[1]
王世峰, 戴祥, 徐宁 无人驾驶汽车环境感知技术综述
[J]. 长春理工大学学报: 自然科学版 , 2017 , 40 (1 ): 1 - 6
URL
[本文引用: 1]
WANG Shi-feng, DAI Xiang, XU Ning Overview of driverless car environment perception technology
[J]. Journal of Changchun University of Science and Technology: Natural Science Edition , 2017 , 40 (1 ): 1 - 6
URL
[本文引用: 1]
[2]
李玺, 查宇飞, 张天柱 深度学习的目标跟踪算法综述
[J]. 中国图象图形学报 , 2019 , 24 (12 ): 2057 - 2080
DOI:10.11834/jig.190372
[本文引用: 1]
LI Xi, ZHA Yu-fei, ZHANG Tian-zhu Overview of deep learning target tracking algorithms
[J]. Chinese Journal of Image and Graphics , 2019 , 24 (12 ): 2057 - 2080
DOI:10.11834/jig.190372
[本文引用: 1]
[3]
储琪. 基于深度学习的视频多目标跟踪算法研究[D]. 合肥: 中国科学技术大学, 2019.
[本文引用: 1]
CHU Qi. Research on video multi-target tracking algorithm based on deep learning[D]. Hefei: University of Science and Technology of China, 2019.
[本文引用: 1]
[4]
KIM C, LI F, CIPTADI A, et al. Multiple hypothesis tracking revisited[C]// Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 4696–4704.
[本文引用: 4]
[5]
HU H, ZHOU L, GUAN Q, et al An automatic tracking method for multiple cells based on multi-feature fusion
[J]. IEEE Access , 2018 , 6 : 69782 - 69793
DOI:10.1109/ACCESS.2018.2880563
[本文引用: 2]
[6]
LEAL-TAIXÉ L, FERRER C C, SCHINDLER K. Learning by tracking: siamese CNN for robust target association[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops . Las Vegas: IEEE, 2016: 33–40.
[本文引用: 1]
[7]
ZHOU H, OUYANG W, CHENG J, et al Deep continuous conditional random fields with asymmetric inter-object constraints for online multi-object tracking
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2018 , 29 (4 ): 1011 - 1022
[本文引用: 1]
[8]
ULLAH M, MOHAMMED A K, CHEIKH F A, et al. A hierarchical feature model for multi-target tracking[C]// Proceedings of the 2017 IEEE International Conference on Image Processing . Beijing: IEEE, 2017: 2612–2616.
[本文引用: 1]
[9]
SHARMA S, ANSARI J A, MURTHY J K, et al. Beyond pixels: Leveraging geometry and shape cues for online multi-object tracking[C]// Proceedings of the 2018 IEEE International Conference on Mechatronics , Robotics and Automation . Brisbane: IEEE, 2018: 3508–3515.
[本文引用: 1]
[10]
CHU Q, OUYANG W, LI H, et al. Online multi-object tracking using CNN-based single object tracker with spatial-temporal attention mechanism[C]// 2017 IEEE International Conference on Computer Vision . Venie: IEEE, 2017: 4836–4845.
[本文引用: 1]
[11]
MILAN A, REZATOFIGHI S H, DICK A, et al. Online multi-target tracking using recurrent neural networks[C]// National Conference on Artificial Intelligence . San Francisco: AAAI Press, 2017: 4225-4232.
[本文引用: 1]
[12]
MA C, YANG C, YANG F, et al. trajectory factory: tracklet cleaving and re-connection by deep siamese bi-GRU for multiple object tracking[C]// 2018 IEEE International Conference on Multimedia and Expo . San Diego: IEEE, 2018: 1-6.
[本文引用: 1]
[13]
ZHU J, YANG H, LIU N, et al. Online multi-object tracking with dual matching attention networks[C]// 2018 European Conference on Computer Vision . Munich: [s. n.], 2018: 366–382.
[本文引用: 1]
[14]
WOJKE N, BEWLEY A, PAULUS D. Simple online and real time tracking with a deep association metric[C]// 2017 IEEE International Conference on Image Processing . [S. l.]: IEEE, 2017: 3645-3649.
[本文引用: 1]
[15]
解耘宇. 基于扩展卡尔曼滤波的单目视觉轨迹跟踪方法的研究[D]. 北京: 华北电力大学, 2017.
[本文引用: 1]
XIE Yun-yu. Research on monocular vision trajectory tracking method based on extended Kalman filter[D]. Beijing: North China Electric Power University, 2017.
[本文引用: 1]
[16]
BISHOP C M. Pattern recognition and machine learning (information science and statistics) [M]. New York: Springer, 2006.
[本文引用: 1]
[17]
WOJKE N, BEWLEY A. Deep cosine metric learning for person re-identification[C]// IEEE Winter Conference on Applications of Computer Vision . Lake Tahoe: IEEE, 2018: 748-756.
[本文引用: 1]
[18]
KRIZHEVSKY A, SUTSKEVER I, HINTON G E Imagenet classification with deep convolutional neural networks
[J]. Communications of the ACM , 2017 , 60 (6 ): 84 - 90
DOI:10.1145/3065386
[本文引用: 1]
[19]
ZAGORUYKO S, KOMODAKIS N. Wide residual networks [C]// 2016 Proceedings of the British Machine Vision Conference . York: DBLP, 2016: 1-15.
[本文引用: 1]
[20]
WEN Y, ZHANG K, LI Z, et al. A discriminative feature learning approach for deep face recognition[C]// European Conference on Computer Vision . Amsterdam: Springer, 2016: 499-515.
[本文引用: 1]
[21]
CHARU C A. Neural networks and deep learning [M]. Cham: Springer, 2018: 48-51.
[本文引用: 1]
[22]
刘鑫辰. 城市视频监控网络中车辆搜索关键技术研究[D]. 北京: 北京邮电大学, 2018.
[本文引用: 1]
LIU Xin-chen. Research on key technologies of vehicle search in urban video surveillance network[D]. Beijing: Beijing University of Posts and Telecommunications, 2018.
[本文引用: 1]
[23]
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 1]
[24]
LIN T Y, DOLLAR P, GIRSHICK R. Feature pyramid networks for object detection[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 936-944.
[本文引用: 1]
[25]
REDMON J, FARHADI A. YOLO v3: an incremental improvement [EB/OL]. [2020-05-31]. https://arxiv.org/abs/1804.02767.
[本文引用: 1]
[26]
CHOI J, CHUN D, KIM H. Gaussian YOLO v3: an accurate and fast object detector using localization uncertainty for autonomous driving[C]// International Conference on Computer Vision . Seoul: IEEE, 2019: 502-511.
[本文引用: 1]
[27]
BEWLEY A, GE Z, OTT L, et al. Simple online and realtime tracking[C]// International Conference on Image Processing . Phoenix: IEEE, 2016: 3464-3468.
[本文引用: 4]
无人驾驶汽车环境感知技术综述
1
2017
... 环境感知通过相机、毫米波雷达、激光雷达以及超声波雷达等传感器实现对无人驾驶车辆周边环境信息的理解,是无人驾驶的关键技术[1 ] . 基于深度学习的视觉多目标跟踪是目前环境感知中的重要技术之一,可通过提取车辆周边目标的深度特征对感兴趣目标进行稳定准确的跟踪,解决目标检测中信息不连续的问题[2 ] . ...
无人驾驶汽车环境感知技术综述
1
2017
... 环境感知通过相机、毫米波雷达、激光雷达以及超声波雷达等传感器实现对无人驾驶车辆周边环境信息的理解,是无人驾驶的关键技术[1 ] . 基于深度学习的视觉多目标跟踪是目前环境感知中的重要技术之一,可通过提取车辆周边目标的深度特征对感兴趣目标进行稳定准确的跟踪,解决目标检测中信息不连续的问题[2 ] . ...
深度学习的目标跟踪算法综述
1
2019
... 环境感知通过相机、毫米波雷达、激光雷达以及超声波雷达等传感器实现对无人驾驶车辆周边环境信息的理解,是无人驾驶的关键技术[1 ] . 基于深度学习的视觉多目标跟踪是目前环境感知中的重要技术之一,可通过提取车辆周边目标的深度特征对感兴趣目标进行稳定准确的跟踪,解决目标检测中信息不连续的问题[2 ] . ...
深度学习的目标跟踪算法综述
1
2019
... 环境感知通过相机、毫米波雷达、激光雷达以及超声波雷达等传感器实现对无人驾驶车辆周边环境信息的理解,是无人驾驶的关键技术[1 ] . 基于深度学习的视觉多目标跟踪是目前环境感知中的重要技术之一,可通过提取车辆周边目标的深度特征对感兴趣目标进行稳定准确的跟踪,解决目标检测中信息不连续的问题[2 ] . ...
1
... 基于深度学习的视觉多目标跟踪的方法一般可分为两类,一类是联合单目标跟踪器的多目标跟踪,另一类是基于目标检测的多目标跟踪[3 ] . 前者为每一个被跟踪的目标单独分配一个跟踪器,充分利用单目标跟踪的先进技术特点,提高多目标跟踪的准确度,但是在驾驶视角下车辆发生遮挡时,检测容易产生飘移现象;后者通过目标检测算法结合数据关联优化算法实现,是目前基于深度学习视觉多目标跟踪的主流算法,其效果对目标检测算法的检测效果与特征区分性有一定的依赖性. ...
1
... 基于深度学习的视觉多目标跟踪的方法一般可分为两类,一类是联合单目标跟踪器的多目标跟踪,另一类是基于目标检测的多目标跟踪[3 ] . 前者为每一个被跟踪的目标单独分配一个跟踪器,充分利用单目标跟踪的先进技术特点,提高多目标跟踪的准确度,但是在驾驶视角下车辆发生遮挡时,检测容易产生飘移现象;后者通过目标检测算法结合数据关联优化算法实现,是目前基于深度学习视觉多目标跟踪的主流算法,其效果对目标检测算法的检测效果与特征区分性有一定的依赖性. ...
4
... 深度学习具有强大的特征提取与表达能力,可提取深度视觉特征,完成目标分类与检测. Kim等[4 ] 首次将深度特征应用于目标跟踪,预训练卷积神经网络(convolutional neural networks,CNN),提取视觉深度特征与多假设跟踪算法进行结合,充分利用多假设跟踪(multiple hypothesis tracking,MHT)算法开发高阶信息的优点,对于每一个跟踪假设,引入在线外观训练模型,将MOT15成绩提升3%. Hu等[5 ] 建立能够区分动静目标的算法,对动目标使用由基于VGG-16的Faster R-CNN提取的运动特征与视觉特征关联,并通过跟踪步骤微调,实现对错误中断轨迹的重新关联,降低漏检率与误检率. Leal-Taixé等[6 ] 提出孪生网络,使用算法学习到最具代表性的特征区分目标,并使用相似性分数衡量检测结果,而后使用线性规划求解数据关联结果. Zhou等[7 ] 提出视觉位移CNN网络,对目标下一帧的位置进行预测,以及对其他目标的影响;可从预测位置和实际检测中提取视觉信息以计算相似度得分. Ullah等[8 ] 使用浅层Inception,利用正交匹配追踪对提取特征进行降维,构建跟踪目标特征字典. 在测试阶段,构建成本矩阵,结合卡尔曼滤波器提取的视觉和运动信息,以匈牙利算法进行数据关联. Sharma等[9 ] 利用单目摄像头获取的目标姿势、形状、位置等3D信息构建代价函数,可解决基于检测的多目标跟踪中可能出现的关联错误. Chu等[10 ] 提出堆叠CNN模型,采用第一个CNN模块提取场景中目标特征,对每个候选目标进行感兴趣区域(region of interest,RoI)特征提取;对于被跟踪的目标,使用第二个在线训练CNN模块进行候选目标的可见性图和空间注意力图提取,在特征细化后使用贪婪算法进行数据关联. Milan等[11 ] 将深度网络应用于相似度计算,以循环神经网络(recurrent neural network,RNN)为主跟踪器,利用长短时记忆网络(long short term memory,LSTM)具有良好记忆状态的特点弥补了RNN因梯度下降只能记住短期数据的不足. Ma等[12 ] 提出孪生双向门控循环单元(gated recurrent unit,GRU)网络实现多目标跟踪,利用CNN和RNN提取的对象特征创建轨迹候选,选取可信度高的候选轨迹生成轨迹. Zhu等[13 ] 提出具有时间和空间双注意力机制的双匹配注意网络,使用高效卷积算子跟踪器,对遮挡后恢复的目标进行重识别训练. ...
... Comparison of MOTA and MOTP for multi-objective tracking algorithms
Tab.2 算法 MOTA MOTP Unsup Track[4 ] 61.7 78.3 Lif-T[4 ] 60.5 79.0 ISE-MOT17R[4 ] 60.1 78.2 msot[5 ] 59.2 78.0 EAMTT[27 ] 52.5 78.8 POI[27 ] 66.1 77.1 SORT[27 ] 59.8 79.6 基准DeepSort[27 ] 61.4 79.1 本文算法 62.5 78.9
3. 结 论 (1)基于Gaussian YOLO v3的前方车辆跟踪算法,充分利用检测器强大的目标检测分类能力,结合车辆Re-ID优化后的DeepSort算法,对实际交通场景下的车辆多目标进行在线跟踪,与流行多目标跟踪算法相比,具有良好的跟踪精确率与准确率. ...
... [
4 ]
60.5 79.0 ISE-MOT17R[4 ] 60.1 78.2 msot[5 ] 59.2 78.0 EAMTT[27 ] 52.5 78.8 POI[27 ] 66.1 77.1 SORT[27 ] 59.8 79.6 基准DeepSort[27 ] 61.4 79.1 本文算法 62.5 78.9 3. 结 论 (1)基于Gaussian YOLO v3的前方车辆跟踪算法,充分利用检测器强大的目标检测分类能力,结合车辆Re-ID优化后的DeepSort算法,对实际交通场景下的车辆多目标进行在线跟踪,与流行多目标跟踪算法相比,具有良好的跟踪精确率与准确率. ...
... [
4 ]
60.1 78.2 msot[5 ] 59.2 78.0 EAMTT[27 ] 52.5 78.8 POI[27 ] 66.1 77.1 SORT[27 ] 59.8 79.6 基准DeepSort[27 ] 61.4 79.1 本文算法 62.5 78.9 3. 结 论 (1)基于Gaussian YOLO v3的前方车辆跟踪算法,充分利用检测器强大的目标检测分类能力,结合车辆Re-ID优化后的DeepSort算法,对实际交通场景下的车辆多目标进行在线跟踪,与流行多目标跟踪算法相比,具有良好的跟踪精确率与准确率. ...
An automatic tracking method for multiple cells based on multi-feature fusion
2
2018
... 深度学习具有强大的特征提取与表达能力,可提取深度视觉特征,完成目标分类与检测. Kim等[4 ] 首次将深度特征应用于目标跟踪,预训练卷积神经网络(convolutional neural networks,CNN),提取视觉深度特征与多假设跟踪算法进行结合,充分利用多假设跟踪(multiple hypothesis tracking,MHT)算法开发高阶信息的优点,对于每一个跟踪假设,引入在线外观训练模型,将MOT15成绩提升3%. Hu等[5 ] 建立能够区分动静目标的算法,对动目标使用由基于VGG-16的Faster R-CNN提取的运动特征与视觉特征关联,并通过跟踪步骤微调,实现对错误中断轨迹的重新关联,降低漏检率与误检率. Leal-Taixé等[6 ] 提出孪生网络,使用算法学习到最具代表性的特征区分目标,并使用相似性分数衡量检测结果,而后使用线性规划求解数据关联结果. Zhou等[7 ] 提出视觉位移CNN网络,对目标下一帧的位置进行预测,以及对其他目标的影响;可从预测位置和实际检测中提取视觉信息以计算相似度得分. Ullah等[8 ] 使用浅层Inception,利用正交匹配追踪对提取特征进行降维,构建跟踪目标特征字典. 在测试阶段,构建成本矩阵,结合卡尔曼滤波器提取的视觉和运动信息,以匈牙利算法进行数据关联. Sharma等[9 ] 利用单目摄像头获取的目标姿势、形状、位置等3D信息构建代价函数,可解决基于检测的多目标跟踪中可能出现的关联错误. Chu等[10 ] 提出堆叠CNN模型,采用第一个CNN模块提取场景中目标特征,对每个候选目标进行感兴趣区域(region of interest,RoI)特征提取;对于被跟踪的目标,使用第二个在线训练CNN模块进行候选目标的可见性图和空间注意力图提取,在特征细化后使用贪婪算法进行数据关联. Milan等[11 ] 将深度网络应用于相似度计算,以循环神经网络(recurrent neural network,RNN)为主跟踪器,利用长短时记忆网络(long short term memory,LSTM)具有良好记忆状态的特点弥补了RNN因梯度下降只能记住短期数据的不足. Ma等[12 ] 提出孪生双向门控循环单元(gated recurrent unit,GRU)网络实现多目标跟踪,利用CNN和RNN提取的对象特征创建轨迹候选,选取可信度高的候选轨迹生成轨迹. Zhu等[13 ] 提出具有时间和空间双注意力机制的双匹配注意网络,使用高效卷积算子跟踪器,对遮挡后恢复的目标进行重识别训练. ...
... Comparison of MOTA and MOTP for multi-objective tracking algorithms
Tab.2 算法 MOTA MOTP Unsup Track[4 ] 61.7 78.3 Lif-T[4 ] 60.5 79.0 ISE-MOT17R[4 ] 60.1 78.2 msot[5 ] 59.2 78.0 EAMTT[27 ] 52.5 78.8 POI[27 ] 66.1 77.1 SORT[27 ] 59.8 79.6 基准DeepSort[27 ] 61.4 79.1 本文算法 62.5 78.9
3. 结 论 (1)基于Gaussian YOLO v3的前方车辆跟踪算法,充分利用检测器强大的目标检测分类能力,结合车辆Re-ID优化后的DeepSort算法,对实际交通场景下的车辆多目标进行在线跟踪,与流行多目标跟踪算法相比,具有良好的跟踪精确率与准确率. ...
1
... 深度学习具有强大的特征提取与表达能力,可提取深度视觉特征,完成目标分类与检测. Kim等[4 ] 首次将深度特征应用于目标跟踪,预训练卷积神经网络(convolutional neural networks,CNN),提取视觉深度特征与多假设跟踪算法进行结合,充分利用多假设跟踪(multiple hypothesis tracking,MHT)算法开发高阶信息的优点,对于每一个跟踪假设,引入在线外观训练模型,将MOT15成绩提升3%. Hu等[5 ] 建立能够区分动静目标的算法,对动目标使用由基于VGG-16的Faster R-CNN提取的运动特征与视觉特征关联,并通过跟踪步骤微调,实现对错误中断轨迹的重新关联,降低漏检率与误检率. Leal-Taixé等[6 ] 提出孪生网络,使用算法学习到最具代表性的特征区分目标,并使用相似性分数衡量检测结果,而后使用线性规划求解数据关联结果. Zhou等[7 ] 提出视觉位移CNN网络,对目标下一帧的位置进行预测,以及对其他目标的影响;可从预测位置和实际检测中提取视觉信息以计算相似度得分. Ullah等[8 ] 使用浅层Inception,利用正交匹配追踪对提取特征进行降维,构建跟踪目标特征字典. 在测试阶段,构建成本矩阵,结合卡尔曼滤波器提取的视觉和运动信息,以匈牙利算法进行数据关联. Sharma等[9 ] 利用单目摄像头获取的目标姿势、形状、位置等3D信息构建代价函数,可解决基于检测的多目标跟踪中可能出现的关联错误. Chu等[10 ] 提出堆叠CNN模型,采用第一个CNN模块提取场景中目标特征,对每个候选目标进行感兴趣区域(region of interest,RoI)特征提取;对于被跟踪的目标,使用第二个在线训练CNN模块进行候选目标的可见性图和空间注意力图提取,在特征细化后使用贪婪算法进行数据关联. Milan等[11 ] 将深度网络应用于相似度计算,以循环神经网络(recurrent neural network,RNN)为主跟踪器,利用长短时记忆网络(long short term memory,LSTM)具有良好记忆状态的特点弥补了RNN因梯度下降只能记住短期数据的不足. Ma等[12 ] 提出孪生双向门控循环单元(gated recurrent unit,GRU)网络实现多目标跟踪,利用CNN和RNN提取的对象特征创建轨迹候选,选取可信度高的候选轨迹生成轨迹. Zhu等[13 ] 提出具有时间和空间双注意力机制的双匹配注意网络,使用高效卷积算子跟踪器,对遮挡后恢复的目标进行重识别训练. ...
Deep continuous conditional random fields with asymmetric inter-object constraints for online multi-object tracking
1
2018
... 深度学习具有强大的特征提取与表达能力,可提取深度视觉特征,完成目标分类与检测. Kim等[4 ] 首次将深度特征应用于目标跟踪,预训练卷积神经网络(convolutional neural networks,CNN),提取视觉深度特征与多假设跟踪算法进行结合,充分利用多假设跟踪(multiple hypothesis tracking,MHT)算法开发高阶信息的优点,对于每一个跟踪假设,引入在线外观训练模型,将MOT15成绩提升3%. Hu等[5 ] 建立能够区分动静目标的算法,对动目标使用由基于VGG-16的Faster R-CNN提取的运动特征与视觉特征关联,并通过跟踪步骤微调,实现对错误中断轨迹的重新关联,降低漏检率与误检率. Leal-Taixé等[6 ] 提出孪生网络,使用算法学习到最具代表性的特征区分目标,并使用相似性分数衡量检测结果,而后使用线性规划求解数据关联结果. Zhou等[7 ] 提出视觉位移CNN网络,对目标下一帧的位置进行预测,以及对其他目标的影响;可从预测位置和实际检测中提取视觉信息以计算相似度得分. Ullah等[8 ] 使用浅层Inception,利用正交匹配追踪对提取特征进行降维,构建跟踪目标特征字典. 在测试阶段,构建成本矩阵,结合卡尔曼滤波器提取的视觉和运动信息,以匈牙利算法进行数据关联. Sharma等[9 ] 利用单目摄像头获取的目标姿势、形状、位置等3D信息构建代价函数,可解决基于检测的多目标跟踪中可能出现的关联错误. Chu等[10 ] 提出堆叠CNN模型,采用第一个CNN模块提取场景中目标特征,对每个候选目标进行感兴趣区域(region of interest,RoI)特征提取;对于被跟踪的目标,使用第二个在线训练CNN模块进行候选目标的可见性图和空间注意力图提取,在特征细化后使用贪婪算法进行数据关联. Milan等[11 ] 将深度网络应用于相似度计算,以循环神经网络(recurrent neural network,RNN)为主跟踪器,利用长短时记忆网络(long short term memory,LSTM)具有良好记忆状态的特点弥补了RNN因梯度下降只能记住短期数据的不足. Ma等[12 ] 提出孪生双向门控循环单元(gated recurrent unit,GRU)网络实现多目标跟踪,利用CNN和RNN提取的对象特征创建轨迹候选,选取可信度高的候选轨迹生成轨迹. Zhu等[13 ] 提出具有时间和空间双注意力机制的双匹配注意网络,使用高效卷积算子跟踪器,对遮挡后恢复的目标进行重识别训练. ...
1
... 深度学习具有强大的特征提取与表达能力,可提取深度视觉特征,完成目标分类与检测. Kim等[4 ] 首次将深度特征应用于目标跟踪,预训练卷积神经网络(convolutional neural networks,CNN),提取视觉深度特征与多假设跟踪算法进行结合,充分利用多假设跟踪(multiple hypothesis tracking,MHT)算法开发高阶信息的优点,对于每一个跟踪假设,引入在线外观训练模型,将MOT15成绩提升3%. Hu等[5 ] 建立能够区分动静目标的算法,对动目标使用由基于VGG-16的Faster R-CNN提取的运动特征与视觉特征关联,并通过跟踪步骤微调,实现对错误中断轨迹的重新关联,降低漏检率与误检率. Leal-Taixé等[6 ] 提出孪生网络,使用算法学习到最具代表性的特征区分目标,并使用相似性分数衡量检测结果,而后使用线性规划求解数据关联结果. Zhou等[7 ] 提出视觉位移CNN网络,对目标下一帧的位置进行预测,以及对其他目标的影响;可从预测位置和实际检测中提取视觉信息以计算相似度得分. Ullah等[8 ] 使用浅层Inception,利用正交匹配追踪对提取特征进行降维,构建跟踪目标特征字典. 在测试阶段,构建成本矩阵,结合卡尔曼滤波器提取的视觉和运动信息,以匈牙利算法进行数据关联. Sharma等[9 ] 利用单目摄像头获取的目标姿势、形状、位置等3D信息构建代价函数,可解决基于检测的多目标跟踪中可能出现的关联错误. Chu等[10 ] 提出堆叠CNN模型,采用第一个CNN模块提取场景中目标特征,对每个候选目标进行感兴趣区域(region of interest,RoI)特征提取;对于被跟踪的目标,使用第二个在线训练CNN模块进行候选目标的可见性图和空间注意力图提取,在特征细化后使用贪婪算法进行数据关联. Milan等[11 ] 将深度网络应用于相似度计算,以循环神经网络(recurrent neural network,RNN)为主跟踪器,利用长短时记忆网络(long short term memory,LSTM)具有良好记忆状态的特点弥补了RNN因梯度下降只能记住短期数据的不足. Ma等[12 ] 提出孪生双向门控循环单元(gated recurrent unit,GRU)网络实现多目标跟踪,利用CNN和RNN提取的对象特征创建轨迹候选,选取可信度高的候选轨迹生成轨迹. Zhu等[13 ] 提出具有时间和空间双注意力机制的双匹配注意网络,使用高效卷积算子跟踪器,对遮挡后恢复的目标进行重识别训练. ...
1
... 深度学习具有强大的特征提取与表达能力,可提取深度视觉特征,完成目标分类与检测. Kim等[4 ] 首次将深度特征应用于目标跟踪,预训练卷积神经网络(convolutional neural networks,CNN),提取视觉深度特征与多假设跟踪算法进行结合,充分利用多假设跟踪(multiple hypothesis tracking,MHT)算法开发高阶信息的优点,对于每一个跟踪假设,引入在线外观训练模型,将MOT15成绩提升3%. Hu等[5 ] 建立能够区分动静目标的算法,对动目标使用由基于VGG-16的Faster R-CNN提取的运动特征与视觉特征关联,并通过跟踪步骤微调,实现对错误中断轨迹的重新关联,降低漏检率与误检率. Leal-Taixé等[6 ] 提出孪生网络,使用算法学习到最具代表性的特征区分目标,并使用相似性分数衡量检测结果,而后使用线性规划求解数据关联结果. Zhou等[7 ] 提出视觉位移CNN网络,对目标下一帧的位置进行预测,以及对其他目标的影响;可从预测位置和实际检测中提取视觉信息以计算相似度得分. Ullah等[8 ] 使用浅层Inception,利用正交匹配追踪对提取特征进行降维,构建跟踪目标特征字典. 在测试阶段,构建成本矩阵,结合卡尔曼滤波器提取的视觉和运动信息,以匈牙利算法进行数据关联. Sharma等[9 ] 利用单目摄像头获取的目标姿势、形状、位置等3D信息构建代价函数,可解决基于检测的多目标跟踪中可能出现的关联错误. Chu等[10 ] 提出堆叠CNN模型,采用第一个CNN模块提取场景中目标特征,对每个候选目标进行感兴趣区域(region of interest,RoI)特征提取;对于被跟踪的目标,使用第二个在线训练CNN模块进行候选目标的可见性图和空间注意力图提取,在特征细化后使用贪婪算法进行数据关联. Milan等[11 ] 将深度网络应用于相似度计算,以循环神经网络(recurrent neural network,RNN)为主跟踪器,利用长短时记忆网络(long short term memory,LSTM)具有良好记忆状态的特点弥补了RNN因梯度下降只能记住短期数据的不足. Ma等[12 ] 提出孪生双向门控循环单元(gated recurrent unit,GRU)网络实现多目标跟踪,利用CNN和RNN提取的对象特征创建轨迹候选,选取可信度高的候选轨迹生成轨迹. Zhu等[13 ] 提出具有时间和空间双注意力机制的双匹配注意网络,使用高效卷积算子跟踪器,对遮挡后恢复的目标进行重识别训练. ...
1
... 深度学习具有强大的特征提取与表达能力,可提取深度视觉特征,完成目标分类与检测. Kim等[4 ] 首次将深度特征应用于目标跟踪,预训练卷积神经网络(convolutional neural networks,CNN),提取视觉深度特征与多假设跟踪算法进行结合,充分利用多假设跟踪(multiple hypothesis tracking,MHT)算法开发高阶信息的优点,对于每一个跟踪假设,引入在线外观训练模型,将MOT15成绩提升3%. Hu等[5 ] 建立能够区分动静目标的算法,对动目标使用由基于VGG-16的Faster R-CNN提取的运动特征与视觉特征关联,并通过跟踪步骤微调,实现对错误中断轨迹的重新关联,降低漏检率与误检率. Leal-Taixé等[6 ] 提出孪生网络,使用算法学习到最具代表性的特征区分目标,并使用相似性分数衡量检测结果,而后使用线性规划求解数据关联结果. Zhou等[7 ] 提出视觉位移CNN网络,对目标下一帧的位置进行预测,以及对其他目标的影响;可从预测位置和实际检测中提取视觉信息以计算相似度得分. Ullah等[8 ] 使用浅层Inception,利用正交匹配追踪对提取特征进行降维,构建跟踪目标特征字典. 在测试阶段,构建成本矩阵,结合卡尔曼滤波器提取的视觉和运动信息,以匈牙利算法进行数据关联. Sharma等[9 ] 利用单目摄像头获取的目标姿势、形状、位置等3D信息构建代价函数,可解决基于检测的多目标跟踪中可能出现的关联错误. Chu等[10 ] 提出堆叠CNN模型,采用第一个CNN模块提取场景中目标特征,对每个候选目标进行感兴趣区域(region of interest,RoI)特征提取;对于被跟踪的目标,使用第二个在线训练CNN模块进行候选目标的可见性图和空间注意力图提取,在特征细化后使用贪婪算法进行数据关联. Milan等[11 ] 将深度网络应用于相似度计算,以循环神经网络(recurrent neural network,RNN)为主跟踪器,利用长短时记忆网络(long short term memory,LSTM)具有良好记忆状态的特点弥补了RNN因梯度下降只能记住短期数据的不足. Ma等[12 ] 提出孪生双向门控循环单元(gated recurrent unit,GRU)网络实现多目标跟踪,利用CNN和RNN提取的对象特征创建轨迹候选,选取可信度高的候选轨迹生成轨迹. Zhu等[13 ] 提出具有时间和空间双注意力机制的双匹配注意网络,使用高效卷积算子跟踪器,对遮挡后恢复的目标进行重识别训练. ...
1
... 深度学习具有强大的特征提取与表达能力,可提取深度视觉特征,完成目标分类与检测. Kim等[4 ] 首次将深度特征应用于目标跟踪,预训练卷积神经网络(convolutional neural networks,CNN),提取视觉深度特征与多假设跟踪算法进行结合,充分利用多假设跟踪(multiple hypothesis tracking,MHT)算法开发高阶信息的优点,对于每一个跟踪假设,引入在线外观训练模型,将MOT15成绩提升3%. Hu等[5 ] 建立能够区分动静目标的算法,对动目标使用由基于VGG-16的Faster R-CNN提取的运动特征与视觉特征关联,并通过跟踪步骤微调,实现对错误中断轨迹的重新关联,降低漏检率与误检率. Leal-Taixé等[6 ] 提出孪生网络,使用算法学习到最具代表性的特征区分目标,并使用相似性分数衡量检测结果,而后使用线性规划求解数据关联结果. Zhou等[7 ] 提出视觉位移CNN网络,对目标下一帧的位置进行预测,以及对其他目标的影响;可从预测位置和实际检测中提取视觉信息以计算相似度得分. Ullah等[8 ] 使用浅层Inception,利用正交匹配追踪对提取特征进行降维,构建跟踪目标特征字典. 在测试阶段,构建成本矩阵,结合卡尔曼滤波器提取的视觉和运动信息,以匈牙利算法进行数据关联. Sharma等[9 ] 利用单目摄像头获取的目标姿势、形状、位置等3D信息构建代价函数,可解决基于检测的多目标跟踪中可能出现的关联错误. Chu等[10 ] 提出堆叠CNN模型,采用第一个CNN模块提取场景中目标特征,对每个候选目标进行感兴趣区域(region of interest,RoI)特征提取;对于被跟踪的目标,使用第二个在线训练CNN模块进行候选目标的可见性图和空间注意力图提取,在特征细化后使用贪婪算法进行数据关联. Milan等[11 ] 将深度网络应用于相似度计算,以循环神经网络(recurrent neural network,RNN)为主跟踪器,利用长短时记忆网络(long short term memory,LSTM)具有良好记忆状态的特点弥补了RNN因梯度下降只能记住短期数据的不足. Ma等[12 ] 提出孪生双向门控循环单元(gated recurrent unit,GRU)网络实现多目标跟踪,利用CNN和RNN提取的对象特征创建轨迹候选,选取可信度高的候选轨迹生成轨迹. Zhu等[13 ] 提出具有时间和空间双注意力机制的双匹配注意网络,使用高效卷积算子跟踪器,对遮挡后恢复的目标进行重识别训练. ...
1
... 深度学习具有强大的特征提取与表达能力,可提取深度视觉特征,完成目标分类与检测. Kim等[4 ] 首次将深度特征应用于目标跟踪,预训练卷积神经网络(convolutional neural networks,CNN),提取视觉深度特征与多假设跟踪算法进行结合,充分利用多假设跟踪(multiple hypothesis tracking,MHT)算法开发高阶信息的优点,对于每一个跟踪假设,引入在线外观训练模型,将MOT15成绩提升3%. Hu等[5 ] 建立能够区分动静目标的算法,对动目标使用由基于VGG-16的Faster R-CNN提取的运动特征与视觉特征关联,并通过跟踪步骤微调,实现对错误中断轨迹的重新关联,降低漏检率与误检率. Leal-Taixé等[6 ] 提出孪生网络,使用算法学习到最具代表性的特征区分目标,并使用相似性分数衡量检测结果,而后使用线性规划求解数据关联结果. Zhou等[7 ] 提出视觉位移CNN网络,对目标下一帧的位置进行预测,以及对其他目标的影响;可从预测位置和实际检测中提取视觉信息以计算相似度得分. Ullah等[8 ] 使用浅层Inception,利用正交匹配追踪对提取特征进行降维,构建跟踪目标特征字典. 在测试阶段,构建成本矩阵,结合卡尔曼滤波器提取的视觉和运动信息,以匈牙利算法进行数据关联. Sharma等[9 ] 利用单目摄像头获取的目标姿势、形状、位置等3D信息构建代价函数,可解决基于检测的多目标跟踪中可能出现的关联错误. Chu等[10 ] 提出堆叠CNN模型,采用第一个CNN模块提取场景中目标特征,对每个候选目标进行感兴趣区域(region of interest,RoI)特征提取;对于被跟踪的目标,使用第二个在线训练CNN模块进行候选目标的可见性图和空间注意力图提取,在特征细化后使用贪婪算法进行数据关联. Milan等[11 ] 将深度网络应用于相似度计算,以循环神经网络(recurrent neural network,RNN)为主跟踪器,利用长短时记忆网络(long short term memory,LSTM)具有良好记忆状态的特点弥补了RNN因梯度下降只能记住短期数据的不足. Ma等[12 ] 提出孪生双向门控循环单元(gated recurrent unit,GRU)网络实现多目标跟踪,利用CNN和RNN提取的对象特征创建轨迹候选,选取可信度高的候选轨迹生成轨迹. Zhu等[13 ] 提出具有时间和空间双注意力机制的双匹配注意网络,使用高效卷积算子跟踪器,对遮挡后恢复的目标进行重识别训练. ...
1
... 深度学习具有强大的特征提取与表达能力,可提取深度视觉特征,完成目标分类与检测. Kim等[4 ] 首次将深度特征应用于目标跟踪,预训练卷积神经网络(convolutional neural networks,CNN),提取视觉深度特征与多假设跟踪算法进行结合,充分利用多假设跟踪(multiple hypothesis tracking,MHT)算法开发高阶信息的优点,对于每一个跟踪假设,引入在线外观训练模型,将MOT15成绩提升3%. Hu等[5 ] 建立能够区分动静目标的算法,对动目标使用由基于VGG-16的Faster R-CNN提取的运动特征与视觉特征关联,并通过跟踪步骤微调,实现对错误中断轨迹的重新关联,降低漏检率与误检率. Leal-Taixé等[6 ] 提出孪生网络,使用算法学习到最具代表性的特征区分目标,并使用相似性分数衡量检测结果,而后使用线性规划求解数据关联结果. Zhou等[7 ] 提出视觉位移CNN网络,对目标下一帧的位置进行预测,以及对其他目标的影响;可从预测位置和实际检测中提取视觉信息以计算相似度得分. Ullah等[8 ] 使用浅层Inception,利用正交匹配追踪对提取特征进行降维,构建跟踪目标特征字典. 在测试阶段,构建成本矩阵,结合卡尔曼滤波器提取的视觉和运动信息,以匈牙利算法进行数据关联. Sharma等[9 ] 利用单目摄像头获取的目标姿势、形状、位置等3D信息构建代价函数,可解决基于检测的多目标跟踪中可能出现的关联错误. Chu等[10 ] 提出堆叠CNN模型,采用第一个CNN模块提取场景中目标特征,对每个候选目标进行感兴趣区域(region of interest,RoI)特征提取;对于被跟踪的目标,使用第二个在线训练CNN模块进行候选目标的可见性图和空间注意力图提取,在特征细化后使用贪婪算法进行数据关联. Milan等[11 ] 将深度网络应用于相似度计算,以循环神经网络(recurrent neural network,RNN)为主跟踪器,利用长短时记忆网络(long short term memory,LSTM)具有良好记忆状态的特点弥补了RNN因梯度下降只能记住短期数据的不足. Ma等[12 ] 提出孪生双向门控循环单元(gated recurrent unit,GRU)网络实现多目标跟踪,利用CNN和RNN提取的对象特征创建轨迹候选,选取可信度高的候选轨迹生成轨迹. Zhu等[13 ] 提出具有时间和空间双注意力机制的双匹配注意网络,使用高效卷积算子跟踪器,对遮挡后恢复的目标进行重识别训练. ...
1
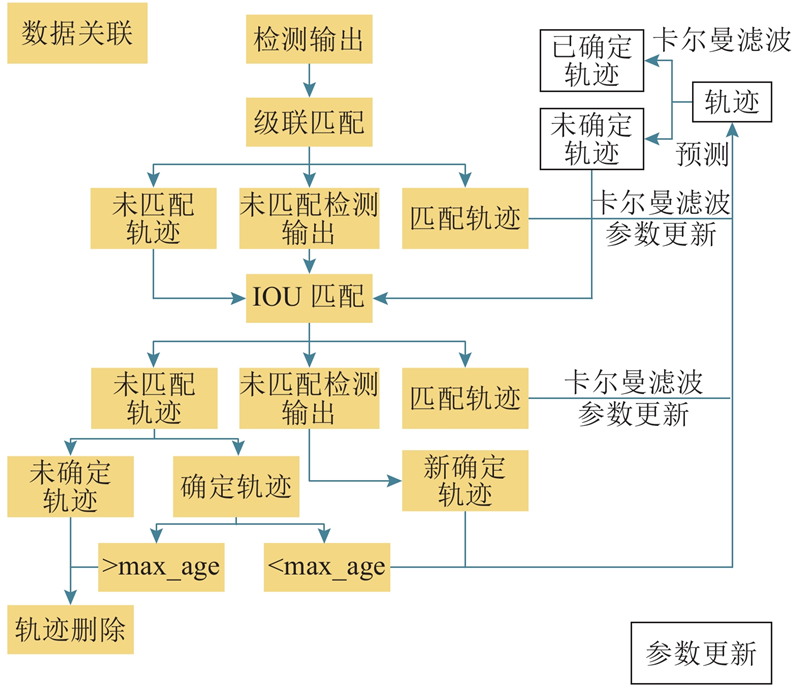
... 基准算法使用递归卡尔曼滤波逐帧处理数据关联性并使用匈牙利算法对检测器的输出进行目标筛选与跨帧匹配,是单假设多目标跟踪方法[14 ] . 在Sort跟踪器基础上增加卷积神经网络进行重识别,提取跟踪目标表观特征进行最近邻匹配,改善因遮挡造成的身份跳变(ID-switch)问题;在被检测目标与跟踪轨迹关联问题上使用级联匹配方法,对出现频率较为频繁的目标赋予优先匹配权,解决连续预测的概率弥散问题. 算法流程图如图1 所示. ...
1
... 跟踪目标被长期遮挡,卡尔曼滤波连续预测不更新会造成协方差矩阵方差变大,造成概率弥散,观察似然峰值降低[15 ] . 跟踪算法采用级联匹配,对关联可能性进行编码,为每个跟踪器设定更新后时间(time since update)参数,跟踪器完成匹配,则参数重置,否则+1,参数小的具有匹配优先级,当参数大于60时,放弃该跟踪器. ...
1
... 跟踪目标被长期遮挡,卡尔曼滤波连续预测不更新会造成协方差矩阵方差变大,造成概率弥散,观察似然峰值降低[15 ] . 跟踪算法采用级联匹配,对关联可能性进行编码,为每个跟踪器设定更新后时间(time since update)参数,跟踪器完成匹配,则参数重置,否则+1,参数小的具有匹配优先级,当参数大于60时,放弃该跟踪器. ...
1
... 深度余弦度量学习通过深度学习计算类间余弦距离,离线训练深度学习网络,得到深度学习权重[16 ] . 输入对象根据网络权重,依据决策边界方向及最近距离查找对象所属聚类[17 ] ,实现跟踪对象目标重识别(Re-ID)、度量学习与分类的统一,同时提升识别准确率[18 ] . ...
1
... 深度余弦度量学习通过深度学习计算类间余弦距离,离线训练深度学习网络,得到深度学习权重[16 ] . 输入对象根据网络权重,依据决策边界方向及最近距离查找对象所属聚类[17 ] ,实现跟踪对象目标重识别(Re-ID)、度量学习与分类的统一,同时提升识别准确率[18 ] . ...
Imagenet classification with deep convolutional neural networks
1
2017
... 深度余弦度量学习通过深度学习计算类间余弦距离,离线训练深度学习网络,得到深度学习权重[16 ] . 输入对象根据网络权重,依据决策边界方向及最近距离查找对象所属聚类[17 ] ,实现跟踪对象目标重识别(Re-ID)、度量学习与分类的统一,同时提升识别准确率[18 ] . ...
1
... 使用CNN在大规模重识别数据集上进行离线训练,CNN网络结构如表1 所示. 网络采用宽残差模块,所有的卷积核大小均为3×3,使用步长为2的卷积替代最大池化[19 ] . 在空间分辨率降低时,增加通道数来避免瓶颈问题,在整个网络中使用指数线性单元(exponential liner unit,ELU)作为激活函数. ...
1
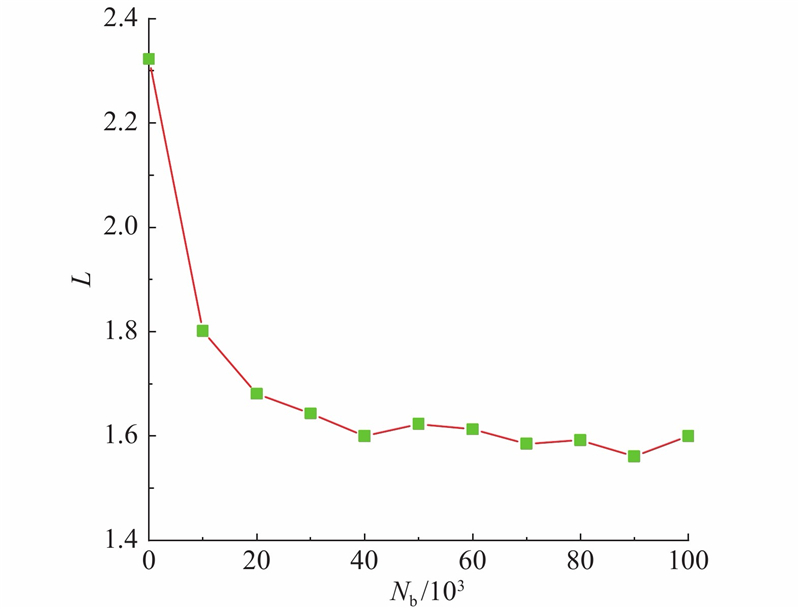
... 式中: ${{{c}}_{{{{y}}_i}}}$ ${{{y}}_i}$ ${{{x}}_i}$ N b 为批大小(batch size). 在起始时刻,中心损失函数对每一个类在网络中随机生成一个中心,而后在一个批次训练中计算样本中心与类中心的距离,将这个数值加到类中心上进行参数修正. 若类内某个样本特征距离中心较远,则需进行惩罚[20 ] . 类中心更新计算方式为 ...
1
... 将L sl 与L cl 结合,提升深层特征辨别力. L sl 使不同类别的深层特征保持分离,L cl 实现层内聚类,将相同类别的深层特征紧凑化,与单一使用传统交叉熵损失函数相比,大幅减小类内差异,且提取的特征具有更好的判别能力[21 ] . 使用标量γ 平衡2种损失函数,取值为[0,1.0]. 最终定义损失函数为 ...
1
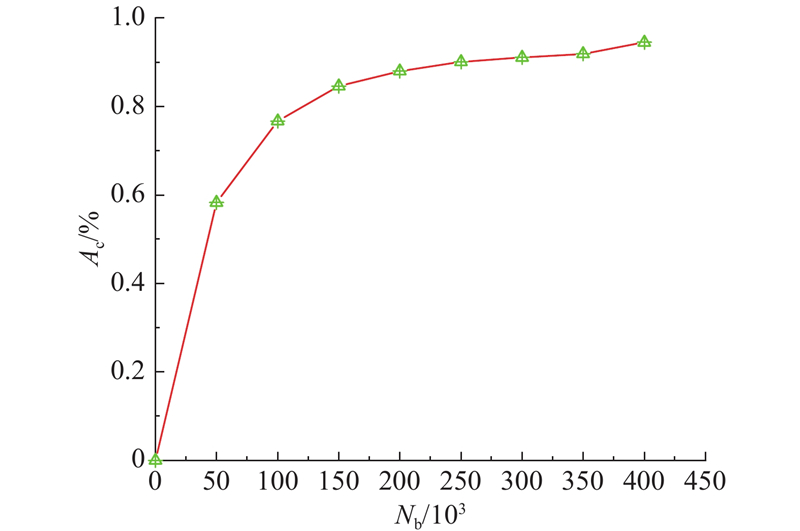
... 使用刘鑫辰[22 ] 制作的大规模城市交通监控车辆再识别图像数据集−VeRi. 该数据集使用20个监控摄像机采集776辆车的图像,共收集50 000多张图片. 保证每辆车都从不同角度、照度、遮挡情况等方面被2~18个摄像机采集. 数据集图片名称中包含车辆标签编号、车辆类别与属性信息、采集摄像机编号、图片处于视频段中的帧数以及检测框是否手工标注等. 编写脚本对VeRi数据集进行图像数据质量增强,加强车辆与背景区分度,并进行随机翻转,将数据集容量增大了1/2. 前、后图片质量对比示例如图2 所示. ...
1
... 使用刘鑫辰[22 ] 制作的大规模城市交通监控车辆再识别图像数据集−VeRi. 该数据集使用20个监控摄像机采集776辆车的图像,共收集50 000多张图片. 保证每辆车都从不同角度、照度、遮挡情况等方面被2~18个摄像机采集. 数据集图片名称中包含车辆标签编号、车辆类别与属性信息、采集摄像机编号、图片处于视频段中的帧数以及检测框是否手工标注等. 编写脚本对VeRi数据集进行图像数据质量增强,加强车辆与背景区分度,并进行随机翻转,将数据集容量增大了1/2. 前、后图片质量对比示例如图2 所示. ...
Faster R-CNN: towards real-time object detection with region proposal networks
1
2017
... YOLO系列为端到端(end to end)的一阶段检测器,与Faster R-CNN等[23 ] 二阶段系列相比,由于采用的是网格划分方法进行区域检测而非像素滑窗方法,准确率稍差,但具有速度快的优点. YOLO可以根据项目需要使用不同的训练框架,对速度与准确性进行权衡,因此YOLO系列已成为目标检测领域应用非常广泛的算法. ...
1
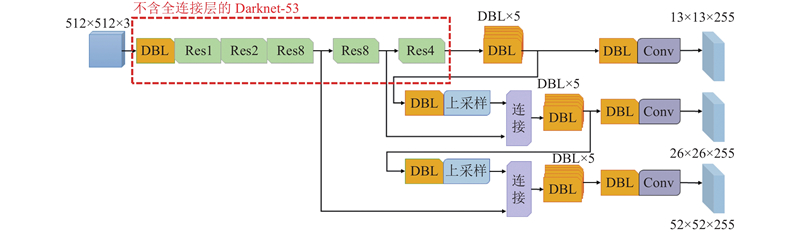
... YOLO v3借鉴特征金字塔网络[24 ] (feature pyramid networks, FPN)思想,采用多尺度检测不同大小的目标,输出3个不同尺度的特征图,即13×13、26×26和52×52,将不同尺度特征图进行连接,使网络融合目标位置信息与高层抽象特征. YOLO v3输出中有目标类别的概率值和目标框的位置[25 ] . YOLO v3网络结构如图3 所示. ...
1
... YOLO v3借鉴特征金字塔网络[24 ] (feature pyramid networks, FPN)思想,采用多尺度检测不同大小的目标,输出3个不同尺度的特征图,即13×13、26×26和52×52,将不同尺度特征图进行连接,使网络融合目标位置信息与高层抽象特征. YOLO v3输出中有目标类别的概率值和目标框的位置[25 ] . YOLO v3网络结构如图3 所示. ...
1
... Gaussian YOLO v3在YOLO v3基础上,对目标框的位置起始像素点坐标与高宽度信息 $({t_x},{t_y},{t_w},{t_h})$ $\mu $ $\left( {{\mu _x},\displaystyle\sum {{t_x}} } \right)$ $\left( {{\mu _y},\displaystyle\sum {{t_y}} } \right)$ $\left( {{\mu _w},\displaystyle\sum {{t_w}} } \right)$ $\left( {{\mu _h},\displaystyle\sum {{t_h}} } \right)$ ${\mu _x}$ ${t_x}$ [26 ] . 试验结果表明,采用Gaussian YOLO v3总体提升了3%预测准确率平均值(mean average precision,MAP). ...
4
... Comparison of MOTA and MOTP for multi-objective tracking algorithms
Tab.2 算法 MOTA MOTP Unsup Track[4 ] 61.7 78.3 Lif-T[4 ] 60.5 79.0 ISE-MOT17R[4 ] 60.1 78.2 msot[5 ] 59.2 78.0 EAMTT[27 ] 52.5 78.8 POI[27 ] 66.1 77.1 SORT[27 ] 59.8 79.6 基准DeepSort[27 ] 61.4 79.1 本文算法 62.5 78.9
3. 结 论 (1)基于Gaussian YOLO v3的前方车辆跟踪算法,充分利用检测器强大的目标检测分类能力,结合车辆Re-ID优化后的DeepSort算法,对实际交通场景下的车辆多目标进行在线跟踪,与流行多目标跟踪算法相比,具有良好的跟踪精确率与准确率. ...
... [
27 ]
66.1 77.1 SORT[27 ] 59.8 79.6 基准DeepSort[27 ] 61.4 79.1 本文算法 62.5 78.9 3. 结 论 (1)基于Gaussian YOLO v3的前方车辆跟踪算法,充分利用检测器强大的目标检测分类能力,结合车辆Re-ID优化后的DeepSort算法,对实际交通场景下的车辆多目标进行在线跟踪,与流行多目标跟踪算法相比,具有良好的跟踪精确率与准确率. ...
... [
27 ]
59.8 79.6 基准DeepSort[27 ] 61.4 79.1 本文算法 62.5 78.9 3. 结 论 (1)基于Gaussian YOLO v3的前方车辆跟踪算法,充分利用检测器强大的目标检测分类能力,结合车辆Re-ID优化后的DeepSort算法,对实际交通场景下的车辆多目标进行在线跟踪,与流行多目标跟踪算法相比,具有良好的跟踪精确率与准确率. ...
... [
27 ]
61.4 79.1 本文算法 62.5 78.9 3. 结 论 (1)基于Gaussian YOLO v3的前方车辆跟踪算法,充分利用检测器强大的目标检测分类能力,结合车辆Re-ID优化后的DeepSort算法,对实际交通场景下的车辆多目标进行在线跟踪,与流行多目标跟踪算法相比,具有良好的跟踪精确率与准确率. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}