

P300拼写器是通过检测脑电波中的P300成分而搭建的字符输出系统[4]. 它须从大量的背景刺激中识别出含有P300成分的行和列(靶刺激),确定目标字符. 脑电信号具有信噪比低和非平稳性的特点,使得拼写器无法满足实际应用的需求. 研究人员设计了更有效的刺激呈现范式(如行列闪烁、刺激间隔等),以增强人脑对于靶刺激的感知能力[5-7]. 支持向量机(support vector machine, SVM)[8]、线性判别(linear discriminant analysis, LDA)[9]、卷积神经网络(convolution neural network, CNN)[10]等常用算法的应用,提高了P300成分的检测能力.
目前,P300检测方法运用至实际,还面临以下挑战:1)P300成分幅值较低,导致信号识别率较低,须合并多次靶刺激特征识别的结果;2)目前尚缺少大规模数据集,造成复杂的网络模型极易产生过拟合,无法挖掘更深层次的脑电特征.
针对上述问题,本文提出融合Inception网络和注意力机制的EEGNet网络,即IncepA-EEGNet. 考虑到传统的神经网络采用单一尺度的卷积会影响特征提取的能力,Inception模块使用不同卷积核并行,可以在不增加网络层数的条件下,通过多个卷积核提取脑电中的多尺度特征,非常适合脑电这种时域和空间域特征丰富的信号. 并行多个卷积核可以提高分类算法的精度和性能,Zhang等[11-12]将其用于运动想象范式. 考虑到Inception模块尽管给网络模型带来丰富信息,仍无法判断哪些信息对分类更有帮助,本文在Inception模块中进一步融入了注意力机制[13-14]. 它可以自适应地提取原始脑电中时域和空间域信息的重要程度,在较少重复识别的轮次上提高字符识别率,为P300拼写器实用提供可能.
1. 相关工作
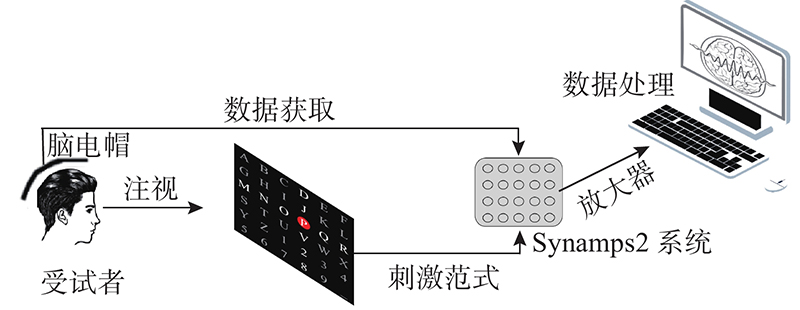
Farwell等[4]提出基于字符矩阵的P300拼写系统,使得人脑信号首次被解码成输出的字符. 该系统中行、列随机闪烁刺激构成了oddball范式. 拼写系统的目的是关注行和列的交叉点对于大脑电位幅值的变化,以发现用户感兴趣的字符. P300拼写器一般由26个字母、9个数字和下划线组成. 在实验过程中,操作人员会给用户呈现一个
图 1

图 2
随着P300信号检测问题研究的不断推进,出现了一些优秀的算法和模型. Rakotomamonjy等[8]提出用SVM分析拼写器的数据,发现枕-顶叶一些区域对分类器有十分重要的贡献. Krusienski等[9]比较4种分类算法,证明了逐步线性判别分析(stepwise linear discriminant analysis,SWLDA)和线性判别分析(linear discriminant analysis, LDA)算法在P300检测中可以获得较好的分类结果. Rivet等[15]提出通过估计空间滤波器(xDAWN)来增强P300诱发电位的无监督算法,将原始脑电图信号投影到估计的信号子空间, 仅重复一次的平均字符正确率接近30%. Xiao等[16]提出判别规范模式匹配算法(discriminative canonical pattern matching, DCPM),在传统算法上获得了不俗的表现.
相对传统的机器学习方法,深度学习方法更善于挖掘高维数据的复杂变化和信号的深层次特征,被广泛应用于脑机接口领域. Cecotti等[10]将7种卷积神经网络(convolution neural network, CNN)用于拼写器中,包括4种单分类器和3种多分类器集成,在多分类器中字符识别率达到较理想的结果. Liu等[17]提出P300信号检测的批归一化的方法,它可以捕获特定的时空特征来提升字符识别性能. 为了防止过拟合,研究人员不断降低网络模型的复杂度,设计轻量级模型, one-dimensional convolutional capsule network (1D-CapsNet)和channel mixing-channel wise-CNN-Ensemble SVM (CM-CW-CNN-ESVM)2种网络模型都得到了较高的字符识别率[18-19]. Lawhern等提出轻量级CNN结构,即EEGNet,该结构被证明对单次P300分类有效. 在小样本下,受试者接收机工作特征曲线下的平均面积高于0.9. 与前人相比,EEGNet在小样本的条件下,利用时序滤波器和空间滤波器,最大可能地挖掘P300信号时空特征,为本研究提供了参考[20].
2. IncepA-EEGNet网络模型
2.1. Inception-v1模块和注意力机制模块
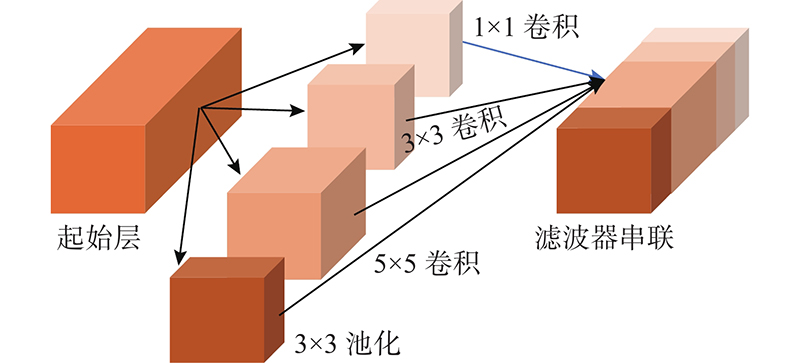
在2014年ImageNet大规模视觉挑战赛上,GoogLeNet取得了冠军. GoogLeNet模型的网络结构深度有22层和500万个参数[21]. 其中的Inception模块起到了至关重要的作用. Inception-v1模块如图3所示,该模块与传统的卷积层、池化层顺序连接不同,它对输入数据分别进行1×1、3×3、5×5等不同的卷积和池化操作,使得网络模型既可以学习到全局信息(3×3、5×5),也可以学习到(1×1)局部信息. 由于Inception-v1模块通过并行卷积层提取同一个输入的特征,在不同的卷积核尺度上进行卷积操作,能够多尺度地提取到P300成分在时域上的信息,避免了分类精度受限于单一尺度卷积核操作的不足.
图 3
2.2. IncepA-EEGNet网络框架
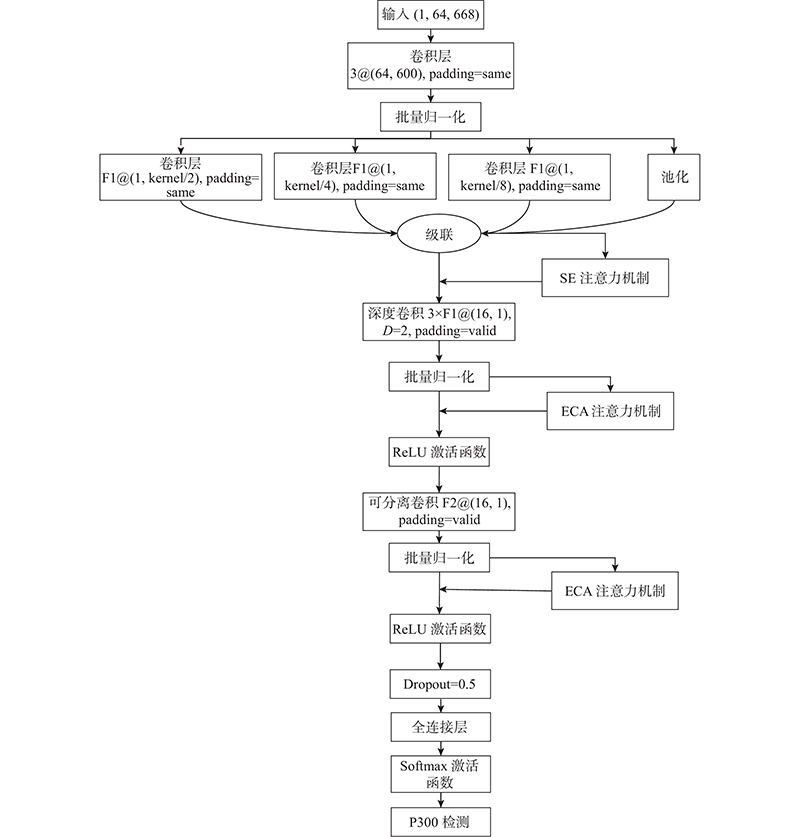
提出的IncepA-EEGNet结合了Inception网络和注意力机制,如图4所示. 图中,F1为第1层时序滤波器的数量,F2为第2层空间滤波器的数量,D为控制每个特征图要学习的空间滤波器的数量,kernel为卷积核大小.
图 4
IncepA-EEGNet网络模型的特点如下.
1)在EEGNet的第1层添加了Inception模块. 它可以同时在多个卷积核上对同一输入进行操作,防止由于串行卷积操作提取到的特征过于简单而引起模型泛化能力降低,通过多尺寸的卷积核提取脑电信号时域上的多尺度信息,从多个分支中学习以下特征:1)具有卷积核大小为 (1, kernel/2) 的卷积分支;2)具有卷积核大小为 (1, kernel/4) 的卷积层分支;3)具有卷积核大小为 (1, kernel) 的卷积层分支;4)具有尺寸大小为 (1, kernel) 的平均池化层分支.
2)使用SE-Attention,结合2.1节的Inception-v1模块,获得对于不同特征的权重. 考虑到Inception网络中使用并行的多尺度卷积核和注意力机制,可以有效地对融合的特征进行选择,减少信息冗余,为后续模型学习重要特征、抑制非重要特征打下基础. SE-Attention网络结合Inception-v1模块如图5所示. 图中,r为注意力机制的降维系数.
图 5
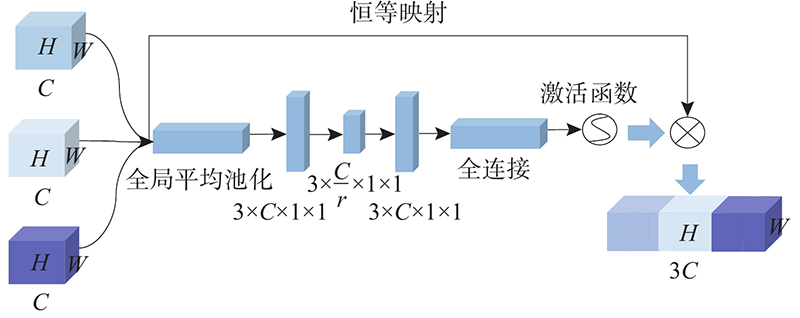
图 5 结合Inception-v1模块的SE注意力机制
Fig.5 SE attention mechanism combined with Inception-v1 module
SE注意力机制对Inception模块后融合特征进行权重分配,使得网络自适应提取重要的时域特征信息用于分类.
3)使用注意力机制提取空间的关键信息. 为了验证EEG通道交互信息对训练网络模型的重要性,使用高效通道注意力机制(ECA-Attention). ECA-Attention用一维卷积来代替SE-Attention第1层的全连接层. 与SE-Attention相比,ECA-Attention的优势在于捕捉到通道之间的局部交互信息,更准确地学习到每个通道对于分类的贡献程度.
3. 实验设计
3.1. P300拼写器数据集和预处理
实验数据集来自BCI Competition III数据集-II
表 1 P300拼写实验数据信息
Tab.1
| 受试者 | 训练集样本数 | 测试集样本数 | |||
| 目标 | 非目标 | 目标 | 非目标 | ||
| 受试者A | 2550 | 12750 | 3000 | 15000 | |
| 受试者B | 2550 | 12750 | 3000 | 15000 | |
对P300拼写器采集到的64通道脑电信号进行预处理. 针对P300信号一般发生在刺激发生300 ms以后的特点,对于一个刺激而言,截取从0 ms到667 ms的脑电信号,包含了足够捕捉到P300成分的全部信息[24]. 使用4阶切比雪夫I型带通滤波器,将原始信号过滤在1~20 Hz截止频率内.
3.2. 字符识别框架
P300拼写器字符识别的整体框架如图6所示. 训练IncepA-EEGNet网络模型;将原始的脑电信号作为网络的输入数据通过深度网络,实现端到端的拼写器字符识别. 在训练阶段,使用公开的数据集对网络模型进行有监督训练,得到IncepA-EEGNet模型的权重参数. 在识别阶段,利用训练阶段得到的网络模型进行P300识别,得到字符识别结果.
图 6
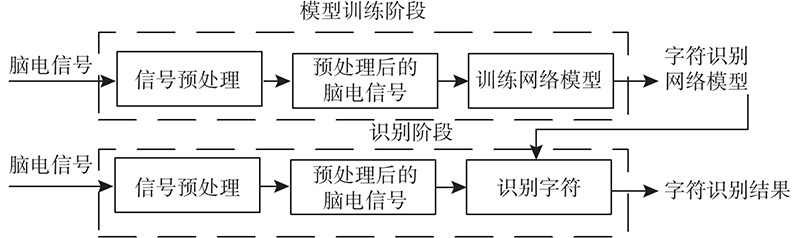
图 6 P300拼写器字符识别的整体框架
Fig.6 Overall framework for P300 speller character recognition
3.3. 评价指标
由于IncepA-EEGNet可以看作是深度网络分类器,分别从分类器指标和用于P300拼写器的评价标准2个角度来介绍.
3.3.1. 分类器指标
使用准确率Acc、精准率P、召回率R和F1分数F1,评估提出方法的分类性能.
式中:
3.3.2. 拼写器指标
使用字符识别正确率
式中:
其中n为训练轮次.
3.4. 参数选择
3.4.1. 对Inception卷积核的选择
表 2 IncepA-EEGNet使用不同卷积核参数K的分类结果
Tab.2
| 受试者 | K | 卷积核大小 | Acc | R | P | F1 |
| A | 8 | (8/4/2,1) | 0.7323 | 0.6630 | 0.3432 | 0.4523 |
| A | 16 | (16/8/4,1) | 0.7384 | 0.6547 | 0.3485 | 0.4548 |
| A | 32 | (32/16/8,1) | 0.7425 | 0.6486 | 0.3520 | 0.4564 |
| A | 64 | (64/32/16,1) | 0.7314 | 0.6677 | 0.3430 | 0.4532 |
| A | 128 | (128/64/32,1) | 0.7553 | 0.6457 | 0.3670 | 0.4679 |
| A | 160 | (160/80/40,1) | 0.7514 | 0.6210 | 0.3582 | 0.4543 |
| B | 8 | (8/4/2,1) | 0.7817 | 0.7034 | 0.4122 | 0.5149 |
| B | 16 | (16/8/4,1) | 0.7855 | 0.7186 | 0.4168 | 0.5276 |
| B | 32 | (32/16/8,1) | 0.7848 | 0.7143 | 0.4154 | 0.5253 |
| B | 64 | (64/32/16,1) | 0.7899 | 0.6993 | 0.4215 | 0.5260 |
| B | 128 | (128/64/32,1) | 0.7914 | 0.7250 | 0.4261 | 0.5367 |
| B | 160 | (160/80/40,1) | 0.7889 | 0.6987 | 0.4199 | 0.5245 |
从表2可以发现,当K=128时,可以获得较好的准确率,其中受试者A的准确率为75.53%,受试者B的准确率为79.14%. 除受试者A的召回率较低外,召回率为64.57%,所有指标都在K = 128时取得较好的结果. 本文中Inception卷积核大小取128.
3.4.2. 注意力机制降维系数选择
注意力机制中间层是信息传输的纽带,将原有的信息压缩后,再通过下一个全连接层,将信息释放掉. 降维系数越大,信息压缩越多,则可以释放的信息越抽象;降维系数较小,信息压缩过少,信息存在冗余,影响网络的效率,因此选择适当的降维系数是至关重要的[26].
如表3所示,当r = 3时,可以获得较好的准确率. 在后面的实验中使用的降维系数为3.
表 3 注意力机制使用不同降维系数的分类结果
Tab.3
| 受试者 | r | Acc | R | P | F1 |
| A | 1 | 0.7458 | 0.6473 | 0.3557 | 0.4592 |
| A | 3 | 0.7553 | 0.6457 | 0.3670 | 0.4679 |
| A | 9 | 0.7425 | 0.6486 | 0.3520 | 0.4610 |
| A | 12 | 0.7314 | 0.6683 | 0.3430 | 0.4533 |
| B | 1 | 0.7869 | 0.7227 | 0.4193 | 0.5307 |
| B | 3 | 0.7914 | 0.7250 | 0.4261 | 0.5367 |
| B | 9 | 0.7954 | 0.6880 | 0.4291 | 0.5285 |
| B | 12 | 0.7829 | 0.7133 | 0.4125 | 0.5227 |
4. 实验结果
提出的IncepA-EEGNet网络基于TensorFlow实现,使用 NVIDIA RTX2080Ti 进行训练. 损失函数使用交叉熵函数(cross entropy loss),采用随机梯度下降(adaptive moment estimation, Adam)方法对模型进行训练,初始学习率为 0.0005,模型训练周期为100,批处理次数为64,网络训练的过程如图7所示. 图中,Loss为训练损失,E为训练迭代周期.
图 7
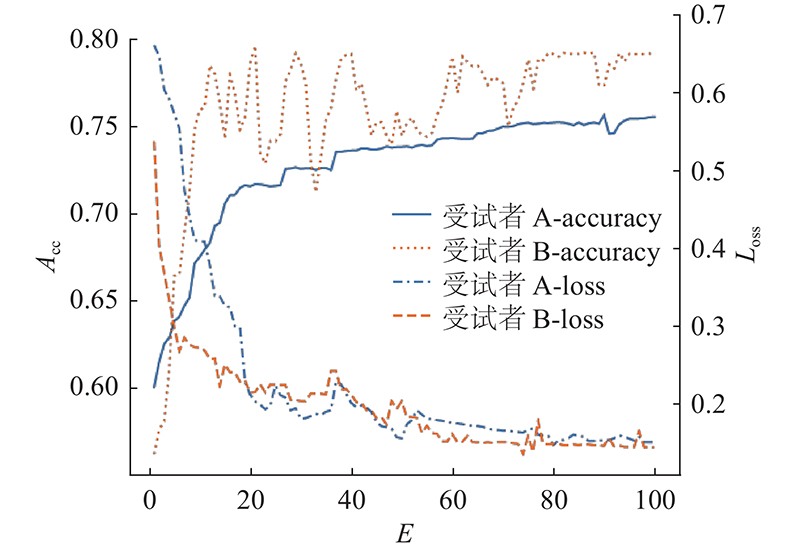
图 7 IncepA-EEGNet训练损失和测试准确率
Fig.7 Training loss and test accuracy on IncepA-EEGNet
4.1. 比较子模块对P300信号分类网络模型的影响
表 4 不同CNN网络添加子模块对分类准确率的影响
Tab.4
| 添加模块 | Acc | ||||
| 受试者 | CNN-1 | MCNN-1 | MCNN-3 | EEGNet | |
| 基础网络(Net) | A | 0.7037 | 0.6899 | 0.7038 | 0.7065 |
| 基础网络(Net) | B | 0.7065 | 0.6912 | 0.7037 | 0.7266 |
| Net+Attention | A | 0.7092 | 0.6906 | 0.7091 | 0.7141 |
| Net+Attention | B | 0.7185 | 0.7154 | 0.7192 | 0.7399 |
| Net+Inception-v1 | A | 0.7100 | 0.6965 | 0.7103 | 0.7174 |
| Net+Inception-v1 | B | 0.7222 | 0.7276 | 0.7203 | 0.7476 |
| Net+Attention +Inception-v1 | A | 0.7186 | 0.7084 | 0.7258 | 0.7553 |
| Net+Attention +Inception-v1 | B | 0.7454 | 0.7384 | 0.7478 | 0.7914 |
4.2. 比较不同深度学习方法在P300信号分类上的表现
如表5所示, IncepA-EEGNet模型的准确率的均值是77.35%,略高于现阶段表现结果最好的BN3网络,且大幅度优于其他几种为 P300 设计的网络. 在召回率上,IncepA-EEGNet保持了较高的水平,特别是在受试者 B 上的表现. 虽然是不平衡数据,但算法在精准度方面,达到了对比方法中的最高水平. 2位被试者在F1上的表现,比在BN3上分别提高了0.74% 和1.21%.
表 5 在P300信号分类上IncepA-EEGNet与其他深度学习方法的比较
Tab.5
| 方法 | 受试者 | Acc | R | P | F1 |
| CNN-1[10] | A | 0.7037 | 0.6737 | 0.3170 | 0.4311 |
| CNN-1[10] | B | 0.7065 | 0.6783 | 0.4073 | 0.5090 |
| MCNN-1[10] | A | 0.6899 | 0.6903 | 0.3085 | 0.4260 |
| MCNN-1[10] | B | 0.6912 | 0.7340 | 0.3833 | 0.5034 |
| MCNN-3[10] | A | 0.7038 | 0.6743 | 0.3172 | 0.4314 |
| MCNN-3[10] | B | 0.7037 | 0.6923 | 0.4089 | 0.5141 |
| EEGNet[20] | A | 0.7065 | 0.6460 | 0.3147 | 0.4232 |
| EEGNet[20] | B | 0.7266 | 0.6950 | 0.4214 | 0.4587 |
| BN3[17] | A | 0.7513 | 0.6133 | 0.3607 | 0.4605 |
| BN3[17] | B | 0.7902 | 0.6947 | 0.4214 | 0.5246 |
| IncepA-EEGNet | A | 0.7553 | 0.6456 | 0.3676 | 0.4679 |
| IncepA-EEGNet | B | 0.7914 | 0.7250 | 0.4261 | 0.5367 |
4.3. 字符传输速率
如图8所示为不同模型的信息传输率对比折线图. 图中,ITR为信息传输速率.
图 8
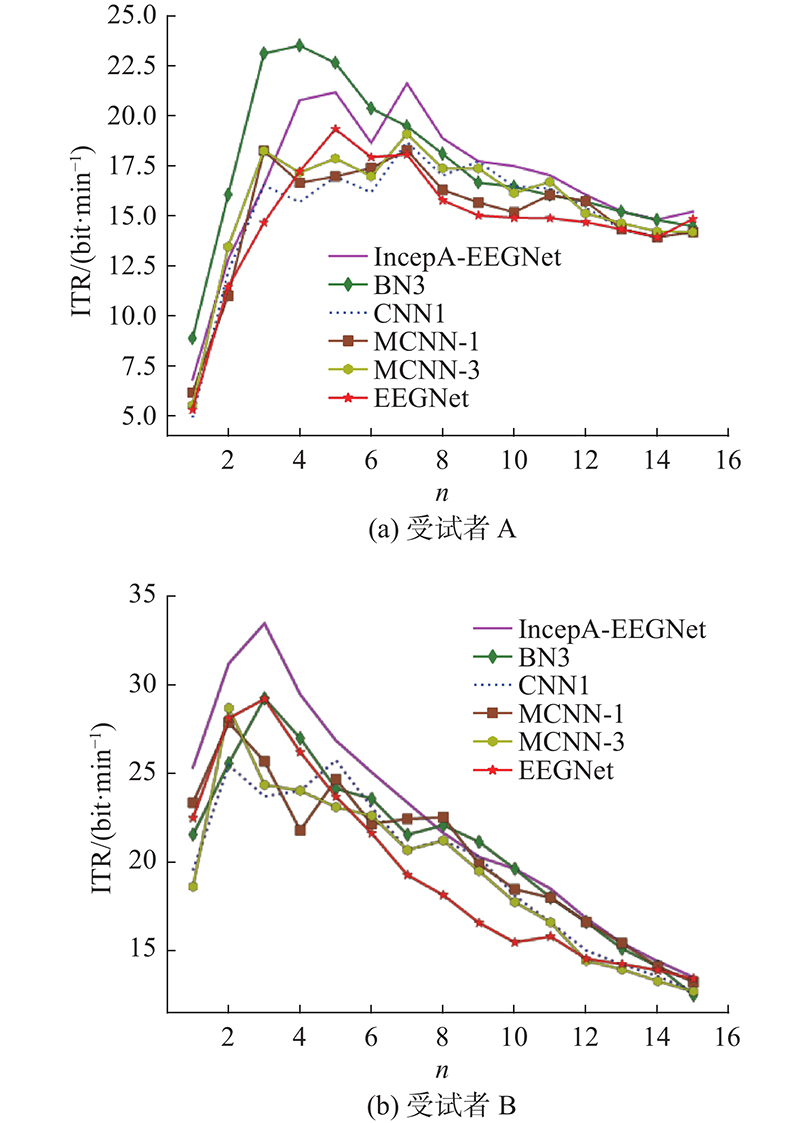
图 8 IncepA-EEGNet模型与其他方法在受试者A和受试者B上的信息传输速率对比
Fig.8 Comparison of information transfer rate of IncepA-EEGNet model with other methods on subject A and subject B
如图8所示,在受试者A 的首次刺激中, IncepA-EEGNet 模型的信息传输速率提升速度不如BN3 模型. 与其他4个深度学习方法相比,IncepA-EEGNet模型在第7次重复刺激之后,最高传输速率为21.59 bit/min. 在受试者 B 上,IncepA-EEGNet 模型在第 3次重复刺激后达到最高水平,即33.44 bit/min,并在后面的轮次中一直保持较高的信息传输速率. 综上所述,这证明了IncepA-EEGNet 模型在信息传输速率上的性能优于其他对比方法.
4.4. 字符识别率
将本文算法与其他7种P300识别算法进行对比,如表6所示.
表 6 IncepA-EEGNet 模型与其他方法的字符识别率
Tab.6
| 方法 | 受试者 | Pc/% | |||||||||||||||
| n = 1 | n = 2 | n = 3 | n = 4 | n = 5 | n = 6 | n = 7 | n = 8 | n = 9 | n = 10 | n = 11 | n = 12 | n = 13 | n = 14 | n = 15 | |||
| CNN-1[10] | A | 16 | 33 | 47 | 52 | 61 | 65 | 77 | 78 | 85 | 86 | 90 | 91 | 91 | 93 | 97 | |
| CNN-1[10] | B | 35 | 52 | 59 | 68 | 79 | 81 | 82 | 89 | 92 | 91 | 91 | 90 | 91 | 92 | 92 | |
| MCNN-1[10] | A | 18 | 31 | 50 | 54 | 61 | 68 | 76 | 76 | 79 | 82 | 89 | 92 | 91 | 93 | 97 | |
| MCNN-1[10] | B | 39 | 55 | 62 | 64 | 77 | 79 | 86 | 92 | 91 | 92 | 95 | 95 | 95 | 94 | 94 | |
| MCNN-3[10] | A | 17 | 35 | 50 | 55 | 63 | 67 | 78 | 79 | 84 | 85 | 91 | 90 | 92 | 94 | 97 | |
| MCNN-3[10] | B | 34 | 56 | 60 | 68 | 74 | 80 | 82 | 89 | 90 | 90 | 91 | 88 | 90 | 91 | 92 | |
| BN3[17] | A | 22 | 39 | 58 | 67 | 73 | 75 | 79 | 81 | 82 | 86 | 89 | 92 | 94 | 96 | 98 | |
| BN3[17] | B | 47 | 59 | 70 | 73 | 76 | 82 | 84 | 91 | 94 | 95 | 95 | 95 | 94 | 94 | 95 | |
| EEGNet[20] | A | 18 | 33 | 46 | 60 | 68 | 70 | 82 | 82 | 83 | 85 | 88 | 90 | 91 | 96 | 99 | |
| EEGNet[20] | B | 39 | 49 | 56 | 65 | 76 | 80 | 85 | 87 | 89 | 89 | 90 | 90 | 90 | 92 | 93 | |
| 1D-CapsNet-64[18] | A | 21 | 32 | 45 | 53 | 60 | 68 | 76 | 83 | 85 | 84 | 82 | 88 | 94 | 96 | 98 | |
| 1D-CapsNet-64[18] | B | 48 | 54 | 60 | 66 | 75 | 81 | 81 | 86 | 87 | 93 | 93 | 93 | 92 | 93 | 94 | |
| CM-CW-CNN-ESVM[19] | A | 22 | 32 | 55 | 59 | 64 | 70 | 74 | 78 | 81 | 86 | 86 | 90 | 91 | 94 | 99 | |
| CM-CW-CNN-ESVM[19] | B | 37 | 58 | 70 | 72 | 80 | 86 | 86 | 89 | 93 | 95 | 95 | 97 | 97 | 98 | 99 | |
| IncepA-EEGNet | A | 19 | 34 | 47 | 62 | 70 | 71 | 84 | 83 | 85 | 89 | 92 | 93 | 94 | 96 | 100 | |
| IncepA-EEGNet | B | 41 | 59 | 73 | 77 | 81 | 85 | 88 | 90 | 92 | 95 | 95 | 95 | 95 | 95 | 95 | |
从表6可知,IncepA-EEGNet模型在受试者 A 上的表现较好,当实验次数超过第7次重复刺激后,字符识别率超过了其他网络模型,识别率达到84%. 在受试者 B 上,该网络在第3次重复刺激后达到最高的字符识别率,识别率为73%,并在后续的重复实验中保持最高的识别率. 在经过第5次重复刺激后,IncepA-EEGNet模型在2个被试上的字符识别率平均为75.5%. CM-CW-CNN-ESVM网络模型[19]在最后第14次和第15次重复刺激更好,这主要是该网络采用了类别平衡的预处理方式,提高了识别率. IncepA-EEGNet使用不平衡的数据输入,与CM-CW-CNN-ESVM算法相比,提出的IncepA-EEGNet模型仅在较少次的重复刺激后就可以实现更高的识别率. 实验结果表明,IncepA-EEGNet可以在真实环境中减少字符重复次数,提高P300拼写器的打字速度,提升用户的舒适程度和良好体验.
4.5. 局限性
比较不同方法在字符识别率和字符传输速率上的表现. 可知,提出的算法与BN3、CNN-1、MCNN-1和MCNN-3相比,在Competition III 数据集-II上取得了较好的效果,但有一些字符出现了混淆. 如表7所示,IncepA-EEGNet在某些字符上出现了混淆.
表 7 P300拼写器的字符识别混淆
Tab.7
| 受试者 | 字符编号 | 期望字符 | 输出字符 |
| A | 16 | P | Q |
| B | 24 | Q | P |
| B | 39 | V | W |
| B | 10 | Z | H |
这些字符混淆主要是由拼写器的闪烁刺激排列导致的,例如字符“P”和“Q”是在同一行或者像字符“Z”和“H”是在同一列. 设计更加新式的闪烁刺激范式,提高拼写器的识别效率.
比较EEGNet添加不同子模块的网络训练参数量,如表8所示. 可知,IncepA-EEGNet的训练参数量远远多于EEGNet,这使得IncepA-EEGNet网络模型识别字符的时间比EEGNet长. 进一步的研究方向是提高网络的运算速度.
表 8 EEGNet添加不同子模块后的网络训练参数量
Tab.8
| 方法 | 参数量 |
| EEGNet | 5428 |
| EEGNet+Attention | 8969 |
| EEGNet+Inception-v1 | 12742 |
| IncepA-EEGNet | 22970 |
5. 结 语
提出基于融合Inception网络和注意力机制的P300检测方法−IncepA-EEGNet. 使用Inception网络,实现不同感受野特征图的组合,更好地挖掘P300信号在时域上的可区分性特征;通过注意力机制对重要特征信息进行加强,提取到P300信号在时间域和空间域上更有效的信息. 该模型网络在公开数据集Competition III上得到验证. 结果表明,与其他应用在P300拼写器上的深度学习方法相比,IncepA-EEGNet具有较高的字符识别率和信息传输速率,可以提高P300拼写器的实用性能.
参考文献
Operation of a P300-based brain–computer interface by individuals with cervical spinal cord injury
[J].DOI:10.1016/j.clinph.2010.08.021 [本文引用: 1]
On the relationship between attention processing and P300-based brain computer interface control in amyotrophic lateral sclerosis
[J].
Talking off the top of your head: toward a mental prosthesis utilizing event-related brain potentials
[J].DOI:10.1016/0013-4694(88)90149-6 [本文引用: 2]
基于 P300 的交互式字符输入脑机接口系统
[J].DOI:10.3969/j.issn.1000-7024.2014.04.051 [本文引用: 1]
P300-based interactive character input brain-computer interface system
[J].DOI:10.3969/j.issn.1000-7024.2014.04.051 [本文引用: 1]
A visual parallel-BCI speller based on the time–frequency coding strategy
[J].
BCI competition III: dataset II-ensemble of SVMs for BCI P300 speller
[J].DOI:10.1109/TBME.2008.915728 [本文引用: 2]
A comparison of classification techniques for the P300 speller
[J].
Convolutional neural networks for p300 detection with application to brain computer interfaces
[J].
EEG-inception: an accurate and robust end-to-end neural network for EEG-based motor imagery classification
[J].
Epileptic seizure detection in EEG signals using a unified temporal-spectral squeeze-and-excitation network
[J].DOI:10.1109/TNSRE.2020.2973434 [本文引用: 1]
基于多尺度特征提取与挤压激励模型的运动想象分类方法
[J].DOI:10.7544/issn1000-1239.2020.20200723 [本文引用: 1]
Motor imagery classification based on multiscale feature extraction and squeeze-excitation model
[J].DOI:10.7544/issn1000-1239.2020.20200723 [本文引用: 1]
xDAWN algorithm to enhance evoked potentials: application to brain–computer interface
[J].DOI:10.1109/TBME.2009.2012869 [本文引用: 1]
Discriminative canonical pattern matching for single-trial classification of ERP components
[J].
Deep learning based on batch normalization for P300 signal detection
[J].DOI:10.1016/j.neucom.2017.08.039 [本文引用: 6]
P300 event-related potential detection using one-dimensional convolutional capsule networks
[J].
P300 based character recognition using convolutional neural network and support vector machine
[J].
EEGNet: a compact convolutional network for EEG-based brain-computer interfaces
[J].
Multi-receptive-field CNN for semantic segmentation of medical images
[J].DOI:10.1109/JBHI.2020.3016306 [本文引用: 1]
A new intelligent bearing fault diagnosis method using SDP representation and SE-CNN
[J].
Attention is all you need
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}