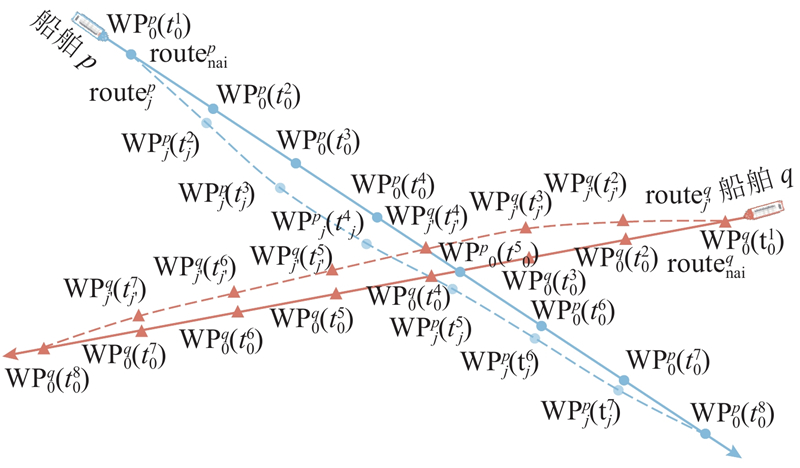
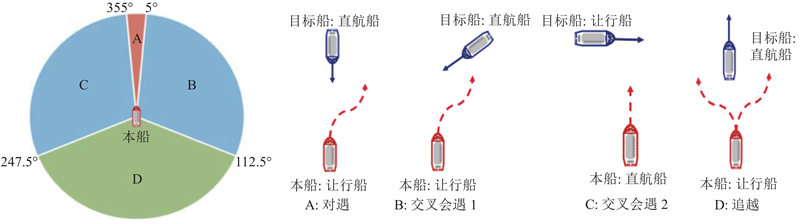
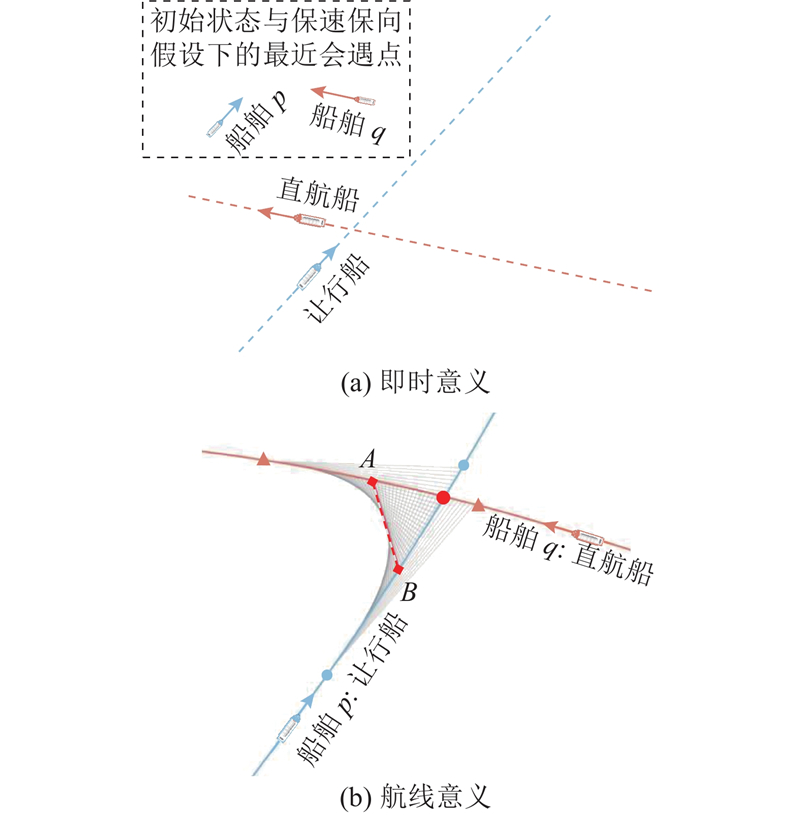
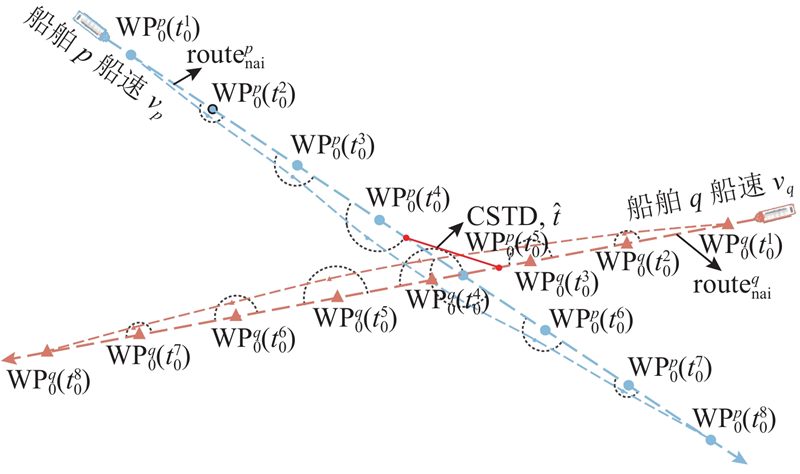
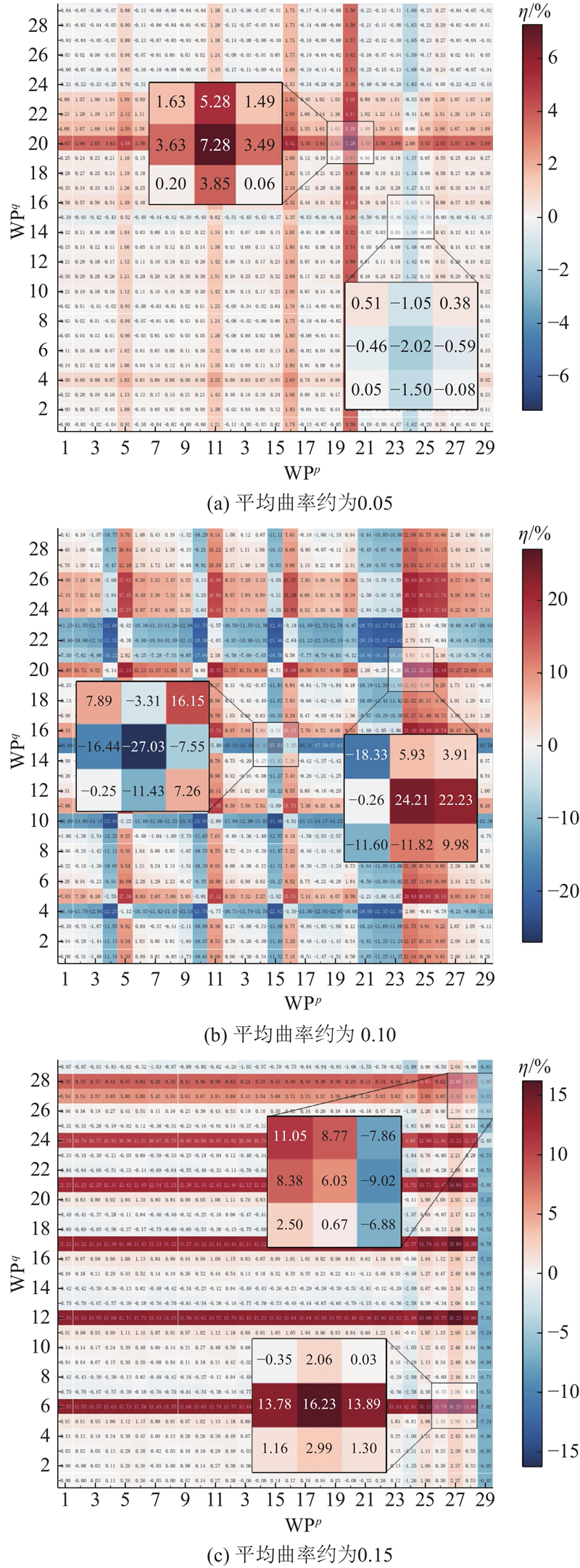
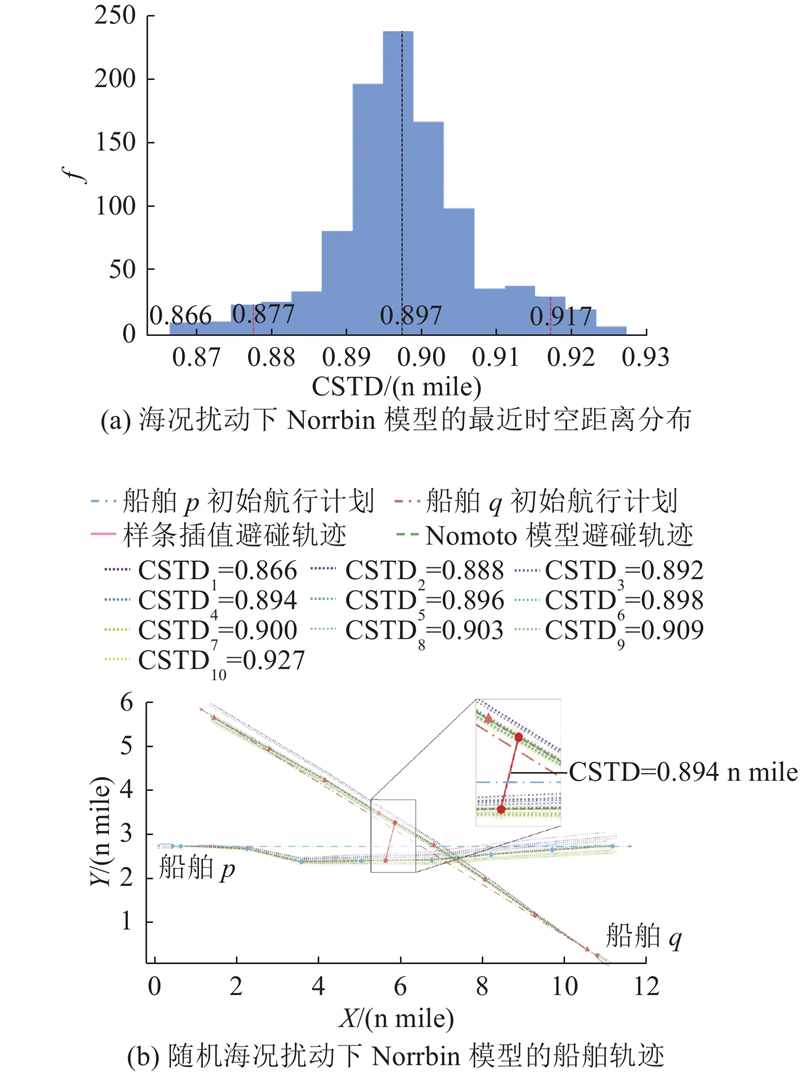
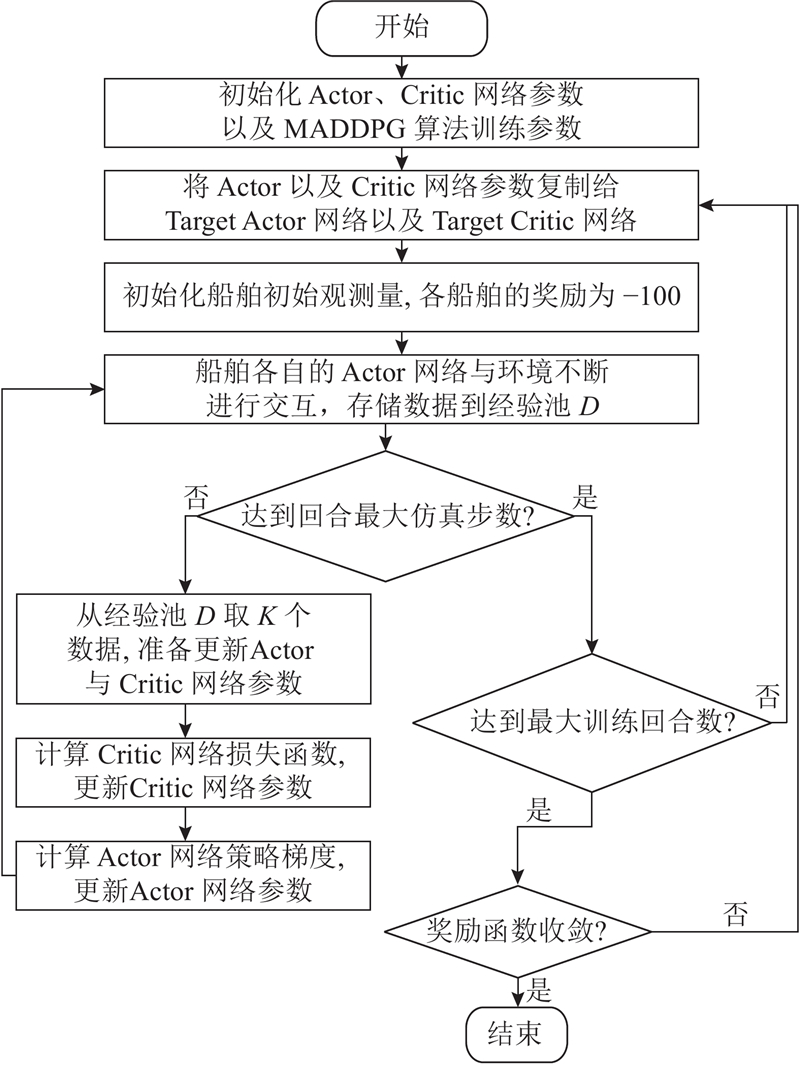
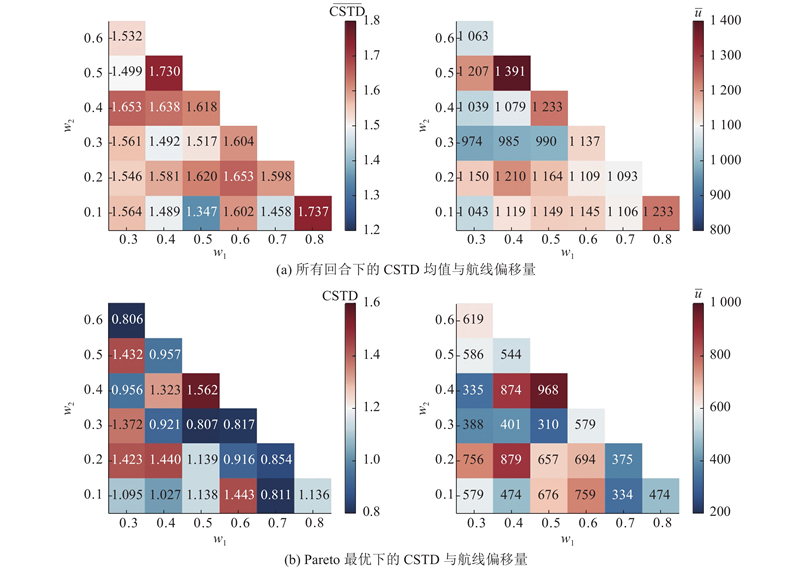
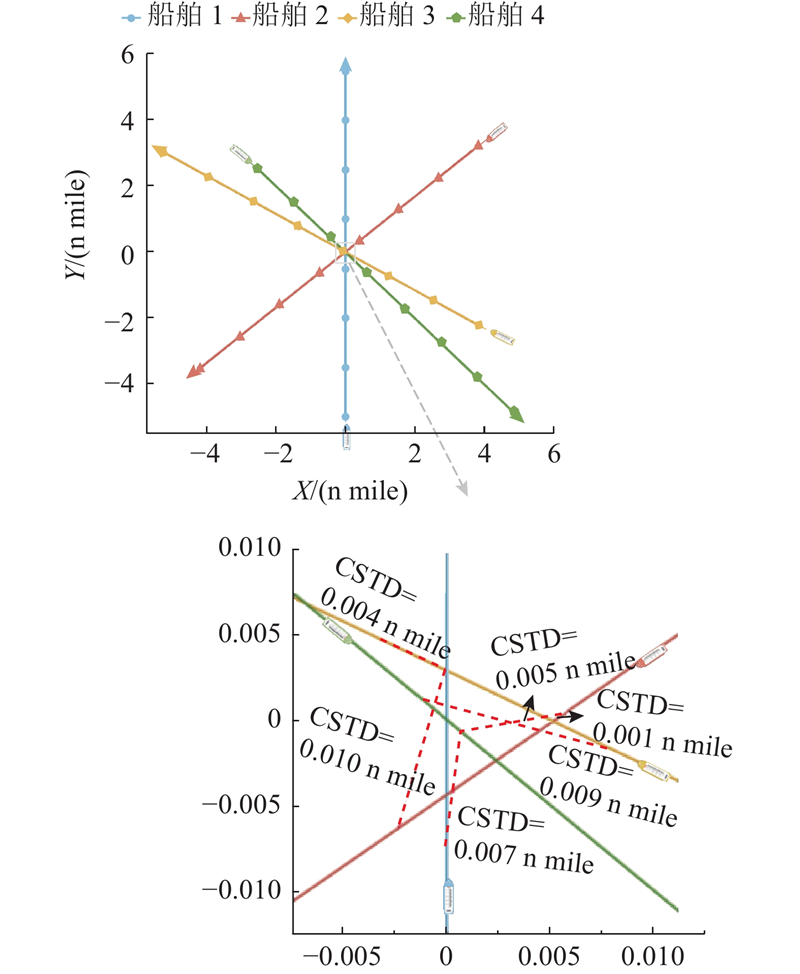
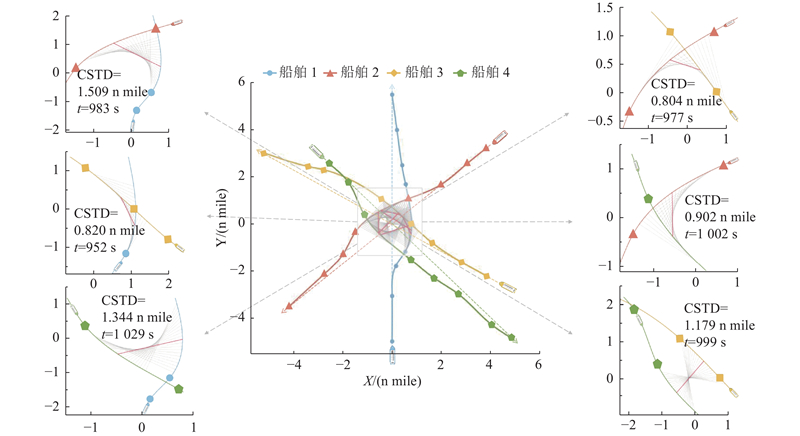
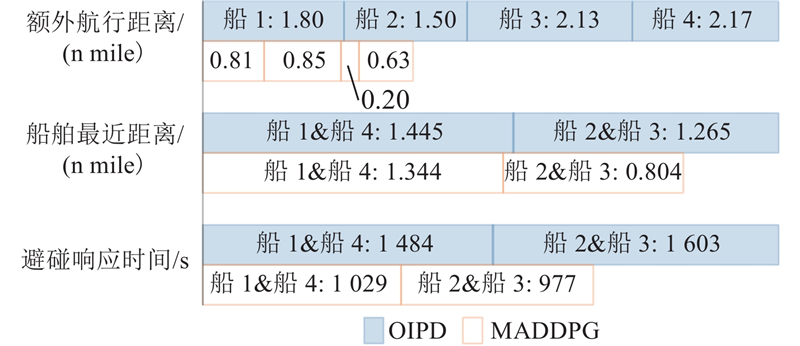
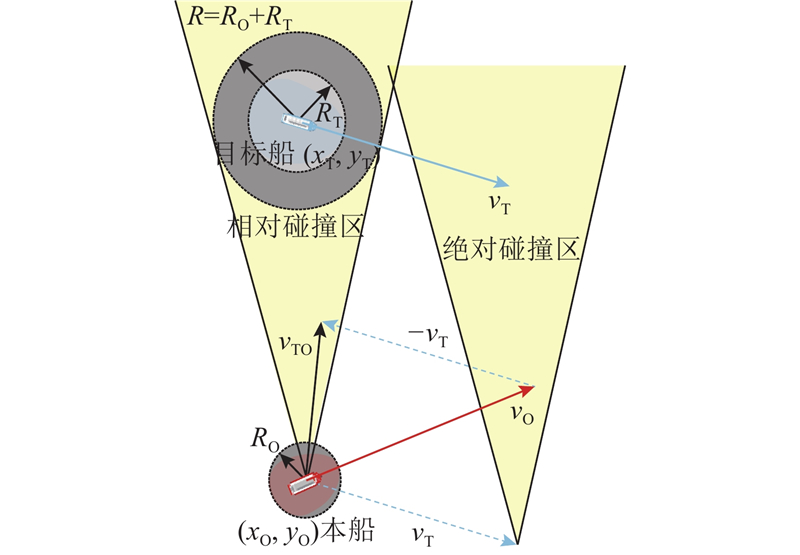
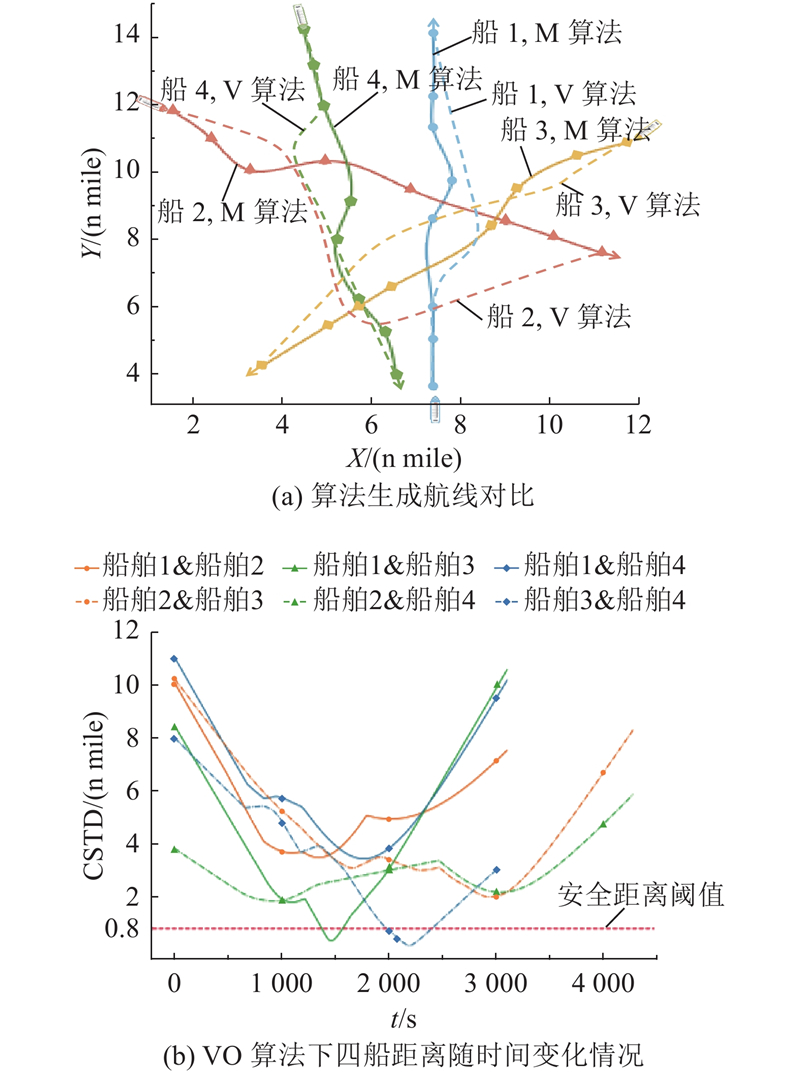
|
|
|
| Multi-ship collision avoidance via route exchange mechanism: strategy learning and game-theoretic decision making |
Yang WANG1,2,3( ),Hongchao LIU1,2,3,Chi TIAN4,Bing WU1,2,3,Di ZHANG1,2,3,*() ),Hongchao LIU1,2,3,Chi TIAN4,Bing WU1,2,3,Di ZHANG1,2,3,*() |
1. State Key Laboratory of Maritime Technology and Safety, Wuhan University of Technology, Wuhan 430063, China
2. Intelligent Transportation Systems Research Center, Wuhan University of Technology, Wuhan 430063, China
3. School of Transportation and Logistics Engineering, Wuhan University of Technology, Wuhan 430063, China
4. CSSC Pride (Nanjing) Technology Group Co., Ltd, Nanjing 211106, China |
|
|
|
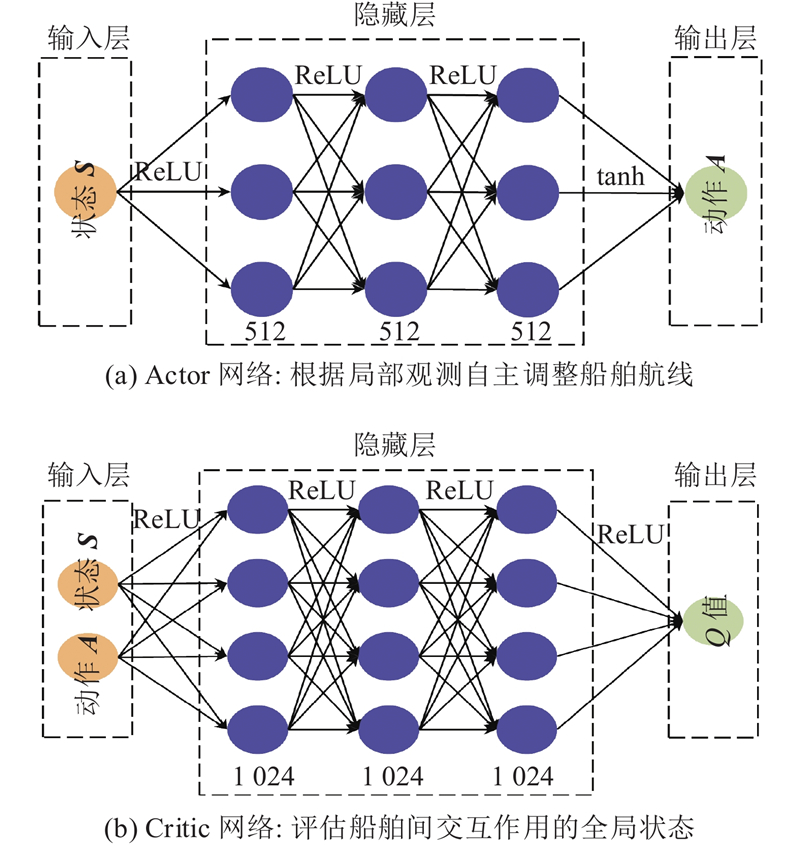
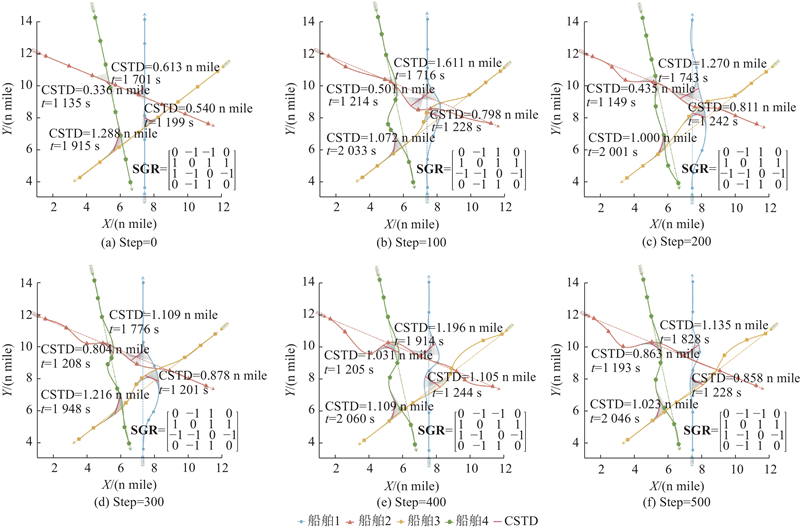
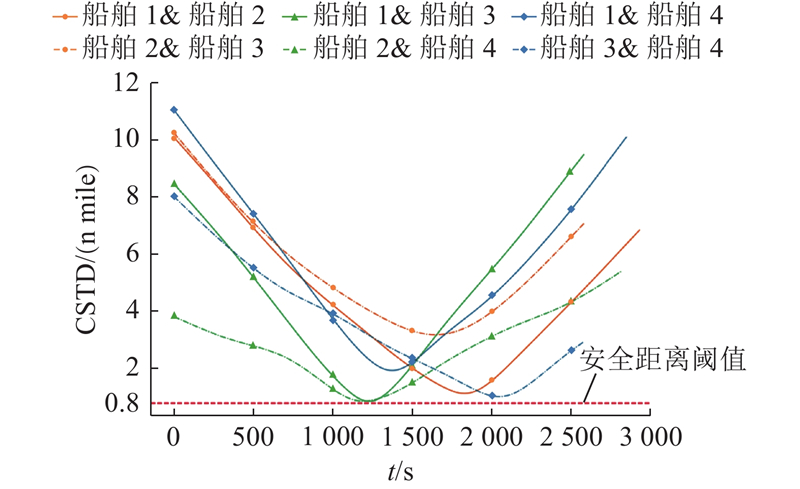
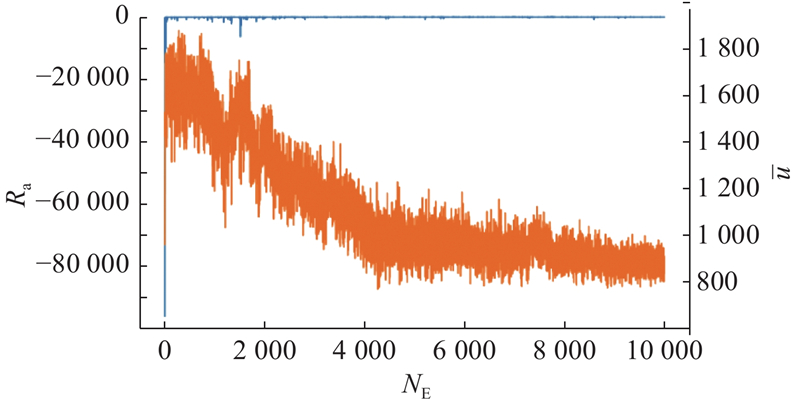
Abstract To address the multi-ship collision avoidance problem in the context of growing onboard intelligence, a cooperative collision avoidance game model based on multi-agent reinforcement learning was developed using the route exchange mechanism. Real-time sharing and negotiation of intended route information among ships were enabled. The multi-ship collision avoidance decision was transformed into a multi-agent cooperative game model, with each ship possessing independent decision-making and execution capabilities and being driven by rationality and economic considerations. The objective is to optimize navigational efficiency, minimize collision risk, and comply with anti-collision rules. The multi-agent deep deterministic policy gradient algorithm was employed within a centralized training with decentralized execution framework to optimize collision avoidance strategies, enabling an approach to the Pareto optimal solution. Simulation results demonstrate that optimized routes obtained through reasonable heading adjustments effectively avoid collision zones, balancing safety, compliance, and navigational efficiency. The model that integrates multi-agent reinforcement learning and game theory provides a feasible solution for intelligent ship collision avoidance decisions under the E-navigation paradigm.
|
|
Received: 29 May 2025
Published: 06 May 2026
|
|
|
| Fund: 国家自然科学基金资助项目(52425210,52372320);国家重点研发计划资助项目(2023YFB4301800,2023YFC3010803). |
|
Corresponding Authors:
Di ZHANG
E-mail: wangyang.itsc@whut.edu.cn;zhangdi@whut.edu.cn
|
航线交换机制下多船避碰的策略学习与博弈决策
针对船舶智能化水平不断提升背景下面临的多船避碰问题,通过航线交换机制,构建基于多智能体强化学习的协同避碰博弈模型,以实现船舶间意向航线信息的实时共享与协商. 由于每艘船舶具备独立的决策与执行能力,在理性与经济性的联合驱动下,将多船避碰决策转化为多智能体协同博弈模型. 各船舶旨在优化航线便捷性、最小化碰撞风险并遵循避让规则,采用多智能体深度确定性策略梯度算法,通过集中训练-分布执行框架优化避碰策略,逐步逼近Pareto最优解. 仿真结果显示,通过合理调整航向得到的优化航线能够有效规避碰撞区域,兼顾安全性与合规性,提升航行效率. 融合多智能体强化学习与博弈论的避碰模型为E-航海条件下智能船舶避碰决策提供了较好可行性的实施方案.
关键词:
水路交通,
多船避碰,
航线交换,
多智能体强化学习,
博弈论
|
|
| [1] |
中国船东互保协会. 2023船舶安全风险报告[EB/OL]. (2024−01−23)[2025−05−11]. https://www.chinapandi.com/index.php/cn/?option=com_attachments&task=download&id=590.
|
|
|
| [2] |
International Maritime Organization. Strategy for the development and implementation of e-navigation [EB/OL]. (2011−07−25)[2025−05−11]. https://wwwcdn.imo.org/localresources/en/OurWork/Safety/Documents/enavigation/MSC%2085%20-%20annex%2020%20-%20Strategy%20for%20the%20development%20and%20implementation%20of%20e-nav.pdf.
|
|
|
| [3] |
International Maritime Organization. E-navigation strategy implementation plan [EB/OL]. (2018−05−28)[2025−05−11]. https://wwwcdn.imo.org/localresources/en/OurWork/Safety/Documents/enavigation/MSC.1-Circ.1595%20-%20E-Navigation%20Strategy%20Implementation%20Plan%20-%20Update%201%20(Secretariat)%20(2).pdf.
|
|
|
| [4] |
贺益雄, 代永刚, 赵兴亚, 等 河口深槽可航宽度变化水域航行决策方法[J]. 上海交通大学学报, 2025, 59 (4): 489- 502
HE Yixiong, DAI Yonggang, ZHAO Xingya, et al Navigation decision method in estuary deep trough with varying width of navigable waters[J]. Journal of Shanghai Jiaotong University, 2025, 59 (4): 489- 502
doi: 10.16183/j.cnki.jsjtu.2023.356
|
|
|
| [5] |
吴建军, 陈炎, 朱清华, 等 紧迫危险威胁下交叉相遇局面应急操船方法[J]. 中国安全科学学报, 2024, 34 (5): 238- 246
WU Jianjun, CHEN Yan, ZHU Qinghua, et al Emergency ship maneuvering method for crossing encounter situation under immediate danger threat[J]. China Safety Science Journal, 2024, 34 (5): 238- 246
doi: 10.16265/j.cnki.issn1003-3033.2024.05.0910
|
|
|
| [6] |
HUANG Y, VAN GELDER P, WEN Y Velocity obstacle algorithms for collision prevention at sea[J]. Ocean Engineering, 2018, 151: 308- 321
doi: 10.1016/j.oceaneng.2018.01.001
|
|
|
| [7] |
WANG T, YAN X, WANG Y, et al Ship domain model for multi-ship collision avoidance decision-making with COLREGs based on artificial potential field[J]. TransNav: International Journal on Marine Navigation and Safety of Sea Transportation, 2017, 11 (1): 85- 92
doi: 10.12716/1001.11.01.09
|
|
|
| [8] |
NING J, CHEN H, LI T, et al COLREGs-compliant unmanned surface vehicles collision avoidance based on multi-objective genetic algorithm[J]. IEEE Access, 2020, 8: 190367- 190377
doi: 10.1109/ACCESS.2020.3030262
|
|
|
| [9] |
WANG T, WU Q, ZHANG J, et al Autonomous decision-making scheme for multi-ship collision avoidance with iterative observation and inference[J]. Ocean Engineering, 2020, 197: 106873
doi: 10.1016/j.oceaneng.2019.106873
|
|
|
| [10] |
欧阳旭东, 支云翔, 王腾飞, 等 基于扩展式动态博弈的多船避碰决策模型[J]. 中国安全科学学报, 2020, 30 (1): 128- 135
OUYANG Xudong, ZHI Yunxiang, WANG Tengfei, et al Antensive form game theory based multi-ship collision avoidance scheme[J]. China Safety Science Journal, 2020, 30 (1): 128- 135
doi: 10.16265/j.cnki.issn1003-3033.2020.01.020
|
|
|
| [11] |
崔浩, 张新宇, 王警, 等 自主船舶与有人驾驶船舶动态博弈避碰决策[J]. 中国舰船研究, 2024, 19 (1): 238- 247
CUI Hao, ZHANG Xinyu, WANG Jing, et al Dynamic game collision avoidance decision-making for autonomous and manned ships[J]. Chinese Journal of Ship Research, 2024, 19 (1): 238- 247
|
|
|
| [12] |
ZHANG X, WANG C, LIU Y, et al Decision-making for the autonomous navigation of maritime autonomous surface ships based on scene division and deep reinforcement learning[J]. Sensor, 2019, 19 (18): 4055
doi: 10.3390/s19184055
|
|
|
| [13] |
黄仁贤, 罗亮 基于多智能体深度强化学习的多船协同避碰策略[J]. 计算机集成制造系统, 2024, 30 (6): 1972- 1988
HUANG Renxian, LUO Liang Multi-ship collaborative collision avoidance strategy based on multi-agent deep reinforcement learning[J]. Computer Integrated Manufacturing Systems, 2024, 30 (6): 1972- 1988
doi: 10.13196/j.cims.2023.0382
|
|
|
| [14] |
WANG Z, CHEN P, CHEN L, et al Collaborative collision avoidance approach for USVs based on multi-agent deep reinforcement learning[J]. IEEE Transactions on Intelligent Transportation Systems, 2025, 26 (4): 4780- 4794
doi: 10.1109/TITS.2025.3547775
|
|
|
| [15] |
Marine Safety Investigation Unit. Marine safety investigation report [EB/OL]. (2020−03−18)[2025−05−11]. https://www.marfag.no/k52/media/mt-aseem-final-safety-investigation-report.pdf.
|
|
|
| [16] |
刘立群, 吴超仲, 褚端峰, 等 基于Vondrak滤波和三次样条插值的船舶轨迹修复研究[J]. 交通信息与安全, 2015, 33 (4): 100- 105
LIU Liqun, WU Chaozhong, CHU Duanfeng, et al A study of ship trajectory restoration based on Vondrak filtering and cubic spline interpolation[J]. Journal of Transport Information and Safety, 2015, 33 (4): 100- 105
doi: 10.3963/j.issn1674-4861.2015.04.016
|
|
|
| [17] |
WANG Y, YE Q, LAU H, et al Nash bargaining strategy in autonomous decision making for multi-ship collision avoidance based on route exchange[J]. IET Intelligent Transport Systems, 2025, 19 (1): e70025
doi: 10.1049/itr2.70025
|
|
|
| [18] |
WANG Y, ZHANG J, CHEN X, et al A spatial-temporal forensic analysis for inland-water ship collisions using AIS data[J]. Safety Science, 2013, 57: 187- 202
|
|
|
| [19] |
ZHANG K, HUANG L, HE Y, et al A real-time multi-ship collision avoidance decision-making system for autonomous ships considering ship motion uncertainty[J]. Ocean Engineering, 2023, 278: 114205
doi: 10.1016/j.oceaneng.2023.114205
|
|
|
| [20] |
LI G, ZHANG X Research on the influence of wind, waves, and tidal current on ship turning ability based on Norrbin model[J]. Ocean Engineering, 2022, 259: 111875
doi: 10.1016/j.oceaneng.2022.111875
|
|
|
| [21] |
符小卫, 王辉, 徐哲 基于DE-MADDPG的多无人机协同追捕策略[J]. 宇航学报, 2022, 43 (5): 325311
FU Xiaowei, WANG Hui, XU Ze Cooperative pursuit strategy for multi-UAVs based on DE-MADDPG algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2022, 43 (5): 325311
|
|
|
| [22] |
WANG N An intelligent spatial collision risk based on the quaternion ship domain[J]. The Journal of Navigation, 2010, 63: 733- 749
doi: 10.1017/S0373463310000202
|
|
|
| [23] |
Sea Traffic Management. Route exchange ship-ship [EB/OL]. (2015−12−10)[2025−05−11]. https://stm-stmvalidation.s3.eu-west-1.amazonaws.com/uploads/20160420153149/Draft-description-of-test-bed-services-and-information-needs_2015-12-10.pdf.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|