VisDrone Dataset)
Tab.1 Methods P /%R /%mAP@ mAP@ Params/6 GFLOPs/9 CBS 44.5 32.3 32.4 18.7 3.01 8.1 DWT 43.4 32.3 32.3 18.7 2.79 7.6 RDWTConv 45.1 33.2 33.7 19.6 3.18 8.5 ADown[23 ] 43.4 30.8 31.1 17.8 2.72 7.4 SCDown[24 ] 44.6 33.1 33.0 19.0 2.66 7.6 DWConv[25 ] 43.1 31.2 31.2 17.8 2.62 7.2 RepVGGBlock[18 ] 43.7 32.6 32.7 18.9 3.05 8.2
2.4. RCDFM模块性能分析 如表2 所示展示了在YOLOv8n的Neck中,使用BiC、SF和RCDFM替代原始Concat结构的检测性能. 三者均优于Concat,表明改进的特征融合机制可提升检测效果. 其中,RCDFM在仅增加0.6×106 参数量和0.3×109 计算量的条件下,使mAP@0.5和mAP@0.5:0.95分别提升1.9和1.2个百分点. 该结果表明,RCDFM能动态调节高层语义与浅层细节差异,提升在密集、遮挡和低光照等复杂背景下多尺度目标的检测精度,显著增强跨尺度信息交互的鲁棒性. ...
1
... Performance comparison of different downsampling modules (VisDrone Dataset)
Tab.1 Methods P /%R /%mAP@ mAP@ Params/6 GFLOPs/9 CBS 44.5 32.3 32.4 18.7 3.01 8.1 DWT 43.4 32.3 32.3 18.7 2.79 7.6 RDWTConv 45.1 33.2 33.7 19.6 3.18 8.5 ADown[23 ] 43.4 30.8 31.1 17.8 2.72 7.4 SCDown[24 ] 44.6 33.1 33.0 19.0 2.66 7.6 DWConv[25 ] 43.1 31.2 31.2 17.8 2.62 7.2 RepVGGBlock[18 ] 43.7 32.6 32.7 18.9 3.05 8.2
2.4. RCDFM模块性能分析 如表2 所示展示了在YOLOv8n的Neck中,使用BiC、SF和RCDFM替代原始Concat结构的检测性能. 三者均优于Concat,表明改进的特征融合机制可提升检测效果. 其中,RCDFM在仅增加0.6×106 参数量和0.3×109 计算量的条件下,使mAP@0.5和mAP@0.5:0.95分别提升1.9和1.2个百分点. 该结果表明,RCDFM能动态调节高层语义与浅层细节差异,提升在密集、遮挡和低光照等复杂背景下多尺度目标的检测精度,显著增强跨尺度信息交互的鲁棒性. ...
1
... Performance comparison of different downsampling modules (VisDrone Dataset)
Tab.1 Methods P /%R /%mAP@ mAP@ Params/6 GFLOPs/9 CBS 44.5 32.3 32.4 18.7 3.01 8.1 DWT 43.4 32.3 32.3 18.7 2.79 7.6 RDWTConv 45.1 33.2 33.7 19.6 3.18 8.5 ADown[23 ] 43.4 30.8 31.1 17.8 2.72 7.4 SCDown[24 ] 44.6 33.1 33.0 19.0 2.66 7.6 DWConv[25 ] 43.1 31.2 31.2 17.8 2.62 7.2 RepVGGBlock[18 ] 43.7 32.6 32.7 18.9 3.05 8.2
2.4. RCDFM模块性能分析 如表2 所示展示了在YOLOv8n的Neck中,使用BiC、SF和RCDFM替代原始Concat结构的检测性能. 三者均优于Concat,表明改进的特征融合机制可提升检测效果. 其中,RCDFM在仅增加0.6×106 参数量和0.3×109 计算量的条件下,使mAP@0.5和mAP@0.5:0.95分别提升1.9和1.2个百分点. 该结果表明,RCDFM能动态调节高层语义与浅层细节差异,提升在密集、遮挡和低光照等复杂背景下多尺度目标的检测精度,显著增强跨尺度信息交互的鲁棒性. ...
1
... Model generalization experiments (Drone-Vehicle Dataset)
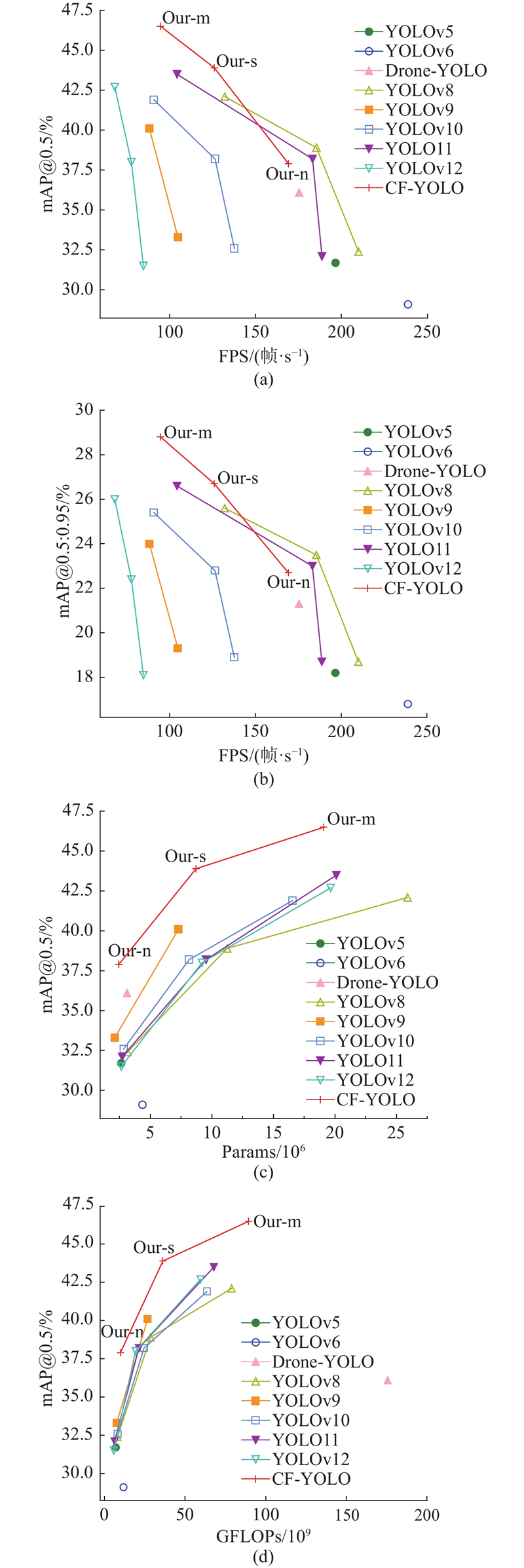
Tab.5 Models mAP@0.5/% mAP@0.5:0.95/% Params/106 FPS/(帧·s−1 ) Drone-YOLO 74.5 50.1 2.97 172.1 FBRT-YOLOn[26 ] 74.6 50.2 0.90 165.3 IV-YOLO[27 ] 74.9 49.6 4.31 184.7 YOLOv8n 75.7 50.5 3.01 205.4 YOLOv9t 77.2 52.2 1.97 103.2 YOLOv10n 76.2 50.6 2.70 136.8 YOLO11n 75.4 50.3 2.58 187.5 YOLO12n 76.3 51.4 2.51 75.9 CF-YOLOn 77.8 53.5 2.30 164.7
2.9. 可视化展示 如图11 所示展示了YOLOv8n与CF-YOLOn在不同场景下的检测可视化结果. 图11 (a)为密集遮挡场景,CF-YOLOn较YOLOv8n漏检更少,覆盖更多真实目标,整体检测精度更高. 图11 (b)为稀疏场景,CF-YOLOn在小目标检测上表现更优,漏检率更低,而YOLOv8n存在误检. 对于黑暗场景,图11 (c)中YOLOv8n未能检测到红色圆圈标注目标,图11 (d)中将高楼玻璃误判为车辆,显示其在低光照环境下检测精度下降. 相比之下,CF-YOLOn在该类场景中检测精度更高,误检与漏检更少. 此外,从图11 (a)、(b)的白天场景可见,CF-YOLO在处理与车辆外观相似的背景目标时仍存在一定误检,表明其在应对背景干扰方面的鲁棒性尚有待提升,这将是后续研究的重要方向. ...
IV-YOLO: a lightweight dual-branch object detection network
1
2024
... Model generalization experiments (Drone-Vehicle Dataset)
Tab.5 Models mAP@0.5/% mAP@0.5:0.95/% Params/106 FPS/(帧·s−1 ) Drone-YOLO 74.5 50.1 2.97 172.1 FBRT-YOLOn[26 ] 74.6 50.2 0.90 165.3 IV-YOLO[27 ] 74.9 49.6 4.31 184.7 YOLOv8n 75.7 50.5 3.01 205.4 YOLOv9t 77.2 52.2 1.97 103.2 YOLOv10n 76.2 50.6 2.70 136.8 YOLO11n 75.4 50.3 2.58 187.5 YOLO12n 76.3 51.4 2.51 75.9 CF-YOLOn 77.8 53.5 2.30 164.7
2.9. 可视化展示 如图11 所示展示了YOLOv8n与CF-YOLOn在不同场景下的检测可视化结果. 图11 (a)为密集遮挡场景,CF-YOLOn较YOLOv8n漏检更少,覆盖更多真实目标,整体检测精度更高. 图11 (b)为稀疏场景,CF-YOLOn在小目标检测上表现更优,漏检率更低,而YOLOv8n存在误检. 对于黑暗场景,图11 (c)中YOLOv8n未能检测到红色圆圈标注目标,图11 (d)中将高楼玻璃误判为车辆,显示其在低光照环境下检测精度下降. 相比之下,CF-YOLOn在该类场景中检测精度更高,误检与漏检更少. 此外,从图11 (a)、(b)的白天场景可见,CF-YOLO在处理与车辆外观相似的背景目标时仍存在一定误检,表明其在应对背景干扰方面的鲁棒性尚有待提升,这将是后续研究的重要方向. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}