|
|
|
| Safe hierarchical reinforcement learning framework for dynamic UAV navigation |
Yiming SHANG( ),Changping DU*(),Rui YANG,Tianrui FANG,Ze’an DU,Yao ZHENG ),Changping DU*(),Rui YANG,Tianrui FANG,Ze’an DU,Yao ZHENG |
| School of Aeronautics and Astronautics, Zhejiang University, Hangzhou 310027, China |
|
|
|
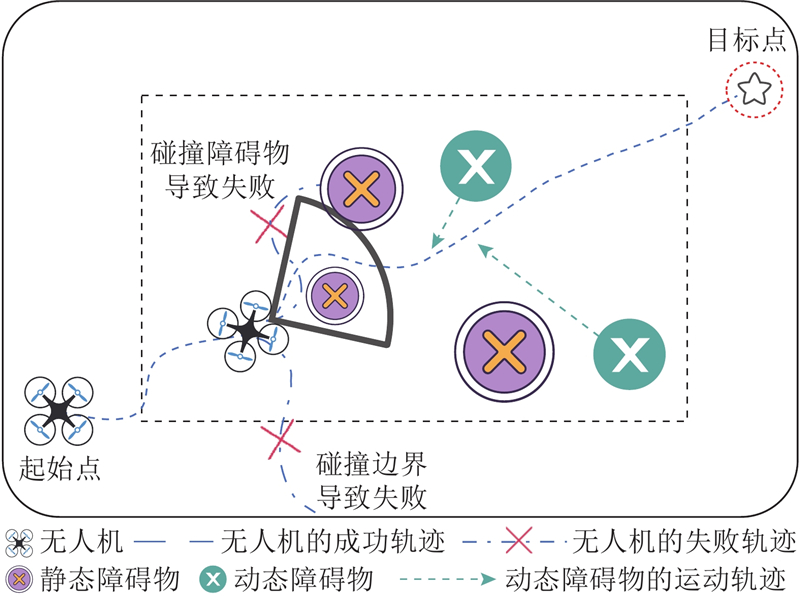
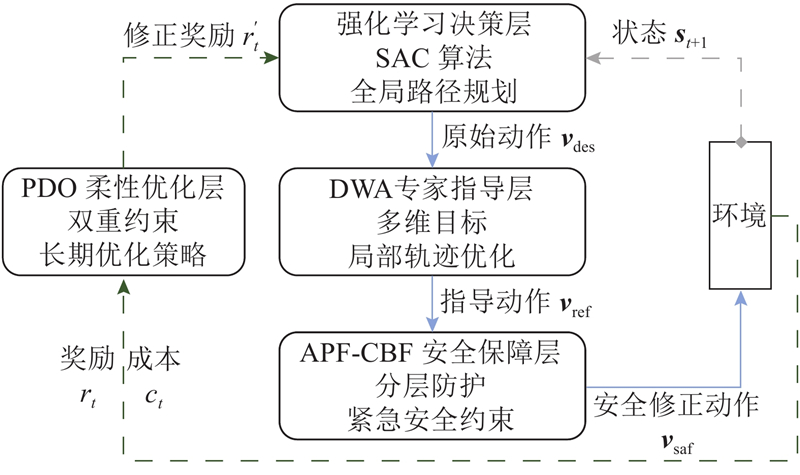
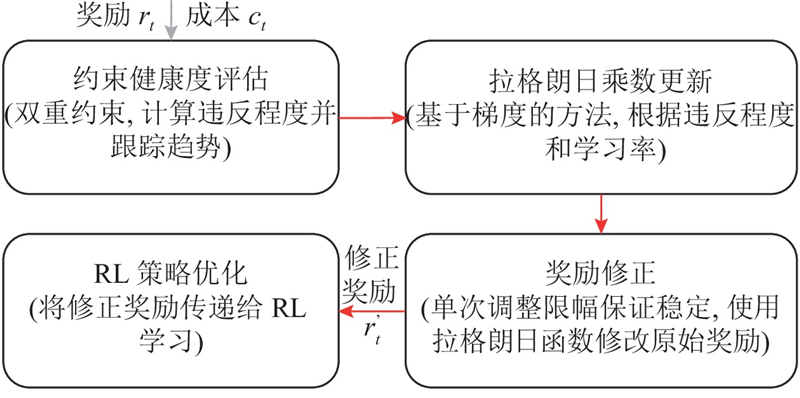
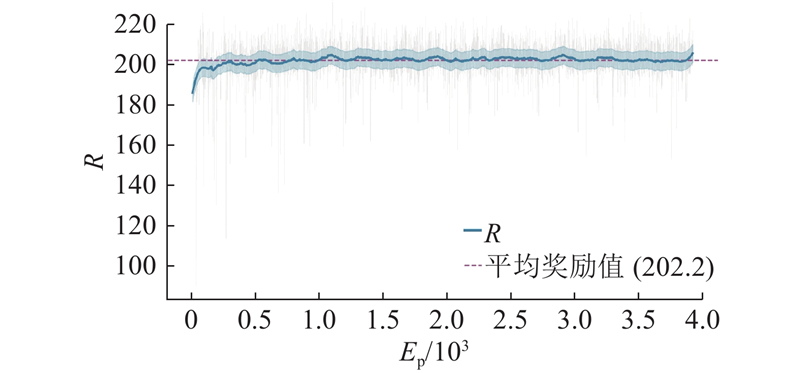
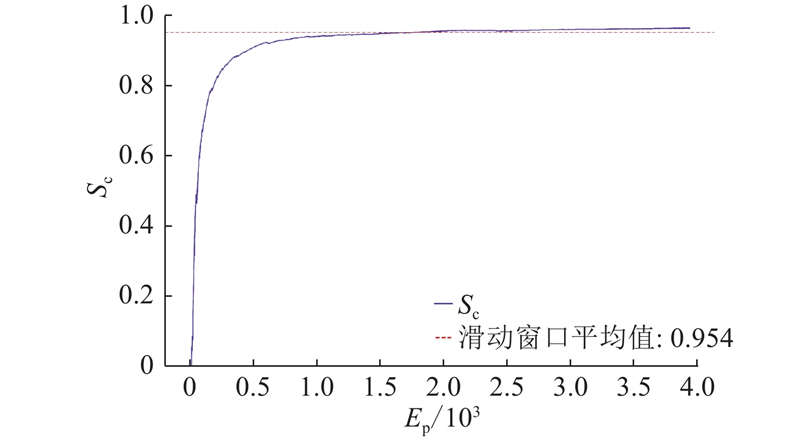
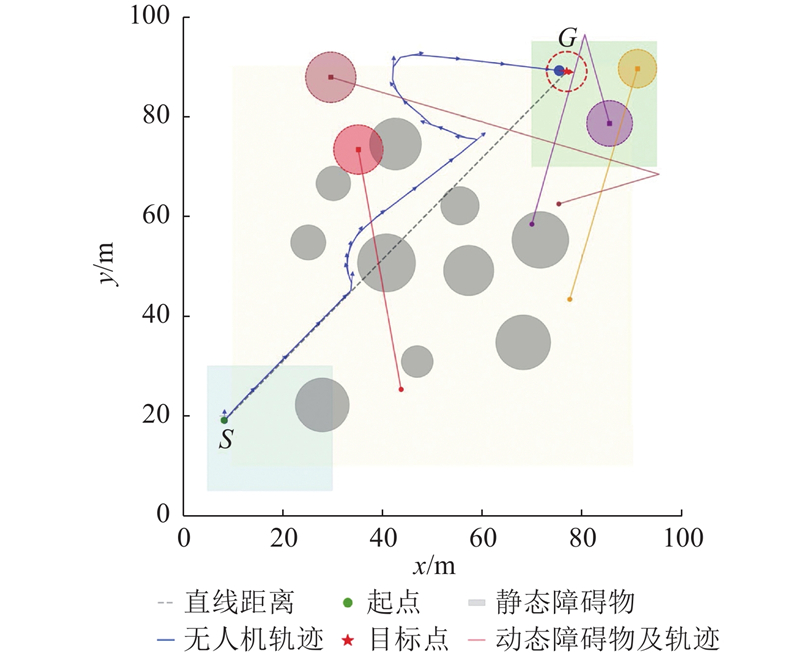
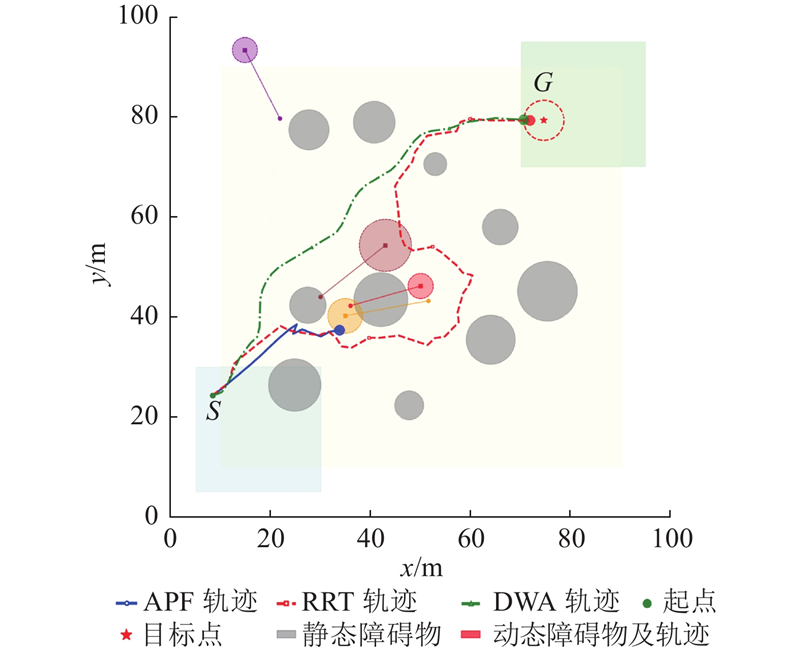
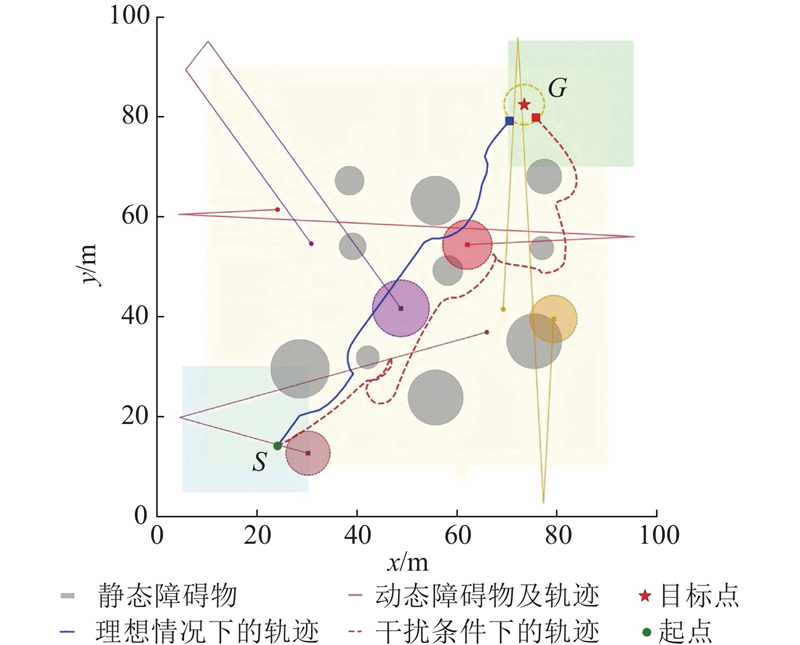
Abstract The safe hierarchical intelligent exploration learning (SHIELD) framework was proposed in order to address the problem of UAV navigation and obstacle avoidance in complex dynamic environment. The framework comprised a four-layer progressive safety-assurance architecture. 1) The reinforcement learning decision-making layer was responsible for global path planning. 2) The expert guidance layer optimized local path via an improved dynamic window approach. 3) The safety assurance layer combined artificial potential field method and control barrier function in order to provide emergency safety constraint. 4) The primal–dual optimization layer optimized long-term policy through a flexible optimization mechanism. A dynamic adaptive reward function was designed, in which the reward weight was adaptively adjusted according to environmental complexity and task progress. Results showed that SHIELD achieved a task success rate of 95.7% and a path efficiency of 0.962 in complex dynamic environment, representing improvement of 48.8% and 30.2% over the reinforcement learning baseline algorithm, and average improvement of 55.0% and 36.0% over three traditional comparative algorithms. The safety and efficiency of UAV navigation in dynamic environment were effectively enhanced.
|
|
Received: 24 August 2025
Published: 06 May 2026
|
|
|
|
Corresponding Authors:
Changping DU
E-mail: 22424059@zju.edu.cn;duchangping@zju.edu.cn
|
动态环境无人机导航的安全分层强化学习框架
针对无人机在复杂动态环境中导航和避障的问题,提出安全分层智能探索学习(SHIELD)框架. 该框架为4层递进式安全保障架构. 1)强化学习决策层负责全局路径规划. 2)专家指导层通过改进的动态窗口法,优化局部路径. 3)安全保障层结合人工势场法和控制屏障函数,提供紧急安全约束. 4)原始-对偶优化层通过柔性优化机制,优化长期策略. 设计动态自适应奖励函数,根据环境复杂度和任务进度自适应调整奖励权重. 结果表明,SHIELD在复杂动态环境中的任务成功率达到95.7%,路径效率达到0.962,较强化学习基线算法提升48.8%和30.2%,较3种传统对比算法平均提升55.0%和36.0%,有效提升了无人机在动态环境中的导航安全性和效率.
关键词:
无人机(UAV),
强化学习,
动态避障规划,
控制屏障函数,
原始-对偶优化,
动态窗口法
|
|
| [1] |
LI Y, ZENG Q, SHAO C, et al UAV localization method with keypoints on the edges of semantic objects for low-altitude economy[J]. Drones, 2024, 9 (1): 14
doi: 10.3390/drones9010014
|
|
|
| [2] |
WANG Z, XIANG X. Improved Astar algorithm for path planning of marine robot [C]//Proceedings of the 37th Chinese Control Conference. Wuhan: IEEE, 2018: 5410-5414.
|
|
|
| [3] |
QI J, YANG H, SUN H MOD-RRT*: a sampling-based algorithm for robot path planning in dynamic environment[J]. IEEE Transactions on Industrial Electronics, 2021, 68 (8): 7244- 7251
doi: 10.1109/TIE.2020.2998740
|
|
|
| [4] |
YANG Y, CHEN Z Optimization of dynamic obstacle avoidance path of multirotor UAV based on ant colony algorithm[J]. Wireless Communications and Mobile Computing, 2022, (1): 1299434
|
|
|
| [5] |
SHORAKAEI H, VAHDANI M, IMANI B, et al Optimal cooperative path planning of unmanned aerial vehicles by a parallel genetic algorithm[J]. Robotica, 2016, 34 (4): 823- 836
doi: 10.1017/S0263574714001878
|
|
|
| [6] |
YU Z, SI Z, LI X, et al A novel hybrid particle swarm optimization algorithm for path planning of UAVs[J]. IEEE Internet of Things Journal, 2022, 9 (22): 22547- 22558
doi: 10.1109/JIOT.2022.3182798
|
|
|
| [7] |
AZAR A T, KOUBAA A, MOHAMED N A, et al Drone deep reinforcement learning: a review[J]. Electronics, 2021, 10 (9): 999
doi: 10.3390/electronics10090999
|
|
|
| [8] |
OUBBATI O S, ATIQUZZAMAN M, BAZ A, et al Dispatch of UAVs for urban vehicular networks: a deep reinforcement learning approach[J]. IEEE Transactions on Vehicular Technology, 2021, 70 (12): 13174- 13189
doi: 10.1109/TVT.2021.3119070
|
|
|
| [9] |
SONNY A, YEDURI S R, CENKERAMADDI L R Q-learning-based unmanned aerial vehicle path planning with dynamic obstacle avoidance[J]. Applied Soft Computing, 2023, 147: 110773
doi: 10.1016/j.asoc.2023.110773
|
|
|
| [10] |
LI D, YIN W, WONG W E, et al Quality-oriented hybrid path planning based on A* and Q-learning for unmanned aerial vehicle[J]. IEEE Access, 2021, 10: 7664- 7674
doi: 10.1109/access.2021.3139534
|
|
|
| [11] |
THOMAS P S, DA SILVA B C, BARTO A G, et al Preventing undesirable behavior of intelligent machines[J]. Science, 2019, 366 (6468): 999- 1004
doi: 10.1126/science.aag3311
|
|
|
| [12] |
HE Y, HOU T, WANG M A new method for unmanned aerial vehicle path planning in complex environments[J]. Scientific Reports, 2024, 14: 9257
doi: 10.1038/s41598-024-60051-4
|
|
|
| [13] |
XU L, XI M, GAO R, et al Dynamic path planning of UAV with least inflection point based on adaptive neighborhood A* algorithm and multi-strategy fusion[J]. Scientific Reports, 2025, 15: 8563
doi: 10.1038/s41598-025-92406-w
|
|
|
| [14] |
HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor [EB/OL]. [2025-08-10]. https://arxiv.org/abs/1801.01290.
|
|
|
| [15] |
FOX D, BURGARD W, THRUN S The dynamic window approach to collision avoidance[J]. IEEE Robotics and Automation Magazine, 1997, 4 (1): 23- 33
doi: 10.1109/100.580977
|
|
|
| [16] |
KHATIB O. Real-time obstacle avoidance for manipulators and mobile robots [M]//Autonomous robot vehicles. New York: Springer, 1990: 396–404.
|
|
|
| [17] |
MATOUI F, BOUSSAID B, ABDELKRIM M N. Local minimum solution for the potential field method in multiple robot motion planning task [C]//Proceedings of the 16th International Conference on Sciences and Techniques of Automatic Control and Computer Engineering. Monastir: IEEE, 2016: 452–457.
|
|
|
| [18] |
ZENG J, ZHANG B, SREENATH K. Safety-critical model predictive control with discrete-time control barrier function [C]//Proceedings of the American Control Conference. New Orleans: IEEE, 2021: 3882–3889.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|