

目前针对车辆类物体的检测[5-7],主要采用基于YOLO(You Only Look Once)的目标检测方法[8-10]. 例如,针对道路车辆遮挡与小目标车辆漏检率高的问题,马永杰等[11]提出改进的YOLOv3车辆检测方法. 为了兼顾算法检测速度和准确性的需求,陈志军等[12]利用GhostNet加速YOLOv4的特征提取,提出基于轻量化网络和注意力机制的车辆目标识别方法. 考虑风险预警的时效性要求,王博等[13]选择基于YOLOv5构建道路监控视角下的车辆目标检测模型. 高速公路货运车辆的货箱形式各异、货物形式多样,货运车辆抛洒风险检测仍存在较大挑战. 现有的车辆检测方法忽略了货车车厢的局部细节信息[12-14],导致对货车车厢类型、篷布遮盖、货物形状等抛洒风险关键特征的学习和关注不足,缺乏足够的判别信息进行准确识别,难以完成抛洒风险车辆检测任务.
面对货运车辆抛洒风险检测的难题,针对现有方法存在的关键抛洒风险特征提取能力不足、特征跨层融合不充分问题,提出面向货运车辆的抛洒风险检测方法(spillage risk vehicles detection network, SRVDNet). 骨干网络引入大核可选择性感受野机制,增强网络对货运车辆抛洒风险特征的学习能力. 颈部网络引入聚集-分发特征融合机制,解决特征融合过程中抛洒风险特征丢失的问题,为检测头提供有助于抛洒风险判断的深层语义特征和浅层细节纹理特征. 该方法提升了模型在货物装载不规则、少量货物和满载货物场景下的抛洒风险识别能力,有效提高了抛洒风险车辆的检测精度,有助于抛洒物的源头治理,提升高速公路安全风险的识别预警能力.
1. 抛洒风险车辆检测方法的框架
图 1
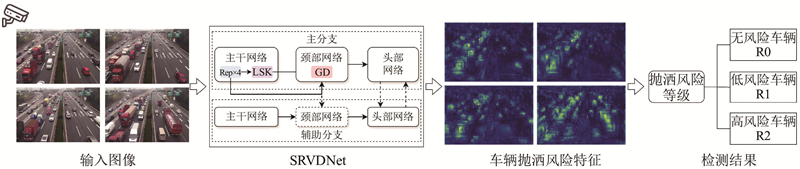
框架的核心为提出的SRVDNet算法,可以实现对具有抛洒风险的非厢式货车的准确检测,降低了对规范装载车辆和空载车辆的误检率.
2. SRVDNet算法的原理
提出的抛洒风险车辆检测网络SRVDNet结构原理如图2所示,主要由骨干网络(backbone)、颈部网络(neck)、头部网络(head)和辅助可逆分支(auxiliary reversible branch,ARB)4部分构成.
图 2

图 2 SRVDNet网络的结构
Fig.2 Architecture of spillage risk vehicles detection network
骨干网络主要使用RepCSPEALN4模块进行特征提取,利用卷积神经网络进行下采样,
2.1. 骨干网络
图 3

采用LSK将传统卷积层的二维卷积核分解为级联的水平和垂直深度可变卷积核. 可变卷积核具有递增的卷积核大小和不同的扩张率,在不增加计算成本的情况下,可以覆盖更大的感受野,捕捉货箱和货物的长距离特征依赖关系,提取更丰富的抛洒风险特征,如下所示:
式中:
为了强化网络更关注于货车抛洒风险最相关的空间上下文区域,采用空间选择机制,将来自不同感受野的卷积核特征进行拼接,应用通道级的平均池化Pavg和最大池化Pmax提取空间特征
式中:
每个空间注意力特征图
式中:
2.2. 颈部网络
不同大小目标信息存在于不同尺度的特征图中,大尺度特征提取低维细节信息和小目标位置,小尺度特征包含高维抽象信息和大目标位置. 现有车辆目标检测SOTA模型的颈部网络所采用的传统特征金字塔特征融合方式仅支持相邻逐层特征融合或跨层间接递归融合,无法实现跨层特征直接融合,导致不同大小的目标信息容易在融合过程中丢失,降低模型对装载少量货物的货车和空车的判别性,造成装载少量货物的抛洒风险货车漏检. 原因在于少量货物的视觉元素较少,多层卷积后,货物深层特征的语义信息容易缺失. 此外,对于篷布的关键特征提取,容易出现浅层的篷布纹理信息丢失问题,导致满载货物形式车辆与篷布覆盖车辆类别混淆,极大地阻碍抛洒风险的准确判断.
图 4

图 4 聚集-分发跨层特征融合网络的结构
Fig.4 Structure of gather-and-distribute cross-layer feature fusion network
Low_GD模块主要用于聚合浅层的特征信息,包括低阶特征对齐模块(low-stage feature alignment module, Low_FAM)、低阶特征信息融合模块(low-stage information fusion module, Low_IFM)、低阶特征信息注入模块(low-stage lightweight adjacent layer fusion, Low_LAF). 在Low_FAM阶段,以
式中:
High_GD模块主要负责聚合来自Low_GD的深层特征和浅层特征. 在高阶特征对齐模块(high-stage feature alignment module, High-FAM)中,以
式中:
通过聚集-分发特征融合机制对图像特征进行低阶特征和高阶特征的跨层融合,既保留了浅层中少量货物小目标信息的高分辨细节纹理特征,也获得了货车车厢、装载形式大中目标的深层语义特征,减少了信息丢失,更有利于模型最后部分的头部网络对货车抛洒风险的判断.
2.3. 头部网络和辅助可逆分支
主分支头部网络采用解耦头及无锚框设计,采用任务对齐分配技术(正负样本分配). 采用分布焦点损失,结合CIoU损失作为回归分支的损失函数,将二元交叉熵损失作为分类损失函数,使得分类和回归任务之间具有较高的对齐一致性. 头部网络含有3级检测头,针对不同尺度下的物体特征,分别用于检测大、中、小目标.
引入辅助可逆分支,采用和主分支相同的检测头,针对反向传播过程中的梯度信息丢失问题,不强制主分支保留完整的原始信息. 通过使用辅助可逆分支,生成有效的梯度并更新网络参数,避免了传统深层监督模型在特征融合过程中的语义损失. 辅助可逆分支在推理阶段将被移除,不会增加模型推理时间.
3. 实验结果的分析
3.1. 实验数据和实验环境
实验数据来源于G4202成都绕城高速-绕西段路侧摄像头在2024年1月白天采集的视频图像,图像尺寸为
实验环境的计算机硬件配置如下. 模型训练采用Tesla A100 GPU,显存为 80 GB,CPU为 Intel(R) Xeon(R) Platinum 8369B CPU@2.90 GHz. 模型推理采用NVIDIA GeForce RTX 4060,显存为8 GB,CPU为Inter(R)Core(TM)i5-12400F,操作系统为Windows11,深度学习框架为PyTorch,使用CUDA11.6、cuDNN8.4.0进行加速.
训练迭代次数为200,Batch_Size为16,使用SGD随机梯度下降法,动量为0.937,学习率为0.01,衰减系数为
考虑准确性和实时性的需求,选用目标检测领域通用的检测指标评价模型性能,包括精确率P(precision)、召回率R(Recall)、F1值(F1-score)、平均精度均值mAP(mean average precision)、权重及每秒帧率v.
3.2. 消融实验
为了验证SRVDNet网络中LSK大核可选择性感受野机制和GD聚集-分发特征融合机制对抛洒风险车辆检测的有效性,在相同环境、参数配置、数据集上进行消融试验,结果如表1所示.
表 1 消融试验的结果
Tab.1
| 网络 | LSK | GD | P/% | R/% | F1/% | mAP@0.5/% | mAP@[0.5:0.95]/% |
| SRVDNet | — | — | 73.02 | 71.26 | 72.13 | 79.50 | 60.67 |
| — | 78.09 | 72.09 | 74.97 | 80.52 | 61.27 | ||
| — | 74.21 | 78.65 | 76.37 | 80.87 | 61.25 | ||
| 79.04 | 74.79 | 76.86 | 81.50 | 61.87 |
从表1可知,在引入LSK机制后,
图 5

3.3. 对比实验
为了验证SRVDNet的性能优势,选取目标检测领域最新的SOTA算法展开对比实验. 所有方法均采用随机初始化参数的方式开始训练,从头学习抛洒风险车辆的检测能力,保证对比实验的公平性和有效性.
表2中,S为模型大小. 从表2可知,对于常用的mAP@0.5指标,SRVDNet较基于YOLOv5[13-14]、YOLOv6[22] 的车辆检测SOTA方法分别提升了3.70%、3.09%,较基于YOLOv8[16]、RT-DETR[23]、PP-YOLOE[22]、YOLOv9[17-18]等目标检测领域的最新SOTA方法提升了2.86%、1.37%、1.41%、2.00%. 对于更严格的mAP@[0.5:0.95]指标,SRVDNet较基于YOLOv5、YOLOv6的车辆检测SOTA方法,分别提升了3.72%、3.53%,较基于YOLOv8、RT-DETR、PP-YOLOE、YOLOv9等目标检测领域的最新SOTA方法,提升了3.67%、1.83%、1.71%、1.20%. 模型参数量相对较小,检测速度较高,达到69帧/s,满足实时性检测的要求.
表 2 不同算法在抛洒风险车辆数据集中的实验结果对比
Tab.2
| 算法 | mAP@0.5/% | mAP@[0.5:0.95]/% | v/(帧·s−1) | S/MB |
| YOLOv5 | 77.80 | 58.15 | 67 | 83.5 |
| YOLOv6 | 78.41 | 58.34 | 73 | 101.6 |
| YOLOv8 | 78.64 | 58.20 | 67 | 83.5 |
| RT-DETR | 80.13 | 60.04 | 28 | 163.6 |
| PPYOLOE | 80.09 | 60.16 | 33 | 203.2 |
| YOLOv9 | 79.50 | 60.67 | 81 | 60.3 |
| SRVDNet | 81.50 | 61.87 | 69 | 62.7 |
与现有方法相比,所提的SRVDNet支持跨层特征融合交互,多层卷积后仍有效保留浅层的小目标少量货物视觉信息、浅层的篷布纹理信息以及货车车厢形式、装载形式的深层语义特征,提升了模型对满载货物形式车辆与篷布覆盖车辆、装载少量货物车辆和空车等容易混淆类别的判别准确性.
3.4. 实验结果可视化对比
为了直观展示所提SRVDNet模型对高速公路抛洒风险车辆检测的提升效果,将实验结果进行可视化对比.
图 6

如图7所示,当面对少量货物这类小目标场景时,YOLOv8和YOLOv9均容易将高风险装载不规则货物货车(Truck_R2)误检为无风险空车(Truck_R0),利用本文算法仍能够准确检测.
图 7

图 7 少量货物场景的检测结果对比
Fig.7 Comparison of detection result in scene with small amount of cargo
如图8所示,面对满载场景时,YOLOv8和YOLOv9容易将满载货物货车(高风险Truck_R2)误检为覆盖篷布货车(低风险Truck_R1)或空车(无风险Truck_R0),利用本文算法仍能够准确检测.
图 8

通过实验对比验证了所提SRVDNet对车厢类型、篷布遮盖、货物形状等关键抛洒风险特征较强的提取能力以及跨层特征融合交互机制的有效性,提升了模型对不规则货物、少量与满载货物、覆盖篷布与空车等容易混淆风险类别的判别准确性.
3.5. 特征图的可视化分析
为了展示SRVDNet对车厢类型、篷布遮盖、货物形状等关键抛洒风险特征的学习能力,将SRVDNet学习到的注意力特征与目前最新的SOTA目标检测算法YOLOv9所学习的注意力特征进行可视化对比.
图 9

在骨干网络引入大核可选择性感受野机制,增强了网络对货运车辆抛洒风险特征的学习能力,可以针对空间上不规则货物的货车目标自适应地选择不同大小的卷积核动态调整感受野,将模型注意力集中于存在抛洒风险的货车车厢部分. 此外,聚集-分发特征融合机制在颈部网络的引入,解决了浅层网络特征和深层网络特征融合过程中货运抛洒风险关键特征丢失的问题,可以为检测头提供更丰富的货物形状轮廓、装载形式、篷布边缘细节纹理等信息.
4. 结 论
(1)大核可选择性感受野机制在骨干网络的引入,增强了网络对货运车辆抛洒风险特征的学习能力. 聚集-分发特征融合机制在颈部网络的引入,解决了特征跨层融合不充分的问题,避免了特征融合过程中货运车辆关键抛洒风险特征的丢失.
(2)对比实验结果表明,所提方法具有明显的精度和效率优势,mAP@0.5精度达到81.50%,mAP@[0.5:0.95]精度达到61.87%,检测速度为69帧/s,模型参数量为62.7 MB.
(3)对于常用的mAP@0.5指标,相较于基于YOLOv5、YOLOv6车辆检测SOTA方法,分别提升了3.70%、3.09%,较基于YOLOv8、RT-DETR、PP-YOLOE、YOLOv9等目标检测领域的最新SOTA方法提升了2.86%、1.37%、1.41%、2.00%. 对于更严格的mAP@[0.5:0.95]指标,较基于YOLOv5、YOLOv6的车辆检测SOTA方法分别提升了3.72%、3.53%,较基于YOLOv8、RT-DETR、PP-YOLOE、YOLOv9等目标检测领域的最新SOTA方法提升了3.67%、1.83%、1.71%、1.20%. 模型大小保持较小,检测速度较高.
(4)有效提高模型在货物装载不规则、少量货物和满载货物场景下的抛洒风险识别能力,在近景目标、远景目标、车辆遮挡等高速常见的场景环境下仍然保持较好的检测效果.
参考文献
Dropped object detection method based on feature similarity learning
[J].
VCANet: vanishing-point-guided context-aware network for small road object detection
[J].DOI:10.1007/s42154-021-00157-x [本文引用: 1]
面向智慧交通的图像处理与边缘计算
[J].
The review of image processing and edge computing for intelligent transportation system
[J].
基于深度学习的YOLO目标检测综述
[J].
A review of YOLO object detection based on deep learning
[J].
基于无损跨尺度特征融合的交通目标检测算法
[J].
Traffic target detection algorithm based on non-loss cross-scale feature fusion
[J].
Soft-weighted-average ensemble vehicle detection method based on single-stage and two-stage deep learning models
[J].
A review of vehicle detection techniques for intelligent vehicles
[J].DOI:10.1109/TNNLS.2021.3128968
基于深度学习的公路货车车型识别
[J].
Type recognition of highway trucks based on deep learning
[J].
浅谈高速公路抛洒物危害与对策
[J].
Talking about hazard and countermeasure of highway dispersion
[J].
一种基于物影匹配算法的道路小目标跟踪方法
[J].
A road small target tracking approach based on object-shadow matching algorithm
[J].
基于特征相似性学习的抛洒物检测方法
[J].
基于改进 YOLOv3 模型与 Deep-SORT 算法的道路车辆检测方法
[J].
Road vehicle detection method based on improved YOLOv3 model and Deep-SORT algorithm
[J].
基于轻量化网络和注意力机制的智能车快速目标识别方法
[J].
Intelligent vehicle target fast recognition based on lightweight networks and attention mechanism
[J].
基于道路监控的高速公路作业区碰撞风险预警
[J].
Crash risk early warning in highway work zone based on road surveillance camera
[J].
FPPNet: a fixed-perspective-perception module for small object detection based on background difference
[J].DOI:10.1109/JSEN.2023.3263539 [本文引用: 2]
基于无锚框的目标检测方法及其在复杂场景下的应用进展
[J].
Anchor-free based target object detection methods and its application progress in complex scenes
[J].
YOLOv8-QSD: an improved small object detection algorithm for autonomous vehicles based on YOLOv8
[J].
MTP-YOLO: you only look once based maritime tiny person detector for emergency rescue
[J].DOI:10.3390/jmse12040669 [本文引用: 2]
高速公路行车风险路侧感知系统的设备优化布设
[J].
Devices’ optimal deployment of roadside sensing system for expressway driving risk
[J].
Gold-YOLO: efficient object detector via gather-and-distribute mechanism
[J].
A review of object detection: datasets, performance evaluation, architecture, applications and current trends
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}