|
|
|
| Application of ensemble learning based on preferred sample selection in desulfurization optimization process |
Zhi-hui GE( ),Jiang-kuan XING,Kun LUO*(),Jian-ren FAN ),Jiang-kuan XING,Kun LUO*(),Jian-ren FAN |
| State Key Laboratory of Clean Energy Utilization, Zhejiang University, Hangzhou 310027, China |
|
|
|
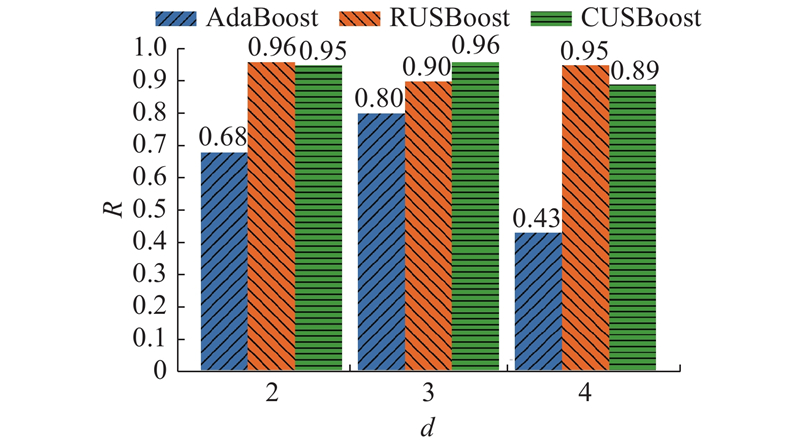
Abstract The ensemble learning approach based on random sampling or cluster sampling was developed to predict the number of desulfurization tower circulating pumps opened. The database was constructed from a realistic power plants, the outliers and unsteady values in the initial one were deleted, and the input parameters of the ensemble learning model with high correlation coefficients with the output were extracted. The problems of imbalanced samples in classification, missing evaluation criteria for optimal samples and desulfurization optimization were solved. Results showed that the improved ensemble learning model had a 33% increase in overall prediction accuracy compared with the original model. In addition, the cluster sampling was slightly better than the random sampling. Furthermore, the recall of a single category prediction was analyzed, and the recall values of different algorithms for the minority category and the majority category were compared. Results showed that the two improved sampling methods had greatly improved the minority category prediction, and the recall reached more than 90%, besides it also had certain improvement on the majority. Finally, the difference in sample distribution and model accuracy was discussed when the pump combination was used as the model’s output.
|
|
Received: 10 August 2020
Published: 01 September 2021
|
|
|
| Fund: 国家重点研发计划资助项目(2017YFB0601805) |
|
Corresponding Authors:
Kun LUO
E-mail: 21827006@zju.edu.cn;zjulk@zju.edu.cn
|
基于样本优选的集成学习在脱硫优化中的应用
基于实际电厂的大量脱硫数据,删除初始脱硫数据库中异常值和非稳态值,提取与输出相关系数较高的集成学习模型输入参数,采用改进的基于随机采样和聚类采样的集成学习算法,建立预测脱硫塔循环泵开启台数的集成学习模型,研究分类问题中样本不均衡、优选样本评价标准缺失和脱硫优化的问题. 结果显示,与改进前模型相比,改进后的集成学习模型总体预测准确度提升了33%,并且基于聚类的采样略优于随机采样. 此外,对单一类别预测的召回率进行分析,对比不同算法对少数类和多数类的召回率,结果显示2种改进的采样方法对少数类的预测有较大的提升,预测的召回率大于90%,对多数类的预测也有一定的提升效果. 讨论泵组合作为模型输出时,其样本分布和模型精度的差异.
关键词:
聚类,
采样,
集成学习,
脱硫系统,
样本优选
|
|
| [1] |
中华人民共和国统计局. 中国统计年鉴[M]. 北京: 中国统计出版社, 2019.
|
|
|
| [2] |
BARMA M C, SAIDUR R, RAHMAN S M, et al A review on boilers energy use, energy savings, and emissions reductions[J]. Renewable and Sustainable Energy Reviews, 2017, 79: 970- 983
doi: 10.1016/j.rser.2017.05.187
|
|
|
| [3] |
赵顺毅, 陈子豪, 张瑾, 等 现代流程工业的机器学习建模[J]. 自动化仪表, 2019, 40 (9): 1- 7
ZHAO Shun-yi, CHEN Zi-hao, ZHANG Jin, et al Modeling based on machine learning for modern process industry[J]. Process Automation Instrumentation, 2019, 40 (9): 1- 7
|
|
|
| [4] |
向鸿鑫, 杨云 不平衡数据挖掘方法综述[J]. 计算机工程与应用, 2019, 55 (4): 1- 16
XIANG Hong-xin, YANG Yun Survey on imbalanced data mining methods[J]. Computer Engineering and Applications, 2019, 55 (4): 1- 16
|
|
|
| [5] |
张洋. SMOTE算法的改进与应用[D]. 重庆: 重庆大学, 2019.
ZHANG Yang. Improvement and application of SMOTE algorithm[D]. Chongqing: Chongqing University, 2019.
|
|
|
| [6] |
LIN W, TSAI C, HU Y, et al Clustering-based undersampling in class-imbalanced data[J]. Information Sciences, 2017, 409: 17- 26
|
|
|
| [7] |
SEIFFERT C, KHOSHGOFTAAR T M, VAN H J, et al Rusboost: a hybrid approach to alleviating class imbalance[J]. IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans, 2009, 40 (1): 185- 197
|
|
|
| [8] |
RAYHAN F, AHMED S, MAHBUB A, et al. Cusboost: cluster-based under-sampling with boosting for imbalanced classification[C]// 2nd International Conference on Computational Systems and Information Technology for Sustainable Solution. Bangalore: IEEE, 2017: 70-75.
|
|
|
| [9] |
WANG R AdaBoost for feature selection, classification and its relation with SVM, a review[J]. Physics Procedia, 2012, 25: 800- 807
doi: 10.1016/j.phpro.2012.03.160
|
|
|
| [10] |
丁伟. 基于数据聚类的机组优化运行目标值研究[D]. 南京: 东南大学, 2019.
DING Wei. Research on target value of unit optimal operation based on data clustering[D]. Nanjing: Southeast University, 2019.
|
|
|
| [11] |
刘晓洋. 风速预测中数椐和样本的有效处理及其模型优化研究[D]. 太原: 太原理工大学, 2016.
LIU Xiao-yang. Research on effective processing of data and samples of wind speed forecasting and its model optimization [D]. Taiyuan: Taiyuan University of Technology, 2016.
|
|
|
| [12] |
RANA M, RAHMAN A Multiple steps ahead solar photovoltaic power forecasting based on univariate machine learning models and data re-sampling[J]. Sustainable Energy, 2020, 21: 100286
|
|
|
| [13] |
纪雪, 周兴华, 唐秋华, 等 多波束测深异常数据检测与剔除方法研究综述[J]. 测绘科学, 2018, 43 (1): 38- 44
JI Xue, ZHOU Xing-hua, TANG Qiu-hua, et al A survey offiltering methods in multibeam bathymetry outliers data[J]. Science of Surveying and Mapping, 2018, 43 (1): 38- 44
|
|
|
| [14] |
刘吉臻, 高萌, 吕游, 等 过程运行数据的稳态检测方法综述[J]. 仪器仪表学报, 2013, 34 (8): 1739- 1748
LIU Ji-zhen, GAO Meng, LV You, et al Overview on the steady-state detection methods of process operating data[J]. Chinese Journal of Scientific Instrument, 2013, 34 (8): 1739- 1748
doi: 10.3969/j.issn.0254-3087.2013.08.009
|
|
|
| [15] |
CAO S, RHINEHART R R An efficient method for on-line identification of steady state[J]. Journal of Process Control, 1995, 5 (6): 363- 374
doi: 10.1016/0959-1524(95)00009-F
|
|
|
| [16] |
CAO S, RHINEHART R R Critical values for a steady-state identifier[J]. Journal of Process Control, 1997, 7 (2): 149- 152
doi: 10.1016/S0959-1524(96)00026-1
|
|
|
| [17] |
金建国 聚类方法综述[J]. 计算机科学, 2014, 41 (Suppl. 2): 288- 293
JIN Jian-guo Review of clustering method[J]. Computer Science, 2014, 41 (Suppl. 2): 288- 293
|
|
|
| [18] |
高新. 一种改进K-means聚类算法与新的聚类有效性指标研究[D]. 合肥: 安徽大学, 2020.
GAO Xin. Research on improved K-means algorithm and new cluster validity index[D]. Hefei: Anhui University, 2020.
|
|
|
| [19] |
BELGIU M, DRAGUT L Random forest in remote sensing: a review of applications and future directions[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2016, 114: 24- 31
doi: 10.1016/j.isprsjprs.2016.01.011
|
|
|
| [20] |
胡蕊. 燃煤电厂湿法脱硫塔能效评价研究[D]. 济南: 山东大学, 2020.
HU Rui. Study on energy efficiency evaluation of wet flue gas desulphurization tower in coal-fired power plant[D]. Jinan: Shandong University, 2020.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|