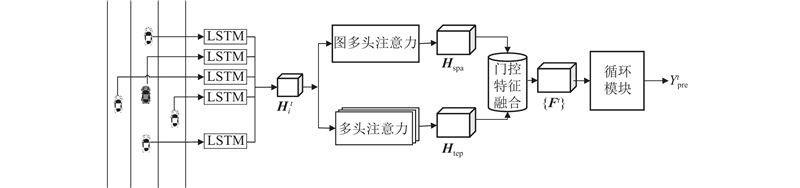
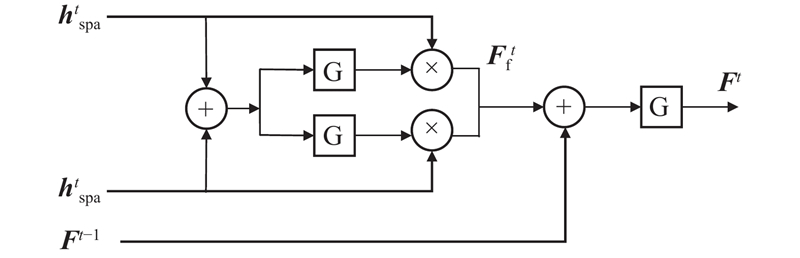
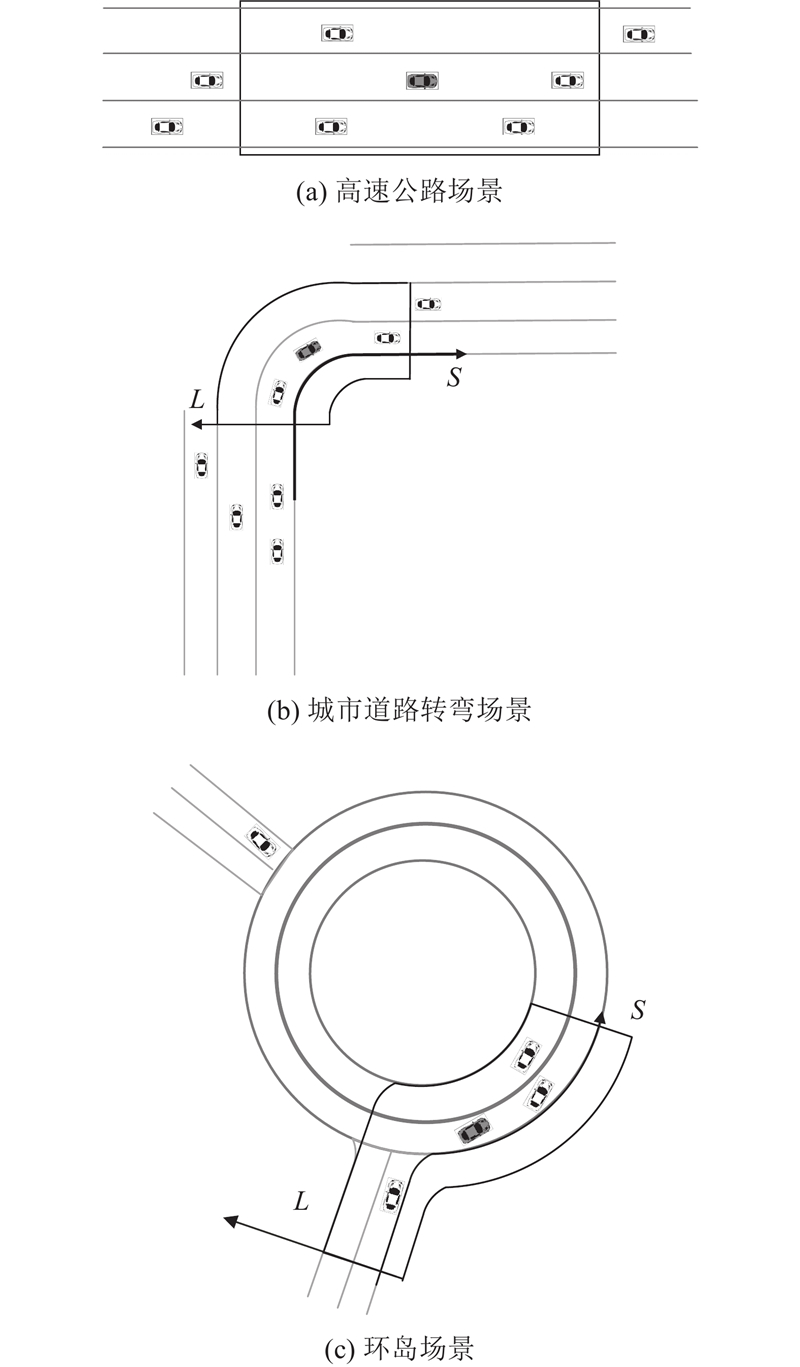
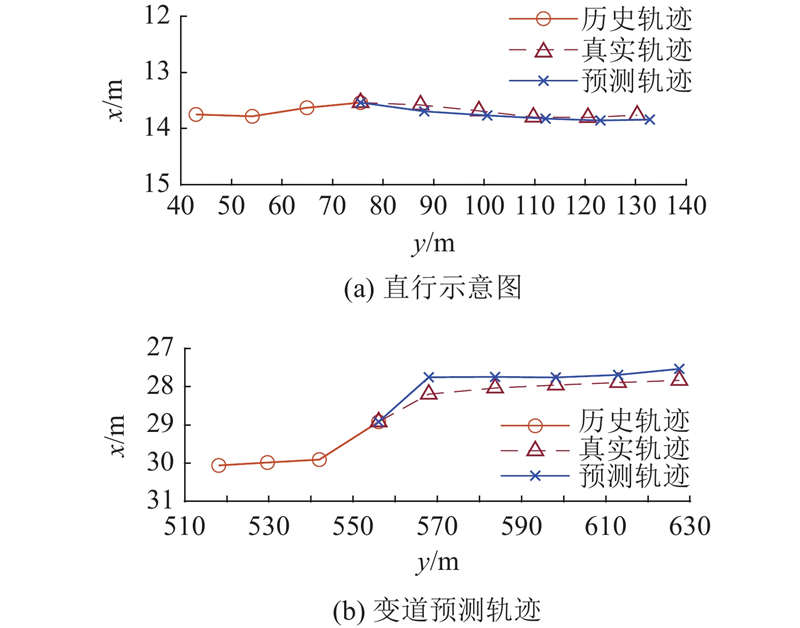
Aiming at the problem that temporal-spatial features affect the trajectory prediction accuracy of autonomous vehicle, a temporal-spatial multi-head attention (TSMHA) vehicle trajectory prediction model was proposed. For the feature information of spatial and temporal dimensions, the multi-head attention mechanism was used to extract the spatial interaction perception and temporal motion pattern of the vehicle. The processed temporal-spatial feature information was transmitted to the gate fusion model for feature fusion, in order to obtain complementary features and remove redundancy. Using the encoder-decoder structure based on long short-term memory (LSTM), future trajectories were recurrently generated considering the potential interaction between trajectories during encoding and decoding. In the training process, the L2 loss function was used to reduce the difference between the predicted trajectory and the ground-truth trajectory. Experimental results show that, compared with the comparison models, the accuracy of the proposed model was improved by 3.95% in the highway, 15.64% in the urban roads, and 31.40% in the roundabout scenario.
ELNAGAR A. Prediction of moving objects in dynamic environments using kalman filters [C]// IEEE International Symposium on Computational Intelligence in Robotics and Automation. New York: IEEE, 2001: 414-419.
ALAHI A, GOEL K, RAMANATHAN V, et al. Social LSTM: human trajectory prediction in crowded spaces [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2016: 961-971.
XIN L, WANG P, CHAN C, et al. Intention-aware long horizon trajectory prediction of surrounding vehicles using dual LSTM networks [C]// 21st International Conference on Intelligent Transportation Systems. New York: IEEE, 2018: 1441-1446.
HOU L, XIN L, LE S E, et al
Interactive trajectory prediction of surrounding road users for autonomous driving using structural-LSTM network
KIM B, KANG C M, KIM J, et al. Probabilistic vehicle trajectory prediction over occupancy grid map via recurrent neural network [C]// IEEE 20th International Conference on Intelligent Transportation Systems. New York: IEEE, 2017: 399-404.
WU Y, CHEN G, LI Z, et al
HSTA: a hierarchical spatio-temporal attention model for trajectory prediction
DEO N, TRIVEDI M M. Convolutional social pooling for vehicle trajectory prediction [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. New York: IEEE, 2018: 1468-1476.
MO X Y, XING Y, LV C. Interaction-aware trajectory prediction of connected vehicles using CNN-LSTM networks [C]// 46th Annual Conference of the IEEE-Industrial- Electronics-Society (IECON). New York: IEEE, 2020: 5057-5062.
MUKHERJEE S, WANG S, WEALLACE A. Interacting vehicle trajectory prediction with convolutional recurrent neural networks [C]// IEEE International Conference on Robotics and Automation. New York: IEEE, 2020: 4336-4342.
GUPTA A, JOHNSON J, LI F F, et al. Social GAN: socially acceptable trajectories with generative Adversarial networks [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2018: 2255-2264.
MNIH V, HEESS N, GRAVES A, et al. Recurrent models of visual attention [C]// 28th Conference on Neural Information Processing Systems. California: NeurIPS, 2014: 2204-2212.
MOHAMED A, QIAN K, ELHOSEINY M, et al. Social-STGCNN: a social spatio-temporal graph convolutional neural network for human trajectory prediction [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. New York: IEEE, 2020: 14412-14420.
YAN S, XIONG Y, LIN D. Spatial temporal graph convolutional networks for skeleton-based action recognition [C]// AAAI Conference on Artificial Intelligence. California: AAAI, 2018, 32(1): 7444-7452.
XUE H, HUYNH D Q, REYNOLDS M
A location-velocity-temporal attention LSTM model for pedestrian trajectory prediction
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// 31st Conference on Neural Information Processing Systems. California: NeurIPS, 2017: 5998-6008.
ZHAO T, XU Y, MONFORT M, et al. Multi-agent tensor fusion for contextual trajectory prediction [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2019: 12118-12126.
SONG H, DING W, CHEN Y, et al. PIP: planning-informed trajectory prediction for autonomous driving [C]// 2020 European Conference on Computer Vision (ECCV 2020). Glasgow: ECCV, 2020: 598-614.


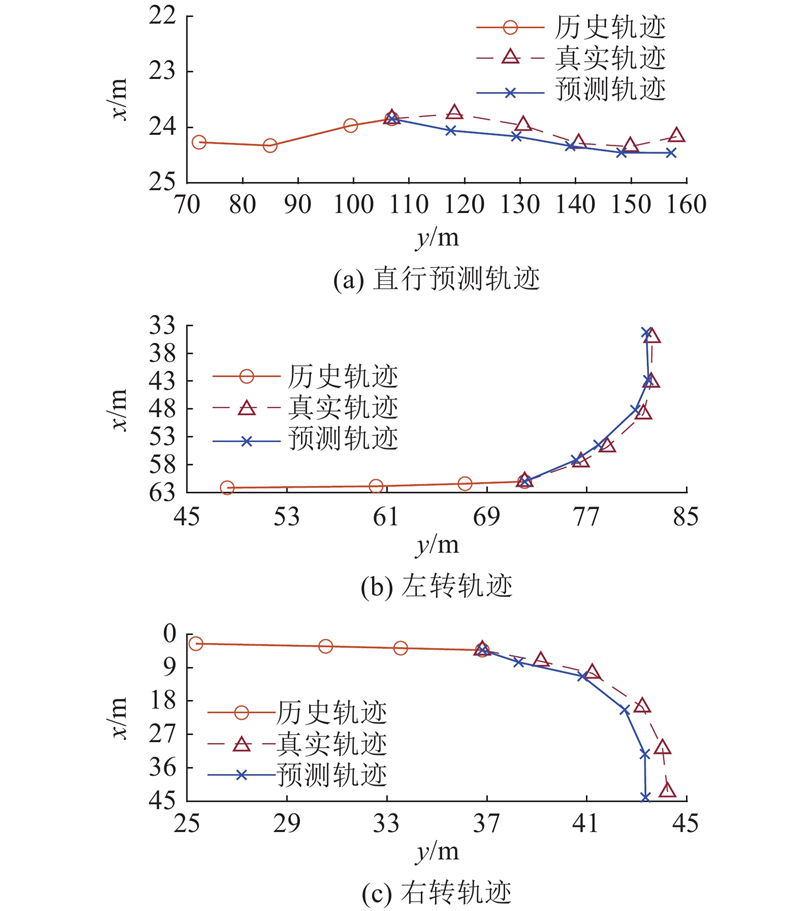



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}