[1]
JACOBI A, CHUNG M, BERNHEIM A, et al. Portable chest X-ray in coronavirus disease-19 (COVID-19): a pictorial review
[J]. Clinical Imaging , 2020 , 64 (8 ): 35 - 42
[本文引用: 1]
[2]
HEIDARI A, NAVIMIPOUR N J, UNAL M, et al. The COVID-19 epidemic analysis and diagnosis using deep learning: a asystematic literature review and future directions
[J]. Computers in Biology and Medicine , 2022 , 141 : 105141
DOI:10.1016/j.compbiomed.2021.105141
[本文引用: 1]
[3]
郑光远, 刘峡壁, 韩光辉 医学影像计算机辅助检测与诊断系统综述
[J]. 软件学报 , 2018 , 29 (5 ): 1471 - 1514
[本文引用: 1]
ZHENG Guangyuan, LIU Xiabi, HAN Guanghui Survey on medical image computer aided detection and diagnosis systems
[J]. Journal of Software , 2018 , 29 (5 ): 1471 - 1514
[本文引用: 1]
[4]
CHEN J T, YU H Y, FENG R W, et al. Flow-Mixup: classifying multi-labeled medical images with corrupted labels [C]// IEEE International Conference on Bioinformatics and Biomedicine. Seoul: IEEE, 2020: 534-541.
[本文引用: 1]
[5]
ANWAR S M, MAJID M, QAYYUM A, et al. Medical image analysis using convolutional neural networks: a review
[J]. Journal of Medical Systems , 2018 , 42 (11 ): 226
DOI:10.1007/s10916-018-1088-1
[本文引用: 1]
[6]
YI X, WALIA E, BABYN P Generative adversarial network in medical imaging: a review
[J]. Medical Image Analysis , 2019 , 58 : 101552
DOI:10.1016/j.media.2019.101552
[7]
ZHOU S K, LE H N, LUU K, et al. Deep reinforcement learning in medical imaging: a literature review
[J]. Medical Image Analysis , 2021 , 73 : 102193
DOI:10.1016/j.media.2021.102193
[本文引用: 1]
[8]
LI Q, LAI Y, ADAMU MJ Multi-level residual feature fusion network for thoracic disease classification in chest x-ray images
[J]. IEEE Access , 2023 , 11 (11 ): 40988 - 41002
[本文引用: 1]
[9]
胡锦波, 聂为之, 宋丹, 等 可形变Transformer辅助的胸部X光影像疾病诊断模型
[J]. 浙江大学学报: 工学版 , 2023 , 57 (10 ): 1923 - 1932
[本文引用: 1]
HU Jinbo, NIE Weizhi, SONG Dan, et al. Chest X-ray imaging disease diagnosis model assisted by deformable Transformer
[J]. Journal of Zhejiang University: Engineering Science , 2023 , 57 (10 ): 1923 - 1932
[本文引用: 1]
[10]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . [S. l.]: Curran Associates, 2017: 6000-6010.
[本文引用: 1]
[11]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale [EB/OL]. (2021-06-03) [2023-08-05]. https://arxiv.org/pdf/2010.11929.pdf.
[本文引用: 1]
[12]
LIU Z, LIN Y T, CAO Y, et al. Swin Transformer: hierarchical vision Transformer using shifted windows [C]// IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 9992-10002.
[本文引用: 3]
[13]
WU K, PENG H W, CHEN M H, et al. Rethinking and improving relative position encoding for vision [C]// IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 10013-10021.
[本文引用: 1]
[14]
ZHU K, WU J K. Residual attention: a simple but effective method for multi-label recognition [C]// IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 184-193.
[本文引用: 1]
[15]
WANG X S, PENG Y F, LU L, et al. ChestX-ray8: hospital-scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases [C]// 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 3462-3471.
[本文引用: 4]
[16]
IRVIN J, RAJPURKAR P, KO M, et al. CheXpert: a large chest radiograph dataset with uncertainty labels and expert comparison [C]// 33rd AAAI Conference on Artificial Intelligence. Honolulu: AAAI, 2019: 590-597.
[本文引用: 4]
[17]
JOHNSON A E W, POLLARD T J, BERKOWITZ S J, et al. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports
[J]. Scientific Data , 2019 , 6 (1 ): 317
DOI:10.1038/s41597-019-0322-0
[本文引用: 2]
[18]
CHEN B Z, LI J X, GUO X B, et al. DualCheXNet: dual asymmetric feature learning for thoracic disease classification in chest X-rays
[J]. Biomedical Signal Processing and Control , 2019 , 53 : 101554
DOI:10.1016/j.bspc.2019.04.031
[本文引用: 1]
[19]
WANG H Y, WANG S S, QIN Z B, et al. Triple attention learning for classification of 14 thoracic diseases using chest radiography
[J]. Medical Image Analysis , 2021 , 67 (1 ): 8415 - 8423
[本文引用: 2]
[20]
CHEN K, WANG X Q, ZHANG S W Thorax disease classification based on pyramidal convolution shuffle attention neural network
[J]. IEEE Access , 2022 , 10 : 85571 - 85581
DOI:10.1109/ACCESS.2022.3198958
[本文引用: 2]
[21]
CHEN B Z, ZHANG Z, LI Y Z, et al. Multi-label chest X-ray image classification via semantic similarity graph embedding
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2022 , 32 (4 ): 2455 - 2468
DOI:10.1109/TCSVT.2021.3079900
[本文引用: 3]
[22]
JIANG X B, ZHU Y, GAI G, et al. MXT: a new variant of pyramid vision Transformer for multi-label chest X-ray image classification
[J]. Cognitive Computation , 2022 , 14 (4 ): 1362 - 1377
DOI:10.1007/s12559-022-10032-4
[本文引用: 1]
[23]
PAN X R, GE C J, LU R, et al. On the integration of self-attention and convolution [C]// IEEE Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 805-815.
[本文引用: 1]
[24]
HU J, SHEN L, SU G. Squeeze-and-Excitation networks [C]// 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132-7141.
[本文引用: 1]
[25]
LIN T, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2020 , 42 (2 ): 318 - 327
DOI:10.1109/TPAMI.2018.2858826
[本文引用: 1]
[26]
PASZKE A, GROSS S, MASSA F, et al. PyTorch: an imperative style, high-performance deep learning library [C]// 33rd Conference on Neural Information Processing Systems . Vancouver: [s. n. ], 2019: 32.
[本文引用: 1]
[27]
PHAM H H, LE T T, TRAN D Q, et al. Interpreting chest X-rays via CNNs that exploit hierarchical disease dependencies and uncertainty labels
[J]. Neurocomputing , 2021 , 437 : 186 - 194
DOI:10.1016/j.neucom.2020.03.127
[本文引用: 1]
[28]
JIANG X B, ZHU Y, LIU Y T, et al TransDD: a transformer-based dual-path decoder for improving the performance of thoracic diseases classification using chest X-ray
[J]. Biomedical Signal Processing and Control , 2024 , 91 : 13
[本文引用: 1]
[29]
ZHU X F, PANG S M, ZHANG X X, et al. PCAN: pixel-wise classification and attention network for thoracic disease classification and weakly supervised localization
[J]. Computerized Medical Imaging and Graphics , 2022 , 102 : 102137
DOI:10.1016/j.compmedimag.2022.102137
[本文引用: 2]
[30]
SUN Z X, QU L H, LUO J Z, et al Label correlation transformer for automated chest X-ray diagnosis with reliable interpretability
[J]. Radiologia Medica , 2023 , 128 (6 ): 726 - 733
DOI:10.1007/s11547-023-01647-0
[本文引用: 1]
[31]
LEE Y W, HUANG S K, CHANG R F CheXGAT: a disease correlation-aware network for thorax disease diagnosis from chest X-ray images
[J]. Artificial Intelligence in Medicine , 2022 , 132 : 102382
DOI:10.1016/j.artmed.2022.102382
[本文引用: 1]
[32]
XIAO J F, BAI Y T, YUILLE A, et al. Delving into masked autoencoders for multi-label thorax disease classification [C]// IEEE/CVF Winter Conference on Applications of Computer Vision. Waikoloa: IEEE, 2023: 3577-3589.
[本文引用: 1]
[33]
LIU Z, CHENG Y Z, TAMURA S Multi-label local to global learning: a novel learning paradigm for chest x-ray abnormality classification
[J]. IEEE Journal of Biomedical and Health Informatics , 2023 , 27 (9 ): 4409 - 4420
DOI:10.1109/JBHI.2023.3281466
[本文引用: 1]
[34]
ZHU X F, FENG Q. MVC-NET: multi-view chest radiograph classification network with deep fusion [C]// 18th IEEE International Symposium on Biomedical Imaging. Nice: IEEE, 2021: 554-558.
[本文引用: 1]
[35]
JACENKOW G, O'NEIL A Q, TSAFTARIS S A. Indication as prior knowledge for multimodal disease classification in chest radiographs with transformers [C]// IEEE International Symposium on Biomedical Imaging. Kolkata: IEEE, 2022.
[本文引用: 1]
[36]
SEIBOLD C, REISS S, SARFRAZ M S, et al. Breaking with fixed set pathology recognition through report-guided contrastive training [C]// Medical Image Computing and Computer Assisted Intervention. Singapore: Springer, 2022, 13435: 690-700.
[本文引用: 1]
[37]
CHEN B, LI J, LU G, et al Label co-occurrence learning with graph convolutional networks for multi-label chest x-ray image classification
[J]. IEEE Journal of Biomedical and Health Informatics , 2020 , 24 (8 ): 2292 - 2302
DOI:10.1109/JBHI.2020.2967084
[本文引用: 1]
[38]
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization
[J]. International Journal of Computer Vision , 2020 , 128 (2 ): 336 - 359
DOI:10.1007/s11263-019-01228-7
[本文引用: 1]
al. Portable chest X-ray in coronavirus disease-19 (COVID-19): a pictorial review
1
2020
... 胸部X光(chest X-Ray,CXR)影像,俗称胸片,是目前应用最广泛的医学成像技术之一. 在新冠肺炎疫情期间,每天都有大量的胸片被拍摄出来[1 -2 ] ,大量的诊断工作对放射科医生的数量、技术水平和专注力有很高的要求. 随着深度学习技术的发展,计算机辅助诊断技术变得更加成熟[3 ] ,能够帮助医生更好地分析医学图像. ...
al. The COVID-19 epidemic analysis and diagnosis using deep learning: a asystematic literature review and future directions
1
2022
... 胸部X光(chest X-Ray,CXR)影像,俗称胸片,是目前应用最广泛的医学成像技术之一. 在新冠肺炎疫情期间,每天都有大量的胸片被拍摄出来[1 -2 ] ,大量的诊断工作对放射科医生的数量、技术水平和专注力有很高的要求. 随着深度学习技术的发展,计算机辅助诊断技术变得更加成熟[3 ] ,能够帮助医生更好地分析医学图像. ...
医学影像计算机辅助检测与诊断系统综述
1
2018
... 胸部X光(chest X-Ray,CXR)影像,俗称胸片,是目前应用最广泛的医学成像技术之一. 在新冠肺炎疫情期间,每天都有大量的胸片被拍摄出来[1 -2 ] ,大量的诊断工作对放射科医生的数量、技术水平和专注力有很高的要求. 随着深度学习技术的发展,计算机辅助诊断技术变得更加成熟[3 ] ,能够帮助医生更好地分析医学图像. ...
医学影像计算机辅助检测与诊断系统综述
1
2018
... 胸部X光(chest X-Ray,CXR)影像,俗称胸片,是目前应用最广泛的医学成像技术之一. 在新冠肺炎疫情期间,每天都有大量的胸片被拍摄出来[1 -2 ] ,大量的诊断工作对放射科医生的数量、技术水平和专注力有很高的要求. 随着深度学习技术的发展,计算机辅助诊断技术变得更加成熟[3 ] ,能够帮助医生更好地分析医学图像. ...
1
... 胸部疾病的诊断是多标签分类问题[4 ] ,由于CXR图像通常包含多个病理标签,这些病变部位在不同的阶段拥有不同的大小、形状和纹理表现[5 -7 ] . 为了提高分类性能,Li等[8 -9 ] 基于卷积神经网络(convolut-ional neural networks,CNN)作出了很多尝试. 胸部疾病的病理间常常存在交叉重叠和互相影响的情况. 卷积运算存在难以捕捉长距离视觉和语义信息的缺点,不能完全满足CXR图像分析的需要. 对于这一缺陷,自注意力机制[10 -11 ] 可以通过动态计算相关像素间的关系来自适应地关注不同的区域,捕获更多的信息特征. 全局自注意力的计算复杂度与图像大小为二次关系,计算成本很高,局部特征提取能力较弱. ...
al. Medical image analysis using convolutional neural networks: a review
1
2018
... 胸部疾病的诊断是多标签分类问题[4 ] ,由于CXR图像通常包含多个病理标签,这些病变部位在不同的阶段拥有不同的大小、形状和纹理表现[5 -7 ] . 为了提高分类性能,Li等[8 -9 ] 基于卷积神经网络(convolut-ional neural networks,CNN)作出了很多尝试. 胸部疾病的病理间常常存在交叉重叠和互相影响的情况. 卷积运算存在难以捕捉长距离视觉和语义信息的缺点,不能完全满足CXR图像分析的需要. 对于这一缺陷,自注意力机制[10 -11 ] 可以通过动态计算相关像素间的关系来自适应地关注不同的区域,捕获更多的信息特征. 全局自注意力的计算复杂度与图像大小为二次关系,计算成本很高,局部特征提取能力较弱. ...
Generative adversarial network in medical imaging: a review
0
2019
al. Deep reinforcement learning in medical imaging: a literature review
1
2021
... 胸部疾病的诊断是多标签分类问题[4 ] ,由于CXR图像通常包含多个病理标签,这些病变部位在不同的阶段拥有不同的大小、形状和纹理表现[5 -7 ] . 为了提高分类性能,Li等[8 -9 ] 基于卷积神经网络(convolut-ional neural networks,CNN)作出了很多尝试. 胸部疾病的病理间常常存在交叉重叠和互相影响的情况. 卷积运算存在难以捕捉长距离视觉和语义信息的缺点,不能完全满足CXR图像分析的需要. 对于这一缺陷,自注意力机制[10 -11 ] 可以通过动态计算相关像素间的关系来自适应地关注不同的区域,捕获更多的信息特征. 全局自注意力的计算复杂度与图像大小为二次关系,计算成本很高,局部特征提取能力较弱. ...
Multi-level residual feature fusion network for thoracic disease classification in chest x-ray images
1
2023
... 胸部疾病的诊断是多标签分类问题[4 ] ,由于CXR图像通常包含多个病理标签,这些病变部位在不同的阶段拥有不同的大小、形状和纹理表现[5 -7 ] . 为了提高分类性能,Li等[8 -9 ] 基于卷积神经网络(convolut-ional neural networks,CNN)作出了很多尝试. 胸部疾病的病理间常常存在交叉重叠和互相影响的情况. 卷积运算存在难以捕捉长距离视觉和语义信息的缺点,不能完全满足CXR图像分析的需要. 对于这一缺陷,自注意力机制[10 -11 ] 可以通过动态计算相关像素间的关系来自适应地关注不同的区域,捕获更多的信息特征. 全局自注意力的计算复杂度与图像大小为二次关系,计算成本很高,局部特征提取能力较弱. ...
可形变Transformer辅助的胸部X光影像疾病诊断模型
1
2023
... 胸部疾病的诊断是多标签分类问题[4 ] ,由于CXR图像通常包含多个病理标签,这些病变部位在不同的阶段拥有不同的大小、形状和纹理表现[5 -7 ] . 为了提高分类性能,Li等[8 -9 ] 基于卷积神经网络(convolut-ional neural networks,CNN)作出了很多尝试. 胸部疾病的病理间常常存在交叉重叠和互相影响的情况. 卷积运算存在难以捕捉长距离视觉和语义信息的缺点,不能完全满足CXR图像分析的需要. 对于这一缺陷,自注意力机制[10 -11 ] 可以通过动态计算相关像素间的关系来自适应地关注不同的区域,捕获更多的信息特征. 全局自注意力的计算复杂度与图像大小为二次关系,计算成本很高,局部特征提取能力较弱. ...
可形变Transformer辅助的胸部X光影像疾病诊断模型
1
2023
... 胸部疾病的诊断是多标签分类问题[4 ] ,由于CXR图像通常包含多个病理标签,这些病变部位在不同的阶段拥有不同的大小、形状和纹理表现[5 -7 ] . 为了提高分类性能,Li等[8 -9 ] 基于卷积神经网络(convolut-ional neural networks,CNN)作出了很多尝试. 胸部疾病的病理间常常存在交叉重叠和互相影响的情况. 卷积运算存在难以捕捉长距离视觉和语义信息的缺点,不能完全满足CXR图像分析的需要. 对于这一缺陷,自注意力机制[10 -11 ] 可以通过动态计算相关像素间的关系来自适应地关注不同的区域,捕获更多的信息特征. 全局自注意力的计算复杂度与图像大小为二次关系,计算成本很高,局部特征提取能力较弱. ...
1
... 胸部疾病的诊断是多标签分类问题[4 ] ,由于CXR图像通常包含多个病理标签,这些病变部位在不同的阶段拥有不同的大小、形状和纹理表现[5 -7 ] . 为了提高分类性能,Li等[8 -9 ] 基于卷积神经网络(convolut-ional neural networks,CNN)作出了很多尝试. 胸部疾病的病理间常常存在交叉重叠和互相影响的情况. 卷积运算存在难以捕捉长距离视觉和语义信息的缺点,不能完全满足CXR图像分析的需要. 对于这一缺陷,自注意力机制[10 -11 ] 可以通过动态计算相关像素间的关系来自适应地关注不同的区域,捕获更多的信息特征. 全局自注意力的计算复杂度与图像大小为二次关系,计算成本很高,局部特征提取能力较弱. ...
1
... 胸部疾病的诊断是多标签分类问题[4 ] ,由于CXR图像通常包含多个病理标签,这些病变部位在不同的阶段拥有不同的大小、形状和纹理表现[5 -7 ] . 为了提高分类性能,Li等[8 -9 ] 基于卷积神经网络(convolut-ional neural networks,CNN)作出了很多尝试. 胸部疾病的病理间常常存在交叉重叠和互相影响的情况. 卷积运算存在难以捕捉长距离视觉和语义信息的缺点,不能完全满足CXR图像分析的需要. 对于这一缺陷,自注意力机制[10 -11 ] 可以通过动态计算相关像素间的关系来自适应地关注不同的区域,捕获更多的信息特征. 全局自注意力的计算复杂度与图像大小为二次关系,计算成本很高,局部特征提取能力较弱. ...
3
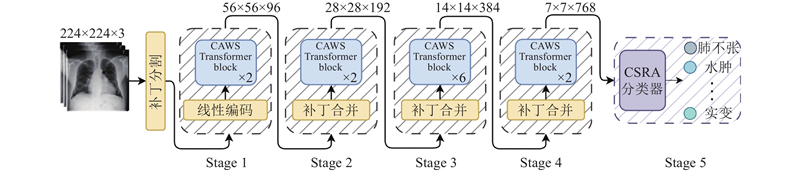
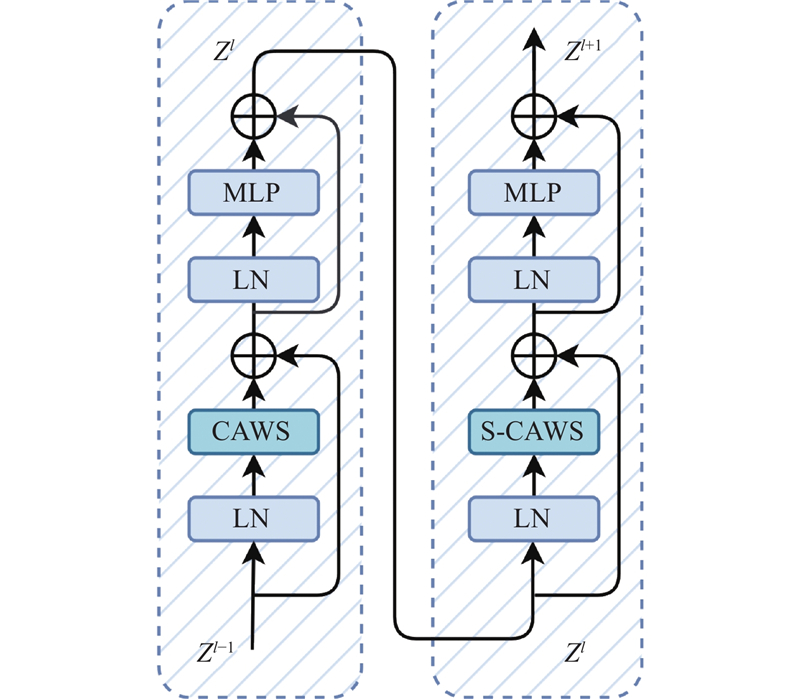
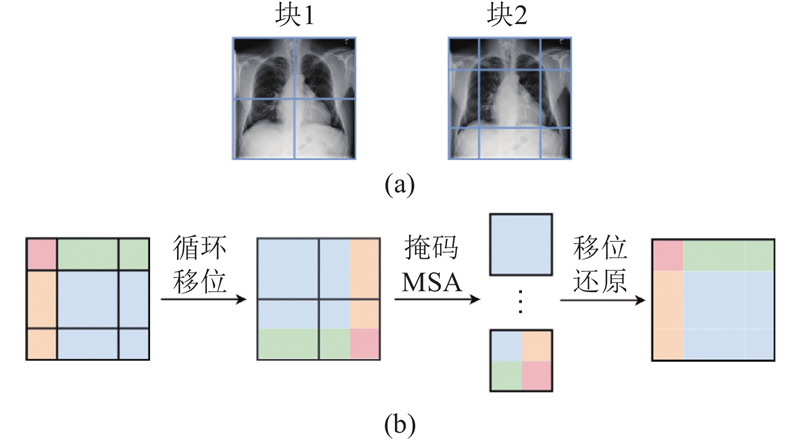
... 针对以上问题,本文提出基于卷积辅助窗口自注意力(convolution-assisted window self-attention,CAWS)的胸部X光影像疾病分类网络,命名为CAWSNet. 针对卷积运算容易丢失CXR图像中的长距离视觉语义信息的缺点,选择以Swin Transformer[12 ] 为骨干网络,利用窗口自注意力,实现对较大区域的关注,建模长距离依赖关系. 在窗口自注意力中以轻量的方法引入卷积,提出全新的卷积辅助窗口自注意力模块,强化网络对CXR图像局部纹理、轮廓的特征提取能力,弥补窗口自注意力的缺陷. 引入通过有向映射计算相对位置,利用动态变化的图像相对位置编码(image relative position encoding,IRPE)[13 ] 配合自注意力的分窗计算. 使用类别残差注意力(class-specific residual attention, CSRA)[14 ] 优化分类器,提高针对多种病理的分类能力. 此外,针对疾病样本不均匀,分类难度差异较大的问题,提出动态难度损失函数,优化网络对计算资源的分配. 在ChestX-ray14[15 ] 、CheXpert[16 ] 和MIMIC-CXR-JPG[17 ] 3个公开数据集上的实验结果以及与多种先进方法的评估分析,验证了所提出网络的性能. 工作代码已经公开,代码链接为:https://github.com/ZhangZr11/CAWSNet.git. ...
... 在目前主流的方法中,特征提取的任务大多是由卷积神经网络来完成. 随着视觉Transformer的兴起,Jiang等[22 ] 提出金字塔视觉Transformer的新变体实现胸部疾病分类,该网络通过自注意力捕获长距离视觉信息,使用下采样空间缩减注意力,减少使用全局自注意力的资源消耗. Liu等[12 ] 提出新的视觉网络Swin Transformer,使用窗口自注意力处理特征图,令计算复杂度与图像大小成线性关系,提出移位窗口方法,弥补分窗计算带来的信息丢失,在图像分类和目标检测领域取得了优秀的效果. 上述方法虽然在胸部疾病分类任务中取得了优秀的效果,但都无法在特征提取阶段很好地兼顾局部特征和长距离视觉依赖关系,导致有效信息的丢失. 以Swin Transformer为骨干网络,引入卷积作为辅助,提出基于卷积辅助窗口自注意力的胸部X光影像疾病分类网络CAWSNet. 使用自注意力和卷积,互补地提取CXR图像特征,获得更加优秀的分类性能. ...
... Comparison of computational complexity of different chest disease classification network
Tab.9 网络 FLOPs/109 t inf /s平均AUC SSGE[21 ] 17.74 0.059 0.830 CheXGCN[37 ] 17.86 0.061 0.826 PCAN[29 ] 3.92 0.054 0.830 Swin Trans[12 ] 4.37 0.013 0.837 CAWSNet 4.52 0.018 0.853
从表9 可以看出,CAWSNet的推理时间较短,可以快速地处理单张CXR图像,FLOPs较小,与Swin Transformer骨干网络相比只增加0.15×109 ,但性能有显著提升. 利用CAWS模块共享部分权重来实现卷积和窗口自注意力并行计算的方法,可以有效地节约计算资源. 综合来说,网络较好地平衡了分类准确度和计算复杂度,在胸部疾病诊断算法中具有较强的竞争力. ...
1
... 针对以上问题,本文提出基于卷积辅助窗口自注意力(convolution-assisted window self-attention,CAWS)的胸部X光影像疾病分类网络,命名为CAWSNet. 针对卷积运算容易丢失CXR图像中的长距离视觉语义信息的缺点,选择以Swin Transformer[12 ] 为骨干网络,利用窗口自注意力,实现对较大区域的关注,建模长距离依赖关系. 在窗口自注意力中以轻量的方法引入卷积,提出全新的卷积辅助窗口自注意力模块,强化网络对CXR图像局部纹理、轮廓的特征提取能力,弥补窗口自注意力的缺陷. 引入通过有向映射计算相对位置,利用动态变化的图像相对位置编码(image relative position encoding,IRPE)[13 ] 配合自注意力的分窗计算. 使用类别残差注意力(class-specific residual attention, CSRA)[14 ] 优化分类器,提高针对多种病理的分类能力. 此外,针对疾病样本不均匀,分类难度差异较大的问题,提出动态难度损失函数,优化网络对计算资源的分配. 在ChestX-ray14[15 ] 、CheXpert[16 ] 和MIMIC-CXR-JPG[17 ] 3个公开数据集上的实验结果以及与多种先进方法的评估分析,验证了所提出网络的性能. 工作代码已经公开,代码链接为:https://github.com/ZhangZr11/CAWSNet.git. ...
1
... 针对以上问题,本文提出基于卷积辅助窗口自注意力(convolution-assisted window self-attention,CAWS)的胸部X光影像疾病分类网络,命名为CAWSNet. 针对卷积运算容易丢失CXR图像中的长距离视觉语义信息的缺点,选择以Swin Transformer[12 ] 为骨干网络,利用窗口自注意力,实现对较大区域的关注,建模长距离依赖关系. 在窗口自注意力中以轻量的方法引入卷积,提出全新的卷积辅助窗口自注意力模块,强化网络对CXR图像局部纹理、轮廓的特征提取能力,弥补窗口自注意力的缺陷. 引入通过有向映射计算相对位置,利用动态变化的图像相对位置编码(image relative position encoding,IRPE)[13 ] 配合自注意力的分窗计算. 使用类别残差注意力(class-specific residual attention, CSRA)[14 ] 优化分类器,提高针对多种病理的分类能力. 此外,针对疾病样本不均匀,分类难度差异较大的问题,提出动态难度损失函数,优化网络对计算资源的分配. 在ChestX-ray14[15 ] 、CheXpert[16 ] 和MIMIC-CXR-JPG[17 ] 3个公开数据集上的实验结果以及与多种先进方法的评估分析,验证了所提出网络的性能. 工作代码已经公开,代码链接为:https://github.com/ZhangZr11/CAWSNet.git. ...
4
... 针对以上问题,本文提出基于卷积辅助窗口自注意力(convolution-assisted window self-attention,CAWS)的胸部X光影像疾病分类网络,命名为CAWSNet. 针对卷积运算容易丢失CXR图像中的长距离视觉语义信息的缺点,选择以Swin Transformer[12 ] 为骨干网络,利用窗口自注意力,实现对较大区域的关注,建模长距离依赖关系. 在窗口自注意力中以轻量的方法引入卷积,提出全新的卷积辅助窗口自注意力模块,强化网络对CXR图像局部纹理、轮廓的特征提取能力,弥补窗口自注意力的缺陷. 引入通过有向映射计算相对位置,利用动态变化的图像相对位置编码(image relative position encoding,IRPE)[13 ] 配合自注意力的分窗计算. 使用类别残差注意力(class-specific residual attention, CSRA)[14 ] 优化分类器,提高针对多种病理的分类能力. 此外,针对疾病样本不均匀,分类难度差异较大的问题,提出动态难度损失函数,优化网络对计算资源的分配. 在ChestX-ray14[15 ] 、CheXpert[16 ] 和MIMIC-CXR-JPG[17 ] 3个公开数据集上的实验结果以及与多种先进方法的评估分析,验证了所提出网络的性能. 工作代码已经公开,代码链接为:https://github.com/ZhangZr11/CAWSNet.git. ...
... 随着深度学习技术的发展,计算机视觉领域取得了许多突破性的进展,其中包括各种医学图像处理任务. 公开数据集ChestX-ray14、CheXpert和MIMIC-CXR-JPG的发表,使得越来越多的研究者将目光投向胸部疾病分类这一多标签分类任务上. Wang等[15 ] 使用AlexNet、ResNet、VGGNet和GooGLeNet 4个经典的CNN架构,在ChestX-ray14数据集上进行胸部疾病分类的研究,其中ResNet的分类效果最突出. Chen等[18 ] 提出双不对称特征学习网络DualCheXNet,结合基于ResNet和DenseNet的2个非对称子网络,以便从原始CXR图像中不对称地学习互补特征,用于多标签胸部疾病分类. Wang等[19 ] 提出三重注意力学习网络A3 Net,使用预训练的DenseNet-121作为骨干网络进行特征提取,将通道、像素和尺度3种注意力集成在统一的框架中,分别关注特征图的通道、病变区域和不同尺度,更好地完成疾病分类任务. Chen等[20 ] 提出基于金字塔卷积模块和Shuffle注意力模块的残差网络. 其中,金字塔卷积模块用于提取病理异常的多尺度判别特征,而Shuffle注意力模块通过分组整合空间和通道注意力,显著提升了对病变区域的聚焦效果. Chen等[21 ] 提出新的语义相似图嵌入框架,该网络根据批量CXR图像的语义标签生成相似性图,以此为依据,使用图卷积网络自适应地重新校准从CNN网络提取的视觉特征,提高多标签CXR图像分类的性能. ...
... ChestX-Ray14[15 ] 包含14种病理的112 120张正面X光影像. 除了60 361张标记为“无发现”的图像外,每张图像都被指定为14种病理中的一种或多种,且880张图像对8种类型的病理进行了984个标记边界框的注释. 为了公平起见,对于实验中的数据集分割,严格遵循Wang等[15 ] 公布的官方数据集分割标准. ...
... [15 ]公布的官方数据集分割标准. ...
4
... 针对以上问题,本文提出基于卷积辅助窗口自注意力(convolution-assisted window self-attention,CAWS)的胸部X光影像疾病分类网络,命名为CAWSNet. 针对卷积运算容易丢失CXR图像中的长距离视觉语义信息的缺点,选择以Swin Transformer[12 ] 为骨干网络,利用窗口自注意力,实现对较大区域的关注,建模长距离依赖关系. 在窗口自注意力中以轻量的方法引入卷积,提出全新的卷积辅助窗口自注意力模块,强化网络对CXR图像局部纹理、轮廓的特征提取能力,弥补窗口自注意力的缺陷. 引入通过有向映射计算相对位置,利用动态变化的图像相对位置编码(image relative position encoding,IRPE)[13 ] 配合自注意力的分窗计算. 使用类别残差注意力(class-specific residual attention, CSRA)[14 ] 优化分类器,提高针对多种病理的分类能力. 此外,针对疾病样本不均匀,分类难度差异较大的问题,提出动态难度损失函数,优化网络对计算资源的分配. 在ChestX-ray14[15 ] 、CheXpert[16 ] 和MIMIC-CXR-JPG[17 ] 3个公开数据集上的实验结果以及与多种先进方法的评估分析,验证了所提出网络的性能. 工作代码已经公开,代码链接为:https://github.com/ZhangZr11/CAWSNet.git. ...
... CheXpert[16 ] 包含65 240例患者的224 316次X光影像结果,其中14次观察结果摘自医学报告. 每种疾病的观测值被指定为正(1)、负(0)或不确定(−1). CheXpert的验证集由200张X光影像组成,由3名委员会认证的放射科医生手工注释. 在验证集上,通过“肺不张”、“心脏扩大”、“实变”、“水肿”和“胸腔积液”这5个观察结果来评估性能[16 ] . ...
... [16 ]. ...
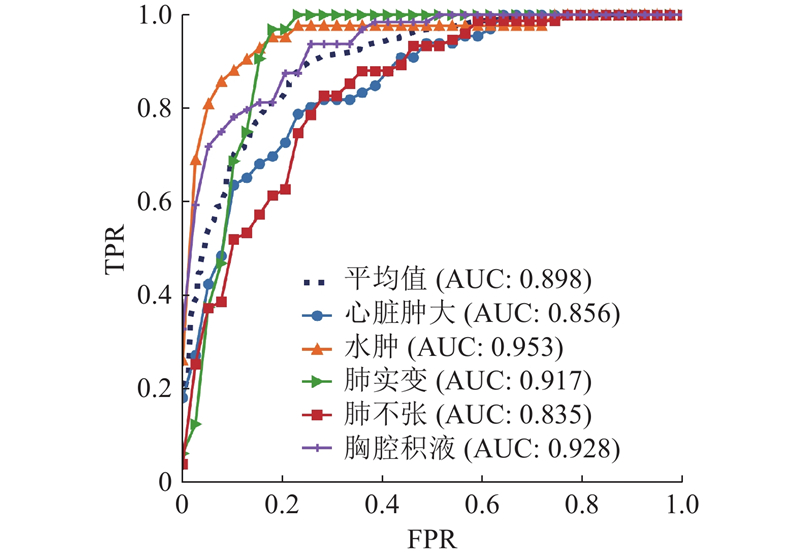
... 针对CheXpert数据集,Irvin等[16 ] 提出3种策略来处理其中的不确定标签:U-Ignore、U-Ones和U-Zeros,即将不确定标签去除、视为患病和视为非患病. 当CAWSNet采取U-Ones策略时取得了最佳的分类效果,故在CheXpert验证集的实验中均将不确定标签视为患病. 从表2 的对比结果可以得到以下结论. 1)相较于其他的SOTA方法,CAWSNet对于5种疾病分类的平均AUC为0.898,取得了最好的整体分类效果. 2)在单一疾病分类上,网络对于水肿(0.953)的诊断效果达到了最先进的水平,对于胸腔积液(0.928)和心脏肿大(0.856)2种疾病的诊断效果接近最优. ...
al. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports
2
2019
... 针对以上问题,本文提出基于卷积辅助窗口自注意力(convolution-assisted window self-attention,CAWS)的胸部X光影像疾病分类网络,命名为CAWSNet. 针对卷积运算容易丢失CXR图像中的长距离视觉语义信息的缺点,选择以Swin Transformer[12 ] 为骨干网络,利用窗口自注意力,实现对较大区域的关注,建模长距离依赖关系. 在窗口自注意力中以轻量的方法引入卷积,提出全新的卷积辅助窗口自注意力模块,强化网络对CXR图像局部纹理、轮廓的特征提取能力,弥补窗口自注意力的缺陷. 引入通过有向映射计算相对位置,利用动态变化的图像相对位置编码(image relative position encoding,IRPE)[13 ] 配合自注意力的分窗计算. 使用类别残差注意力(class-specific residual attention, CSRA)[14 ] 优化分类器,提高针对多种病理的分类能力. 此外,针对疾病样本不均匀,分类难度差异较大的问题,提出动态难度损失函数,优化网络对计算资源的分配. 在ChestX-ray14[15 ] 、CheXpert[16 ] 和MIMIC-CXR-JPG[17 ] 3个公开数据集上的实验结果以及与多种先进方法的评估分析,验证了所提出网络的性能. 工作代码已经公开,代码链接为:https://github.com/ZhangZr11/CAWSNet.git. ...
... MIMIC-CXR-JPG[17 ] (在后续实验中简称为MIMIC-CXR)是包含377 110幅图像和227 835项成像报告的大型数据集,数据来自2011—2016年在美国哈佛医学院贝斯以色列女执事医疗中心急诊部就诊的65 379名患者. 每份成像报告对应1幅或多幅CXR图像,通常为正面或侧面视图. 数据集包含12种胸部疾病类别以及2种非疾病类别“无发现”和“支持设备”,每个类别的观测值被指定为正(1)、负(0)或不确定(−1). 为了公平起见,实验中使用的数据集按照官方公布的方式进行分割. ...
al. DualCheXNet: dual asymmetric feature learning for thoracic disease classification in chest X-rays
1
2019
... 随着深度学习技术的发展,计算机视觉领域取得了许多突破性的进展,其中包括各种医学图像处理任务. 公开数据集ChestX-ray14、CheXpert和MIMIC-CXR-JPG的发表,使得越来越多的研究者将目光投向胸部疾病分类这一多标签分类任务上. Wang等[15 ] 使用AlexNet、ResNet、VGGNet和GooGLeNet 4个经典的CNN架构,在ChestX-ray14数据集上进行胸部疾病分类的研究,其中ResNet的分类效果最突出. Chen等[18 ] 提出双不对称特征学习网络DualCheXNet,结合基于ResNet和DenseNet的2个非对称子网络,以便从原始CXR图像中不对称地学习互补特征,用于多标签胸部疾病分类. Wang等[19 ] 提出三重注意力学习网络A3 Net,使用预训练的DenseNet-121作为骨干网络进行特征提取,将通道、像素和尺度3种注意力集成在统一的框架中,分别关注特征图的通道、病变区域和不同尺度,更好地完成疾病分类任务. Chen等[20 ] 提出基于金字塔卷积模块和Shuffle注意力模块的残差网络. 其中,金字塔卷积模块用于提取病理异常的多尺度判别特征,而Shuffle注意力模块通过分组整合空间和通道注意力,显著提升了对病变区域的聚焦效果. Chen等[21 ] 提出新的语义相似图嵌入框架,该网络根据批量CXR图像的语义标签生成相似性图,以此为依据,使用图卷积网络自适应地重新校准从CNN网络提取的视觉特征,提高多标签CXR图像分类的性能. ...
al. Triple attention learning for classification of 14 thoracic diseases using chest radiography
2
2021
... 随着深度学习技术的发展,计算机视觉领域取得了许多突破性的进展,其中包括各种医学图像处理任务. 公开数据集ChestX-ray14、CheXpert和MIMIC-CXR-JPG的发表,使得越来越多的研究者将目光投向胸部疾病分类这一多标签分类任务上. Wang等[15 ] 使用AlexNet、ResNet、VGGNet和GooGLeNet 4个经典的CNN架构,在ChestX-ray14数据集上进行胸部疾病分类的研究,其中ResNet的分类效果最突出. Chen等[18 ] 提出双不对称特征学习网络DualCheXNet,结合基于ResNet和DenseNet的2个非对称子网络,以便从原始CXR图像中不对称地学习互补特征,用于多标签胸部疾病分类. Wang等[19 ] 提出三重注意力学习网络A3 Net,使用预训练的DenseNet-121作为骨干网络进行特征提取,将通道、像素和尺度3种注意力集成在统一的框架中,分别关注特征图的通道、病变区域和不同尺度,更好地完成疾病分类任务. Chen等[20 ] 提出基于金字塔卷积模块和Shuffle注意力模块的残差网络. 其中,金字塔卷积模块用于提取病理异常的多尺度判别特征,而Shuffle注意力模块通过分组整合空间和通道注意力,显著提升了对病变区域的聚焦效果. Chen等[21 ] 提出新的语义相似图嵌入框架,该网络根据批量CXR图像的语义标签生成相似性图,以此为依据,使用图卷积网络自适应地重新校准从CNN网络提取的视觉特征,提高多标签CXR图像分类的性能. ...
... 为了验证网络在胸部疾病分类任务上的有效性和准确性,将提出的CAWSNet在ChestX-Ray14、CheXpert和MIMIC 3个数据集上进行实验,并与现有的SOTA方法进行比较. 利用DCNN[27 ] 和MXT[21 ] 2种方法,对网络结构进行优化. TransDD[28 ] 、PCAN[29 ] 和PCSANet[19 ] 3种方法使用注意力机制帮助网络关注重要的信息,提高分类效果. SSGE[20 ] 、LCT[30 ] 和 CheXGAT[31 ] 通过对病理标签间的相关性进行建模,辅助网络进行分类. MAE使用掩膜自动编码器,在CXR数据上预训练ViT进行分类[32 ] . ML-LGL利用临床知识杠杆选择函数生成异常递增的课程,通过课程学习来训练DNN模型[33 ] . MVCNet在特征和决策层面融合正面和侧面2种视图的CXR图像来辅助分类[34 ] . MMBT[35 ] 和MedCLIP[36 ] 利用医学报告中的文本信息作为辅助,使用多模态学习的方法完成疾病的识别. 在ChestX-Ray14测试集、CheXpert验证集和MIMIC-CXR测试集上,每种病理的ROC曲线和AUC分数如图6 ~8 所示,可以看出所提方法的分类性能(为了使标记清晰,每条曲线都由间隔取点的40个数据点绘制). 如表1 ~3 所示分别为CAWSNet与其他SOTA方法在3个数据集上的比较结果. ...
Thorax disease classification based on pyramidal convolution shuffle attention neural network
2
2022
... 随着深度学习技术的发展,计算机视觉领域取得了许多突破性的进展,其中包括各种医学图像处理任务. 公开数据集ChestX-ray14、CheXpert和MIMIC-CXR-JPG的发表,使得越来越多的研究者将目光投向胸部疾病分类这一多标签分类任务上. Wang等[15 ] 使用AlexNet、ResNet、VGGNet和GooGLeNet 4个经典的CNN架构,在ChestX-ray14数据集上进行胸部疾病分类的研究,其中ResNet的分类效果最突出. Chen等[18 ] 提出双不对称特征学习网络DualCheXNet,结合基于ResNet和DenseNet的2个非对称子网络,以便从原始CXR图像中不对称地学习互补特征,用于多标签胸部疾病分类. Wang等[19 ] 提出三重注意力学习网络A3 Net,使用预训练的DenseNet-121作为骨干网络进行特征提取,将通道、像素和尺度3种注意力集成在统一的框架中,分别关注特征图的通道、病变区域和不同尺度,更好地完成疾病分类任务. Chen等[20 ] 提出基于金字塔卷积模块和Shuffle注意力模块的残差网络. 其中,金字塔卷积模块用于提取病理异常的多尺度判别特征,而Shuffle注意力模块通过分组整合空间和通道注意力,显著提升了对病变区域的聚焦效果. Chen等[21 ] 提出新的语义相似图嵌入框架,该网络根据批量CXR图像的语义标签生成相似性图,以此为依据,使用图卷积网络自适应地重新校准从CNN网络提取的视觉特征,提高多标签CXR图像分类的性能. ...
... 为了验证网络在胸部疾病分类任务上的有效性和准确性,将提出的CAWSNet在ChestX-Ray14、CheXpert和MIMIC 3个数据集上进行实验,并与现有的SOTA方法进行比较. 利用DCNN[27 ] 和MXT[21 ] 2种方法,对网络结构进行优化. TransDD[28 ] 、PCAN[29 ] 和PCSANet[19 ] 3种方法使用注意力机制帮助网络关注重要的信息,提高分类效果. SSGE[20 ] 、LCT[30 ] 和 CheXGAT[31 ] 通过对病理标签间的相关性进行建模,辅助网络进行分类. MAE使用掩膜自动编码器,在CXR数据上预训练ViT进行分类[32 ] . ML-LGL利用临床知识杠杆选择函数生成异常递增的课程,通过课程学习来训练DNN模型[33 ] . MVCNet在特征和决策层面融合正面和侧面2种视图的CXR图像来辅助分类[34 ] . MMBT[35 ] 和MedCLIP[36 ] 利用医学报告中的文本信息作为辅助,使用多模态学习的方法完成疾病的识别. 在ChestX-Ray14测试集、CheXpert验证集和MIMIC-CXR测试集上,每种病理的ROC曲线和AUC分数如图6 ~8 所示,可以看出所提方法的分类性能(为了使标记清晰,每条曲线都由间隔取点的40个数据点绘制). 如表1 ~3 所示分别为CAWSNet与其他SOTA方法在3个数据集上的比较结果. ...
al. Multi-label chest X-ray image classification via semantic similarity graph embedding
3
2022
... 随着深度学习技术的发展,计算机视觉领域取得了许多突破性的进展,其中包括各种医学图像处理任务. 公开数据集ChestX-ray14、CheXpert和MIMIC-CXR-JPG的发表,使得越来越多的研究者将目光投向胸部疾病分类这一多标签分类任务上. Wang等[15 ] 使用AlexNet、ResNet、VGGNet和GooGLeNet 4个经典的CNN架构,在ChestX-ray14数据集上进行胸部疾病分类的研究,其中ResNet的分类效果最突出. Chen等[18 ] 提出双不对称特征学习网络DualCheXNet,结合基于ResNet和DenseNet的2个非对称子网络,以便从原始CXR图像中不对称地学习互补特征,用于多标签胸部疾病分类. Wang等[19 ] 提出三重注意力学习网络A3 Net,使用预训练的DenseNet-121作为骨干网络进行特征提取,将通道、像素和尺度3种注意力集成在统一的框架中,分别关注特征图的通道、病变区域和不同尺度,更好地完成疾病分类任务. Chen等[20 ] 提出基于金字塔卷积模块和Shuffle注意力模块的残差网络. 其中,金字塔卷积模块用于提取病理异常的多尺度判别特征,而Shuffle注意力模块通过分组整合空间和通道注意力,显著提升了对病变区域的聚焦效果. Chen等[21 ] 提出新的语义相似图嵌入框架,该网络根据批量CXR图像的语义标签生成相似性图,以此为依据,使用图卷积网络自适应地重新校准从CNN网络提取的视觉特征,提高多标签CXR图像分类的性能. ...
... 为了验证网络在胸部疾病分类任务上的有效性和准确性,将提出的CAWSNet在ChestX-Ray14、CheXpert和MIMIC 3个数据集上进行实验,并与现有的SOTA方法进行比较. 利用DCNN[27 ] 和MXT[21 ] 2种方法,对网络结构进行优化. TransDD[28 ] 、PCAN[29 ] 和PCSANet[19 ] 3种方法使用注意力机制帮助网络关注重要的信息,提高分类效果. SSGE[20 ] 、LCT[30 ] 和 CheXGAT[31 ] 通过对病理标签间的相关性进行建模,辅助网络进行分类. MAE使用掩膜自动编码器,在CXR数据上预训练ViT进行分类[32 ] . ML-LGL利用临床知识杠杆选择函数生成异常递增的课程,通过课程学习来训练DNN模型[33 ] . MVCNet在特征和决策层面融合正面和侧面2种视图的CXR图像来辅助分类[34 ] . MMBT[35 ] 和MedCLIP[36 ] 利用医学报告中的文本信息作为辅助,使用多模态学习的方法完成疾病的识别. 在ChestX-Ray14测试集、CheXpert验证集和MIMIC-CXR测试集上,每种病理的ROC曲线和AUC分数如图6 ~8 所示,可以看出所提方法的分类性能(为了使标记清晰,每条曲线都由间隔取点的40个数据点绘制). 如表1 ~3 所示分别为CAWSNet与其他SOTA方法在3个数据集上的比较结果. ...
... Comparison of computational complexity of different chest disease classification network
Tab.9 网络 FLOPs/109 t inf /s平均AUC SSGE[21 ] 17.74 0.059 0.830 CheXGCN[37 ] 17.86 0.061 0.826 PCAN[29 ] 3.92 0.054 0.830 Swin Trans[12 ] 4.37 0.013 0.837 CAWSNet 4.52 0.018 0.853
从表9 可以看出,CAWSNet的推理时间较短,可以快速地处理单张CXR图像,FLOPs较小,与Swin Transformer骨干网络相比只增加0.15×109 ,但性能有显著提升. 利用CAWS模块共享部分权重来实现卷积和窗口自注意力并行计算的方法,可以有效地节约计算资源. 综合来说,网络较好地平衡了分类准确度和计算复杂度,在胸部疾病诊断算法中具有较强的竞争力. ...
al. MXT: a new variant of pyramid vision Transformer for multi-label chest X-ray image classification
1
2022
... 在目前主流的方法中,特征提取的任务大多是由卷积神经网络来完成. 随着视觉Transformer的兴起,Jiang等[22 ] 提出金字塔视觉Transformer的新变体实现胸部疾病分类,该网络通过自注意力捕获长距离视觉信息,使用下采样空间缩减注意力,减少使用全局自注意力的资源消耗. Liu等[12 ] 提出新的视觉网络Swin Transformer,使用窗口自注意力处理特征图,令计算复杂度与图像大小成线性关系,提出移位窗口方法,弥补分窗计算带来的信息丢失,在图像分类和目标检测领域取得了优秀的效果. 上述方法虽然在胸部疾病分类任务中取得了优秀的效果,但都无法在特征提取阶段很好地兼顾局部特征和长距离视觉依赖关系,导致有效信息的丢失. 以Swin Transformer为骨干网络,引入卷积作为辅助,提出基于卷积辅助窗口自注意力的胸部X光影像疾病分类网络CAWSNet. 使用自注意力和卷积,互补地提取CXR图像特征,获得更加优秀的分类性能. ...
1
... 受ACmix方法[23 ] 的启发,该模块在实现卷积和窗口自注意力的并行计算时,采取通过共享权重来节约计算资源的方法,将计算拆解为2个阶段. 假设输入和输出特征图分别为${\boldsymbol{X}} \in {{\bf{R}}^{H \times W \times {C_{{\text{in}}}}}}$ ${\boldsymbol{Z}} \in {{\bf{R}}^{H \times W \times {C_{{\text{out}}}}}}$ $(i,j)$ ${{\boldsymbol{x}}_{ij}} \in {{\bf{R}}^{{C_{{\text{in}}}}}}$ ${{\boldsymbol{z}}_{ij}} \in {{\bf{R}}^{{C_{{\mathrm{out}}}}}}$ $H$ $W$ ${C_{{\text{in}}}}$ ${C_{{\text{out}}}}$ ${\boldsymbol{K}} \in {{\bf{R}}^{{C_{{\text{out}}}} \times {C_{{\text{in}}}} \times k \times k}}$ $k$
1
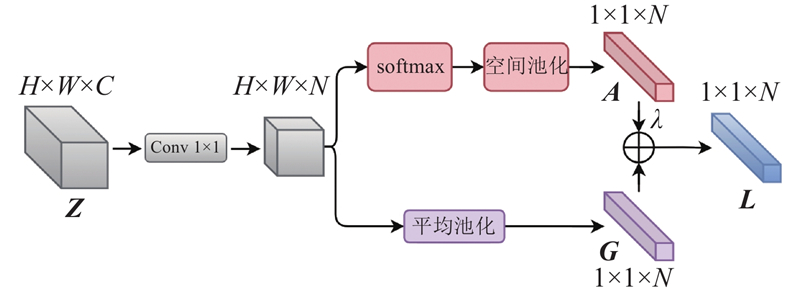
... 窗口自注意力在空间维度上动态计算权重,通道之间缺乏信息交互,而卷积运算的通道间存在充分的信息交互与整合. 模块利用卷积支路的输出,生成通道权重,并将其作用于窗口自注意力支路,强化通道建模能力. 对于通道权重的生成,采取类似挤压激励块[24 ] 的设计:使用平均池化层,对特征图的全局空间信息进行压缩;通过2个$1 \times 1$
al. Focal loss for dense object detection
1
2020
... 在胸部疾病分类任务中,各种疾病区域的大小、轮廓、纹理特征均呈现多样化,且数据集中的样本分布不均匀,导致分类难度具有较大的差异,阻碍了多标签分类任务准确率的提高. 在一张CXR图像中,往往只有1~3种疾病标签为正标签,其余均为负,这意味着每类疾病的正样本数量远低于负样本. 为了解决以上问题,在焦点损失函数[25 ] 的基础上,加入基于AUC分数动态调节的平衡系数,提出动态难度损失函数(dynamic difficulty loss,DDL). 对于每种疾病,计算公式如下: ...
1
... 实验在Pytorch[26 ] 框架上实现. 对于训练,使用Adam优化器对网络进行优化,batch size为32,训练轮次为20. 初始学习率为0.000 1,每2个轮次学习率乘以0.9. 为了提高网络的收敛速度和学习能力,实验中的骨干网络将在ImageNet上进行预训练. 当验证集上的损失不再减少或开始增加时,训练将停止. ...
al. Interpreting chest X-rays via CNNs that exploit hierarchical disease dependencies and uncertainty labels
1
2021
... 为了验证网络在胸部疾病分类任务上的有效性和准确性,将提出的CAWSNet在ChestX-Ray14、CheXpert和MIMIC 3个数据集上进行实验,并与现有的SOTA方法进行比较. 利用DCNN[27 ] 和MXT[21 ] 2种方法,对网络结构进行优化. TransDD[28 ] 、PCAN[29 ] 和PCSANet[19 ] 3种方法使用注意力机制帮助网络关注重要的信息,提高分类效果. SSGE[20 ] 、LCT[30 ] 和 CheXGAT[31 ] 通过对病理标签间的相关性进行建模,辅助网络进行分类. MAE使用掩膜自动编码器,在CXR数据上预训练ViT进行分类[32 ] . ML-LGL利用临床知识杠杆选择函数生成异常递增的课程,通过课程学习来训练DNN模型[33 ] . MVCNet在特征和决策层面融合正面和侧面2种视图的CXR图像来辅助分类[34 ] . MMBT[35 ] 和MedCLIP[36 ] 利用医学报告中的文本信息作为辅助,使用多模态学习的方法完成疾病的识别. 在ChestX-Ray14测试集、CheXpert验证集和MIMIC-CXR测试集上,每种病理的ROC曲线和AUC分数如图6 ~8 所示,可以看出所提方法的分类性能(为了使标记清晰,每条曲线都由间隔取点的40个数据点绘制). 如表1 ~3 所示分别为CAWSNet与其他SOTA方法在3个数据集上的比较结果. ...
TransDD: a transformer-based dual-path decoder for improving the performance of thoracic diseases classification using chest X-ray
1
2024
... 为了验证网络在胸部疾病分类任务上的有效性和准确性,将提出的CAWSNet在ChestX-Ray14、CheXpert和MIMIC 3个数据集上进行实验,并与现有的SOTA方法进行比较. 利用DCNN[27 ] 和MXT[21 ] 2种方法,对网络结构进行优化. TransDD[28 ] 、PCAN[29 ] 和PCSANet[19 ] 3种方法使用注意力机制帮助网络关注重要的信息,提高分类效果. SSGE[20 ] 、LCT[30 ] 和 CheXGAT[31 ] 通过对病理标签间的相关性进行建模,辅助网络进行分类. MAE使用掩膜自动编码器,在CXR数据上预训练ViT进行分类[32 ] . ML-LGL利用临床知识杠杆选择函数生成异常递增的课程,通过课程学习来训练DNN模型[33 ] . MVCNet在特征和决策层面融合正面和侧面2种视图的CXR图像来辅助分类[34 ] . MMBT[35 ] 和MedCLIP[36 ] 利用医学报告中的文本信息作为辅助,使用多模态学习的方法完成疾病的识别. 在ChestX-Ray14测试集、CheXpert验证集和MIMIC-CXR测试集上,每种病理的ROC曲线和AUC分数如图6 ~8 所示,可以看出所提方法的分类性能(为了使标记清晰,每条曲线都由间隔取点的40个数据点绘制). 如表1 ~3 所示分别为CAWSNet与其他SOTA方法在3个数据集上的比较结果. ...
al. PCAN: pixel-wise classification and attention network for thoracic disease classification and weakly supervised localization
2
2022
... 为了验证网络在胸部疾病分类任务上的有效性和准确性,将提出的CAWSNet在ChestX-Ray14、CheXpert和MIMIC 3个数据集上进行实验,并与现有的SOTA方法进行比较. 利用DCNN[27 ] 和MXT[21 ] 2种方法,对网络结构进行优化. TransDD[28 ] 、PCAN[29 ] 和PCSANet[19 ] 3种方法使用注意力机制帮助网络关注重要的信息,提高分类效果. SSGE[20 ] 、LCT[30 ] 和 CheXGAT[31 ] 通过对病理标签间的相关性进行建模,辅助网络进行分类. MAE使用掩膜自动编码器,在CXR数据上预训练ViT进行分类[32 ] . ML-LGL利用临床知识杠杆选择函数生成异常递增的课程,通过课程学习来训练DNN模型[33 ] . MVCNet在特征和决策层面融合正面和侧面2种视图的CXR图像来辅助分类[34 ] . MMBT[35 ] 和MedCLIP[36 ] 利用医学报告中的文本信息作为辅助,使用多模态学习的方法完成疾病的识别. 在ChestX-Ray14测试集、CheXpert验证集和MIMIC-CXR测试集上,每种病理的ROC曲线和AUC分数如图6 ~8 所示,可以看出所提方法的分类性能(为了使标记清晰,每条曲线都由间隔取点的40个数据点绘制). 如表1 ~3 所示分别为CAWSNet与其他SOTA方法在3个数据集上的比较结果. ...
... Comparison of computational complexity of different chest disease classification network
Tab.9 网络 FLOPs/109 t inf /s平均AUC SSGE[21 ] 17.74 0.059 0.830 CheXGCN[37 ] 17.86 0.061 0.826 PCAN[29 ] 3.92 0.054 0.830 Swin Trans[12 ] 4.37 0.013 0.837 CAWSNet 4.52 0.018 0.853
从表9 可以看出,CAWSNet的推理时间较短,可以快速地处理单张CXR图像,FLOPs较小,与Swin Transformer骨干网络相比只增加0.15×109 ,但性能有显著提升. 利用CAWS模块共享部分权重来实现卷积和窗口自注意力并行计算的方法,可以有效地节约计算资源. 综合来说,网络较好地平衡了分类准确度和计算复杂度,在胸部疾病诊断算法中具有较强的竞争力. ...
Label correlation transformer for automated chest X-ray diagnosis with reliable interpretability
1
2023
... 为了验证网络在胸部疾病分类任务上的有效性和准确性,将提出的CAWSNet在ChestX-Ray14、CheXpert和MIMIC 3个数据集上进行实验,并与现有的SOTA方法进行比较. 利用DCNN[27 ] 和MXT[21 ] 2种方法,对网络结构进行优化. TransDD[28 ] 、PCAN[29 ] 和PCSANet[19 ] 3种方法使用注意力机制帮助网络关注重要的信息,提高分类效果. SSGE[20 ] 、LCT[30 ] 和 CheXGAT[31 ] 通过对病理标签间的相关性进行建模,辅助网络进行分类. MAE使用掩膜自动编码器,在CXR数据上预训练ViT进行分类[32 ] . ML-LGL利用临床知识杠杆选择函数生成异常递增的课程,通过课程学习来训练DNN模型[33 ] . MVCNet在特征和决策层面融合正面和侧面2种视图的CXR图像来辅助分类[34 ] . MMBT[35 ] 和MedCLIP[36 ] 利用医学报告中的文本信息作为辅助,使用多模态学习的方法完成疾病的识别. 在ChestX-Ray14测试集、CheXpert验证集和MIMIC-CXR测试集上,每种病理的ROC曲线和AUC分数如图6 ~8 所示,可以看出所提方法的分类性能(为了使标记清晰,每条曲线都由间隔取点的40个数据点绘制). 如表1 ~3 所示分别为CAWSNet与其他SOTA方法在3个数据集上的比较结果. ...
CheXGAT: a disease correlation-aware network for thorax disease diagnosis from chest X-ray images
1
2022
... 为了验证网络在胸部疾病分类任务上的有效性和准确性,将提出的CAWSNet在ChestX-Ray14、CheXpert和MIMIC 3个数据集上进行实验,并与现有的SOTA方法进行比较. 利用DCNN[27 ] 和MXT[21 ] 2种方法,对网络结构进行优化. TransDD[28 ] 、PCAN[29 ] 和PCSANet[19 ] 3种方法使用注意力机制帮助网络关注重要的信息,提高分类效果. SSGE[20 ] 、LCT[30 ] 和 CheXGAT[31 ] 通过对病理标签间的相关性进行建模,辅助网络进行分类. MAE使用掩膜自动编码器,在CXR数据上预训练ViT进行分类[32 ] . ML-LGL利用临床知识杠杆选择函数生成异常递增的课程,通过课程学习来训练DNN模型[33 ] . MVCNet在特征和决策层面融合正面和侧面2种视图的CXR图像来辅助分类[34 ] . MMBT[35 ] 和MedCLIP[36 ] 利用医学报告中的文本信息作为辅助,使用多模态学习的方法完成疾病的识别. 在ChestX-Ray14测试集、CheXpert验证集和MIMIC-CXR测试集上,每种病理的ROC曲线和AUC分数如图6 ~8 所示,可以看出所提方法的分类性能(为了使标记清晰,每条曲线都由间隔取点的40个数据点绘制). 如表1 ~3 所示分别为CAWSNet与其他SOTA方法在3个数据集上的比较结果. ...
1
... 为了验证网络在胸部疾病分类任务上的有效性和准确性,将提出的CAWSNet在ChestX-Ray14、CheXpert和MIMIC 3个数据集上进行实验,并与现有的SOTA方法进行比较. 利用DCNN[27 ] 和MXT[21 ] 2种方法,对网络结构进行优化. TransDD[28 ] 、PCAN[29 ] 和PCSANet[19 ] 3种方法使用注意力机制帮助网络关注重要的信息,提高分类效果. SSGE[20 ] 、LCT[30 ] 和 CheXGAT[31 ] 通过对病理标签间的相关性进行建模,辅助网络进行分类. MAE使用掩膜自动编码器,在CXR数据上预训练ViT进行分类[32 ] . ML-LGL利用临床知识杠杆选择函数生成异常递增的课程,通过课程学习来训练DNN模型[33 ] . MVCNet在特征和决策层面融合正面和侧面2种视图的CXR图像来辅助分类[34 ] . MMBT[35 ] 和MedCLIP[36 ] 利用医学报告中的文本信息作为辅助,使用多模态学习的方法完成疾病的识别. 在ChestX-Ray14测试集、CheXpert验证集和MIMIC-CXR测试集上,每种病理的ROC曲线和AUC分数如图6 ~8 所示,可以看出所提方法的分类性能(为了使标记清晰,每条曲线都由间隔取点的40个数据点绘制). 如表1 ~3 所示分别为CAWSNet与其他SOTA方法在3个数据集上的比较结果. ...
Multi-label local to global learning: a novel learning paradigm for chest x-ray abnormality classification
1
2023
... 为了验证网络在胸部疾病分类任务上的有效性和准确性,将提出的CAWSNet在ChestX-Ray14、CheXpert和MIMIC 3个数据集上进行实验,并与现有的SOTA方法进行比较. 利用DCNN[27 ] 和MXT[21 ] 2种方法,对网络结构进行优化. TransDD[28 ] 、PCAN[29 ] 和PCSANet[19 ] 3种方法使用注意力机制帮助网络关注重要的信息,提高分类效果. SSGE[20 ] 、LCT[30 ] 和 CheXGAT[31 ] 通过对病理标签间的相关性进行建模,辅助网络进行分类. MAE使用掩膜自动编码器,在CXR数据上预训练ViT进行分类[32 ] . ML-LGL利用临床知识杠杆选择函数生成异常递增的课程,通过课程学习来训练DNN模型[33 ] . MVCNet在特征和决策层面融合正面和侧面2种视图的CXR图像来辅助分类[34 ] . MMBT[35 ] 和MedCLIP[36 ] 利用医学报告中的文本信息作为辅助,使用多模态学习的方法完成疾病的识别. 在ChestX-Ray14测试集、CheXpert验证集和MIMIC-CXR测试集上,每种病理的ROC曲线和AUC分数如图6 ~8 所示,可以看出所提方法的分类性能(为了使标记清晰,每条曲线都由间隔取点的40个数据点绘制). 如表1 ~3 所示分别为CAWSNet与其他SOTA方法在3个数据集上的比较结果. ...
1
... 为了验证网络在胸部疾病分类任务上的有效性和准确性,将提出的CAWSNet在ChestX-Ray14、CheXpert和MIMIC 3个数据集上进行实验,并与现有的SOTA方法进行比较. 利用DCNN[27 ] 和MXT[21 ] 2种方法,对网络结构进行优化. TransDD[28 ] 、PCAN[29 ] 和PCSANet[19 ] 3种方法使用注意力机制帮助网络关注重要的信息,提高分类效果. SSGE[20 ] 、LCT[30 ] 和 CheXGAT[31 ] 通过对病理标签间的相关性进行建模,辅助网络进行分类. MAE使用掩膜自动编码器,在CXR数据上预训练ViT进行分类[32 ] . ML-LGL利用临床知识杠杆选择函数生成异常递增的课程,通过课程学习来训练DNN模型[33 ] . MVCNet在特征和决策层面融合正面和侧面2种视图的CXR图像来辅助分类[34 ] . MMBT[35 ] 和MedCLIP[36 ] 利用医学报告中的文本信息作为辅助,使用多模态学习的方法完成疾病的识别. 在ChestX-Ray14测试集、CheXpert验证集和MIMIC-CXR测试集上,每种病理的ROC曲线和AUC分数如图6 ~8 所示,可以看出所提方法的分类性能(为了使标记清晰,每条曲线都由间隔取点的40个数据点绘制). 如表1 ~3 所示分别为CAWSNet与其他SOTA方法在3个数据集上的比较结果. ...
1
... 为了验证网络在胸部疾病分类任务上的有效性和准确性,将提出的CAWSNet在ChestX-Ray14、CheXpert和MIMIC 3个数据集上进行实验,并与现有的SOTA方法进行比较. 利用DCNN[27 ] 和MXT[21 ] 2种方法,对网络结构进行优化. TransDD[28 ] 、PCAN[29 ] 和PCSANet[19 ] 3种方法使用注意力机制帮助网络关注重要的信息,提高分类效果. SSGE[20 ] 、LCT[30 ] 和 CheXGAT[31 ] 通过对病理标签间的相关性进行建模,辅助网络进行分类. MAE使用掩膜自动编码器,在CXR数据上预训练ViT进行分类[32 ] . ML-LGL利用临床知识杠杆选择函数生成异常递增的课程,通过课程学习来训练DNN模型[33 ] . MVCNet在特征和决策层面融合正面和侧面2种视图的CXR图像来辅助分类[34 ] . MMBT[35 ] 和MedCLIP[36 ] 利用医学报告中的文本信息作为辅助,使用多模态学习的方法完成疾病的识别. 在ChestX-Ray14测试集、CheXpert验证集和MIMIC-CXR测试集上,每种病理的ROC曲线和AUC分数如图6 ~8 所示,可以看出所提方法的分类性能(为了使标记清晰,每条曲线都由间隔取点的40个数据点绘制). 如表1 ~3 所示分别为CAWSNet与其他SOTA方法在3个数据集上的比较结果. ...
1
... 为了验证网络在胸部疾病分类任务上的有效性和准确性,将提出的CAWSNet在ChestX-Ray14、CheXpert和MIMIC 3个数据集上进行实验,并与现有的SOTA方法进行比较. 利用DCNN[27 ] 和MXT[21 ] 2种方法,对网络结构进行优化. TransDD[28 ] 、PCAN[29 ] 和PCSANet[19 ] 3种方法使用注意力机制帮助网络关注重要的信息,提高分类效果. SSGE[20 ] 、LCT[30 ] 和 CheXGAT[31 ] 通过对病理标签间的相关性进行建模,辅助网络进行分类. MAE使用掩膜自动编码器,在CXR数据上预训练ViT进行分类[32 ] . ML-LGL利用临床知识杠杆选择函数生成异常递增的课程,通过课程学习来训练DNN模型[33 ] . MVCNet在特征和决策层面融合正面和侧面2种视图的CXR图像来辅助分类[34 ] . MMBT[35 ] 和MedCLIP[36 ] 利用医学报告中的文本信息作为辅助,使用多模态学习的方法完成疾病的识别. 在ChestX-Ray14测试集、CheXpert验证集和MIMIC-CXR测试集上,每种病理的ROC曲线和AUC分数如图6 ~8 所示,可以看出所提方法的分类性能(为了使标记清晰,每条曲线都由间隔取点的40个数据点绘制). 如表1 ~3 所示分别为CAWSNet与其他SOTA方法在3个数据集上的比较结果. ...
Label co-occurrence learning with graph convolutional networks for multi-label chest x-ray image classification
1
2020
... Comparison of computational complexity of different chest disease classification network
Tab.9 网络 FLOPs/109 t inf /s平均AUC SSGE[21 ] 17.74 0.059 0.830 CheXGCN[37 ] 17.86 0.061 0.826 PCAN[29 ] 3.92 0.054 0.830 Swin Trans[12 ] 4.37 0.013 0.837 CAWSNet 4.52 0.018 0.853
从表9 可以看出,CAWSNet的推理时间较短,可以快速地处理单张CXR图像,FLOPs较小,与Swin Transformer骨干网络相比只增加0.15×109 ,但性能有显著提升. 利用CAWS模块共享部分权重来实现卷积和窗口自注意力并行计算的方法,可以有效地节约计算资源. 综合来说,网络较好地平衡了分类准确度和计算复杂度,在胸部疾病诊断算法中具有较强的竞争力. ...
al. Grad-CAM: visual explanations from deep networks via gradient-based localization
1
2020
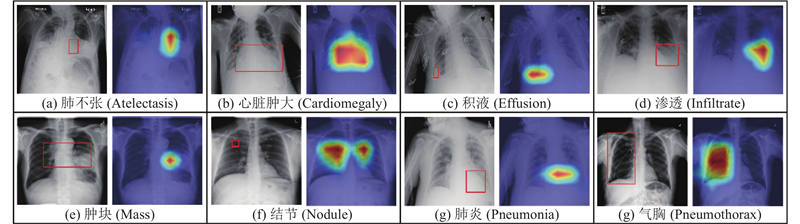
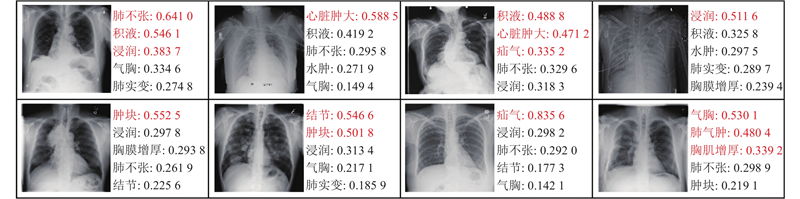
... 加权梯度类激活映射[38 ] (Grad-CAM)利用梯度信息,给特征映射的各个通道赋予权重,生成热图,可以显示网络关注的病灶区域. 为了验证网络识别的准确性,通过Grad-CAM在一些ChestX-Ray14中的CXR图像上生成热图,与专业医生提供的病变标记图进行比较. 对一部分CXR图像进行疾病预测得分的可视化,直观地表现网络的分类效果. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}