

经典的CNN感受野较小,缺乏对全局上下文信息或长距离依赖关系的恢复建模能力. 新的卷积神经网络Segnext采用CNN融合Transformer的前馈网络结构优点,同时利用多尺度卷积捕获多尺度信息,获得长范围提取特征能力,克服传统CNN网络仅能提取局部特征的缺点[8].
在语义分割任务中,采用局部信息恢复重建的分割图会出现像素类别分类不精确的问题. 在全局信息的指导下,像素的语义分类更加精确. UnetFormer[9]网络中全局局部注意力的全局分支存在窗口机制,割裂了空间信息. 借助多尺度卷积注意力机制,解决全局分支中存在割裂的全局空间信息的问题.
融合浅层和深层的上下文信息,能够更好地恢复重建分割图. 在末端分割中,浅层信息因编码器连续下采样而损失高分辨率信息,这些信息与深层语义权重相加,会导致较低的分割精度. 本文的主要贡献如下.
(1) 本文引入多尺度卷积注意力(multi-scale convolutional attention,MSCA)和前馈网络结构的多尺度卷积注意力骨干网络(multi scale convolutional attention backbone network, MSCAN)到遥感语义分割领域. MSCAN提取多层级多尺度的高分辨率遥感图像的全局信息.
(2)设计全局多分支局部Transformer模块(global multi-branch local transformer block,GMBLTB). 多尺度逐通道条带状卷积(depth-wisestrip convolution, DWS)恢复重建多尺度空间的上下文信息,GMBLTB重建全局上下文信息.
(3)网络末端输出区域设计极化特征精炼头(polarization feature refining head, PFRH). PFRH能够融合浅层修复后的高分辨率信息和深层全局上下文信息,高质量实现逐像素分类. 源代码地址为
1. 相关研究工作
本文设计的GMBLTB模块,通过重建不同尺度的空间信息,修复窗口机制存在的空间信息割裂.
2. 方法简介
提出多尺度注意力提取与全局信息重建Transformer网络(multi-scale attention extraction and global information reconstruction transformer, MAGIFormer),结构如图1所示.
图 1
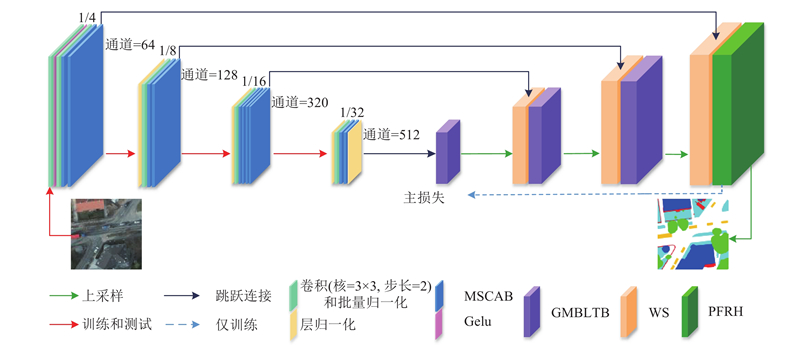
图 1 多尺度注意力提取与全局信息重建Transformer的整体网络架构图
Fig.1 Overall network architecture diagram of Transformer for multi-scale attention extraction and global information reconstruction
编码结构引入MSCAN小型结构. 它由卷积下采样层、层归一化(layer norm, LN)和多尺度卷积注意力模块(multi-scale convolutional attention module,MSCAB)构成. 其中卷积下采样层包含核大小为3×3、步长为2的卷积和批量规范化(batch normalization, BN). MSCAN小型结构包含4个阶段:第1、2和4阶段采用2个MSCAB,第3阶段采用4个MSCAB. 第1阶段进行4倍下采样和输出64通道特征图,图像经过卷积下采样层,获得的特征图经过高斯误差线性单元激活函数(Gaussian error linear unit, Gelu)得到激活图. 激活图再经过卷积下采样层,输入到2个MSCAB. 第2、3阶段都进行2倍下采样,分别获得128通道特征图和320通道特征图,都经过层批量化和卷积下采样层,其中第2阶段经过2个MSCAB,第3阶段经过4个MSCAB. 第4阶段进行2倍下采样,获得512通道特征图. 将第4阶段的特征图经过层批量化和卷积下采样层,再送入2个MSCAB和1个层批量化,获得特征图.
解码结构包含3个权重相加块(weight addition, WS)、3个GMBLTB和1个PFRH.
2.1. 多尺度卷积注意力模块
传统CNN骨干网络仅能提取局部特征,本文引入多尺度卷积注意力骨干到深度学习遥感语义分割,编码器提取的全局信息有利于解码器恢复重建分割图. 如图2所示,MSCAB是由多尺度注意力块和前馈网络构成,每个多尺度注意力块是由1个MSCA、2个卷积和1个Gelu组成. 图中,K为卷积核大小.
图 2
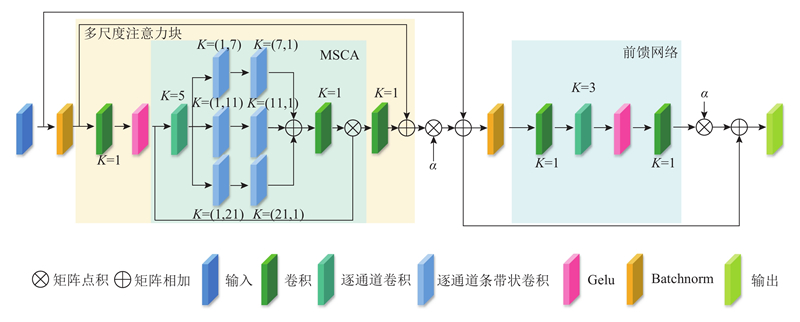
图 2 多尺度卷积注意力模块的网络架构图
Fig.2 Network architecture diagram of multi scale convolutional attention module
式中:
多尺度注意力块
式中:
式中:
前馈网络
FFP能够在多尺度上下文信息中提取更丰富的语义信息.
整个
2.2. 全局多分支局部Transformer块
解码器在恢复重建过程中,将来自编码器的特征图进行全局上下文信息恢复重建,是实现高精准分割图的重要一环. 在UnetFormer提供的全局局部注意力块中,全局分支能够提供全面的语义上下文信息,但是基于窗口机制的自注意力机制会割裂空间信息,使用简单的小核卷积仅能提供局部空间信息. 越接近浅层,详细的全局空间信息有利于解码器末端实现高精准的分割. 本文对局部分支进行改进,利用多分支DWS捕获多尺度上下文空间信息,采用1×1的卷积构建通道之间的依赖,与来自深层的信息进行点积运算,重建多尺度空间上下文,构建多分支局部分支. 将多分支局部分支与全局分支的权重进行相加,重建多尺度的全局信息,整体结构如图3所示.
图 3
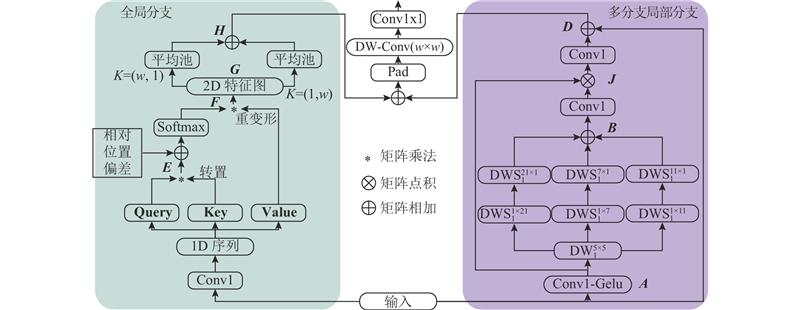
图 3 全局多分支局部Transformer模块的整体网络架构图
Fig.3 Overall network architecture diagram of global multi branch local Transformer block
多分支局部分支将权重相加模块输出的混合特征图
全局分支将混合特征图
将全局分支H含有的全局上下文语义信息与多分支局部分支D含有的多尺度空间上下文信息进行权重相加,采用核为w的DW,在1×1的卷积构建通道依赖,后续逐层恢复重建分割图.
2.3. 极化特征精炼头
来自编码器浅层的特征图富含繁杂的空间信息. 这些空间信息因连续下采样或池化失去潜在的高分辨率信息,缺少语义信息. 从解码器恢复重建的深层分割图,富含语义信息,但是缺少详细的空间细节. 将两者的权重直接加和,不利于提升浅层纹理细节的分割精度. 设计的PFRH由WS、通道自注意力和混合权重3部分构成. WS模块实现深浅层信息权重的相加. 通道自注意力中依靠softmax和sigmoid组合在通道维度上高度拟合非线性变换,利用这种拟合获得更好的输出分布,恢复浅层潜在的高分辨率信息损失. 混合权重将WS特征图通过残差与通道自注意力进行权重相加,得到具有精细的空间纹理,完成最终的分割,整体结构如图4所示.
图 4
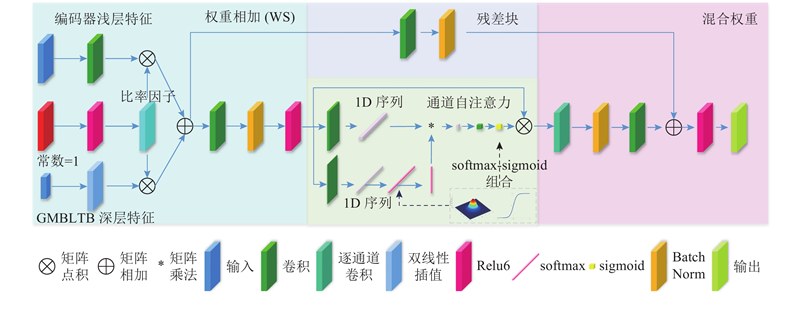
图 4 极化特征精炼头的整体网络架构图
Fig.4 Overall network architecture diagram of polarization feature refining head
式中:
式中:
通道自注意力通过softmax和sigmoid组合在通道上构建概率分布函数,近似拟合二维高斯分布或二维二项分布函数,恢复浅层潜在的高分辨率信息;
2.4. 损失函数
切块损失对正、负样本严重不平衡的场景有着不错的性能,在训练过程中更侧重对前景区域的挖掘. 在训练损失容易不稳定,尤其是小目标的情况下,极端情况会导致梯度饱和现象,切块损失需要结合二叉熵损失. 本文的损失
式中:N为样本数量,K为类别数量,
3. 实验结果与分析
3.1. 数据集
ISPRS Potsdam:该数据集是在一个典型的历史城市进行航空摄影. 它有着巨大的建筑群、间隙较小的街道、密集的车辆,复杂的道路与植被交互. 数据集类别共有6种,分别为不可渗透表面、建筑物、低矮植被、树木、汽车和杂物. 该数据集共包含38张图像,图像大小为6 000×6 000像素,在地面每隔5 cm进行采样. 在本文试验中,ID为2_13、2_14、3_13、3_14、4_13、4_14、4_15、5_13、5_14、5_15、6_13、6_14、6_15和7_13的图像用于测试集,除了7_10错误标记被舍弃外,余下的23张图片被用于训练. 所有图像被裁剪为1 024×1 024像素.
ISPRS Vaihingen:该数据集共包含33张图像,图像的大小为2 000~4 000像素,在地面每隔9 cm进行采样,拥有较多的小建筑物且建筑物比较独立. Vaihingen数据集有6个图像类别. 在本文实验中,使用三通道图像(红、绿、蓝),ID为2、4、6、8、10、12、14、16、20、22、24、27、29、31、33、35和38的图像用于测试集,剩余的16张场景图像用于训练集. ISPRS Potsdam和ISPRS Vaihingen数据集的制作方法遵循文献[8]中的标准. 全部图像被裁剪为1 024×1 024像素.
3.2. 工具细节
系统Ubuntu 版本号为9.4.0,所有的模型使用PyTorch框架,在单个显存大小为24 GB 的Tesla P40上进行训练. CPU为I5-9400F,内存大小为32 GB,固态硬盘大小为512 GB,虚拟内存设置为256 GB.
为了更好地快速收敛,使用AdamW优化器训练所有模型,所有模型的骨干网络均使用对ImageNet-22K数据集进行预训练的权重. 学习率设为6×10−4,权重衰减为0.01,骨干网络学习率为6×10−5,骨干网络权重衰减为0.01,学习率的调度策略是余弦退火重启算法,受2个参数的影响,T_0表示最开始周期的迭代轮数,T_mult为下一个周期与上一个周期迭代轮数的比值. T_0 = 15,T_mult = 2. 经过多次基准实验,在225轮达到原始精度.
对于Potsdam、Vaihingen数据集,在整个训练过程中,训练集图像大小为1 024×1 024像素,先使用数据增强技术如随机尺度(0.5,0.75,1.0,1.25,1.5),在每一张图片中随机裁剪出512×512像素的图像. 之后,每一张图片使用数据增强技术,如随机水平翻转、随机垂直翻转和随机旋转,这些增强技术在整个训练过程中被使用. 将训练批量数设置为16,被随机裁剪出512×512像素的图像,最终输入模型. 在整个验证过程中,使用全部1 024×1 024像素的训练集作为验证集,不使用任何数据增强,将测试批量数设为16. 在整个测试阶段,多尺度和随机翻转增强方法在测试集上被使用. 2个数据集上的训练及验证遵循UnetFormer文献,完成实验过程.
3.3. 评价指标和对比网络
使用整体精确度(overall accuracy, OA)、F1分数(F1 score, F1)、平均F1分数F1mean(mean F1 score)、平均交并比(mean intersection over union, mIoU)、查准率P、召回率R作为评价指标.
式中:
为了评价整个网络的性能,引入浮点运算次数Nf参数来评估网络的计算量, 引入内存占用C参数来评价显存占据大小,引入模型参数量Np(model parameters)来评估网络模型总参数.
3.4. 消融研究
表 1 GMSLTransFormer每个组件的消融研究
Tab.1
| 数据集 | 方法 | OA/% | F1mean/% | mIoU/% |
Vaihingen | Baseline | 89.32 | 89.30 | 80.87 |
| Baseline+MSCAN | 89.76 | 89.46 | 81.12 | |
| Baseline+MSCAN+GMSLTB | 90.73 | 90.31 | 82.74 | |
| Baseline+ MSCAN+GMSLTB+PFRH | 90.88 | 90.54 | 82.94 |
图 5
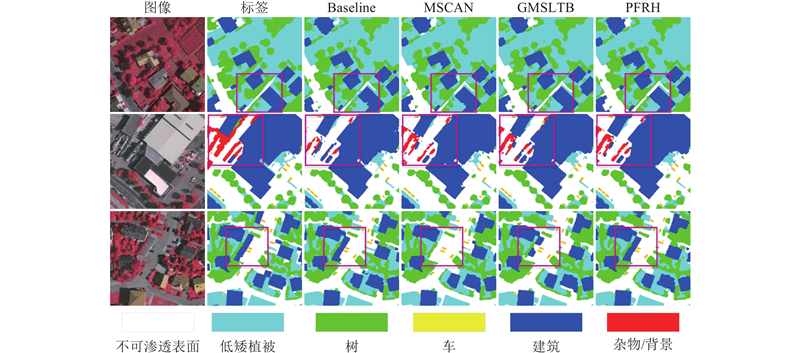
图 5 在Vaihingen数据集上的模型消融实验可视化结果对比
Fig.5 Comparison of visualization results of model ablation experiments on Vaihingen dataset
Baseline:采用Resnet骨干的类Unet网络. 本文模型基于Unet架构,使用卷积神经网络更强的Resnet18骨干,加载Resnet18骨干网络的ImageNet预训练权重. 引入WS模块,如图4所示. 在解码器网络末端加入4倍上采样率的分割头,以此作为基准.
Baseline+MSCAN:Baseline加入多尺度卷积注意力骨干. 在基准网络上,将Resnet18骨干替换为MSCAN-tiny骨干. 在Vaihingen数据集上,OA提升了0.44%,mIoU提升了0.25%, F1mean提升了0.16%. 对于基准网络而言,MSCAN骨干最大的特点是能够提取全局信息. 对比Baseline和Baseline+MSCAN,如图5的第2行所示. 全局信息能够帮助建立更远距离的像素理解,如背景部分识别,但在局部会出现理解不够的问题;在第3行,单个建筑物消失.
Baseline+MSCAN+GMSLTB:在Baseline与 MSCAN上加入全局多分支局部Transformer块. 在Vaihingen数据集上F1mean提升了0.85%, mIoU提升了1.62%,OA提升了0.97%. 如图5的第1、3行所示,分别修正了不可渗透表面和过度全局信息理解而消失的建筑物,说明GMSLTB在逐步恢复重建的过程中,能够将MSCAN过度联系的全局像素,修正和增强到正确的类别理解.
Baseline+ MSCAN+GMSLTB+PFRH:在Baseline+MSCAN+GMSLTB上加入极化特征精炼头. 在Vaihingen数据集上,mIoU提升了0.20%,PFRH能够修复浅层潜在的高分辨率信息损失,完成对语义和空间信息的精炼. 如图5的第2、3行所示,分别纠正了背景类别的错误识别和建筑物的类别缺失,提升了分割效果.
3.5. ISPRS Potsdam数据集上的参数对比
如表2所示为MAGIFormer模型对内存、参数和计算复杂度的评估,复杂度测量用
表 2 在Potsdam测试集与先进的遥感语义分割网络结果进行对比
Tab.2
| 方法 | 骨干 | C/MB | Np/106 | Nf/109 | F1mean/% | OA/% | mIoU/% |
| DANet(2019) | Resnet18 | 12.6 | 120.24 | 90.7 | 90.2 | 83.1 | |
| BANet(2021) | ResTLi | 12.7 | 29.38 | 92.1 | 90.6 | 85.6 | |
| ABCNet(2021) | Resnet18 | 14.0 | 62.16 | 92.2 | 90.8 | 85.8 | |
| MANet(2021) | Resnet18 | 12.0 | 88.25 | 92.4 | 90.8 | 86.1 | |
| UnetFormer(2022) | Resnet18 | 11.7 | 11.67 | 92.7 | 91.1 | 86.6 | |
| MAResUNet(2022) | Resnet18 | 638.51 | 16.2 | 25.29 | 92.7 | 91.3 | 86.7 |
| DCswin(2022) | Swin-tiny | 45.6 | 89.30 | 92.9 | 91.3 | 86.9 | |
| MAGIFormer | MSCAN_tiny | 13.9 | 62.70 | 93.0 | 91.4 | 87.1 |
3.6. ISPRS Potsdam数据集上的类别对比
表 3 在Potsdam测试集上与先进的高精度网络的定量比较结果
Tab.3
| 方法 | 骨干 | F1/% | F1mean/% | OA/% | mIoU/% | ||||
| 不可渗透 | 建筑 | 低矮植被 | 树 | 车 | |||||
| DANet(2019) | Resnet18 | 92.3 | 96.0 | 86.6 | 88.4 | 90.3 | 90.7 | 90.2 | 83.1 |
| MAResUNet(2021) | Resnet18 | 93.3 | 96.8 | 87.9 | 89.0 | 96.6 | 92.7 | 91.3 | 86.7 |
| ABCNet(2021) | Resnet18 | 93.0 | 96.5 | 87.5 | 88.2 | 96.2 | 92.2 | 90.8 | 85.8 |
| BANet(2021) | ResT-Lite | 92.5 | 96.1 | 87.1 | 88.8 | 96.0 | 92.1 | 90.6 | 85.6 |
| MANet(2022) | Resnet18 | 92.9 | 96.1 | 87.5 | 88.8 | 96.6 | 92.4 | 90.9 | 86.1 |
| UnetFormer(2022) | Resnet18 | 93.1 | 96.5 | 87.8 | 89.2 | 96.7 | 92.7 | 91.1 | 86.6 |
| DCswin(2022) | Swin-tiny | 93.3 | 96.7 | 88.1 | 89.7 | 96.6 | 92.9 | 91.3 | 86.9 |
| MAGIFormer | MSCAN-tiny | 93.3 | 97.1 | 88.1 | 89.5 | 96.9 | 93.0 | 91.4 | 87.1 |
图 6
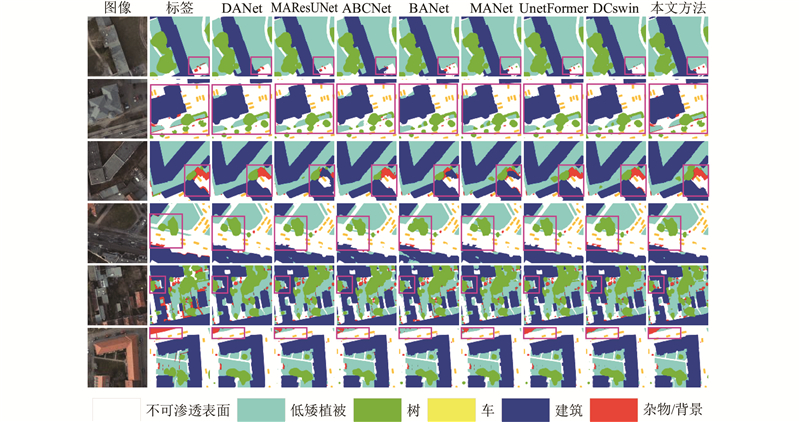
图 6 不同分割网络在ISPRS Potsdam数据集上的实验结果可视化对比
Fig.6 Visualization comparison of experimental result of different segmentation network on ISPRS Potsdam dataset
3.7. ISPRS Vaihingen数据集上的类别对
表 4 在Vaihingen测试集上与先进的高精度网络定量比较结果
Tab.4
| 方法 | 骨干 | F1/% | F1mean/% | OA/% | mIoU/% | |||||
| 不可渗透 | 建筑 | 植被 | 树 | 车 | 杂物 | |||||
| DANet(2019) | Resnet18 | 90.3 | 93.9 | 82.5 | 88.3 | 75.8 | 54.1 | 86.2 | 88.8 | 76.2 |
| ABCNet(2021) | Resnet18 | 90.6 | 93.0 | 81.5 | 89.6 | 84.2 | 38.1 | 87.8 | 88.7 | 78.5 |
| MANet(2022) | Resnet18 | 92.0 | 94.5 | 83.5 | 89.4 | 88.0 | 50.9 | 89.5 | 90.0 | 81.1 |
| BANet(2021) | ResT-Lite | 92.4 | 95.1 | 83.8 | 89.8 | 89.0 | 54.5 | 90.0 | 90.5 | 82.1 |
| MAResUNet(2021) | Resnet18 | 92.2 | 95.1 | 84.3 | 90.0 | 88.5 | 50.9 | 90.0 | 90.5 | 82.0 |
| UnetFormer(2022) | Resnet18 | 92.7 | 95.4 | 84.4 | 90.1 | 89.7 | 57.1 | 90.5 | 90.8 | 82.8 |
| DCswin(2022) | Swin-tiny | 92.5 | 95.5 | 84.7 | 90.2 | 88.8 | 44.9 | 90.4 | 90.8 | 82.6 |
| MAGIFormer | MSCAN-tiny | 92.7 | 95.3 | 84.7 | 90.3 | 89.8 | 53.7 | 90.6 | 90.9 | 82.9 |
图 7

图 7 不同分割网络在ISPRS Vaihingen数据集上的实验结果可视化对比
Fig.7 Visualization comparison of experimental result of different segmentation network on ISPRS Vaihingen dataset
4. 结 语
本文使用多尺度卷积注意力骨干网络,逐层捕获多尺度信息. 在每层中,这些多尺度信息包含局部、长范围和全局信息. 这些捕获的多层级、多尺度信息给解码器提供多层级、多尺度的浅层空间信息和深层语义信息. GMBLTB能够利用多尺度逐通道带状卷积,分别输出不同尺度的空间上下文信息,与全局语义上下文信息共同恢复重建全局信息分割图. 网络末端设计了PFRH,WS特征图汇聚深浅层不同的信息特征. softmax和sigmoid组合在通道上构建概率分布函数,拟合二维高斯分布或二维二项分布函数. 拟合函数具有高度非线性,拟合恢复浅层潜在复杂的高分辨率信息,融合和指导WS特征图,实现高质量的逐像素级回归. 实验结果表明,MAGIFormer能够提高遥感图像的分割精度,为遥感技术的工程化普及提供一定的参考.
参考文献
Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFS
[J].
UNetFormer: a UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery
[J].DOI:10.1016/j.isprsjprs.2022.06.008 [本文引用: 1]
ResUNet-a: a deep learning framework for semantic segmentation of remotely sensed data
[J].DOI:10.1016/j.isprsjprs.2020.01.013 [本文引用: 1]
Problems of encoder-decoder frameworks for high-resolution remote sensing image segmentation: Structural stereotype and insufficient learning
[J].DOI:10.1016/j.neucom.2018.11.051 [本文引用: 1]
遥感图像语义分割空间全局上下文信息网络
[J].
Remote sensing image semantic segmentation space global context information network
[J].
ABCNet: attentive bilateral contextual network for efficient semantic segmentation of fine-resolution remotely sensed imagery
[J].DOI:10.1016/j.isprsjprs.2021.09.005 [本文引用: 1]
Polarized self-attention: towards high-quality pixel-wise mapping
[J].DOI:10.1016/j.neucom.2022.07.054 [本文引用: 2]
Transformer meets convolution: a bilateral awareness network for semantic segmentation of very fine resolution urban scene images
[J].DOI:10.3390/rs13163065 [本文引用: 1]
Multiattention network for semantic segmentation of fine-resolution remote sensing images
[J].
Multistage attention ResU-Net for semantic segmentation of fine-resolution remote sensing images
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}