[1]
LI Z, PENG X B, ABBEEL P, et al Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control
[J]. The International Journal of Robotics Research , 2025 , 44 (5 ): 840 - 888
DOI:10.1177/02783649241285161
[本文引用: 1]
[2]
RAIBERT M H, BROWN H B Jr, CHEPPONIS M Experiments in balance with a 3D one-legged hopping machine
[J]. The International Journal of Robotics Research , 1984 , 3 (2 ): 75 - 92
DOI:10.1177/027836498400300207
[3]
CASTILLO G A, WENG B, ZHANG W, et al Reinforcement learning-based cascade motion policy design for robust 3D bipedal locomotion
[J]. IEEE Access , 2022 , 10 : 20135 - 20148
DOI:10.1109/ACCESS.2022.3151771
[本文引用: 1]
[4]
GULIYEV Z, PARSAYAN A. Reinforcement learning based robot control [C]// Proceedings of the IEEE 16th International Conference on Application of Information and Communication Technologies . Washington DC: IEEE, 2023: 1–6.
[本文引用: 1]
[5]
WANG S, BRAAKSMA J, BABUSKA R, et al. Reinforcement learning control for biped robot walking on uneven surfaces [C]// Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings . Vancouver: IEEE, 2006: 4173–4178.
[本文引用: 1]
[6]
SHAO Y, JIN Y, HUANG Z, et al A learning-based control pipeline for generic motor skills for quadruped robots
[J]. Journal of Zhejiang University: Science A , 2024 , 25 (6 ): 443 - 454
DOI:10.1631/jzus.A2300128
[本文引用: 1]
[7]
JIN Y, LIU X, SHAO Y, et al High-speed quadrupedal locomotion by imitation-relaxation reinforcement learning
[J]. Nature Machine Intelligence , 2022 , 4 (12 ): 1198 - 1208
DOI:10.1038/s42256-022-00576-3
[8]
KIM J W, ZHAO T Z, SCHMIDGALL S, et al. Surgical robot transformer (SRT): imitation learning for surgical tasks [EB/OL]. (2024−07−17)[2025−06−11]. https://arxiv.org/pdf/2407.12998.
[9]
VINYALS O, BABUSCHKIN I, CZARNECKI W M, et al Grandmaster level in StarCraft II using multi-agent reinforcement learning
[J]. Nature , 2019 , 575 (7782 ): 350 - 354
DOI:10.1038/s41586-019-1724-z
[本文引用: 1]
[10]
丁加涛, 何杰, 李林芷, 等 基于模型预测控制的仿人机器人实时步态优化
[J]. 浙江大学学报: 工学版 , 2019 , 53 (10 ): 1843 - 1851
[本文引用: 1]
DING Jiatao, HE Jie, LI Linzhi, et al Real-time walking pattern optimization for humanoid robot based on model predictive control
[J]. Journal of Zhejiang University: Engineering Science , 2019 , 53 (10 ): 1843 - 1851
[本文引用: 1]
[11]
秦海鹏, 秦瑞, 施晓芬, 等 基于模型预测的四足机器人运动控制
[J]. 浙江大学学报: 工学版 , 2024 , 58 (8 ): 1565 - 1576
[本文引用: 1]
QIN Haipeng, QIN Rui, SHI Xiaofen, et al Motion control of quadruped robot based on model prediction
[J]. Journal of Zhejiang University: Engineering Science , 2024 , 58 (8 ): 1565 - 1576
[本文引用: 1]
[12]
AHN K, MHAMMEDI Z, MANIA H, et al. Model predictive control via on-policy imitation learning [EB/OL]. (2022−10−17)[2025−06−11]. https://arxiv.org/pdf/2210.09206.
[本文引用: 1]
[13]
TAGLIABUE A, HOW J P. Output feedback tube MPC-guided data augmentation for robust, efficient sensorimotor policy learning [C]// Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems . Kyoto: IEEE, 2022: 8644−8651.
[本文引用: 1]
[14]
DUAN H, DAO J, GREEN K, et al. Learning task space actions for bipedal locomotion [C]// Proceedings of the IEEE International Conference on Robotics and Automation . Xi’an: IEEE, 2021: 1276–1282.
[本文引用: 1]
[15]
SATO M A, NAKAMURA Y, ISHII S. Reinforcement learning for biped locomotion [C]// Artificial Neural Networks — ICANN 2002 . Berlin: Springer, 2002: 777–782.
[本文引用: 1]
[16]
PETERS J, VIJAYAKUMAR S, SCHAAL S. Reinforcement learning for humanoid robotics [C]// Proceedings of the Third IEEE-RAS International Conference on Humanoid Robots . Karlsruhe: [s.n.], 2003: 1–20.
[本文引用: 1]
[17]
PENG X B, ABBEEL P, LEVINE S, et al DeepMimic: example-guided deep reinforcement learning of physics-based character skills
[J]. ACM Transactions on Graphics , 2018 , 37 (4 ): 1 - 14
[本文引用: 1]
[18]
PENG X B, KANAZAWA A, MALIK J, et al SFV: reinforcement learning of physical skills from videos
[J]. ACM Transactions on Graphics , 2018 , 37 (6 ): 1 - 14
[本文引用: 1]
[19]
GALLJAMOV R, ZHAO G, BELOUSOV B, et al. Improving sample efficiency of example-guided deep reinforcement learning for bipedal walking [C]// Proceedings of the IEEE-RAS 21st International Conference on Humanoid Robots . Ginowan: IEEE, 2023: 587–593.
[本文引用: 1]
[20]
JUDAH K, FERN A, TADEPALLI P, et al Imitation learning with demonstrations and shaping rewards
[J]. Proceedings of the AAAI Conference on Artificial Intelligence , 2014 , 28 (1 ): 1
DOI:10.1609/aaai.v28i1.9024
[本文引用: 1]
[21]
WEI T, LUO Q, MO Y, et al Design of the three-bus control system utilising periodic relay for a centipede-like robot
[J]. Robotica , 2016 , 34 (8 ): 1841 - 1854
DOI:10.1017/S0263574714002628
[本文引用: 1]
[22]
WANG D, BELTRAME G. Deployable reinforcement learning with variable control rate [EB/OL]. (2024–04–02)[2025–06–11]. https://arxiv.org/pdf/2401.09286.
[本文引用: 1]
[23]
PAN Z, YIN S, WEN G, et al Reinforcement learning control for a three-link biped robot with energy-efficient periodic gaits
[J]. Acta Mechanica Sinica , 2023 , 39 (2 ): 522304
DOI:10.1007/s10409-022-22304-x
[本文引用: 1]
[24]
AGRAWAL R, DAHLIN N, JAIN R, et al Markov balance satisfaction improves performance in strictly batch offline imitation learning
[J]. Proceedings of the AAAI Conference on Artificial Intelligence , 2025 , 39 (15 ): 15311 - 15319
[本文引用: 1]
[25]
DANIEL C, VAN HOOF H, PETERS J, et al Probabilistic inference for determining options in reinforcement learning
[J]. Machine Learning , 2016 , 104 (2 ): 337 - 357
[本文引用: 4]
[26]
ZHANG Z, PASCHALIDIS I. Provable hierarchical imitation learning via EM [C]// Proceedings of the 24th International Conference on Artificial Intelligence and Statistics (AISTATS) . San Diego: PMLR, 2021, 130: 883–891.
[本文引用: 2]
[27]
JING M, HUANG W, SUN F, et al. Adversarial option-aware hierarchical imitation learning [C]// Proceedings of the International Conference on Machine Learning (ICML) . [S. l.]: PMLR, 2021: 5097–5106.
[本文引用: 3]
[28]
LI Z, XU T, QIN Z, et al. Imitation learning from imperfection: theoretical justifications and algorithms [C]// 37th Conference on Neural Information Processing Systems . 2023: 1−40.
[本文引用: 2]
[29]
SIKCHI H S, ZHENG Q, ZHANG A, et al. Dual RL: unification and new methods for reinforcement and imitation learning [C]// Proceedings of the International Conference on Learning Representations . Vienna: [s.n.], 2024: 1−48.
[本文引用: 2]
[30]
KUJANPÄÄ K, PAJARINEN J, ILIN A. Hierarchical imitation learning with vector quantized models [C]// Proceedings of the 40th International Conference on Machine Learning (ICML) . [S.l.]: PMLR, 2023: 17896–17919.
[本文引用: 2]
[31]
GRANDIA R, JENELTEN F, YANG S, et al Perceptive locomotion through nonlinear model-predictive control
[J]. IEEE Transactions on Robotics , 2023 , 39 (5 ): 3402 - 3421
DOI:10.1109/TRO.2023.3275384
[本文引用: 1]
[32]
DARIO BELLICOSO C, GEHRING C, HWANGBO J, et al. Perception-less terrain adaptation through whole body control and hierarchical optimization [C]// Proceedings of the IEEE-RAS 16th International Conference on Humanoid Robots . Cancun: IEEE, 2017: 558–564.
[33]
SLEIMAN J P, FARSHIDIAN F, MINNITI M V, et al A unified MPC framework for whole-body dynamic locomotion and manipulation
[J]. IEEE Robotics and Automation Letters , 2021 , 6 (3 ): 4688 - 4695
DOI:10.1109/LRA.2021.3068908
[本文引用: 1]
[34]
YI X, CARAMANIS C. Regularized EM algorithms: a unified framework and statistical guarantees [C]// Proceedings of the 28th Advances in Neural Information Processing Systems (NeurIPS) . [S.l.]: Curran Associates, Inc. , 2015: 1567−1575.
[本文引用: 1]
[35]
SUTTON R S, PRECUP D, SINGH S Between MDPs and semi-MDPs: a framework for temporal abstraction in reinforcement learning
[J]. Artificial Intelligence , 1999 , 112 (1/2 ): 181 - 211
DOI:10.1016/s0004-3702(99)00052-1
[本文引用: 1]
[36]
BACON P L, HARB J, PRECUP D. The option-critic architecture [J]. Proceedings of the AAAI Conference on Artificial Intelligence . [S.l.]: AAAI, 2017: 1726–1734.
[本文引用: 1]
[37]
KHREICH W, GRANGER E, MIRI A, et al On the memory complexity of the forward–backward algorithm
[J]. Pattern Recognition Letters , 2010 , 31 (2 ): 91 - 99
DOI:10.1016/j.patrec.2009.09.023
[本文引用: 1]
[38]
PENG X B, MA Z, ABBEEL P, et al. AMP: adversarial motion priors for stylized physics-based character control [EB/OL]. (2022−05−12)[2025−06−11]. https://arxiv.org/pdf/2104.02180.
[本文引用: 2]
[39]
TAN J, ZHANG T, COUMANS E, et al. Sim-to-real: learning agile locomotion for quadruped robots [EB/OL]. (2018–05–16)[2025–06–11]. https://arxiv.org/pdf/1804.10332.
[本文引用: 1]
[40]
PENG X B, BERSETH G, VAN DE PANNE M Terrain-adaptive locomotion skills using deep reinforcement learning
[J]. ACM Transactions on Graphics , 2016 , 35 (4 ): 1 - 12
DOI:10.1145/2897824.2925881
[本文引用: 1]
[41]
KIM D, DI CARLO J, KATZ B, et al. Highly dynamic quadruped locomotion via whole-body impulse control and model predictive control [EB/OL]. (2019−09−14)[2025−06−11]. https://arxiv.org/pdf/1909.06586.
[本文引用: 1]
[42]
IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// Proceedings of the 32nd International Conference on Machine Learning . [S.l.]: PMLR, 2015: 448−456.
[本文引用: 1]
[43]
SANTURKAR S, TSIPRAS D, ILYAS A, et al. How does batch normalization help optimization [C]// Proceedings of the 32nd Conference on Neural Information Processing Systems . [S.l.]: Curran Associates Inc. , 2018: 2488–2498.
[本文引用: 1]
Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control
1
2025
... 强化学习(reinforcement learning,RL)是双足机器人控制领域的研究热点[1 -3 ] . 双足机器人具备高度非线性、强耦合性及动态不稳定性等复杂动力学特征,使强化学习算法在实际训练过程中面临巨大的挑战,特别是在缺乏先验知识的初始阶段,算法容易出现策略发散、失稳的问题[4 -5 ] . 模仿学习 (imitation learning,IL) 是高效引导策略优化过程的学习范式,能够在强化学习的早期阶段提供良好的初始化能力,被广泛应用于包括机器人运动控制、医疗机器人精细操作、多智能体对抗博弈等多个高复杂度任务中[6 -9 ] . 在大多数实际场景中,IL的专家策略通常来自经典控制方法生成的数据轨迹,例如 PID 控制器或模型预测控制 (model predictive control,MPC)[10 -11 ] ,这些方法设计成熟且易于实现,是IL中专家数据的可靠来源[12 -13 ] . ...
Experiments in balance with a 3D one-legged hopping machine
0
1984
Reinforcement learning-based cascade motion policy design for robust 3D bipedal locomotion
1
2022
... 强化学习(reinforcement learning,RL)是双足机器人控制领域的研究热点[1 -3 ] . 双足机器人具备高度非线性、强耦合性及动态不稳定性等复杂动力学特征,使强化学习算法在实际训练过程中面临巨大的挑战,特别是在缺乏先验知识的初始阶段,算法容易出现策略发散、失稳的问题[4 -5 ] . 模仿学习 (imitation learning,IL) 是高效引导策略优化过程的学习范式,能够在强化学习的早期阶段提供良好的初始化能力,被广泛应用于包括机器人运动控制、医疗机器人精细操作、多智能体对抗博弈等多个高复杂度任务中[6 -9 ] . 在大多数实际场景中,IL的专家策略通常来自经典控制方法生成的数据轨迹,例如 PID 控制器或模型预测控制 (model predictive control,MPC)[10 -11 ] ,这些方法设计成熟且易于实现,是IL中专家数据的可靠来源[12 -13 ] . ...
1
... 强化学习(reinforcement learning,RL)是双足机器人控制领域的研究热点[1 -3 ] . 双足机器人具备高度非线性、强耦合性及动态不稳定性等复杂动力学特征,使强化学习算法在实际训练过程中面临巨大的挑战,特别是在缺乏先验知识的初始阶段,算法容易出现策略发散、失稳的问题[4 -5 ] . 模仿学习 (imitation learning,IL) 是高效引导策略优化过程的学习范式,能够在强化学习的早期阶段提供良好的初始化能力,被广泛应用于包括机器人运动控制、医疗机器人精细操作、多智能体对抗博弈等多个高复杂度任务中[6 -9 ] . 在大多数实际场景中,IL的专家策略通常来自经典控制方法生成的数据轨迹,例如 PID 控制器或模型预测控制 (model predictive control,MPC)[10 -11 ] ,这些方法设计成熟且易于实现,是IL中专家数据的可靠来源[12 -13 ] . ...
1
... 强化学习(reinforcement learning,RL)是双足机器人控制领域的研究热点[1 -3 ] . 双足机器人具备高度非线性、强耦合性及动态不稳定性等复杂动力学特征,使强化学习算法在实际训练过程中面临巨大的挑战,特别是在缺乏先验知识的初始阶段,算法容易出现策略发散、失稳的问题[4 -5 ] . 模仿学习 (imitation learning,IL) 是高效引导策略优化过程的学习范式,能够在强化学习的早期阶段提供良好的初始化能力,被广泛应用于包括机器人运动控制、医疗机器人精细操作、多智能体对抗博弈等多个高复杂度任务中[6 -9 ] . 在大多数实际场景中,IL的专家策略通常来自经典控制方法生成的数据轨迹,例如 PID 控制器或模型预测控制 (model predictive control,MPC)[10 -11 ] ,这些方法设计成熟且易于实现,是IL中专家数据的可靠来源[12 -13 ] . ...
A learning-based control pipeline for generic motor skills for quadruped robots
1
2024
... 强化学习(reinforcement learning,RL)是双足机器人控制领域的研究热点[1 -3 ] . 双足机器人具备高度非线性、强耦合性及动态不稳定性等复杂动力学特征,使强化学习算法在实际训练过程中面临巨大的挑战,特别是在缺乏先验知识的初始阶段,算法容易出现策略发散、失稳的问题[4 -5 ] . 模仿学习 (imitation learning,IL) 是高效引导策略优化过程的学习范式,能够在强化学习的早期阶段提供良好的初始化能力,被广泛应用于包括机器人运动控制、医疗机器人精细操作、多智能体对抗博弈等多个高复杂度任务中[6 -9 ] . 在大多数实际场景中,IL的专家策略通常来自经典控制方法生成的数据轨迹,例如 PID 控制器或模型预测控制 (model predictive control,MPC)[10 -11 ] ,这些方法设计成熟且易于实现,是IL中专家数据的可靠来源[12 -13 ] . ...
High-speed quadrupedal locomotion by imitation-relaxation reinforcement learning
0
2022
Grandmaster level in StarCraft II using multi-agent reinforcement learning
1
2019
... 强化学习(reinforcement learning,RL)是双足机器人控制领域的研究热点[1 -3 ] . 双足机器人具备高度非线性、强耦合性及动态不稳定性等复杂动力学特征,使强化学习算法在实际训练过程中面临巨大的挑战,特别是在缺乏先验知识的初始阶段,算法容易出现策略发散、失稳的问题[4 -5 ] . 模仿学习 (imitation learning,IL) 是高效引导策略优化过程的学习范式,能够在强化学习的早期阶段提供良好的初始化能力,被广泛应用于包括机器人运动控制、医疗机器人精细操作、多智能体对抗博弈等多个高复杂度任务中[6 -9 ] . 在大多数实际场景中,IL的专家策略通常来自经典控制方法生成的数据轨迹,例如 PID 控制器或模型预测控制 (model predictive control,MPC)[10 -11 ] ,这些方法设计成熟且易于实现,是IL中专家数据的可靠来源[12 -13 ] . ...
基于模型预测控制的仿人机器人实时步态优化
1
2019
... 强化学习(reinforcement learning,RL)是双足机器人控制领域的研究热点[1 -3 ] . 双足机器人具备高度非线性、强耦合性及动态不稳定性等复杂动力学特征,使强化学习算法在实际训练过程中面临巨大的挑战,特别是在缺乏先验知识的初始阶段,算法容易出现策略发散、失稳的问题[4 -5 ] . 模仿学习 (imitation learning,IL) 是高效引导策略优化过程的学习范式,能够在强化学习的早期阶段提供良好的初始化能力,被广泛应用于包括机器人运动控制、医疗机器人精细操作、多智能体对抗博弈等多个高复杂度任务中[6 -9 ] . 在大多数实际场景中,IL的专家策略通常来自经典控制方法生成的数据轨迹,例如 PID 控制器或模型预测控制 (model predictive control,MPC)[10 -11 ] ,这些方法设计成熟且易于实现,是IL中专家数据的可靠来源[12 -13 ] . ...
基于模型预测控制的仿人机器人实时步态优化
1
2019
... 强化学习(reinforcement learning,RL)是双足机器人控制领域的研究热点[1 -3 ] . 双足机器人具备高度非线性、强耦合性及动态不稳定性等复杂动力学特征,使强化学习算法在实际训练过程中面临巨大的挑战,特别是在缺乏先验知识的初始阶段,算法容易出现策略发散、失稳的问题[4 -5 ] . 模仿学习 (imitation learning,IL) 是高效引导策略优化过程的学习范式,能够在强化学习的早期阶段提供良好的初始化能力,被广泛应用于包括机器人运动控制、医疗机器人精细操作、多智能体对抗博弈等多个高复杂度任务中[6 -9 ] . 在大多数实际场景中,IL的专家策略通常来自经典控制方法生成的数据轨迹,例如 PID 控制器或模型预测控制 (model predictive control,MPC)[10 -11 ] ,这些方法设计成熟且易于实现,是IL中专家数据的可靠来源[12 -13 ] . ...
基于模型预测的四足机器人运动控制
1
2024
... 强化学习(reinforcement learning,RL)是双足机器人控制领域的研究热点[1 -3 ] . 双足机器人具备高度非线性、强耦合性及动态不稳定性等复杂动力学特征,使强化学习算法在实际训练过程中面临巨大的挑战,特别是在缺乏先验知识的初始阶段,算法容易出现策略发散、失稳的问题[4 -5 ] . 模仿学习 (imitation learning,IL) 是高效引导策略优化过程的学习范式,能够在强化学习的早期阶段提供良好的初始化能力,被广泛应用于包括机器人运动控制、医疗机器人精细操作、多智能体对抗博弈等多个高复杂度任务中[6 -9 ] . 在大多数实际场景中,IL的专家策略通常来自经典控制方法生成的数据轨迹,例如 PID 控制器或模型预测控制 (model predictive control,MPC)[10 -11 ] ,这些方法设计成熟且易于实现,是IL中专家数据的可靠来源[12 -13 ] . ...
基于模型预测的四足机器人运动控制
1
2024
... 强化学习(reinforcement learning,RL)是双足机器人控制领域的研究热点[1 -3 ] . 双足机器人具备高度非线性、强耦合性及动态不稳定性等复杂动力学特征,使强化学习算法在实际训练过程中面临巨大的挑战,特别是在缺乏先验知识的初始阶段,算法容易出现策略发散、失稳的问题[4 -5 ] . 模仿学习 (imitation learning,IL) 是高效引导策略优化过程的学习范式,能够在强化学习的早期阶段提供良好的初始化能力,被广泛应用于包括机器人运动控制、医疗机器人精细操作、多智能体对抗博弈等多个高复杂度任务中[6 -9 ] . 在大多数实际场景中,IL的专家策略通常来自经典控制方法生成的数据轨迹,例如 PID 控制器或模型预测控制 (model predictive control,MPC)[10 -11 ] ,这些方法设计成熟且易于实现,是IL中专家数据的可靠来源[12 -13 ] . ...
1
... 强化学习(reinforcement learning,RL)是双足机器人控制领域的研究热点[1 -3 ] . 双足机器人具备高度非线性、强耦合性及动态不稳定性等复杂动力学特征,使强化学习算法在实际训练过程中面临巨大的挑战,特别是在缺乏先验知识的初始阶段,算法容易出现策略发散、失稳的问题[4 -5 ] . 模仿学习 (imitation learning,IL) 是高效引导策略优化过程的学习范式,能够在强化学习的早期阶段提供良好的初始化能力,被广泛应用于包括机器人运动控制、医疗机器人精细操作、多智能体对抗博弈等多个高复杂度任务中[6 -9 ] . 在大多数实际场景中,IL的专家策略通常来自经典控制方法生成的数据轨迹,例如 PID 控制器或模型预测控制 (model predictive control,MPC)[10 -11 ] ,这些方法设计成熟且易于实现,是IL中专家数据的可靠来源[12 -13 ] . ...
1
... 强化学习(reinforcement learning,RL)是双足机器人控制领域的研究热点[1 -3 ] . 双足机器人具备高度非线性、强耦合性及动态不稳定性等复杂动力学特征,使强化学习算法在实际训练过程中面临巨大的挑战,特别是在缺乏先验知识的初始阶段,算法容易出现策略发散、失稳的问题[4 -5 ] . 模仿学习 (imitation learning,IL) 是高效引导策略优化过程的学习范式,能够在强化学习的早期阶段提供良好的初始化能力,被广泛应用于包括机器人运动控制、医疗机器人精细操作、多智能体对抗博弈等多个高复杂度任务中[6 -9 ] . 在大多数实际场景中,IL的专家策略通常来自经典控制方法生成的数据轨迹,例如 PID 控制器或模型预测控制 (model predictive control,MPC)[10 -11 ] ,这些方法设计成熟且易于实现,是IL中专家数据的可靠来源[12 -13 ] . ...
1
... RL具备在复杂状态空间中自动学习最优策略的能力,能够摆脱传统控制器对动力学模型的依赖,被广泛应用于双足机器人控制领域[14 ] . 将 RL直接应用于真实机器人系统仍面临显著挑战: 1) 双足机器人系统高度不稳定,动作维度多,导致学习空间维度极高,常常使得策略训练过程处于易发散、难收敛的状态[15 -16 ] . 2) RL往往需要海量交互数据才能进行有效优化,但在真实机器人环境中,这类大规模训练不仅成本高昂,而且训练过程极易受到如硬件磨损、控制异常的现实因素干扰[17 -18 ] . 3) RL初始策略通常完全随机,在早期阶段难以探索到合理的步态模式,导致学习陷入瓶颈,训练效率低下,策略质量难以保障[19 ] . IL被视为有效提升 RL 训练效率与稳定性的辅助方法,基本思想是利用已有专家行为数据,提前对策略进行监督训练,从而快速引导策略向有效区域收敛[20 ] . ...
1
... RL具备在复杂状态空间中自动学习最优策略的能力,能够摆脱传统控制器对动力学模型的依赖,被广泛应用于双足机器人控制领域[14 ] . 将 RL直接应用于真实机器人系统仍面临显著挑战: 1) 双足机器人系统高度不稳定,动作维度多,导致学习空间维度极高,常常使得策略训练过程处于易发散、难收敛的状态[15 -16 ] . 2) RL往往需要海量交互数据才能进行有效优化,但在真实机器人环境中,这类大规模训练不仅成本高昂,而且训练过程极易受到如硬件磨损、控制异常的现实因素干扰[17 -18 ] . 3) RL初始策略通常完全随机,在早期阶段难以探索到合理的步态模式,导致学习陷入瓶颈,训练效率低下,策略质量难以保障[19 ] . IL被视为有效提升 RL 训练效率与稳定性的辅助方法,基本思想是利用已有专家行为数据,提前对策略进行监督训练,从而快速引导策略向有效区域收敛[20 ] . ...
1
... RL具备在复杂状态空间中自动学习最优策略的能力,能够摆脱传统控制器对动力学模型的依赖,被广泛应用于双足机器人控制领域[14 ] . 将 RL直接应用于真实机器人系统仍面临显著挑战: 1) 双足机器人系统高度不稳定,动作维度多,导致学习空间维度极高,常常使得策略训练过程处于易发散、难收敛的状态[15 -16 ] . 2) RL往往需要海量交互数据才能进行有效优化,但在真实机器人环境中,这类大规模训练不仅成本高昂,而且训练过程极易受到如硬件磨损、控制异常的现实因素干扰[17 -18 ] . 3) RL初始策略通常完全随机,在早期阶段难以探索到合理的步态模式,导致学习陷入瓶颈,训练效率低下,策略质量难以保障[19 ] . IL被视为有效提升 RL 训练效率与稳定性的辅助方法,基本思想是利用已有专家行为数据,提前对策略进行监督训练,从而快速引导策略向有效区域收敛[20 ] . ...
DeepMimic: example-guided deep reinforcement learning of physics-based character skills
1
2018
... RL具备在复杂状态空间中自动学习最优策略的能力,能够摆脱传统控制器对动力学模型的依赖,被广泛应用于双足机器人控制领域[14 ] . 将 RL直接应用于真实机器人系统仍面临显著挑战: 1) 双足机器人系统高度不稳定,动作维度多,导致学习空间维度极高,常常使得策略训练过程处于易发散、难收敛的状态[15 -16 ] . 2) RL往往需要海量交互数据才能进行有效优化,但在真实机器人环境中,这类大规模训练不仅成本高昂,而且训练过程极易受到如硬件磨损、控制异常的现实因素干扰[17 -18 ] . 3) RL初始策略通常完全随机,在早期阶段难以探索到合理的步态模式,导致学习陷入瓶颈,训练效率低下,策略质量难以保障[19 ] . IL被视为有效提升 RL 训练效率与稳定性的辅助方法,基本思想是利用已有专家行为数据,提前对策略进行监督训练,从而快速引导策略向有效区域收敛[20 ] . ...
SFV: reinforcement learning of physical skills from videos
1
2018
... RL具备在复杂状态空间中自动学习最优策略的能力,能够摆脱传统控制器对动力学模型的依赖,被广泛应用于双足机器人控制领域[14 ] . 将 RL直接应用于真实机器人系统仍面临显著挑战: 1) 双足机器人系统高度不稳定,动作维度多,导致学习空间维度极高,常常使得策略训练过程处于易发散、难收敛的状态[15 -16 ] . 2) RL往往需要海量交互数据才能进行有效优化,但在真实机器人环境中,这类大规模训练不仅成本高昂,而且训练过程极易受到如硬件磨损、控制异常的现实因素干扰[17 -18 ] . 3) RL初始策略通常完全随机,在早期阶段难以探索到合理的步态模式,导致学习陷入瓶颈,训练效率低下,策略质量难以保障[19 ] . IL被视为有效提升 RL 训练效率与稳定性的辅助方法,基本思想是利用已有专家行为数据,提前对策略进行监督训练,从而快速引导策略向有效区域收敛[20 ] . ...
1
... RL具备在复杂状态空间中自动学习最优策略的能力,能够摆脱传统控制器对动力学模型的依赖,被广泛应用于双足机器人控制领域[14 ] . 将 RL直接应用于真实机器人系统仍面临显著挑战: 1) 双足机器人系统高度不稳定,动作维度多,导致学习空间维度极高,常常使得策略训练过程处于易发散、难收敛的状态[15 -16 ] . 2) RL往往需要海量交互数据才能进行有效优化,但在真实机器人环境中,这类大规模训练不仅成本高昂,而且训练过程极易受到如硬件磨损、控制异常的现实因素干扰[17 -18 ] . 3) RL初始策略通常完全随机,在早期阶段难以探索到合理的步态模式,导致学习陷入瓶颈,训练效率低下,策略质量难以保障[19 ] . IL被视为有效提升 RL 训练效率与稳定性的辅助方法,基本思想是利用已有专家行为数据,提前对策略进行监督训练,从而快速引导策略向有效区域收敛[20 ] . ...
Imitation learning with demonstrations and shaping rewards
1
2014
... RL具备在复杂状态空间中自动学习最优策略的能力,能够摆脱传统控制器对动力学模型的依赖,被广泛应用于双足机器人控制领域[14 ] . 将 RL直接应用于真实机器人系统仍面临显著挑战: 1) 双足机器人系统高度不稳定,动作维度多,导致学习空间维度极高,常常使得策略训练过程处于易发散、难收敛的状态[15 -16 ] . 2) RL往往需要海量交互数据才能进行有效优化,但在真实机器人环境中,这类大规模训练不仅成本高昂,而且训练过程极易受到如硬件磨损、控制异常的现实因素干扰[17 -18 ] . 3) RL初始策略通常完全随机,在早期阶段难以探索到合理的步态模式,导致学习陷入瓶颈,训练效率低下,策略质量难以保障[19 ] . IL被视为有效提升 RL 训练效率与稳定性的辅助方法,基本思想是利用已有专家行为数据,提前对策略进行监督训练,从而快速引导策略向有效区域收敛[20 ] . ...
Design of the three-bus control system utilising periodic relay for a centipede-like robot
1
2016
... 传统 IL往往默认专家数据完全满足马尔可夫假设,即当前动作和奖励仅依赖当前状态. 机器人控制任务中很多控制策略 (尤其是传统控制器) 会显式或隐式地依赖历史状态、频率设定或外部调节器等非显性信息[21 -22 ] ,导致生成的数据序列难以满足RL或IL中通常假设的马尔可夫决策过程 (Markov decision process,MDP) 结构. 例如,部分双足机器人控制器依赖周期性调节信号以生成稳定步态[23 ] ,这类信息在数据中未被直接体现,加剧了模仿学习中的建模偏差. 如何从非马尔可夫特性较强的专家演示中提取稳定、可泛化的策略[24 ] ,成为IL研究中的关键问题之一. 针对上述难点,本研究提出普适性双足机器人稳定行走模仿学习方法,不再以专家策略满足马尔可夫性质为前提假设,能够直接处理包含历史依赖或隐含控制变量的专家示范数据,提升IL在复杂控制场景下的适应性与鲁棒性. 本研究将双足机器人的模仿学习过程抽象为包含隐变量的策略学习问题,引入概率选择框架 (probabilistic framework for options,PFFO)[25 ] 对传统模仿学习范式进行扩展. PFFO 是专门为处理隐变量问题设计的结构建模方法,能够在策略建模过程中显式地考虑不可观测的决策因子,更好地恢复原始控制意图. 基于该框架,本研究提出结构更简洁、推理更高效的简化 PFFO 策略模型. 为了验证这种方法的有效性,在基准任务上,将该模型与PFFO、平滑PFFO[26 ] (smoothing PFFO,S-PFFO)、GAIL-Option[27 ] 、 双V值学习[28 ] (dual-V learning,DVL)、 重要性采样加权行为克隆[29 ] (importance sampling weighted behavioral cloning,ISWBC)及基于子目标的层级模仿规划[30 ] (hierarchical imitation planning with subgoals,HIPS) 进行比较;将结合非线性模型预测控制 (nonlinear model predictive control,NMPC) 与全身控制器 (whole-body controller,WBC) 框架生成专家演示数据[31 -33 ] ,通过对所提模型的训练,在Mujoco仿真环境中部署验证,实现EC-Hunter80-v01双足机器人的稳定行走. ...
1
... 传统 IL往往默认专家数据完全满足马尔可夫假设,即当前动作和奖励仅依赖当前状态. 机器人控制任务中很多控制策略 (尤其是传统控制器) 会显式或隐式地依赖历史状态、频率设定或外部调节器等非显性信息[21 -22 ] ,导致生成的数据序列难以满足RL或IL中通常假设的马尔可夫决策过程 (Markov decision process,MDP) 结构. 例如,部分双足机器人控制器依赖周期性调节信号以生成稳定步态[23 ] ,这类信息在数据中未被直接体现,加剧了模仿学习中的建模偏差. 如何从非马尔可夫特性较强的专家演示中提取稳定、可泛化的策略[24 ] ,成为IL研究中的关键问题之一. 针对上述难点,本研究提出普适性双足机器人稳定行走模仿学习方法,不再以专家策略满足马尔可夫性质为前提假设,能够直接处理包含历史依赖或隐含控制变量的专家示范数据,提升IL在复杂控制场景下的适应性与鲁棒性. 本研究将双足机器人的模仿学习过程抽象为包含隐变量的策略学习问题,引入概率选择框架 (probabilistic framework for options,PFFO)[25 ] 对传统模仿学习范式进行扩展. PFFO 是专门为处理隐变量问题设计的结构建模方法,能够在策略建模过程中显式地考虑不可观测的决策因子,更好地恢复原始控制意图. 基于该框架,本研究提出结构更简洁、推理更高效的简化 PFFO 策略模型. 为了验证这种方法的有效性,在基准任务上,将该模型与PFFO、平滑PFFO[26 ] (smoothing PFFO,S-PFFO)、GAIL-Option[27 ] 、 双V值学习[28 ] (dual-V learning,DVL)、 重要性采样加权行为克隆[29 ] (importance sampling weighted behavioral cloning,ISWBC)及基于子目标的层级模仿规划[30 ] (hierarchical imitation planning with subgoals,HIPS) 进行比较;将结合非线性模型预测控制 (nonlinear model predictive control,NMPC) 与全身控制器 (whole-body controller,WBC) 框架生成专家演示数据[31 -33 ] ,通过对所提模型的训练,在Mujoco仿真环境中部署验证,实现EC-Hunter80-v01双足机器人的稳定行走. ...
Reinforcement learning control for a three-link biped robot with energy-efficient periodic gaits
1
2023
... 传统 IL往往默认专家数据完全满足马尔可夫假设,即当前动作和奖励仅依赖当前状态. 机器人控制任务中很多控制策略 (尤其是传统控制器) 会显式或隐式地依赖历史状态、频率设定或外部调节器等非显性信息[21 -22 ] ,导致生成的数据序列难以满足RL或IL中通常假设的马尔可夫决策过程 (Markov decision process,MDP) 结构. 例如,部分双足机器人控制器依赖周期性调节信号以生成稳定步态[23 ] ,这类信息在数据中未被直接体现,加剧了模仿学习中的建模偏差. 如何从非马尔可夫特性较强的专家演示中提取稳定、可泛化的策略[24 ] ,成为IL研究中的关键问题之一. 针对上述难点,本研究提出普适性双足机器人稳定行走模仿学习方法,不再以专家策略满足马尔可夫性质为前提假设,能够直接处理包含历史依赖或隐含控制变量的专家示范数据,提升IL在复杂控制场景下的适应性与鲁棒性. 本研究将双足机器人的模仿学习过程抽象为包含隐变量的策略学习问题,引入概率选择框架 (probabilistic framework for options,PFFO)[25 ] 对传统模仿学习范式进行扩展. PFFO 是专门为处理隐变量问题设计的结构建模方法,能够在策略建模过程中显式地考虑不可观测的决策因子,更好地恢复原始控制意图. 基于该框架,本研究提出结构更简洁、推理更高效的简化 PFFO 策略模型. 为了验证这种方法的有效性,在基准任务上,将该模型与PFFO、平滑PFFO[26 ] (smoothing PFFO,S-PFFO)、GAIL-Option[27 ] 、 双V值学习[28 ] (dual-V learning,DVL)、 重要性采样加权行为克隆[29 ] (importance sampling weighted behavioral cloning,ISWBC)及基于子目标的层级模仿规划[30 ] (hierarchical imitation planning with subgoals,HIPS) 进行比较;将结合非线性模型预测控制 (nonlinear model predictive control,NMPC) 与全身控制器 (whole-body controller,WBC) 框架生成专家演示数据[31 -33 ] ,通过对所提模型的训练,在Mujoco仿真环境中部署验证,实现EC-Hunter80-v01双足机器人的稳定行走. ...
Markov balance satisfaction improves performance in strictly batch offline imitation learning
1
2025
... 传统 IL往往默认专家数据完全满足马尔可夫假设,即当前动作和奖励仅依赖当前状态. 机器人控制任务中很多控制策略 (尤其是传统控制器) 会显式或隐式地依赖历史状态、频率设定或外部调节器等非显性信息[21 -22 ] ,导致生成的数据序列难以满足RL或IL中通常假设的马尔可夫决策过程 (Markov decision process,MDP) 结构. 例如,部分双足机器人控制器依赖周期性调节信号以生成稳定步态[23 ] ,这类信息在数据中未被直接体现,加剧了模仿学习中的建模偏差. 如何从非马尔可夫特性较强的专家演示中提取稳定、可泛化的策略[24 ] ,成为IL研究中的关键问题之一. 针对上述难点,本研究提出普适性双足机器人稳定行走模仿学习方法,不再以专家策略满足马尔可夫性质为前提假设,能够直接处理包含历史依赖或隐含控制变量的专家示范数据,提升IL在复杂控制场景下的适应性与鲁棒性. 本研究将双足机器人的模仿学习过程抽象为包含隐变量的策略学习问题,引入概率选择框架 (probabilistic framework for options,PFFO)[25 ] 对传统模仿学习范式进行扩展. PFFO 是专门为处理隐变量问题设计的结构建模方法,能够在策略建模过程中显式地考虑不可观测的决策因子,更好地恢复原始控制意图. 基于该框架,本研究提出结构更简洁、推理更高效的简化 PFFO 策略模型. 为了验证这种方法的有效性,在基准任务上,将该模型与PFFO、平滑PFFO[26 ] (smoothing PFFO,S-PFFO)、GAIL-Option[27 ] 、 双V值学习[28 ] (dual-V learning,DVL)、 重要性采样加权行为克隆[29 ] (importance sampling weighted behavioral cloning,ISWBC)及基于子目标的层级模仿规划[30 ] (hierarchical imitation planning with subgoals,HIPS) 进行比较;将结合非线性模型预测控制 (nonlinear model predictive control,NMPC) 与全身控制器 (whole-body controller,WBC) 框架生成专家演示数据[31 -33 ] ,通过对所提模型的训练,在Mujoco仿真环境中部署验证,实现EC-Hunter80-v01双足机器人的稳定行走. ...
Probabilistic inference for determining options in reinforcement learning
4
2016
... 传统 IL往往默认专家数据完全满足马尔可夫假设,即当前动作和奖励仅依赖当前状态. 机器人控制任务中很多控制策略 (尤其是传统控制器) 会显式或隐式地依赖历史状态、频率设定或外部调节器等非显性信息[21 -22 ] ,导致生成的数据序列难以满足RL或IL中通常假设的马尔可夫决策过程 (Markov decision process,MDP) 结构. 例如,部分双足机器人控制器依赖周期性调节信号以生成稳定步态[23 ] ,这类信息在数据中未被直接体现,加剧了模仿学习中的建模偏差. 如何从非马尔可夫特性较强的专家演示中提取稳定、可泛化的策略[24 ] ,成为IL研究中的关键问题之一. 针对上述难点,本研究提出普适性双足机器人稳定行走模仿学习方法,不再以专家策略满足马尔可夫性质为前提假设,能够直接处理包含历史依赖或隐含控制变量的专家示范数据,提升IL在复杂控制场景下的适应性与鲁棒性. 本研究将双足机器人的模仿学习过程抽象为包含隐变量的策略学习问题,引入概率选择框架 (probabilistic framework for options,PFFO)[25 ] 对传统模仿学习范式进行扩展. PFFO 是专门为处理隐变量问题设计的结构建模方法,能够在策略建模过程中显式地考虑不可观测的决策因子,更好地恢复原始控制意图. 基于该框架,本研究提出结构更简洁、推理更高效的简化 PFFO 策略模型. 为了验证这种方法的有效性,在基准任务上,将该模型与PFFO、平滑PFFO[26 ] (smoothing PFFO,S-PFFO)、GAIL-Option[27 ] 、 双V值学习[28 ] (dual-V learning,DVL)、 重要性采样加权行为克隆[29 ] (importance sampling weighted behavioral cloning,ISWBC)及基于子目标的层级模仿规划[30 ] (hierarchical imitation planning with subgoals,HIPS) 进行比较;将结合非线性模型预测控制 (nonlinear model predictive control,NMPC) 与全身控制器 (whole-body controller,WBC) 框架生成专家演示数据[31 -33 ] ,通过对所提模型的训练,在Mujoco仿真环境中部署验证,实现EC-Hunter80-v01双足机器人的稳定行走. ...
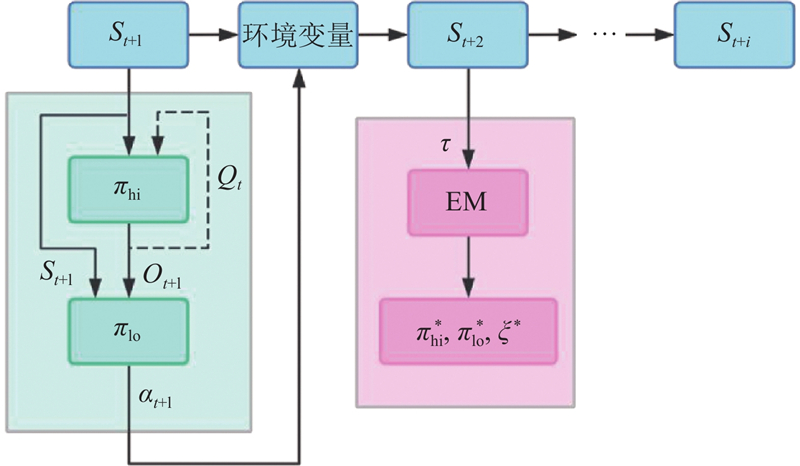
... 在解决需要长序列决策或复杂策略建模的RL任务时,传统方法面临样本效率低下与策略泛化能力弱的问题. Daniel 等[25 ] 提出基于概率推断的选项发现方法——PFFO框架. 该框架在选项框架的基础上,利用期望最大化(expectation maximization,EM)算法从行为轨迹中联合学习选项的低层策略、高层策略与终止策略,实现高效的分层策略建模与学习[34 ] . ...
... 本研究提出的简化PFFO 结合拉格朗日约束方法是结构紧凑的隐变量学习方法. 尽管本研究的理论分析过程建立在离散空间当中,但文献[25 ]~[27 ]表明,该类结构可以自然扩展至连续状态空间,并在高维连续任务(如机器人控制)中保持稳定的优化性能. 尤其是在双足机器人策略学习中,去除终止变量使模型在动态平衡与步态切换过程中避免了冗余状态估计,显著降低了训练噪声与梯度震荡,提升了策略的收敛稳定性与泛化能力. ...
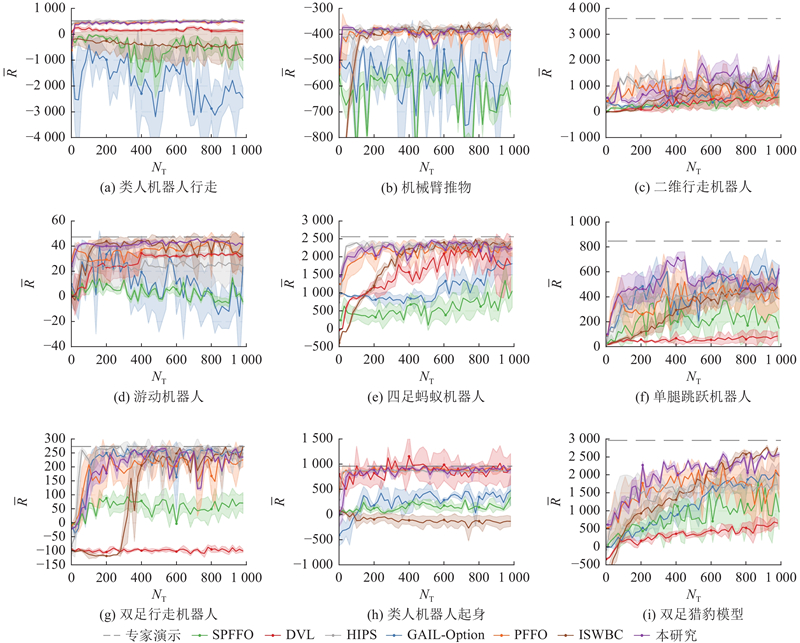
... 对比现有方法,评估简化PFFO在标准控制任务中的表现,重点验证所提方法在低层动作输出不满足马尔可夫性质的控制环境下的鲁棒性与策略泛化能力. 实验选取OpenAI Gym平台提供的多个典型连续动作控制任务作为评测环境,这些任务在机器人控制中广泛应用,具有较高的动态稳定性与控制挑战性. 6类代表性方法为PFFO[25 ] 、S-PFFO[26 ] 、GAIL-Option[27 ] 、DVL[28 ] 、ISWBC[29 ] 以及HIPS[30 ] . 其中PFFO与S-PFFO均采用与本研究方法一致的分层选项结构,便于从同一结构层面分析模型性能差异. GAIL-Option是在复杂隐变量场景中具有较强建模能力的IL,常作为有竞争力的基线算法使用. DVL、ISWBC 和 HIPS 属于先进的IL,具有代表性与前沿性. 考虑到任务之间的异质性,实验共选取9个具有代表性的控制任务进行对比分析,采集训练过程中的平均表现并进行对比分析. 在基准实验中,为了破坏马尔可夫性质 (模拟双足机器人传统控制器特性), 随机屏蔽10%的维度. 实验结果如图2 所示,实线表示平均值,阴影区域表示最大值和最小值的范围. 考虑到随机性的影响,每种方法针对每个任务训练5次,所有实验的种子点固定. 图2 中,N T 为训练回合数,$ \overline{R} $
2
... 传统 IL往往默认专家数据完全满足马尔可夫假设,即当前动作和奖励仅依赖当前状态. 机器人控制任务中很多控制策略 (尤其是传统控制器) 会显式或隐式地依赖历史状态、频率设定或外部调节器等非显性信息[21 -22 ] ,导致生成的数据序列难以满足RL或IL中通常假设的马尔可夫决策过程 (Markov decision process,MDP) 结构. 例如,部分双足机器人控制器依赖周期性调节信号以生成稳定步态[23 ] ,这类信息在数据中未被直接体现,加剧了模仿学习中的建模偏差. 如何从非马尔可夫特性较强的专家演示中提取稳定、可泛化的策略[24 ] ,成为IL研究中的关键问题之一. 针对上述难点,本研究提出普适性双足机器人稳定行走模仿学习方法,不再以专家策略满足马尔可夫性质为前提假设,能够直接处理包含历史依赖或隐含控制变量的专家示范数据,提升IL在复杂控制场景下的适应性与鲁棒性. 本研究将双足机器人的模仿学习过程抽象为包含隐变量的策略学习问题,引入概率选择框架 (probabilistic framework for options,PFFO)[25 ] 对传统模仿学习范式进行扩展. PFFO 是专门为处理隐变量问题设计的结构建模方法,能够在策略建模过程中显式地考虑不可观测的决策因子,更好地恢复原始控制意图. 基于该框架,本研究提出结构更简洁、推理更高效的简化 PFFO 策略模型. 为了验证这种方法的有效性,在基准任务上,将该模型与PFFO、平滑PFFO[26 ] (smoothing PFFO,S-PFFO)、GAIL-Option[27 ] 、 双V值学习[28 ] (dual-V learning,DVL)、 重要性采样加权行为克隆[29 ] (importance sampling weighted behavioral cloning,ISWBC)及基于子目标的层级模仿规划[30 ] (hierarchical imitation planning with subgoals,HIPS) 进行比较;将结合非线性模型预测控制 (nonlinear model predictive control,NMPC) 与全身控制器 (whole-body controller,WBC) 框架生成专家演示数据[31 -33 ] ,通过对所提模型的训练,在Mujoco仿真环境中部署验证,实现EC-Hunter80-v01双足机器人的稳定行走. ...
... 对比现有方法,评估简化PFFO在标准控制任务中的表现,重点验证所提方法在低层动作输出不满足马尔可夫性质的控制环境下的鲁棒性与策略泛化能力. 实验选取OpenAI Gym平台提供的多个典型连续动作控制任务作为评测环境,这些任务在机器人控制中广泛应用,具有较高的动态稳定性与控制挑战性. 6类代表性方法为PFFO[25 ] 、S-PFFO[26 ] 、GAIL-Option[27 ] 、DVL[28 ] 、ISWBC[29 ] 以及HIPS[30 ] . 其中PFFO与S-PFFO均采用与本研究方法一致的分层选项结构,便于从同一结构层面分析模型性能差异. GAIL-Option是在复杂隐变量场景中具有较强建模能力的IL,常作为有竞争力的基线算法使用. DVL、ISWBC 和 HIPS 属于先进的IL,具有代表性与前沿性. 考虑到任务之间的异质性,实验共选取9个具有代表性的控制任务进行对比分析,采集训练过程中的平均表现并进行对比分析. 在基准实验中,为了破坏马尔可夫性质 (模拟双足机器人传统控制器特性), 随机屏蔽10%的维度. 实验结果如图2 所示,实线表示平均值,阴影区域表示最大值和最小值的范围. 考虑到随机性的影响,每种方法针对每个任务训练5次,所有实验的种子点固定. 图2 中,N T 为训练回合数,$ \overline{R} $
3
... 传统 IL往往默认专家数据完全满足马尔可夫假设,即当前动作和奖励仅依赖当前状态. 机器人控制任务中很多控制策略 (尤其是传统控制器) 会显式或隐式地依赖历史状态、频率设定或外部调节器等非显性信息[21 -22 ] ,导致生成的数据序列难以满足RL或IL中通常假设的马尔可夫决策过程 (Markov decision process,MDP) 结构. 例如,部分双足机器人控制器依赖周期性调节信号以生成稳定步态[23 ] ,这类信息在数据中未被直接体现,加剧了模仿学习中的建模偏差. 如何从非马尔可夫特性较强的专家演示中提取稳定、可泛化的策略[24 ] ,成为IL研究中的关键问题之一. 针对上述难点,本研究提出普适性双足机器人稳定行走模仿学习方法,不再以专家策略满足马尔可夫性质为前提假设,能够直接处理包含历史依赖或隐含控制变量的专家示范数据,提升IL在复杂控制场景下的适应性与鲁棒性. 本研究将双足机器人的模仿学习过程抽象为包含隐变量的策略学习问题,引入概率选择框架 (probabilistic framework for options,PFFO)[25 ] 对传统模仿学习范式进行扩展. PFFO 是专门为处理隐变量问题设计的结构建模方法,能够在策略建模过程中显式地考虑不可观测的决策因子,更好地恢复原始控制意图. 基于该框架,本研究提出结构更简洁、推理更高效的简化 PFFO 策略模型. 为了验证这种方法的有效性,在基准任务上,将该模型与PFFO、平滑PFFO[26 ] (smoothing PFFO,S-PFFO)、GAIL-Option[27 ] 、 双V值学习[28 ] (dual-V learning,DVL)、 重要性采样加权行为克隆[29 ] (importance sampling weighted behavioral cloning,ISWBC)及基于子目标的层级模仿规划[30 ] (hierarchical imitation planning with subgoals,HIPS) 进行比较;将结合非线性模型预测控制 (nonlinear model predictive control,NMPC) 与全身控制器 (whole-body controller,WBC) 框架生成专家演示数据[31 -33 ] ,通过对所提模型的训练,在Mujoco仿真环境中部署验证,实现EC-Hunter80-v01双足机器人的稳定行走. ...
... 本研究提出的简化PFFO 结合拉格朗日约束方法是结构紧凑的隐变量学习方法. 尽管本研究的理论分析过程建立在离散空间当中,但文献[25 ]~[27 ]表明,该类结构可以自然扩展至连续状态空间,并在高维连续任务(如机器人控制)中保持稳定的优化性能. 尤其是在双足机器人策略学习中,去除终止变量使模型在动态平衡与步态切换过程中避免了冗余状态估计,显著降低了训练噪声与梯度震荡,提升了策略的收敛稳定性与泛化能力. ...
... 对比现有方法,评估简化PFFO在标准控制任务中的表现,重点验证所提方法在低层动作输出不满足马尔可夫性质的控制环境下的鲁棒性与策略泛化能力. 实验选取OpenAI Gym平台提供的多个典型连续动作控制任务作为评测环境,这些任务在机器人控制中广泛应用,具有较高的动态稳定性与控制挑战性. 6类代表性方法为PFFO[25 ] 、S-PFFO[26 ] 、GAIL-Option[27 ] 、DVL[28 ] 、ISWBC[29 ] 以及HIPS[30 ] . 其中PFFO与S-PFFO均采用与本研究方法一致的分层选项结构,便于从同一结构层面分析模型性能差异. GAIL-Option是在复杂隐变量场景中具有较强建模能力的IL,常作为有竞争力的基线算法使用. DVL、ISWBC 和 HIPS 属于先进的IL,具有代表性与前沿性. 考虑到任务之间的异质性,实验共选取9个具有代表性的控制任务进行对比分析,采集训练过程中的平均表现并进行对比分析. 在基准实验中,为了破坏马尔可夫性质 (模拟双足机器人传统控制器特性), 随机屏蔽10%的维度. 实验结果如图2 所示,实线表示平均值,阴影区域表示最大值和最小值的范围. 考虑到随机性的影响,每种方法针对每个任务训练5次,所有实验的种子点固定. 图2 中,N T 为训练回合数,$ \overline{R} $
2
... 传统 IL往往默认专家数据完全满足马尔可夫假设,即当前动作和奖励仅依赖当前状态. 机器人控制任务中很多控制策略 (尤其是传统控制器) 会显式或隐式地依赖历史状态、频率设定或外部调节器等非显性信息[21 -22 ] ,导致生成的数据序列难以满足RL或IL中通常假设的马尔可夫决策过程 (Markov decision process,MDP) 结构. 例如,部分双足机器人控制器依赖周期性调节信号以生成稳定步态[23 ] ,这类信息在数据中未被直接体现,加剧了模仿学习中的建模偏差. 如何从非马尔可夫特性较强的专家演示中提取稳定、可泛化的策略[24 ] ,成为IL研究中的关键问题之一. 针对上述难点,本研究提出普适性双足机器人稳定行走模仿学习方法,不再以专家策略满足马尔可夫性质为前提假设,能够直接处理包含历史依赖或隐含控制变量的专家示范数据,提升IL在复杂控制场景下的适应性与鲁棒性. 本研究将双足机器人的模仿学习过程抽象为包含隐变量的策略学习问题,引入概率选择框架 (probabilistic framework for options,PFFO)[25 ] 对传统模仿学习范式进行扩展. PFFO 是专门为处理隐变量问题设计的结构建模方法,能够在策略建模过程中显式地考虑不可观测的决策因子,更好地恢复原始控制意图. 基于该框架,本研究提出结构更简洁、推理更高效的简化 PFFO 策略模型. 为了验证这种方法的有效性,在基准任务上,将该模型与PFFO、平滑PFFO[26 ] (smoothing PFFO,S-PFFO)、GAIL-Option[27 ] 、 双V值学习[28 ] (dual-V learning,DVL)、 重要性采样加权行为克隆[29 ] (importance sampling weighted behavioral cloning,ISWBC)及基于子目标的层级模仿规划[30 ] (hierarchical imitation planning with subgoals,HIPS) 进行比较;将结合非线性模型预测控制 (nonlinear model predictive control,NMPC) 与全身控制器 (whole-body controller,WBC) 框架生成专家演示数据[31 -33 ] ,通过对所提模型的训练,在Mujoco仿真环境中部署验证,实现EC-Hunter80-v01双足机器人的稳定行走. ...
... 对比现有方法,评估简化PFFO在标准控制任务中的表现,重点验证所提方法在低层动作输出不满足马尔可夫性质的控制环境下的鲁棒性与策略泛化能力. 实验选取OpenAI Gym平台提供的多个典型连续动作控制任务作为评测环境,这些任务在机器人控制中广泛应用,具有较高的动态稳定性与控制挑战性. 6类代表性方法为PFFO[25 ] 、S-PFFO[26 ] 、GAIL-Option[27 ] 、DVL[28 ] 、ISWBC[29 ] 以及HIPS[30 ] . 其中PFFO与S-PFFO均采用与本研究方法一致的分层选项结构,便于从同一结构层面分析模型性能差异. GAIL-Option是在复杂隐变量场景中具有较强建模能力的IL,常作为有竞争力的基线算法使用. DVL、ISWBC 和 HIPS 属于先进的IL,具有代表性与前沿性. 考虑到任务之间的异质性,实验共选取9个具有代表性的控制任务进行对比分析,采集训练过程中的平均表现并进行对比分析. 在基准实验中,为了破坏马尔可夫性质 (模拟双足机器人传统控制器特性), 随机屏蔽10%的维度. 实验结果如图2 所示,实线表示平均值,阴影区域表示最大值和最小值的范围. 考虑到随机性的影响,每种方法针对每个任务训练5次,所有实验的种子点固定. 图2 中,N T 为训练回合数,$ \overline{R} $
2
... 传统 IL往往默认专家数据完全满足马尔可夫假设,即当前动作和奖励仅依赖当前状态. 机器人控制任务中很多控制策略 (尤其是传统控制器) 会显式或隐式地依赖历史状态、频率设定或外部调节器等非显性信息[21 -22 ] ,导致生成的数据序列难以满足RL或IL中通常假设的马尔可夫决策过程 (Markov decision process,MDP) 结构. 例如,部分双足机器人控制器依赖周期性调节信号以生成稳定步态[23 ] ,这类信息在数据中未被直接体现,加剧了模仿学习中的建模偏差. 如何从非马尔可夫特性较强的专家演示中提取稳定、可泛化的策略[24 ] ,成为IL研究中的关键问题之一. 针对上述难点,本研究提出普适性双足机器人稳定行走模仿学习方法,不再以专家策略满足马尔可夫性质为前提假设,能够直接处理包含历史依赖或隐含控制变量的专家示范数据,提升IL在复杂控制场景下的适应性与鲁棒性. 本研究将双足机器人的模仿学习过程抽象为包含隐变量的策略学习问题,引入概率选择框架 (probabilistic framework for options,PFFO)[25 ] 对传统模仿学习范式进行扩展. PFFO 是专门为处理隐变量问题设计的结构建模方法,能够在策略建模过程中显式地考虑不可观测的决策因子,更好地恢复原始控制意图. 基于该框架,本研究提出结构更简洁、推理更高效的简化 PFFO 策略模型. 为了验证这种方法的有效性,在基准任务上,将该模型与PFFO、平滑PFFO[26 ] (smoothing PFFO,S-PFFO)、GAIL-Option[27 ] 、 双V值学习[28 ] (dual-V learning,DVL)、 重要性采样加权行为克隆[29 ] (importance sampling weighted behavioral cloning,ISWBC)及基于子目标的层级模仿规划[30 ] (hierarchical imitation planning with subgoals,HIPS) 进行比较;将结合非线性模型预测控制 (nonlinear model predictive control,NMPC) 与全身控制器 (whole-body controller,WBC) 框架生成专家演示数据[31 -33 ] ,通过对所提模型的训练,在Mujoco仿真环境中部署验证,实现EC-Hunter80-v01双足机器人的稳定行走. ...
... 对比现有方法,评估简化PFFO在标准控制任务中的表现,重点验证所提方法在低层动作输出不满足马尔可夫性质的控制环境下的鲁棒性与策略泛化能力. 实验选取OpenAI Gym平台提供的多个典型连续动作控制任务作为评测环境,这些任务在机器人控制中广泛应用,具有较高的动态稳定性与控制挑战性. 6类代表性方法为PFFO[25 ] 、S-PFFO[26 ] 、GAIL-Option[27 ] 、DVL[28 ] 、ISWBC[29 ] 以及HIPS[30 ] . 其中PFFO与S-PFFO均采用与本研究方法一致的分层选项结构,便于从同一结构层面分析模型性能差异. GAIL-Option是在复杂隐变量场景中具有较强建模能力的IL,常作为有竞争力的基线算法使用. DVL、ISWBC 和 HIPS 属于先进的IL,具有代表性与前沿性. 考虑到任务之间的异质性,实验共选取9个具有代表性的控制任务进行对比分析,采集训练过程中的平均表现并进行对比分析. 在基准实验中,为了破坏马尔可夫性质 (模拟双足机器人传统控制器特性), 随机屏蔽10%的维度. 实验结果如图2 所示,实线表示平均值,阴影区域表示最大值和最小值的范围. 考虑到随机性的影响,每种方法针对每个任务训练5次,所有实验的种子点固定. 图2 中,N T 为训练回合数,$ \overline{R} $
2
... 传统 IL往往默认专家数据完全满足马尔可夫假设,即当前动作和奖励仅依赖当前状态. 机器人控制任务中很多控制策略 (尤其是传统控制器) 会显式或隐式地依赖历史状态、频率设定或外部调节器等非显性信息[21 -22 ] ,导致生成的数据序列难以满足RL或IL中通常假设的马尔可夫决策过程 (Markov decision process,MDP) 结构. 例如,部分双足机器人控制器依赖周期性调节信号以生成稳定步态[23 ] ,这类信息在数据中未被直接体现,加剧了模仿学习中的建模偏差. 如何从非马尔可夫特性较强的专家演示中提取稳定、可泛化的策略[24 ] ,成为IL研究中的关键问题之一. 针对上述难点,本研究提出普适性双足机器人稳定行走模仿学习方法,不再以专家策略满足马尔可夫性质为前提假设,能够直接处理包含历史依赖或隐含控制变量的专家示范数据,提升IL在复杂控制场景下的适应性与鲁棒性. 本研究将双足机器人的模仿学习过程抽象为包含隐变量的策略学习问题,引入概率选择框架 (probabilistic framework for options,PFFO)[25 ] 对传统模仿学习范式进行扩展. PFFO 是专门为处理隐变量问题设计的结构建模方法,能够在策略建模过程中显式地考虑不可观测的决策因子,更好地恢复原始控制意图. 基于该框架,本研究提出结构更简洁、推理更高效的简化 PFFO 策略模型. 为了验证这种方法的有效性,在基准任务上,将该模型与PFFO、平滑PFFO[26 ] (smoothing PFFO,S-PFFO)、GAIL-Option[27 ] 、 双V值学习[28 ] (dual-V learning,DVL)、 重要性采样加权行为克隆[29 ] (importance sampling weighted behavioral cloning,ISWBC)及基于子目标的层级模仿规划[30 ] (hierarchical imitation planning with subgoals,HIPS) 进行比较;将结合非线性模型预测控制 (nonlinear model predictive control,NMPC) 与全身控制器 (whole-body controller,WBC) 框架生成专家演示数据[31 -33 ] ,通过对所提模型的训练,在Mujoco仿真环境中部署验证,实现EC-Hunter80-v01双足机器人的稳定行走. ...
... 对比现有方法,评估简化PFFO在标准控制任务中的表现,重点验证所提方法在低层动作输出不满足马尔可夫性质的控制环境下的鲁棒性与策略泛化能力. 实验选取OpenAI Gym平台提供的多个典型连续动作控制任务作为评测环境,这些任务在机器人控制中广泛应用,具有较高的动态稳定性与控制挑战性. 6类代表性方法为PFFO[25 ] 、S-PFFO[26 ] 、GAIL-Option[27 ] 、DVL[28 ] 、ISWBC[29 ] 以及HIPS[30 ] . 其中PFFO与S-PFFO均采用与本研究方法一致的分层选项结构,便于从同一结构层面分析模型性能差异. GAIL-Option是在复杂隐变量场景中具有较强建模能力的IL,常作为有竞争力的基线算法使用. DVL、ISWBC 和 HIPS 属于先进的IL,具有代表性与前沿性. 考虑到任务之间的异质性,实验共选取9个具有代表性的控制任务进行对比分析,采集训练过程中的平均表现并进行对比分析. 在基准实验中,为了破坏马尔可夫性质 (模拟双足机器人传统控制器特性), 随机屏蔽10%的维度. 实验结果如图2 所示,实线表示平均值,阴影区域表示最大值和最小值的范围. 考虑到随机性的影响,每种方法针对每个任务训练5次,所有实验的种子点固定. 图2 中,N T 为训练回合数,$ \overline{R} $
Perceptive locomotion through nonlinear model-predictive control
1
2023
... 传统 IL往往默认专家数据完全满足马尔可夫假设,即当前动作和奖励仅依赖当前状态. 机器人控制任务中很多控制策略 (尤其是传统控制器) 会显式或隐式地依赖历史状态、频率设定或外部调节器等非显性信息[21 -22 ] ,导致生成的数据序列难以满足RL或IL中通常假设的马尔可夫决策过程 (Markov decision process,MDP) 结构. 例如,部分双足机器人控制器依赖周期性调节信号以生成稳定步态[23 ] ,这类信息在数据中未被直接体现,加剧了模仿学习中的建模偏差. 如何从非马尔可夫特性较强的专家演示中提取稳定、可泛化的策略[24 ] ,成为IL研究中的关键问题之一. 针对上述难点,本研究提出普适性双足机器人稳定行走模仿学习方法,不再以专家策略满足马尔可夫性质为前提假设,能够直接处理包含历史依赖或隐含控制变量的专家示范数据,提升IL在复杂控制场景下的适应性与鲁棒性. 本研究将双足机器人的模仿学习过程抽象为包含隐变量的策略学习问题,引入概率选择框架 (probabilistic framework for options,PFFO)[25 ] 对传统模仿学习范式进行扩展. PFFO 是专门为处理隐变量问题设计的结构建模方法,能够在策略建模过程中显式地考虑不可观测的决策因子,更好地恢复原始控制意图. 基于该框架,本研究提出结构更简洁、推理更高效的简化 PFFO 策略模型. 为了验证这种方法的有效性,在基准任务上,将该模型与PFFO、平滑PFFO[26 ] (smoothing PFFO,S-PFFO)、GAIL-Option[27 ] 、 双V值学习[28 ] (dual-V learning,DVL)、 重要性采样加权行为克隆[29 ] (importance sampling weighted behavioral cloning,ISWBC)及基于子目标的层级模仿规划[30 ] (hierarchical imitation planning with subgoals,HIPS) 进行比较;将结合非线性模型预测控制 (nonlinear model predictive control,NMPC) 与全身控制器 (whole-body controller,WBC) 框架生成专家演示数据[31 -33 ] ,通过对所提模型的训练,在Mujoco仿真环境中部署验证,实现EC-Hunter80-v01双足机器人的稳定行走. ...
A unified MPC framework for whole-body dynamic locomotion and manipulation
1
2021
... 传统 IL往往默认专家数据完全满足马尔可夫假设,即当前动作和奖励仅依赖当前状态. 机器人控制任务中很多控制策略 (尤其是传统控制器) 会显式或隐式地依赖历史状态、频率设定或外部调节器等非显性信息[21 -22 ] ,导致生成的数据序列难以满足RL或IL中通常假设的马尔可夫决策过程 (Markov decision process,MDP) 结构. 例如,部分双足机器人控制器依赖周期性调节信号以生成稳定步态[23 ] ,这类信息在数据中未被直接体现,加剧了模仿学习中的建模偏差. 如何从非马尔可夫特性较强的专家演示中提取稳定、可泛化的策略[24 ] ,成为IL研究中的关键问题之一. 针对上述难点,本研究提出普适性双足机器人稳定行走模仿学习方法,不再以专家策略满足马尔可夫性质为前提假设,能够直接处理包含历史依赖或隐含控制变量的专家示范数据,提升IL在复杂控制场景下的适应性与鲁棒性. 本研究将双足机器人的模仿学习过程抽象为包含隐变量的策略学习问题,引入概率选择框架 (probabilistic framework for options,PFFO)[25 ] 对传统模仿学习范式进行扩展. PFFO 是专门为处理隐变量问题设计的结构建模方法,能够在策略建模过程中显式地考虑不可观测的决策因子,更好地恢复原始控制意图. 基于该框架,本研究提出结构更简洁、推理更高效的简化 PFFO 策略模型. 为了验证这种方法的有效性,在基准任务上,将该模型与PFFO、平滑PFFO[26 ] (smoothing PFFO,S-PFFO)、GAIL-Option[27 ] 、 双V值学习[28 ] (dual-V learning,DVL)、 重要性采样加权行为克隆[29 ] (importance sampling weighted behavioral cloning,ISWBC)及基于子目标的层级模仿规划[30 ] (hierarchical imitation planning with subgoals,HIPS) 进行比较;将结合非线性模型预测控制 (nonlinear model predictive control,NMPC) 与全身控制器 (whole-body controller,WBC) 框架生成专家演示数据[31 -33 ] ,通过对所提模型的训练,在Mujoco仿真环境中部署验证,实现EC-Hunter80-v01双足机器人的稳定行走. ...
1
... 在解决需要长序列决策或复杂策略建模的RL任务时,传统方法面临样本效率低下与策略泛化能力弱的问题. Daniel 等[25 ] 提出基于概率推断的选项发现方法——PFFO框架. 该框架在选项框架的基础上,利用期望最大化(expectation maximization,EM)算法从行为轨迹中联合学习选项的低层策略、高层策略与终止策略,实现高效的分层策略建模与学习[34 ] . ...
Between MDPs and semi-MDPs: a framework for temporal abstraction in reinforcement learning
1
1999
... 选项框架早期被引入RL领域是用于建模长时序任务中的策略切换机制[35 -36 ] ,基本结构为四元组 $ (S,A,O,B) $ $ O $ $ B=\{0,1\} $ $ ({\pi }_{\mathrm{hi}},{\pi }_{\mathrm{lo}},{\pi }_{\mathrm{b}}) $ $ {\pi }_{\mathrm{hi}}\colon S\rightarrow \Delta (O) $ $ s $ $ {\pi }_{\mathrm{lo}}\colon S\times O\rightarrow \Delta (A) $ $ {\pi }_{\mathrm{b}}\colon S\rightarrow \Delta (B) $
1
... 选项框架早期被引入RL领域是用于建模长时序任务中的策略切换机制[35 -36 ] ,基本结构为四元组 $ (S,A,O,B) $ $ O $ $ B=\{0,1\} $ $ ({\pi }_{\mathrm{hi}},{\pi }_{\mathrm{lo}},{\pi }_{\mathrm{b}}) $ $ {\pi }_{\mathrm{hi}}\colon S\rightarrow \Delta (O) $ $ s $ $ {\pi }_{\mathrm{lo}}\colon S\times O\rightarrow \Delta (A) $ $ {\pi }_{\mathrm{b}}\colon S\rightarrow \Delta (B) $
On the memory complexity of the forward–backward algorithm
1
2010
... 时间复杂度分析[37 ] : 在含终止变量的标准 PFFO 中,由式(3)可知,EM算法的 E步骤须计算后验分布$ P({o}_{t},{b}_{t}|\tau ) $ $ P({o}_{t},{b}_{t},{o}_{t+1},{b}_{t+1}|\tau ) $ $ ({o}_{t},{b}_{t}) $ $ O(T|O{|}^{2}|B{|}^{2}) $ $ |O| $ $ |B|=2 $ $ {o}_{t} $ $ O(T|O{|}^{2}) $ $ O(T|O{|}^{2}|B{|}^{2}) $ $ |B{|}^{2} $ $ |B|=2 $ $ \theta ={\theta }_{\text{hi}}、{\theta }_{\text{lo}}、{\theta }_{\text{b}} $ $ {\theta }^{\prime}={\theta }_{\text{hi}}、{\theta }_{\text{lo}} $ . 设各模块参数维度分别为$ {d}_{\text{hi}}、{d}_{\text{lo}}、{d}_{\text{b}} $
2
... 实现 EC-Hunter80-v01 在平坦地面上稳定、节能、目标导向的行走行为须设计合理的奖励. 通常来讲,设计机器人控制任务的奖励函数会考虑被控对象的前进方向[38 ] 、能量效率[39 -40 ] 、动作平滑及目标位置[38 ] 等,本研究考虑包含前进、能量效率、动作平滑性、足端接触力误差和目标位置共5项子目标的加权奖励结构,总奖励函数为 ...
... [38 ]等,本研究考虑包含前进、能量效率、动作平滑性、足端接触力误差和目标位置共5项子目标的加权奖励结构,总奖励函数为 ...
1
... 实现 EC-Hunter80-v01 在平坦地面上稳定、节能、目标导向的行走行为须设计合理的奖励. 通常来讲,设计机器人控制任务的奖励函数会考虑被控对象的前进方向[38 ] 、能量效率[39 -40 ] 、动作平滑及目标位置[38 ] 等,本研究考虑包含前进、能量效率、动作平滑性、足端接触力误差和目标位置共5项子目标的加权奖励结构,总奖励函数为 ...
Terrain-adaptive locomotion skills using deep reinforcement learning
1
2016
... 实现 EC-Hunter80-v01 在平坦地面上稳定、节能、目标导向的行走行为须设计合理的奖励. 通常来讲,设计机器人控制任务的奖励函数会考虑被控对象的前进方向[38 ] 、能量效率[39 -40 ] 、动作平滑及目标位置[38 ] 等,本研究考虑包含前进、能量效率、动作平滑性、足端接触力误差和目标位置共5项子目标的加权奖励结构,总奖励函数为 ...
1
... WBC 模块负责将上层 NMPC的输出映射为各关节的控制命令. WBC依据文献[41 ]采用任务优先级投影法,确保硬约束任务(浮动基座动力学、扭矩限制、摩擦锥约束)在多个冗余自由度中严格满足,软约束任务(基座轨迹跟踪、摆动腿轨迹规划、接触力控制)在硬约束的零空间中协同执行. WBC模块运行频率为100 Hz. WBC在每个控制周期内构建约束优化问题: ...
1
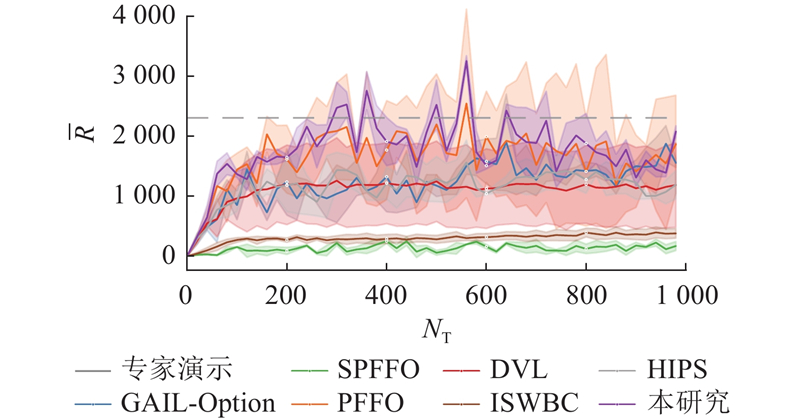
... 式中:$ {{L}}_{{\mathrm{phys}}} $ $ {\lambda }_{{\mathrm{phys}}} $ [42 -43 ] . 为了确保泛化性能,每训练一定轮数便在验证集上评估当前模型的负对数似然损失与每步动作误差,若连续若干次评估未提升性能,则启动早停机制防止过拟合. 训练过程中使用的主要超参数配置如表3 所示. 在EC-Hunter80-v01上对比分析不同模仿学习方法的训练性能,对比方法在相同的专家数据集、训练参数及随机种子条件下独立重复训练5次,所有实验均采用固定种子点,结果如图3 所示. 可以看出,简化 PFFO 的训练曲线与标准 PFFO 的高度一致,甚至表现更好,在多个任务中的曲线几乎重合,未见明显性能下降. 其他方法在 EC-Hunter80-v01控制任务中均未能成功复现专家演示行为,表现出较低的策略可迁移性与稳定性. 这表明,尽管简化 PFFO 去除了终止变量并将低层动作视为隐变量进行联合建模,依然能够保持原模型的表达能力与稳定性,验证了该策略在复杂控制任务中的可行性与稳定性;进一步说明,在应对 PD 控制引发的非马尔可夫问题时,该方法能够有效融合高层隐变量结构,实现稳定控制策略的学习. ...
1
... 式中:$ {{L}}_{{\mathrm{phys}}} $ $ {\lambda }_{{\mathrm{phys}}} $ [42 -43 ] . 为了确保泛化性能,每训练一定轮数便在验证集上评估当前模型的负对数似然损失与每步动作误差,若连续若干次评估未提升性能,则启动早停机制防止过拟合. 训练过程中使用的主要超参数配置如表3 所示. 在EC-Hunter80-v01上对比分析不同模仿学习方法的训练性能,对比方法在相同的专家数据集、训练参数及随机种子条件下独立重复训练5次,所有实验均采用固定种子点,结果如图3 所示. 可以看出,简化 PFFO 的训练曲线与标准 PFFO 的高度一致,甚至表现更好,在多个任务中的曲线几乎重合,未见明显性能下降. 其他方法在 EC-Hunter80-v01控制任务中均未能成功复现专家演示行为,表现出较低的策略可迁移性与稳定性. 这表明,尽管简化 PFFO 去除了终止变量并将低层动作视为隐变量进行联合建模,依然能够保持原模型的表达能力与稳定性,验证了该策略在复杂控制任务中的可行性与稳定性;进一步说明,在应对 PD 控制引发的非马尔可夫问题时,该方法能够有效融合高层隐变量结构,实现稳定控制策略的学习. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}