[2]
LIU Y, JIANG J, SUN J. Hand pose estimation from RGB images based on deep learning: a survey [C]// 2021 IEEE 7th International Conference on Virtual Reality . Foshan: IEEE, 2021: 82−89.
[本文引用: 1]
[3]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . [S.l.]: Curran Associates, 2017: 6000−6010.
[本文引用: 1]
[4]
LIN K, WANG L, LIU Z. End-to-end human pose and mesh reconstruction with transformers [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 1954−1963.
[本文引用: 6]
[5]
CHO J, KIM Y, OH T H. Cross-attention of disentangled modalities for 3D human mesh recovery with transformers [C]// European Conference on Computer Vision . [S.l.]: Springer, 2022: 342−359.
[本文引用: 4]
[6]
ZHENG C, WU W, CHEN C, et al Deep learning-based human pose estimation: a survey
[J]. ACM Computing Surveys , 2023 , 56 (1 ): 11
[本文引用: 1]
[7]
ROMERO J, TZIONAS D, BLACK M J Embodied hands: modeling and capturing hands and bodies together
[J]. ACM Transactions on Graphics , 2017 , 36 (6 ): 245
[本文引用: 2]
[8]
ZHANG X, LI Q, MO H, et al. End-to-end hand mesh recovery from a monocular RGB image [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 2354−2364.
[本文引用: 1]
[9]
BAEK S, KIM K I, KIM T K. Pushing the envelope for RGB-based dense 3D hand pose estimation via neural rendering [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 1067−1076.
[本文引用: 1]
[10]
BOUKHAYMA A, DE BEM R, TORR P H S. 3D hand shape and pose from images in the wild [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 10835−10844.
[本文引用: 1]
[11]
ZIMMERMANN C, BROX T. Learning to estimate 3D hand pose from single RGB images [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 4913−4921.
[本文引用: 1]
[12]
IQBAL U, MOLCHANOV P, BREUEL T, et al. Hand pose estimation via latent 2.5D heatmap regression [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 125−143.
[本文引用: 1]
[13]
KULON D, GÜLER R A, KOKKINOS I, et al. Weakly-supervised mesh-convolutional hand reconstruction in the wild [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 4989−4999.
[本文引用: 1]
[14]
GE L, REN Z, LI Y, et al. 3D hand shape and pose estimation from a single RGB image [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 10825−10834.
[本文引用: 1]
[15]
CHEN X, LIU Y, MA C, et al. Camera-space hand mesh recovery via semantic aggregation and adaptive 2D-1D registration [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 13269−13278.
[本文引用: 2]
[16]
ZHU X, SU W, LU L, et al. Deformable DETR: deformable transformers for end-to-end object detection [EB/OL]. (2021−03−18)[2023−11−20]. https://arxiv.org/abs/2010.04159.
[本文引用: 2]
[17]
LIN K, WANG L, LIU Z. Mesh graphormer [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 12919−12928.
[本文引用: 1]
[18]
ZIMMERMANN C, CEYLAN D, YANG J, et al. FreiHAND: a dataset for markerless capture of hand pose and shape from single RGB images [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 813−822.
[本文引用: 1]
[19]
HAMPALI S, RAD M, OBERWEGER M, et al. HOnnotate: a method for 3D annotation of hand and object poses [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 3193−3203.
[本文引用: 1]
[20]
HAMPALI S, SARKAR S D, LEPETIT V. HO-3D_v3: improving the accuracy of hand-object annotations of the HO-3D dataset [EB/OL]. (2021−07−02)[2024−03−17]. https://arxiv.org/abs/2107.00887.
[本文引用: 1]
[22]
LIM G M, JATESIKTAT P, ANG W T. Mobilehand: real-time 3D hand shape and pose estimation from color image [C]// International Conference on Neural Information Processing . [S.l.]: Springer, 2020: 450−459.
[本文引用: 1]
[23]
CHOI H, MOON G, LEE K M. Pose2Mesh: graph convolutional network for 3D human pose and mesh recovery from a 2D human pose [C]// European Conference on Computer Vision . [S.l.]: Springer, 2020: 769−787.
[本文引用: 2]
[24]
MOON G, LEE K M. I2l-MeshNet: image-to-lixel prediction network for accurate 3D human pose and mesh estimation from a single RGB image [C]// European Conference on Computer Vision . [S.l.]: Springer, 2020: 752−768.
[本文引用: 1]
[25]
CHEN P, CHEN Y, YANG D, et al. I2UV-HandNet: image-to-UV prediction network for accurate and high-fidelity 3D hand mesh modeling [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 12909−12918.
[本文引用: 1]
[26]
SEEBER M, PORANNE R, POLLEYFEYS M, et al. Realistichands: a hybrid model for 3D hand reconstruction [C]// 2021 International Conference on 3D Vision . London: IEEE, 2021: 22−31.
[本文引用: 1]
[27]
YU T, BIDULKA L, MCKEOWN M J, et al PA-Tran: learning to estimate 3D hand pose with partial annotation
[J]. Sensors , 2023 , 23 (3 ): 1555
DOI:10.3390/s23031555
[本文引用: 1]
[28]
VASU P K A, GABRIEL J, ZHU J, et al. FastViT: a fast hybrid vision Transformer using structural reparameterization [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Paris: IEEE, 2023: 5762−5772.
[本文引用: 1]
[29]
YANG L, LI K, ZHAN X, et al. ArtiBoost: boosting articulated 3D hand-object pose estimation via online exploration and synthesis [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 2740−2750.
[本文引用: 2]
[30]
HAMPALI S, SARKAR S D, RAD M, et al. Keypoint Transformer: solving joint identification in challenging hands and object interactions for accurate 3D pose estimation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 11080−11090.
[本文引用: 2]
[31]
PARK J, OH Y, MOON G, et al. HandOccNet: occlusion-robust 3D hand mesh estimation network [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 1486−1495.
[本文引用: 1]
A survey on 3D hand pose estimation: cameras, methods, and datasets
1
2019
... 手部姿态估计是先从图像或视频中精确定位手部关节点的位置,再根据这些位置确定手部姿态的技术. 三维手部姿态估计要求在空间中展现具体的手部姿态,被广泛应用于机器人[1 ] 、虚拟现实[2 ] 和增强现实等领域. 因此,通过分析图像/视频数据,恢复图像/视频中的三维手部姿态具有重大的应用研究价值. ...
1
... 手部姿态估计是先从图像或视频中精确定位手部关节点的位置,再根据这些位置确定手部姿态的技术. 三维手部姿态估计要求在空间中展现具体的手部姿态,被广泛应用于机器人[1 ] 、虚拟现实[2 ] 和增强现实等领域. 因此,通过分析图像/视频数据,恢复图像/视频中的三维手部姿态具有重大的应用研究价值. ...
1
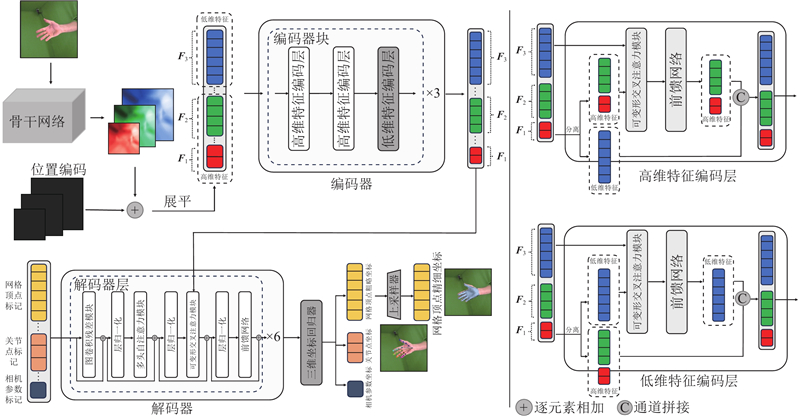
... 通过单目RGB图像实现三维手部姿态估计备受学者关注. 在数据获取方面,单目RGB图像比其他形式的数据(如深度图像和可穿戴设备获取的数据)获取成本更低;在实际应用方面,手机、智能眼镜设置的相机是单目相机,只能得到人手的单目RGB图像. 此外,多目RGB图像及深度图像相较于单目RGB图像虽然包含了有效的深度信息,但是多目相机系统和深度相机的技术尚不完善,难以应用至现实生活中. 随着深度学习技术的进步,有学者使用Transformer[3 ] 结构从单目RGB图像中回归三维手部姿态. 如METRO (mesh transformer)[4 ] 、FastMETRO[5 ] 的基于Transformer的姿态估计方法被相继提出,均在人体姿态估计[6 ] 、手部姿态估计应用中取得了不错的效果. METRO由于重复利用图像特征序列导致模型庞大而遭到诟病. FastMETRO将图像特征和关节点、网格顶点标记进行交叉注意力计算,大大减少了模型参数,便于模型优化. FastMETRO的模型设计难以引入低维(高分辨率)图像特征,仅利用来自骨干网络深层的高维(低分辨率)图像特征,这些图像特征蕴含丰富的全局语义信息,却缺乏图像的空间局部信息,如果能在模型中融入低维图像特征,则有望促使网络学习到更丰富的空间局部信息,从而回归出更准确的手部姿态. ...
6
... 通过单目RGB图像实现三维手部姿态估计备受学者关注. 在数据获取方面,单目RGB图像比其他形式的数据(如深度图像和可穿戴设备获取的数据)获取成本更低;在实际应用方面,手机、智能眼镜设置的相机是单目相机,只能得到人手的单目RGB图像. 此外,多目RGB图像及深度图像相较于单目RGB图像虽然包含了有效的深度信息,但是多目相机系统和深度相机的技术尚不完善,难以应用至现实生活中. 随着深度学习技术的进步,有学者使用Transformer[3 ] 结构从单目RGB图像中回归三维手部姿态. 如METRO (mesh transformer)[4 ] 、FastMETRO[5 ] 的基于Transformer的姿态估计方法被相继提出,均在人体姿态估计[6 ] 、手部姿态估计应用中取得了不错的效果. METRO由于重复利用图像特征序列导致模型庞大而遭到诟病. FastMETRO将图像特征和关节点、网格顶点标记进行交叉注意力计算,大大减少了模型参数,便于模型优化. FastMETRO的模型设计难以引入低维(高分辨率)图像特征,仅利用来自骨干网络深层的高维(低分辨率)图像特征,这些图像特征蕴含丰富的全局语义信息,却缺乏图像的空间局部信息,如果能在模型中融入低维图像特征,则有望促使网络学习到更丰富的空间局部信息,从而回归出更准确的手部姿态. ...
... 随着深度学习技术的进步,各种非基于参数化模型的方法被提出,Zimmermann等[11 ] 直接估计三维关节点坐标或者热图,Iqbal等[12 -13 ] 使用2.5D特征表示方法,Ge等[14 -15 ] 通过图卷积网络的方式直接估计三维手部网格顶点等,流行的方法是通过Transformer网络结构直接估计三维手部网格顶点. Lin等[4 ] 改进Transformer结构,提出无参数化模型的方法,通过所提出的层级递减的Transformer编码器将图像特征附加在网格顶点的标记上来构建网格顶点向量,在编码器中多次更新后回归生成三维网格顶点坐标. 该方法实现效果较好,但是重复利用图像特征致使模型参数量庞大,增大了训练难度. Cho等[5 ] 改进了Lin等[4 ] 提出的网络模型,设计出基于交叉注意力机制的编解码器方法——FastMETRO. 该方法利用骨干网络提取图像高维特征,再对图像高维特征进行位置编码,并将位置编码后的图像高维特征与预定义的关节点标记、网格顶点标记输入双Transformer编码器-双Transformer解码器结构中,输出的关节点标记、网格顶点标记将在坐标回归器中回归成对应坐标. 交叉注意力机制让FastMETRO不仅能够利用图像特征和网格顶点标记这2种不同模态各自的内在关系,还能够利用图像特征与网格顶点标记之间的模态间关系,补充并增强图像特征与网格顶点标记间的匹配关系. 此外,该方法利用人体形态学的先验知识来屏蔽注意力. FastMETRO没有解决Transformer的多头注意力机制计算复杂度与输入序列长度高度相关的问题. 若特征图分辨率较高,对应的图像特征序列很长,将直接导致FastMETRO多头注意力机制的计算开销增长,因此该方法无法有效利用低维图像特征的局部空间信息生成手部姿态. ...
... [4 ]提出的网络模型,设计出基于交叉注意力机制的编解码器方法——FastMETRO. 该方法利用骨干网络提取图像高维特征,再对图像高维特征进行位置编码,并将位置编码后的图像高维特征与预定义的关节点标记、网格顶点标记输入双Transformer编码器-双Transformer解码器结构中,输出的关节点标记、网格顶点标记将在坐标回归器中回归成对应坐标. 交叉注意力机制让FastMETRO不仅能够利用图像特征和网格顶点标记这2种不同模态各自的内在关系,还能够利用图像特征与网格顶点标记之间的模态间关系,补充并增强图像特征与网格顶点标记间的匹配关系. 此外,该方法利用人体形态学的先验知识来屏蔽注意力. FastMETRO没有解决Transformer的多头注意力机制计算复杂度与输入序列长度高度相关的问题. 若特征图分辨率较高,对应的图像特征序列很长,将直接导致FastMETRO多头注意力机制的计算开销增长,因此该方法无法有效利用低维图像特征的局部空间信息生成手部姿态. ...
... Performance comparison of different 3D hand pose estimation methods in FreiHAND dataset
Tab.1 方法 PA-MPJPE/mm PA-MPVPE/mm F@5 F@15 MobileHand[22 ] — 13.1 0.439 0.902 FreiHAND[7 ] 11.0 10.9 0.516 0.934 Pose2Mesh[23 ] 7.8 7.7 0.674 0.969 I2L-MeshNet[24 ] 7.4 7.6 0.681 0.973 CMR[15 ] 6.9 7.0 0.715 0.977 I2UV-HandNet[25 ] 6.7 6.9 0.707 0.977 METRO[4 ] 6.3 6.5 0.731 0.984 RealisticHands[26 ] — 7.8 0.662 0.971 FastMETRO[5 ] 6.5 7.2 0.688 0.983 PA-Tran[27 ] 6.0 6.3 — — FastViT-MA36[28 ] 6.6 6.7 0.722 0.981 本研究(ResNet) 6.4 6.7 0.714 0.982 本研究(HRNet) 5.8 6.2 0.749 0.986
如图5 所示为本研究所提方法预测得到的6组手部网格(各分图的右侧图)和真实手部网格(各分图的居中图)结果对比,原始图像(各分图的左侧图)来自FreiHAND. 在挑选的6组手部图像示例中,一部分没有任何遮挡,一部分存在手部自遮挡,还有一部分被不相关的物体遮挡. 如图5 (a)所示,虽然图像中手部被物体遮挡,缺少了部分手部信息,但是恢复出的三维手部网格仍较为准确. 总体来看,所提方法可以在一定程度上处理物体对手部的遮挡,具有较好的鲁棒性. ...
... Performance parameters of Transformer related methods in FreiHAND dataset
Tab.2 方法 N TP /106 N OP /106 FPS/(帧·s−1 ) PA-MPJPE/mm PA-MPVPE/mm FLOPs/109 METRO[4 ] 102.3 230.4 37±3 6.3 6.5 108.7 FastMETRO[5 ] 24.9 153.0 52±3 6.5 7.2 71.0 本研究(HRNet) 13.9 129.6 38±3 5.8 6.2 80.0
为了验证所提方法的泛用性,采用数据集HO3D V2、HO3D V3进行评估和验证. 所提方法与其他方法在HO3D V2数据集上的评估结果对比如表3 所示. HO3D V2相较于FreiHAND遮挡更为严重,遮挡物更加丰富,因此回归精度更低. 由表可知,相较于METRO、ArtiBoost、Keypoint Transformer等方法,所提方法的回归精度更高,经普鲁克对齐后,关节点坐标误差和网格顶点坐标误差均为10.0 mm,F@5=0.512,F@15=0.951. 综合FreiHAND和HO3D V2数据集上的评估表现可以发现,所提方法在手部姿态估计任务中性能良好,具有一定的泛化性. 所提方法与其他方法在HO3D V3数据集上的评估结果对比如表4 所示. 所提方法在该数据集上关节点坐标平均误差为10.5 mm,网格顶点坐标平均误差为10.3 mm,均优于其他先进方法. ...
... Performance comparison of different 3D hand pose estimation methods in HO3D V2 dataset
Tab.3 方法 PA- PA- F@5 F@15 Pose2Mesh[23 ] 12.5 12.7 0.441 0.909 METRO[4 ] 10.4 11.1 0.484 0.946 ArtiBoost[29 ] 11.4 10.9 0.488 0.944 Keypoint Transformer[30 ] 10.8 — — — 本研究(HRNet) 10.0 10.0 0.512 0.951
表 4 不同三维手部姿态估计方法在HO3D V3数据集上的性能对比 ...
4
... 通过单目RGB图像实现三维手部姿态估计备受学者关注. 在数据获取方面,单目RGB图像比其他形式的数据(如深度图像和可穿戴设备获取的数据)获取成本更低;在实际应用方面,手机、智能眼镜设置的相机是单目相机,只能得到人手的单目RGB图像. 此外,多目RGB图像及深度图像相较于单目RGB图像虽然包含了有效的深度信息,但是多目相机系统和深度相机的技术尚不完善,难以应用至现实生活中. 随着深度学习技术的进步,有学者使用Transformer[3 ] 结构从单目RGB图像中回归三维手部姿态. 如METRO (mesh transformer)[4 ] 、FastMETRO[5 ] 的基于Transformer的姿态估计方法被相继提出,均在人体姿态估计[6 ] 、手部姿态估计应用中取得了不错的效果. METRO由于重复利用图像特征序列导致模型庞大而遭到诟病. FastMETRO将图像特征和关节点、网格顶点标记进行交叉注意力计算,大大减少了模型参数,便于模型优化. FastMETRO的模型设计难以引入低维(高分辨率)图像特征,仅利用来自骨干网络深层的高维(低分辨率)图像特征,这些图像特征蕴含丰富的全局语义信息,却缺乏图像的空间局部信息,如果能在模型中融入低维图像特征,则有望促使网络学习到更丰富的空间局部信息,从而回归出更准确的手部姿态. ...
... 随着深度学习技术的进步,各种非基于参数化模型的方法被提出,Zimmermann等[11 ] 直接估计三维关节点坐标或者热图,Iqbal等[12 -13 ] 使用2.5D特征表示方法,Ge等[14 -15 ] 通过图卷积网络的方式直接估计三维手部网格顶点等,流行的方法是通过Transformer网络结构直接估计三维手部网格顶点. Lin等[4 ] 改进Transformer结构,提出无参数化模型的方法,通过所提出的层级递减的Transformer编码器将图像特征附加在网格顶点的标记上来构建网格顶点向量,在编码器中多次更新后回归生成三维网格顶点坐标. 该方法实现效果较好,但是重复利用图像特征致使模型参数量庞大,增大了训练难度. Cho等[5 ] 改进了Lin等[4 ] 提出的网络模型,设计出基于交叉注意力机制的编解码器方法——FastMETRO. 该方法利用骨干网络提取图像高维特征,再对图像高维特征进行位置编码,并将位置编码后的图像高维特征与预定义的关节点标记、网格顶点标记输入双Transformer编码器-双Transformer解码器结构中,输出的关节点标记、网格顶点标记将在坐标回归器中回归成对应坐标. 交叉注意力机制让FastMETRO不仅能够利用图像特征和网格顶点标记这2种不同模态各自的内在关系,还能够利用图像特征与网格顶点标记之间的模态间关系,补充并增强图像特征与网格顶点标记间的匹配关系. 此外,该方法利用人体形态学的先验知识来屏蔽注意力. FastMETRO没有解决Transformer的多头注意力机制计算复杂度与输入序列长度高度相关的问题. 若特征图分辨率较高,对应的图像特征序列很长,将直接导致FastMETRO多头注意力机制的计算开销增长,因此该方法无法有效利用低维图像特征的局部空间信息生成手部姿态. ...
... Performance comparison of different 3D hand pose estimation methods in FreiHAND dataset
Tab.1 方法 PA-MPJPE/mm PA-MPVPE/mm F@5 F@15 MobileHand[22 ] — 13.1 0.439 0.902 FreiHAND[7 ] 11.0 10.9 0.516 0.934 Pose2Mesh[23 ] 7.8 7.7 0.674 0.969 I2L-MeshNet[24 ] 7.4 7.6 0.681 0.973 CMR[15 ] 6.9 7.0 0.715 0.977 I2UV-HandNet[25 ] 6.7 6.9 0.707 0.977 METRO[4 ] 6.3 6.5 0.731 0.984 RealisticHands[26 ] — 7.8 0.662 0.971 FastMETRO[5 ] 6.5 7.2 0.688 0.983 PA-Tran[27 ] 6.0 6.3 — — FastViT-MA36[28 ] 6.6 6.7 0.722 0.981 本研究(ResNet) 6.4 6.7 0.714 0.982 本研究(HRNet) 5.8 6.2 0.749 0.986
如图5 所示为本研究所提方法预测得到的6组手部网格(各分图的右侧图)和真实手部网格(各分图的居中图)结果对比,原始图像(各分图的左侧图)来自FreiHAND. 在挑选的6组手部图像示例中,一部分没有任何遮挡,一部分存在手部自遮挡,还有一部分被不相关的物体遮挡. 如图5 (a)所示,虽然图像中手部被物体遮挡,缺少了部分手部信息,但是恢复出的三维手部网格仍较为准确. 总体来看,所提方法可以在一定程度上处理物体对手部的遮挡,具有较好的鲁棒性. ...
... Performance parameters of Transformer related methods in FreiHAND dataset
Tab.2 方法 N TP /106 N OP /106 FPS/(帧·s−1 ) PA-MPJPE/mm PA-MPVPE/mm FLOPs/109 METRO[4 ] 102.3 230.4 37±3 6.3 6.5 108.7 FastMETRO[5 ] 24.9 153.0 52±3 6.5 7.2 71.0 本研究(HRNet) 13.9 129.6 38±3 5.8 6.2 80.0
为了验证所提方法的泛用性,采用数据集HO3D V2、HO3D V3进行评估和验证. 所提方法与其他方法在HO3D V2数据集上的评估结果对比如表3 所示. HO3D V2相较于FreiHAND遮挡更为严重,遮挡物更加丰富,因此回归精度更低. 由表可知,相较于METRO、ArtiBoost、Keypoint Transformer等方法,所提方法的回归精度更高,经普鲁克对齐后,关节点坐标误差和网格顶点坐标误差均为10.0 mm,F@5=0.512,F@15=0.951. 综合FreiHAND和HO3D V2数据集上的评估表现可以发现,所提方法在手部姿态估计任务中性能良好,具有一定的泛化性. 所提方法与其他方法在HO3D V3数据集上的评估结果对比如表4 所示. 所提方法在该数据集上关节点坐标平均误差为10.5 mm,网格顶点坐标平均误差为10.3 mm,均优于其他先进方法. ...
Deep learning-based human pose estimation: a survey
1
2023
... 通过单目RGB图像实现三维手部姿态估计备受学者关注. 在数据获取方面,单目RGB图像比其他形式的数据(如深度图像和可穿戴设备获取的数据)获取成本更低;在实际应用方面,手机、智能眼镜设置的相机是单目相机,只能得到人手的单目RGB图像. 此外,多目RGB图像及深度图像相较于单目RGB图像虽然包含了有效的深度信息,但是多目相机系统和深度相机的技术尚不完善,难以应用至现实生活中. 随着深度学习技术的进步,有学者使用Transformer[3 ] 结构从单目RGB图像中回归三维手部姿态. 如METRO (mesh transformer)[4 ] 、FastMETRO[5 ] 的基于Transformer的姿态估计方法被相继提出,均在人体姿态估计[6 ] 、手部姿态估计应用中取得了不错的效果. METRO由于重复利用图像特征序列导致模型庞大而遭到诟病. FastMETRO将图像特征和关节点、网格顶点标记进行交叉注意力计算,大大减少了模型参数,便于模型优化. FastMETRO的模型设计难以引入低维(高分辨率)图像特征,仅利用来自骨干网络深层的高维(低分辨率)图像特征,这些图像特征蕴含丰富的全局语义信息,却缺乏图像的空间局部信息,如果能在模型中融入低维图像特征,则有望促使网络学习到更丰富的空间局部信息,从而回归出更准确的手部姿态. ...
Embodied hands: modeling and capturing hands and bodies together
2
2017
... 三维手部姿态估计方法分为2个大类. 1)基于参数化模型的方法:先回归以具有铰接和非刚性变形的手模型(model with articulated and non-rigid deformations,MANO)[7 ] 为代表的手部参数化模型的全局姿态参数和形状参数,再通过这些参数恢复出三维手部网格的方法. 早期的研究基本采用这类方法. 2)非基于参数化模型的方法:直接回归出三维手部网格顶点的坐标,目前这类方法更受关注. ...
... Performance comparison of different 3D hand pose estimation methods in FreiHAND dataset
Tab.1 方法 PA-MPJPE/mm PA-MPVPE/mm F@5 F@15 MobileHand[22 ] — 13.1 0.439 0.902 FreiHAND[7 ] 11.0 10.9 0.516 0.934 Pose2Mesh[23 ] 7.8 7.7 0.674 0.969 I2L-MeshNet[24 ] 7.4 7.6 0.681 0.973 CMR[15 ] 6.9 7.0 0.715 0.977 I2UV-HandNet[25 ] 6.7 6.9 0.707 0.977 METRO[4 ] 6.3 6.5 0.731 0.984 RealisticHands[26 ] — 7.8 0.662 0.971 FastMETRO[5 ] 6.5 7.2 0.688 0.983 PA-Tran[27 ] 6.0 6.3 — — FastViT-MA36[28 ] 6.6 6.7 0.722 0.981 本研究(ResNet) 6.4 6.7 0.714 0.982 本研究(HRNet) 5.8 6.2 0.749 0.986
如图5 所示为本研究所提方法预测得到的6组手部网格(各分图的右侧图)和真实手部网格(各分图的居中图)结果对比,原始图像(各分图的左侧图)来自FreiHAND. 在挑选的6组手部图像示例中,一部分没有任何遮挡,一部分存在手部自遮挡,还有一部分被不相关的物体遮挡. 如图5 (a)所示,虽然图像中手部被物体遮挡,缺少了部分手部信息,但是恢复出的三维手部网格仍较为准确. 总体来看,所提方法可以在一定程度上处理物体对手部的遮挡,具有较好的鲁棒性. ...
1
... 基于参数化模型的方法主要利用手部参数化模型生成三维手部姿态,弥补了单目RGB图像缺少有效的深度信息的不足. MANO是应用较广泛的手部参数化模型,包含778个网格顶点,1 538个面片,16个手部关节点以及从网格顶点中获取的5个指尖点构成的完整的前向动力学树. Zhang等[8 ] 利用MANO实现了三维手部姿态估计,提出的HAMR方法将单目RGB图像回归成二维关节点热图,并将热图迭代回归成MANO模型参数,生成对应的手部网格并通过线性插值得到手部关节点的空间坐标. Baek等[9 ] 提出通过神经网络和微分渲染器实现网格估计,应用迭代测试细化和自我数据增强实现更好拟合. Boukhayma等[10 ] 使用深度卷积编码器回归MANO参数模型,结合二维关节点损失和三维关节点损失进行监督训练. 这类方法存在共同的问题:通过二维图像进行手部模型参数的回归是高度非线性的,在表示复杂的手形时效果可能不理想. ...
1
... 基于参数化模型的方法主要利用手部参数化模型生成三维手部姿态,弥补了单目RGB图像缺少有效的深度信息的不足. MANO是应用较广泛的手部参数化模型,包含778个网格顶点,1 538个面片,16个手部关节点以及从网格顶点中获取的5个指尖点构成的完整的前向动力学树. Zhang等[8 ] 利用MANO实现了三维手部姿态估计,提出的HAMR方法将单目RGB图像回归成二维关节点热图,并将热图迭代回归成MANO模型参数,生成对应的手部网格并通过线性插值得到手部关节点的空间坐标. Baek等[9 ] 提出通过神经网络和微分渲染器实现网格估计,应用迭代测试细化和自我数据增强实现更好拟合. Boukhayma等[10 ] 使用深度卷积编码器回归MANO参数模型,结合二维关节点损失和三维关节点损失进行监督训练. 这类方法存在共同的问题:通过二维图像进行手部模型参数的回归是高度非线性的,在表示复杂的手形时效果可能不理想. ...
1
... 基于参数化模型的方法主要利用手部参数化模型生成三维手部姿态,弥补了单目RGB图像缺少有效的深度信息的不足. MANO是应用较广泛的手部参数化模型,包含778个网格顶点,1 538个面片,16个手部关节点以及从网格顶点中获取的5个指尖点构成的完整的前向动力学树. Zhang等[8 ] 利用MANO实现了三维手部姿态估计,提出的HAMR方法将单目RGB图像回归成二维关节点热图,并将热图迭代回归成MANO模型参数,生成对应的手部网格并通过线性插值得到手部关节点的空间坐标. Baek等[9 ] 提出通过神经网络和微分渲染器实现网格估计,应用迭代测试细化和自我数据增强实现更好拟合. Boukhayma等[10 ] 使用深度卷积编码器回归MANO参数模型,结合二维关节点损失和三维关节点损失进行监督训练. 这类方法存在共同的问题:通过二维图像进行手部模型参数的回归是高度非线性的,在表示复杂的手形时效果可能不理想. ...
1
... 随着深度学习技术的进步,各种非基于参数化模型的方法被提出,Zimmermann等[11 ] 直接估计三维关节点坐标或者热图,Iqbal等[12 -13 ] 使用2.5D特征表示方法,Ge等[14 -15 ] 通过图卷积网络的方式直接估计三维手部网格顶点等,流行的方法是通过Transformer网络结构直接估计三维手部网格顶点. Lin等[4 ] 改进Transformer结构,提出无参数化模型的方法,通过所提出的层级递减的Transformer编码器将图像特征附加在网格顶点的标记上来构建网格顶点向量,在编码器中多次更新后回归生成三维网格顶点坐标. 该方法实现效果较好,但是重复利用图像特征致使模型参数量庞大,增大了训练难度. Cho等[5 ] 改进了Lin等[4 ] 提出的网络模型,设计出基于交叉注意力机制的编解码器方法——FastMETRO. 该方法利用骨干网络提取图像高维特征,再对图像高维特征进行位置编码,并将位置编码后的图像高维特征与预定义的关节点标记、网格顶点标记输入双Transformer编码器-双Transformer解码器结构中,输出的关节点标记、网格顶点标记将在坐标回归器中回归成对应坐标. 交叉注意力机制让FastMETRO不仅能够利用图像特征和网格顶点标记这2种不同模态各自的内在关系,还能够利用图像特征与网格顶点标记之间的模态间关系,补充并增强图像特征与网格顶点标记间的匹配关系. 此外,该方法利用人体形态学的先验知识来屏蔽注意力. FastMETRO没有解决Transformer的多头注意力机制计算复杂度与输入序列长度高度相关的问题. 若特征图分辨率较高,对应的图像特征序列很长,将直接导致FastMETRO多头注意力机制的计算开销增长,因此该方法无法有效利用低维图像特征的局部空间信息生成手部姿态. ...
1
... 随着深度学习技术的进步,各种非基于参数化模型的方法被提出,Zimmermann等[11 ] 直接估计三维关节点坐标或者热图,Iqbal等[12 -13 ] 使用2.5D特征表示方法,Ge等[14 -15 ] 通过图卷积网络的方式直接估计三维手部网格顶点等,流行的方法是通过Transformer网络结构直接估计三维手部网格顶点. Lin等[4 ] 改进Transformer结构,提出无参数化模型的方法,通过所提出的层级递减的Transformer编码器将图像特征附加在网格顶点的标记上来构建网格顶点向量,在编码器中多次更新后回归生成三维网格顶点坐标. 该方法实现效果较好,但是重复利用图像特征致使模型参数量庞大,增大了训练难度. Cho等[5 ] 改进了Lin等[4 ] 提出的网络模型,设计出基于交叉注意力机制的编解码器方法——FastMETRO. 该方法利用骨干网络提取图像高维特征,再对图像高维特征进行位置编码,并将位置编码后的图像高维特征与预定义的关节点标记、网格顶点标记输入双Transformer编码器-双Transformer解码器结构中,输出的关节点标记、网格顶点标记将在坐标回归器中回归成对应坐标. 交叉注意力机制让FastMETRO不仅能够利用图像特征和网格顶点标记这2种不同模态各自的内在关系,还能够利用图像特征与网格顶点标记之间的模态间关系,补充并增强图像特征与网格顶点标记间的匹配关系. 此外,该方法利用人体形态学的先验知识来屏蔽注意力. FastMETRO没有解决Transformer的多头注意力机制计算复杂度与输入序列长度高度相关的问题. 若特征图分辨率较高,对应的图像特征序列很长,将直接导致FastMETRO多头注意力机制的计算开销增长,因此该方法无法有效利用低维图像特征的局部空间信息生成手部姿态. ...
1
... 随着深度学习技术的进步,各种非基于参数化模型的方法被提出,Zimmermann等[11 ] 直接估计三维关节点坐标或者热图,Iqbal等[12 -13 ] 使用2.5D特征表示方法,Ge等[14 -15 ] 通过图卷积网络的方式直接估计三维手部网格顶点等,流行的方法是通过Transformer网络结构直接估计三维手部网格顶点. Lin等[4 ] 改进Transformer结构,提出无参数化模型的方法,通过所提出的层级递减的Transformer编码器将图像特征附加在网格顶点的标记上来构建网格顶点向量,在编码器中多次更新后回归生成三维网格顶点坐标. 该方法实现效果较好,但是重复利用图像特征致使模型参数量庞大,增大了训练难度. Cho等[5 ] 改进了Lin等[4 ] 提出的网络模型,设计出基于交叉注意力机制的编解码器方法——FastMETRO. 该方法利用骨干网络提取图像高维特征,再对图像高维特征进行位置编码,并将位置编码后的图像高维特征与预定义的关节点标记、网格顶点标记输入双Transformer编码器-双Transformer解码器结构中,输出的关节点标记、网格顶点标记将在坐标回归器中回归成对应坐标. 交叉注意力机制让FastMETRO不仅能够利用图像特征和网格顶点标记这2种不同模态各自的内在关系,还能够利用图像特征与网格顶点标记之间的模态间关系,补充并增强图像特征与网格顶点标记间的匹配关系. 此外,该方法利用人体形态学的先验知识来屏蔽注意力. FastMETRO没有解决Transformer的多头注意力机制计算复杂度与输入序列长度高度相关的问题. 若特征图分辨率较高,对应的图像特征序列很长,将直接导致FastMETRO多头注意力机制的计算开销增长,因此该方法无法有效利用低维图像特征的局部空间信息生成手部姿态. ...
1
... 随着深度学习技术的进步,各种非基于参数化模型的方法被提出,Zimmermann等[11 ] 直接估计三维关节点坐标或者热图,Iqbal等[12 -13 ] 使用2.5D特征表示方法,Ge等[14 -15 ] 通过图卷积网络的方式直接估计三维手部网格顶点等,流行的方法是通过Transformer网络结构直接估计三维手部网格顶点. Lin等[4 ] 改进Transformer结构,提出无参数化模型的方法,通过所提出的层级递减的Transformer编码器将图像特征附加在网格顶点的标记上来构建网格顶点向量,在编码器中多次更新后回归生成三维网格顶点坐标. 该方法实现效果较好,但是重复利用图像特征致使模型参数量庞大,增大了训练难度. Cho等[5 ] 改进了Lin等[4 ] 提出的网络模型,设计出基于交叉注意力机制的编解码器方法——FastMETRO. 该方法利用骨干网络提取图像高维特征,再对图像高维特征进行位置编码,并将位置编码后的图像高维特征与预定义的关节点标记、网格顶点标记输入双Transformer编码器-双Transformer解码器结构中,输出的关节点标记、网格顶点标记将在坐标回归器中回归成对应坐标. 交叉注意力机制让FastMETRO不仅能够利用图像特征和网格顶点标记这2种不同模态各自的内在关系,还能够利用图像特征与网格顶点标记之间的模态间关系,补充并增强图像特征与网格顶点标记间的匹配关系. 此外,该方法利用人体形态学的先验知识来屏蔽注意力. FastMETRO没有解决Transformer的多头注意力机制计算复杂度与输入序列长度高度相关的问题. 若特征图分辨率较高,对应的图像特征序列很长,将直接导致FastMETRO多头注意力机制的计算开销增长,因此该方法无法有效利用低维图像特征的局部空间信息生成手部姿态. ...
2
... 随着深度学习技术的进步,各种非基于参数化模型的方法被提出,Zimmermann等[11 ] 直接估计三维关节点坐标或者热图,Iqbal等[12 -13 ] 使用2.5D特征表示方法,Ge等[14 -15 ] 通过图卷积网络的方式直接估计三维手部网格顶点等,流行的方法是通过Transformer网络结构直接估计三维手部网格顶点. Lin等[4 ] 改进Transformer结构,提出无参数化模型的方法,通过所提出的层级递减的Transformer编码器将图像特征附加在网格顶点的标记上来构建网格顶点向量,在编码器中多次更新后回归生成三维网格顶点坐标. 该方法实现效果较好,但是重复利用图像特征致使模型参数量庞大,增大了训练难度. Cho等[5 ] 改进了Lin等[4 ] 提出的网络模型,设计出基于交叉注意力机制的编解码器方法——FastMETRO. 该方法利用骨干网络提取图像高维特征,再对图像高维特征进行位置编码,并将位置编码后的图像高维特征与预定义的关节点标记、网格顶点标记输入双Transformer编码器-双Transformer解码器结构中,输出的关节点标记、网格顶点标记将在坐标回归器中回归成对应坐标. 交叉注意力机制让FastMETRO不仅能够利用图像特征和网格顶点标记这2种不同模态各自的内在关系,还能够利用图像特征与网格顶点标记之间的模态间关系,补充并增强图像特征与网格顶点标记间的匹配关系. 此外,该方法利用人体形态学的先验知识来屏蔽注意力. FastMETRO没有解决Transformer的多头注意力机制计算复杂度与输入序列长度高度相关的问题. 若特征图分辨率较高,对应的图像特征序列很长,将直接导致FastMETRO多头注意力机制的计算开销增长,因此该方法无法有效利用低维图像特征的局部空间信息生成手部姿态. ...
... Performance comparison of different 3D hand pose estimation methods in FreiHAND dataset
Tab.1 方法 PA-MPJPE/mm PA-MPVPE/mm F@5 F@15 MobileHand[22 ] — 13.1 0.439 0.902 FreiHAND[7 ] 11.0 10.9 0.516 0.934 Pose2Mesh[23 ] 7.8 7.7 0.674 0.969 I2L-MeshNet[24 ] 7.4 7.6 0.681 0.973 CMR[15 ] 6.9 7.0 0.715 0.977 I2UV-HandNet[25 ] 6.7 6.9 0.707 0.977 METRO[4 ] 6.3 6.5 0.731 0.984 RealisticHands[26 ] — 7.8 0.662 0.971 FastMETRO[5 ] 6.5 7.2 0.688 0.983 PA-Tran[27 ] 6.0 6.3 — — FastViT-MA36[28 ] 6.6 6.7 0.722 0.981 本研究(ResNet) 6.4 6.7 0.714 0.982 本研究(HRNet) 5.8 6.2 0.749 0.986
如图5 所示为本研究所提方法预测得到的6组手部网格(各分图的右侧图)和真实手部网格(各分图的居中图)结果对比,原始图像(各分图的左侧图)来自FreiHAND. 在挑选的6组手部图像示例中,一部分没有任何遮挡,一部分存在手部自遮挡,还有一部分被不相关的物体遮挡. 如图5 (a)所示,虽然图像中手部被物体遮挡,缺少了部分手部信息,但是恢复出的三维手部网格仍较为准确. 总体来看,所提方法可以在一定程度上处理物体对手部的遮挡,具有较好的鲁棒性. ...
2
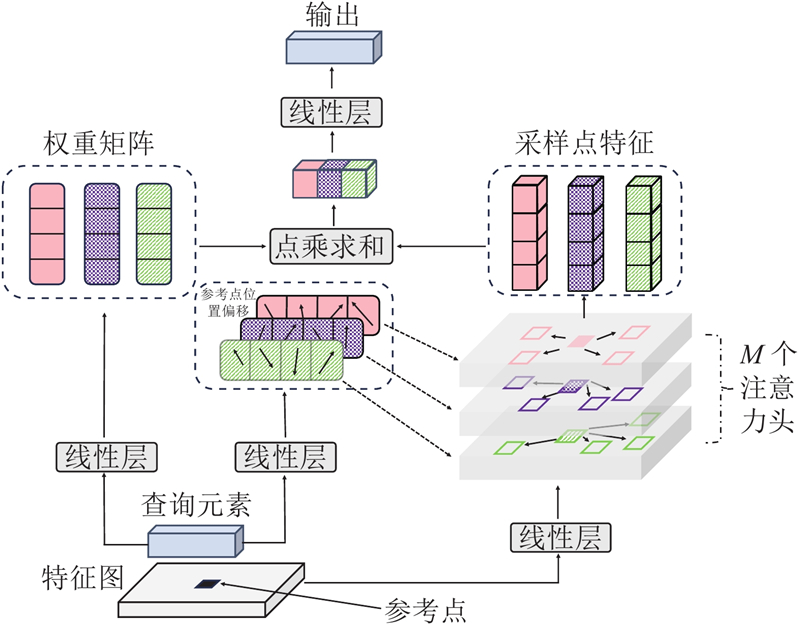
... FastMETRO编码器采用传统多头注意力机制,计算过程处理了过多的无效信息. 由于图像特征的序列长度与特征图的分辨率高度相关,当特征图分辨率较高时,注意力机制的计算十分复杂. 受Zhu等[16 ] 的工作启发,本研究引入可变形注意力机制,该机制的计算流程如图2 所示. 在骨干网络输出的多尺度特征图中,假定任一单张特征图$ {\boldsymbol{X}} \in {{\bf{R}}^{C{{ \times }}H{{ \times }}W}} $ C 为通道数,H ×W 为分辨率,对应的特征序列为${\boldsymbol{x}} \in {{\bf{R}}^{\left( {H{{ \times }}W} \right){{ \times }}{\mathrm{dim}}}}$ $ {\boldsymbol{q}} \in {{\bf{R}}^{1 \times {\mathrm{dim}}}} $ $ {\boldsymbol{p}} \in {\left[ {0,1} \right]^2} $ . 可变形注意力机制的每个注意力头均在参考点周围采集$S$ $S$ $S = 4$ . 查询元素q $ \Delta {{\boldsymbol{p}}_{m,s}} $ m 为该注意力的头号索引,同时q ${{\boldsymbol{A}}_{m,s}}$ . 将注意力权重和采样点特征进行点乘求和,经过线性变化得到该注意力特征,表达式为 ...
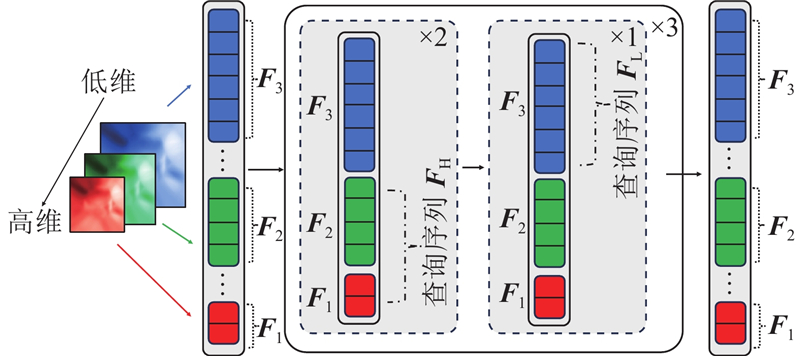
... 多尺度特征是指图像在模型中经过特征提取表示在不同尺度下的信息. 引入多尺度特征可以充分利用手部图像的空间局部信息及全局语义信息,使得模型回归的手部网格顶点坐标更为准确. 本研究所提方法为了更好地融入多尺度特征和简化模型,设计并应用了交错更新多尺度特征编码器. 在常规的多尺度特征编码器中,如文献[16 ],会同时更新高维图像特征和低维图像特征,这种方式的缺点是将低维图像特征和高维图像特征进行无差别处理. 低维特征包含的语义信息并不丰富,但包含的局部细节较多,对低维特征进行更新需要大量参数,耗费计算资源. 相对而言,高维特征包含的全局语义信息更丰富,但缺少空间局部细节. 因此,通过交错更新高维特征和低维特征的方式来设计编码器相对更为合理,可以实现效率和精度的平衡,具体流程如图3 所示. 图中,$ {\boldsymbol{F}} \in {{\bf{R}}^{{\text{(}}{N_{\mathrm{L}}}{\text{+}}{N_{\mathrm{H}}}{\text{)}} \times {\mathrm{dim}}}} $ ${N_{\mathrm{L}}}$ ${N_{\mathrm{H}}}$ $ {{\boldsymbol{F}}_1} $ ${{\boldsymbol{F}}_2}$ ${{\boldsymbol{F}}_3}$ . 编码器交错更新多尺度特征是以编码器块为单位,即整个编码器由3个完全相同的编码器块顺序堆叠组成,每个编码器块内部包含3个编码器层,其中前2层编码器层为高维特征编码层,负责更新高维特征,第三个编码器层为低维特征编码层,负责更新低维特征. 在每个编码器层更新特征前,须将多尺度特征划分为低维特征和高维特征: ...
1
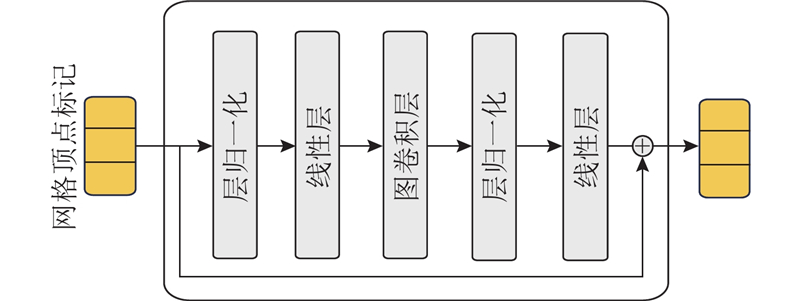
... 引入图卷积残差模块可以在模型内显式编码图结构,提高特征的空间局部性,有效捕获网格顶点间的本地依赖关系. 本研究所提方法调整了Mesh Graphomer[17 ] 中的图卷积残差模块,采用的图卷积残差模块主要包含依次顺序连接的线性层、图卷积层、线性层,输入输出进行残差连接,具体结构如图4 所示. 图卷积残差模块的计算对象为网格顶点标记序列,对于网格顶点标记序列${\boldsymbol{V}} \in {{\bf{R}}^{{N^{{\text{rou}}}} \times {\mathrm{dim}}}}$ ${N^{{\text{rou}}}}$
1
... 本研究所提方法主要使用FreiHAND[18 ] 作为训练和评估对象. FreiHAND是三维手部姿态数据集,采集了32位受试者的手部动作,每张手部图像都提供了基于MANO手部参数化模型的三维手部姿势注释. 该数据集包含32 560个训练样本和3 960个评估样本. 训练集使用3种后处理策略进行数据扩充,测试集不使用后处理策略进行数据扩充,因此该数据集总计包括130 240张训练集图像和3 960张测试集图像. ...
1
... 为了验证模型的泛化性,将HO3D V2[19 ] 作为辅助的训练和评估数据集. HO3D V2是手物交互3D手部姿态估计数据集,包含66 034个训练样本和11 524个测试样本,提供了MANO手部参数化模型注释. 相较于FreiHAND,HO3D V2的图像均有手物交互动作,不利于姿态估计. HO3D V2中的评估样本注释尚未公开,对该数据集的评估要将模型预测结果上传至CodaLab挑战官网中进行线上评估. ...
1
... HO3D V3[20 ] 比HO3D V2的规模大,手物接触更多,数据标注方法更先进. HO3D V3包含83 325个训练样本和20 137个测试样本. ...
Generalized procrustes analysis
1
1975
... PA-MPJPE是通用的、评估三维人体姿态估计和三维手部姿态估计方法准确性的指标. 该指标基于普鲁克分析[21 ] ,先对预测标注进行刚性变换以对齐真实标注,再计算平均每个关节位置的误差,用于评估关节点预测的准确性. PA-MPVPE计算原理与PA-MPJPE相同,不同的是该指标计算的是每个网格顶点间的误差,用于评估网格顶点预测的准确性. F-Score表示2个网格之间在特定误差阈值内的召回率和准确率之间的调和平均值,F@5表示该调和平均值的误差阈值为5 mm,F@15表示该调和平均值的误差阈值为15 mm. ...
1
... Performance comparison of different 3D hand pose estimation methods in FreiHAND dataset
Tab.1 方法 PA-MPJPE/mm PA-MPVPE/mm F@5 F@15 MobileHand[22 ] — 13.1 0.439 0.902 FreiHAND[7 ] 11.0 10.9 0.516 0.934 Pose2Mesh[23 ] 7.8 7.7 0.674 0.969 I2L-MeshNet[24 ] 7.4 7.6 0.681 0.973 CMR[15 ] 6.9 7.0 0.715 0.977 I2UV-HandNet[25 ] 6.7 6.9 0.707 0.977 METRO[4 ] 6.3 6.5 0.731 0.984 RealisticHands[26 ] — 7.8 0.662 0.971 FastMETRO[5 ] 6.5 7.2 0.688 0.983 PA-Tran[27 ] 6.0 6.3 — — FastViT-MA36[28 ] 6.6 6.7 0.722 0.981 本研究(ResNet) 6.4 6.7 0.714 0.982 本研究(HRNet) 5.8 6.2 0.749 0.986
如图5 所示为本研究所提方法预测得到的6组手部网格(各分图的右侧图)和真实手部网格(各分图的居中图)结果对比,原始图像(各分图的左侧图)来自FreiHAND. 在挑选的6组手部图像示例中,一部分没有任何遮挡,一部分存在手部自遮挡,还有一部分被不相关的物体遮挡. 如图5 (a)所示,虽然图像中手部被物体遮挡,缺少了部分手部信息,但是恢复出的三维手部网格仍较为准确. 总体来看,所提方法可以在一定程度上处理物体对手部的遮挡,具有较好的鲁棒性. ...
2
... Performance comparison of different 3D hand pose estimation methods in FreiHAND dataset
Tab.1 方法 PA-MPJPE/mm PA-MPVPE/mm F@5 F@15 MobileHand[22 ] — 13.1 0.439 0.902 FreiHAND[7 ] 11.0 10.9 0.516 0.934 Pose2Mesh[23 ] 7.8 7.7 0.674 0.969 I2L-MeshNet[24 ] 7.4 7.6 0.681 0.973 CMR[15 ] 6.9 7.0 0.715 0.977 I2UV-HandNet[25 ] 6.7 6.9 0.707 0.977 METRO[4 ] 6.3 6.5 0.731 0.984 RealisticHands[26 ] — 7.8 0.662 0.971 FastMETRO[5 ] 6.5 7.2 0.688 0.983 PA-Tran[27 ] 6.0 6.3 — — FastViT-MA36[28 ] 6.6 6.7 0.722 0.981 本研究(ResNet) 6.4 6.7 0.714 0.982 本研究(HRNet) 5.8 6.2 0.749 0.986
如图5 所示为本研究所提方法预测得到的6组手部网格(各分图的右侧图)和真实手部网格(各分图的居中图)结果对比,原始图像(各分图的左侧图)来自FreiHAND. 在挑选的6组手部图像示例中,一部分没有任何遮挡,一部分存在手部自遮挡,还有一部分被不相关的物体遮挡. 如图5 (a)所示,虽然图像中手部被物体遮挡,缺少了部分手部信息,但是恢复出的三维手部网格仍较为准确. 总体来看,所提方法可以在一定程度上处理物体对手部的遮挡,具有较好的鲁棒性. ...
... Performance comparison of different 3D hand pose estimation methods in HO3D V2 dataset
Tab.3 方法 PA- PA- F@5 F@15 Pose2Mesh[23 ] 12.5 12.7 0.441 0.909 METRO[4 ] 10.4 11.1 0.484 0.946 ArtiBoost[29 ] 11.4 10.9 0.488 0.944 Keypoint Transformer[30 ] 10.8 — — — 本研究(HRNet) 10.0 10.0 0.512 0.951
表 4 不同三维手部姿态估计方法在HO3D V3数据集上的性能对比 ...
1
... Performance comparison of different 3D hand pose estimation methods in FreiHAND dataset
Tab.1 方法 PA-MPJPE/mm PA-MPVPE/mm F@5 F@15 MobileHand[22 ] — 13.1 0.439 0.902 FreiHAND[7 ] 11.0 10.9 0.516 0.934 Pose2Mesh[23 ] 7.8 7.7 0.674 0.969 I2L-MeshNet[24 ] 7.4 7.6 0.681 0.973 CMR[15 ] 6.9 7.0 0.715 0.977 I2UV-HandNet[25 ] 6.7 6.9 0.707 0.977 METRO[4 ] 6.3 6.5 0.731 0.984 RealisticHands[26 ] — 7.8 0.662 0.971 FastMETRO[5 ] 6.5 7.2 0.688 0.983 PA-Tran[27 ] 6.0 6.3 — — FastViT-MA36[28 ] 6.6 6.7 0.722 0.981 本研究(ResNet) 6.4 6.7 0.714 0.982 本研究(HRNet) 5.8 6.2 0.749 0.986
如图5 所示为本研究所提方法预测得到的6组手部网格(各分图的右侧图)和真实手部网格(各分图的居中图)结果对比,原始图像(各分图的左侧图)来自FreiHAND. 在挑选的6组手部图像示例中,一部分没有任何遮挡,一部分存在手部自遮挡,还有一部分被不相关的物体遮挡. 如图5 (a)所示,虽然图像中手部被物体遮挡,缺少了部分手部信息,但是恢复出的三维手部网格仍较为准确. 总体来看,所提方法可以在一定程度上处理物体对手部的遮挡,具有较好的鲁棒性. ...
1
... Performance comparison of different 3D hand pose estimation methods in FreiHAND dataset
Tab.1 方法 PA-MPJPE/mm PA-MPVPE/mm F@5 F@15 MobileHand[22 ] — 13.1 0.439 0.902 FreiHAND[7 ] 11.0 10.9 0.516 0.934 Pose2Mesh[23 ] 7.8 7.7 0.674 0.969 I2L-MeshNet[24 ] 7.4 7.6 0.681 0.973 CMR[15 ] 6.9 7.0 0.715 0.977 I2UV-HandNet[25 ] 6.7 6.9 0.707 0.977 METRO[4 ] 6.3 6.5 0.731 0.984 RealisticHands[26 ] — 7.8 0.662 0.971 FastMETRO[5 ] 6.5 7.2 0.688 0.983 PA-Tran[27 ] 6.0 6.3 — — FastViT-MA36[28 ] 6.6 6.7 0.722 0.981 本研究(ResNet) 6.4 6.7 0.714 0.982 本研究(HRNet) 5.8 6.2 0.749 0.986
如图5 所示为本研究所提方法预测得到的6组手部网格(各分图的右侧图)和真实手部网格(各分图的居中图)结果对比,原始图像(各分图的左侧图)来自FreiHAND. 在挑选的6组手部图像示例中,一部分没有任何遮挡,一部分存在手部自遮挡,还有一部分被不相关的物体遮挡. 如图5 (a)所示,虽然图像中手部被物体遮挡,缺少了部分手部信息,但是恢复出的三维手部网格仍较为准确. 总体来看,所提方法可以在一定程度上处理物体对手部的遮挡,具有较好的鲁棒性. ...
1
... Performance comparison of different 3D hand pose estimation methods in FreiHAND dataset
Tab.1 方法 PA-MPJPE/mm PA-MPVPE/mm F@5 F@15 MobileHand[22 ] — 13.1 0.439 0.902 FreiHAND[7 ] 11.0 10.9 0.516 0.934 Pose2Mesh[23 ] 7.8 7.7 0.674 0.969 I2L-MeshNet[24 ] 7.4 7.6 0.681 0.973 CMR[15 ] 6.9 7.0 0.715 0.977 I2UV-HandNet[25 ] 6.7 6.9 0.707 0.977 METRO[4 ] 6.3 6.5 0.731 0.984 RealisticHands[26 ] — 7.8 0.662 0.971 FastMETRO[5 ] 6.5 7.2 0.688 0.983 PA-Tran[27 ] 6.0 6.3 — — FastViT-MA36[28 ] 6.6 6.7 0.722 0.981 本研究(ResNet) 6.4 6.7 0.714 0.982 本研究(HRNet) 5.8 6.2 0.749 0.986
如图5 所示为本研究所提方法预测得到的6组手部网格(各分图的右侧图)和真实手部网格(各分图的居中图)结果对比,原始图像(各分图的左侧图)来自FreiHAND. 在挑选的6组手部图像示例中,一部分没有任何遮挡,一部分存在手部自遮挡,还有一部分被不相关的物体遮挡. 如图5 (a)所示,虽然图像中手部被物体遮挡,缺少了部分手部信息,但是恢复出的三维手部网格仍较为准确. 总体来看,所提方法可以在一定程度上处理物体对手部的遮挡,具有较好的鲁棒性. ...
PA-Tran: learning to estimate 3D hand pose with partial annotation
1
2023
... Performance comparison of different 3D hand pose estimation methods in FreiHAND dataset
Tab.1 方法 PA-MPJPE/mm PA-MPVPE/mm F@5 F@15 MobileHand[22 ] — 13.1 0.439 0.902 FreiHAND[7 ] 11.0 10.9 0.516 0.934 Pose2Mesh[23 ] 7.8 7.7 0.674 0.969 I2L-MeshNet[24 ] 7.4 7.6 0.681 0.973 CMR[15 ] 6.9 7.0 0.715 0.977 I2UV-HandNet[25 ] 6.7 6.9 0.707 0.977 METRO[4 ] 6.3 6.5 0.731 0.984 RealisticHands[26 ] — 7.8 0.662 0.971 FastMETRO[5 ] 6.5 7.2 0.688 0.983 PA-Tran[27 ] 6.0 6.3 — — FastViT-MA36[28 ] 6.6 6.7 0.722 0.981 本研究(ResNet) 6.4 6.7 0.714 0.982 本研究(HRNet) 5.8 6.2 0.749 0.986
如图5 所示为本研究所提方法预测得到的6组手部网格(各分图的右侧图)和真实手部网格(各分图的居中图)结果对比,原始图像(各分图的左侧图)来自FreiHAND. 在挑选的6组手部图像示例中,一部分没有任何遮挡,一部分存在手部自遮挡,还有一部分被不相关的物体遮挡. 如图5 (a)所示,虽然图像中手部被物体遮挡,缺少了部分手部信息,但是恢复出的三维手部网格仍较为准确. 总体来看,所提方法可以在一定程度上处理物体对手部的遮挡,具有较好的鲁棒性. ...
1
... Performance comparison of different 3D hand pose estimation methods in FreiHAND dataset
Tab.1 方法 PA-MPJPE/mm PA-MPVPE/mm F@5 F@15 MobileHand[22 ] — 13.1 0.439 0.902 FreiHAND[7 ] 11.0 10.9 0.516 0.934 Pose2Mesh[23 ] 7.8 7.7 0.674 0.969 I2L-MeshNet[24 ] 7.4 7.6 0.681 0.973 CMR[15 ] 6.9 7.0 0.715 0.977 I2UV-HandNet[25 ] 6.7 6.9 0.707 0.977 METRO[4 ] 6.3 6.5 0.731 0.984 RealisticHands[26 ] — 7.8 0.662 0.971 FastMETRO[5 ] 6.5 7.2 0.688 0.983 PA-Tran[27 ] 6.0 6.3 — — FastViT-MA36[28 ] 6.6 6.7 0.722 0.981 本研究(ResNet) 6.4 6.7 0.714 0.982 本研究(HRNet) 5.8 6.2 0.749 0.986
如图5 所示为本研究所提方法预测得到的6组手部网格(各分图的右侧图)和真实手部网格(各分图的居中图)结果对比,原始图像(各分图的左侧图)来自FreiHAND. 在挑选的6组手部图像示例中,一部分没有任何遮挡,一部分存在手部自遮挡,还有一部分被不相关的物体遮挡. 如图5 (a)所示,虽然图像中手部被物体遮挡,缺少了部分手部信息,但是恢复出的三维手部网格仍较为准确. 总体来看,所提方法可以在一定程度上处理物体对手部的遮挡,具有较好的鲁棒性. ...
2
... Performance comparison of different 3D hand pose estimation methods in HO3D V2 dataset
Tab.3 方法 PA- PA- F@5 F@15 Pose2Mesh[23 ] 12.5 12.7 0.441 0.909 METRO[4 ] 10.4 11.1 0.484 0.946 ArtiBoost[29 ] 11.4 10.9 0.488 0.944 Keypoint Transformer[30 ] 10.8 — — — 本研究(HRNet) 10.0 10.0 0.512 0.951
表 4 不同三维手部姿态估计方法在HO3D V3数据集上的性能对比 ...
... Performance comparison of different 3D hand pose estimation methods in HO3D V3 dataset
Tab.4 方法 PA- PA- F@5 F@15 ArtiBoost[29 ] 10.8 10.4 0.507 0.946 Keypoint Transformer[30 ] 10.9 — — — HandOccNet[31 ] 10.7 10.4 0.479 0.935 本研究(HRNet) 10.5 10.3 0.491 0.941
3.5. 消融实验 以ResNet-50为骨干网络在FreiHAND数据集上对本研究所提方法进行消融实验,实验结果如表5 所示. 将所提方法作为基线模型,分别消融交错更新多尺度特征编码器、可变形注意力机制、图卷积残差模块,进行模型的性能对比实验. 实验一模型含可变形注意力机制模块和图卷积残差模块;实验二模型仅含图卷积残差模块;实验三模型含交错更新多尺度特征编码器模块和可变形注意力机制模块. 当消融交错更新多尺度特征编码器而使用单尺度编码器块时,模型相较于基线模型失去了多尺度信息,仅靠来自单一尺度的较高维的图像特征,丧失了大量局部细节,导致模型的PA-MPJPE从6.4 mm下降到了8.2 mm. 进行可变形注意力机制的消融实验时,单独消融可变形注意力机制而不消融交错更新多尺度特征编码器会导致模型参数量和计算量变得异常庞大而难以训练,因此在进行可变形注意力机制的消融实验时须一并消融交错更新多尺度特征编码器. 对比实验一和实验二发现,当仅利用单尺度图像特征时,传统注意力机制的性能好于可变形注意力机制. 对比实验二模型与基线模型发现,同时应用交错更新多尺度特征编码器和可变形注意力机制,模型性能有较大提升,PA-MPJPE从7.0 mm提高到6.4 mm. 可以看出,同时利用多尺度特征和可变形注意力机制,相较于在单尺度特征下利用传统注意力机制,模型性能有显著提升;在单尺度特征下利用可变形注意力机制,性能有所下降. 实验三单独消融图卷积残差模块,对比实验三模型和基线模型发现,实验三的PA-MPJPE从6.4 mm下降至6.8 mm,表明应用图卷积残差模块来挖掘网格顶点间显式的语义联系可以使模型的性能得到可观的提升. ...
2
... Performance comparison of different 3D hand pose estimation methods in HO3D V2 dataset
Tab.3 方法 PA- PA- F@5 F@15 Pose2Mesh[23 ] 12.5 12.7 0.441 0.909 METRO[4 ] 10.4 11.1 0.484 0.946 ArtiBoost[29 ] 11.4 10.9 0.488 0.944 Keypoint Transformer[30 ] 10.8 — — — 本研究(HRNet) 10.0 10.0 0.512 0.951
表 4 不同三维手部姿态估计方法在HO3D V3数据集上的性能对比 ...
... Performance comparison of different 3D hand pose estimation methods in HO3D V3 dataset
Tab.4 方法 PA- PA- F@5 F@15 ArtiBoost[29 ] 10.8 10.4 0.507 0.946 Keypoint Transformer[30 ] 10.9 — — — HandOccNet[31 ] 10.7 10.4 0.479 0.935 本研究(HRNet) 10.5 10.3 0.491 0.941
3.5. 消融实验 以ResNet-50为骨干网络在FreiHAND数据集上对本研究所提方法进行消融实验,实验结果如表5 所示. 将所提方法作为基线模型,分别消融交错更新多尺度特征编码器、可变形注意力机制、图卷积残差模块,进行模型的性能对比实验. 实验一模型含可变形注意力机制模块和图卷积残差模块;实验二模型仅含图卷积残差模块;实验三模型含交错更新多尺度特征编码器模块和可变形注意力机制模块. 当消融交错更新多尺度特征编码器而使用单尺度编码器块时,模型相较于基线模型失去了多尺度信息,仅靠来自单一尺度的较高维的图像特征,丧失了大量局部细节,导致模型的PA-MPJPE从6.4 mm下降到了8.2 mm. 进行可变形注意力机制的消融实验时,单独消融可变形注意力机制而不消融交错更新多尺度特征编码器会导致模型参数量和计算量变得异常庞大而难以训练,因此在进行可变形注意力机制的消融实验时须一并消融交错更新多尺度特征编码器. 对比实验一和实验二发现,当仅利用单尺度图像特征时,传统注意力机制的性能好于可变形注意力机制. 对比实验二模型与基线模型发现,同时应用交错更新多尺度特征编码器和可变形注意力机制,模型性能有较大提升,PA-MPJPE从7.0 mm提高到6.4 mm. 可以看出,同时利用多尺度特征和可变形注意力机制,相较于在单尺度特征下利用传统注意力机制,模型性能有显著提升;在单尺度特征下利用可变形注意力机制,性能有所下降. 实验三单独消融图卷积残差模块,对比实验三模型和基线模型发现,实验三的PA-MPJPE从6.4 mm下降至6.8 mm,表明应用图卷积残差模块来挖掘网格顶点间显式的语义联系可以使模型的性能得到可观的提升. ...
1
... Performance comparison of different 3D hand pose estimation methods in HO3D V3 dataset
Tab.4 方法 PA- PA- F@5 F@15 ArtiBoost[29 ] 10.8 10.4 0.507 0.946 Keypoint Transformer[30 ] 10.9 — — — HandOccNet[31 ] 10.7 10.4 0.479 0.935 本研究(HRNet) 10.5 10.3 0.491 0.941
3.5. 消融实验 以ResNet-50为骨干网络在FreiHAND数据集上对本研究所提方法进行消融实验,实验结果如表5 所示. 将所提方法作为基线模型,分别消融交错更新多尺度特征编码器、可变形注意力机制、图卷积残差模块,进行模型的性能对比实验. 实验一模型含可变形注意力机制模块和图卷积残差模块;实验二模型仅含图卷积残差模块;实验三模型含交错更新多尺度特征编码器模块和可变形注意力机制模块. 当消融交错更新多尺度特征编码器而使用单尺度编码器块时,模型相较于基线模型失去了多尺度信息,仅靠来自单一尺度的较高维的图像特征,丧失了大量局部细节,导致模型的PA-MPJPE从6.4 mm下降到了8.2 mm. 进行可变形注意力机制的消融实验时,单独消融可变形注意力机制而不消融交错更新多尺度特征编码器会导致模型参数量和计算量变得异常庞大而难以训练,因此在进行可变形注意力机制的消融实验时须一并消融交错更新多尺度特征编码器. 对比实验一和实验二发现,当仅利用单尺度图像特征时,传统注意力机制的性能好于可变形注意力机制. 对比实验二模型与基线模型发现,同时应用交错更新多尺度特征编码器和可变形注意力机制,模型性能有较大提升,PA-MPJPE从7.0 mm提高到6.4 mm. 可以看出,同时利用多尺度特征和可变形注意力机制,相较于在单尺度特征下利用传统注意力机制,模型性能有显著提升;在单尺度特征下利用可变形注意力机制,性能有所下降. 实验三单独消融图卷积残差模块,对比实验三模型和基线模型发现,实验三的PA-MPJPE从6.4 mm下降至6.8 mm,表明应用图卷积残差模块来挖掘网格顶点间显式的语义联系可以使模型的性能得到可观的提升. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}