[1]
WANG Y, WAN R, YANG W, et al. Low-light image enhancement with normalizing flow [C]// Proceedings of the AAAI Conference on Artificial Intelligence . [S.l.]: AAAI, 2022: 2604-2612.
[本文引用: 1]
[2]
LV F, LI Y, LU F Attention guided low-light image enhancement with a large scale low-light simulation dataset
[J]. International Journal of Computer Vision , 2021 , 129 : 2175 - 2193
DOI:10.1007/s11263-021-01466-8
[本文引用: 2]
[3]
WANG L, LIU Z, SIU W, et al Lightening network for low-light image enhancement
[J]. IEEE Transactions on Image Processing , 2020 , 29 : 7984 - 7996
DOI:10.1109/TIP.2020.3008396
[本文引用: 1]
[4]
ZHOU S, LI C, LOY C C. LEDNet: joint low-light enhancement and deblurring in the dark [C]// Proceedings of the European Conference on Computer Vision . [S.l.]: Springer, 2022: 573-589.
[本文引用: 1]
[5]
ZHENG C, SHI D, SHI W. Adaptive unfolding total variation network for low-light image enhancement [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 4439-4448.
[本文引用: 1]
[6]
WU W, WENG J, ZHANG P, et al. URetinex-Net: retinex-based deep unfolding network for low-light image enhancement [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 5901-5910.
[本文引用: 2]
[7]
HAO S, HAN X, GUO Y, et al Low-light image enhancement with semi-decoupled decomposition
[J]. IEEE Transactions on Multimedia , 2020 , 22 (12 ): 3025 - 3038
DOI:10.1109/TMM.2020.2969790
[本文引用: 1]
[8]
GUO C, LI C, GUO J, et al. Zero-reference deep curve estimation for low-light image enhancement [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 1777–1786.
[本文引用: 1]
[9]
MA L, MA T, LIU R, et al. Toward fast, flexible, and robust low-light image enhancement [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 5627-5636.
[本文引用: 1]
[10]
ZHANG Z, ZHENG H, HONG R, et al. Deep color consistent network for low-light image enhancement [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 1889-1898.
[本文引用: 1]
[11]
WEI C, WANG W, YANG W, et al. Deep retinex decomposition for low-light enhancement [C]// Proceedings of the 29th British Machine Vision Conference . Newcastle Upon Tyne: [s.n.], 2018.
[本文引用: 5]
[12]
CHEN C, CHEN Q, XU J, et al. Learning to see in the dark [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 3291-3300.
[本文引用: 1]
[13]
PANG Y, NIE J, XIE J, et al. BidNet: binocular image dehazing without explicit disparity estimation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 5931-5940.
[本文引用: 1]
[14]
ZHOU S, ZHANG J, ZUO W, et al. DAVANet: stereo deblurring with view aggregation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 10996-11005.
[本文引用: 1]
[15]
ZHANG K, LUO W, REN W, et al. Beyond monocular deraining: stereo image deraining via semantic understanding [C]// Proceedings of the European Conference on Computer Vision . [S.l.]: Springer, 2020: 71-89.
[本文引用: 1]
[16]
HUANG J, FU X, XIAO Z, et al Low-light stereo image enhancement
[J]. IEEE Transactions on Multimedia , 2022 , 25 : 2978 - 2992
[本文引用: 4]
[17]
LI C, GUO C, LOY C C Learning to enhance low-light image via zero-reference deep curve estimation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 44 (8 ): 4225 - 4238
[本文引用: 6]
[18]
WANG L, WANG Y, LIANG Z, et al. Learning parallax attention for stereo image super-resolution [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 12250-12259.
[本文引用: 1]
[19]
MITTAL A, MOORTHY A K, BOVIK A C No-reference image quality assessment in the spatial domain
[J]. IEEE Transactions on Image Processing , 2012 , 21 (12 ): 4695 - 4708
DOI:10.1109/TIP.2012.2214050
[本文引用: 1]
[20]
MITTAL A, SOUNDARARAJAN R, BOVIK A C Making a “completely blind” image quality analyzer
[J]. IEEE Signal Processing Letters , 2012 , 20 (3 ): 209 - 212
[本文引用: 1]
[21]
VENKATANATH N, PRANEETH D, BH M C, et al. Blind image quality evaluation using perception based features [C]// Proceedings of the Twenty First National Conference on Communications . Mumbai: IEEE, 2015: 1-6.
[本文引用: 1]
[22]
WANG S, ZHENG J, HU H, et al Naturalness preserved enhancement algorithm for non-uniform illumination images
[J]. IEEE Transactions on Image Processing , 2013 , 22 (9 ): 3538 - 3548
DOI:10.1109/TIP.2013.2261309
[本文引用: 1]
[23]
ZHANG R, ISOLA P, EFROS A A, et al. The unreasonable effectiveness of deep features as a perceptual metric [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 586-595.
[本文引用: 2]
[24]
FAN M, WANG W, YANG W, et al. Integrating semantic segmentation and retinex model for low-light image enhancement [C]// Proceedings of the 28th ACM International Conference on Multimedia . [S.l.]: ACM, 2020: 2317-2325.
[本文引用: 4]
[25]
WANG W, WEI C, YANG W, et al. GLADNet: low-light enhancement network with global awareness [C]// Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition . Xi’an: IEEE, 2018: 751-755.
[本文引用: 4]
[26]
LIU R, MA L, ZHANG J, et al. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 10561-10570.
[本文引用: 3]
[27]
GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Providence: IEEE, 2012: 3354-3361.
[本文引用: 1]
[29]
SUN J, CHEN L, XIE Y, et al. Disp R-CNN: stereo 3D object detection via shape prior guided instance disparity estimation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10548-10557.
[本文引用: 1]
1
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
Attention guided low-light image enhancement with a large scale low-light simulation dataset
2
2021
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
... 进行目标检测实验,对比使用不同方法增强后的图像的目标检测效果. 本实验使用经过亮度暗化处理的低光照KITTI[27 ] 数据集,实现过程是将获取的原始KITTI数据集图像经过Gamma变换[28 ] ,通过调整亮度曲线使图像的亮度变低[2 ] . 这种方法可以模拟类似在低光照条件下获取到的双目低光照图像. 该实验主要考察光照不充分的车辆图像在使用不同方法进行图像增强后,是否可以标出目标车辆的三维检测框. 实验选用KITTI数据集的训练集图像,其中训练图像3 712张、验证图像3 769张,图像大小约为1 224×370像素. 目标检测网络选用Disp-RCNN[29 ] . Disp-RCNN是基于实例级视差估计的双目三维目标检测框架,主要由3个部分组成:1)检测每个输入对象的二维边框和实例掩码,2)仅估计属于对象的像素视差,3)使用三维检测器从实例点云中预测出三维边界框. 具体参数使用Disp-RCNN的默认参数,检测网络采用官方提供的预训练模型,再将各种方法增强后的双目图像分别输入检测网络,测试各自检测结果. ...
Lightening network for low-light image enhancement
1
2020
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
1
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
1
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
2
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
... FCNet是端到端的可训练网络,无须对子模块进行预先训练. 本次实验使用8 086幅室外图像训练FCNet,使用4 572幅室内图像对和205幅室内图像测试FCNet. 为了便于对网络进行训练和测试,图像大小设定为640×480像素. 本研究在单个GeForce GTX Titan X显卡上使用PyTorch实现提出的方法,用于训练的优化器为Adam,学习率固定为0.000 1. 设置本次实验的批大小为1,epoch的数量为50, $ {W}_{\mathrm{s}\mathrm{p}\mathrm{a}} $ $ {W}_{\mathrm{e}\mathrm{x}\mathrm{p}}=5 $ $ {W}_{\mathrm{c}\mathrm{o}\mathrm{l}}=5 $ $ {W}_{{\mathrm{t}\mathrm{v}}}=1 \; 900 $ $ {W}_{\mathrm{s}\mathrm{c}}=1 $ . SLL10K的测试集分为有参考的室内子集和无参考的室外子集. 对于无参考图像的室外子集,采用4个无参考指标来评价不同方法的增强效果,包括无参考图像空间质量评价器(blind/referenceless image spatial quality evaluator,BRISQUE)[19 ] 、自然图像质量评价器(natural image quality evaluator, NIQE)[20 ] 、基于感知的图像质量评价器(perception-based image quality evaluator, PIQE)[21 ] 和亮度顺序误差(lightness order error, LOE)[22 ] . 对于有参考图像的室内子集,采用3个有参考指标和4个无参考指标来评价不同方法的增强效果,其中有参考指标包括峰值信噪比(peak signal to noise ratio, PSNR)、结构相似度(structural similarity, SSIM)和学习感知图像块相似度(learned perceptual image patch similarity, LPIPS)[6 ,23 ] ,无参考指标包括BRISQUE、NIQE、LOE、PIQE. 指标BRISQUE、NIQE、PIQE、LOE和LPIPS的数值越小表示图像增强的效果越好,指标PSNR和SSIM的数值越大表示图像增强的效果越好. 提供室内图像的主要目的是方便其他方法采用本数据集测试时的有参考指标比较. ...
Low-light image enhancement with semi-decoupled decomposition
1
2020
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
1
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
1
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
1
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
5
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
... 将FCNet与RetinexNet[11 ] 、ISSR[24 ] 、GLAD[25 ] 、DVENet[16 ] 、ZeroDCE++[17 ] 、RUAS[26 ] 的单目、双目低光照图像增强方法进行对比. 其中RetinexNet、ISSR、GLAD和DVENet是有监督学习方法,ZeroDCE++、RUAS和FCNet是无监督学习方法;DVENet是双目低光照图像增强方法. 无监督学习方法均在SLL10K训练集上进行训练,之后在测试集上得到增强结果;有监督学习方法由于缺乏参考图像,采用其论文提供的预训练模型在SLL10K上进行测试. ...
... Indicators comparison of different image enhancement methods on SLL10K outdoor dataset
Tab.4 方法 左目 右目 BRISQUE NIQE PIQE LOE BRISQUE NIQE PIQE LOE RetinexNet[11 ] 24.640 7 4.257 3 36.454 5 1 741.5 24.420 5 4.270 1 36.276 1 1752.7 ISSR[24 ] 28.392 8 2.815 1 27.923 2 753.0 28.903 5 2.810 7 28.525 2 724.2 GLAD[25 ] 23.628 8 3.280 8 28.633 4 590.8 23.729 0 3.268 0 28.310 2 584.8 DVENet[16 ] 23.100 2 2.931 7 28.175 1 791.9 22.706 7 2.872 3 27.531 7 740.2 ZeroDCE++[17 ] 25.684 8 2.832 7 32.569 0 807.7 25.560 2 2.857 2 32.118 0 814.4 RUAS[26 ] 29.713 1 3.746 6 30.512 2 2 520.0 29.736 9 3.675 5 30.863 7 2 300.6 FCNet 23.095 1 2.641 1 28.111 5 679.2 22.689 8 2.632 3 27.374 5 669.9
表 5 不同图像增强方法在SLL10K室内数据集上的指标对比 ...
... Indicators comparison of different image enhancement methods on SLL10K indoor dataset
Tab.5 方法 左目 右目 BRISQUE NIQE PIQE LOE PSNR SSIM LPIPS BRISQUE NIQE PIQE LOE PSNR SSIM LPIPS RetinexNet[11 ] 34.042 9 5.592 2 49.155 6 3 241.0 11.640 2 0.222 1 0.812 2 33.562 7 5.596 0 48.305 5 3 102.3 11.211 8 0.238 0 0.798 2 ISSR[24 ] 23.900 7 2.751 8 29.193 1 2 599.6 8.858 8 0.258 8 0.674 5 24.626 0 2.950 9 28.848 0 2 577.8 8.199 8 0.261 9 0.660 3 GLAD[25 ] 23.139 6 3.673 4 42.574 7 2 547.2 12.875 1 0.229 0 0.666 0 25.854 5 3.581 8 41.646 0 2 515.4 12.174 0 0.247 5 0.648 3 DVENet[16 ] 23.075 7 3.405 7 32.115 1 2 595.8 9.026 0 0.246 0 0.656 9 22.189 2 3.391 6 30.236 3 2 543.2 8.595 1 0.248 9 0.643 7 ZeroDCE++[17 ] 27.663 3 3.694 9 38.553 7 2 738.0 11.230 5 0.360 5 0.725 4 27.262 2 3.649 7 38.050 0 2 671.1 10.410 9 0.363 1 0.713 0 RUAS[26 ] 24.693 4 3.361 7 35.548 8 2 671.3 9.864 7 0.380 4 0.710 2 24.375 1 3.305 0 33.077 0 2 581.7 9.234 6 0.369 1 0.693 1 FCNet 22.531 7 3.390 1 31.279 4 2 593.4 11.222 1 0.406 2 0.609 2 21.273 6 3.329 7 29.109 7 2 539.9 10.407 3 0.407 3 0.598 0
3.3.2. 视觉对比 FCNet是无监督图像增强方法,因此仅选择2个无监督方法RUAS和ZeroDCE++进行可视化对比. 如图6 所示为FCNet与ZeroDCE++、RUAS无监督方法在不同场景下的视觉比较. 对比夜晚灯笼场景图像可以看出,RUAS增强的图像周围环境的色彩受到灯光区域影响严重,且过曝现象严重;ZeroDCE++增强的图像框出区域路肩受到光照过曝,损失路肩部分细节;FCNet增强的图像保证了周围环境的色彩,也保证了图像对比度,还避免了过噪和过曝现象,相较于其他方法优势显著. 对比夜晚公交场景图像可以看出,RUAS增强的图像路面和路灯过曝现象严重,损失车辆上和路面上的部分细节;ZeroDCE++增强的图像框出区域车辆玻璃上的噪声显著,车身也略微发白;FCNet增强的图像路面和路灯没有显著的过曝现象,车辆玻璃上的噪声也不显著,相较于其他方法优势显著. 对比夜晚车辆和建筑场景图像可以看出,RUAS增强的图像路灯过曝现象严重,损失部分细节;ZeroDCE++增强的图像车身区域噪声明显,框出区域的路灯灯光过曝明显;FCNet增强的图像既能降低噪声,又避免了过曝现象,相较于其他方法优势显著. 对比夜晚树木和建筑场景图像可以看出,RUAS增强的图像增强效果不明显,且路面和窗户部分区域有过曝现象;ZeroDCE++增强的图像框出区域过曝现象严重,损失部分细节;FCNet增强的图像既降低了噪声,又避免了过曝现象,相较于其他方法优势显著. ...
... Object detection results of different image enhancement methods
Tab.6 % 方法 $ {\mathrm{A}\mathrm{P}}_{{\rm{2d}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{ori}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{bev}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{3d}}} $ 原始 88.86 86.90 64.54 50.49 低光照 70.48 68.14 48.16 34.43 RetinexNet[11 ] 69.70 67.71 48.99 36.21 ISSR[23 ] 70.73 68.12 46.20 33.45 GLAD[24 ] 88.30 86.12 57.23 45.05 ZeroDCE++[17 ] 88.23 86.03 57.12 44.98 RUAS[25 ] 87.81 84.24 55.27 42.32 FCNet 88.51 86.55 57.72 45.45
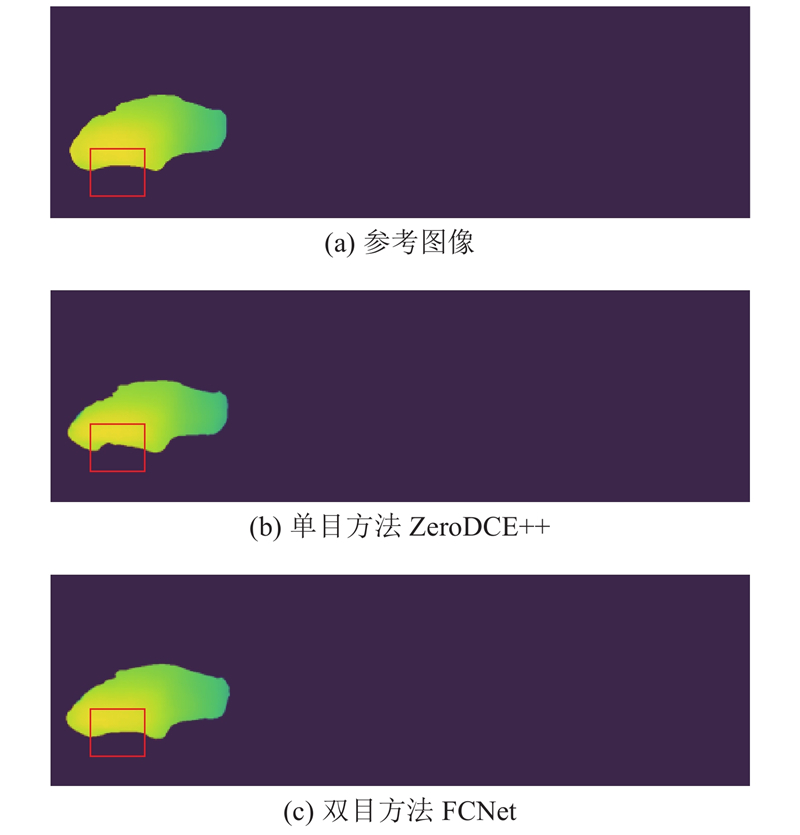
图 8 单、双目图像增强方法的视差图对比 ...
1
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
1
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
1
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
1
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
Low-light stereo image enhancement
4
2022
... 低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强. 有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang等[1 ] 提出的流正则化模型增强低光照图像;Lv等[2 ] 提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang等[3 ] 将低光照增强任务转化为求残差的任务;Zhou等[4 ] 将低光照增强任务和去模糊任务共同进行;Zheng等[5 ] 提出全局的噪声模型估计,对图像进行亮度提高与去噪处理. Retinex理论已被用于低光照图像增强任务中[6 -7 ] ,核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像. 无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo等[8 ] 通过估计亮度增强曲线调整低光照图像,Ma等[9 ] 通过级联自标定学习机制提升低光照图像质量,Zhang等[10 ] 将每张彩色图像解耦为灰度图像和颜色直方图. 为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11 ] 、短曝光和长曝光图像对数据集SID[12 ] . 低光照图像增强的方法大部分基于单目图像. 相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13 ] (学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14 ] (联合视差估计和双目图像去模糊)、成对的降雨去除网络[15 ] (该网络可以补充遮挡区域的信息). 此外,Huang等[16 ] 提出使用Retinex的双目增强方法,初步表明了双目低光照图像增强的有效性. ...
... 将FCNet与RetinexNet[11 ] 、ISSR[24 ] 、GLAD[25 ] 、DVENet[16 ] 、ZeroDCE++[17 ] 、RUAS[26 ] 的单目、双目低光照图像增强方法进行对比. 其中RetinexNet、ISSR、GLAD和DVENet是有监督学习方法,ZeroDCE++、RUAS和FCNet是无监督学习方法;DVENet是双目低光照图像增强方法. 无监督学习方法均在SLL10K训练集上进行训练,之后在测试集上得到增强结果;有监督学习方法由于缺乏参考图像,采用其论文提供的预训练模型在SLL10K上进行测试. ...
... Indicators comparison of different image enhancement methods on SLL10K outdoor dataset
Tab.4 方法 左目 右目 BRISQUE NIQE PIQE LOE BRISQUE NIQE PIQE LOE RetinexNet[11 ] 24.640 7 4.257 3 36.454 5 1 741.5 24.420 5 4.270 1 36.276 1 1752.7 ISSR[24 ] 28.392 8 2.815 1 27.923 2 753.0 28.903 5 2.810 7 28.525 2 724.2 GLAD[25 ] 23.628 8 3.280 8 28.633 4 590.8 23.729 0 3.268 0 28.310 2 584.8 DVENet[16 ] 23.100 2 2.931 7 28.175 1 791.9 22.706 7 2.872 3 27.531 7 740.2 ZeroDCE++[17 ] 25.684 8 2.832 7 32.569 0 807.7 25.560 2 2.857 2 32.118 0 814.4 RUAS[26 ] 29.713 1 3.746 6 30.512 2 2 520.0 29.736 9 3.675 5 30.863 7 2 300.6 FCNet 23.095 1 2.641 1 28.111 5 679.2 22.689 8 2.632 3 27.374 5 669.9
表 5 不同图像增强方法在SLL10K室内数据集上的指标对比 ...
... Indicators comparison of different image enhancement methods on SLL10K indoor dataset
Tab.5 方法 左目 右目 BRISQUE NIQE PIQE LOE PSNR SSIM LPIPS BRISQUE NIQE PIQE LOE PSNR SSIM LPIPS RetinexNet[11 ] 34.042 9 5.592 2 49.155 6 3 241.0 11.640 2 0.222 1 0.812 2 33.562 7 5.596 0 48.305 5 3 102.3 11.211 8 0.238 0 0.798 2 ISSR[24 ] 23.900 7 2.751 8 29.193 1 2 599.6 8.858 8 0.258 8 0.674 5 24.626 0 2.950 9 28.848 0 2 577.8 8.199 8 0.261 9 0.660 3 GLAD[25 ] 23.139 6 3.673 4 42.574 7 2 547.2 12.875 1 0.229 0 0.666 0 25.854 5 3.581 8 41.646 0 2 515.4 12.174 0 0.247 5 0.648 3 DVENet[16 ] 23.075 7 3.405 7 32.115 1 2 595.8 9.026 0 0.246 0 0.656 9 22.189 2 3.391 6 30.236 3 2 543.2 8.595 1 0.248 9 0.643 7 ZeroDCE++[17 ] 27.663 3 3.694 9 38.553 7 2 738.0 11.230 5 0.360 5 0.725 4 27.262 2 3.649 7 38.050 0 2 671.1 10.410 9 0.363 1 0.713 0 RUAS[26 ] 24.693 4 3.361 7 35.548 8 2 671.3 9.864 7 0.380 4 0.710 2 24.375 1 3.305 0 33.077 0 2 581.7 9.234 6 0.369 1 0.693 1 FCNet 22.531 7 3.390 1 31.279 4 2 593.4 11.222 1 0.406 2 0.609 2 21.273 6 3.329 7 29.109 7 2 539.9 10.407 3 0.407 3 0.598 0
3.3.2. 视觉对比 FCNet是无监督图像增强方法,因此仅选择2个无监督方法RUAS和ZeroDCE++进行可视化对比. 如图6 所示为FCNet与ZeroDCE++、RUAS无监督方法在不同场景下的视觉比较. 对比夜晚灯笼场景图像可以看出,RUAS增强的图像周围环境的色彩受到灯光区域影响严重,且过曝现象严重;ZeroDCE++增强的图像框出区域路肩受到光照过曝,损失路肩部分细节;FCNet增强的图像保证了周围环境的色彩,也保证了图像对比度,还避免了过噪和过曝现象,相较于其他方法优势显著. 对比夜晚公交场景图像可以看出,RUAS增强的图像路面和路灯过曝现象严重,损失车辆上和路面上的部分细节;ZeroDCE++增强的图像框出区域车辆玻璃上的噪声显著,车身也略微发白;FCNet增强的图像路面和路灯没有显著的过曝现象,车辆玻璃上的噪声也不显著,相较于其他方法优势显著. 对比夜晚车辆和建筑场景图像可以看出,RUAS增强的图像路灯过曝现象严重,损失部分细节;ZeroDCE++增强的图像车身区域噪声明显,框出区域的路灯灯光过曝明显;FCNet增强的图像既能降低噪声,又避免了过曝现象,相较于其他方法优势显著. 对比夜晚树木和建筑场景图像可以看出,RUAS增强的图像增强效果不明显,且路面和窗户部分区域有过曝现象;ZeroDCE++增强的图像框出区域过曝现象严重,损失部分细节;FCNet增强的图像既降低了噪声,又避免了过曝现象,相较于其他方法优势显著. ...
Learning to enhance low-light image via zero-reference deep curve estimation
6
2022
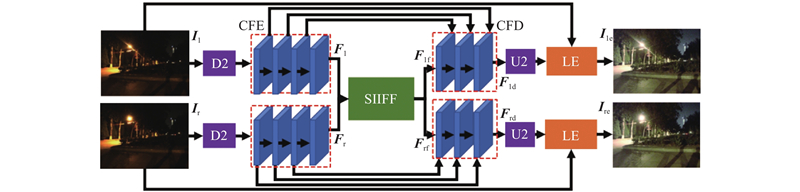
... 为了充分挖掘双目提供的多视角信息用于双目低光照图像增强,本研究提出FCNet,在单目低光照图像增强方法ZeroDCE++[17 ] 的基础上,添加2个双目相关模块提取双目多视角信息:双目内外特征融合(stereo inter-intra-feature fusion, SIIFF)模块和双目一致性(stereo consistency, SC)损失函数,提升双目低光照图像增强的性能. FCNet的整体架构如图4 所示. ...
... 采用单目低光照增强方法ZeroDCE++[17 ] 预测RGB的3个通道的亮度增强曲线,利用亮度增强曲线对低光照图像进行增强,表达式为 ...
... 将FCNet与RetinexNet[11 ] 、ISSR[24 ] 、GLAD[25 ] 、DVENet[16 ] 、ZeroDCE++[17 ] 、RUAS[26 ] 的单目、双目低光照图像增强方法进行对比. 其中RetinexNet、ISSR、GLAD和DVENet是有监督学习方法,ZeroDCE++、RUAS和FCNet是无监督学习方法;DVENet是双目低光照图像增强方法. 无监督学习方法均在SLL10K训练集上进行训练,之后在测试集上得到增强结果;有监督学习方法由于缺乏参考图像,采用其论文提供的预训练模型在SLL10K上进行测试. ...
... Indicators comparison of different image enhancement methods on SLL10K outdoor dataset
Tab.4 方法 左目 右目 BRISQUE NIQE PIQE LOE BRISQUE NIQE PIQE LOE RetinexNet[11 ] 24.640 7 4.257 3 36.454 5 1 741.5 24.420 5 4.270 1 36.276 1 1752.7 ISSR[24 ] 28.392 8 2.815 1 27.923 2 753.0 28.903 5 2.810 7 28.525 2 724.2 GLAD[25 ] 23.628 8 3.280 8 28.633 4 590.8 23.729 0 3.268 0 28.310 2 584.8 DVENet[16 ] 23.100 2 2.931 7 28.175 1 791.9 22.706 7 2.872 3 27.531 7 740.2 ZeroDCE++[17 ] 25.684 8 2.832 7 32.569 0 807.7 25.560 2 2.857 2 32.118 0 814.4 RUAS[26 ] 29.713 1 3.746 6 30.512 2 2 520.0 29.736 9 3.675 5 30.863 7 2 300.6 FCNet 23.095 1 2.641 1 28.111 5 679.2 22.689 8 2.632 3 27.374 5 669.9
表 5 不同图像增强方法在SLL10K室内数据集上的指标对比 ...
... Indicators comparison of different image enhancement methods on SLL10K indoor dataset
Tab.5 方法 左目 右目 BRISQUE NIQE PIQE LOE PSNR SSIM LPIPS BRISQUE NIQE PIQE LOE PSNR SSIM LPIPS RetinexNet[11 ] 34.042 9 5.592 2 49.155 6 3 241.0 11.640 2 0.222 1 0.812 2 33.562 7 5.596 0 48.305 5 3 102.3 11.211 8 0.238 0 0.798 2 ISSR[24 ] 23.900 7 2.751 8 29.193 1 2 599.6 8.858 8 0.258 8 0.674 5 24.626 0 2.950 9 28.848 0 2 577.8 8.199 8 0.261 9 0.660 3 GLAD[25 ] 23.139 6 3.673 4 42.574 7 2 547.2 12.875 1 0.229 0 0.666 0 25.854 5 3.581 8 41.646 0 2 515.4 12.174 0 0.247 5 0.648 3 DVENet[16 ] 23.075 7 3.405 7 32.115 1 2 595.8 9.026 0 0.246 0 0.656 9 22.189 2 3.391 6 30.236 3 2 543.2 8.595 1 0.248 9 0.643 7 ZeroDCE++[17 ] 27.663 3 3.694 9 38.553 7 2 738.0 11.230 5 0.360 5 0.725 4 27.262 2 3.649 7 38.050 0 2 671.1 10.410 9 0.363 1 0.713 0 RUAS[26 ] 24.693 4 3.361 7 35.548 8 2 671.3 9.864 7 0.380 4 0.710 2 24.375 1 3.305 0 33.077 0 2 581.7 9.234 6 0.369 1 0.693 1 FCNet 22.531 7 3.390 1 31.279 4 2 593.4 11.222 1 0.406 2 0.609 2 21.273 6 3.329 7 29.109 7 2 539.9 10.407 3 0.407 3 0.598 0
3.3.2. 视觉对比 FCNet是无监督图像增强方法,因此仅选择2个无监督方法RUAS和ZeroDCE++进行可视化对比. 如图6 所示为FCNet与ZeroDCE++、RUAS无监督方法在不同场景下的视觉比较. 对比夜晚灯笼场景图像可以看出,RUAS增强的图像周围环境的色彩受到灯光区域影响严重,且过曝现象严重;ZeroDCE++增强的图像框出区域路肩受到光照过曝,损失路肩部分细节;FCNet增强的图像保证了周围环境的色彩,也保证了图像对比度,还避免了过噪和过曝现象,相较于其他方法优势显著. 对比夜晚公交场景图像可以看出,RUAS增强的图像路面和路灯过曝现象严重,损失车辆上和路面上的部分细节;ZeroDCE++增强的图像框出区域车辆玻璃上的噪声显著,车身也略微发白;FCNet增强的图像路面和路灯没有显著的过曝现象,车辆玻璃上的噪声也不显著,相较于其他方法优势显著. 对比夜晚车辆和建筑场景图像可以看出,RUAS增强的图像路灯过曝现象严重,损失部分细节;ZeroDCE++增强的图像车身区域噪声明显,框出区域的路灯灯光过曝明显;FCNet增强的图像既能降低噪声,又避免了过曝现象,相较于其他方法优势显著. 对比夜晚树木和建筑场景图像可以看出,RUAS增强的图像增强效果不明显,且路面和窗户部分区域有过曝现象;ZeroDCE++增强的图像框出区域过曝现象严重,损失部分细节;FCNet增强的图像既降低了噪声,又避免了过曝现象,相较于其他方法优势显著. ...
... Object detection results of different image enhancement methods
Tab.6 % 方法 $ {\mathrm{A}\mathrm{P}}_{{\rm{2d}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{ori}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{bev}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{3d}}} $ 原始 88.86 86.90 64.54 50.49 低光照 70.48 68.14 48.16 34.43 RetinexNet[11 ] 69.70 67.71 48.99 36.21 ISSR[23 ] 70.73 68.12 46.20 33.45 GLAD[24 ] 88.30 86.12 57.23 45.05 ZeroDCE++[17 ] 88.23 86.03 57.12 44.98 RUAS[25 ] 87.81 84.24 55.27 42.32 FCNet 88.51 86.55 57.72 45.45
图 8 单、双目图像增强方法的视差图对比 ...
1
... 受Wang等[18 ] 启发,为了减少右目中不相关的点对左目图像的影响,将 $ {\boldsymbol{S}}_{\mathrm{l}\to \mathrm{r}} $ $ {\boldsymbol{M}}_{\mathrm{l}}\in {\mathbf{R}}^{B\times 1\times H\times W} $ . AIF模块将 $ {\boldsymbol{F}}_{\mathrm{l}} $ $ {\boldsymbol{M}}_{\mathrm{l}} $ $ {\boldsymbol{A}}_{\mathrm{l}} $ $ {\boldsymbol{F}}_{\mathrm{l}\mathrm{a}}\in {\mathbf{R}}^{B\times C\times H\times W} $
No-reference image quality assessment in the spatial domain
1
2012
... FCNet是端到端的可训练网络,无须对子模块进行预先训练. 本次实验使用8 086幅室外图像训练FCNet,使用4 572幅室内图像对和205幅室内图像测试FCNet. 为了便于对网络进行训练和测试,图像大小设定为640×480像素. 本研究在单个GeForce GTX Titan X显卡上使用PyTorch实现提出的方法,用于训练的优化器为Adam,学习率固定为0.000 1. 设置本次实验的批大小为1,epoch的数量为50, $ {W}_{\mathrm{s}\mathrm{p}\mathrm{a}} $ $ {W}_{\mathrm{e}\mathrm{x}\mathrm{p}}=5 $ $ {W}_{\mathrm{c}\mathrm{o}\mathrm{l}}=5 $ $ {W}_{{\mathrm{t}\mathrm{v}}}=1 \; 900 $ $ {W}_{\mathrm{s}\mathrm{c}}=1 $ . SLL10K的测试集分为有参考的室内子集和无参考的室外子集. 对于无参考图像的室外子集,采用4个无参考指标来评价不同方法的增强效果,包括无参考图像空间质量评价器(blind/referenceless image spatial quality evaluator,BRISQUE)[19 ] 、自然图像质量评价器(natural image quality evaluator, NIQE)[20 ] 、基于感知的图像质量评价器(perception-based image quality evaluator, PIQE)[21 ] 和亮度顺序误差(lightness order error, LOE)[22 ] . 对于有参考图像的室内子集,采用3个有参考指标和4个无参考指标来评价不同方法的增强效果,其中有参考指标包括峰值信噪比(peak signal to noise ratio, PSNR)、结构相似度(structural similarity, SSIM)和学习感知图像块相似度(learned perceptual image patch similarity, LPIPS)[6 ,23 ] ,无参考指标包括BRISQUE、NIQE、LOE、PIQE. 指标BRISQUE、NIQE、PIQE、LOE和LPIPS的数值越小表示图像增强的效果越好,指标PSNR和SSIM的数值越大表示图像增强的效果越好. 提供室内图像的主要目的是方便其他方法采用本数据集测试时的有参考指标比较. ...
Making a “completely blind” image quality analyzer
1
2012
... FCNet是端到端的可训练网络,无须对子模块进行预先训练. 本次实验使用8 086幅室外图像训练FCNet,使用4 572幅室内图像对和205幅室内图像测试FCNet. 为了便于对网络进行训练和测试,图像大小设定为640×480像素. 本研究在单个GeForce GTX Titan X显卡上使用PyTorch实现提出的方法,用于训练的优化器为Adam,学习率固定为0.000 1. 设置本次实验的批大小为1,epoch的数量为50, $ {W}_{\mathrm{s}\mathrm{p}\mathrm{a}} $ $ {W}_{\mathrm{e}\mathrm{x}\mathrm{p}}=5 $ $ {W}_{\mathrm{c}\mathrm{o}\mathrm{l}}=5 $ $ {W}_{{\mathrm{t}\mathrm{v}}}=1 \; 900 $ $ {W}_{\mathrm{s}\mathrm{c}}=1 $ . SLL10K的测试集分为有参考的室内子集和无参考的室外子集. 对于无参考图像的室外子集,采用4个无参考指标来评价不同方法的增强效果,包括无参考图像空间质量评价器(blind/referenceless image spatial quality evaluator,BRISQUE)[19 ] 、自然图像质量评价器(natural image quality evaluator, NIQE)[20 ] 、基于感知的图像质量评价器(perception-based image quality evaluator, PIQE)[21 ] 和亮度顺序误差(lightness order error, LOE)[22 ] . 对于有参考图像的室内子集,采用3个有参考指标和4个无参考指标来评价不同方法的增强效果,其中有参考指标包括峰值信噪比(peak signal to noise ratio, PSNR)、结构相似度(structural similarity, SSIM)和学习感知图像块相似度(learned perceptual image patch similarity, LPIPS)[6 ,23 ] ,无参考指标包括BRISQUE、NIQE、LOE、PIQE. 指标BRISQUE、NIQE、PIQE、LOE和LPIPS的数值越小表示图像增强的效果越好,指标PSNR和SSIM的数值越大表示图像增强的效果越好. 提供室内图像的主要目的是方便其他方法采用本数据集测试时的有参考指标比较. ...
1
... FCNet是端到端的可训练网络,无须对子模块进行预先训练. 本次实验使用8 086幅室外图像训练FCNet,使用4 572幅室内图像对和205幅室内图像测试FCNet. 为了便于对网络进行训练和测试,图像大小设定为640×480像素. 本研究在单个GeForce GTX Titan X显卡上使用PyTorch实现提出的方法,用于训练的优化器为Adam,学习率固定为0.000 1. 设置本次实验的批大小为1,epoch的数量为50, $ {W}_{\mathrm{s}\mathrm{p}\mathrm{a}} $ $ {W}_{\mathrm{e}\mathrm{x}\mathrm{p}}=5 $ $ {W}_{\mathrm{c}\mathrm{o}\mathrm{l}}=5 $ $ {W}_{{\mathrm{t}\mathrm{v}}}=1 \; 900 $ $ {W}_{\mathrm{s}\mathrm{c}}=1 $ . SLL10K的测试集分为有参考的室内子集和无参考的室外子集. 对于无参考图像的室外子集,采用4个无参考指标来评价不同方法的增强效果,包括无参考图像空间质量评价器(blind/referenceless image spatial quality evaluator,BRISQUE)[19 ] 、自然图像质量评价器(natural image quality evaluator, NIQE)[20 ] 、基于感知的图像质量评价器(perception-based image quality evaluator, PIQE)[21 ] 和亮度顺序误差(lightness order error, LOE)[22 ] . 对于有参考图像的室内子集,采用3个有参考指标和4个无参考指标来评价不同方法的增强效果,其中有参考指标包括峰值信噪比(peak signal to noise ratio, PSNR)、结构相似度(structural similarity, SSIM)和学习感知图像块相似度(learned perceptual image patch similarity, LPIPS)[6 ,23 ] ,无参考指标包括BRISQUE、NIQE、LOE、PIQE. 指标BRISQUE、NIQE、PIQE、LOE和LPIPS的数值越小表示图像增强的效果越好,指标PSNR和SSIM的数值越大表示图像增强的效果越好. 提供室内图像的主要目的是方便其他方法采用本数据集测试时的有参考指标比较. ...
Naturalness preserved enhancement algorithm for non-uniform illumination images
1
2013
... FCNet是端到端的可训练网络,无须对子模块进行预先训练. 本次实验使用8 086幅室外图像训练FCNet,使用4 572幅室内图像对和205幅室内图像测试FCNet. 为了便于对网络进行训练和测试,图像大小设定为640×480像素. 本研究在单个GeForce GTX Titan X显卡上使用PyTorch实现提出的方法,用于训练的优化器为Adam,学习率固定为0.000 1. 设置本次实验的批大小为1,epoch的数量为50, $ {W}_{\mathrm{s}\mathrm{p}\mathrm{a}} $ $ {W}_{\mathrm{e}\mathrm{x}\mathrm{p}}=5 $ $ {W}_{\mathrm{c}\mathrm{o}\mathrm{l}}=5 $ $ {W}_{{\mathrm{t}\mathrm{v}}}=1 \; 900 $ $ {W}_{\mathrm{s}\mathrm{c}}=1 $ . SLL10K的测试集分为有参考的室内子集和无参考的室外子集. 对于无参考图像的室外子集,采用4个无参考指标来评价不同方法的增强效果,包括无参考图像空间质量评价器(blind/referenceless image spatial quality evaluator,BRISQUE)[19 ] 、自然图像质量评价器(natural image quality evaluator, NIQE)[20 ] 、基于感知的图像质量评价器(perception-based image quality evaluator, PIQE)[21 ] 和亮度顺序误差(lightness order error, LOE)[22 ] . 对于有参考图像的室内子集,采用3个有参考指标和4个无参考指标来评价不同方法的增强效果,其中有参考指标包括峰值信噪比(peak signal to noise ratio, PSNR)、结构相似度(structural similarity, SSIM)和学习感知图像块相似度(learned perceptual image patch similarity, LPIPS)[6 ,23 ] ,无参考指标包括BRISQUE、NIQE、LOE、PIQE. 指标BRISQUE、NIQE、PIQE、LOE和LPIPS的数值越小表示图像增强的效果越好,指标PSNR和SSIM的数值越大表示图像增强的效果越好. 提供室内图像的主要目的是方便其他方法采用本数据集测试时的有参考指标比较. ...
2
... FCNet是端到端的可训练网络,无须对子模块进行预先训练. 本次实验使用8 086幅室外图像训练FCNet,使用4 572幅室内图像对和205幅室内图像测试FCNet. 为了便于对网络进行训练和测试,图像大小设定为640×480像素. 本研究在单个GeForce GTX Titan X显卡上使用PyTorch实现提出的方法,用于训练的优化器为Adam,学习率固定为0.000 1. 设置本次实验的批大小为1,epoch的数量为50, $ {W}_{\mathrm{s}\mathrm{p}\mathrm{a}} $ $ {W}_{\mathrm{e}\mathrm{x}\mathrm{p}}=5 $ $ {W}_{\mathrm{c}\mathrm{o}\mathrm{l}}=5 $ $ {W}_{{\mathrm{t}\mathrm{v}}}=1 \; 900 $ $ {W}_{\mathrm{s}\mathrm{c}}=1 $ . SLL10K的测试集分为有参考的室内子集和无参考的室外子集. 对于无参考图像的室外子集,采用4个无参考指标来评价不同方法的增强效果,包括无参考图像空间质量评价器(blind/referenceless image spatial quality evaluator,BRISQUE)[19 ] 、自然图像质量评价器(natural image quality evaluator, NIQE)[20 ] 、基于感知的图像质量评价器(perception-based image quality evaluator, PIQE)[21 ] 和亮度顺序误差(lightness order error, LOE)[22 ] . 对于有参考图像的室内子集,采用3个有参考指标和4个无参考指标来评价不同方法的增强效果,其中有参考指标包括峰值信噪比(peak signal to noise ratio, PSNR)、结构相似度(structural similarity, SSIM)和学习感知图像块相似度(learned perceptual image patch similarity, LPIPS)[6 ,23 ] ,无参考指标包括BRISQUE、NIQE、LOE、PIQE. 指标BRISQUE、NIQE、PIQE、LOE和LPIPS的数值越小表示图像增强的效果越好,指标PSNR和SSIM的数值越大表示图像增强的效果越好. 提供室内图像的主要目的是方便其他方法采用本数据集测试时的有参考指标比较. ...
... Object detection results of different image enhancement methods
Tab.6 % 方法 $ {\mathrm{A}\mathrm{P}}_{{\rm{2d}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{ori}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{bev}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{3d}}} $ 原始 88.86 86.90 64.54 50.49 低光照 70.48 68.14 48.16 34.43 RetinexNet[11 ] 69.70 67.71 48.99 36.21 ISSR[23 ] 70.73 68.12 46.20 33.45 GLAD[24 ] 88.30 86.12 57.23 45.05 ZeroDCE++[17 ] 88.23 86.03 57.12 44.98 RUAS[25 ] 87.81 84.24 55.27 42.32 FCNet 88.51 86.55 57.72 45.45
图 8 单、双目图像增强方法的视差图对比 ...
4
... 将FCNet与RetinexNet[11 ] 、ISSR[24 ] 、GLAD[25 ] 、DVENet[16 ] 、ZeroDCE++[17 ] 、RUAS[26 ] 的单目、双目低光照图像增强方法进行对比. 其中RetinexNet、ISSR、GLAD和DVENet是有监督学习方法,ZeroDCE++、RUAS和FCNet是无监督学习方法;DVENet是双目低光照图像增强方法. 无监督学习方法均在SLL10K训练集上进行训练,之后在测试集上得到增强结果;有监督学习方法由于缺乏参考图像,采用其论文提供的预训练模型在SLL10K上进行测试. ...
... Indicators comparison of different image enhancement methods on SLL10K outdoor dataset
Tab.4 方法 左目 右目 BRISQUE NIQE PIQE LOE BRISQUE NIQE PIQE LOE RetinexNet[11 ] 24.640 7 4.257 3 36.454 5 1 741.5 24.420 5 4.270 1 36.276 1 1752.7 ISSR[24 ] 28.392 8 2.815 1 27.923 2 753.0 28.903 5 2.810 7 28.525 2 724.2 GLAD[25 ] 23.628 8 3.280 8 28.633 4 590.8 23.729 0 3.268 0 28.310 2 584.8 DVENet[16 ] 23.100 2 2.931 7 28.175 1 791.9 22.706 7 2.872 3 27.531 7 740.2 ZeroDCE++[17 ] 25.684 8 2.832 7 32.569 0 807.7 25.560 2 2.857 2 32.118 0 814.4 RUAS[26 ] 29.713 1 3.746 6 30.512 2 2 520.0 29.736 9 3.675 5 30.863 7 2 300.6 FCNet 23.095 1 2.641 1 28.111 5 679.2 22.689 8 2.632 3 27.374 5 669.9
表 5 不同图像增强方法在SLL10K室内数据集上的指标对比 ...
... Indicators comparison of different image enhancement methods on SLL10K indoor dataset
Tab.5 方法 左目 右目 BRISQUE NIQE PIQE LOE PSNR SSIM LPIPS BRISQUE NIQE PIQE LOE PSNR SSIM LPIPS RetinexNet[11 ] 34.042 9 5.592 2 49.155 6 3 241.0 11.640 2 0.222 1 0.812 2 33.562 7 5.596 0 48.305 5 3 102.3 11.211 8 0.238 0 0.798 2 ISSR[24 ] 23.900 7 2.751 8 29.193 1 2 599.6 8.858 8 0.258 8 0.674 5 24.626 0 2.950 9 28.848 0 2 577.8 8.199 8 0.261 9 0.660 3 GLAD[25 ] 23.139 6 3.673 4 42.574 7 2 547.2 12.875 1 0.229 0 0.666 0 25.854 5 3.581 8 41.646 0 2 515.4 12.174 0 0.247 5 0.648 3 DVENet[16 ] 23.075 7 3.405 7 32.115 1 2 595.8 9.026 0 0.246 0 0.656 9 22.189 2 3.391 6 30.236 3 2 543.2 8.595 1 0.248 9 0.643 7 ZeroDCE++[17 ] 27.663 3 3.694 9 38.553 7 2 738.0 11.230 5 0.360 5 0.725 4 27.262 2 3.649 7 38.050 0 2 671.1 10.410 9 0.363 1 0.713 0 RUAS[26 ] 24.693 4 3.361 7 35.548 8 2 671.3 9.864 7 0.380 4 0.710 2 24.375 1 3.305 0 33.077 0 2 581.7 9.234 6 0.369 1 0.693 1 FCNet 22.531 7 3.390 1 31.279 4 2 593.4 11.222 1 0.406 2 0.609 2 21.273 6 3.329 7 29.109 7 2 539.9 10.407 3 0.407 3 0.598 0
3.3.2. 视觉对比 FCNet是无监督图像增强方法,因此仅选择2个无监督方法RUAS和ZeroDCE++进行可视化对比. 如图6 所示为FCNet与ZeroDCE++、RUAS无监督方法在不同场景下的视觉比较. 对比夜晚灯笼场景图像可以看出,RUAS增强的图像周围环境的色彩受到灯光区域影响严重,且过曝现象严重;ZeroDCE++增强的图像框出区域路肩受到光照过曝,损失路肩部分细节;FCNet增强的图像保证了周围环境的色彩,也保证了图像对比度,还避免了过噪和过曝现象,相较于其他方法优势显著. 对比夜晚公交场景图像可以看出,RUAS增强的图像路面和路灯过曝现象严重,损失车辆上和路面上的部分细节;ZeroDCE++增强的图像框出区域车辆玻璃上的噪声显著,车身也略微发白;FCNet增强的图像路面和路灯没有显著的过曝现象,车辆玻璃上的噪声也不显著,相较于其他方法优势显著. 对比夜晚车辆和建筑场景图像可以看出,RUAS增强的图像路灯过曝现象严重,损失部分细节;ZeroDCE++增强的图像车身区域噪声明显,框出区域的路灯灯光过曝明显;FCNet增强的图像既能降低噪声,又避免了过曝现象,相较于其他方法优势显著. 对比夜晚树木和建筑场景图像可以看出,RUAS增强的图像增强效果不明显,且路面和窗户部分区域有过曝现象;ZeroDCE++增强的图像框出区域过曝现象严重,损失部分细节;FCNet增强的图像既降低了噪声,又避免了过曝现象,相较于其他方法优势显著. ...
... Object detection results of different image enhancement methods
Tab.6 % 方法 $ {\mathrm{A}\mathrm{P}}_{{\rm{2d}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{ori}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{bev}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{3d}}} $ 原始 88.86 86.90 64.54 50.49 低光照 70.48 68.14 48.16 34.43 RetinexNet[11 ] 69.70 67.71 48.99 36.21 ISSR[23 ] 70.73 68.12 46.20 33.45 GLAD[24 ] 88.30 86.12 57.23 45.05 ZeroDCE++[17 ] 88.23 86.03 57.12 44.98 RUAS[25 ] 87.81 84.24 55.27 42.32 FCNet 88.51 86.55 57.72 45.45
图 8 单、双目图像增强方法的视差图对比 ...
4
... 将FCNet与RetinexNet[11 ] 、ISSR[24 ] 、GLAD[25 ] 、DVENet[16 ] 、ZeroDCE++[17 ] 、RUAS[26 ] 的单目、双目低光照图像增强方法进行对比. 其中RetinexNet、ISSR、GLAD和DVENet是有监督学习方法,ZeroDCE++、RUAS和FCNet是无监督学习方法;DVENet是双目低光照图像增强方法. 无监督学习方法均在SLL10K训练集上进行训练,之后在测试集上得到增强结果;有监督学习方法由于缺乏参考图像,采用其论文提供的预训练模型在SLL10K上进行测试. ...
... Indicators comparison of different image enhancement methods on SLL10K outdoor dataset
Tab.4 方法 左目 右目 BRISQUE NIQE PIQE LOE BRISQUE NIQE PIQE LOE RetinexNet[11 ] 24.640 7 4.257 3 36.454 5 1 741.5 24.420 5 4.270 1 36.276 1 1752.7 ISSR[24 ] 28.392 8 2.815 1 27.923 2 753.0 28.903 5 2.810 7 28.525 2 724.2 GLAD[25 ] 23.628 8 3.280 8 28.633 4 590.8 23.729 0 3.268 0 28.310 2 584.8 DVENet[16 ] 23.100 2 2.931 7 28.175 1 791.9 22.706 7 2.872 3 27.531 7 740.2 ZeroDCE++[17 ] 25.684 8 2.832 7 32.569 0 807.7 25.560 2 2.857 2 32.118 0 814.4 RUAS[26 ] 29.713 1 3.746 6 30.512 2 2 520.0 29.736 9 3.675 5 30.863 7 2 300.6 FCNet 23.095 1 2.641 1 28.111 5 679.2 22.689 8 2.632 3 27.374 5 669.9
表 5 不同图像增强方法在SLL10K室内数据集上的指标对比 ...
... Indicators comparison of different image enhancement methods on SLL10K indoor dataset
Tab.5 方法 左目 右目 BRISQUE NIQE PIQE LOE PSNR SSIM LPIPS BRISQUE NIQE PIQE LOE PSNR SSIM LPIPS RetinexNet[11 ] 34.042 9 5.592 2 49.155 6 3 241.0 11.640 2 0.222 1 0.812 2 33.562 7 5.596 0 48.305 5 3 102.3 11.211 8 0.238 0 0.798 2 ISSR[24 ] 23.900 7 2.751 8 29.193 1 2 599.6 8.858 8 0.258 8 0.674 5 24.626 0 2.950 9 28.848 0 2 577.8 8.199 8 0.261 9 0.660 3 GLAD[25 ] 23.139 6 3.673 4 42.574 7 2 547.2 12.875 1 0.229 0 0.666 0 25.854 5 3.581 8 41.646 0 2 515.4 12.174 0 0.247 5 0.648 3 DVENet[16 ] 23.075 7 3.405 7 32.115 1 2 595.8 9.026 0 0.246 0 0.656 9 22.189 2 3.391 6 30.236 3 2 543.2 8.595 1 0.248 9 0.643 7 ZeroDCE++[17 ] 27.663 3 3.694 9 38.553 7 2 738.0 11.230 5 0.360 5 0.725 4 27.262 2 3.649 7 38.050 0 2 671.1 10.410 9 0.363 1 0.713 0 RUAS[26 ] 24.693 4 3.361 7 35.548 8 2 671.3 9.864 7 0.380 4 0.710 2 24.375 1 3.305 0 33.077 0 2 581.7 9.234 6 0.369 1 0.693 1 FCNet 22.531 7 3.390 1 31.279 4 2 593.4 11.222 1 0.406 2 0.609 2 21.273 6 3.329 7 29.109 7 2 539.9 10.407 3 0.407 3 0.598 0
3.3.2. 视觉对比 FCNet是无监督图像增强方法,因此仅选择2个无监督方法RUAS和ZeroDCE++进行可视化对比. 如图6 所示为FCNet与ZeroDCE++、RUAS无监督方法在不同场景下的视觉比较. 对比夜晚灯笼场景图像可以看出,RUAS增强的图像周围环境的色彩受到灯光区域影响严重,且过曝现象严重;ZeroDCE++增强的图像框出区域路肩受到光照过曝,损失路肩部分细节;FCNet增强的图像保证了周围环境的色彩,也保证了图像对比度,还避免了过噪和过曝现象,相较于其他方法优势显著. 对比夜晚公交场景图像可以看出,RUAS增强的图像路面和路灯过曝现象严重,损失车辆上和路面上的部分细节;ZeroDCE++增强的图像框出区域车辆玻璃上的噪声显著,车身也略微发白;FCNet增强的图像路面和路灯没有显著的过曝现象,车辆玻璃上的噪声也不显著,相较于其他方法优势显著. 对比夜晚车辆和建筑场景图像可以看出,RUAS增强的图像路灯过曝现象严重,损失部分细节;ZeroDCE++增强的图像车身区域噪声明显,框出区域的路灯灯光过曝明显;FCNet增强的图像既能降低噪声,又避免了过曝现象,相较于其他方法优势显著. 对比夜晚树木和建筑场景图像可以看出,RUAS增强的图像增强效果不明显,且路面和窗户部分区域有过曝现象;ZeroDCE++增强的图像框出区域过曝现象严重,损失部分细节;FCNet增强的图像既降低了噪声,又避免了过曝现象,相较于其他方法优势显著. ...
... Object detection results of different image enhancement methods
Tab.6 % 方法 $ {\mathrm{A}\mathrm{P}}_{{\rm{2d}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{ori}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{bev}}} $ $ {\mathrm{A}\mathrm{P}}_{{\rm{3d}}} $ 原始 88.86 86.90 64.54 50.49 低光照 70.48 68.14 48.16 34.43 RetinexNet[11 ] 69.70 67.71 48.99 36.21 ISSR[23 ] 70.73 68.12 46.20 33.45 GLAD[24 ] 88.30 86.12 57.23 45.05 ZeroDCE++[17 ] 88.23 86.03 57.12 44.98 RUAS[25 ] 87.81 84.24 55.27 42.32 FCNet 88.51 86.55 57.72 45.45
图 8 单、双目图像增强方法的视差图对比 ...
3
... 将FCNet与RetinexNet[11 ] 、ISSR[24 ] 、GLAD[25 ] 、DVENet[16 ] 、ZeroDCE++[17 ] 、RUAS[26 ] 的单目、双目低光照图像增强方法进行对比. 其中RetinexNet、ISSR、GLAD和DVENet是有监督学习方法,ZeroDCE++、RUAS和FCNet是无监督学习方法;DVENet是双目低光照图像增强方法. 无监督学习方法均在SLL10K训练集上进行训练,之后在测试集上得到增强结果;有监督学习方法由于缺乏参考图像,采用其论文提供的预训练模型在SLL10K上进行测试. ...
... Indicators comparison of different image enhancement methods on SLL10K outdoor dataset
Tab.4 方法 左目 右目 BRISQUE NIQE PIQE LOE BRISQUE NIQE PIQE LOE RetinexNet[11 ] 24.640 7 4.257 3 36.454 5 1 741.5 24.420 5 4.270 1 36.276 1 1752.7 ISSR[24 ] 28.392 8 2.815 1 27.923 2 753.0 28.903 5 2.810 7 28.525 2 724.2 GLAD[25 ] 23.628 8 3.280 8 28.633 4 590.8 23.729 0 3.268 0 28.310 2 584.8 DVENet[16 ] 23.100 2 2.931 7 28.175 1 791.9 22.706 7 2.872 3 27.531 7 740.2 ZeroDCE++[17 ] 25.684 8 2.832 7 32.569 0 807.7 25.560 2 2.857 2 32.118 0 814.4 RUAS[26 ] 29.713 1 3.746 6 30.512 2 2 520.0 29.736 9 3.675 5 30.863 7 2 300.6 FCNet 23.095 1 2.641 1 28.111 5 679.2 22.689 8 2.632 3 27.374 5 669.9
表 5 不同图像增强方法在SLL10K室内数据集上的指标对比 ...
... Indicators comparison of different image enhancement methods on SLL10K indoor dataset
Tab.5 方法 左目 右目 BRISQUE NIQE PIQE LOE PSNR SSIM LPIPS BRISQUE NIQE PIQE LOE PSNR SSIM LPIPS RetinexNet[11 ] 34.042 9 5.592 2 49.155 6 3 241.0 11.640 2 0.222 1 0.812 2 33.562 7 5.596 0 48.305 5 3 102.3 11.211 8 0.238 0 0.798 2 ISSR[24 ] 23.900 7 2.751 8 29.193 1 2 599.6 8.858 8 0.258 8 0.674 5 24.626 0 2.950 9 28.848 0 2 577.8 8.199 8 0.261 9 0.660 3 GLAD[25 ] 23.139 6 3.673 4 42.574 7 2 547.2 12.875 1 0.229 0 0.666 0 25.854 5 3.581 8 41.646 0 2 515.4 12.174 0 0.247 5 0.648 3 DVENet[16 ] 23.075 7 3.405 7 32.115 1 2 595.8 9.026 0 0.246 0 0.656 9 22.189 2 3.391 6 30.236 3 2 543.2 8.595 1 0.248 9 0.643 7 ZeroDCE++[17 ] 27.663 3 3.694 9 38.553 7 2 738.0 11.230 5 0.360 5 0.725 4 27.262 2 3.649 7 38.050 0 2 671.1 10.410 9 0.363 1 0.713 0 RUAS[26 ] 24.693 4 3.361 7 35.548 8 2 671.3 9.864 7 0.380 4 0.710 2 24.375 1 3.305 0 33.077 0 2 581.7 9.234 6 0.369 1 0.693 1 FCNet 22.531 7 3.390 1 31.279 4 2 593.4 11.222 1 0.406 2 0.609 2 21.273 6 3.329 7 29.109 7 2 539.9 10.407 3 0.407 3 0.598 0
3.3.2. 视觉对比 FCNet是无监督图像增强方法,因此仅选择2个无监督方法RUAS和ZeroDCE++进行可视化对比. 如图6 所示为FCNet与ZeroDCE++、RUAS无监督方法在不同场景下的视觉比较. 对比夜晚灯笼场景图像可以看出,RUAS增强的图像周围环境的色彩受到灯光区域影响严重,且过曝现象严重;ZeroDCE++增强的图像框出区域路肩受到光照过曝,损失路肩部分细节;FCNet增强的图像保证了周围环境的色彩,也保证了图像对比度,还避免了过噪和过曝现象,相较于其他方法优势显著. 对比夜晚公交场景图像可以看出,RUAS增强的图像路面和路灯过曝现象严重,损失车辆上和路面上的部分细节;ZeroDCE++增强的图像框出区域车辆玻璃上的噪声显著,车身也略微发白;FCNet增强的图像路面和路灯没有显著的过曝现象,车辆玻璃上的噪声也不显著,相较于其他方法优势显著. 对比夜晚车辆和建筑场景图像可以看出,RUAS增强的图像路灯过曝现象严重,损失部分细节;ZeroDCE++增强的图像车身区域噪声明显,框出区域的路灯灯光过曝明显;FCNet增强的图像既能降低噪声,又避免了过曝现象,相较于其他方法优势显著. 对比夜晚树木和建筑场景图像可以看出,RUAS增强的图像增强效果不明显,且路面和窗户部分区域有过曝现象;ZeroDCE++增强的图像框出区域过曝现象严重,损失部分细节;FCNet增强的图像既降低了噪声,又避免了过曝现象,相较于其他方法优势显著. ...
1
... 进行目标检测实验,对比使用不同方法增强后的图像的目标检测效果. 本实验使用经过亮度暗化处理的低光照KITTI[27 ] 数据集,实现过程是将获取的原始KITTI数据集图像经过Gamma变换[28 ] ,通过调整亮度曲线使图像的亮度变低[2 ] . 这种方法可以模拟类似在低光照条件下获取到的双目低光照图像. 该实验主要考察光照不充分的车辆图像在使用不同方法进行图像增强后,是否可以标出目标车辆的三维检测框. 实验选用KITTI数据集的训练集图像,其中训练图像3 712张、验证图像3 769张,图像大小约为1 224×370像素. 目标检测网络选用Disp-RCNN[29 ] . Disp-RCNN是基于实例级视差估计的双目三维目标检测框架,主要由3个部分组成:1)检测每个输入对象的二维边框和实例掩码,2)仅估计属于对象的像素视差,3)使用三维检测器从实例点云中预测出三维边界框. 具体参数使用Disp-RCNN的默认参数,检测网络采用官方提供的预训练模型,再将各种方法增强后的双目图像分别输入检测网络,测试各自检测结果. ...
图像处理中Gamma校正的研究和实现
1
2006
... 进行目标检测实验,对比使用不同方法增强后的图像的目标检测效果. 本实验使用经过亮度暗化处理的低光照KITTI[27 ] 数据集,实现过程是将获取的原始KITTI数据集图像经过Gamma变换[28 ] ,通过调整亮度曲线使图像的亮度变低[2 ] . 这种方法可以模拟类似在低光照条件下获取到的双目低光照图像. 该实验主要考察光照不充分的车辆图像在使用不同方法进行图像增强后,是否可以标出目标车辆的三维检测框. 实验选用KITTI数据集的训练集图像,其中训练图像3 712张、验证图像3 769张,图像大小约为1 224×370像素. 目标检测网络选用Disp-RCNN[29 ] . Disp-RCNN是基于实例级视差估计的双目三维目标检测框架,主要由3个部分组成:1)检测每个输入对象的二维边框和实例掩码,2)仅估计属于对象的像素视差,3)使用三维检测器从实例点云中预测出三维边界框. 具体参数使用Disp-RCNN的默认参数,检测网络采用官方提供的预训练模型,再将各种方法增强后的双目图像分别输入检测网络,测试各自检测结果. ...
图像处理中Gamma校正的研究和实现
1
2006
... 进行目标检测实验,对比使用不同方法增强后的图像的目标检测效果. 本实验使用经过亮度暗化处理的低光照KITTI[27 ] 数据集,实现过程是将获取的原始KITTI数据集图像经过Gamma变换[28 ] ,通过调整亮度曲线使图像的亮度变低[2 ] . 这种方法可以模拟类似在低光照条件下获取到的双目低光照图像. 该实验主要考察光照不充分的车辆图像在使用不同方法进行图像增强后,是否可以标出目标车辆的三维检测框. 实验选用KITTI数据集的训练集图像,其中训练图像3 712张、验证图像3 769张,图像大小约为1 224×370像素. 目标检测网络选用Disp-RCNN[29 ] . Disp-RCNN是基于实例级视差估计的双目三维目标检测框架,主要由3个部分组成:1)检测每个输入对象的二维边框和实例掩码,2)仅估计属于对象的像素视差,3)使用三维检测器从实例点云中预测出三维边界框. 具体参数使用Disp-RCNN的默认参数,检测网络采用官方提供的预训练模型,再将各种方法增强后的双目图像分别输入检测网络,测试各自检测结果. ...
1
... 进行目标检测实验,对比使用不同方法增强后的图像的目标检测效果. 本实验使用经过亮度暗化处理的低光照KITTI[27 ] 数据集,实现过程是将获取的原始KITTI数据集图像经过Gamma变换[28 ] ,通过调整亮度曲线使图像的亮度变低[2 ] . 这种方法可以模拟类似在低光照条件下获取到的双目低光照图像. 该实验主要考察光照不充分的车辆图像在使用不同方法进行图像增强后,是否可以标出目标车辆的三维检测框. 实验选用KITTI数据集的训练集图像,其中训练图像3 712张、验证图像3 769张,图像大小约为1 224×370像素. 目标检测网络选用Disp-RCNN[29 ] . Disp-RCNN是基于实例级视差估计的双目三维目标检测框架,主要由3个部分组成:1)检测每个输入对象的二维边框和实例掩码,2)仅估计属于对象的像素视差,3)使用三维检测器从实例点云中预测出三维边界框. 具体参数使用Disp-RCNN的默认参数,检测网络采用官方提供的预训练模型,再将各种方法增强后的双目图像分别输入检测网络,测试各自检测结果. ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}