|
|
|
| Normal region segmentation of road scene based on spatial context algorithm |
Xue-yun CHEN( ),Qu YAO*(),Qi-chen DING,Xue-yu BEI,Xiao-qiao HUANG,Xin JIN ),Qu YAO*(),Qi-chen DING,Xue-yu BEI,Xiao-qiao HUANG,Xin JIN |
| School of Electrical Engineering, Guangxi University, Nanning 530000, China |
|
|
|
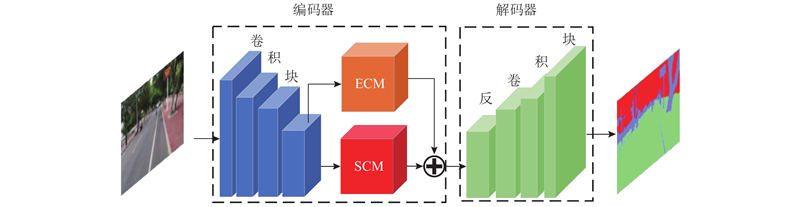
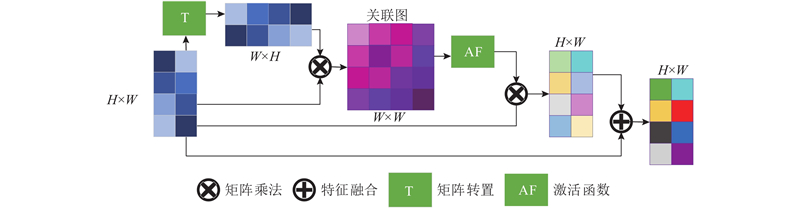
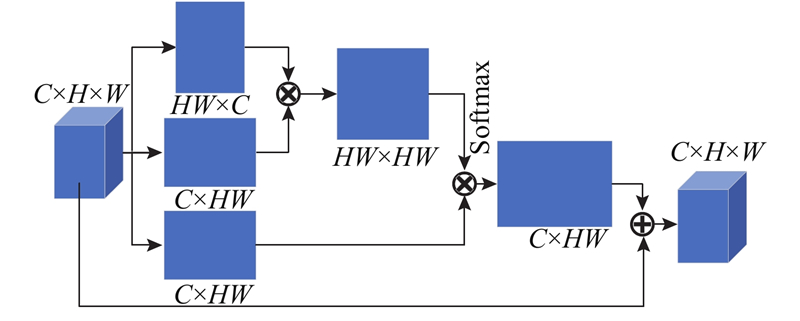
Abstract Aiming at the problem of ignoring normal attributes in road scene detection, in order to strengthen the use of spatial context and edge information, a road scene normal region segmentation method combined with spatial context algorithm was proposed, and the road scene was identified as the horizontal and the vertical regions corresponding to the road and the obstacles, respectively. On the basis of the cross-entropy loss function, the obstacle enhancement loss was added to improve the weight distribution of different categories in the training process, and improve the recognition rate of obstacles in small areas. The context improvement algorithm was proposed to optimize the matrix calculation method of the position association graph, reduce the space complexity and improve the calculation efficiency. The edge context module was embedded to reduce noise and strengthen the main edge, enhancing the use of edge information. Experimental results on the self-built dataset and the Cityscapes dataset show that compared with mainstream semantic segmentation methods, the proposed method strengthens the ability of network feature extraction, effectively improves the segmentation accuracy of the road normal region, of which the intersection is 2.1% higher than that of Deeplab, easily and effectively achieving obstacle avoidance tasks.
|
|
Received: 25 March 2021
Published: 05 November 2021
|
|
|
| Fund: 国家自然科学基金资助项目(62061002) |
|
Corresponding Authors:
Qu YAO
E-mail: cxy17777@163.com;576661193@qq.com
|
结合空间上下文算法的道路场景法线区域分割
针对道路场景检测忽略法线属性的问题,为了加强对空间上下文和边缘信息的利用,提出结合空间上下文算法的道路场景法线区域分割方法,将道路场景识别为路面和障碍物分别对应的水平区域和竖直区域. 在交叉熵损失函数的基础上添加障碍物增强损失,改善训练过程不同分类的权重分配,提高小区域障碍物识别率. 提出上下文改进算法优化位置关联图的矩阵计算方式,减少空间复杂度提高运算效率. 嵌入边缘上下文模块削减噪声并强化主要边缘,加强边缘信息的利用. 在自建数据集和Cityscapes数据集的实验结果表明,与主流的语义分割方法相比,本研究方法加强网络特征提取能力,能有效提高对道路法线区域的分割准确度,相较Deeplab, 交并比提高了2.1%,能简单有效地实现避障任务.
关键词:
法线区域分割,
空间上下文,
边缘信息,
道路场景,
障碍物增强损失
|
|
| [1] |
HOIEM D, EFROS A, HEBERT M Recovering surface layout from an image[J]. International Journal of Computer Vision, 2007, 75 (1): 151- 172
doi: 10.1007/s11263-006-0031-y
|
|
|
| [2] |
FOUHEY D, GUPTA A, HEBERT M. Data-driven 3D primitives for single image understanding[C]// International Conference on Computer Vision. Sydney: IEEE, 2013: 3392-3399.
|
|
|
| [3] |
LADICK L, ZEISL B, POLLEFEYS M. Discriminatively trained dense surface normal estimation[C]// European Conference on Computer Vision. Cham: Springer, 2014: 468-484.
|
|
|
| [4] |
KUSUPAT U, CHENG S, CHEN R, et al. Normal assisted stereo depth estimation[C]// Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 2189-2199.
|
|
|
| [5] |
ZHANG S, XIE W, ZHANG G, et al. Robust stereo matching with surface normal prediction[C]// International Conference on Robotics and Automation. Singapore: IEEE, 2017: 2540-2547.
|
|
|
| [6] |
EIGEN D, FERGUS R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture[C]// International Conference on Computer Vision. Santiago: IEEE, 2015: 2650-2658.
|
|
|
| [7] |
KRIZHEVSKY A , SUTSKEVER I , HINTON G . Classification with deep convolutional neural networks[J]. Communications of the ACM. 2017, 60(6): 84-90.
|
|
|
| [8] |
BANSAL A, RUSSELL B, GUPTA A. Marr revisited: 2D-3D alignment via surface normal prediction[C]// Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 5965-5974.
|
|
|
| [9] |
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [C]// International Conference on Learning Representations. San Diego: ICRL, 2014.
|
|
|
| [10] |
冼楚华, 刘欣, 李桂清, 等 基于多尺度卷积网络的单幅图像的点法向估计[J]. 华南理工大学学报:自然科学版, 2018, 46 (12): 7- 15
XIAN Chu-hua, LIU Xin, LI Gui-qing, et al Normal estimation from single monocular images based on multi-scale convolution network[J]. Journal of South China University of Technology: Natural Science Edition, 2018, 46 (12): 7- 15
|
|
|
| [11] |
HAN Y, ZHANG S, ZHANG Y, et al Monocular depth estimation with guidance of surface normal map[J]. Neurocomputing, 2018, 280: 86- 100
doi: 10.1016/j.neucom.2017.08.074
|
|
|
| [12] |
SHEIHAMER E, LONG J, DARRELL T Fully convolutional networks for semantic segmentation[J]. Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (4): 640- 651
doi: 10.1109/TPAMI.2016.2572683
|
|
|
| [13] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
|
|
| [14] |
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]// International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich: Springer, 2015: 234-241.
|
|
|
| [15] |
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network[C]// Conference on Computer Vision And Pattern Recognition. Honolulu: IEEE, 2017: 6230-6239.
|
|
|
| [16] |
CHEN L, PAPANDREOU G, KOKKINOS I, et al DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. Transactions on Pattern Analysis and Machine Intelligence, 2018, 40 (4): 834- 848
doi: 10.1109/TPAMI.2017.2699184
|
|
|
| [17] |
WANG X, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]// Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7794-7803.
|
|
|
| [18] |
FU J , LIU J , TIAN H , et al. Dual attention network for scene segmentation[C]// Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 3141-3149.
|
|
|
| [19] |
CAO Y, XU J , LIN S, et al. GCNet: non-local networks meet squeeze-excitation networks and beyond[C]// International Conference on Computer Vision Workshops. Seoul: IEEE, 2019: 1971-1980.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|