

无人机(unmanned aerial vehicle, UAV)具有机动性强、灵活度高的特点,在城市空域中的应用日益广泛. 随着“低空经济”[1]的兴起,城市空中机动性和无人机交付系统更是成为热点,驱动了无人机自主导航技术的发展. 在城市高密度障碍和多移动目标的复杂环境中,如何保障无人机的自主安全高效导航成为核心挑战.
本文提出安全分层强化学习框架SHIELD,主要贡献如下. 1)构建4层递进式安全保障架构,包括强化学习决策层(全局规划)、专家指导层(局部优化)、安全保障层(“软硬”结合,提供刚性安全约束)和柔性优化层(长期策略优化),实现从策略学习到安全执行的全流程安全保障. 2)设计动态自适应奖励函数,根据环境复杂度和任务进度自适应调整权重,实现全局规划、安全避障和目标接近的智能切换. 3)在复杂动态环境中进行一系列对比实验,有效验证了所提框架的有效性和鲁棒性.
1. 问题建模与强化学习框架
在RL任务中,无人机被视为具有一定半径的圆形实体,可以在平面内以受限的线速度和角速度移动,并需要在避开所有障碍物和地图边界的前提下,以最短时间或最优路径到达目标点.
1.1. 无人机模型
主要研究四旋翼无人机,其状态在时间
式中:
控制输入为
此外,无人机运动受以下约束:
当无人机中心与障碍物、边界的距离小于无人机物理半径
1.2. 环境模型
环境建模是无人机路径规划与避障的重要基础. 如图1所示,构建的环境为100 m×100 m的二维矩形区域,采用笛卡尔坐标系. 起始点随机分布在地图左下角,初始速度和航向随机生成. 目标点为半径为
图 1
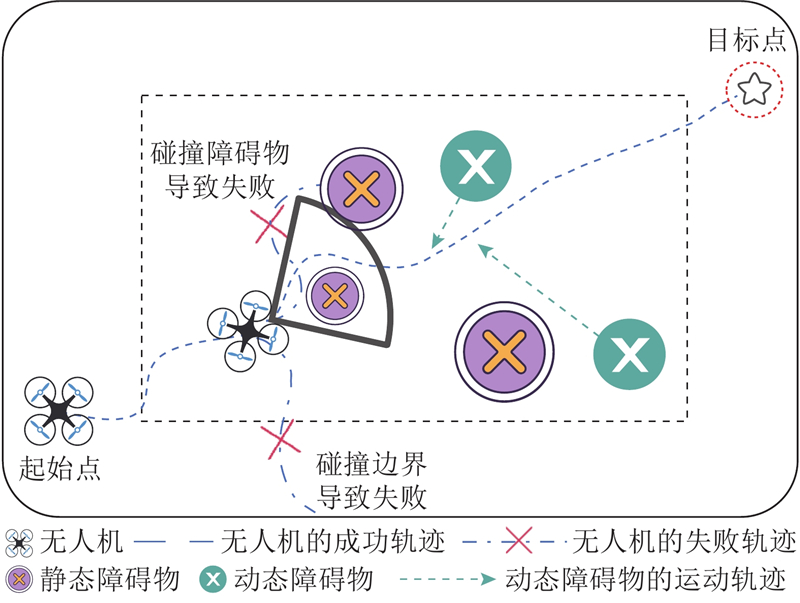
环境中设置静态和动态2类障碍物. 静态障碍物为固定圆形区域,半径在
为了模拟真实感知能力,设计局部感知系统. 1)感知距离受限,无人机仅能探测以自身当前位置为中心、半径为
1.3. 强化学习框架
强化学习框架包含观测空间、动作空间和多目标奖励函数3个核心组件.
1.3.1. 观测空间设计和动作空间定义
观测空间包括如下信息:1)自身状态(速度、航向角);2)目标信息(相对距离、方位角);3)静态障碍物信息(最近
强化学习策略采用连续动作空间,其输出被统一归一化到区间[−3,3]. 该归一化动作并不直接作为物理控制量,而是在环境交互过程中通过线性映射转换为实际控制输入:其中一维动作对应速度调节指令,用于生成每个时间步的速度增量,该增量按最大速度的一定比例进行缩放后与当前速度叠加,最终被限制在系统允许的速度上下界内;另一维动作对应角速度指令,经比例缩放后得到实际角速度,实际角速度被限制在预设的角速度上下界内.
1.3.2. 多目标奖励函数
设计多目标奖励函数,集成分层自适应的奖励塑形机制. 根据环境复杂度和任务进度自动调整权重,实现从宏观规划到微观避障的平滑过渡,在确保安全的同时优化导航效率. 该奖励函数包含以下5个主要类别.
1)目标导向奖励. 包括目标到达奖励和方向引导奖励.
a)目标到达奖励,当无人机到达目标时给予正奖励.
式中:
b)方向引导奖励,鼓励运动方向角
式中:
2)安全性奖励,包括碰撞惩罚和静态障碍、动态障碍避让奖励.
a)碰撞惩罚,碰撞施加负奖励.
式中:
b)静态障碍避让奖励,当无人机与最近障碍物的距离
式中:
c)动态障碍避让奖励,基于相对距离
式中:
3)路径优化奖励,包括路径偏差惩罚和速度激励奖励.
a)路径偏差惩罚,惩罚偏离最优直线路径的行为.
式中:
b)速度激励奖励,在安全前提下鼓励高速运动.
式中:
4)能耗与平滑性奖励. 包括能耗、时间惩罚.
a)能耗惩罚,惩罚速度和航向的剧烈变化.
式中:
b)时间惩罚,每步给予负奖励,鼓励快速到达.
式中:
5)智能决策协调奖励,旨在促进RL与DWA、人工势场法与控制屏障函数(artificial potential field and control barrier function, APF-CBF)模块的协作. 系统根据当前环境的威胁等级(基于障碍物距离、相对速度和预测碰撞时间)和障碍物密度等级(基于视场内障碍物数量和面积占比),动态调整对不同模块建议的信任度. 威胁等级和障碍物密度等级都分为4个等级. 如表1所示,不同等级对应不同的权重系数
表 1 不同等级下的威胁权重、障碍物密度权重
Tab.1
| 等级 | |||||
| DWA | CBF | DWA | CBF | ||
| high | 2.0 | 2.5 | 1.5 | 1.8 | |
| medium | 1.5 | 1.8 | 1.0 | 1.0 | |
| low | 1.0 | 1.2 | 0.7 | 0.9 | |
| none | 0.5 | 0.8 | 0.5 | 0.7 | |
通过动态调整权重,使智能体能够根据当前环境的威胁水平和复杂程度,通过奖励函数,合理分配对DWA和APF-CBF模块建议的信任度.
1)DWA对齐奖励,鼓励遵循DWA避障建议.
式中:
式中:
2)APF-CBF对齐奖励,鼓励遵循APF-CBF模块安全速度建议.
式中:
当APF-CBF模块建议调整方向时,
1.3.3. 自适应奖励塑形机制
基于环境复杂度和任务进度实现分层自适应的奖励塑形机制,分为以下3层. 1)全局规划层:当障碍较少且距离目标较远时,侧重长期路径规划. 2)安全避障层:当障碍密度高时,优先考虑安全. 3)目标接近层:当障碍较少且距离目标较近时,专注精确到达. 为了实现层级间的自适应切换,根据障碍物密度等级及无人机当前到目标的距离
1)当障碍物密度等级为low或none时,
式中:
2)当障碍物密度等级为high时,无论距离远近,均切换到安全避障层.
3)当障碍物密度等级为medium时,
式中:
针对上述分层,设计如表2所示的差异化的奖励权重配置. 基于“分层专业化”原则,全局规划层(Global)侧重效率,安全避障层(Safety)强化安全保障,目标接近层(Approach)平衡精度与能耗.
表 2 自适应奖励塑形下的权重分配
Tab.2
| 奖励组件 | Global | Safety | Approach |
| Goal | 1.0 | 1.0 | 1.0 |
| Direction | 1.8 | 0.8 | 2.2 |
| Collision | 1.0 | 1.0 | 1.0 |
| Boundary | 1.0 | 1.0 | 1.0 |
| Static | 0.5 | 1.8 | 1.2 |
| Dynamic | 0.6 | 2.2 | 1.0 |
| Deviation | 0.7 | 1.5 | 0.8 |
| Speed | 2.5 | 0.6 | 0.9 |
| Energy | 0.4 | 1.4 | 1.6 |
| Time | 0.6 | 1.2 | 1.6 |
| DWA | 0.6 | 2.8 | 1.8 |
| CBF | 0.8 | 2.0 | 1.6 |
通过智能化的权重动态调整,为无人机自主导航提供兼具灵活性与鲁棒性的解决方案. 在仿真过程中,这些权重与基础奖励函数进行加权融合,实现动态的行为调节.
1.3.4. 总体奖励函数
综合各奖励分项和自适应权重,构建总体奖励函数如下:
式中:
该多目标奖励函数实现了目标导向、安全性、路径优化、运动平滑性和智能决策协调的全面整合.
2. SHIELD算法框架设计
2.1. SHIELD安全分层强化学习架构
2.1.1. 整体架构设计
构建多层次智能安全导航架构,采用“分层决策+实时反馈+长期优化”的设计理念,通过动作传递和奖励反馈形成闭环控制,将强化学习的全局决策能力与专家系统的局部优化和安全保障能力有机结合. 整体架构如图2所示.
图 2
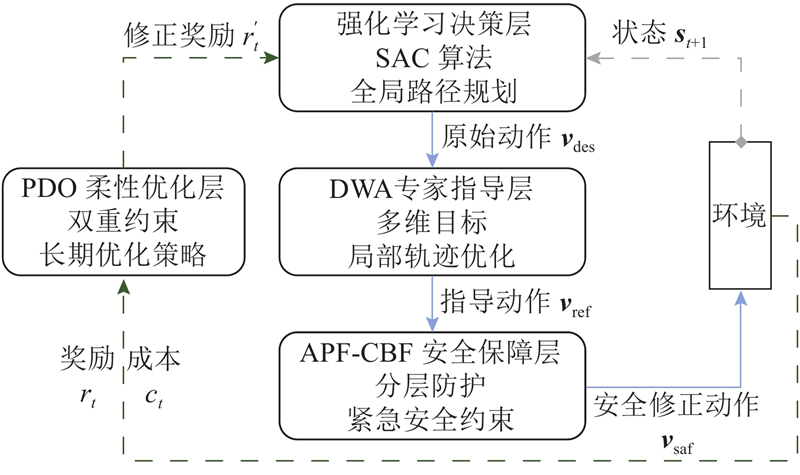
该架构包含以下4个核心层级. 1)强化学习决策层,基于SAC(soft actor-critic)算法,负责全局路径规划和高层决策制定. 2)DWA专家指导层,处理动态威胁的预测性规避和局部轨迹优化. 3)APF-CBF安全保障层,提供紧急安全约束. 4)原始-对偶优化(primal-dual optimization, PDO)柔性优化层,通过长期约束优化策略. 这种多维度协同机制使系统从传统的被动安全响应模式转变为主动安全预防模式,在确保高安全性的基础上,显著提升了导航效率和智能化水平.
2.1.2. 分层协同控制流程
系统通过以下6个步骤实现分层协同控制的完整执行过程. 1)强化学习原始决策. 输入当前环境状态观测,输出原始动作指令,并转换为期望速度
2.2. 强化学习决策层
强化学习决策层作为架构的核心决策单元,采用SAC算法. 该算法通过熵正则化实现探索与利用的平衡,采用双评论家网络应对Q值过估计的问题,并支持连续动作空间[14].
2.2.1. 网络架构与参数设置
SAC采用演员-评论家结构. 1)策略网络采用3层全连接层(每层256个神经元,ReLU激活),输出动作均值和方差. 2)评论家网络采用相同的结构,输出Q值估计. 训练采用Adam优化器,主要超参数的设置如表3所示.
表 3 SAC算法的主要超参数
Tab.3
| 超参数 | 数值 | 超参数 | 数值 | |
| 折扣因子 | 0.99 | 经验回放缓冲区大小 | 100 000 | |
| 学习率 | 0.000 5 | 批次大小 | 256 | |
| 软更新系数 | 0.01 | 总训练步数 | 100 000 |
2.2.2. 改进的训练策略
为了提高训练效率和稳定性,提出以下改进. 1)基于连续成功阈值的伪随机训练机制. 仅当智能体在当前环境下连续成功一定次数后才重新生成环境,提高样本利用效率并避免频繁环境切换导致的学习不稳定问题. 2)基于最近表现的动态阈值调整机制. 成功率小于30%时降低阈值以增大环境变化频率,成功率大于80%时提高阈值以增强训练稳定性. 3)障碍物配置随机化. 当需要重新生成环境时有小概率生成为不同障碍物配置的组合,避免过拟合. 4)学习率衰减机制. 初期使用较大的学习率以加速收敛,后期减小学习率以实现精细调优.
2.3. DWA专家指导层
构建动态窗口专家指导模块,在传统的DWA[15]基础上进行改进,实现与RL的协同融合.
2.3.1. 智能化改进策略
提出以下2个智能化优化机制.
1)自适应激活. 持续激活会导致不必要的计算开销并干扰强化学习策略. 提出仅在威胁条件满足时激活:在动态障碍情况下,当相对距离小于
2)多维度目标函数. 针对传统DWA静态权重和轨迹质量不足的问题,构建五维综合评估体系:
式中:
五维代价函数的具体计算如下:
式中:
2.3.2. RL协同机制
为了充分发挥DWA的局部规划优势和RL的全局学习能力,设计双重引导策略,实现DWA和RL的深度协同.
1)速度指导融合. 提出基于环境状态、威胁权重
式中:
在每个决策周期内,RL决策层根据当前状态输出连续动作,并映射得到原始期望速度
系统能够在复杂环境中智能切换控制策略:在障碍密集区域更多依赖DWA的局部避障能力,在开阔区域更多发挥RL的全局优化优势.
2)奖励函数引导. 在RL奖励函数中引入DWA行为对齐项(式(14)),促进智能体学习协同策略.
该模块通过智能激活、多维目标优化和双重引导这三重改进,在保持RL全局优化能力的同时,充分利用DWA在局部动态避障方面的优势,在复杂动态环境下高效安全导航.
构建多层次安全保护模块,融合改进的APF和CBF,为智能体提供分层安全保障机制.
与传统的APF[16]不同,本算法直接在速度空间操作,基于几何关系和动力学约束生成安全速度,主要包含以下3种力的设计.
1)目标导向力. 引导无人机朝目标移动,
2)分离式避障力. 为了解决局部最小值问题[17],将避障力分解为径向排斥力和切向引导力:
式中:
3)边界约束力. 为了避免强化学习初期的“乱飞”现象,提高训练效率,设计边界约束力:
式中:
通过多力合成,最终的避障调整方向为
最终的速度合成方向为
式中:
引入时序平滑机制避免速度突变:
式中:
采用离散时间CBF约束[18],设计包含障碍物屏障函数、边界屏障函数和自适应参数调节机制的优化CBF框架.
1)屏障函数设计. 定义障碍物屏障函数:
式中:
为了防止无人机越界,设计四边界约束:
相应的边界CBF约束为
2)安全性分析. 为了确保该模块在实际应用中的可靠性,从理论角度对算法的安全性进行严格分析.
定理1:离散时间CBF安全性. 考虑离散时间系统状态(式(2))和障碍物屏障函数
则对所有
证明:数学归纳法.
基础步骤:由假设可知,
归纳假设:假设在时刻
归纳步骤:须证明
由离散时间CBF约束(式(35)),可得
由
当
这表明离散步长
采用“分层架构+分级备份”的双重设计理念. 与传统方法不同,本模块将APF重新定位为CBF约束求解的智能初值生成器,为CBF优化提供安全且目标导向的候选解.
1)分层架构. 第1层:APF导航层,对输入的速度进行初次安全性验证,输出具有物理直觉的安全方向,为CBF二次规划提供高质量初值
2)分级备份. 当优化求解失败时,按优先级提供备用策略. 优先级1(智能切向绕行):基于障碍物几何关系生成2个正交切线方向的候选速度,选择与目标方向对齐度更高且更安全的最优切线方向. 对每个最优切向方向,生成多尺度候选速度,优先选择速度更大且满足约束的最优候选速度. 优先级2(保持方向、速度缩放):保持APF推荐的运动方向,逐步降低速度幅值,选择满足CBF约束的最大速度. 优先级3(卡死检测与逃逸机制):引入卡死检测与逃逸机制,通过最近时间窗口内的平均速度vrec 和位置变化Δq双重指标检测卡死状态:当平均速度低于速度阈值vstk且位置变化量小于位置阈值dstk时,判定无人机陷入卡死状态。
检测到卡死状态后触发逃逸机制,在8个均匀分布的方向上采样生成逃逸候选速度,选择满足CBF约束且违反度最小的方向. 优先级4(紧急停止):当所有备用策略均失败时,执行紧急停止策略.
3)RL协同策略. 与DWA模块类似,RL协同策略是促进RL智能体学习与安全保护层协调的策略,在奖励函数中引入CBF对齐项(式(16)).
图 3
记无人机在时刻
约束条件为
式中:
根据原始-对偶优化理论,最优解可由以下原始问题与对偶问题刻画:1)原始问题
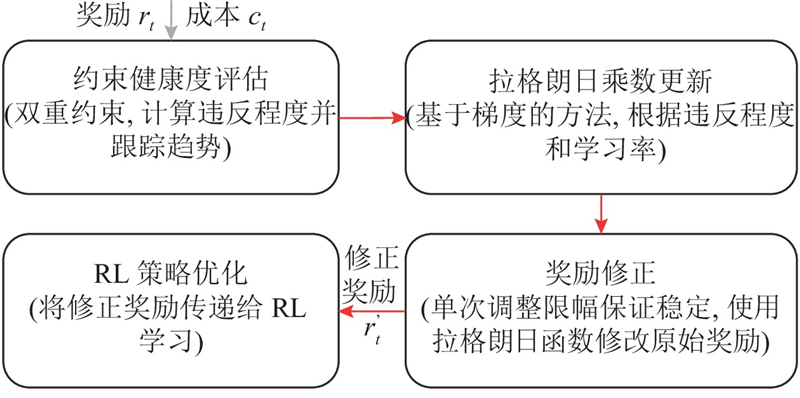
为了精确地量化约束违规程度,引入约束健康度概念(值域为[0.05, 1],值越小表示违规越严重). 累积约束健康度基于最近
式中:
由式(46)可知,健康度函数随着违规率、平均违规程度和最大违规程度的增大而单调递减,即违规越严重,健康度越低. 单步约束健康度的计算类似,即关注最近
1)拉格朗日乘数更新机制. 采用带动量的自适应梯度上升法更新拉格朗日乘数:
式中:clip为裁剪函数;
式中:
2)奖励修正机制. 基于拉格朗日函数的框架,将惩罚项转化为对原始奖励的动态调整:
式中:
采用连续梯度成本函数,确保处处可微.
1)静态障碍物成本
2)动态障碍物成本
3)总成本函数. 总成本函数定义为各障碍物成本分量的和:
3. 仿真实验
3.1. 实验平台与环境设置
仿真实验的实现基于Python 3.11.4和PyTorch 2.7.0. 硬件为AMD Ryzen 9 9900X CPU@4.4 GHz、32 GB RAM和NVIDIA GeForce GTX
实验环境基于Gymnasium构建,为100 m×100 m的二维矩形空间;无人机质心进入目标区域视为任务成功,若发生碰撞或超时,则判定为失败. 强化学习实验在包含10个静态障碍和4个动态障碍的场景下进行,总训练步数为1×
表 4 仿真实验中的主要控制参数与环境参数
Tab.4
| 参数 | 数值 | 参数 | 数值 | 参数 | 数值 | 参数 | 数值 | |||
| 1.0 | 2 | 0.5 | 0.3 | |||||||
| 3.0 | 200 | 0.1 | 0.3 | |||||||
| 2 | 1.8 | 70 | 0.8 | |||||||
| 6 | 20 | 25 | 0.8 | |||||||
| 10 | 20 | 0.8 | 0.3 | |||||||
| 5.0 | 1.0 | 1.2 | 2 | |||||||
| 2.0 | 0.15 | 15 | ||||||||
| 1.0 | 1.5 | 0.02 | 0.008 | |||||||
| 2.5 | 1.2 | 0.6 | 0.01 | |||||||
| 120 | 1.8 | 20 | 0.85 | |||||||
| 8 | 0.3 | 0.3 | 20 | |||||||
| 6 | 1.5 | 6 | 3 |
3.2. 实验结果与分析
3.2.1. 基础性能测试
主要的评价指标为任务成功率和路径效率(路径效率指起始点到目标点的直线距离与实际路径长度的比值,接近1表明路线接近最优).
如图4所示为训练过程中回合累积奖励的原始数据(细实线)和经指数移动平均处理后的平滑曲线(粗实线). 其中,Ep为训练轮次,R为奖励值. 在初始阶段,奖励值迅速上升,表明智能体快速学习到基本避障策略. 约500个回合后,平滑曲线整体上趋于收敛.
图 4
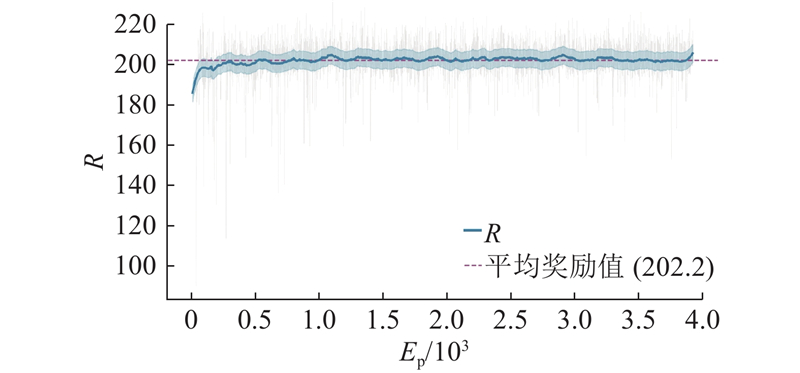
图 5
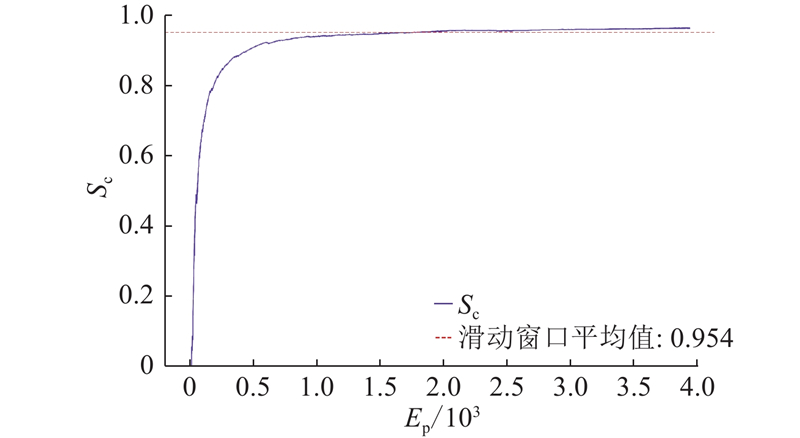
图 6
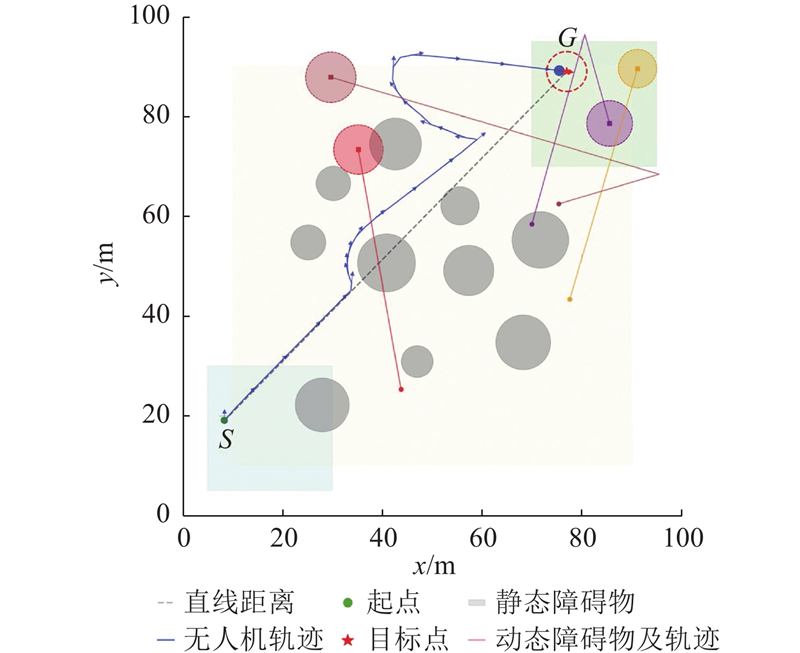
测试结果显示,提出的算法框架在复杂动态环境中的平均成功率达到95.7%,路径效率达到0.962,验证了算法的有效性和可行性.
3.2.2. 对比实验
为了进一步验证所提算法在复杂动态环境下的优越性,将该算法与APF、RRT、DWA 3种传统算法进行对比,仿真结果如表5所示. 其中,E为路径效率.
表 5 所提算法与传统算法在成功率和路径效率上的对比
Tab.5
| 算法 | Sc/% | E |
| APF | 51.6 | 0.738 |
| RRT | 62.8 | 0.665 |
| DWA | 75.4 | 0.716 |
| 所提算法 | 95.7 | 0.962 |
从表5可知,采用所提算法取得的任务成功率显著高于传统算法,较APF提升85.5%,较RRT提升52.4%,较DWA提升26.9%. 路径效率同样领先:较APF提升30.4%,较RRT提升44.7%,较DWA提升33.0%,表明路径更接近最优直线. 这些优势源于所提算法的自适应学习能力,能够从经验中优化策略,而传统算法依赖固定规则,在复杂环境中易失效.
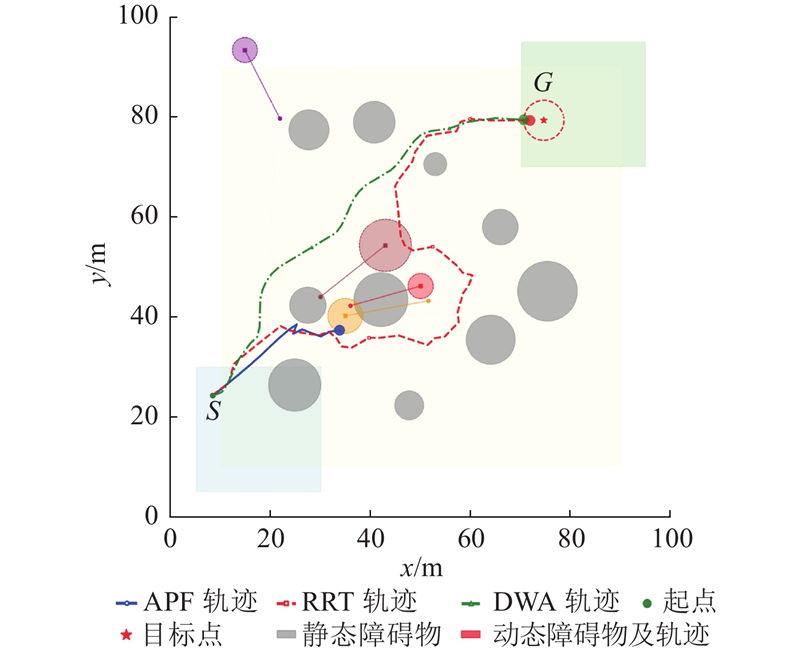
如图7所示为传统算法在复杂动态环境下的典型路径. APF的路径用实线表示,在x = 30 m,y = 35 m附近陷入局部极小值,显著抖动后碰撞障碍物失败. RRT的路径用虚线表示,可见其路径不光滑,特别是在x = 60 m,y = 45 m附近绕行过度,导致路径冗长. DWA的路径用点划线表示,可见其中段路径呈波浪形抖动. 相比之下,利用所提算法生成近直线路径,避免了上述典型问题.
图 7
3.2.3. 消融实验
为了理解所提算法框架各模块的贡献并验证设计的合理性和模块间的协同性,通过消融实验系统性地移除关键模块,分析各模块对整体性能的影响. 除成功率和路径效率2项指标外,引入平均转角和平均决策时间(本文中特指算法推演时间)2项指标,评估算法的轨迹平滑性与实时性能. 实验包括基线实验(0号)、单模块实验(1~3号)、双模块组合实验(4~6号)及完整框架(7号),实验结果如表6所示. 其中,
表 6 消融实验中的成功率、路径效率、平均转角和平均决策时间的对比
Tab.6
| 序号 | +DWA | +CBF | +PDO | Sc/% | E | ||
| 0 | — | — | — | 64.3 | 0.739 | 21.41 | 1.87 |
| 1 | √ | — | — | 78.8 | 0.779 | 9.99 | 2.41 |
| 2 | — | √ | — | 85.6 | 0.893 | 17.72 | 2.03 |
| 3 | — | — | √ | 75.2 | 0.752 | 13.75 | 1.88 |
| 4 | √ | √ | — | 90.3 | 0.922 | 12.70 | 2.54 |
| 5 | √ | — | √ | 83.4 | 0.807 | 8.93 | 2.43 |
| 6 | — | √ | √ | 89.9 | 0.908 | 14.82 | 2.11 |
| 7 | √ | √ | √ | 95.7 | 0.962 | 9.41 | 2.57 |
对比基线实验(0号)与完整框架(7号)可知,成功率从64.3%提升至95.7%(提升48.8%),路径效率从0.739提升至0.962(提升30.2%),平均转角从21.41°减小至9.41°(降幅为56.0%),决策时间从1.87 ms增至2.57 ms(增幅为37.4%). 完整框架在适度增加计算时间的前提下,实现了安全性、效率性和平滑性的全面优化.
单模块实验(1~3号)证明了各模块的有效性,双模块组合实验(4~6号)展示了模块间的协同效应,完整框架的性能优于任何双模块组合,表明3个模块的协同作用不是简单的线性叠加,而是通过“局部平滑—即时安全—全局优化”形成立体化协同机制.
在决策时间方面,DWA的引入使决策时间增加28.9%,这是由于动态窗口法需要实时评估多条候选轨迹. APF-CBF的计算开销较小,仅增加8.6%,这得益于APF初值生成的高效性. PDO对实时决策几乎无影响. 完整框架的决策时间为2.57 ms,满足实时性的要求. 在平均转角方面,DWA使转角减小53.4%,提升了轨迹平滑性. 由于安全保障导致的路径保守,APF-CBF使转角增加至17.72°. PDO通过优化决策减少了不必要的转向,转角减小了35.8%. 完整框架的协同将平均转角优化至9.41°(减小了56.0%),生成了更适合无人机执行的路径.
3.2.4. 鲁棒性验证
通过改变障碍物复杂度(即静态和动态障碍的数量配置),验证算法的鲁棒性. 基线配置为10静态+4动态障碍,逐步增至15静态+6动态,仿真结果如表7所示.
表 7 不同障碍物配置下的成功率和路径效率对比
Tab.7
| 障碍物数量配置(静+动) | Sc/% | E |
| 10+4 | 95.7 | 0.962 |
| 12+5 | 92.3 | 0.931 |
| 15+6 | 89.6 | 0.908 |
从表7可知,随着障碍复杂度的增加,成功率从95.7%降至89.6%,路径效率从0.962降至0.908,最高复杂度下的成功率仅降低6.1%,突显3个模块的协同缓冲作用.
3.2.5. 真实干扰实验
为了验证SHIELD算法的工程适用性,在仿真环境中引入以下3类典型真实干扰. 1)阵风干扰,采用“恒定基础风+周期性阵风”组合模型,风速为0~2.0 m/s. 2)激光雷达测距噪声,对视场内所有障碍物的距离观测添加零均值高斯白噪声(
分别在无干扰、单干扰、多干扰的情况下测试,并在多干扰条件下与传统算法进行对比. 如表8所示,SHIELD算法的抗干扰特征明显:雷达噪声和GPS误差的影响轻微,阵风干扰导致成功率显著降至81.6%,表明动力学层面的扰动是主要挑战. 在多干扰条件下,决策时间仅从2.57 ms增至2.86 ms(增幅为11.3%),表明计算开销的增长可控. 虽然传统算法的决策时间更短,但成功率远低于SHIELD,证明了所提算法的工程价值.
表 8 不同干扰下的成功率、路径效率和平均决策时间对比
Tab.8
| 算法与条件 | Sc/% | E | |
| 无干扰 | 95.7 | 0.962 | 2.57 |
| 单阵风干扰 | 81.6 | 0.863 | 2.61 |
| 单雷达噪声 | 95.3 | 0.962 | 2.57 |
| 单GPS误差 | 95.6 | 0.961 | 2.57 |
| 多干扰APF | 31.8 | 0.593 | 1.06 |
| 多干扰RRT | 38.7 | 0.512 | 2.07 |
| 多干扰DWA | 55.3 | 0.638 | 2.49 |
| 多干扰,本文方法 | 81.4 | 0.861 | 2.86 |
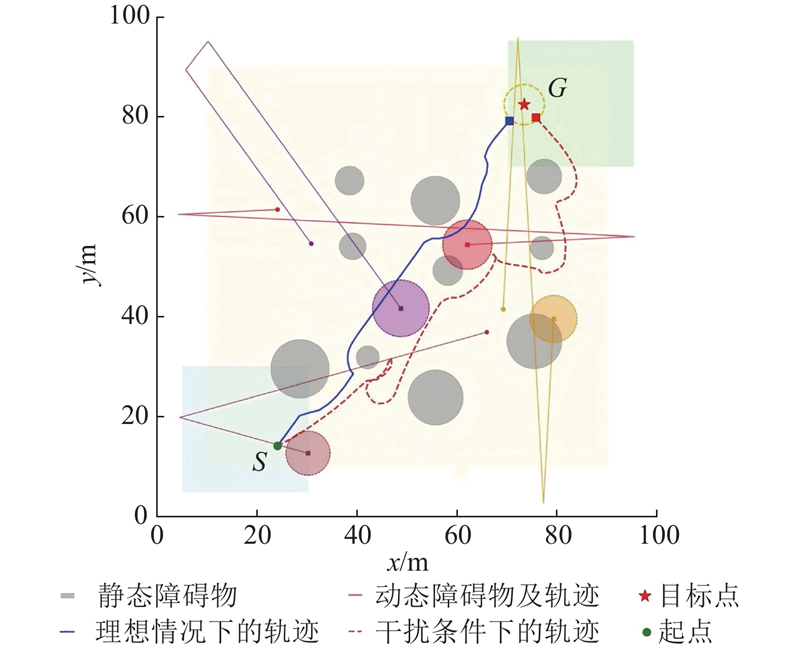
如图8所示为SHIELD在无干扰(实线)和多干扰(虚线)条件下的轨迹对比. 经测试可知,多干扰条件下的轨迹相对于无干扰轨迹平均偏移8.636 m,约为地图尺寸的8.6%,偏移量较小,验证了算法的鲁棒性.
图 8
通过真实干扰实验,验证了SHIELD算法的工程可靠性,与传统算法相比,该算法在鲁棒性上展现出了显著优势,为实际无人机的部署提供了重要参考.
4. 结 语
提出SHIELD安全分层集成强化学习框架,有效解决了无人机在复杂动态环境中的导航和避障问题. 构建4层递进式安全保障架构:强化学习决策层负责全局路径规划,专家指导层优化局部路径,安全保障层“软硬”结合提供紧急安全约束,柔性优化层优化长期策略.
仿真结果表明,SHIELD算法框架在任务成功率和路径效率方面相对于传统算法均有大幅的提升,在不同环境复杂度及真实干扰条件下均表现稳定,展现出良好的泛化能力和鲁棒性. 虽然多层架构增加了计算负担,但性能提升显著,这是可接受的.
现有研究仅考虑单机导航场景,未来研究将把SHIELD框架扩展至多智能体强化学习框架,实现多架无人机在共享低空空域中的冲突避免与任务协同. 现有研究仅采用二维平面模型进行验证,未来将针对真实的飞行场景,将算法扩展至3D空间,设计相应的屏障函数约束和奖励塑形机制.
参考文献
UAV localization method with keypoints on the edges of semantic objects for low-altitude economy
[J].DOI:10.3390/drones9010014 [本文引用: 1]
MOD-RRT*: a sampling-based algorithm for robot path planning in dynamic environment
[J].DOI:10.1109/TIE.2020.2998740 [本文引用: 1]
Optimization of dynamic obstacle avoidance path of multirotor UAV based on ant colony algorithm
[J].
Optimal cooperative path planning of unmanned aerial vehicles by a parallel genetic algorithm
[J].DOI:10.1017/S0263574714001878 [本文引用: 1]
A novel hybrid particle swarm optimization algorithm for path planning of UAVs
[J].DOI:10.1109/JIOT.2022.3182798 [本文引用: 1]
Drone deep reinforcement learning: a review
[J].DOI:10.3390/electronics10090999 [本文引用: 1]
Dispatch of UAVs for urban vehicular networks: a deep reinforcement learning approach
[J].DOI:10.1109/TVT.2021.3119070 [本文引用: 1]
Q-learning-based unmanned aerial vehicle path planning with dynamic obstacle avoidance
[J].DOI:10.1016/j.asoc.2023.110773 [本文引用: 1]
Quality-oriented hybrid path planning based on A* and Q-learning for unmanned aerial vehicle
[J].DOI:10.1109/access.2021.3139534 [本文引用: 1]
Preventing undesirable behavior of intelligent machines
[J].DOI:10.1126/science.aag3311 [本文引用: 1]
A new method for unmanned aerial vehicle path planning in complex environments
[J].DOI:10.1038/s41598-024-60051-4 [本文引用: 1]
Dynamic path planning of UAV with least inflection point based on adaptive neighborhood A* algorithm and multi-strategy fusion
[J].DOI:10.1038/s41598-025-92406-w [本文引用: 1]
The dynamic window approach to collision avoidance
[J].DOI:10.1109/100.580977 [本文引用: 1]
On the implementation of a primal-dual interior point method
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}