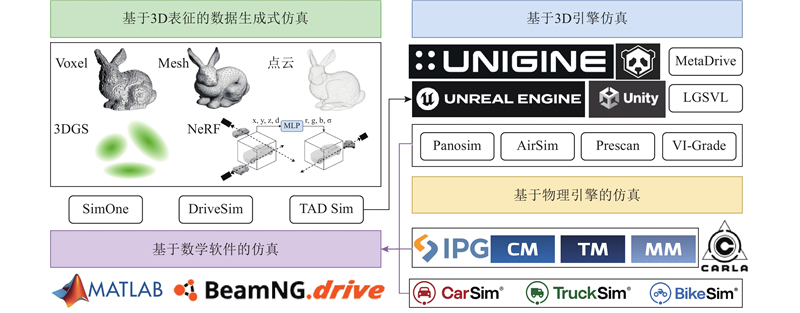
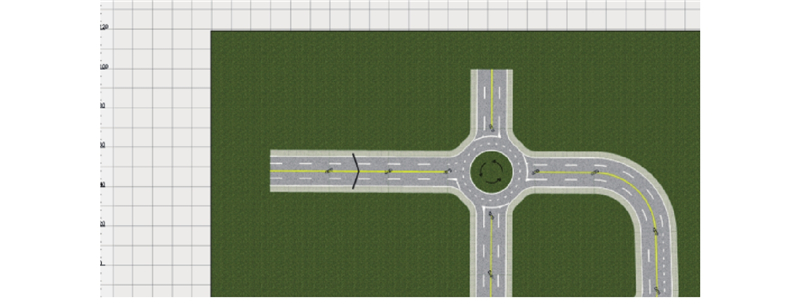
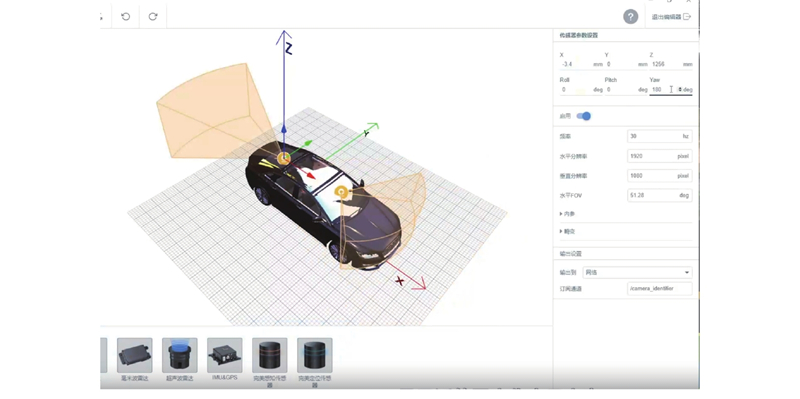
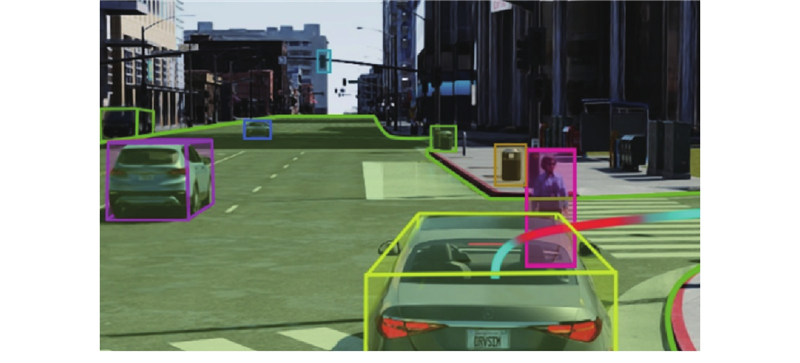
Autonomous driving simulation platforms play a vital role in the development, testing and validation of autonomous driving systems. A systematic review of the classification and key technical pathways of mainstream simulation platforms was presented, covering aspects such as environment modeling, sensor simulation, vehicle dynamics modeling, perception algorithm evaluation, V2X communication and cloud-based simulation. Core challenges and research progress related to synthetic data generation, cost-effective algorithm training, cross-domain generalization and platform scalability were analyzed, emphasizing simulation technologies based on computer vision and artificial intelligence. Future development trends were discussed. Simulation platforms are evolving toward higher realism, interactivity and closed-loop validation with the advancement of emerging technologies such as generative AI, neural rendering and multimodal learning, gradually forming a comprehensive pipeline that integrates data generation, algorithm training and performance evaluation. Simulation platforms will continue to play an essential role in enhancing the generalization capability of autonomous driving system, accelerating product deployment, and establishing standard testing and validation framework in the future.
LV Juntao, QI Jueyu, YU Haochen, MA Lei, MA Huimin, HU Tianyu. Current status and future prospect of integrated simulation platform for autonomous driving. Journal of Zhejiang University(Engineering Science)[J], 2026, 60(3): 513-526 doi:10.3785/j.issn.1008-973X.2026.03.007
SONG Y, ERMON S. Generative modeling by estimating gradients of the data distribution [EB/OL]. (2020-10-10)[2025-04-30]. https://arxiv.org/abs/1907.05600.
SONG Y, SOHL-DICKSTEIN J, KINGMA D P, et al. Score-based generative modeling through stochastic differential equations [EB/OL]. (2021-02-10)[2025-04-30]. https://arxiv.org/abs/2011.13456.
DONG R, HAN C, PENG Y, et al. DreamLLM: synergistic multimodal comprehension and creation [EB/OL]. (2024-03-15)[2025-04-30]. https://arxiv.org/abs/2309.11499.
PANAGOPOULOU A, XUE L, YU N, et al. X-InstructBLIP: a framework for aligning X-modal instruction-aware representations to LLMs and emergent cross-modal reasoning [EB/OL]. (2024-09-09)[2025-04-30]. https://arxiv.org/abs/2311.18799.
FENG T, WANG W, YANG Y. A survey on visual traffic simulation: Models, evaluations, and applications in autonomous driving [J]. Computer Graphics Forum, 2020, 39(1): 287-308.
SARKER S, MAPLES B, ISLAM I, et al. A comprehensive review on traffic datasets and simulators for autonomous vehicles [EB/OL]. (2025-04-14)[2025-04-30]. https://arxiv.org/abs/2412.14207.
RADFORD A, METZ L, CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks [EB/OL]. (2016-01-07) [2025-04-30]. https://arxiv.org/abs/1511.06434.
KARRAS T, LAINE S, AILA T. A style-based generator architecture for generative adversarial networks [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2020: 4396–4405.
RAMESH A, PAVLOV M, GOH G, et al. Zero-shot text-to-image generation [C]//International Conference on Machine Learning. [S. l. ]: PMLR, 2021: 8821-8831.
LIN C H, GAO J, TANG L, et al. Magic3D: high-resolution text-to-3D content creation [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 300–309.
ZHANG L, RAO A, AGRAWALA M. Adding conditional control to text-to-image diffusion models [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2024: 3813–3824.
LIU Y, ZHANG K, LI Y, et al. Sora: a review on background, technology, limitations, and opportunities of large vision models [EB/OL]. (2024-04-17) [2025-04-30]. https://arxiv.org/abs/2402.17177.
WANG X, MALEKI M A, AZHAR M W, et al. Moving forward: a review of autonomous driving software and hardware systems [EB/OL]. (2024-11-15) [2025-04-30]. https://arxiv.org/abs/2411.10291.
CHU Y J R, WEI T H, HUANG J B, et al. Sim-to-real transfer for miniature autonomous car racing [EB/OL]. (2020-11-11)[2025-04-30]. https://arxiv.org/abs/2011.05617.
ZHANG C, LIU Y, ZHAO D, et al. RoadView: a traffic scene simulator for autonomous vehicle simulation testing [C]//Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems. Qingdao: IEEE, 2014: 1160–1165.
TAN S, WONG K, WANG S, et al. SceneGen: learning to generate realistic traffic scenes [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 892–901.
WEI Y, WANG Z, LU Y, et al. Editable scene simulation for autonomous driving via collaborative LLM-agents [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 15077–15087.
HU A, RUSSELL L, YEO H, et al. Gaia-1: a generative world model for autonomous driving [EB/OL]. (2023-09-29)[2025-04-30]. https://arxiv.org/abs/2309.17080.
ZHAO G, NI C, WANG X, et al. DriveDreamer4D: world models are effective data machines for 4D driving scene representation [C]// Proceedings of the Computer Vision and Pattern Recognition Conference. Los Angeles: IEEE, 2025: 12015-12026.
LI X, ZHANG Y, YE X. DrivingDiffusion: layout-guided multi-view driving scenarios video generation with latent diffusion model [C]// European Conference on Computer Vision. Cham: Springer, 2024: 469-485.
MÜLLER N, SIMONELLI A, PORZI L, et al. AutoRF: learning 3D object radiance fields from single view observations [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 3961–3970.
YAN Y, LIN H, ZHOU C, et al. Street Gaussians: modeling dynamic urban scenes with Gaussian splatting [C]//European Conference on Computer Vision. Milan: Springer, 2024: 156-173.
ZHOU X, LIN Z, SHAN X, et al. DrivingGaussian: composite Gaussian splatting for surrounding dynamic autonomous driving scenes [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 21634-21643.
KHAN M, FAZLALI H, SHARMA D, et al. AutoSplat: constrained Gaussian splatting for autonomous driving scene reconstruction [C]//2025 IEEE International Conference on Robotics and Automation. Atlanta: IEEE, 2025: 8315-8321.
ZYRIANOV V, CHE H, LIU Z, et al. LidarDM: generative LiDAR simulation in a generated world [C]//2025 IEEE International Conference on Robotics and Automation. Seattle: IEEE, 2025: 6055-6062.
LI Y, LIN Z H, FORSYTH D, et al. Climatenerf: extreme weather synthesis in neural radiance field [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 3227-3238.
DAI Q, NI X, SHEN Q, et al. RainyGS: efficient rain synthesis with physically-based Gaussian splatting [C]//Proceedings of the Computer Vision and Pattern Recognition Conference. Los Angeles: IEEE, 2025: 16153-16162.
XIE Y, ZHANG M, HAO Q. ClimateGS: real-time climate simulation with 3D Gaussian style transfer [EB/OL]. (2025-03-19)[2025-04-30]. https://arxiv.org/abs/2503.14845.
CAESAR H, BANKITI V, LANG A H, et al. nuScenes: a multimodal dataset for autonomous driving [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 11618-11628.
SUN P, KRETZSCHMAR H, DOTIWALLA X, et al. Scalability in perception for autonomous driving: waymo open dataset [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 2443–2451.
IŞLER H. Comparison of electric (EV) and fossil fuel (gasoline-diesel) vehicles in terms of torque and power [EB/OL]. (2023-05-31) [2025-05-02]. https://www.researchgate.net/publication/370553199.
JHA S, TSAI T, HARI S, et al. Kayotee: a fault injection-based system to assess the safety and reliability of autonomous vehicles to faults and errors [EB/OL]. (2019-07-01)[2025-04-30]. https://arxiv.org/abs/1907.01024.
JHA S, BANERJEE S S, CYRIAC J, et al. AVFI: fault injection for autonomous vehicles [C]//Proceedings of the 48th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops. Luxembourg: IEEE, 2018: 55–56.
QUIGLEY M, CONLEY K, GERKEY B, et al. ROS: an open-source robot operating system [C]//Open-Source Software Workshop of the International Conference on Robotics and Automation. Kobe: IEEE, 2009: 5-6.
RONG G, SHIN B H, TABATABAEE H, et al. LGSVL simulator: a high fidelity simulator for autonomous driving [C]//Proceedings of the IEEE 23rd International Conference on Intelligent Transportation Systems. Rhodes: IEEE, 2020: 1–6.
DOSOVITSKIY A, ROS G, CODEVILLA F, et al. CARLA: an open urban driving simulator [C] // Proceedings of theConference on Robot Learning. Sydney: PMLR, 2017: 1-16.
XU X, LIU K, DAI P, et al. Enabling digital twin in vehicular edge computing: a multi-agent multi-objective deep reinforcement learning solution [EB/OL]. (2023-01-27)[2025-04-30]. https://arxiv.org/abs/2210.17386v1.
YANG X, WEN L, MA Y, et al. DriveArena: a closed-loop generative simulation platform for autonomous driving [EB/OL]. (2024-08-01)[2025-04-30]. https://arxiv.org/abs/2408.00415.
HUANG Z, SHENG Z, WAN Z, et al. Sky-drive: a distributed multi-agent simulation platform for human-AI collaborative and socially-aware future transportation [EB/OL]. (2025-04-25)[2025-04-30]. https://arxiv.org/abs/2504.18010.
JUNG H Y, PAEK D H, KONG S H. Open-source autonomous driving software platforms: comparison of autoware and Apollo [EB/OL]. (2025-01-31) [2025-04-30]. https://arxiv.org/abs/2501.18942.
EREZ T, TASSA Y, TODOROV E. Simulation tools for model-based robotics: comparison of bullet, havok, MuJoCo, ODE and PhysX [C]//Proceedings of the IEEE International Conference on Robotics and Automation. Seattle: IEEE, 2015: 4397–4404.
RAO V, JAIN N, RANA P, et al. Game development using Panda 3D game engine [J]. International Journal on Recent and Innovation Trends in Computing and Communication, 3(2): 534-536.
HENRICH V, REUTER T. CarDriver: using Python and Panda3D to construct a virtual environment for teaching driving [EB/OL]. (2008-12-31) [2025-04-30]. https://api.semanticscholar.org/CorpusID:109635468.
SHAH S, DEY D, LOVETT C, et al. Airsim: high-fidelity visual and physical simulation for autonomous vehicles [C] // Conference on Field and Service Robotics. Zurich: Springer, 2017: 621-635.
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779-788.
SARDA A, DIXIT S, BHAN A. Object detection for autonomous driving using YOLO [you only look once] algorithm [C]//Proceedings of the 3rd International Conference on Intelligent Communication Technologies and Virtual Mobile Networks. Tirunelveli: IEEE, 2021: 1370–1374.
CAO Y, LI C, PENG Y, et al
MCS-YOLO: a multiscale object detection method for autonomous driving road environment recognition
WEI Y, ZHAO L, ZHENG W, et al. Surroundocc: multi-camera 3d occupancy prediction for autonomous driving [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 21729-21740.
Occ3D: a large-scale 3D occupancy prediction benchmark for autonomous driving
[J]. Advances in Neural Information Processing Systems, 2023, 36: 64318- 64330
ZHENG W, CHEN W, HUANG Y, et al. Occworld: learning a 3d occupancy world model for autonomous driving [C]//European Conference on Computer Vision. Milan: Springer, 2024: 55-72.
YANG Z, CHEN Y, WANG J, et al. Unisim: a neural closed-loop sensor simulator [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 1389- 1399.
MILDENHALL B, SRINIVASAN P P, TANCIK M, et al. NeRF: representing scenes as neural radiance fields for view synthesis [C]//European Conference on Computer Vision. [S. l. ]: Springer, 2020: 405-421.
WU Z, LIU T, LUO L, et al. Mars: an instance-aware, modular and realistic simulator for autonomous driving [C]// International Conference on Artificial Intelligence. Singapore: Springer, 2023: 3-15.
YANG J, IVANOVIC B, LITANY O, et al. EmerNeRF: emergent spatial-temporal scene decomposition via self-supervision [EB/OL]. (2023-11-03)[2025-04-30]. https://arxiv.org/abs/2311.02077.
ZHAO W, QUERALTA J P, WESTERLUND T. Sim-to-real transfer in deep reinforcement learning for robotics: a survey [C]//2020 IEEE Symposium Series on Computational Intelligence. Canberra: IEEE, 2020: 737-744.
AKHAURI S, ZHENG L, LIN M C. Enhanced transfer learning for autonomous driving with systematic accident simulation [C]//IEEE/RSJ International Conference on Intelligent Robots and Systems. Las Vegas: IEEE, 2020: 5986–5993.
AKHAURI S, ZHENG L, GOLDSTEIN T, et al. Improving generalization of transfer learning across domains using spatio-temporal features in autonomous driving [EB/OL]. (2021-09-23)[2025-04-30]. https://arxiv.org/abs/2103.08116.
TAN J, ZHANG T, COUMANS E, et al. Sim-to-real: learning agile locomotion for quadruped robots [EB/OL]. (2018-05-16)[2025-04-30]. https://arxiv.org/abs/1804.10332.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}